
基于公共词块及N-gram模型的问句相似度算法
2017-11-04 03:45黄贤英龙姝言
重庆理工大学学报(自然科学) 2017年10期
黄贤英,谢 晋,龙姝言
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
基于公共词块及N-gram模型的问句相似度算法
黄贤英,谢 晋,龙姝言
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
问句相似度算法是问答系统的核心问题,直接影响着问答系统的准确性。针对公共词块算法(CCS)对于中文文本的不适用性,提出一种改进的问句相似度算法(CNS)。该方法结合N-gram模型及公共词块来计算问句向量的相似度,其主要思路是把问句分解成一元模型和二元模型,然后再分析问句之间的公共词块并考虑其顺序结构。实验结果表明:新算法在Top-N条数据集的平均相似度和不同相似度阈值下的准确率均优于常用的问句相似度算法。
问句相似度;N-gram模型;一元模型;公共词块
近年来,随着信息技术的飞速发展,智能问答(QA)领域吸引了大量的用户[1],问句相似度计算则成为了QA中最为关键的环节[2]。QA通过问句相似度计算来获取用户所要查询的内容与知识库中现有问题之间的关系,再通过合理的筛选答案候选集[3]自动给出用户满意答案[4-5]。
目前,问句相似度算法主要使用的是针对所有句子的相似度算法[6]。这种方法忽略问句的特殊句型结构,将问句视为短文本,利用常用的短文本处理方法来分析问句。首先对问句进行分词、词性标注、去停用词处理,为处理后的问句赋值权重,将其转换成向量化的形式,再使用相似度算法进行计算。文献[7]提出一种基于平均信息熵的中文问句关键词提取方法,其中心思想是通过计算问句中每个词的平均信息熵以更好地体现该词在问句中的重要性。但这种算法只考虑了单个词的贡献度,没有考虑到词语组合的贡献度。文献[8]提出一种改进的TFIDF问句相似度算法,对特征词进行聚类,并赋予其更高的权重,但这种算法需要有良好的分类语料库作为支撑。文献[9]考虑到了中文分词对相似度计算的影响,提出结合多种分词结果的相似度计算方式,但分词方式的改变会影响句子所包含的特征词。文献[10]考虑了公共特征词以及词序对于相似度计算的影响,但这种算法面向英文语料,对于中文语料有一定的约束性。
传统基于词项的文本相似度算法只考虑了词项因素,忽略了词序对短文本相似性的影响。本文为了将问句的词序纳入考量,引入了问句的公共词块信息。考虑到中文文本与英文文本的不同,本文同时引入N-gram模型,在考虑公共词块及其相关顺序的同时,也将汉语语言模型作为影响因子,提出一种在N-gram语言模型的基础上利用公共词块作为计算单元的问句相似度算法。
1 相关研究
1.1 问题定义及参数
本文将Q1和Q2定义为2个不同的问句,sw(Q1,Q2)为2个问句之间都出现的关键词个数,L(Qi)表示第i个问句中的关键词个数,如表1所示。其中,pwi(Q1)表示Q1中第i个关键词的权重,pwi(Q2)为Q2中第i个关键词的权重。Sim1(Q1,Q2)表示基于公共子序列的相似度,Sim2(Q1,Q2)表示基于关键词序的相似度。

表1 参数定义
1.2 公共词块的相似度算法
基于公共词块的相似度算法主要是将2个文本中所有连续出现的相同关键词看作1个词块单元,利用所有公共词块中的关键词计算重叠相似度,并考虑这些公共词块在2个文本中的出现顺序对短文本相似度的影响,做加权处理,以提高文本相似度计算的算法性能。它的主要工作流程为:首先,从2条需要进行相似度计算的问句中提取出共同出现的词项;然后,在2条问句挑选出的共同词项集合中,寻找2条问句都连续出现的共同词组,这个共现词组即为一个公共词块。
传统的基于公共子序列的相似度算法为保证2个短文本的相对相似度一致,相似度计算方法如式(1)所示:
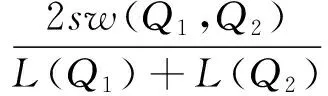
(1)
由于上述相似度算法未考虑公共关键词出现的顺序,文本相似度计算存在较大误差,因此需要考虑公共关键词的词序,相似度计算如下:
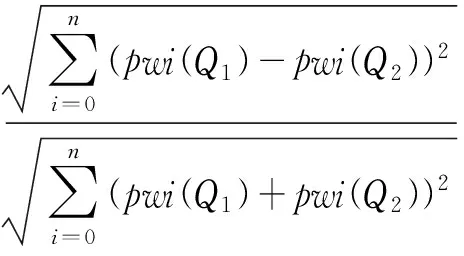
(2)
综合考虑最优子序列相似度计算方法与基于顺序的相似度计算方法,对式(1)和(2)做加权处理。文献[10]提出一种基于公共词块的相似度计算方法,如式(3)所示:
Sim(Q1,Q2)=α*Sim1(Q1,Q2)+
β*Sim2(Q1,Q2)
(3)
其中α+β=1。文献[10]详细解释了参数的取值。
2基于公共词块及N-gram模型的问句相似度算法
N-gram语言模型是一种基于统计的文本模型,其算法的基本思想是将文本内容按字节流进行大小为N的滑动窗口操作,形成长度为N的字节片断序列,每个字节片断被称为gram。对全部gram的出现频度进行统计,并按照事先设定的阈值进行过滤,形成关键gram列表,即为该文本内容的特征向量空间,列表中每一种gram均为一个特征向量维度[12]。因此,在处理中文语料时,使用N-gram模型不需要对文本内容进行语言学处理,也不需要构建词典和规则,能避免中文文本分词过程中的数据缺失,可有效保留特征项之间的关系。
在中文文本中应用公共词块的相似度算法,由于时常会存在检测不到公共词块的问题,因此会影响相似度的计算。例如:通过中文分词得到{飞机场}和{飞机},这2个词项相似度很高,但他们不属于公共词块,因此忽略了二者之间的相似关系。针对这一问题,本文提出了基于公共词块及N-gram模型的问句相似度算法,综合考虑了中文文本一元模型和二元模型表示时的作用各不相同的情况,通过结合一元模型及二元模型作为特征来表示问句,并融合问句之间的公共词块共同表征问句相似度,以提高相似度计算的准确率。
首先,对于需要进行相似度计算的2条问句Q1和Q2,使用中科院分词工具ICTCLAS进行一元模型及二元模型表示。示例如下:
Q1:院长您好,我想请问如何重修物理?
一元模型表示Q1-U:院,长,您,好,我,想,请,问,如,何,重,修,物,理
二元模型表示Q1-B:院长,您好,我想,请问,如何,重修,物理
Q2:院长,办理物理重修需要哪些手续?
一元模型表示Q2-U:院,长,办,理,物,理,重,修,需,要,哪,些,手,续
二元模型表示Q2-B:院长,办理,物理,重修,需要,哪些,手续
将每组问句以一元模型及二元模型的形式表示出来,分别查询一元模型及二元模型中的公共词块。上述例子通过检测可以得到:Q1-U与Q2-U的公共词块集合为{{院},{长},{重},{修},{物},{理}};Q1-B和Q2-B的公共词块集合为{{院长},{重修},{物理}}。然后,将其应用到相似度计算式(3),得到Sim(Q1-U,Q2-U)以及Sim(Q1-B,Q2-B),分别表示利用一元模型和二元模型表示的问句相似度值。对得到的两个相似度进行加权处理,如式(4)所示:
Sim-T(Q1,Q2)=λ×Sim(Q1-U,Q2-U)+
(1-λ)×Sim(Q1-B,Q2-B)
(4)
其中:Sim-T(Q1,Q2)表示问句Q1和Q2的整体相似度;λ和1-λ表示一元模型和二元模型相似度值的比率,经多次调整参数值发现,其取值的变化对结果影响不大,因此设置参数值为0.5。
3 实验与分析
3.1 实验数据
实验数据来自重庆理工大学计算机学院院长信箱(“http://cs.cqut.edu.cn/ DeanMail/MailList.aspx”),选取了“2014年4月1日—2017年4月1日”共6 129条数据,并清洗掉无文字的数据(数据中存在一些由特殊符号或表情组成的无法识别的信息)。数据格式如表2所示。
3.2 实验评价标准
实验评价标准分为3部分:第1部分为不同数据集数目时相似度平均值的比较;第2部分为不同相似度阈值下的准确率比较;第3部分为不同相似度阈值下的召回率比较。

(5)


(6)
3.3 实验结果
选取表2中学生所提出的问题内容和问题回复这2项作为相似度计算的对比数据集,同时选取3种常规算法进行对比试验。
算法1:余弦相似度算法
算法2:最长公共子序列算法
算法3:基于公共词块的相似度算法
表3直观地反映出当前N条数据作为数据集时,4种算法的相似度平均值。由实验结果可以看出:算法1的相似度平均值保持在0.09~0.11;算法2的相似度平均值保持在0.08~0.09;算法3的相似度平均值保持在0.20~0.22;而本文算法的相似度平均值高于前3个算法,保持在0.36~0.41附近。
在表4中,分别比较算法1、算法2、算法3以及本文算法在不同相似度阈值下的准确率。各算法在不同相似度阈值下的准确率对比如图1所示。
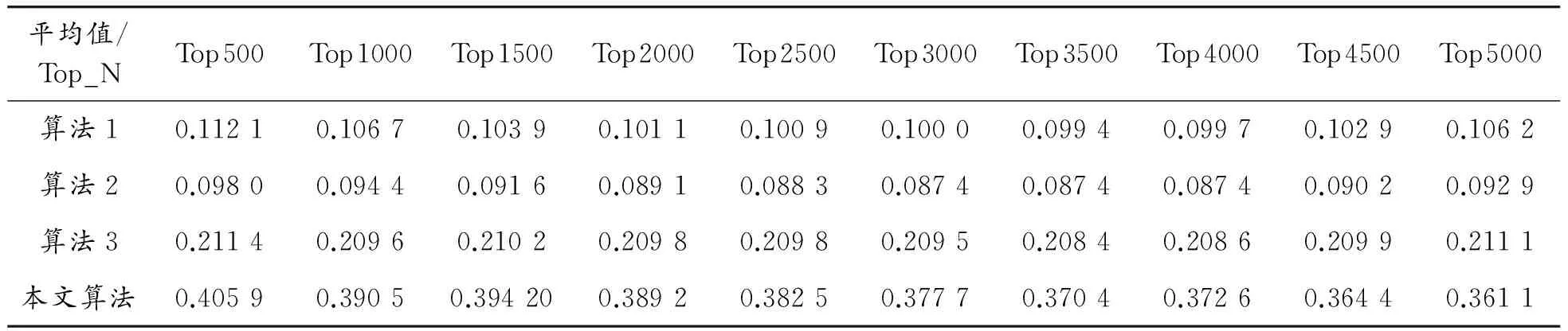
表3 各算法在不同数据集数目时的相似度平均值

表4 各算法在不同相似度阈值下的准确率
从图1可以看出:算法1即使在较小的阈值下准确率依然偏低;算法3及本文算法的准确率明显高于前两种算法,但算法3的准确率在不同阈值下的波动性偏大,当阈值大于0.19时,其准确率骤减;本文算法相比其他算法,在准确率及稳定性方面均有提高。从图2可以看出:算法1的召回率低于其他方法;当相似度阈值低于0.1时,算法2、算法3和本文算法的召回率基本接近100%;当相似度阈值大于0.3时,本文算法的召回率最大,算法2 和算法3 的召回率基本相同,其中算法3略大于算法2。
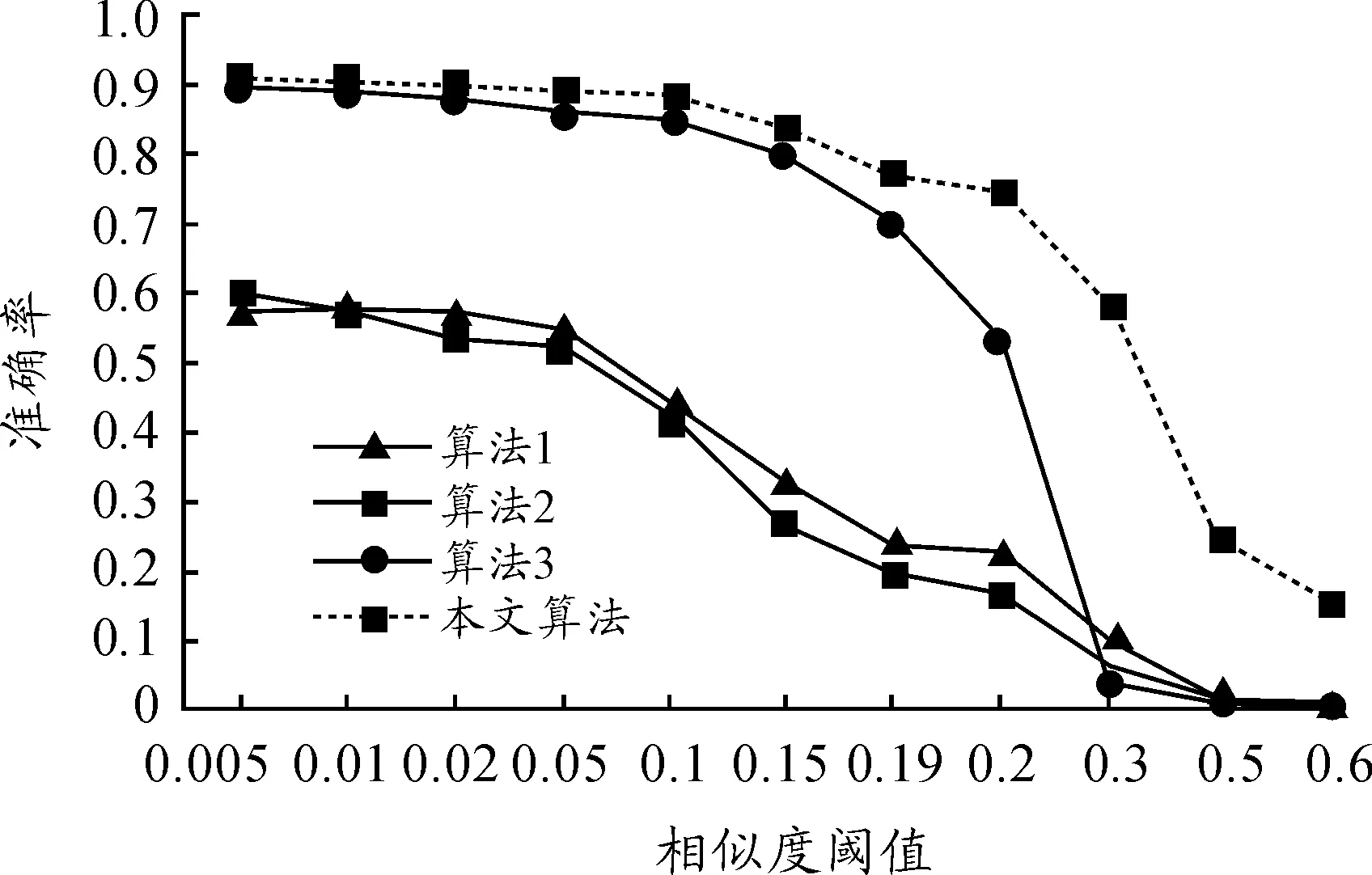
图1 各算法在不同相似度阈值下的准确率对比
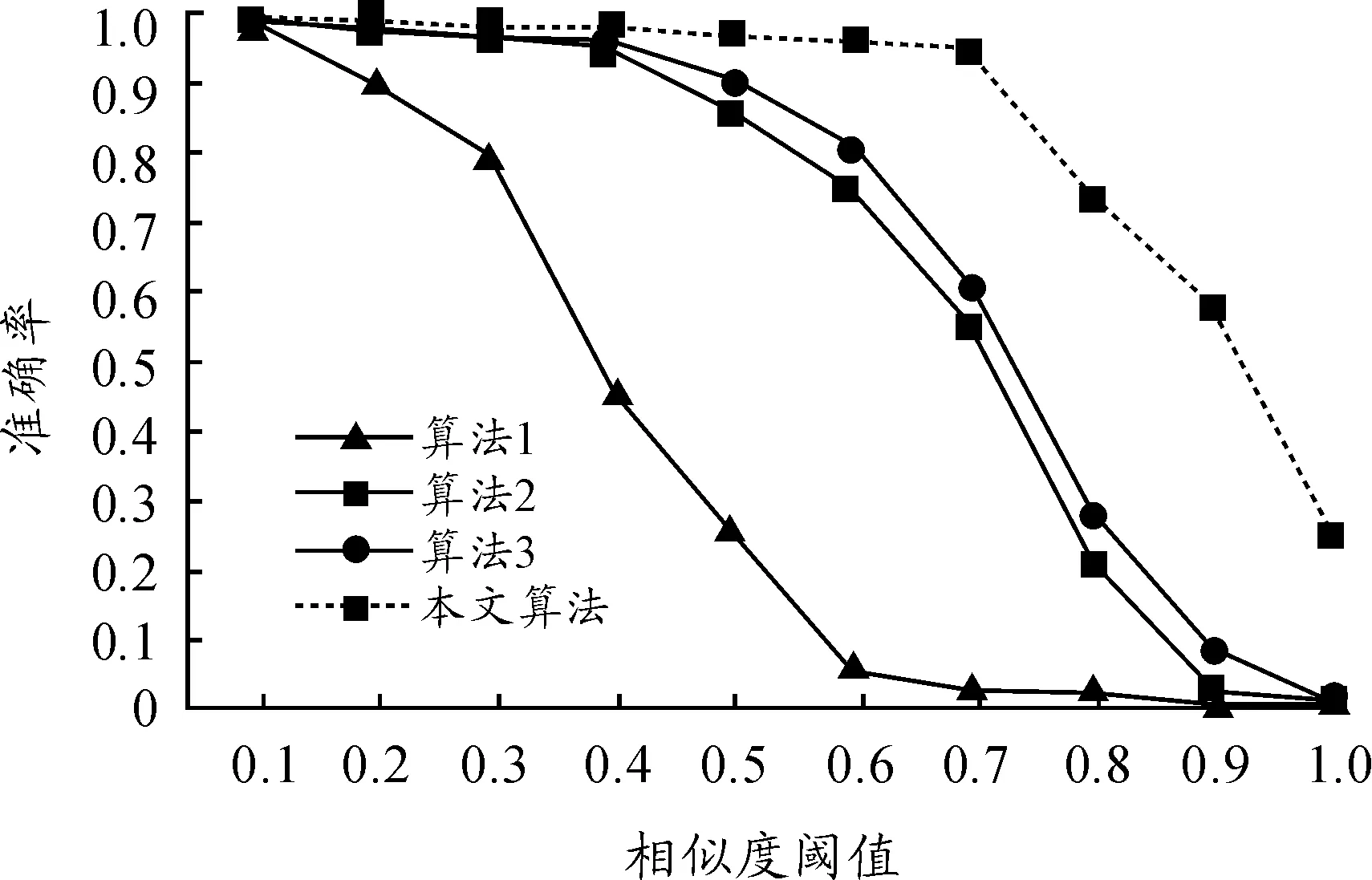
图2 各算法在不同相似度阈值下的召回率对比
3.4 结果分析
本文在实验部分主要比较了基于词项的余弦相似度算法、基于词项的最长公共子序列相似度算法、基于公共词块的相似度算法以及本文算法。
基于词项的余弦相似度算法只集中于独立词项的相同数量关系,未考虑词项间的词序关系,虽然相似度均值较大,召回率较低。基于词项的最长公共子序列相似度算法集中于句子对间的最长公共子序列,考虑了词序信息,但仅提取部分共现词,相似度均值不高。基于公共词块的相似度算法加入了公共词块信息,考虑词序关系影响,通过对句子中共现词的数量自动调整加权系数,但在使用中文分词器划分公共词块时存在较大的误差,会导致错分或漏分。本文算法既考虑了共现词的词项信息,又兼顾了词项间的词序信息,并将N-gram模型融入算法,改善了划分公共词块的准确性,得到了较高的相似度均值,同时具有较好的稳定性。
4 结束语
本文针对基于最优公共子序列和利用公共词块计算中文文本相似度时存在的缺陷,提出一种结合N-gram模型及公共词块的新方法。这种方法既考虑了中文文本在寻找公共词块时的稀疏性,又加大了词块之间的相似性,从而避免了因该词项未被公共词块收录而出现较大实验误差的情况。在实验部分对比了本文算法和其他3种相似度计算方法。实验结果表明:本文算法在相似度平均值以及相似度准确率方面有良好的表现。本文算法的不足之处是:在表示问句文本时并未考虑语义信息,因此在今后的研究中将考虑同义词项的重要性以及问句的语义相似度。
[1] AMIRI H,RESNIK P,BOYD G J,et al.Learning Text Pair Similarity with Context-sensitive Autoencoders[C]//Meeting of the Association for Computational Linguistics. Germany:[s.n.],2016:1882-1892.
[2] GAIZAUSKAS R,HUMPHREYS K.A Combined IR/NLP Approach to Question Answering Against Large Text Collections[C]//Proceedings of the 6th Content-based Multimedia Information Access(RlAO-2000).France:[s.n.],2000.
[3] VOORHEES E.The TREC-8 Question Answering TrackReport[C]//Proceedings of the Eighth Text Retrieval Conference(TREC 2002).USA:[s.n.],2002.
[4] POONAM G,VISHAI G.A Survey of Text Question Answering Techniques[J],International Journal of Computer Applications,2013,53(4):1-8.
[5] MATTHEW W B,ERIC N.Improving Text Retrieval Precision and Answer Accuracy in Question Answering Systems[C]//Proceedings of the 2nd workshop onInformation Retrieval for Question Answering(Coling 2008),Manchester.UK:[s.n.],2008:1-8.
[6] 徐海洲.自动问答系统中问句相似度计算方法研究[D].南昌:华东交通大学,2014.
[7] 丁菲菲,杨思春,刘仁金.基于平均信息熵的中文问句关键词提取[J].皖西学院学报,2014(5):46-49.
[8] 李吉月.中文社区问答系统中问题检索技术研究[D].北京:北京理工大学,2016.
[9] JIANG R,KIM S,BANCHS R E,et al.Towards improving the performance of Vector Space Model for Chinese Frequently Asked Question Answering[C]//International Conference on Asian Language Processing.China:IEEE,2015:136-139.
[10] 黄贤英,刘英涛,饶勤菲.一种基于公共词块的英文短文本相似度算法[J].重庆理工大学学报(自然科学),2015,29(8):88-93.
[11] SEVERYN A,NICOSIA M,MOSCHITTI A.Learning Semantic Textual Similarity with Structural Representations[C]//51st Annual Meeting of the Association for Computational Linguistics.Bulgaria:[s.n.],2013:714-718.
[12] 于津凯,王映雪,陈怀楚.一种基于N-Gram改进的文本特征提取算法[J].图书情报工作,2004,48(8):48-50.
(责任编辑杨黎丽)
QuestionSimilarityAlgorithmBasedonCommonChunksandN-GramModel
HUANG Xianying, XIE Jin, LONG Shuyan
(College of Computer Science and Engineering, Chongqing University of Technology, Chongqing 400054, China)
Question similarity algorithm is the key problem of QA, which directly affects the accuracy of QA. Aiming at the non applicability of the common chunks similarity algorithm (CCS) to Chinese text, an improved question similarity algorithm (CNS) is proposed, which combines the N-gram model and the common chunks to compute the similarity of the question vectors. The main idea is to break the question into unigram model and bigram model, then to analyze the common chunks between the questions and consider their sequential structure. Experimental results show that the new algorithm is better than the commonly used question similarity algorithms in the average similarity of Top-N data sets and the accuracy of different similarity threshold.
question similarity; N-gram model; unigram model; common chunks
2017-02-25
教育部人文社科青年项目(16YJC860010),重庆市社会科学规划博士项目(2015BS059)
黄贤英(1967—),女,重庆人,教授,硕士生导师,主要从事信息检索、移动计算研究,E-mail:hxy@cqut.edu.cn;谢晋(1993—),男,湖北十堰人,硕士研究生,主要从事信息检索、文本挖掘研究,E-mail: 895309382@qq.com。
黄贤英,谢晋,龙姝言.基于公共词块及N-gram模型的问句相似度算法[J].重庆理工大学学报(自然科学),2017(10):175-179,197.
formatHUANG Xianying, XIE Jin, LONG Shuyan.Question Similarity Algorithm Based on Common Chunks and N-Gram Model[J].Journal of Chongqing University of Technology(Natural Science),2017(10):175-179,197.
10.3969/j.issn.1674-8425(z).2017.10.028
TP391.1
A
1674-8425(2017)10-0175-05
猜你喜欢
苏州科技大学学报(社会科学版)(2022年5期)2022-03-15
孩子(2019年12期)2019-12-27
哲学评论(2018年1期)2018-09-14
广东教育·综合(2017年7期)2017-07-27
心理与行为研究(2016年4期)2016-12-16
新课程研究(2016年1期)2016-12-01
北方文学·中旬(2016年6期)2016-08-01
湖南工业职业技术学院学报(2016年6期)2016-04-17
中学生英语(2015年48期)2015-08-15
江西教育C(2015年4期)2015-05-25
