
并行环境下Java哈希机制的对比及重构
2017-12-02 01:40郑雅洁张冬雯梁亚楠魏萌萌
河北工业科技 2017年6期
郑雅洁,张冬雯,张 杨,郭 松,梁亚楠,魏萌萌,于 欣
(河北科技大学信息科学与工程学院,河北石家庄 050018)
并行环境下Java哈希机制的对比及重构
郑雅洁,张冬雯,张 杨,郭 松,梁亚楠,魏萌萌,于 欣
(河北科技大学信息科学与工程学院,河北石家庄 050018)
针对并行环境下出现的非线程安全问题,以哈希机制的Hashtable和ConcurrentHashMap的线程安全问题为切入点,设计了可改变线程总数和读写线程数的测试程序,分析了线程安全的ConcurrentHashMap和Hashtable的性能差异。根据性能差异,设计了从Hashtable到ConcurrentHashMap的程序自动重构插件,进而在Hashtable封装数据的情况下,通过对比传统多线程处理方式和Java8中的并行流处理方式的性能差异,分析了流处理方式相对普通多线程处理方式的高效性。对比结果显示,ConcurrentHashMap在并行程序中的性能要优于Hashtable。研究结果为多线程程序开发提出了解决非线程安全提供了较为可行的新思路,对于并行编程具有借鉴意义。
程序设计及其语言;线程安全;ConcurrentHashMap;哈希机制;重构;并行;流处理;Java8
随着多核处理器的普及和众核处理器设计技术的不断发展,并行程序设计模型、语言和工具越来越受到人们的重视[1-3]。然而程序的并发必然会出现多个线程互斥访问临界资源的情况[4],为了保证程序的安全性,并行程序的线程安全问题已成为并行程序设计和开发中的重要问题。
哈希表是依据键值对进行访问的一种数据结构,它可以快速地插入数据和查找数据[5-8],是一种程序开发者常用的数据结构。国内外很多研究人员对哈希表的性能进行过研究,文献[9]提出了一种重构工具,可以使程序从HashMap自动重构为ConcurrentHashMap,并且分析了重构需要面临和解决的问题。文献[10]分析了Java哈希表的实现特点,并给出了导致其性能恶化的一种数据模式,针对这种数据模式的特点,提出了基于素数序列的哈希表优化方法,从而几乎完全避免了该模式下哈希表的性能恶化。
随着Java版本的更新换代,编程方法越来越高效和完善。从Java2中非线程安全的HashMap到后来提出了线程安全的Hashtable和ConcurrentHashMap,再到Java8的普及和应用,均针对线程安全问题提出了新的解决办法。Java8中新增了Lambda表达式、流和默认方法[11-12],提出了行为参数化的软件开发模式。同时在Lambda表达式的基础上提出了流处理[13]。流处理这种较为新型的处理数据模式避免了多线程程序的线程临界域访问带来的非线程安全问题,为程序开发者提供了性能提高的新思路[14]。然而国内外对并行流的研究还不够全面,因此流处理编程依然存在很大的发展和研究空间。Java8的Stream包中包含了一种parallelStream()方法,并行流的运行机制实则是将一个流智能分为多个区间,多个小区间的流同时启动多个线程运行[15]。随着并行流处理数据方式的提出,程序开发者在传统多线程和并行流处理方式之间的选择成为了程序开发的又一个关键性问题。
重构是代码修改完善的主要方法。如何快速高效地重构程序实现编程人员的预期效果,成为了软件缺陷检测、软件功能完善等领域的关键问题[16]。文献[17]提出了静态竞争检测的重要问题,其不仅可以检测传统java.lang.Thread等底层并行机制的数据竞争,而且还实现了检测fork-join、并行循环等高级并行机制的数据竞争。为了提高精确度和可伸缩性,引入了集合中的线程、安全和数据流以及Java8中的新循环并行化结构,还评估了每个专业化技术对运行时间和精度的影响。文献[18]研究了关于度量代码的隐含风险错误和开发人员执行的重构活动之间关系,发现两者之间没有实质性的关系,存在代码隐含风险的程序可能需要重构,有42%的重构操作是受代码隐含风险影响的,并且只有7%的执行操作直接删除了隐含风险部分。
本文对哈希机制线程安全问题进行研究,对比了两种线程安全的哈希机制Hashtable和ConcurrentHashMap,实现了Hashtable程序自动重构为ConcurrentHashMap,以减少改写代码的任务量。同时探究了并行流编程方式和传统多线程方式的性能差异。
1 问题的提出
从JDK1.2开始,出现了哈希映射(Hashmap),它是基于哈希表(Hashtable)的Map接口实现,与哈希表的实现大致相同[19]。值得注意的是,哈希映射的实现并不是同步的。当多个线程同时访问一个哈希映射且其中不止一个线程对该映射的结构进行了修改时,这个哈希映射必须保持外部同步[20]。因此,在多线程环境下哈希映射是非线性安全的,也就是说在多线程环境下哈希映射的出错率更高。随着JDK1.5版本的出现,一个新的类ConcurrentHashMap解决了哈希映射在多线程程序中的问题[21]。它可以支持并行多线程操作,保证了程序的线程安全,使操作不产生数据冲突。对比Hashtable和ConcurrentHashMap,同样都能保证多线程对哈希表进行操作时的线程安全。那么在多线程编程时,如何在Hashtable和ConcurrentHashMap中做出选择,就变成了并行程序开发人员面临的重要问题。为了提高程序开发者在并行程序中的开发效率,避免编程中对Hashtable和ConcurrentHashMap进行选择而浪费不必要的时间,笔者分别利用Hashtable和ConcurrentHashMap,在相同的实验环境下对程序进行对比测试。
随着Java8的普及,流处理作为一种新型的处理数据模式引起了程序开发人员的广泛关注,在流处理中的并行流处理更是为并行程序设计开辟了新的天地[22-24]。流处理方式不仅减少了普通编程模式的代码量,而且实现了编程效率和程序性能的大幅度提高。尤其并行流不仅省去了普通多线程程序划分线程的繁琐工作,而且避免了多线程中的非线性安全问题的发生。深入研究并行流的性能,可以为并行程序开发者提供一种安全可靠的新思路。本文探究了传统多线程编程模式和流处理方式处理程序的性能优劣。
2 性能比较框架
通过设计2个不同的测试程序,从以下两方面进行比较。
1)分别用Hashtable和ConcurrentHashMap对并行程序进行操作,在改变读写线程数、总数据量等参数的情况下,检测两者的性能差异。
2)在用Hashtable封装数据的情况下,分别用传统多线程编程模式和并行流编程模式完成同一任务,探究是否用并行流处理数据的效率更显著,分析流处理相对于传统多线程处理方式的性能差异。
2.1Hashtable和ConcurrentHashMap的对比
Hashtable是线程安全的,而HashMap是非线程安全的,然而ConcurrentHashMap的出现,使哈希映射变成线程安全的[13]。考虑到Hashtable和ConcurrentHashMap在用法上的相似之处,这里在相同的实验环境下分别用Hashtable和ConcurrentHashMap来对同样规模的数据进行读写操作。由于哈希表本身有读操作和写操作,为了保证实验的全面性,本文需要实现多线程读写操作,需要创建一个可以改变不同总线程数,不同读写线程数和数据总量的测试程序。
本测试程序将指定取值范围0~100的随机数组分别放入Hashtable和ConcurrentHashMap中,改变总线程数和读写线程数,记录程序执行时间并对比实验数据。设计了ReadThread,WriteThread类,分别定义了读线程和写线程的参数,在读写线程类中引入了一个for循环来控制读写次数。
通过执行多次读写线程来避免由于单个读写操作的时间太短而无法准确测试出多线程下的读写性能差,以2个for循环与线程启动方法start()启动预定的读写线程,让读写操作自动运行,这时多线程的操作控制调配权就交给了JVM,不需要且也无权再进行人为干预。为了保证时间记录的准确性,在设计程序时,将选出的随机数组放入哈希表中的操作时间去掉。ConcurrentHashMap与Hashtable的程序设计思路类似,不同的是需要将哈希表定义运用ConcurrentHashMap包来实现。
2.2基于Java哈希表的并行流的程序设计
在JDk1.8的Stream包中包含了一种parallelStream()方法,其中如果一个流因为内在的数据关系无法进行拆分,尽管定义了并行流,也会按照串行流的机制进行单线程的运行,新出现的处理数据方式Stream包中的并行方式对程序执行效率有多大影响,本研究通过具体实验探究并行流的性能差异。
将指定取值范围0~100的随机数组放入Hashtable中,比较使用传统多线程模式和并行流模式时,执行筛选大于50的奇数操作使之呈现出的性能差异。
stream只是一种新的编程思路,但是它本身不包括装载数据的容器,所以,分别选用Hashtable作为数据容器来完成多线程和并行流对比程序的编写。并行流程序设计范例如下。
1 private static final int
DATA_SCALE = 3_000_000;
2 private static long count = 0;
...
3 Stream stream;
...
4 filter(Map.Entry
〈String, Integer〉 n) -〉 {
5 return n.getValue() > 50;
6 }).filter(n -〉 {
7 return n.getValue() % 2 == 1;
8 }).count();
...
9 System.out.println
("Done. It took " + new Date
(new Date().getTime() - hashtable_
before.getTime()).getTime()
+ "ms to operate on HashTable.
" + count + " odd numbers found. ")。
分别在多线程和流程序测试类中定义DATA_SCALE用来控制数据总量;count用于统计符合条件数据的数量;流测试程序中定义Stream类型的stream。创建Hashtable,为了保证放入哈希表时所用的时间影响最终测量时间,先计量初始时间,用for循环将0~100之间的随机数组放入哈希表内,再次记录时间,最后在总时间中将放数据的时间去掉。在处理哈希表的数据时,分别采用多线程方式和并行流进行处理。多线程程序中人为设定,将数据平均分为4份放入4个线程中,启动线程,用线程同时处理数据,记录处理数据时间。流处理程序中先设置Date类型的对象stream_before,用来计算数据处理所使用的时间。Hashtable调用entrySet()方法,用于把Hashtable转化为Set类型的容器。调用stream()方法将其转变为流,而不能直接使用Hashtable转变。因为stream()方法定义在Collection接口中,而Set实现了Collection接口,从而可以调用stream()方法,将自身转变为流。但是Hashtable实现的是Map接口,故无法转变为流。在形成流之后,在流中调用流的filter()方法实现数据的筛选。通过n.getValue()方法筛选出大于50的所有数据;继续调用filter()方法,对流进行操作,这次是通过%运算找出所有大于50 的数据中的奇数。在处理结束后调用count()方法,统计处理后一共有多少个符合要求的数据。最后通过Date的getTime()方法与ConcurrentHashMap_before的减法运算计算出筛选数据所使用的时间。
3 实 验
本实验测试环境如下:硬件上,使用英特尔Xeon E5-2650处理器,主频为2.6 GHz,该处理器有16个处理核,均支持超线程技术,硬件线程数为32,内存为128 GB;软件上,使用Windows7 64位操作系统,使用Eclipse 4.5.1为重构平台,JDK版本是1.8.0_25。
3.1Hashtable与ConcurrentHashMap多线程读写性能对比
在本实验中,分别设置不同线程总数,每个总线程数又分不同读写线程数,分别为1个读线程、(总线程数*1/2)的读线程和(总线程数-1)的读线程。测试数据设置3个数量级别:100万,200万和300万。实验通过对比在固定线程数量时,随着数据量的增加,在对Hashtable和ConcurrentHashMap执行同样操作、处理同等数据时所消耗时间的差别,来测试出两者在性能上的差异。在本次测试过程中,每组数据测试5次,取5次的平均值,最终通过表格展现出来。
为了更直观地看清不同线程数的对比效果,将以上数据绘制成图表。如图1—图4所示,分别是8线程、16线程、32线程、64线程在不同数据量时的时间差异对比。其中横轴代表总线程数:读线程数+写线程数;纵轴代表运行时间,ms。
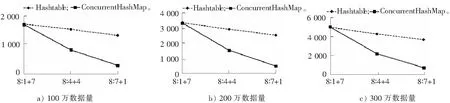
图1 8线程的对比图Fig.1 Comparison of 8 threads

图2 16线程的对比图Fig.2 Comparison of 16 threads
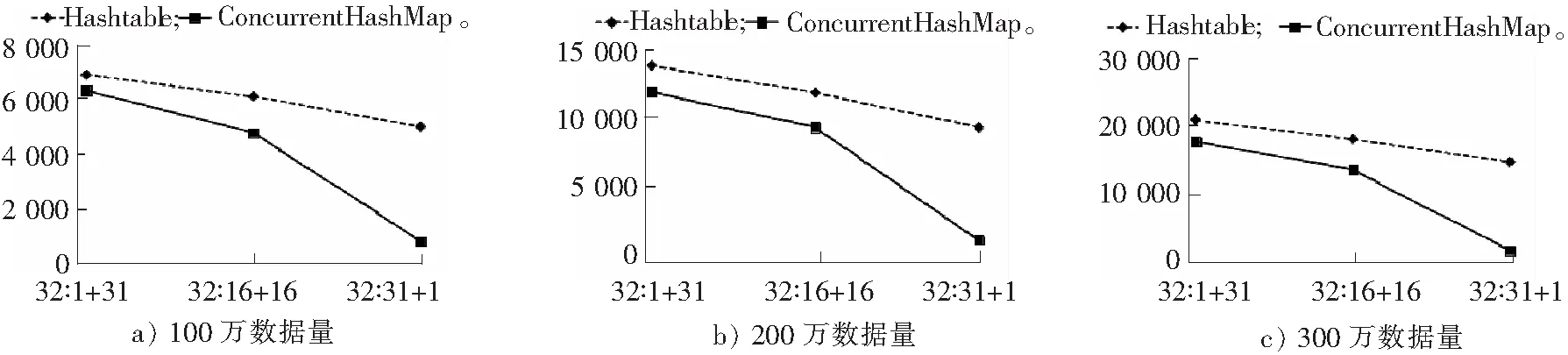
图3 32线程的对比图Fig.3 Comparison of 32 threads

图4 64线程的对比图Fig.4 Comparison of 64 threads
通过计算ConcurrentHashMap和Hashtable性能的提升情况,显示用ConcurrentHashMap会比用Hashtable的性能有所提升。大部分情况下,当数据量增加时,使用ConcurrentHashMap的性能优越性有更明显的趋势。在总线程数相同的情况下,读线程越多,ConcurrentHashMap的优越性越明显,当写线程变为1时,性能已经提升了3倍~6倍,这说明当读线程多的情况下,使用ConcurrentHashMap的性能要远优于Hashtable。随着总线程数的增加,ConcurrentHashMap的优越性越明显。
因此,当遇到总线程多、读线程多的程序时,应该选择ConcurrentHashMap来实现编程。
3.2面向哈希表的重构
通过3.1节的对比不难看出,在程序设计的过程中,需要将使用Hashtable的地方替换为ConcurrentHashMap来提高程序的运行效率。针对本文的程序对比情况,基于Eclipse JDT开发一种可以使Hashtable自动转换为ConcurrentHashMap的重构工具。
Hashtable重构为ConcurrentHashMap的实现思路:选择被重构的类,将其生成AST树,并存放在设定的容器中;挨个遍历容器中的每个节点,找到要被重构的节点;使用JDT技术进行ConcurrentHashMap代码的替换和生成。
图5展示了重构的部分界面,图5中完成的更改操作是将Hashtable的get()方法重构为ConcurrentHashMap的get()方法,取出数据。重构的意义就是改变代码的内部结构,而不更改程序的功能,使程序的代码更加的高效,同时使自己的程序更加的健全。
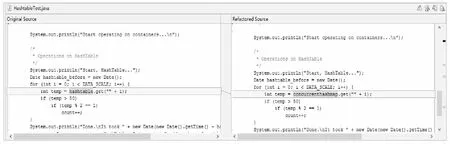
图5 重构预览Fig.5 Refactoring preview
3.3基于哈希表的并行流性能对比
为了测试传统多线程和并行流在Hashtable中的数据筛选性能,在Hashtable数据容器中放入指定数据量的数据,分别用多线程和并行流处理数据,筛选出符合预先设置条件的数据,通过改变放入容器的数据量进行多次测量,来进行两者之间的比较,统计从开始筛选到筛选结束所使用的时间差异,体现出其性能上的差异。设定选择从300万数据起,以100万为递增梯度,一直到3 000万数据量。每个数据量下测试5次,取5次测试的平均值做最后的汇总分析,中间会剔除个别由于JVM或者计算机系统本身所导致的异常数据。同时为了保证测试的准确性,测试时将所有无关进程与后台程序手动关闭,在同一台机器上保证同样的运行环境以完成所有的测试。
根据测试结果绘制折线图,如图6所示。
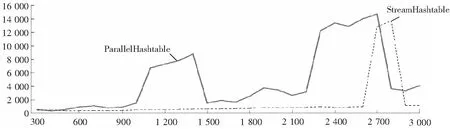
图6 基于Hashtable的多线程和并行流对比图Fig.6 Multi thread and parallel flow contrast diagram based on Hashtable
图6为基于Hashtable的多线程和并行流对比图,横轴代表数据量的大小,纵轴代表程序的执行时间,ms。可以看出,用多线程执行程序比并行流的时间波动更大,数据总量在1 000万~1 500万和数据总量在2 200万~2 800万时有着明显的时间波动,这说明使用并行流处理程序出现偶然时间波动情况的概率更小。从时间差异来看,数据量为300万~2 700万时,并行流方式都显示出很大的时间性能优势,时间差高至10倍。需要说明的是,由于多线程处理模式中,人为将数据分为多个线程可能造成无法均分的现象,多线程会出现时间的波动,数据量越大数据波动越明显。由于执行程序的机器执行数据的能力有限,当数据量过大时会造成处理数据时间上的偏差。总之,并行流的执行效率比多线程要高,程序设计者在编写大数据处理量的程序时可以考虑用并行流方式来替代多线程方式。
4 结 语
本文对线程安全的Java哈希机制性能差异问题进行了研究,对它们的性能进行对比,并且实现了从Hashtable到ConcurrentHashMap的自动重构转换。实验表明,ConcurrentHashMap在并行程序中的性能要优于Hashtable。进而又研究了Hashtable封装下的多线程和并行流在设计程序时的性能差异,验证了并行流处理数据方式的高效性。若仅仅是数据的过滤筛选和映射等操作,不涉及数据的写入、修改,那么Java8新增的流处理更加高效,可以为并行程序设计提供参考。
/
[1] RADOI C, HERHUT S, SREERAM J, et al. Are web applications ready for parallelism?[C]// Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. New York:ACM, 2015:289-290.
[2] 柳晨光. 面向多线程机制的软件重构方法研究与实现[D]. 石家庄:河北科技大学,2016.
LIU Chenguang. Research and Implementation of Software Refactoring Method for Multi-thread Mechanism[D].Shijiazhuang: Hebei University of Science and Technology, 2016.
[3] JONES C G, LIU R, MEYEROVICH L, et al. Parallelizing the web browser[C]// HotPar’09 Proceedings of the First USENIX Conference on Hot Topics in Parallelism. Berkeley:USENIX Association, 2009:7.
[4] 麻孜宁, 伊浩, 李祥. Java多线程并发系统中的安全性与公平性[J]. 计算机技术与发展, 2006, 16(2):120-122.
MA Zining,YI Hao,LI Xiang.Safety and fairness in Java multithreading concurrent system[J].Computer Technology and Development,2006, 16(2):120-122.
[5] 杨虹,卢贵武,张雪粉,等. 油、水、活性剂混合体系在方解石表面吸附的微观机理[J]. 中国石油大学学报(自然科学版),2009,33(1):131-135.
YANG Hong, LU Guiwu,ZHANG Xuefen,et al. Microscopic mechanism of adsorption of oil-water-surfactant mixture on calcite surface[J]. Journal of China University of Petroleum(Edition of National Science), 2009,33(1):131-135.
[6] 卫冰洁, 王啸, 熊刚,等. 一种并发哈希表的无锁操作方法[P]. 中国专利:CN106055646A, 2016-05-31.
[7] 成学文, 李德群, 周华民,等. 基于哈希表的STL面片冗余顶点快速滤除算法[J]. 华中科技大学学报(自然科学版), 2004, 32(6):69-71.
CHENG Xuewen,LI Dequn,ZHOU Huamin,et al.Algorithm for fast filtering redundancy vertex in STL solid based on Hashtable[J].Journal of Huazhong University of Science and Technology(Nature Science Edition), 2004, 32(6):69-71.
[8] 邓绍江,廖晓峰,肖迪.一种基于混沌的可并行Hash函数[J].计算机科学, 2008, 35(6):217-219.
DENG Shaojiang,LIAO Xiaofeng,XIAO Di. A parallel Hash function based on chaos[J]. Computer Science, 2008, 35(6):217-219.
[9] DIG D, MARRERO J, ERNST M D. Refactoring sequential Java code for concurrency via concurrent libraries[C]// ICSE’09 Proceedings of the 31st International Conference on Software Engineering.Washington DC:IEEE Computer Society,2009:397-407.
[10] 廖名学, 范植华. 基于素数序列的Java哈希表性能优化[J]. 计算机工程与应用, 2008, 44(3):108-109.
LIAO Mingxue,FAN Zhihua.Prime number sequence based performance improvement in Java Hashtable[J].Computer Engineering and Applications,2008,44(3):108-109.
[11] BEDI K, SNYDER N, BRANDIMARTO J, et al. Evidence for intramyocardial disruption of lipid metabolism and increased myocardial ketone utilization in advanced human heart failure[J]. Circulation, 2016, 133(8):706-716.
[12] RICCI A, VIROLI M, PIANCASTELLI G. simpA : An agent-oriented approach for programming concurrent applications on top of Java[J]. Science of Computer Programming, 2011, 76(1):37-62.
[13] MASEGOSA A R, MARTINEZ A M, BORCHANI H. Probabilistic graphical models on multi-core CPUs using Java 8[J]. IEEE Computational Intelligence Magazine, 2016, 11(2):41-54.
[14] 王栋, 熊金波, 张晓颖. 面向云数据安全自毁的分布式哈希表网络节点信任评估机制[J]. 计算机应用, 2016, 36(10):2715-2722.
WANG Dong,XIONG Jinbo,ZHANG Xiaoying.Trust evaluation mechanism for distributed Hash table network nodes in cloud data secure self-destruction svstem[J].Journal of Computer Applications, 2016, 36(10):2715-2722.
[15] BENDORY T. Robust recovery of positive stream of pulses[J]. IEEE Transactions on Signal Processing, 2017, 65(8):2114-2122.
[16] 陈翔, 顾庆, 刘望舒,等. 静态软件缺陷预测方法研究[J]. 软件学报, 2016, 27(1):1-25.
CHEN Xiang, GU Qing, LIU Wangshu,et al. Survey of static software defect prediction[J].Journal of Software, 2016,27(1):1-25.
[17] RADOI C, DIG D. Effective techniques for static race detection in Java parallel loops[J]. ACM Transactions on Software Engineering and Methodology, 2015, 24(4):1-30.
[18] BAVOTA G, LUCIA A D, PENTA M D, et al. An experimental investigation on the innate relationship between quality and refactoring[J]. Journal of Systems and Software, 2015, 107:1-14.
[19] SAKAMOTO N. Parallel online exact sum for Java8[C]// 2016 IEEE/ACIS 15th International Conference on Computer and Information Science. Okayama: IEEE, 2016:26-29.
[20] 魏志鹏. HASH型高速缓存的页着色方法研究[D]. 北京:中国科学院大学, 2015.
[21] URMA R-G,FUSCO M, MYCROFT A. Java 8 实战[M].陆明刚,劳佳,译.北京:人民邮电出版社, 2016.
[22] 张杨, 张冬雯. 基于Joeq编译器的软件分析及其应用[J]. 河北师范大学学报(自然科学版), 2015,39(3):202-207.
ZHANG Yang, ZHANG Dongwen. Research on program analysis using Joeq compiler framework[J]. Journal of Hebei Normal University(Natural Science Edition), 2015,39(3):202-207.
[23] 王伟,许云峰,高凯.基于哈希表的动态向量降维方法的研究及应用[J].河北科技大学学报,2011,32(4):351-354.
WANG Wei,XU Yunfeng,GAO Kai.Research in dynamic vector dimension-reduction algorithm based on hash table and its application[J]. Journal of Hebei University of Science and Technology,2011,32(4):351-354.
[24] 袁阳,赵耿,沈薇.数字签名技术中混沌哈希函数的构造与分析[J].计算机工程与应用,2010,46(9):92-94.
YUAN Yang, ZHAO Geng, SHEN Wei. Spatiotemporal chaotic Hash function construction and analysis in digital signature[J].Computer Engineering and Applications,2010,46(9):92-94.
Comparison and reconfiguration of Java hash mechanisms on parallel environment
ZHENG Yajie, ZHANG Dongwen, ZHANG Yang, GUO Song, LIANG Yanan, WEI Mengmeng, YU Xin
(School of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)
Aiming at the non-thread-safe under parallel environment,taking Hashtable and ConcurrentHashMap of Hash Mechanism as study objects, the test programs with variable numbers of threads and read-write threads are designed. The performance difference between ConcurrentHashMap and Hashtable is analyzed through the test program. According to the performance difference, the automatic refactoring of the program from Hashtable to ConcurrentHashMap is completed. Then in condition of the Hashtable encapsulation data, the performance difference between traditional multithreaded program processing and Java8 parallel stream handling approach is compared to analyze the effectiveness of parallel stream handling approach.The comparison result shows that the performance of ConcurrentHashMap in the parallel program is better than that of Hashtable. The research result provides new ways for solving non-thread-safe problems,which can be reference for parallel programming.
program design and its language; thread safety; ConcurrentHashMap; Hash mechanism; refactoring; parallel; stream handling; Java8
1008-1534(2017)06-0414-07
TP312
A
10.7535/hbgykj.2017yx06005
2017-05-04;
2017-10-12;责任编辑:陈书欣
国家自然科学基金(61440012);河北省研究生创新项目(XZZSS2017087)
郑雅洁(1993—),女,河北石家庄人,硕士研究生,主要从事并行计算、软件重构方面的研究。
张 杨副教授。E-mail:51113288@qq.com
郑雅洁,张冬雯,张 杨,等.并行环境下Java哈希机制的对比及重构[J].河北工业科技,2017,34(6):414-420.
ZHENG Yajie, ZHANG Dongwen, ZHANG Yang,et al.Comparison and reconfiguration of Java hash mechanisms on parallel environment[J].Hebei Journal of Industrial Science and Technology,2017,34(6):414-420.
猜你喜欢
大数据(2021年6期)2021-11-22
北京大学学报(自然科学版)(2021年3期)2021-07-16
山西电子技术(2021年3期)2021-06-28
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年13期)2020-01-14
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
电脑爱好者(2015年13期)2015-09-10
