
基于向量空间的文本聚类算法
2017-11-08 05:46山东青年政治学院
电子世界 2017年20期
山东青年政治学院 高 强
基于向量空间的文本聚类算法
山东青年政治学院 高 强
聚类是一种非监督学习,以k-means为例,簇心的选取是个非常随机的过程,导致k值相同的情况下聚类的结果每次都不一样,又不好取个平均,所以聚类的好坏很难被评价出来。文本聚类是将一个个文档由原有的自然语言文字信息转化成数学信息,以向量空间点的形式展现出来,通过计算那些点距离比较近来将那些点聚成一个簇,簇的中心叫做簇心。一个好的聚类要保证簇内点的距离尽量的近,但簇与簇之间的点要尽量的远。通过对数字信息的聚类,使所代表的文本内容产生分类的结果,并能一定程度的保证文本聚类结果的精度。
聚类;文本聚类;向量空间
一、引言
文本挖掘是随着web的兴起,而发展起来,就文本挖掘本身来说,它不仅是一门单纯的数据挖掘技术,更融合了机器学习、模式识别、人工智能、统计学、计算机语言学、计算机网络技术、信息学等多个领域。和数据挖掘一样,文本挖掘仍然强调发现隐含的知识信息,但两者仍有很大的不同,这种不同在于,和传统的数据挖掘处理的对象相比,文本挖掘所面对的是大量的、异构的、分布式的web信息,这些信息可以是多种文件类型、或多种文字、甚至是文字流媒体,因此是半结构化、非结构化的信息。
由于在浩如烟海的互联网信息中,80%的信息都是以文本形式存放的,因此对web的挖掘是当前文本挖掘的主要方向,自然语言处理所要面对的基本问题是:采用什么方法,把非结构化的问题转化为结构化或半结构化,以致于能利用成熟的数学模型去解决。文本的处理亦是如此,首先面对文本的结构和所包含的信息进行抽象,建立适合某种算法的模型,从而能代替文本信息本身,然后,能把抽象出来的结构和特征运用结构化的算法加以运算,,在这个过程中,要保证特征项能够满足原文本的维度,也就是说,在转化的过程中,要保证文本信息的特征不丢失,不损耗,在新的模型中,仍能够显示的、有差异性的表达。
要完成上述的过程,目前比较成熟的方法是将文本信息按照分词法和词频统计方法得到原文本的特征值,再将此特征值做进一步净化,再把最后得到的数据当成一个词频向量,打到一个向量空间里去进一步分析,有时为了使向量所表达的特征项维数不至于太高,在保证原文含义的基础上,找出对文本特征类别最具代表性的文本特征。为了解决这个问题,最有效的办法就是通过特征选择来降维。
二、文本特征向量
文本挖掘的研究重点集中到文本模型的表达和特征词的选取算法上,特定的挖掘算法对对象的特征项往往有比较严格和针对性要求,因此,在对文本数据做数据转化时,往往要考虑比较多的因素,一般来说,应注意以下几个方面:1)特征项要能够确实标识文本内容;2)特征项具有将目标文本与其他文本相区分的能力;3)特征项的个数不能太多;4)特征项分离要比较容易实现。
在分析完特征项选取的因素后,我们将考虑如何进行特征抽取,在中文文本中,我们更习惯于把词作为特征项抽取出来,这是因为,和字相比,词有更强的表达能力;和短语相比,词又更容易切分。这样,切分出来的作为文本特征的词,进一步抽象成为向量,用来实现文本之间的相似度的度量。而相似性度量算法方面又有很多选择,应用比较广泛的有:1)欧氏距离算法;2)余弦相似度算法;3)皮尔逊相关度。
至此,文本挖掘一般采用向量空间模型,用特征词条(T1,T2,…Tn) 及其权值Wi 代表目标信息,再用这些特征词条的向量进行相似度运算,运算结果显示文本的相关程度。特征词条和权重的选择在意过程中称作特征提取,提取方法的优劣直接影响到系统的运行。
设D为一个包含m个文档的文档集合,Di为第i个文档的特征向量,则有:
D={D1,D2,…,Dm}, Di=(di1,di2,…,din),i=1,2,…,m
其中dij(i=1,2,…,m;j=1,2,…,n)为文档Di中第j个词条tj的权值,它一般被定义为tj在Di中出现的频率tij的函数,例如采用TFIDF函数,即dij=tij*log(N/nj)其中,N是文档数据库中文档总数,nj是文档数据库含有词条tj的文档数目。假设用户给定的文档向量为Di,未知的文档向量为Dj,则两者的相似程度可用两向量的夹角余弦来度量,夹角越小说明相似度越高。
通过上述的向量空间模型,文本数据就转换成了计算机可以处理的结构化数据,两个文档之间的相似性问题转变成了两个向量之间的相似性问题。
三、文本聚类过程
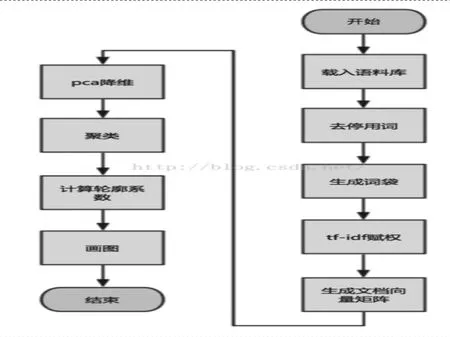
图1
图1所示的几个部分,一般生成文档向量矩阵的格式是,每一行代表一个文档,每一列是一个维度代表该文档这个词的权重,没出现这个词就是0,几千个文件维度在10多W左右(看文档的大小),矩阵将其稀疏,也就是说,在一个高维空间中,几千个点几乎都聚在了一起,虽说彼此之间有距离,但是距离非常之小,很明显这样聚类效果肯定非常差,实测过,跟抛硬币的概率一样。于是将矩阵稠密一点就想到了pca降维,pca是主成分分析的缩写,主要思想是取这个高维向量中方差最大的方向,经过一些数学变换将有用的部分保留,没用的部分舍弃,这种办法同样适合分类算法中寻找最显著的特征。该算法可以比较好的解决k-means每次聚类结果偏差太大的问题,相比dbscan有可以设置聚类的个数(当然阈值也可以设置),最重要的是sklearn有现成的库调用,速度还很快。
以上详细论述了文本挖掘的一般思路,但对于特征抽取时,选词如何确定,一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。这就是单词权重最为有效的实现方法就是TF*IDF。
它是由Salton在1988年提出的。其中TF 称为词频,用于计算该词描述文档内容的能力;IDF称为反文档频率,用于计算该词区分文档的能力。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词给予最小的权重,较常见的词给予较小的权重,较少见的词给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。因此,运用这一算法,我们可以很方便的提取出关键词作为向量的特征项。
四、结论
本文比较完整的论述了文本挖掘的技术细节,着重分析了特征词抽取、运用TF*IDF方法等文本挖掘必备环节,该方法对当前的web文档处理、分析都有广泛而深入的应用,可以说很多针对文本内容的挖掘算法,都是在向量空间基础上做进的一步开发,因此理解和运用这一方法对文本数据的处理有着重大的现实意义。
[1]孙爽,章勇.一种基于语义相似度的文本聚类算法[J].南京航空航天大学学报,2006.
[2]蒋旦,周文乐,朱明.基于语义和图的文本聚类算法研究[J].中文信息学报,2016.
[3]杜坤,刘怀亮,王帮金.基于语义相关度的中文文本聚类方法研究[J].情报理论与实践,2016.
高强,男,山东大学计算机科学与技术学院硕士研究生,山东青年政治学院信息工程学院讲师,研究领域包括数据库、数据挖掘、大数据的分布式存储等。
猜你喜欢
客联(2022年3期)2022-05-31
园林科技(2021年3期)2022-01-19
中国新闻周刊(2021年26期)2021-07-27
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
信息安全研究(2016年4期)2016-12-01
读者·校园版(2015年7期)2015-05-14
深圳大学学报(理工版)(2015年5期)2015-02-28
