
基于启发式强化学习的空战机动智能决策
2017-11-17 09:05:59左家亮杨任农张滢李中林邬蒙
航空学报 2017年10期
左家亮,杨任农,张滢,李中林,邬蒙
1.空军工程大学 航空航天工程学院,西安 710038 2.空军驻沪宁地区军代表室,南京 210007
基于启发式强化学习的空战机动智能决策
左家亮1,*,杨任农1,张滢1,李中林2,邬蒙1
1.空军工程大学 航空航天工程学院,西安 710038 2.空军驻沪宁地区军代表室,南京 210007
空战机动智能决策一直是研究热点,现有的空战机动决策主要采用优化理论和传统的人工智能算法,是在相对固定的环境下进行决策序列计算研究。但实际空战是动态变化的,且有很多不确定性因素。采用传统的理论方法进行求解,很难获取与实际情况相符的决策序列。提出了基于启发式强化学习的空战机动智能决策方法,在与外界环境动态交互的过程中,采用“试错”的方式计算相对较优的空战机动决策序列,并采用神经网络方法对强化学习的过程进行学习,积累知识,启发后续的搜索过程,很大程度上提高了搜索效率,实现空战决策过程中决策序列的实时动态迭代计算。最后仿真实验结果表明本文提出的算法所计算的决策序列与实际情况相符。
空战机动;智能决策;启发式强化学习;神经网络;决策序列
空战机动智能决策一直是研究热点[1-2]。由于空战过程动态变化,且有很多不确定性因素,使对空战智能机动决策研究充满挑战[1]。现有空战决策研究主要采用专家系统[3]、基于对策[4]和优化理论[5-6]等方法求解,计算相对最优或局部最优[3]的决策序列[7],但由于计算复杂度的限制,建模过程需要一定程度简化[8],使得出的结果很难符合空战实际情况。文献[9]提出一种改进的蚁群算法,解决了机器人路径规划问题,实现在复杂环境中也能快速规划出最优空战路径,并且可以避免陷入路径死锁状态;文献[3]针对专家系统的缺陷,采用基于滚动时域控制的机动决策方法对最优控制问题进行求解;文献[6]在一对一的背景下提出了启发粒子群算法可提高空战决策的搜索效率,使在空战中占据有利态势。但上述方法在求解空战机动决策问题时,前提条件是目标环境和约束条件是已知的,且较多针对的是固定目标[10],不适合动态变化的空战决策过程。
本文针对空战决策过程的动态与未知性,基于强化学习[11-12]理论,通过不断“试错”的方式与外部环境进行交互式的在线学习[13],并根据学习过程中的累加回报值选取最优的决策序列。强化学习是一种重要的机器学习方法,本质上是一种无监督的机器学习方法。但由于标准的强化学习搜索过程是随机的,且回报累加较慢,很难在较短的时间内获取到相对较优的决策序列。在对实时性要求很高的空战决策过程中,本文采用基于神经网络的方法,对强化学习的搜索过程进行学习,启发后面的搜索过程,提高搜索,可在较短时间内获取与空战实际情况相符的机动决策序列。因此,采用启发式[14]强化学习的方法更适合用来解决动态变化的空战机动决策问题。本文把空战决策仿真中的每一架飞机定义为一个智能体(agent),agent在空战机动决策过程中相对独立,实时获取其他agent决策仿真执行的结果,更新该agent下一步决策仿真的输入。
1 空战攻击效果预测
1.1 空战攻击效果分类
典型的空空导弹攻击包线是指以目标机为中心的一个空间范围,攻击机在该范围内向目标机发射导弹,能以不低于一定概率命中目标机。但这种方式对空战决策的意义并不大,只能大致说明从不同角度对目标机进行有效攻击的范围。而以攻击机为中心,定义攻击效果分类如图1所示,可很大程度上指导攻击机如何进行攻击决策,目标机如何规避攻击,其中AIi为攻击机,Tgtj为目标机,hi为攻击机高度,vi为攻击机速度,φi为攻击机航向,d为两机距离,ψ为目标机相对方位,ho为目标机高度,vo为目标机速度和φo为目标机航向。
在实际应用中,需要把攻击效果分为4种情况,区域Ω1表示此态势下对目标机发射武器,目标机做任何机动都无效,即不可逃逸区;区域Ω2表示此态势下对目标机发射武器,目标机做规避机动(默认为180°置尾机动),可摆脱攻击;区域Ω3表示此态势下对目标机发射武器,目标机保持现有运动状态,可摆脱攻击;此态势下的其他区域为Ω4,表示被攻击有效的概率极低。
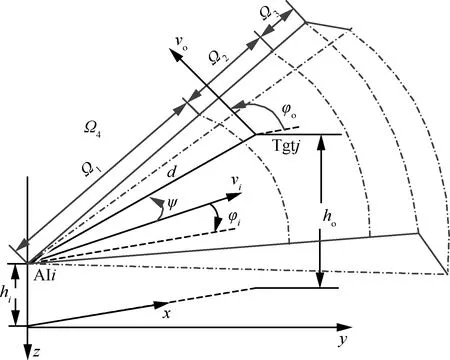
图1 攻击效果分类Fig.1 Classification of result of missile attack
理论上可对攻击区分类进行动态计算,但时间复杂度很高,无法满足实时性要求。因此,本文将采用基于神经网络的方法,通过学习不同态势下空战结果数据,实现对类似态势下攻击效果相对精确的预测。如图1所示,Tgtj处于AIi的区域Ω2内。
1.2 神经网络预测空战攻击效果
理论上可通过选择攻击机高度hi、攻击机速度vi、攻击机航向φi、两机距离d、目标机方位ψ、目标机高度ho、目标机速度vo和目标机航向φo共8个主要参数可基本描述空战相对态势(如图1所示),这些数据可直接从空战训练记录数据中提取,并作为神经网络的输入层。
因此神经网络的输入层为8个节点;输出层可采用2个节点表达攻击效果的预测,每个输出节点的取值范围为1或0,[1,1]为Ω1,[1,0]为Ω2,[0,1]为Ω3,[0,0]为Ω4。神经网络在其他条件相同的情况下,输出层节点数与网络的预测能力成反比,输出层节点数越小,其预测精度越高。基于攻击效果预测模型结构为8-n-2,如图2所示。采用日常空战训练中所产生的模拟发射数据,自动生成样本数据(样本量为20 000),训练样本与检验样本为1∶1。采用模糊C均值聚类方法对训练样本进行处理,可得神经网络隐层节点数n=51较为合理,设学习率为0.01,离线训练1 500次的实验结果如图3所示。
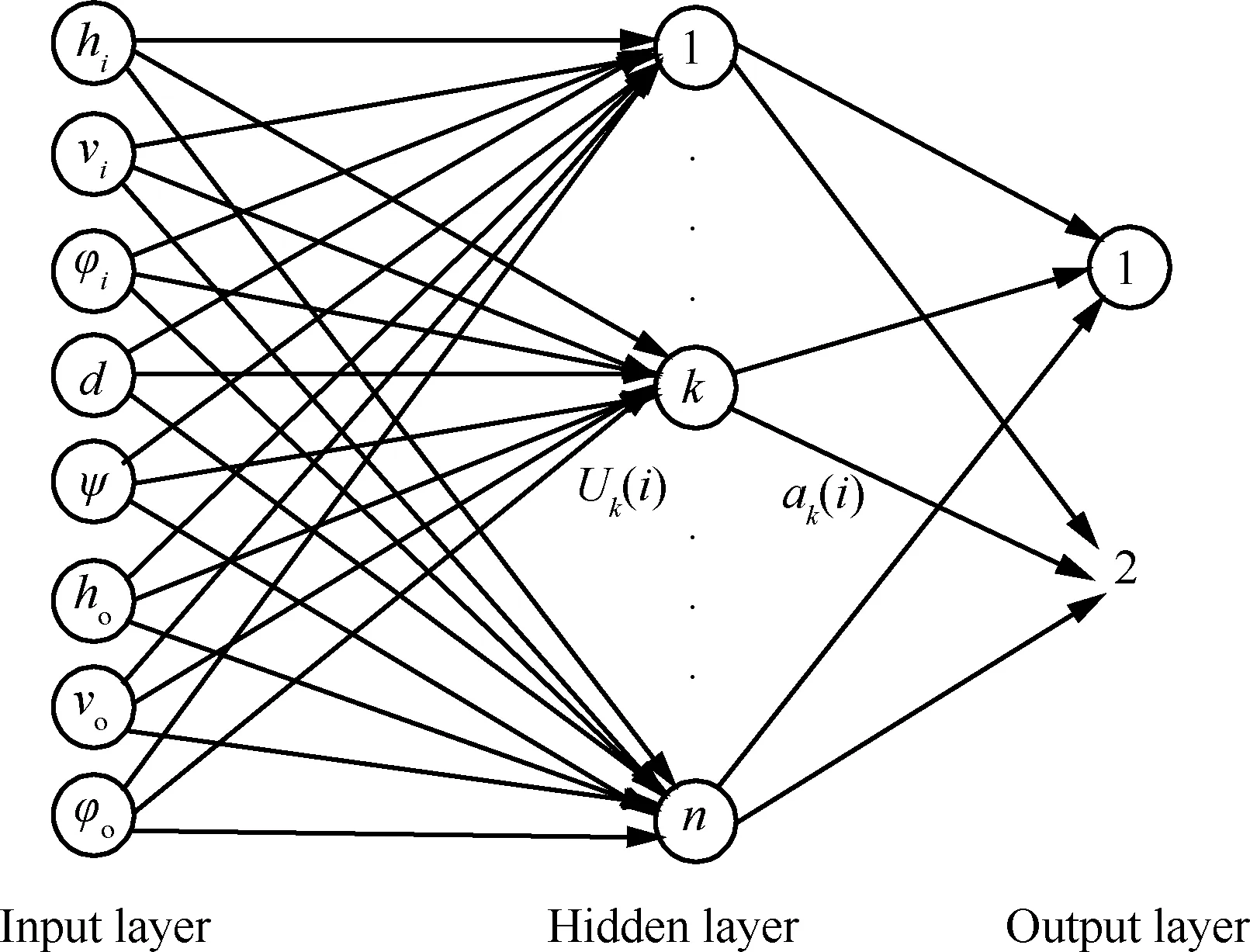
图2 基于神经网络的攻击效果预测模型Fig.2 Model for predicting result of missile attack based on neural network
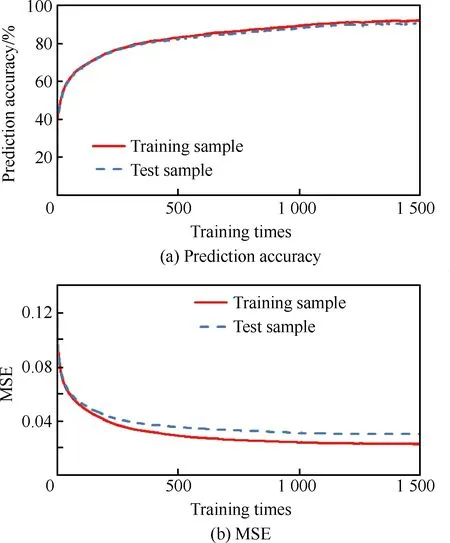
图3 神经网络预测攻击效果Fig.3 Results of prediction of missile attack with neural network
2 空战机动智能决策模型
本文研究重点是空战决策过程,即决策序列的计算。agent通过动态执行最新的空战决策序列实现编队协同空战仿真,决策序列是由一系列时间连续的决策点组成,如图4所示。

图4 空战决策序列示意图Fig.4 Diagram of air combat decision sequence
空战决策点有空战机动类型、速度、侧滚角、过载、决策周期、位置、高度、航向角和俯仰角组成。空战决策序列是n个时间连续的空战决策点组成,如图4所示。假设目标机保持当前状态飞行,agent执行空战决策序列,可由当前状态快速逼近到攻击目标区域,如图5所示。为避免强化学习陷入死锁,当每轮最大搜索步数没有获取可行的决策序列,则强制由当前状态重新开始决策序列迭代搜索。在当前战术执行周期内没有获取到决策序列,则沿用上一战术周期的获取的决策序列。
最理想情况下,只需一轮决策序列计算,即可到达对目标的攻击区域。但实际情况中,随着目标的不断变化,攻击目标的区域也在不断的变化,同时需要避开目标的攻击区域(如图5所示),进行周期性地动态迭代计算决策序列,实现逐渐逼近攻击目标区域。
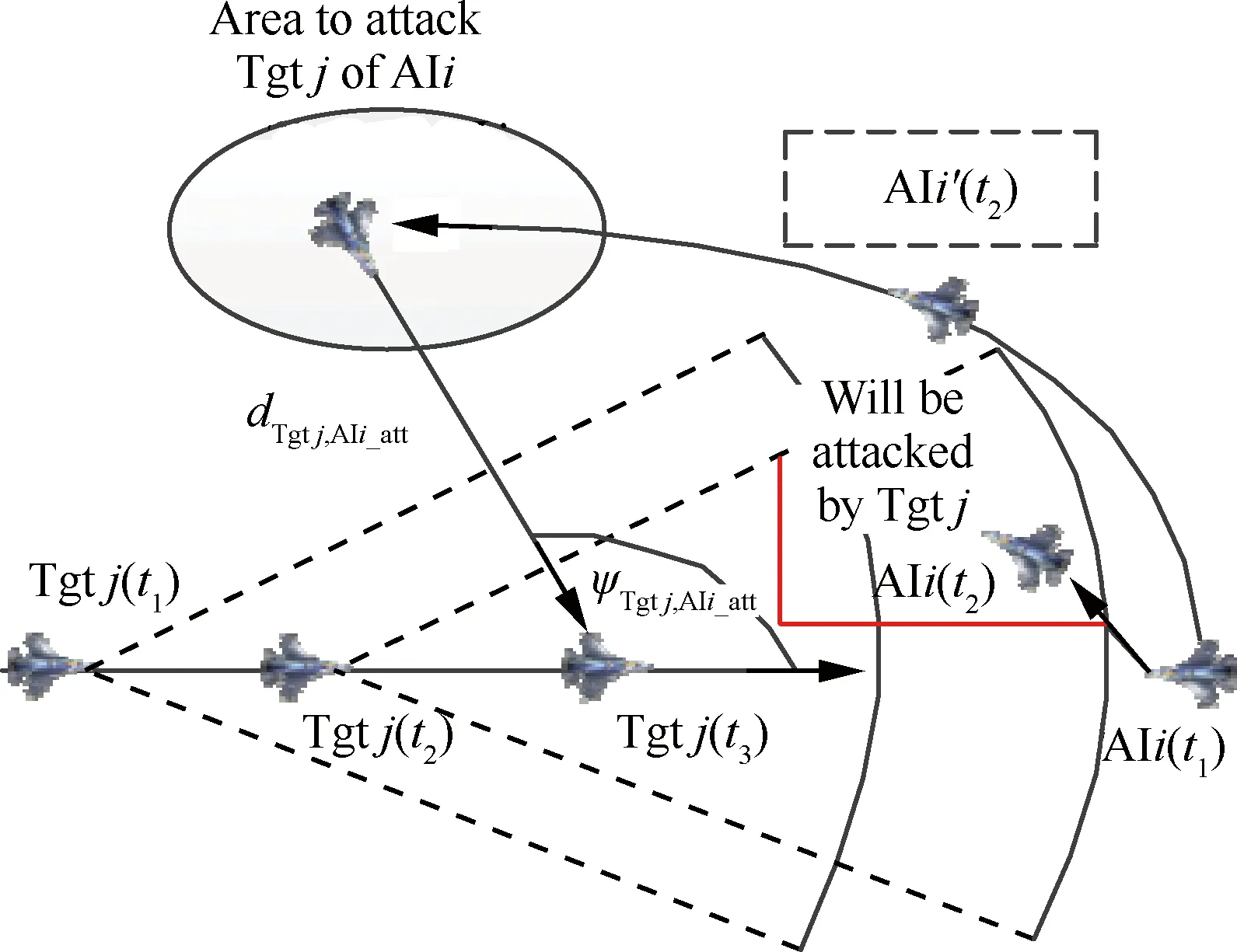
图5 AIi空战决策搜索过程示意图Fig.5 Diagram of air combat decision search process of AIi
2.1 标准强化学习过程
强化学习是基于Markov决策过程(Markov Decision Process,MDP)的理论框架[6],将MDP的〈S,A,T,R〉4元组(S为状态集,A为动作集,T状态转移概率,R为回报函数),转换化为基于当前状态s(t),选择状态转移函数a(t+1),为达到新的状态s(t+1)寻找最大化累积回报的强化学习过程[15]。定义折扣累积回报期望值Qπ(S,A):
(1)
式中:γ为折扣因子,0<γ<1;π为策略空间。在文献[16]中已经证明了Q值累加的收敛性。Q值迭代计算表达式为
Q(s(t+1),a(t+1))=Q(s(t),a(t))+

(2)
式中:α为调节系数;R(s(t),a(t+1),s(t+1))为从状态s(t)选择动作a(t+1)达到s(t+1)的回报函数,s(t)状态下的V值为
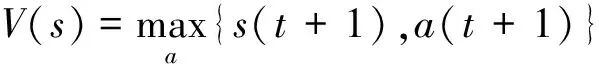
且s(t)状态下的最优策略为
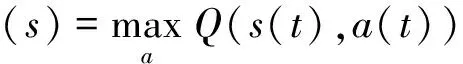
(3)
标准强化学习算法过程如图6所示。
空战决策序列搜索是指AIi从t1时刻开始,可在最短时间内,规避目标Tgtj的攻击区域,为到达预定攻击目标区域AIi_att,而进行空战决策序列AAIi_Set计算的过程。AIi的一轮(episode)学习是指为获取完整AAIi_Set而进行搜索计算的过程。
根据空战决策实时性要求,对AIi在空战决策执行之前,要完成一轮可行的空战决策序列AAIi_Set的预测计算。下一个战术周期开始之前,需要根据更新的外部环境(包括攻击目标区域和战场态势的变化),重新完成空战决策序列AAIi_Set计算,通过不断的迭代计算,实现agent攻击目标区域的动态逼近。
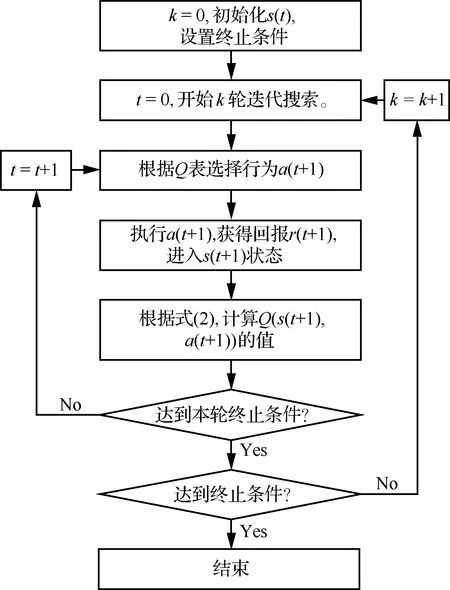
图6 标准强化学习过程Fig.6 Process of standard reinforcement learning
2.2 空战状态
本文在三维空间中将飞机视为质点,如图7所示,可用飞机质心位置和姿态表达其所处的状态。因此,可将t时刻攻击机与目标机的相对状态s(t)定义为
s(t)=[ψ(t),μ(t),d(t),Δh(t),δ(t)]T
在北东地惯性坐标系下,记x、y、z分别表示飞机的位置坐标。φ表示飞机的航向角,则飞机j相对于飞机i的相对位置参数计算如下:
式中:ψ(t)为攻击机的视线角;μ(t)为目标机进入角;d(t)为两机之间的相对距离;Δh(t)为两机之间的相对高度差;δ(t)为两机速度矢量夹角,且ψ∈[0°,+180°],μ∈[0°,+180°],d∈(0,+∞) m,Δh∈(0,+20 000) m,δ∈[0°,+180°]。高度z∈(0,20 000) m,x和y取值范围无限制,速度v∈[0,400) m·s-1,航向角φ∈[-180°,180°]。ψij为飞机i攻击目标机j的视线角。

图7 两方空战相对位置Fig.7 Relative position between two sides in air combat
2.3 空战状态转移函数
空战机动概括起来主要体现在3个方面,即改变航向、改变高度和稳定飞行,可定义决策时刻可采取的行动[17]集A:
A={lt,rt,up,dn,sb}
假设飞机转弯为稳定盘旋转弯,即高度不变且无侧滑。其中,lt表示左转,机动类型代码为1;rt表示右转,机动类型代码为2; up表示保持航向不变拉起爬升机动,机动类型代码为3;dn表示保持航向不变下拉俯冲机动,机动类型代码为4;sb表示保持航向和速率稳定飞行,机动类型代码为5。
Δτ为微分时间步长,当Δτ很小时,飞机的推力、阻力、坡度、速率、航向和俯仰角等改变飞机运动状态的变量在Δτ时间内保持不变。约定,阶段t飞机i采取行动ai(t)∈Ai,只作用于状态的xi、yi、zi、vi、θi和φi元素。假设飞机i的最大可用推力为Pi,最大坡度(即滚转角)为γi+和γi-,最大过载为ni+和ni-。
1) 改变航向(左转lt和右转rt)。飞机保持高度稳定盘旋转弯且无侧滑,则飞机作圆周运动的角速度为
当ai(t)=lt时,γi=γi+; 当ai(t)=rt时,γi=γi-。则
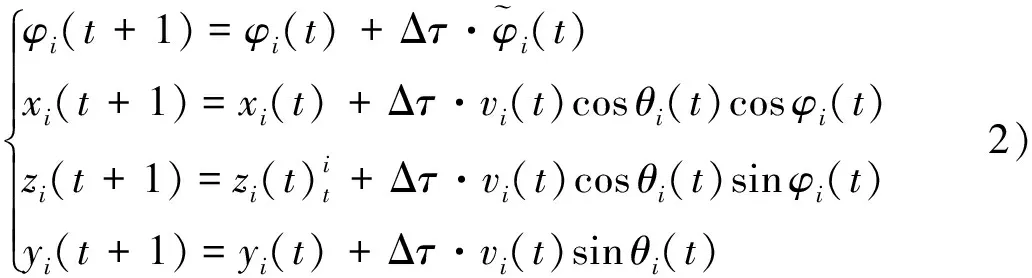
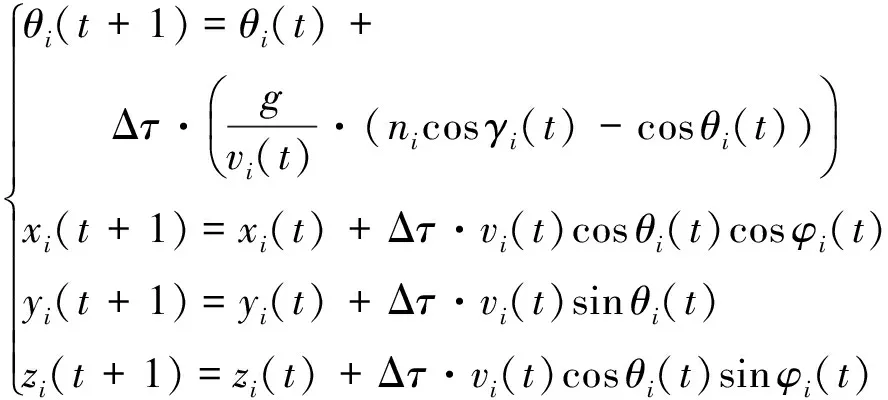
3) 稳定飞行sb。飞机保持速度、航迹倾角和航向角不变,仅发生位置改变,有
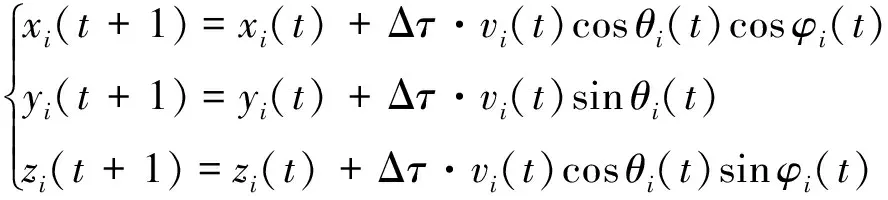
式中:P和X分别为飞机所受推力和阻力;g为重力加速度;m为飞机质量。本章暂不考虑对速度的控制,根据状态转移的需要,设置速度v在约束条件范围内即可,侧滚角γi采用相同的处理方式,重点在战术空战决策序列计算。
2.4 空战决策回报函数
当AIi空战能力弱于Tgtj的情况下,AIi对目标Tgtj理想的攻击位置为目标Tgtj的后半球,如图5中椭圆形区域,AIi_att表示该区域的中心点,满足:
(4)
式中:φAIi,Tgtj(t)为t时刻AIi攻击Tgtj的理想攻击区域中心点的水平方位角度,α1为下限,α2为上限,默认取值范围为[135°,215°],其为Tgtj的侧后方;dAIi_att,Tgtj(t)为t时刻Tgtj相对于AIi理想攻击区域中心点的距离ΔD小于AIi的有效攻击距离;ΔH为AIi的高度差范围。
定义AIi单步空战动作A选择的回报函数RAIi(A):
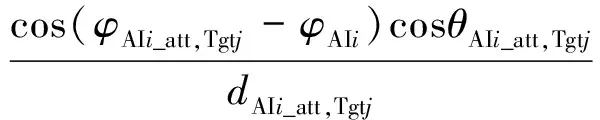
当Ω(Tgtj,AIi)=Ω1时,RAIi(A)取值为-1(如图4虚线部分所示),则停止本轮搜索,重新开始下一轮搜索;当Ω(Tgtj,AIi)=Ω2‖Ω3‖Ω4时,φAIi(t)为t时刻AIi的航向,当该值越逼近φAIi_att,Tgtj(t)时,cos(φAIi_att,Tgtj(t)-φAIi(t))的值越大,RAIi(A)值也越大;dTgtj,AIi_att(t)>1,其值越小,RAIi(A)值越大;RAIi(A)的取值有正有负,为正时,说明正在接近攻击区域为负时说明正在远离攻击区域,并具有很强的连续性。可对AIi的空战决策选择具有很强的启发性,突出即时回报函数的方向性,减少每轮搜索迭代的步数。
2.5 动态目标分配及攻击目标区域计算
空战目标分配的目的是预测经过k个决策周期后,假设攻击目标为Tgtj的相关智能体各自执行决策序列后,可对目标机Tgtj形成合围之势,且不会经过目标机Tgtj的可攻击区域Ω1。如图8所示,AI1、AI2和AI3的攻击目标为Tgt1理想状态分别对目标形成合围之势。
设同时攻击Tgtj的agent数量为kj,则可计算kj个攻击Tgtj区域,其中第i个攻击区域中心AAIi_att(Tgtj)={φAIi_att,xAIi_att,yAIi_att,zAIi_att}的计算公式为
(5)
式中:φTgtj为目标Tgtj的航向;xTgtj、yTgtj和zTgtj为目标位置;d为攻击区域中心到目标机Tgtj的距离,d小于AIi导弹的最大发射距离。
将目标分配问题转换为m个agent攻击n个目标的路径最短的最优化问题,求解攻击目标Tgtj的agent数量kj及对应的智能体编号。要求:
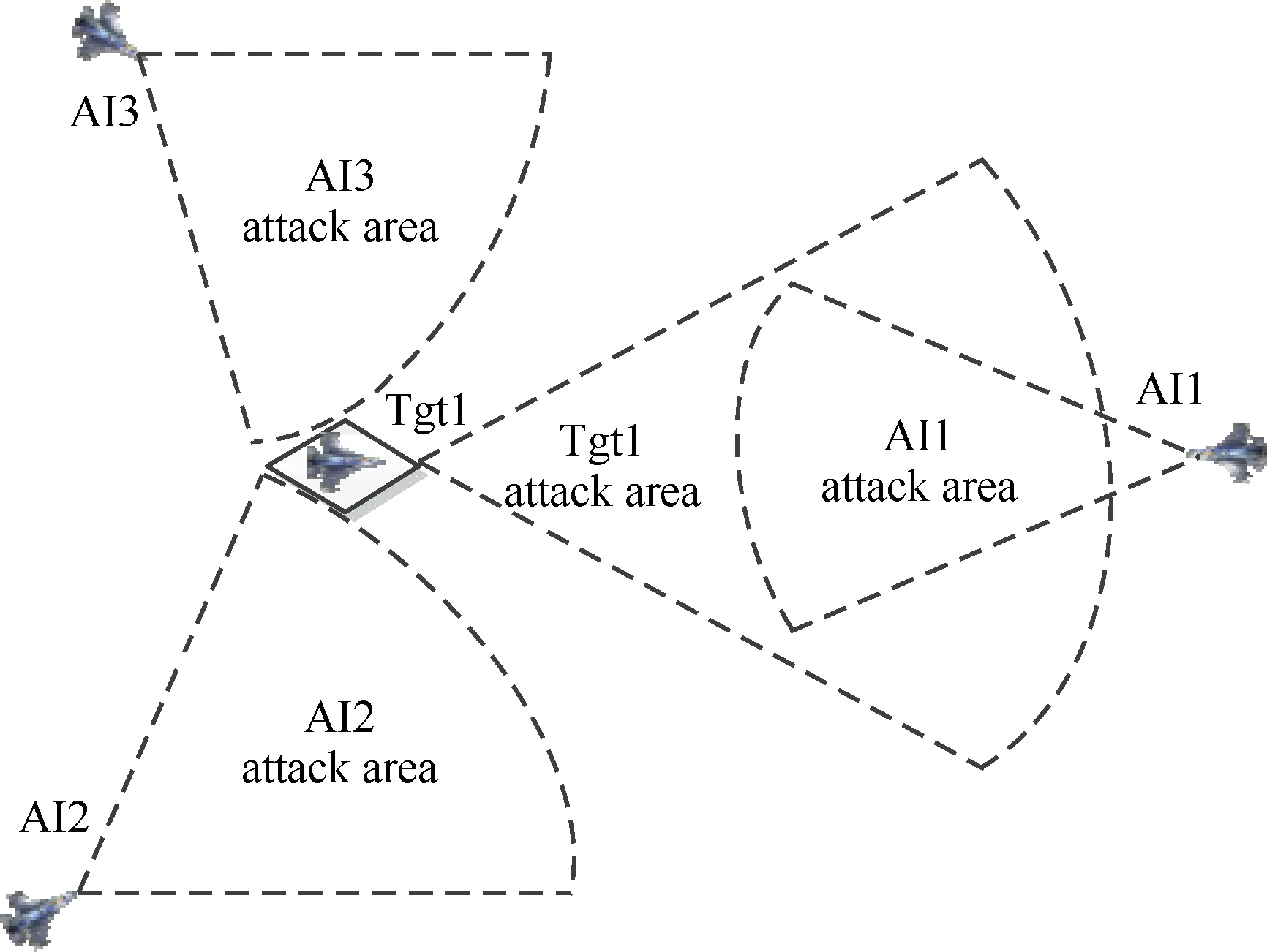
图8 动态目标分配Fig.8 Target assignment for agents
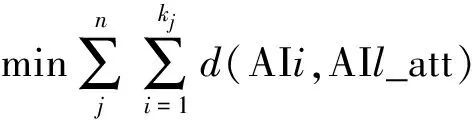
式中:d(AIi,AIl_att)为AIi到第l个攻击Tgtj的区域中心的距离,1≤i≤kj,1≤l≤kj。
当编队完成对目标Tgtj的攻击,或该编队中的一半以上智能体被命中,则重新进行目标分配。
2.6 空战决策策略空间
预测第1步时,可选择5种空战机动,即有5种策略;预测第2步,可选择5种空战机动类型,将会产生25种策略;当预测第n步,将会产生5n种策略。因此,当预测的步数越多,可选的策略越多,并呈指数增长,其计算量也会剧增,会带来“维数灾”的问题。因此采用标准强化学习的方法,在较短的时间内搜索出效果相对理想的决策序列是比较困难的。
3 启发式强化学习的决策序列搜索
由于标准强化学习搜索过程的决策选择是随机的,回报累积过程相对较慢,用于求解复杂的在线空战决策问题比较困难。本文通过在强化学习过程中增加启发[9]函数F(s(t),a(t+1),s(t+1)),构建分层强化学习模型,如图9所示。上层是基于神经网络构建攻击效果预测的启发层,启发底层决策搜索的强化学习过程。
启发式强化学习过程需要根据启发函数值而选择策略,Q值迭代方法需要增加考虑启发函数带来的回报。
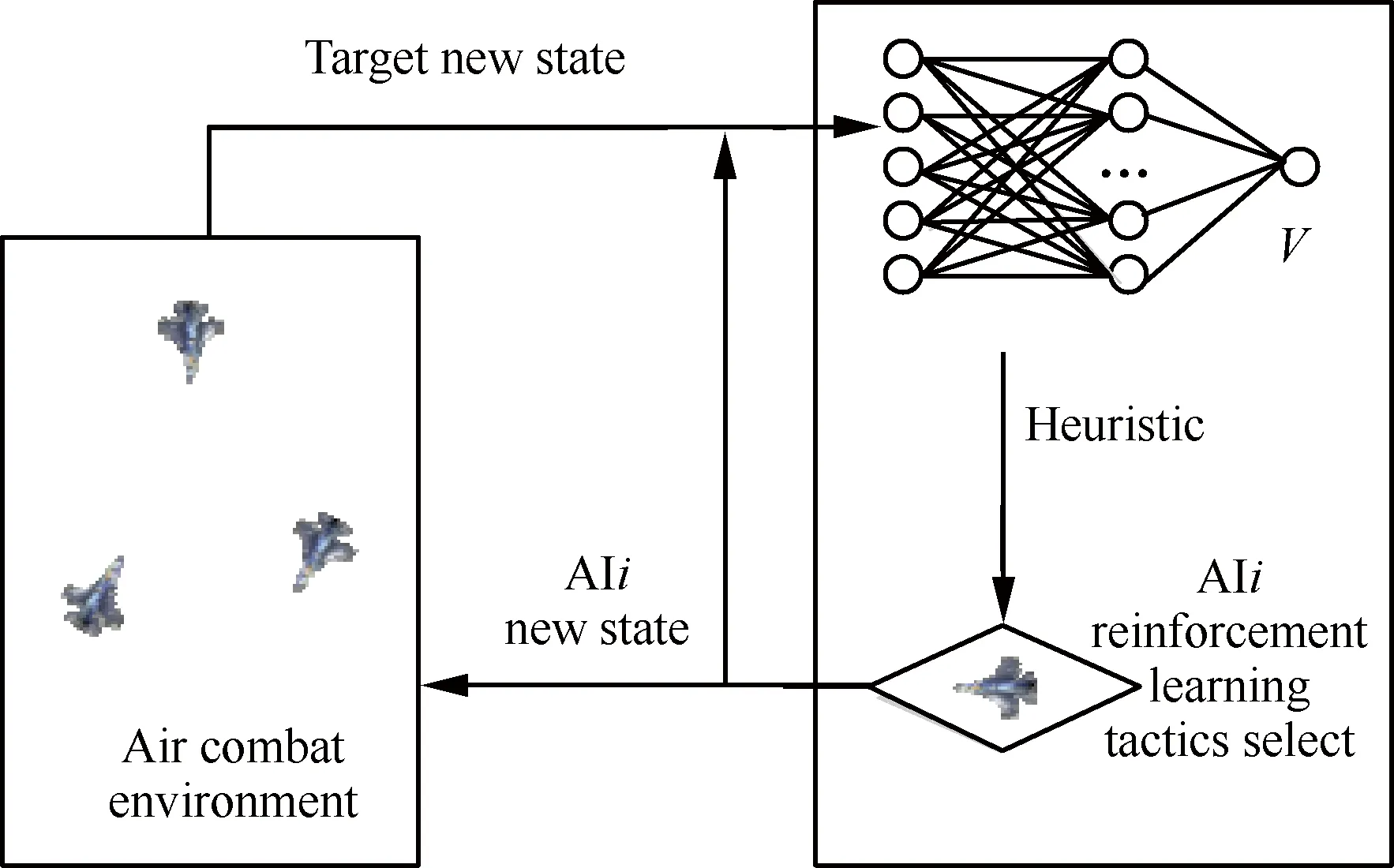
图9 启发式强化学习模型Fig.9 Heuristic reinforcement learning model
Q(s(t+1),a(t+1))=Q(s(t),a(t))+
(6)
3.1 空战决策启发式搜索
通过对强化学习的搜索过程进行学习并积累经验,并启发后面的搜索过程,逐步减少搜索步数,提高效率。基于神经网络的空战决策分层强化学习模型,上层神经网络采用5-16-1相对简单的网络结构,输入为空战状态,输出为V值。在线学习过程中,同步采用在搜索过程中获取的经验知识对神经网络进行在线训练,提高对强化学习过程中策略选择的启发性。
当且仅当出现a(t)是s(t)状态下的最优策略时,即满足:
说明此态势是攻击效果预测最佳的数据样本,且搜索方向是向攻击目标区域直接逼近,可用来对上层神经网络进行在线训练,提高强化学习搜索的方向性。
F(s(t),a(t+1),s(t+1))为强化学习中从状态s(t),执行a(t+1),进入状态s(t+1)时获得的启发值,表达式为
F(s(t),a(t+1),s(t+1))=
γV(s(t+1))-V(s(t))
式中:V(s(t))和V(s(t+1))分别对应s(t)和s(t+1)状态输入到神经网络得出的输出值。
在a(t+1)策略选择时,优先考虑F(s(t),a(t+1),s(t+1))值最大的a(t+1)是否满足要求。同时采用梯度下降的方法,更新神经网络权值修正量计算方法,即
Δw(t)=η[R(s(t))+γV(s(t+1))-V(s(t))]·
(7)
式中:η为学习率,0<η<1;λ为启发因子,0<λ<1。并调整神经网络隐藏层到输出层的权值wij,再根据训练神经网络的误差反向传播原理,更新输入层到隐藏层的权值。
启发式强化学习的空战决策搜索算法分为初始阶段与动态搜索阶段。初始阶段为快速计算由当前状态到攻击目标区域的最短路径的空战决策序列,为负责启发学习函数的神经网络提供训练样本数据;动态搜索阶段则根据agent当前状态和最新的目标机态势,对空战决策序列进行动态迭代计算。
3.2 空战决策序列初始化
根据目标分配的结果,设AIi的目标为Tgtj,AIi_att为攻击目标区域中心,k为周期数。初始时刻,AIi需要完成从当前状态向攻击目标区域直线逼近的空战决策序列AAIi_Set的计算,不考虑中间是否会出现Ω(Tgtj,AIi)=Ω1的情况,为启发函数的神经网络提供了攻击效果预测的训练样本,对空战决策搜索的强化学习过程明确了搜索的方向性。空战决策序列初始化计算的目的使agent最少有一个可执行的空战决策序列,其计算方法如图10所示。
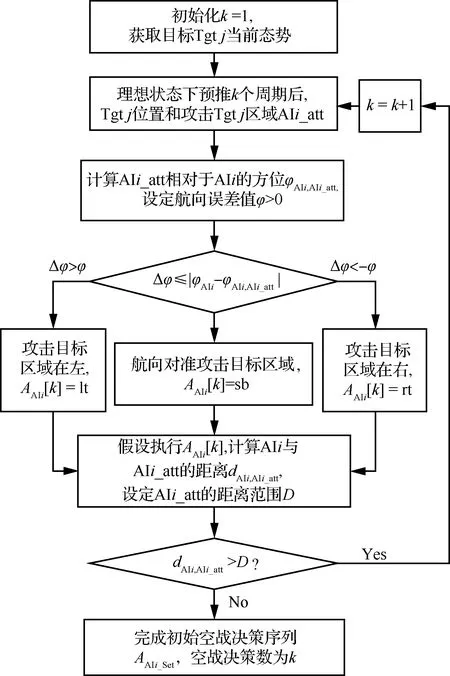
图10 启发式强化学习初始化Fig.10 Initialization of heuristic reinforcement learning algorithm
空战决策序列初始化计算过程描述如下:
步骤1获取目标机Tgtj的当前最新的态势,迭代次数k=1。
步骤2k=k+1,理想状态下,预推k个周期后目标机Tgtj的位置和攻击该目标的区域AAIi_att。
步骤3计算AAIi_att相对于AIi的方位φAIi,AIi_att,设定航向误差值φ>0。
步骤4Δφ=|φAIi-φAIi,AIi_att|。当Δφ>φ,攻击目标区域在左,选择AAIi[k]=lt;当Δφ<-φ,攻击目标区域在右,选择AAIi[k]=rt;其他情况下,航向对准攻击目标区域,选择AAIi[k]=sb。
步骤5假设执行AAIi[k]=[k],计算AIi与AIi_att的距离dAIi,AIi_att,设定AIi_att的距离范围D。如果dAIi,AIi_att>D,回到步骤2。
步骤6完成空战决策序列AAIi_Set初始化,空战决策数为k。
3.3 空战决策序列动态迭代搜索
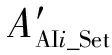
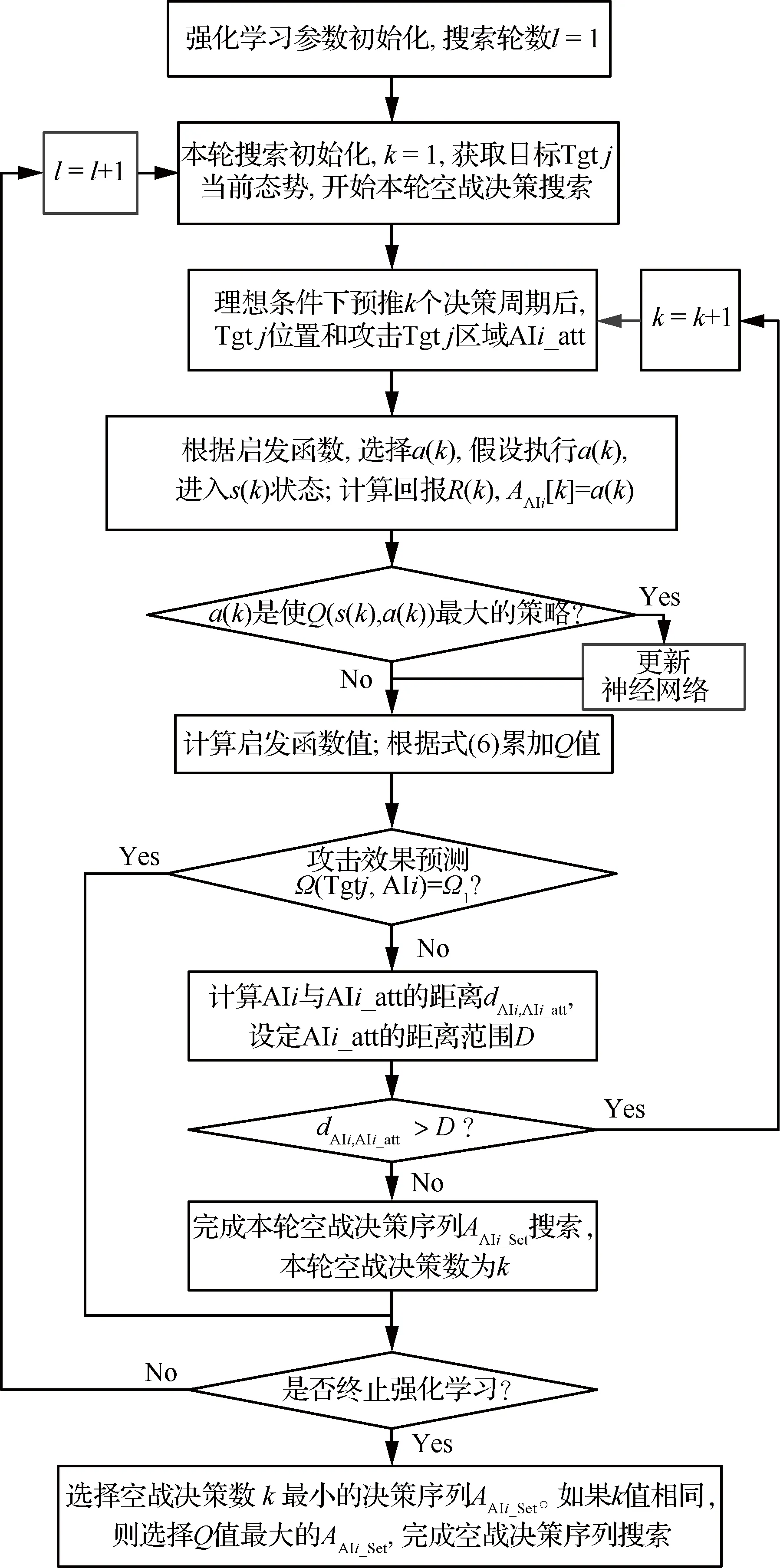
图11 启发式强化学习决策序列动态搜索Fig.11 Dynamic search in heuristic reinforcement learning algorithm
空战决策序列动态迭代搜索过程描述如下:
步骤1强化学习参数初始化,迭代轮数l=1。
步骤2获取目标机Tgtj的最新态势,开始一轮决策序列搜索,设本轮搜索记数k=1。
步骤3理想条件下,预推k个决策周期后,目标Tgtj的位置和攻击Tgtj的区域AIi_att。
步骤4根据启发函数值,选择a(k),执行a(k),进入s(k)状态,预测获得即时回报R(k),AAIi[k] =a(k)。
步骤5如果a(k)是使Q(s(k),a(k))最大的策略,说明是攻击效果预测最佳的样本,对负责启发函数值的神经网络进行训练,并更新网络结构。
步骤6根据式(6),累加计算Q值。
步骤7采用攻击效果预测模型预测a(k)的攻击效果,如果存在Ω(Tgtj,AIi)=Ω1的情况,需要判断是否进入下一轮搜索,如果需要则回到步骤2,开始下一轮决策序列的搜索如果不存在Ω(Tgtj,AIi)=Ω1的情况,则进入步骤9。
步骤8计算AAIi与区域AIi_att的距离,如果小于攻击距离D或达到设定的最大搜索步数,则完成本轮决策序列搜索;反之,则k=k+1,回到步骤3,进行下一步空战决策的搜索。
步骤9判断是否如果达到强化学习终止条件,如果没有则回到步骤2。
步骤10结束搜索,取空战决策数k最小的空战决策序列。在k值相同的情况下,取Q值最大的空战决策序列,替换正在执行的空战决策序列。
4 仿真实验
设空战决策周期为2 s,战术执行周期为6 s,强化学习的折扣因子γ=0.95,神经网络的学习率η=0.1,启发因子λ=0.85。样本量为20 000的空战结果数据,对agent离线训练15 000次,由初始阶段转入相对高级阶段。二对四是典型的现代编队空战样式,因此本文以二对四为例,对整个空战决策过程进行仿真。
红方编队4架为相对高级阶段的agent,蓝方双机编队仍为初始阶段的agent,但蓝方的空空武器作用距离为红方的1.2倍。初始时刻,双方的高度均为10 000 m,迎头进入,从空战态势上,空战双方是平等的。
4.1 空战决策过程仿真
编队决策仿真起始时间为K=0 s,空战决策仿真过程持续342 s,共57个战术执行周期。
初始态势:红方四机编队(AI3,AI4,AI5,AI6),蓝方双机编队(AI1,AI2)相距100 km,相向(迎头)进入。
阶段1K=0 s,红方编队保持原有队形进入;蓝方发现红方编队,进行目标分配。

图12 阶段2(蓝方编队:目标分配,红方编队:战术机动)Fig.12 Phase 2 (blue formation:Target assignment; red formation:Tactics maneuvering)
阶段2如图12所示。K=36 s,红方编队发现被蓝方跟踪,根据对AI1、AI2威胁程度的计算结果,进行第1次目标分配,AI4、AI5和AI6的攻击目标为AI1,AI3的攻击目标为AI2。AI6攻击AI1的区域为AI1的左后侧,AI5攻击AI1的区域为AI1的正前方,AI4攻击AI1的区域为AI1的右后侧,AI3攻击AI1的区域为AI2的右后侧。AI3开始向南机动,AI6开始向北机动,开始获取战术优势;AI1和AI2保持进入态势;蓝方AI1跟踪AI5,AI2跟踪AI4。
阶段3如图13所示。K=138 s,AI5被迫进入AI1的Ω2区域,选择回转机动,AI3、AI4和AI6根据需要到达的攻击目标区域,进行机动。AI1发现AI5进入到Ω2区域,发射武器攻击AI5,并对AI5保持尾追的攻击态势,AI2的攻击目标为AI3。

图13 阶段3(红方编队:目标分配)Fig.13 Phase 3 (red formation:Target assignment)
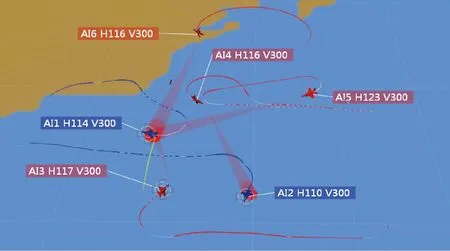
图14 阶段4(红方编队:合围蓝方AI1)Fig.14 Phase 4 (red formation:Attack AI1)
阶段4如图14所示。K=210 s,AI5回转机动摆脱了AI1发射武器的攻击,由于态势发生变化,红方进行第2次目标分配,AI3、AI5和AI6的聚类攻击目标为AI1,AI4攻击目标为AI2。AI1对AI5发射武器后,开始攻击新目标,但已经进入了AI3、AI5和AI6的合围当中,并在AI3的Ω1区域内,AI3对AI1获取较大战术优势,发射武器攻击AI1,根据弹道仿真的结果,判定为命中目标,完成对AI1的攻击,AI1停止决策仿真(用×标明);在AI1正在被围攻时,AI2回援AI1,AI2的攻击目标为AI3。
阶段5如图15所示。K=342 s,红方AI3、AI5和AI6完成对AI1的攻击后,编队进行第3次目标分配,红方编队的攻击目标都为AI2; AI1已被命中;AI2保持对AI3攻击态势,但很快陷入AI3、AI4、AI5和AI6的合围;AI2进入AI5的Ω1区域,AI5对AI2构成较大的战术优势,并对其发射武器,根据弹道仿真的结果判定为命中目标,结束整个二对四空战决策过程仿真。

图15 阶段5(红方编队:合围蓝方AI2)Fig.15 Phase 5 (red formation:Attack AI2)
4.2 攻击效果预测分析
agent初级阶段与相对高级阶段最大的区别在于攻击效果预测的准确度,即预测agent会不会进入目标的Ω1或Ω2区域,目标会不会进入agent的Ω1或Ω2区域。从图16可以看出蓝方编队对目标(红方)的威胁程度预测结果变化比较大,不稳定,且与实际情况相差较大。
从图17可以看出红方编队对目标(蓝方)的威胁程度预测结果比较稳定,说明经过训练后相对高级阶段的agent的攻击效果预测更准确。

图16 蓝方编队预测红方编队威胁程度Fig.16 Blue formation predict threaten degree of red formation
4.3 决策序列执行分析
蓝方编队的空战决策序列执行情况如图16所示,从中可以看出蓝方编队的决策序列变化较快,是因为在初级阶段缺少样本与训练的情况下,对攻击效果预测不够准确,导致空战决策序列没有在战术执行周期内完成计算。
红方编队的决策序列执行情况如图18所示,
从图18可看出红方编队AI3、AI4、AI5和AI6执行的空战决策序列相对连续,是因为相对高级阶段的agent经过训练后可对攻击效果预测更加准确,战术意图也十分明显,并最终获得空战的胜利。说明经过训练后相对高级阶段的agent,空战决策智能度更高。
4.4 决策序列计算时间分析
设置相同的仿真初始条件进行一个相对简单的仿真,是为了计算该条件下获取相对较优的决策序列所需要搜索步数,如图19中红方僚机机动轨迹所示。实验得出在这种态势获取相对较优解的搜索步数为210。
因此本文设置每轮强化学习最大搜索步数为500,即机动策略空间为5500。随着双机距离的接近,获取相对较优解的搜索步数会逐步减少,机动策略空间也会成指数减少。当一轮搜索步数超过500步时,则停止本轮搜索,开始下一轮搜索。设战术执行周期内搜索最多不超过50轮,同时记录这50轮搜索中最小的搜索次数,如图20所示。

图20 双方相对较优空战决策序列搜索步数Fig.20 Steps to search relatively better air combat decision sequence for both formations
启发式分层强化学习的空战决策序列搜索中,记录每轮获得相对更优的空战决策序列,最少的搜索步数如图20所示。图19中AI3、AI4、AI5和AI6在前6个战术执行周期和初始空战决策序列的搜索过程中,完成攻击效果预测好的训练样本积累,并对计算启发函数V值的神经网络进行训练。后续搜索到相对较优的空战决策周期所需的步数下降很快,说明神经网络有效启发了agent强化学习的搜索过程,提高了搜索效率,并随着空战态势的接近进一步减少了搜索步数。AI1和AI2由于训练样本与次数不够,在相对复杂的空战态势下攻击效果预测不够准确,导致空战决策搜索过程不会持续收敛,不同程度上有发散的情况,进一步说明训练可提高agent的空战决策序列的搜索计算速度。
4.5 agent鲁棒性分析
agent在决策仿真过程中相对独立,且在同一时刻一个agent只能攻击一个目标,理论分析空战飞机数量的增加不会对agent产生较大的影响。随着目标数量的增加,会增加空战结果预测的计算量,但不足以影响agent的决策效率。因此agent具有较强的鲁棒性。
agent学习的空战训练结果数据和实际决策仿真应用中判定攻击结果是否有效,都是采用相同的原则、基于相同的空空导弹仿真模型进行计算判定,确保学习与实际应用的基本条件是相同的。
5 结 论
本文通过二对四典型空战样式进行决策仿真,对比分析初始阶段和相对高级阶段agent的空战决策情况,实验结果说明经过训练后agent,智能性与实效性更高,与实际情况更相符;同时也说明基于神经网络的攻击效果预测方法对空战决策的强化学习过程具有很好启发性,明显提高了决策序列计算效率。下一步还需要针对不同空战态势和不同数量agent等多种情况,进行广泛的仿真验证。
[1] NICHOLAS E, DAVID C, COREY S, et al. Genetic fuzzy based artificial intelligence for unmanned combat aerial vehicle control in simulated air combat missions[J]. Journal of Defense Management, 2016, 6(1): 1-7.
[2] YIN Y, GONG G, HAN L. An approach to pilot air-combat behavior assessment[J]. Procedia Engineering, 2011, 15: 4036-4040.
[3] 傅莉, 谢福怀. 基于滚动时域的无人机空战决策专家系统[J]. 北京航空航天大学学报, 2015, 41(11): 1994-1999.
FU L, XIE F H. Real-time path planning to track moving target in complex environment for UAV[J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(11): 1994-1999 (in Chinese).
[4] 傅莉, 王晓光. 无人战机近距空战微分对策建模研究[J]. 兵工学报, 2012, 33(10): 1210-1216.
FU L, WANG X G. Research on close air combat modeling of differential games for unmanned combat air vehicles[J]. Acta Armamentarii, 2012, 33(10): 1210-1216 (in Chinese).
[5] SU M C, LAI S C. A new approach to multi-aircraft air combat assignments[J]. Swarm and Evolutionary Computation, 2012(6): 39-46.
[6] 张涛, 于雷, 周中良, 等. 基于混合算法的空战机动决策[J]. 系统工程与电子技术, 2013, 35 (7): 1445-1450.
ZHANG T, YU L, ZHOU Z L, et al. Decision-making for air combat maneuvering based on hybrid algorithm[J]. Systems Engineering and Electronics, 2013, 35(7): 1445-1450 (in Chinese).
[7] 左家亮, 杨任农. 基于模糊聚类的近距空战决策过程与评估[J]. 航空学报, 2015, 36(5): 1650-1660.
ZUO J L, YANG R N. Reconstruction and evaluation of close air combat decision-making process based on fuzzy clustering[J]. Acta Aeronautica et Astronautica Sinica, 2015, 36(5): 1650-1660 (in Chinese).
[8] RUAN C W, ZHOU Z L. Task assignment under constraint of timing sequential for cooperative air combat[J]. Journal of Systems Engineering and Electronics, 2016, 27(4): 836-844.
[9] 康冰, 王曦辉, 刘富. 基于改进蚁群算法的搜索机器人路径规划[J]. 吉林大学学报(工学版), 2014, 44(4): 1062-1068.
KANG B, WANG X H, LIU F. Path planning of searching robot based on improved ant colony algorithm[J]. Journal of Jilin University (Engineering and Technology Edition), 2014, 44(4): 1062-1068 (in Chinese).
[10] 梁宵, 王宏伦, 曹梦磊, 等. 无人机复杂环境中跟踪运动目标的实时航路规划[J]. 北京航空航天大学学报, 2012, 38(9): 1129-1133.
LIANG X, WANG H L, CAO M L, et al. Real-time path planning to track moving target in complex environment for UAV[J]. Journal of Beijing University of Aeronautics and Astronautics, 2012, 38(9): 1129-1133 (in Chinese).
[11] SUTTON R S, BARTO A G. Introduction to reinforcement learning[M]. Cambridge: MIT Press, 1988.
[12] LIU C, XU X, HU D. Multi-objective reinforcement learning: A comprehensive overview[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Application and Reviews, 2013, 99(4): 1-13.
[13] 陈兴国, 俞扬. 强化学习及其在电脑围棋中的应用[J]. 自动化学报, 2016, 42(5): 685-695.
CHEN X G, YU Y. Reinforcement learning and its application to game of go[J]. Acta Automatica Sinica, 2016, 42(5): 685-695 (in Chinese).
[14] 薛羽, 庄毅. 基于启发式自适应离散差分进化算法的多UCAV协同干扰空战决策[J]. 航空学报, 2013, 34(2): 343-351.
XUE Y, ZHANG Y. Multiple UCAV cooperative jamming air combat decision making based on heuristic self-adaptive discrete differential algorithm[J]. Acta Aeronautica et Astronautica Sinca, 2013, 34(2): 343-351 (in Chinese).
[15] BIANCHI R A C, RIBEIRO C H C, COSTA A H R. Accelerating autonomous learning by using heuristic selection of actions[J]. Journal of Heuristics, 2008, 14(2): 135-168.
[16] DIETTERICH T G. Hierarchical reinforcement learning with the MAXQ value function decomposition[J]. Journal of Artificial Intelligence Research, 2000(13): 227-303.
[17] AUSTIN F, CARBONE G, FALCO M. Automated maneuvering during air-to-air combat:RE-742[R]. Bethpage, NY: Grumman Corporate Research Center,1990.
Intelligentdecision-makinginaircombatmaneuveringbasedonheuristicreinforcementlearning
ZUOJialiang1,*,YANGRennong1,ZHANGYing1,LIZhonglin2,WUMeng1
1.CollegeofAeronauticsandAstronauticEngineering,AirForceEngineeringUniversity,Xi’an710038,China2.AirForceRepresentativeOfficeinShanghaiandNanjingArea,Nanjing210007,China
Intelligentdecision-makingaircombatmaneuveringhasbeenaresearchhotspotallthetime.Currentresearchontheaircombatmainlyusesoptimizationtheoryandalgorithmoftraditionalartificialintelligencetocomputetheaircombatdecisionsequenceintherelativefixedenvironment.However,theprocessoftheaircombatisdynamicandthuscontainsmanyuncertainelements.Itisthusdifficulttoobtainthedecisionsequencethatistallywiththeactualconditionsoftheaircombatbyusingthetraditionaltheoreticalmethods.Anewmethodforintelligentdecision-makinginaircombatmaneuveringbasedonheuristicreinforcementlearningisproposedinthispaper.The“trialanderrorlearning”methodisadoptedtocomputetherelativebetteraircombatdecisionsequenceinthedynamicaircombat,andtheneuralnetworkisusedtolearntheprocessofthereinforcementlearningatthesametimetoaccumulateknowledgeandinspirethesearchprocessofthereinforcementlearning.Thesearchefficiencyisincreasedtoagreatextent,andreal-timedynamiccomputationofthedecisionsequenceduringtheaircombatisrealized.Experimentresultsindicatethatthedecisionsequenceconformstoactualconditions.
aircombatmaneuvering;intelligencedecision-making;heuristicreinforcementlearning;neuralnetwork;decisionsequence
2017-02-06;Revised2017-03-13;Accepted2017-04-12;Publishedonline2017-04-281648
URL:http://hkxb.buaa.edu.cn/CN/html/20171021.html
.E-mailjialnzuo@163.com
http://hkxb.buaa.edu.cnhkxb@buaa.edu.cn
10.7527/S1000-6893.2017.321168
V323
A
1000-6893(2017)10-321168-14
2017-02-06;退修日期2017-03-13;录用日期2017-04-12;< class="emphasis_bold">网络出版时间
时间:2017-04-281628
http://hkxb.buaa.edu.cn/CN/html/20171021.html
.E-mailjialnzuo@163.com
左家亮,杨任农,张滢,等.基于启发式强化学习的空战机动智能决策J.航空学报,2017,38(10):321168.ZUOJL,YANGRN,ZHANGY,etal.Intelligentdecision-makinginaircombatmaneuveringbasedonheuristicreinforcementlearningJ.ActaAeronauticaetAstronauticaSinica,2017,38(10):321168.
(责任编辑:苏磊)
猜你喜欢
小学生学习指导·高年级(2023年8期)2023-11-19 05:33:56
小哥白尼(军事科学)(2022年1期)2022-04-26 14:02:40
装备制造技术(2020年3期)2020-12-25 05:21:52
当代陕西(2019年12期)2019-07-12 09:12:02
汉语世界(The World of Chinese)(2019年1期)2019-03-18 01:50:16
军营文化天地(2017年6期)2017-06-28 11:30:09
百科探秘·航空航天(2015年10期)2015-11-07 07:05:14
小哥白尼·军事科学画报(2014年8期)2015-04-07 03:54:50
棋艺(2014年3期)2014-05-29 14:27:14
棋艺(2009年8期)2009-04-29 08:53:52
