
分布式检索在异构科技信息资源中的应用及优化
2017-11-01 17:14刘应波文若瑾陈亚杰
计算机应用与软件 2017年10期
李 城 童 彬 刘应波,* 邬 平 王 锋, 文若瑾 陈亚杰
1(昆明理工大学云南省计算机技术应用重点实验室 云南 昆明 650504)
2(云南省科学技术情报研究院 云南 昆明 650500)
分布式检索在异构科技信息资源中的应用及优化
李 城1童 彬1刘应波1,2*邬 平2王 锋1,2文若瑾2陈亚杰1
1(昆明理工大学云南省计算机技术应用重点实验室 云南 昆明 650504)
2(云南省科学技术情报研究院 云南 昆明 650500)
为解决使用传统集中式检索处理海量异构科技信息资源时存在单点故障、性能低、不易扩展等问题,提出一种在异构科技资源下应用的分布式高性能检索系统(DHRS),并对其核心技术进行重点研究和分析。针对检索结果资源访问开销大的问题,给出基于访问代价的评估算法。并结合实际应用场景对算法进行优化,优化后请求数减少了80%,实验环境下的性能平均提高了68%。同时通过真实数据集的测试,验证了DHRS检索海量科技资源的可行性,能够适用于对检索和扩展性能要求较高的场景。
科技资源 分布式检索 海量数据 ElasticSearch 异构资源
0 引 言
科技资源主要是指科技知识信息资源,既包括各种电子或纸质的中外文期刊、杂志、报纸、论文、专利、标准等,也包括一些可发布的科研成果表格、视频、图形图像数据等。近十年来,互联网技术的飞速发展使科技资源呈爆炸式增长,科技资源的检索模式也转向了“浏览-检索”模式[1],对大数据网络环境下的科技资源进行有效的检索和管理,提高科技资源的利用率成为了领域内研究的重点。
检索技术是科技资源管理服务的核心,目前常用的专用检索系统和搜索引擎,其起步之初都是以集中式的组织架构和检索技术来实现资源检索的。通常认为第一代搜索引擎便是以集中式检索为主要特征。这种集中式的检索方式资源覆盖面较窄,资源更新和维护比较困难,检索速度也比较缓慢。而且,集中式的检索方式在应对专业度和性能都要求较高的科技资源检索时,无法达到预期的要求。此外,集中式的检索方式还存在着中心节点失效的致命缺点。集中式检索的其他不足和问题参见文献[1]。
分布式检索技术克服了集中式检索的不足,在分布的环境下使用多个中小型搜索引擎协作的分布式工作方式[2-3],可以改善传统集中式搜索引擎更新和检索速度较慢的问题,以便满足广大用户的需求。分布式技术的性能优势使得它在信息资源的检索中得到了广泛的研究与应用[4-8]。同时,以分布式技术为基础的云计算[9]推动了检索技术的发展。例如:万方的RMSCloud[10-12]云搜索引擎、清华大学的网络指南针联邦搜索引擎[3]都已成功应用了分布式的检索方式。
当前,科技资源存在异构性、海量性、分布性等特点。由于其物理存储体系、存储系统、存储管理机制、存储地域、存储载体、保存方式以及存储逻辑模型的不同,导致了科技资源存在着异构性。同时,随着信息获取手段的提高以及网络技术的飞速发展,科技资源在这些技术手段的推动下正在高速增长,呈现出海量增长的趋势。另一方面,各个研究机构和高校自身拥有庞大的科技资源,这些资源存在着交叉重叠,本身具有分布的特征。对具有如上特征的科技资源进行整合,提供统一、高效、精确的检索服务是一项具有挑战性的工作[13]。
1 分布式搜索引擎
当前主流的分布式搜索引擎有Solr、Solandra、SolrCloud、Solr+Katta、Elasticsearch等。Solr是由Java开发,基于Lucene的分布式搜索引擎,提供了webserver样式的编程接口,由于其使用范围广,比较成熟,故能很快速、方便地部署。Solandra是一个基于Solr和nosql数据库的Cassandra的分布式引擎。Cassandra是facebook开源的数据库,是基于列结构的非关系型数据库。其有个重要的特性是对外没有中心节点,所以不存在单点故障问题,倘若主节点挂掉了,剩余节点会自动投票,再次选出主节点。SolrCloud是一个基于Solr的开源项目,使用Zookeeper进行节点通信管理,提供索引分片功能,是一个实时的搜索引擎。Solr+Katta是一个分布式索引建立和管理工具,底层是Hadoop的HDFS分布式文件系统,具备拓展和容错机制,准实时的搜索方案。
以上调研我们可以看到,当前搜索引擎主要是Solr演化版本以及本文重点讲的ElasticSearch。二者都是基于Lucence平台。Solr相较于ElasticSearch,是最流行的企业级搜索引擎,拥有更大、更加成熟的用户、开发和贡献者社区,支持添加多种格式的索引,并且从技术角度讲,其更加的成熟、稳定,在传统的搜索应用中表现好于ElasticSearch。但如果考虑到实时性问题时,ElasticSearch具有优势。
弹性搜索(ElasticSearch-ES)是一个基于Lucene[16]的开源的分布式搜索引擎,可以提供实时、稳定、可靠的搜索。它是从弹性网络演化而来,继承了弹性网络的思想,使用弹性搜索的方法进行检索可以大大降低时间复杂度。ES的一个重要的优势在于它的高可用性、易扩展性以及近实时性,其高可用性和易扩展性都来源于其强大的分布式支持[17]。
目前,对于科技资源检索这一领域来说,ES从2010年诞生[15]到现在,国内外几乎没有任何关于ES在科技资源检索领域的研究文献。虽然在全文检索需求时ES已经对分布式资源提供了通用的检索支持,但是,由于科技资源本身分布、异构、海量和其领域特性,使用ES进行分布式异构科技资源的检索还存在着很多限制。例如,需要在ES检索接口的基础上研究并开发面向科技资源的检索接口,来满足这一领域规范的检索需求。对于ES目前不支持的数据资源的导入,还需要在其基础上扩展更多针对科技资源的数据适配器,并且需要对科技资源检索结果中重复的数据资源进行特殊处理等。
2 基于ES的分布式异构检索系统
为实现科技资源文献的高性能检索,解决科技资源检索在其异构性、海量性和分布性方面存在的不足,设计并实现了基于ES的分布式异构检索系统(DHRS),以满足当前分布式异构科技资源的检索需求。DHRS系统的主体框架如图1所示。

图1 DHRS系统的框架图
其核心组件主要由查询解析系统、索引构建、适配系统、索引检索系统以及检索结果处理系统各部分构成。由于分布式异构检索引擎基于ES,所以详细的ES引擎部分参看文献[14-15]。除此之外,该系统的三大子系统(异构数据源适配器、查询解析、结果处理)将在下文中进行介绍。
2.1 异构数据源适配器
当前,科技资源最常用的数据存储载体是数据库和文件系统,随着数据量的增大,一些非关系型数据库也引入到科技资源的存储应用中。想要有效构建这些不同数据资源的索引,就要求我们为其提供统一的异构数据源适配器。在ES中可以根据它所提供的River机制来进行不同异构数据源的数据访问,目前主要能够访问关系型数据库、非关系型数据库如CouchDB和文件系统等。
对于当前科技资源的存储来说,关系型数据库还是主流的科技资源存储的数据管理工具,科技资源数据位于不同的异构数据库上。为了支持统一的异构数据资源检索,需要为所有异构关系型数据库上的数据资源构建索引。因此,研究过程中,采用并发的ES插件机制来实现从关系型数据库中提取索引信息。ES没有提供直接访问关系型数据库的接口,所以,本文主要通过使用JDBC的River插件来完成索引信息的构建工作。
2.2 查询解析系统
由于科技资源本身具有特定的数据存储约束,则相对应的查询方式也具有这个领域的独特特征,所以对此特殊查询方式的规范处理便构成了整个检索系统不可或缺的部分。以科技文献信息资源为例,目前,国内外期刊、文献、会议检索系统等都可以使用多种方式进行检索,归纳起来主要有三种:简单查询、高级查询和专业化查询。专业查询是本文研究的重点,它可以很容易地实现前两种查询。专业查询是对用户要求较高的一种查询方式,国内的万方和CNKI都提供了类似的功能,采用了CQL或类似CQL的查询语言。专业查询中,系统要求用户输入规范的查询语句,并会为用户提供可检索字段,用户必须严格按照系统提供的检索字段进行检索,而不能在系统提供的检索字段之外构造检索条件。例如在万方数据的专业检索中,提供了主题、题名、创作者、作者单位、关键词、摘要、日期、DOI、期刊名、期号等可检索字段以及“与”、“或”、“非”三种逻辑关系。用户必须严格按照给定的检索字段和逻辑关系构造规范查询语句才能够进行正确检索。
科技资源的独特特征决定了其特殊的查询访问接口方式,为了能够向用户提供透明化的查询访问方式,需要对用户查询请求做标准化处理。如图 2所示,用户无论使用何种查询方式,其查询请求在提交到分布式异构检索引擎之前,都需要经过科技资源的查询预解析器将查询条件解析为检索引擎的标准化查询格式,其查询请求才能够被准确传递到ES分布式检索集群。

图2 科技资源查询示意图
ES并没有具体给出上述三种查询方式的规范处理方法,这就需要系统实现查询应用到ES自身查询机制接口的转换,即需要在用户接口和ES之间引入一层查询转换器。基于如下考虑:(1)目前几乎所有的检索系统都是基于Web的B/S实现;(2)为了对多种查询方式进行统一处理;(3)为了便于描述用户的查询意图和对查询请求进行语法分析和校验;(4)为了便于多种终端的访问,能够跨平台实现数据交互。因此,设计并实现了一种基于XML和JSON的科技资源统一查询描述语言(SUDL),图 3给出了这种查询语言的基础DTD规范描述。每一个查询请求由一个

图3 科技资源统一检索描述语言规范(部分)
2.3 检索结果处理
定义1对于某一特定资源R,可能会存储在不同的科研机构内,既存在于机构U1中,也存在于机构U2中。即存在于其资源库L1中也存在于资源库L2中等。将这种存在资源覆盖的情况,记为α。
定义2对于某一特定资源R,只存在于机构U1中,或者机构U2中。即存在于资源库L1或者资源库L2中,将这种不存在资源覆盖的情况,记为β。
2.3.1 基于访问代价的科技资源访问算法
从ES的检索结果来看,对于每一个分布的数据资源,相同记录的访问存在不同的访问开销。例如,某资源同时存储在D1、D2两个数据源库上,但是用户访问这两个库的时间不同,网络性能好的数据源能够极大提高资源的访问速度。所以,在检索结果中需要根据资源的访问时间来对对应的资源进行结果处理,生成排序结果,并利用其他工具为使用者提供建议。如图4所示,是对各机构拥有的重复资源的访问示意图,针对α的情况,当用户访问重复资源的时间AC如图 4中所示时,则AC=19为最终选择的用户最优的数据访问路径。

图4 α情况下,冗余结果的最优化访问示意图
目前在分布式异构环境下的科技资源检索中,衡量用户访问效率的最好计算方式是用户访问资源的时间。当不同机构中存在相同资源时,系统需要为用户提供一条最优的访问路径,即需要将在最短时间内访问到的指定资源返回给用户。这就需要从ES访问存储有相同资源的不同机构的多个访问时间中选择最短访问时间。
本系统是基于B/S的实现,为了准确计算用户访问不同机构数据源的时间,在客户端用户可以使用网页版的ping.js获取访问存储在不同机构的相同资源的时间t,此时得到的t是客户端直接到机构数据源的访问时间。算法简单描述见算法1。
算法1QUserTRequest
Input:R,资源记录;n,资源记录数
Output:AC,资源访问评估时间
1 var array;
2 var AC;
3 for each j in n
4 do
5 var t;
6 ping(j.ip).then(function(delta) {
7 t←delta;
8 array.add(j,t)
9 })
10 Done
11 AC←min(array).t
12 Return AC;
如果访问机构U1,U2,…,Un中资源的时间分别为t1,t2,…,tn,则访问存放相同资源的所有机构的时间集合可表示为:
T={t1,t2,…,tn}
(1)
在α情况下,需要找到集合T中的最小值作为用户的最小访问时间,将对应机构中的资源返回给用户,作为用户的最优访问路径。
2.3.2 算法性能分析及优化
假设某一指定查询记录的数据为M条,前端检索按照PageSize分页,满足查询的某一资源最多存在于N个独立机构内。利用本文设计和实现的检索系统创建索引,则某科技资源最多存在N条重复的索引项。某一用户独立访问N个远程机构中同一资源的时间分别为:t1,t2,…,tN。考虑从用户前端访问ES索引库,响应PageSize的平均时间为Tavg,则获取含有重复索引的一条数据记录的总时间开销为(AC+Tavg),发起的请求数等于重复索引数N。假设最坏情况下,PageSize中每一条记录都具有N个重复索引项,那么需要发起的Ajax请求为PageSize×N,例如分页PageSize大小为15条每页,共有3个机构,则请求为45个,这是算法2得到的请求开销。显然随着分页记录和多个机构之间的重复数据越来越多,发起的Ajax请求也越来越大。这就需要对该请求方式进行优化,实现过程中的优化算法描述如算法2、算法3所示。
算法2Query
Input: pagesize, 分页大小
Output:分页中包含每条记录所在的位置及评估时间
1 var tmp,array;;
燃烧炉内生成的有机硫是硫磺回收装置有机硫的主要来源,而常用控制方案是将其在一级克劳斯反应器内最大限度地水解生成H 2 S,残余有机硫在尾气处理单元加氢水解反应器中进行转化。在硫磺回收单元各级反应器中,通常一级反应器床层温度为280~360℃,后续各级反应器床层温度略低于此值,而现有工业催化剂性能存在局限性,在较低的反应温度下对有机硫的水解催化性能均较差。尾气处理单元加氢水解反应器床层温度往往在240~330℃,可实现一定的末级催化加氢水解作用,现有主流尾气处理工艺对加氢反应器后的残余有机硫几乎不再进行更深度的转化,将直接被带入灼烧炉燃烧转化为SO2后,通过烟囱排入大气。
2 for each i in pagesize
3 do
4 tmp.t ←UserTRequest(k,i);
5 tmp.ip ←i.ip;
6 array.push(tmp);
7 Done
算法3QueryOptimizer
Input: T, 超时时间;pagesize, 分页大小
1 var tmp,array;
2 for each i in pagesize
3 do
4 if(array.contain(tmp)) {
5 get tmp from array;
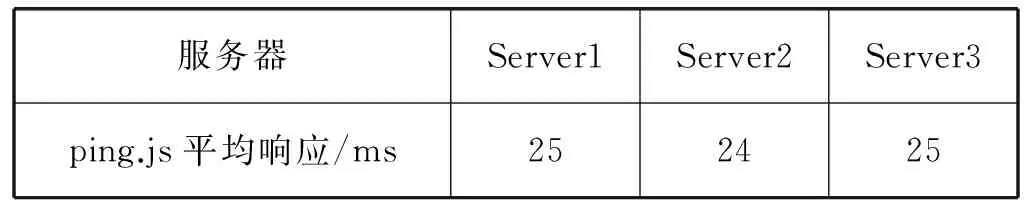
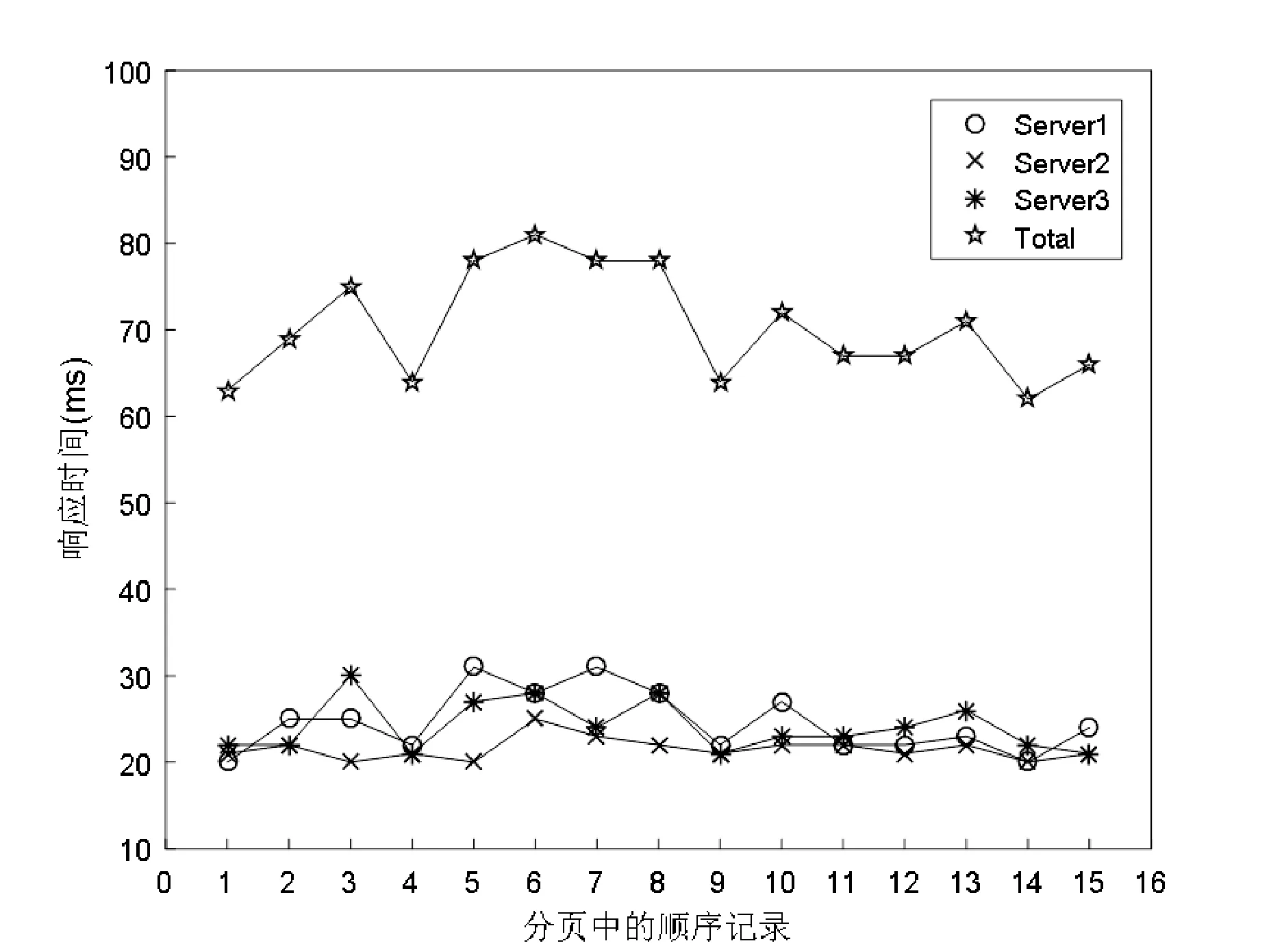
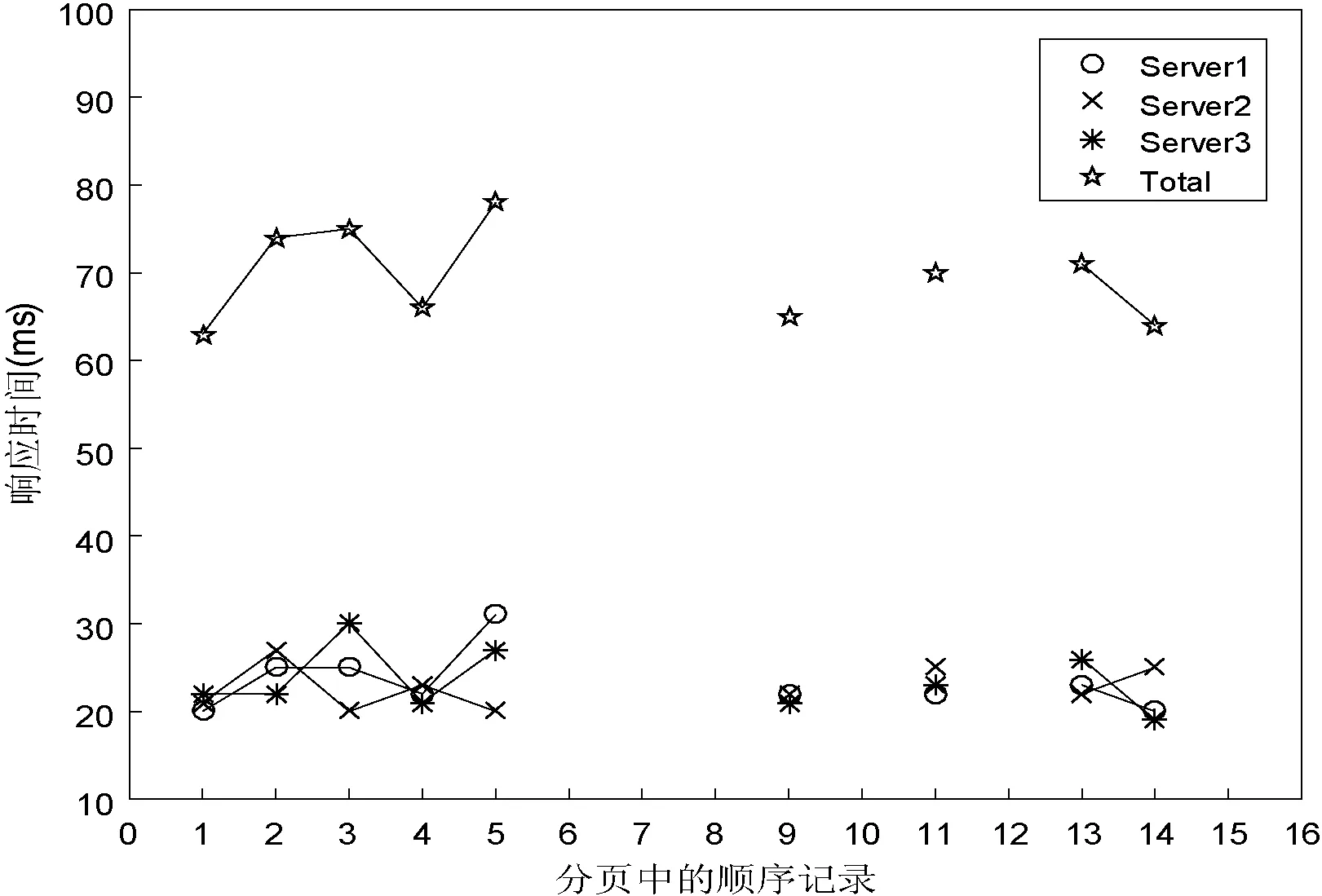
6 if(tmp && i.ip==tmp.ip && time 7 i.t = tmp.t 8 }else{ 9 tmp.t ←UserTRequest(k,i); 10 tmp.ip ←i.ip; 11 array.push(tmp); 12 } 13 } else { 14 tmp.t ←UserTRequest(k,i); 15 tmp.ip ←i.ip; 16 array.push(tmp); 17 } 18 Done 每次检索返回的PageSize中,若满足要求的第一条记录包含N个索引项,则必然需要N次请求。这个请求操作是必须要发生的,用户在查询同一分页中的记录或者在T时间内发起查询请求时,如果所查资源在同一IP内,就以第一次访问的时间t作为当前记录的访问时间。这样,N条重复记录发起的请求数量最大为N,如前面的15条每页,在T时间内,无论用户获取的记录数为多少,发起的最大数总是等于3,与未优化之前相比减少了80%的请求数。显然,这种方式能够大量减少用户提交的请求数,而其不足在于,用户获取的访问时间可能因为时延等因素,导致一定的误差,但是这种方式综合考虑了访问代价和性能。 本研究主要设计了两个实验,首先验证DHRS的可行性(记为:实验一),然后再针对DHRS中资源访问优化算法的改进性能进行验证(记为:实验二)。DHRS基于Java Web实现,Java运行时版本1.7.0_79;ES版本为1.4.2,操作系统为:CentOS release 6.4,系统配置为Quad-Core AMD Opteron(TM) Processor 2352 CPU@2.10 GHz,内存为4 GB,实验一的测试工具选用JMeter。 3.1.1 实验数据 本文实验所使用的数据是由万方提供的部分科技资源文献300万条真实元数据。这些数据来源于不同的服务器、不同的数据库、不同的数据表,能够体现资源的异构性,资源组成如表1所示。 表1 测试使用的数据源 从用户常用查询角度出发,根据库中数据所代表的类型,设计了如下几组常用的科技资源检索条件,这些条件包括了基础以及其组合查询(包含了与、或、非谓词),同时也具有一定的代表性: Q1:查询“1999”年公布的科技成果; Q2:查询在2004年1月1日到2004年1月3日申请的专利; Q3:查询办学类型中含有“高等学校”字样的学校; Q4:查询涉及“能源”、“信息”、“资源”或 “资源环境”的项目; Q5:查询1959年到1999年成立的,职工总数在50人以上的所有机构; Q6:查询在北京举办的会议中,作者规范单位名称中包含“上海交通大学”的中文会议论文; Q7:查询“2013”年发表的所有外文论文; Q8:查询论文编号在“28737000”与“28738000”之间和 “2111800”与“2112000”之间的所有论文; Q9:查询作者姓名中含有“Mariangela”的外文论文。 3.1.2 单节点检索性能 在单机环境下,根据上述9个不同的查询条件,分别通过DHRS和ES提交,测得其查询响应时间如图5所示。 图5 DHRS系统和ES查询的单机响应时间对比 由图 5可以看出在进行集成测试时,DHRS的整体性能不及ES,但都能够在50~110 ms内获取检索结果,可以满足用户需要。这些性能差异的原因是DHRS在查询时,使用SUDL语言规范来描述查询请求,而查询则是基于ES实现。因此,系统需要先将SUDL语言解析成ES的标准查询指令,查询解析的时间开销视查询文件的大小而定。在DHRS系统中进行测试时,上述9个查询条件被描述为符合SUDL规范的XML文件,其查询文件大小都在1 KB以内,解析查询文件的时间开销在40~45 ms。由于解析过程占用时间开销,DHRS系统必然比直接使用ES进行查询耗费时间。而且对于不同的查询请求,查询解析的时间可能会远大于其实际的查询时间,例如Q4、Q5,所以与ES相比,系统的时间开销主要在于查询文件的解析过程。 3.1.3 多服务器检索性能 配置DHRS系统的ES分布式检索集群,集群节点数从1逐渐增加到6,当节点数增加到大于等于2时,数据集的所有分片及副本都将平衡分配在不同节点上。在此过程中,每增加一个节点,ES都会对索引分片和副本进行重新分配以达到负载平衡。每增加一个节点就分别对上述9个查询请求进行一次测试,测得其查询响应时间的变化如图6所示。 图6 DHRS系统的分布式集群的查询响应时间 从图6中可以看出,在集群节点数逐渐增加时,不同查询条件对应的查询时间都有不同程度的减少,并且在节点数增加到一定数量时,查询响应时间会趋于稳定。由此,可以得到如下结论,在ES检索集群中,上述9个检索请求基本上都能够在较短时间内完成。并且随着集群节点数的增加,检索响应时间也随之减少,说明可以通过增加节点来提高性能。当集群数为5时,检索性能趋于稳定,已达到当前系统软、硬件配置为当前检索所能提供的最大性能。 在三台服务器上分别部署DB1、DB2、DB3(见表1)数据库,并利用ES分别构建索引,模拟分布式异构文献资源,客户端使用Chrome(版本53.0.2763.0)浏览器。按照15条记录分页,记录大小平均1 KB,这样可以减少DOM渲染带来的影响,每条记录在本实验环境下的平均响应时间如表2所示,利用Ping.js的响应时间进行性能比较。 表2 平均响应时间 通过DHRS查询数据返回15条分页记录,在客户端通过Ajax请求对15条记录进行数据访问评估、测试性能如图7所示。其中,(a)和(c)是在算法2下执行的性能;(b)和(d)在算法3下执行的性能;在(b)中,第2至第15条记录的响应评估时间由第一条记录估算。在(d)中第6至第8条记录,由第5条估算,第10、12和15条以此类推。 (a) 总耗时1 067 ms (b) 总耗时63 ms (c) 总耗时1 055 ms (d) 总耗时626 ms图7 测试性能结果 本实验在局域网内模拟不同机构提供相同数据集,通过对比实验,评估了不同算法实际执行效果。在T=5 s的时间内,算法2每次都要对不同机构的数据访问,这样带来了严重的性能问题,从图7(a)和(c)可以看出总耗时在1 s以上。数据虽然在3台服务器上都有分布,但是通过UserTRequest选中了Server2,因此数据信息均来自同一IP,所以根据算法3,图7(b)只需要获取第一条记录即可知道其他记录的访问时间,即总耗时为63 ms,与(a)相比,性能提高了94%。图7(d)则根据三台服务器不同响应时间选中了不同的服务器,一旦后续数据在同一记录上则可以很大程度减少额外开销。在本实验环境下较图7(c)性能提高了41%,综合来看性能较未优化前提高了68%,说明优化后算法3的可行性和高效性。 综上所述,DHRS通过集成ES能够充分利用ES的分布式检索优势,可以方便地整合异构科技资源。在本实验环境给定的检索条件下,虽然引入了中间描述语言对整体的检索性能有一定影响,但查询条件仍能在较短的时间内处理百万级数据。当数据在多个机构之间存在重复记录的时候,通过优化检索结果访问时间,可以极大地提高系统的性能。 针对实际应用需求,本文研究了基于弹性搜索技术的分布式异构科技资源的高性能检索解决方案,重点对分布式异构科技资源检索中出现的问题进行了分析,并给出了可行的解决方案。设计并实现了基于弹性搜索的分布式异构检索系统DHRS以及描述异构资源查询的中间描述语言,解决了异构科技资源的统一整合和规范化查询问题。通过优化异构科技文献检索中的资源访问算法,提高了异构文献资源的访问效率。该研究可为分布式科技资源统一访问、异构科技资源数据融合提供借鉴和参考。在后续工作中将进一步优化SUDL语言的解析引擎。 [1] 焦玉英,温有奎,陆伟,等.信息检索新论[M]. 武汉:武汉大学出版社, 2008:1-17. [2] Sato N, Uehara M, Sakai Y, et al. Distributed in-formation retrieval by using cooperative meta search engines[C]//IEEE. Distributed Computing Systems Workshop, 2001 International Conference on, 2001:345-350. [3] 许静芳. 指南针联邦:突破集中式搜索之困[J].中国教育网络, 2007(6):14-16. [4] 张渊源,张琴燕,蒋关富. 面向Web电子产品信息分布式检索系统的设计与实现[J].计算机应用, 2013,33(4):1026-1030. [5] Cacheda F, Carneiro V, Plachouras V, et al. Performance analysis of distributed information retrieval architectures using an improved network simulation model[J]. Information Processing and Management, 2007,43(1):204-224. [6] Paltoglou G, Salampasis M, Satratzemi M. Collection-integral source selection for uncooperative distributed information retrieval environments[J]. Information Sciences, 2010, 180(14):2763-2776. [7] Romero-Tris C, Castellà-Roca J, Viejo A. Distributed system for private web search with untrusted partners[J]. Computer Networks, 2014,67(5):26-42. [8] Das S, Shuster K, Wu C, et al. Mobile Agents for Distributed and Heterogeneous Information Retrieval[J]. Information Retrieval, 2005, 8(3):383-416. [9] Armbrust M, Fox A, Griffith R, et al. A view of cloud computing[J]. Communications of the Acm, 2010, 53(4):50-58. [10] 吴广印.分布式学术搜索引擎研制及其大数据应用[J].数字图书馆论坛, 2013(6):10-18. [11] 吴广印. RMSCloud与科技文献云服务[J].中国科技资源导刊, 2013(5):72-78. [12] 吴广印. RMS系统架构与情报检索系统的功能需求研究[J]. 数字图书馆论坛, 2013(6):31-38. [13] Baezayates R, Castillo C, Junqueira F, et al. Challenges on Distributed Web Retrieval[C]//IEEE, International Conference on Data Engineering. IEEE, 2007:6-20. [14] Elasticsearch[EB/OL].[2016-08-11]. http://www.elasticsearch.cn/. [16] Apache Lucence [EB/OL].2016-08-11]. http://lucene.apach-e.org/. [17] 陈俊杰,黄国凡. 应用Elasticsearch重构图书馆站内搜索引擎[J]. 情报探索, 2014(11):114-119. [18] JDBC plugin for Elasticsearch[EB/OL]. [2015-05-21].http-s://github.com/jprante/elasticsearch-jdbc. [19] 吴广印,杨奕虹,杨贺. 从知识获取看知识组织——基于“知识获取五要素”的知识组织研究与实现[C]//数字图书馆高层论坛2010年年会论文集, 2010:29-36. [20] 吴广印. 知识获取“五要素”的研究与实践[C]//中国索引学会第三次全国会员代表大会暨学术论坛论文集, 2008:29. APPLICATIONANDOPTIMIZATIONOFDISTRIBUTEDHETEROGENEOUSRETRIEVALINSCIENTIFICANDTECHNOLOGICALINFORMATIONRESOURCES Li Cheng1Tong Bin1Liu Yingbo1,2*Wu Ping2Wang Feng1,2Wen Ruojin2Chen Yajie1 1(ComputerTechnologyApplicationKeyLaboratoryofYunnanProvince,KunmingUniversityofScienceandTechnology,Kunming650504,Yunnan,China)2(YunnanAcademyofScientificandTechnicalInformation,Kunming650500,Yunnan,China) When using the traditional centralized retrieval method to deal with massive heterogeneous technology information resources, there are many problems such as single point of failure, poor performance and extensibility. To solve this problem, a distributed high-performance retrieval system (DHRS) applied to heterogeneous technology resources is proposed. First, key techniques of the DHRS were studied and analyzed. Aiming at the problem of large access cost of retrieval results, an evaluation algorithm based on access cost was proposed. Secondly, the algorithm was optimized according to the practical application scenario. The number of requests after optimization was reduced by 80%, and the performance in the experimental environment was improved by 68%. Finally, the test of real data sets proves the feasibility of DHRS retrieval of large amount of scientific and technological resources. It can be applied to search and extend performance requirements of the scene. Scientific and technological resources Distributed retrieval Massive data ElasticSearch Heterogeneous resources TP3 A 10.3969/j.issn.1000-386x.2017.10.013 2017-01-14。国家自然科学基金项目(61462053);中国博士后科学基金项目(2016M602730)。李城,硕士,主研领域:机器学习,人机交互。童彬,硕士。刘应波,博士。邬平,高工。王锋,教授。文若瑾,助理研究员。陈亚杰,硕士。3 实验及分析
3.1 实验一



3.2 实验二


4 结 语
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
自动化学报(2018年2期)2018-04-12
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国洗涤用品工业(2017年2期)2017-04-16
雷达与对抗(2015年3期)2015-12-09
