
基于互信息特征选择和LSSVM的网络入侵检测系统
2017-11-29 13:31庄夏
中国测试 2017年11期
庄 夏
(中国民航飞行学院科研处,四川 广汉 618307)
基于互信息特征选择和LSSVM的网络入侵检测系统
庄 夏
(中国民航飞行学院科研处,四川 广汉 618307)
为提高网络入侵检测系统(IDS)的性能,提出一种基于互信息特征选择和LSSVM的入侵检测方案(BMIFSLSSVM)。将采集到的网络连接数据进行规范化处理,并提出一种权衡考虑特征相关性和冗余性的新型互信息特征选择(BMIFS)方法,以此从网络连接数据中选择出有效特征集。根据提取的训练样本特征集,利用最小二乘支持向量机(LSSVM)构建分类器和简化粒子群优化(SPSO)算法来优化LSSVM的核函数宽度系数和正则化参数,最后利用训练好的分类器进行入侵检测。仿真结果表明:提出的BMIFS能够选择出最优特征集,使BMIFS-LSSVM提高入侵检测准确率且降低误报率。
网络入侵检测;互信息特征选择;最小二乘支持向量机;简化粒子群优化
0 引 言
随着网络技术的发展,计算机网络面临的安全问题越来越严重。但由于网络安全漏洞的不断增加,当前计算机网络具备的防火墙、统一威胁管理系统等安全应用已不能实现高安全性[1]。为此,需要一种高效的网络入侵检测系统(intrusion detection system,IDS)[2]。近些年,学者提出了多种IDS,主要可分为3类:基于数据统计的IDS,基于数据挖掘的IDS和基于机器学习的IDS。其中,机器学习方法是基于对数据的智能学习来构建分类器,其检测性能较好[3],如神经网络算法、支持向量机(support vector machine,SVM)等。
最小二乘 SVM(least square SVM,LSSVM)[4]比SVM具有更快的运算速度,在入侵检测领域中广泛应用。然而,其性能依赖于两个参数因子。为了获得最优参数组合,学者提出了多种智能算法与LSSVM相结合的 IDS,如遗传算法(GA)[5]、粒子群算法(PSO)[6]、杜鹃鸟搜索(MCS)[7]等。 这些算法的结合一定程度上提高了LSSVM的性能,但由于这些智能优化算法的计算复杂度较高,使整个系统的运行时间较长,不太适合应用在实时网络入侵检测中。
另外,网络连接数据具有大量的特征,冗余特征不仅增加了分类器的计算时间,而且还会降低检测准确率。为此,在输入到分类器进行检测之前,需要对其进行特征降维。目前,特征选择方法主要有欧式距离法、余弦相似度法、互信息法等[8]。其中,互信息(mutual information,MI)是衡量两个随机变量相关性的一种有效方法。学者提出了多种基于MI的特征选择算法,如传统的互信息特征选择(mutual information feature selection,MIFS)、MIFS-U 算法等[9]。然而,这些算法都涉及到一个用来表征输入特征之间冗余度的参数β,而选择合适的β目前还较为困难。基于上述分析,本文提出一种新型MIFS和参数优化LSSVM的网络入侵检测系统,表示为BMIFS-LSSVM(SPSO)。其主要创新点在于:
1)基于MI提出了一种新的均衡型MIFS(BMIFS)。在传统MIFS计算候选特征之间相关性中融入了特征与类之间的相关性,以此来表征在已选特征集中,特征fi对于特征fs的相对最小冗余。同时也不需要确定参数β的值,从而提高了特征选择的能力。
2)利用LSSVM来构建分类器,利用一种新型的简化粒子群优化 (simplified particle swarm optimization,SPSO)算法来优化LSSVM参数,在提高分类器性能的同时,避免过大的计算复杂度,提升训练过程的时间效率。
1 系统框架
入侵检测系统框架如图1所示,主要由4个部分组成:1)数据收集和预处理,即收集网络数据包,并将收集的数据进行规范化处理;2)特征选择,即通过提出的BMIFS从数据特征集中选择出具有代表性的特征;3)训练分类器,即根据所选择的特征集来训练LSSVM分类器;4)入侵检测,即利用训练好的分类器来检测测试数据。

图1 提出的BMIFS-LSSVM(SPSO)入侵检测系统框图
2 数据收集和预处理
数据收集是入侵检测的第一个关键步骤。数据源的类型和收集数据的位置是IDS有效性的两个决定性因素。为了为目标主机或网络提供最佳保护,本研究提出了一种基于网络的IDS,在距离保护目标最近的路由器上运行并监视入站的网络流量。在训练阶段,根据传输/互联网层协议来分类所收集的数据样本,并将其标记为各类攻击。
本研究根据标准数据集KDD Cup 99中的数据格式,对收集的网络数据进行规范化预处理。首先,执行数据转换,即用特定的数值表示数据的一些属性特征,例如协议类型(TCP、UDP、ICMP),服务类型(HTTP、FTP、Telnet等)和 TCP 状态(SF、REJ)等。 然后,执行数据归一化。即将每个属性值归一化到[0-1]范围内。
在训练阶段还需要将每条数据标记为正常或特定的攻击类型,本研究采用了4种常见类型,即探测攻击(Probe)、拒绝服务攻击(DoS)、远程登陆攻击(R2L)和提权攻击(U2R)。
3 基于BMIFS的特征选择
如果将网络流量记录之间的相关性视为线性关联的,则可以使用线性相关系数来度量两个随机变量之间的相关性。然而,在实际网络通信中,变量之间的相关性也可以是非线性的。因此,本文提出一种新的基于MI的特征选择度量BMIFS,用来分析线性和非线性变量之间关系,从而选择出最佳特征集。
3.1 互信息
互信息(MI)是两个随机变量关系的对称度量,输出为一个非负值,其中零表示两个变量是统计独立的[9]。
给定 2 个联系随机变量U={u1,u2,…,ud}和V={ν1,ν2,…,νd},其中d为样本总数,U和V之间的 MI定义为
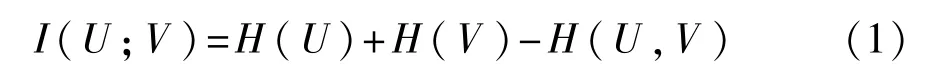
其中,H(U)和H(V)为U和V的信息熵,信息熵为变量不确定性的度量,其表达式分别为
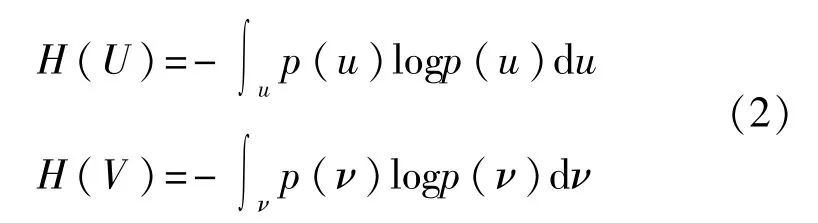
U和V之间的联合熵定义为

那么,U和V之间的MI可表示为

对于离散化的U和V,则MI可表示为

在特征选择中,如果特征包含关于类的重要信息,则该特征与该类相关,否则不相关或多余。由于MI可以量化两个随机变量共享的信息量,因此可用作评估特征和类标签之间相关性,预测能力更高的特征f具有更大的互信息I(C;f)。
3.2 互信息特征选择(MIFS)
在互信息特征选择(MIFS)[10]中,通过计算I(C;fi,S)来选择特征。I(C;fi,S)表示在所选择的特征集S中,增加特征fi后形成的新特征集与类别C之间的互信息,反应了特征fi对分类的贡献程度。I(C;fi,S)的计算思想是计算特征fi与类别C之间的互信息I(C;fi),然后计算特征fi与先前所选特征fs之间的互信息I(fi;fs)之和,并将其乘以一个比例系数β对I(C;fi)进行校正。 表达式如下:

β值为进行特征选择时考虑输入特征之间冗余度的权重,其决定选择特征时,两个方面(即特征与类之间的MI和特征与特征之间的MI)的重要性比重。
3.3 BMIFS算法
在传统MIFS基础上,学者提出的改进型MIFS算法大多是对式(6)中I(C;fi,S)中第 2 项进行改进。然而,这些方法存在一些限制。 例如,I(C;fi,S)等式右边的第1项是计算候选特征与类别之间的互信息,表示相关性;第2项则是求和候选特征与已选特征之间的互信息,表示冗余性。这两个部分通过一个参数β来进行权衡。如果β太小,则算法偏重候选特征与类之间的MI,根据单个候选特征和类之间的MI依次选择特征。如果选择的β太大,则算法偏重考虑候选特性之间的MI。为此β的选择较为困难,且目前也没有选择参数β的合适方法。
为了解决上述问题,本文提出一种均衡考虑相关性和冗余性的新型MIFS算法(BMIFS),在第2项中引入了候选特征与类别之间的互信息,且不再需要人为设置一个额外的参数,即利用1/|S|代替β。BMIFS从一个初始特征集中选择出具有最大化I(C;fi)并最小化冗余的特征,表达式如下:

式中|S|为已选择特征的数量,MR表示在已选特征集S中,特征fi对于特征fs的相对最小冗余,定义如下:
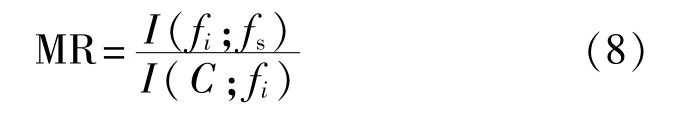
当I(C;fi)=0 时,特征fi可被丢弃。 如果对于类C,fi和fs之间高度相关,那么fi也将是冗余的。为此,需要设定一个阈值Th=0来与GMI进行比较。如果GMI≤0,则当前特征fi对于类C是无关紧要的,其将会降低所选择的特征集S与类C之间的MI,并将其从S中删除。如果GMI>0,则将特征fi作为候选特征。BMIFS选择特征的过程如算法1所示。
算法1:BMIFS特征选择
输入:特征集F={fi,i=1,2,…,n}
输出:选择的特征集S
开始
1)初始化S=φ
2)为每个特征计算I(C;fi)
3)设置nf=n,根据下式选择特征fi:

设置F←F/{fi};S←S∪{fi};nf=nf-1
4)WhileF≠φdo
根据式(7)计算GMI,找到fi,i∈{1,2,…,nf}
设置nf=nf-1;F←F/{fi}
If(GMI>0) then
S←S∪{fi}
End if
End while
5)根据S中每个特征的GMI对特征进行排序
6)返回
4 基于LSSVM的入侵分类
4.1 LSSVM模型
在传统LSSVM中,设定训练数据为{xi,yi}ni=1,xi为输入数据,yi为输出类别[11]。 为在非线性映射 φ(x)构成的特征空间中估计最优拟合函数 y(x)=ωTφ(xi)+b,需将LSSVM转换为如下线性方程组:

式中 y=[y1,y2,…,yn],1n=[1,1,…,1]T,K=φ(xi)Tφ(xj)=K(xi,xj),γ为正则化参数。 LSSVM 分类器的表达式为

式中K(x,xi)为LSSVM的核函数,通常情况下选择径向基函数(RBF)作为核函数,其表达式为
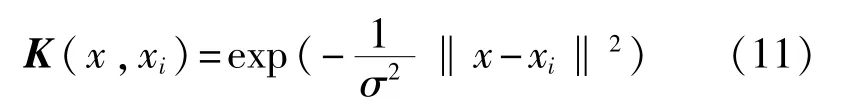
4.2 SPSO优化LSSVM模型参数
在LSSVM中,核函数宽度系数σ和正则化参数γ是影响LSSVM分类性能的关键参数。γ用来描述训练过程中最大分类边界和分类误差之间的平衡关系。γ越大,分类正确性越高,但泛化能力降低。σ用来控制RBF核的宽度,σ过大会使其性能与一阶多项式核相近,失去了RBF核的作用。为了获得最优的参数组合(σ,γ),大多采用一些智能优化算法进行全局搜索。例如,遗传算法、粒子群算法、模拟退火算法、蚁群算法等。然而,这些算法的计算量都较大,对LSSVM分类速度的影响较大,不适合应用在实时网络入侵检测中。
基于上述分析,本文采用了一种由文献[12]提出的简化粒子群优化(SPSO)算法,以分类准确性作为适应度函数,对LSSVM中的参数进行优化。SPSO算法在不降低求解质量的同时,大大降低了收敛时间,可适用于实时应用。
在传统PSO算法中,基于从全局最优解和当前最优解的信息来更新每个粒子的位置,使其在每次迭代中都会向吸引子所引导的方向移动,最终获得最优解。粒子的速度和位置更新公式为
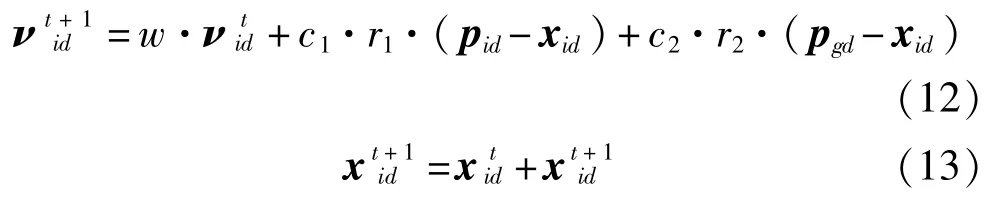
式中i=1,2,…,N,其中N为j维粒子数,xid表示第i个粒子在第d维的当前位置,νid表示速度向量,pid和pgd分别表示全局最优解和当前最优解。c1和c2通常设置为2。r1和r2是0和1范围内的随机数。w为惯性权重,通常设置为0.8。
文献[12]通过分析生物模型和进化迭代过程,发现PSO的进化过程与粒子速度无关。另外,粒子速度的大小并不代表粒子能够有效趋近最优解位置,反而可能造成粒子偏离正确方向,延缓后期收敛速度。为此,其将PSO进行改进,去掉了速度项,形成一种简化粒子群优化(SPSO)算法。简化后的粒子位置方程为

可以看出,简化后的PSO位置方程由二阶降到了一阶,大大简化了粒子进化过程和时间复杂度,使其能够应用到实时网络入侵检测中。
5 仿真及分析
5.1 实验设置
利用Matlab构建实验环境,实验中采用了NSLKDD和Kyoto 2006+数据集。其中,NSL-KDD数据集是2009年建立的,其是在KDD Cup99基准数据集基础上移除了冗余和重复的记录信息后构建的精简数据集,包含了Probe、DoS、R2L和U2R攻击。NSL-KDD数据集具有148517个网络连接数据,其中有77 054个正常连接和71 463个异常连接。另外,所包含的网络连接类型有TCP、UDP和ICMP协议,分别为121569、17614、9334个。每个连接数据有41个特征和一个类标签,表1列举了前14个特征及其描述。
Kyoto 2006+数据集包含了由京都大学部署服务器从2006年11月至2009年8月收集的连接数据。此数据集中的每个连接有24个不同的特征。
在训练LSSVM分类器之前,需要通过提出的BMIFS选择出5个类的特征集。由于LSSVM是二进制分类器,所以要分别训练5个LSSVM分类器,最后融合成一个检测模型。其中,本研究采用了一对多(one-vs-all,OVA)的训练方式来训练分类器。
另外,在利用SPSO优化LSSVM参数(σ,γ)时,设置σ的取值范围为[2-5,25],步长为2-5,粒子编码为5位二进制数。γ的取值范围为[2-1,210],步长为2-1,粒子编码同样为5位二进制数。设置SPSO算法的种群数量N=30。通过实验表明,SPSO算法大约迭代25次后就能收敛到最优解,比传统PSO快了近一倍。为此,这里设置最大迭代数量Tmax=50。

表1 NSL-KDD数据集中连接数据的特征举例
5.2 性能指标
每次实验中,统计IDS入侵检测的真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。 实验中采用3种性能指标,分别为准确度(accuracy),检测率(detection rate,DR)和误报率(false positive rate,FPR),表达式如下:

5.3 性能分析
首先,为了验证提出的BMIFS特征选择方法的有效性,将其与传统MIFS和MIFS-U进行比较。将NSL-KDD和Kyoto 2006+数据集中20%作为训练集,利用上述3种方法进行特征选择。其中,对于MIFS和MIFS-U,文献[9]认为当β=0.3时效果最佳。表2和表3为3种方法所选择出的最优特征及排序。可以看出,提出的BMIFS所选择出的特征数量最少。

表2 NSL-KDD数据集上选择的特征及排序

表3 Kyoto 2006+数据集上选择的特征及排序
在选择出特征之后,将NSL-KDD和Kyoto 2006+数据集的80%作为测试集,进行5次分类实验。为了公平比较,分类器都采用SPSO优化的LSSVM分类器(LSSVM(SPSO)),分类性能比较结果如表 4所示,其中数据为5次实验的平均值。另外,表4还给出了没有采用SPSO优化的LSSVM性能,以此来验证SPSO算法的优化作业。
表中可以看出,特征选择操作对分类性能具有很大的影响,其中所有特征+LSSVM(SPSO)方法的性能最低,这表明在没有进行特征选择时,大量的冗余特征会降低分类精度。另外,MIFS-U特征选择方法的性能比传统MIFS具有一定的改善。而本文提出的BMIFS在检测率、误报率和准确率方面都具有最高的性能。另外,对比LSSVM(SPSO)和传统LSSVM的性能可以看出,LSSVM的参数选择对分类性能具有一定的影响,采用SPSO优化后的LSSVM性能有所提高。
在上述实验进行过程中,统计了各种方法的训练和测试时间,结果如表5所示。可以看出,提出的BMIFS+LSSVM(SPSO)的训练和测试时间都最小,这是因为采用了BMIFS,在保持分类准确性下选择出最少数量的所需特征,有效降低了LSSVM分类器的计算量,从而缩短了训练和测试时间。
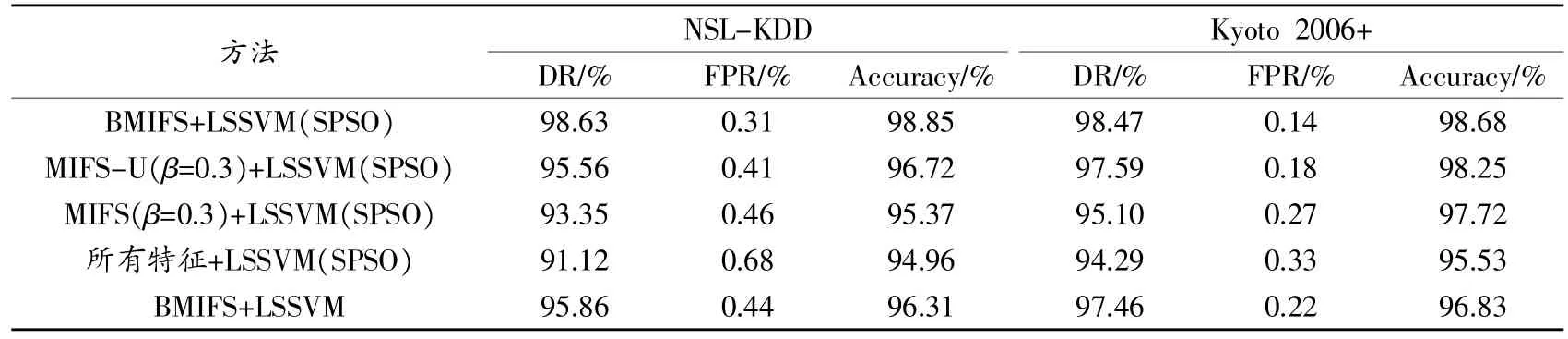
表4 各种方法的分类性能比较

表5 各种方法的时间复杂性比较

表6 各种IDS在NSL-KDD数据集上的性能比较
为了进一步验证提出方法的有效性,将提出的BMIFS+LSSVM(SPSO)与文献[13]提出的粗糙集特征选择+LSSVM、文献[6]提出的 LSSVM(PSO)方法、文献[14]提出MIFS+决策树分类器方法在NSL-KDD数据集上进行比较。各种方案的检测率结果如表6所示。可以看出,提出的方法整体检测率最高。这是因为,本文采用了BMIFS提取出了最佳特征,避免了特征冗余,这一定程度上有助于后续分类器的分类。另外,采用了SPSO算法对LSSVM参数进行了优化,有效提高了其分类性能。
6 结束语
本文提出一种基于互信息特征选择和LSSVM的入侵检测系统。为解决现有互信息特征选择中的缺陷,提出一种综合考虑特征相关性和冗余性的互信息选择方法(BMIFS),以此为分类器选择最小数量的有效特征集。采用了LSSVM作为分类器,考虑到算法的运行时效问题,使用SPSO算法来优化LSSVM的参数提高其分类能力。在NSL-KDD和Kyoto 2006+数据集上进行了实验,并与相关方法进行了比较。结果证明了提出的BMIFS能够选择出最少数量的有效特征,同时也表明了BMIFS+LSSVM(SPSO)方案的可行性和有效性。
[1]田志宏,王佰玲,张伟哲,等.基于上下文验证的网络入侵检测模型[J].计算机研究与发展,2013,50(3):498-508.
[2]李佳.基于AFSA-KNN选择特征的网络入侵检测[J].计算机工程与设计,2014,35(8):2675-2679.
[3]KOC L, MAZZUCHI T A, SARKANI S.A network intrusion detection system based on a Hidden Naïve Bayes multiclass classifier[J].Expert Systems with Applications,2012,39(18):13492-13500.
[4]陈天宇,吴凡,马世杰,等.基于CS和LS-SVM的入侵检测算法[J].计算机技术与发展,2016,26(5):99-103.
[5]LIU C.Network intrusion detection model based on genetic algorithm optimizing parameters of support vector machine[J].Advanced Materials Research,2014,98(9):2012-2015.
[6]QI F, XIE X, JING F.Application of improved PSOLSSVM on network threat detection[J].Wuhan University Journal of Natural Sciences,2013,18(5):418-426.
[7]陈健,陈雪刚,张家录,等.杜鹃鸟搜索算法优化最小二乘支持向量机的网络入侵检测模型[J].微电子学与计算机,2013,30(10):29-32.
[8]高鹏.推荐系统中信息相似度的研究及其应用[D].上海:上海交通大学,2013.
[9]KWAK N,CHOI C H.Input feature selection for classification problems[J].IEEE Transactions on Neural Networks,2002,13(1):143-159.
[10]AMIRI F, REZAEI Y M, LUCAS C, et al.Mutual information-based feature selection for intrusion detection systems[J].Journal of Networkamp;Computer Applications,2011,34(4):1184-1199.
[11]王建国,杨云中,秦波,等.基于峭度与IMF能量融合特征和LS-SVM的齿轮故障诊断研究[J].中国测试,2016,42(4):93-97.
[12]SANTOS R P B D, MARTINS C H, SANTOS F L.Simplified particle swarm optimization algorithm[J].Acta Scientiarum Technology,2012,34(1):521-531.
[13]WANG F N, WANG S S, CHE W F, et al.Network intrusion detection method based on RS-LSSVM[J].Applied Mechanicsamp;Materials,2014,60(2):1634-1637.
[14]SONG J, ZHU Z, SCULLY P, et al.Modified mutual information-based feature selection for intrusion detection systems in decision tree learning[J].Chinese Journal of Computers,2014,9(7):1542-1546.
(编辑:李妮)
Network intrusion detection system based on mutual information feature selection and LSSVM
ZHUANG Xia
(Research Department,Civil Aviation Flight University of China,Guanghan 618307,China)
In order to improve the performance of network intrusion detection system (IDS), an intrusion detection scheme based on mutualinformation feature selection and LSSVM was proposed (BMIFS-LSSVM).First, the collected network connection data was normalized.Then, a new mutual information feature selection (BMIFS) method was proposed to balance the feature correlation and redundancy,and a effective feature set was selected from the network connection data.Then, the least squares support vector machine(LSSVM) was used to construct the classifier according to the extracted training sample feature set, and the simplified particle swarm optimization (SPSO) algorithm was used to optimize the kernel function width and regularization parametersof LSSVM.Finally, the trained classifierwasused forintrusion detection.The simulation results show that the proposed BMIFS can select the optimal feature set,make the BMIFS-LSSVM improve the intrusion detection accuracy and reduce the false alarm rate.
network intrusion detection; mutual information feature selection; least squares support vector machine;simplified particle swarm optimization
A
1674-5124(2017)11-0134-06
10.11857/j.issn.1674-5124.2017.11.026
2017-03-19;
2017-04-25
国家自然科学基金民航联合基金重点项目(U1233202/F01)
庄 夏(1980-),男,四川广汉市人,副教授,硕士,研究方向为计算机网络安全。
猜你喜欢
福州大学学报(自然科学版)(2022年1期)2022-01-21
河南科学(2021年3期)2021-05-06
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年3期)2017-05-24
计算机应用(2016年10期)2017-05-12
电子制作(2017年23期)2017-02-02
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
