
基于spark的投资机构个性化推荐
2017-11-27 05:47陈贵涛屈建勤严坤
汕头大学学报(自然科学版) 2017年4期
陈贵涛,屈建勤,严坤
(汕头大学计算机科学与技术系 广东 汕头 515063)
基于spark的投资机构个性化推荐
(汕头大学计算机科学与技术系 广东 汕头 515063)
在spark大数据技术平台上,根据交替最小二乘协同过滤算法(Alternating Least Squares)对投资融资行业的历史数据进行分析建模,提出并构建该行业个性化推荐应用解决方案.该解决方案通过向初创企业推荐可靠的投资机构,能够更快、更好的满足企业的融资需求,具有重要的现实意义和商业价值.根据投资融资行业特点,提出图计算作为统计分析的方法,给出了处理投资融资领域数据的评分算法,采用springMVC架构实现了微型WEB推荐系统,最后结合实际实验数据给出了推荐模型评价标准并给出该推荐系统的优化思路.
Spark;大数据;交替最小二乘协同过滤算法;图计算;推荐系统;投资融资
0 引言
投资界权威研究机构—清科研究中心发布数据显示:2016上半年中外创业投资机构新募集基金173支,新增可投资于中国大陆的资本量为788.60亿元人民币,单支基金平均募集规模达6.26亿元人民币,单支基金平均募资规模同环比上升幅度很大;投资方面,2016上半年共发生1 264起投资案例,同比下降33.3%,其中1 052起披露金额的交易共计涉及584.95亿元人民币,同比下降12.5%,平均投资规模达5 560.40万元人民币,与2015年同期相比,投资活跃度下降.由上述数据可知,虽然可投资金额上涨,但实际投资量下降,资本投资遇冷.
以往在中国的创业投资领域各类财务顾问、创业平台、资本中介搜集到的项目策划书(BP)经过简单的分类,直接发送给投资机构.创业公司在整个过程中只能等待投资机构的反馈,处境十分被动,很难及时满足创业公司迫切的融资需求.在当前的全民创业时代众多新生创业公司将面临较大的融资压力.若资本投资持续遇冷,创业公司将面临大面积倒闭的风险,直接导致大量人员失业.反之,若创业公司能及时融资,公司存活率大大增加,将创造更多就业机会,减轻当前就业压力.因此,在创业投资领域为创业公司提供投资机构的个性化推荐成为一种必然需求.然而,国内鲜有投资领域成熟的个性化推荐应用.
创业投资领域积累了几十年的创投数据,这些数据记录了大量的成功和失败的融投案例.随着大数据技术逐渐成熟,为存储分析这些历史数据提供了很好技术支撑.因此,构建投资领域的个性化推荐成为可能.本文给出了构建微型WEB推荐系统实例,并提出将图计算作为统计分析的方法,给出了处理投资领域数据评分算法,结合实际实验数据给出了推荐模型评价标准并给出推荐系统的优化思路.
1 spark与个性化推荐
1.1 spark
起初,spark[1]是一个类似于hadoop[2-4]的计算框架.随着开源社区的贡献,spark成长为一个基于内存的开源并行分布式集群通用计算框架,试图给出大数据运算一站式解决方案.spark主要由graphx[5]、MLlib[6]、spark streaming、spark SQL等组件构成.spark的graphx提供了优秀图计算API,适合于图计算.MLlib是一个机器学习库:引入的RDD[7]数据模型并应用内存存储计算中间结果的特性非常适合构建大型迭代式数据挖掘/机器学习应用.spark streaming用于实时和批处理计算:spark的低延迟执行引擎,虽然比不上专门的流式数据处理软件,但也可以用于实时计算.此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法. spark SQL是一个用来处理结构化数据的spark组件.它提供了一个叫做DataFrames的可编程抽象数据模型,并且可被视为一个分布式的SQL查询引擎.spark组件架构如图1,本文主要使用适用于图计算的graphx与机器学习库MLlib组件.
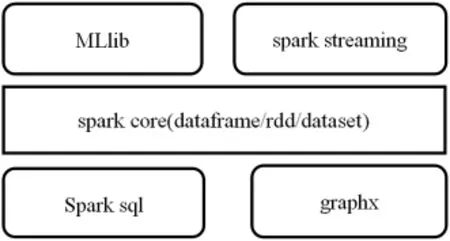
图1 spark组件架构
1.2 个性化推荐
个性化推荐系统是建立在海量数据挖掘基础上的一种高级商务智能平台,以帮助电子商务网站为其顾客购物提供完全个性化的决策支持和信息服务.个性化推荐实现细分市场和精准营销,目标是“给每个用户信息服务定制化”.目前国内个性化推荐主要应用于商品推荐、广告.个性化搜索,阅读推荐等领域应用还有待发展.典型的个性化推荐WEB应用包括4个模块:用户基本信息与行为信息的收集模块,分析用户喜好的模型分析模块和推荐算法模块,对推荐结果提供展示的可视化模块.
在推荐算法领域,各种算法及其改进层出不穷.目前推荐算法[8]主要有:协同过滤推荐、内容推荐、关联规则推荐、知识推荐、混合推荐等.针对具体的应用场景,各种推荐算法有各自的优缺点.本文采用spark-MLlib库中交替最小二乘协同过滤算法[7]属于协同过滤算法,该算法详细内容可查阅标题4部分.
但个性化推荐还面临着数据稀疏性、冷启动、多样性与精确性的两难困境、大数据处理与增量计算等问题[8].这些问题成为当前个性化推荐研究领域的热点.
2 获取数据与预处理
在公开网站IT桔子上爬取创业公司与投资机构的历史融投数据共20 785条,作为构建本次推荐应用数据源.数据爬取采用python编写爬虫实现,并保存数据为txt.csv格式,主要数据属性如表1.
本次获取的数据并不能直接使用,需要对数据进行预处理.对于数据缺失,常规处理方法主要有三种:(1)用平均值、中值、分位数、众数、随机值等替代;(2)用其他变量做预测模型来算出缺失变量;(3)把变量映射到高维空间.由于本次数据缺失比较极端:本次获取的全部数据中899条(约占总共爬取数据的4.33%)数据项缺失比较严重,因此直接删除该部分数据.对有个别数据项缺失的少量噪声数据(共8条)采用(1)中描述的众数处理.处理后的数据样例如表1.将处理后的19 886条数据存储到mysql5.5中.创建数据库表存储创业公司、投资机构、投资事件对应的数据.

表1 数据样例
统计是数据分析的重要方式,能够获得数据的隐含信息.传统统计分析一般采用python、matlab或者数据仓库技术.但普通python、matlab应用很难对大规模数据进行统计分析,而数据仓库技术需要数据建模.图计算模型由很多个节点(vertex)构成,节点之间通过边(edge)连接,节点和边中都包含了计算状态数据.在社交网络中如Twitter、Facebook,图模型很好的反应了人与人的关系,节点表示个体,边表示不同个体之间的联系.图模型可以很好的反映本文所述创业公司与投资机构的关系.因此本文采用图计算的方法对抓取的数据进行统计分析.
spark的graphx提供了优秀图计算API,这里使用graphx做了不同角度的统计.统计结果以json格式保存,并使用echart3展示出统计结果.这样在html5页面中可以直观的查看数据分布情况,如投资次数最大值、最小值、联合投资等.统计效果展示如图2~5所示.

图2 投资轮次-投资数量图

图3 项目领域-融资次数
3 模型训练与预测
交替最小二乘协同过滤算法(Alternating Least Squares)是一种基于矩阵分解[9]的协同过滤算法.用户—商品推荐应用中,常常缺少足够的用户对商品评分数据.ALS算法能很好的处理这类数据稀疏场景,算法思想大致如下文所述,公式中各变量详细说明请参照ALS[10],这里不再赘述.

图4 TOP5投资机构-融资公司关联图
图5 TOP5融资公司-投资机构关联图
(1)定义一个预测模型(数学公式),在推荐系统中常常是用户—商品模型,如公式(1)

R表示用户对产品的偏好评分矩阵,UT代表用户对隐含特征的偏好矩阵,P表示产品的隐含特征矩阵.
(2)然后确定一个损失函数如公式(2)所示:

其中rij表示用户i对产品j评分;表示uT中第i个用户特征向量;Pj是P中第j个产品特征向量,是正则系数;nui表示用户的个数;npj表示产品的个数.
(3)从用于实验的数据总体中划分出训练集.
(4)不断迭代最小化损失函数的值,从而求得参数U和P.
其迭代步骤是:首先随机初始化U,利用ALS参考文献中公式更新得到P,然后利用ui的表达式更新U,直到RMSE(均方根误差)变化小于给定阈值或者达到最大迭代次数为止,本次实验使用MLlib库默认设置.RMSE计算方法如公式(3).
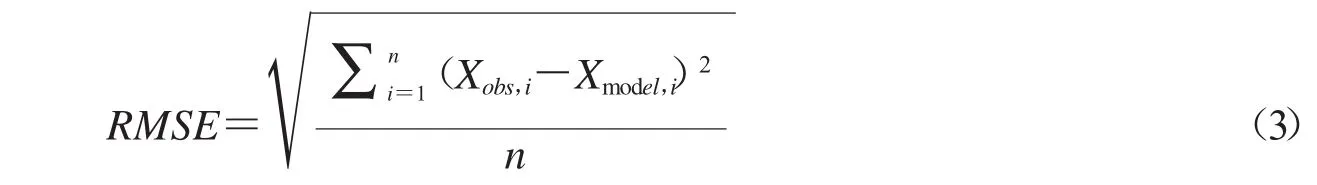
(5)把学习到的模型用做预测.
本文以创业公司的视角结合历史融投数据对投资机构进行打分,构建出训练测试集.打分规则如下文所述,客观性尚待考证,仅作为本次实验的处理办法.本文所述推荐系统关键点是从初始数据获得评分,好的评分算法将得到较好训练效果,反之训练效果较差.评分算法描述如下:
(1)选择特征
本次仅选取投资的轮次、投资次数、投资机构成立时间三维特征,其中投资次数由统计而来,没有考虑公司类别、公司地址等其他难以统一量化的属性.
(2)确定特征权重
采用层次分析法[11]确定本次特征的权重,但层次分析法确定特征重要性程度时依赖于领域知识、经验,主观性较强,建立的模型可靠性可能存在一定的问题.具体流程如下:
a.投资的轮次(m1)、投资次数(m2)、投资机构成立时间(m3)三维特征,建立层次结构如图6.

图6 层次结构图
b.根据上述三维特征间相对重要性,构造判定矩阵M,本次构造的M如表2所示.

表2 判定矩阵
c.按文献[11]所述方法求解M的特征向量并归一化得到权向量W,W经一致性检验后若具备满意的一致性,则W表示特征权重.W=[w1,w2,w3],
其中w1,w2,w3分别表示投资的轮次、投资次数、投资机构成立时间的权重.
d.判断矩阵一致性检验,确定权向量W,本次试验中求得W值为w1=0.4,w2=0.5,w3=0.1.
(3)确定特征值
对评分归一化到[0-10]之间.对投资轮次天使轮至E轮的特征赋值范围为(1-10),例如天使轮10分,A轮9分,B轮8分等依次衰减记为s1;投资次数按最大值中间值,均值,最小值划分段依次衰减赋值记为s2和投资机构成立时间按60年代,70年代等依次衰减赋值记为s3.
(4)计算出历史融投事件数据中创业公司对投资机构评分.每个投资机构最终得分为计算公式(4):

评分后得出txt格式存储的数据如表3.机构评分数据的75%用来训练模型,剩下的25%进行测试.

表3 评分样例
使用 IntelliJ IDEA编写调用 spark-MLlib中ALS算法的scala作业程序,该作业中需要设置初始值,综合计算资源与多次试验尝试:迭代次数numIterations取10,表示userFeatures和itemFeatures的个数的rank取8,正则化参数lambda取0.01.使用ALS算法对训练集数据进行反复训练,并用测试集对模型进行测试.通过计算RMSE(平均误差平方和开根号)来调整迭代的次数,RMSE值越小模型效果越好.训练之后的模型可以保存,需要在线实时推荐时可以加载该模型,进行实时推荐,这也是spark平台实现ALS算法的优势.
4 可视化
本文通过springMVC框架实现可视化.架构与数据流如图7所示.
将训练后的算法模型保存,并可以根据输入的创业公司名称如“拼班”在线个性化推荐.将预测评分进行排序,取评分最高的前5名投资机构推荐给创业公司:评分最高的前5名投资机构的序号与投资机构名称的对应关系通过与mysql中存储的投资机构数据进行映射实现.个性化推荐效果如图8所示.

图7 架构与数据流图

图8 个性化推荐样例
5 实验与优化
本文对IT桔子公开网站上获得的20 785条原始数据预处理得到19 886条实验数据,进而得到19 886条评分数据.使用IDEA编写spark的scala本地程序,调用ALS算法,随机选取75%评分数据进行模型训练,发现单机模式下个人计算机由于内存溢出而无法完成计算.首次使用的是2核4GB内存的个人计算机,spark是基于RDD的内存式并行计算,应是内存过小导致.然后,缩小训练数据集,仅仅使用之前1/4的数据,顺利运行出预测评分.更换为4核12GB内存的个人计算机再次训练全部数据,但最终内存溢出而结束.分析ALS算法原理,原因是本次计算过程是笛卡尔积式的矩阵计算,并行度较高,对CPU个数有更大需求.借助某公司的CDH5集群,顺利运行全部得分数据,并得出对所有创业公司的推荐评分结果集.具体运行情况如表4所示.

表4 试验环境与结果
由上述试验结果可得出结论:若采用spark平台集成的ALS算法对大规模数据集进行模型训练,对spark集群的硬件资源要求较高,尤其是需要实时训练的场景.若想得到理想的运算速度,同时减少硬件投资,需要对该训练任务进行优化.结合自己与他人的实践经验[12]现提出以下优化方案:(1)如果搜集到的数据以小文件(小于hdfs[2]存储块大小)的形式存在,会由于频繁的I/O增加运行时间,参考在某公司实习合并flume分散日志的经验,需要对小文件进行合并减少打开关闭文件次数.(2)众所周知,笛卡尔积运算,具有指数级运算复杂度.可以采取对矩阵进行预先分块,减少网络包的传输量和笛卡尔积的计算量.(3)把分区操作提前到分块操作之前,均衡task分布,并为每个task设置合适输入数据大小.
本文采用RMSE衡量ALS算法的效果,RMSE越小模型越好.正则化参数lambda取固定值0.01,迭代次数numIterations和表示userFeatures和itemFeatures个数的rank,这两个参数取值对RMSE具有较大影响,需要反复试验来确定rank,numIterations的值.对19 886条评分数据随机划分,其中75%用作训练集训练ALS算法模型.表5展示了同一训练集使用不同参数训练后的RMSE.发现固定numIterations小范围增加rank值对RMSE没有太大影响,而固定rank小范围增加numIterations值对RMSE影响较大.

表5 不同参数的RMSE
参数lambda取0.01,numIterations、rank取表5中RMSE较小时的值,对19 886条评分数据按随机划分,其中75%用作训练集训练ALS算法模型,若训练集同时作为测试集,则会出现过拟合现象.剩下的25%用于测试模型效果,重复3次,3次测试集的RMSE和平均RMSE如表6所示,效果表现总体较好.

表6 3次测试集的RMSE和平均RMSE
6 结语
本文应用spark平台集成的ALS算法对投资领域的推荐应用进行了初步探索,提出图计算作为投资融资行业数据集统计分析的方法并结合garaphx完成了相关数据统计分析工作,给出了处理投资领域数据评分算法,结合实际实验数据给出了优化思路,并使用springMVC实现了微型WEB推荐系统.但限于集群运算资源、数据资源、个人经验等因素,还有许多需要加强与改进的地方.后续还有很多工作可以做:获取更多的数据应用于实验,增加数据分析的维度,更精细分类推荐,构造更好的评分算法、损失函数,实现为投资机构推荐好的创业项目等.
[1]ZAHARIA M,CHOWDHURY M,DAS T,et al.Fast and interactive analytics over Hadoop data with Spark[J].USENIX Login,2012,37(4):45-51.
[2]SHVACHKO K,KUANG H,RADIA S,et al.The hadoop distributed file system[C]//2010 IEEE 26th symposium on mass storage systems and technologies(MSST).IEEE,2010:1-10.
[3]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[4]VAVILAPALLIV K,MURTHY A C,DOUGLAS C,et al.Apache hadoop yarn:Yet another resource negotiator[C]//Proceedings of the 4th annual Symposium on Cloud Computing.ACM,2013:5.
[5]XIN R S,GONZALEZ J E,FRANKLIN M J,et al.Graphx:A resilient distributed graph system on spark[C]//First International Workshop on Graph Data Management Experiences and Systems.ACM,2013:2.
[6]MENG X,BRADLEY J,YAVUZ B,et al.Mllib:Machine learning in apache spark[J].Journal of Machine Learning Research,2016,17(34):1-7.
[7]ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient distributed datasets:A fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation.USENIX Association,2012:2.
[8]LÜ L,MEDO M,YEUNG C H,et al.Recommender systems[J].Physics Reports,2012,519(1):1-49.
[9]KOREN Y,BELLR,VOLINSKY C.Matrix factorization techniquesforrecommendersystems[J].IEEE,Computer Journal,42(8),30-37.
[10]ZHOU Y,WILKINSON D,SCHREIBER R,et al.Large-scale parallel collaborative filtering for the netflix prize[C]//Algorithmic Aspectsin Information and Management,International Conference,Aaim 2008,Shanghai,China,June 23-25,2008.Proceedings.DBLP,2008:337-348.
[11]常建娥,蒋太立.层次分析法确定权重的研究[J].武汉理工大学学报(信息与管理工程版),2007,29(1):153-156.
[12]杨志伟.基于Spark平台推荐系统研究[D].合肥:中国科学技术大学,2015.
Personalized Recommendation of Investment Institutions Based on Spark
CHEN Guitao,QU Jianqin,YAN Yikun
(Department of Computer Science and Technology,Shantou University,Shantou 515063,Guangdong,China)
In the big data technology platform of spark,analysis and modeling of the historical data of venture capital financing industry is based on alternating least squares algorithm.The personalized recommendation application solution is proposed and constructed for the industry. By recommending reliable investment institutions to startups,the solution can meet the needs of financing of enterprises faster and better,which has important practical significance and commercial value.Accordingtothe characteristics ofventure capital financingindustry,the graph calculation is proposed as the method of statistical analysis.A scoring algorithm is presented for dealing with data in the field of investment finance.The miniature WEB recommendation system with springMVC architecture is implemented and finally the recommended model evaluation criteria based on the actual experimental data is given and the ideas of optimization of the recommendation system is shown.
spark big data;alternating least squares algorithm;graph calculation;recommendation system;investment financing
1001-4217(2017)04-0056-08
TP3
A
2017-02-24
陈贵涛(1987—),男,河南信阳人,硕士,研究方向:大数据、软件工程.E-mail:14gtchen@stu.edu.cn.
猜你喜欢
文苑(2020年4期)2020-05-30
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
股市动态分析(2016年29期)2016-08-04
