
结合金字塔模型和随机森林的运动捕获序列语义标注
2017-11-28 09:00:26徐濛彭淑娟柳欣
华侨大学学报(自然科学版) 2017年6期
徐濛, 彭淑娟, 柳欣
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)

结合金字塔模型和随机森林的运动捕获序列语义标注
徐濛, 彭淑娟, 柳欣
(华侨大学 计算机科学与技术学院, 福建 厦门 361021)
针对原始运动捕获数据结构复杂、语义模糊的问题,提出一种结合金字塔模型和随机森林的运动捕获序列语义标注方法.首先,利用概率主成分分析将运动序列划分为具有特定语义的运动片段.然后,将运动片段的欧拉角数据转换为人体各个关节点的三维空间位置坐标数据,统一骨骼长度,提取运动数据的2种互补性几何特征,并分别归一化.再次,运用傅里叶时间金字塔模型构建运动片段完整的时空特征.最后,利用已训练的随机森林分类器对各个运动片段进行标注.结果表明:该方法能够对具有不同语义的复杂运动序列进行有效标注,且可用于不同表演者,具有一定的实用性和通用性.
语义标注; 概率主成分分析; 傅里叶时间金字塔; 随机森林
随着数字媒体技术的发展及光学运动捕获设备的广泛应用,人们可以方便地获得大量的运动捕获数据.这些运动捕获数据被广泛地应用于三维动画、影视制作、游戏、教育等领域.同时,大规模的运动捕获数据库也应运而生,动画师从这些数据库中快速、高效地获取满足需求的运动数据片段用于动画创作.有效地对运动数据进行分类,并进行有组织的数据库管理,首先,需要对一段未知的运动片段进行识别和标注.近年来,关于运动识别和标注已经有大量的研究成果[1-7].现阶段大多数方法仅对特定语义的运动片段进行分类识别,而在运动捕获过程中,为了保持动作的连贯性,捕获到的数据通常包含多个连续的动作.传统的手动分割及标注方法往往需要花费大量的人力和时间.因此,有效地对一段复杂运动序列进行自动语义标注,对于后续的存储、编辑和重用具有极其重要的意义.鉴于此,本文提出一种针对复杂运动捕获序列的自动语义划分及标注方法.
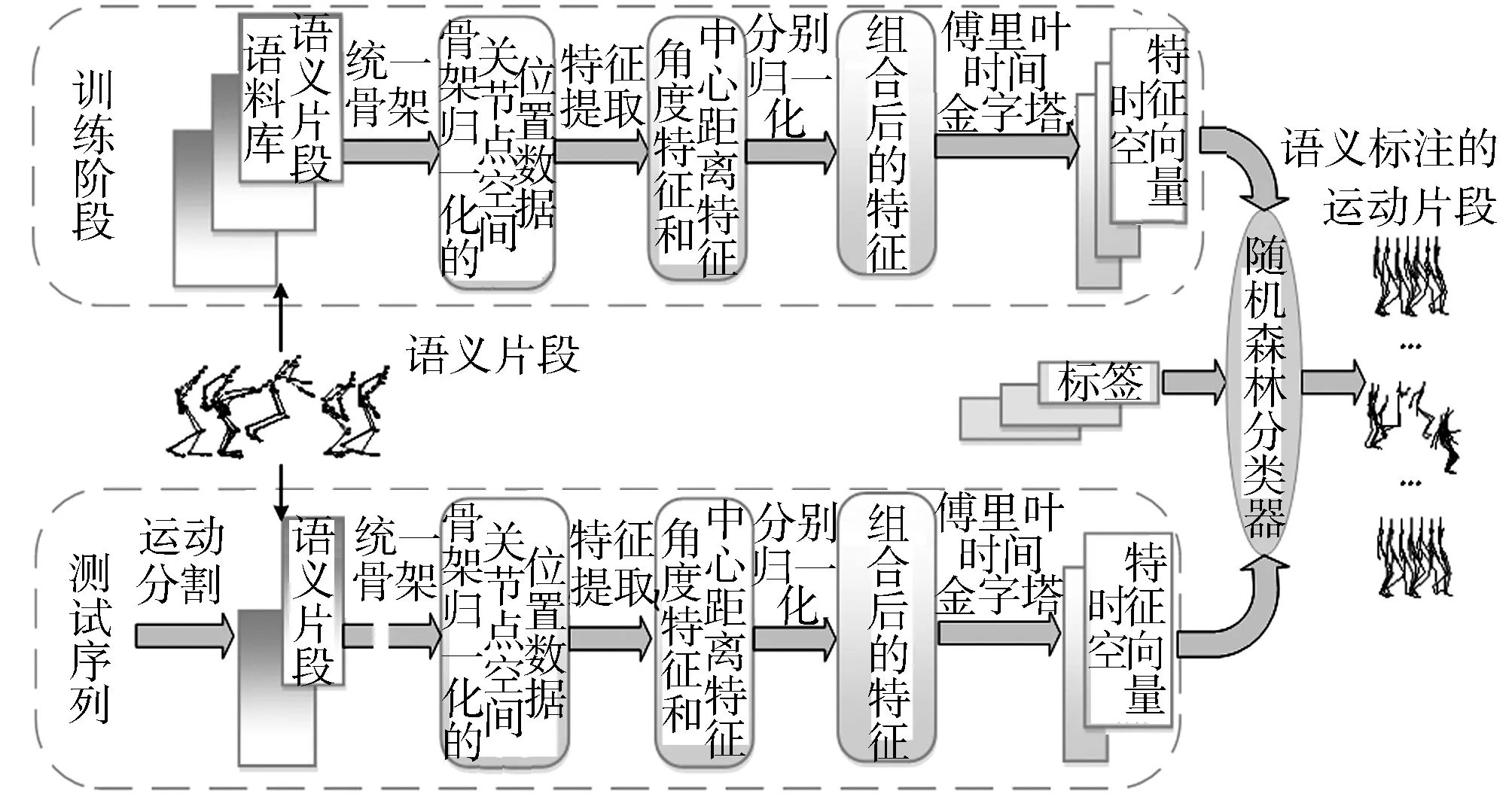
图1 文中方法流程图Fig.1 Flow chart of our method
1 运动捕获序列语义标注方法
结合金字塔模型和随机森林进行运动捕获序列语义标注,其流程如图1所示.流程主要分为训练阶段和测试阶段.在训练阶段,对训练集中的运动语义片段进行统一骨架预处理,提取2种互补性特征并分别归一化,构建傅里叶时间金字塔模型,对时间序列进行对齐,得到完整的时空特征向量.在测试阶段,运用概率主成分分析方法(PPCA)将一段具有多个语义的运动序列进行语义划分,得到具有特定语义的子片段集合,通过与训练阶段相同的处理,得到各个语义片段的特征向量,根据训练阶段得到的随机森林模型,对语义片段进行标注.
1.1人体运动数据表示形式
采用HDM05[8]数据库中标准的ASF/AMC文件格式.其中,ASF文件表示人体骨架模型.该模型有31个关节点,各个关节点采用树形层次结构组织.人体在空间中的位置由各个关节点的自由度(DOF)决定,并记录在AMC文件中,可用矩阵S=[s1,s2,…,sm]T表示,si∈R62,m为运动序列帧数.
1.2运动序列分割
对于原始运动序列,采用PPCA[9]方法将其划分为不同语义的运动片段.假定一段运动序列为S=[s1,s2,…,sm]T,S∈Rm×62,m为运动序列帧数,具体分割过程有以下6个步骤.

步骤2奇异值分解矩阵D,即D=UΣVT.其中,U,V为单位正交矩阵;Σ为由元素σi组成的非负递减对角矩阵.

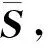



步骤6根据跳变原则,对步骤5获得的马氏距离曲线进行分割,得到运动序列的子运动片段Si∈Rmi×62.其中,m=[m1,m2,…,mcut],mi为第i段运动序列的帧数,cut为分段数.
1.3语义片段预处理
由于AMC格式存储的运动捕获数据是由欧拉角表示的,首先,将其转换为笛卡尔坐标系下各个关节点的空间位置信息,数学描述为P=[p1,p2,…,pm]T,pi∈R3×j,j为关节点数目,m为运动序列帧数.

(a,b).


1.4运动序列标注
1.4.1 傅里叶时间金字塔 由于采样速度或表演风格的不同,单个运动片段在时间上往往是未对齐的.参考文献[13]的方法,利用傅里叶时间金字塔模型,将各个运动片段进行对齐.为了获取一段运动片段的时间信息和全局傅里叶系数,递归地将运动片段划分为金字塔,对所有的划分片段使用短时傅里叶变换(STFT).序列最终可以表示为所有划分片段的短时傅里叶变换系数的时序组合,如图2所示.
1.4.2 随机森林分类 随机森林[14](RF)旨在将多个弱分类器融合为一个强分类器,能够很好地解决多分类问题.同时,RF算法将Bagging和随机选择分裂特征结合,能够有效处理高维数据且不会导致过拟合.因此,采用随机森林分类器对待测运动片段进行分类.
随机森林分类过程,如图3所示.随机森林是决策树{h(X,θk)}的集合,X为输入向量,θk是独立同分布的随机向量,决定单棵树的生长.假定训练集为T={(xi,yi)},xi为特征向量,xi∈RN,yi为类别标签,yi∈R,i=1,2,…,n,待测样本xt∈RN.具体有以下3个步骤.

图2 傅里叶时间金字塔 图3 随机森林分类器 Fig.2 Fourier temporal pyramid Fig.3 Random forests classifier
步骤1采用给定权重的方法建立随机向量模型θ.
步骤2构建随机森林分类器.1) 对原始训练集T进行Boostrap抽样,生成训练集Ti.2) 使用Ti通过CART算法生成一棵不减枝的决策树hi.a) 从N个特征中随机选取Ntry个特征;b) 在树的每个节点上,依据Gini指标从Ntry个特征选取最佳分裂特征作为节点;c) 分裂直至树生长到最大.3) 循环1),2)步,直至建立k棵决策树,树的集合为{hi},i=1,2,…,k.

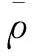
1.5文中算法
结合金字塔模型和随机森林对运动捕获序列进行语义标注.输入:训练集运动片段{tr1,tr2,…,trn},测试运动序列test.输出:加标签的语义片段{te1,te2,…,tel}.具体有以下6个步骤.


步骤3加标签.经过步骤1~2,训练集数据可以表示为矩阵{xtr1,xtr2,…,xtrn},加入类别标签ytri为{xtri,ytri}.
步骤4训练模型.假设决策树的数量为k.对{xtri,ytri}进行训练,可得到随机森林模型{hi},i=1,2,…,k.
步骤5运动序列语义划分.使用PPCA方法将测试序列test划分为具有不同语义的子运动片段组合{te1,te2,…,tel}.
步骤6语义片段标注.使用步骤1,2对语义片段进行处理,得到各片段时空特征向量,则语义片段可以表示为{xte1,xte2,…,xtel}.使用步骤4训练好的随机森林模型对{xte1,xte2,…,xtel}进行分类,可得到各个语义片段{te1,te2,…,tel}的类别标签.
2 结果及分析
2.1实验数据选取及描述
为了验证文中方法的有效性,从HDM05数据库中选取408段不同长度的运动片段组成运动捕获数据语料库,并按照不同的运动风格分为12个基本类别,如表1所示.表1中:每类运动包含15~57段不同的运动片段,每个片段包括动作从开始到结束的完整过程,但可以多次重复,如“移动”、“击拳”、“单脚跳跃”等类型的运动片段包含了2~3次相同的动作.
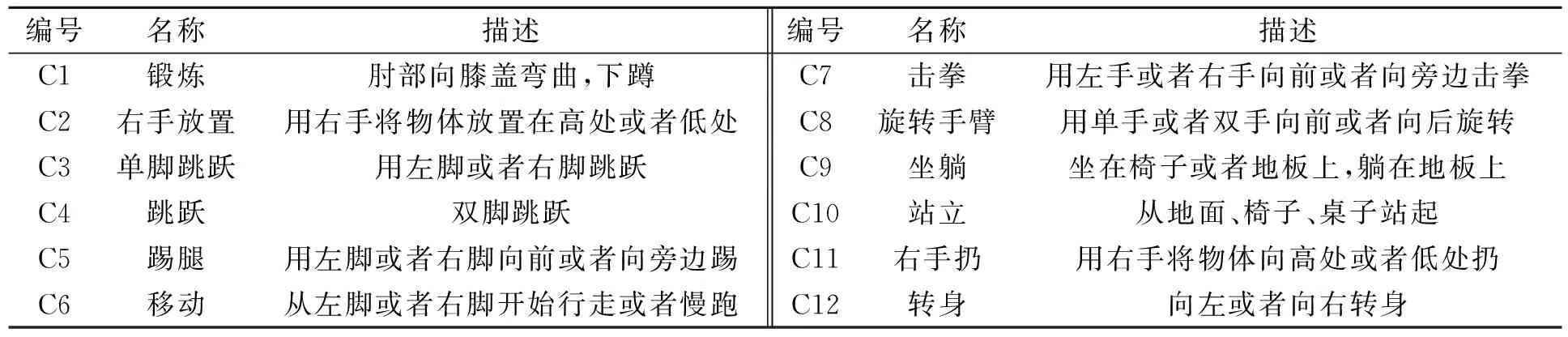
表1 运动捕获数据语料库Tab.1 Corpus of motion capture data
2.2语义片段识别

图4 4种方法识别率比较Fig.4 Comparison of recognition rate in four methods
为了评估文中语义片段识别方法的有效性,从语料库中随机抽取2/3的运动片段用于训练,其余用于测试.在相同实验条件下,将文中方法与DTW[1],HMM[4],SVM[5]等3种经典的运动识别方法进行比较.基于HMM的方法,为每类运动建立一个隐马尔科夫模型,每个模型的隐藏状态数设置为3,每个隐藏状态所包含的混合高斯分布数也设置为3,通过Baum-Welch算法对训练集进行学习得到模型的各个参数.在分段基础上计算识别率,如图4所示.测试集中每类运动中分类正确的片段数与每类运动总的片段数之比为每个类的识别率,并用条形图表示.整个测试集中分类正确的片段数与测试集总片段数之比为总识别率(η),并用线段表示.
由图4可知:对于各类语义片段,当随机森林分类过程中决策树的数量设置为120时,文中方法均能取得较好的识别正确率,而基于SVM的方法在惩罚项c设置为100,核函数半径g设置为0.001时,在某些类别中也能取得较好的分类结果.由于基于DTW 的相似度匹配方法,只注重运动序列的局部缩放,在全局缩放及统一缩放尺度下效果不佳,且计算比较耗时.基于HMM的方法由于需要提前指定隐藏状态,而对不同的运动指定相同数量的状态对其识别结果造成了一定影响. 此外,文中方法总的识别率分

表2 复杂运动捕获数据序列Tab.2 Complex motion capture data sequences
别为0.54,0.82,0.91,0.96,可以看出文中方法明显优于其他3种方法,具有更好的识别效果.
2.3运动序列语义标注
为了验证具有多个运动语义的运动序列的标注效果,选取9个复杂运动序列用于测试分段识别效果,如表2所示.这9个动作序列来自3个表演者BD,BK,DG.每个运动序列均包含多个动作,最短的序列长度为2 469帧,包含16个不同的动作,最长的序列长度为8 527帧,包含18个不同的动作.9个复杂运动序列分割和识别的查准率(P(D))和查全率(R(D)),如表3所示.
为了便于对比分析,手动分割和标注相应复杂运动序列,将查准率和查全率分别定义为

上式中:M(D)为手动标注的结果;A(D)为自动标注的结果.
在一段连续的运动序列中,由于动作的起始和结束位置一般不能精确确定,因此,以分段层次的查准率和查全率定义识别结果,只考虑自动标注与手动标注的结果重叠部分,当自动标注与手动标注有重叠且为相同分类时,则认为该片段正确标注.首先,使用相同的分割算法PPCA对运动序列进行分段;之后,采用在运动片段识别中识别率较高的HMM,SVM与文中方法进行比较.
由表3可知:文中方法能够得到较理想的查准率和查全率,且更接近真实标注结果.同时,用文中方法对最短和最长的运动序列进行标注,耗时分别为19,56 s,与手动分割和标注方法相比,可节省大量时间,具有一定的时间效率和可用性.

表3 查准率和查全率比较Tab.3 Comparison of precision and recall
3 结束语
针对复杂运动捕获序列标注,基于分段识别的思想,首先,使用概率主成分分析方法确定动作边界临近的过渡帧,将运动序列自动划分为具有特定语义的运动片段.然后,提取2种典型的几何特征,在进行数据降维的同时,更好地保留了单帧运动姿态信息.最后,结合傅里叶时间金字塔模型和随机森林进行自动标注,对运动片段进行对齐,并加入时间信息,进一步提高了方法的识别率.该方法存在一些不足:1) 由于一段运动序列中相邻运动片段间的过渡区域往往存在歧义,概率主成分分析方法不能精准地分析此类区域中运动帧的具体语义归属,从而给后序标注造成影响;2) 进一步提高方法的时间效率,同时,将实验扩展到连续在线运动的实时分割及标注.
[1] ADISTAMBHA K,RITZ C H,BURNETT I S.Motion classification using dynamic time warping[C]∥Proceedings of the Multimedia Signal Workshops.Cairns:IEEE Press,2008:622-627.
[2] LYU Fengjun,NEVATIA R.Recognition and segmentation of 3D human action using HMM and multi-class adaboost[C]∥Proceedings of the European Conference on Computer Vision.Graz:Springer Press,2006:359-372.
[3] ZHU Hongli,DU Pengying,XIANG Jian.3D Motion Recognition based on ensemble learning[C]∥Proceedings of the International Conference on Image Analysis for Multimedia Interactive Services Workshops.Santorini:IEEE Press,2007:1-4.
[4] XIA Lu, CHEN C C, AGGARWAL J K. View invariant human action recognition using histograms of 3D joints[C]∥Proceedings of the International Conference on Computer Vision and Pattern Recognition.Providence:IEEE Press,2012:20-27.DOI:10.1109/CVPRW.2012.6239233.
[5] BENGALUR M D.Human activity recognition using body pose features and support vector machine[C]∥Proceedings of the International Conference on Advances in Computing, Communications and Informatics.Mysore:IEEE Press,2013:1970-1975.DOI:10.1109/ICACCI.2013.6637484.
[6] HAN Lei,WEI Liang,WU Xinxiao,etal.Human action recognition using discriminative models in the learned hierarchical manifold space[C]∥Proceedings of the International Conference on Automatic Face and Gesture Recognition.Amsterdam:IEEE Press,2008:1-6.
[7] LI Chuanjun,ZHENG Soqing,PRABHAKARAN B.Segmentation and recognition of motion streams by similarity search[J].ACM Transactions on Multimedia Computing, Communications, and Applications,2007,3(3):79-82.DOI:10.1145/1236471.1236475·Source:DBLP.
[8] MULLER M,ROER T,CLAUSEN M,etal.Documentation: Mocap da-tabase HDM05[EB/OL].[2016-03-02].http:∥www.mpi-inf.mpg.de/resources/HDM05.
[9] BARBI V C J,SAFONOVA A,PAN J,etal.Segmenting motion capture data into distinct behaviors[C]∥Proceedings of the International Conference on Graphics Interface.London:Canadian Human-Computer Communications Society,2004:185-194.
[10] SHUM H,HO E S.Real-time physical modelling of character movements with Microsoft kinect[C]∥Proceedings of the Symposium on Virtual Reality Software and Technology.Toronto:ACM Press,2012:17-24.
[11] 杨跃东,王莉莉,郝爱民,等.基于几何特征的人体运动捕获数据分割方法[J].系统仿真学报,2007,19(10):2229-2234.DOI:10.3969/j.issn.1004-731X.2007.10.022.
[12] 彭淑娟.基于中心距离特征的人体运动序列关键帧提取[J].系统仿真学报,2012,24(3):565-569.
[13] WANG Jiang,LIU Zicheng,WU Ying,etal.Learning actionlet ensemble for 3D human action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(5):914-927.
[14] BREIMAN L.Random forests [J].Machine Learning,2001,45(1):5-32.
(责任编辑: 钱筠英文审校: 吴逢铁)
MotionCaptureSequenceSemanticAnnotationViaPyramidModelandRandomForests
XU Meng, PENG Shujuan, LIU Xin
(College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China)
According to the complexity and semantic ambiguity within original motion capture data, we presents an effective motion capture sequence semantic approach via pyramid model and random forests. Firstly, utilize probabilistic principal component analysis to segment motion sequences into several motion clips with certain semantics. Then, the Euler angler data of each motion clip are transformed into three-dimensional space coordinates of each human joint, and the bone lengths are unified. Subsequently, two complementary features are extracted and normalized. Accordingly, the Fourier temporal pyramid model is adopted to represent the spatiotemporal characteristics of motion clips. Finally, the trained random forests classifier is employed to label each motion clip. The proposed approach is able to well annotate complex motion sequences effectively and can be applied to different performers. The experimental results show that it has certain practically and generality.
semantic annotation; probabilistic principal component analysis; fourier temporal pyramid; random forests
10.11830/ISSN.1000-5013.201601011
TP 391
A
1000-5013(2017)06-0848-06
2015-01-06
彭淑娟(1982-),女,讲师,博士,主要从事计算机视觉与计算机动画的研究.E-mail:pshujuan@hqu.edu.cn.
国家自然科学基金资助项目(61202298, 61300138); 福建省自然科学基金资助项目(2014J01239, 2015J01656); 华侨大学高层次人才科研启动项目(14BS207); 华侨大学中青年科研提升计划(ZQN-PY309); 华侨大学研究生科研创新能力培育计划资助项目(1400414009)
猜你喜欢
环球时报(2022-09-19)2022-09-19 17:19:22
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
开放教育研究(2020年2期)2020-03-31 01:54:14
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
数学物理学报(2019年2期)2019-05-10 11:32:38
测控技术(2018年7期)2018-12-09 08:58:26
童话世界(2017年11期)2017-05-17 05:28:25
现代语文(2016年21期)2016-05-25 13:13:44
舰船科学技术(2016年1期)2016-02-27 15:39:21
电测与仪表(2015年5期)2015-04-09 11:30:44
