
基于推理现象识别的答案抽取
2017-09-22 06:14任函
湖北科技学院学报 2017年4期
任 函
(广东外语外贸大学 语言工程与计算实验室,广东 广州 510006)
基于推理现象识别的答案抽取
任 函
(广东外语外贸大学 语言工程与计算实验室,广东 广州 510006)
答案抽取是问答系统的核心任务之一。为了改进答案抽取性能,本文提出一种基于推理现象的答案抽取方法,该方法通过分析问句和检索候选句间的推理现象,进而判断两个句子间的蕴涵关系,并据此抽取候选答案。该方法的特点在于,首先从局部上把握两者所包含的推理关系,然后基于此从整体上分析问题与答案句的关系,以此作为答案抽取的依据。实验表明,本文方法能够在一定程度上改进答案抽取的性能。
答案抽取; 推理现象; 文本蕴涵识别; 支持向量机
一、 概述
答案抽取(Answer Extraction)是问答式检索系统(又称问答系统,Question Answering)的核心任务之一,是指从检索到的相关信息中抽取出和答案类型一致的部分,并根据某种原则选择最有可能的候选答案返回给用户[1]。传统的问答系统一般采用句法语义分析、相似度计算和模式匹配等方法抽取候选答案[2],然而,对于那些在词汇和句子结构上存在较大差异的问题和答案,这类系统往往难以获得理想的性能,其原因在于,这类问题和答案涉及复杂的语义关系,需要进行深度的语义分析和推理。
为此,一些研究者利用文本蕴涵识别(Recognizing Textual Entailment)方法进行答案抽取。该方法将答案抽取问题转化为问题和答案的蕴涵关系判断问题,从而提供了一种分析问题和答案之间语义关系的有效途径[3]。作为一种语义推理的通用框架,文本蕴涵识别能够应用在问答系统、多文档自动摘要、信息抽取等众多自然语言处理应用中[4, 5]。
然而,尽管文本蕴涵识别能够改进问答系统的性能,现有文本蕴涵识别研究仍集中于针对某一特定类型的推理问题设计精确的解决方案,这种方式虽然能够提高针对这类问题的推理能力,然而由于文本蕴涵识别涉及的推理关系众多,使得这种方式对于文本蕴涵识别的整体性能提升非常有限[6]。为此,一些研究尝试对推理中涉及的推理关系进行分类,称之为推理现象,并据此建立推理现象的标注方法和资源[7, 8, 9]。例如:
Q1:上下文无关文法的创立者是谁?
A1:乔姆斯基提出了形式语法理论。
其中,“上下文无关文法”和“形式语法理论”属于“领属”现象,“创立者”和“提出”属于“词义蕴涵”现象。显然,获取这些推理现象有助于对问题和答案间的蕴涵关系进行判断。基于此,本文提出一种基于推理现象的答案抽取方法,该方法通过分析问句和检索候选句间的推理现象,来判断两个句子间的蕴涵关系,并据此抽取候选答案。与现有方法相比,本文方法能够深入分析问题和答案之间的语义关系,即首先从局部上把握两者所包含的推理关系,然后基于此从全局上进行分析判断,得到包含了问题所表达的意思的答案候选句,以此作为答案抽取的依据。实验表明,本文方法能够在一定程度上改进答案抽取的性能。
二、 本文方法
1.系统架构
本文利用基于推理现象识别的方法对文档搜索得到句子进行分析,找出可能包含了答案的候选句,并抽取其中的答案,总体架构如图1所示。具体而言:首先,对问句进行分析,得到期望答案类型(Expected Answer Type, EAT),并对问句进行扩展以进行检索;在答案抽取阶段,分析检索到的句子与问句之间的推理现象;之后,利用文本推理方法对句子与问句进行推理判断,即将句子看作T,问题看作H,判断T是否蕴含了H,若存在蕴涵关系,则表明问题所表示的意思包含在句子中,则该句可能为包含答案的候选句;最后,按照蕴涵度进行排序,并利用EAT进行答案验证以抽取答案。
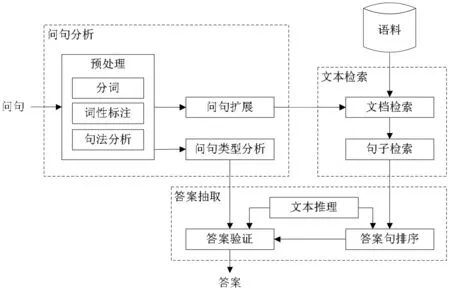
图1 系统总体架构
以前述(Q1,A1)为例,系统首先分析问题,得到EAT为人物名称,然后,利用本文提出的推理现象识别方法分析Q1和A1中涉及的推理现象,包括“领属”、“词义蕴涵”和“指代”。之后,利用推理现象识别结果进行文本蕴涵识别,得出A1蕴涵了Q1的判断。最后,根据EAT,从A1中抽取出答案“乔姆斯基”。
2.答案抽取模型
答案抽取的任务是,利用推理现象识别结果对问句和答案句进行文本蕴涵识别,找出与问题最相关的答案句,并进行排序和验证。如果将答案句看作T,问题看作H,则这一问题可转化为文本蕴涵识别问题,即判断T是否蕴含了H,若存在蕴涵关系,则表明问题所表示的意思包含在句子中,则该句可能为包含答案的候选句。由此,答案排序可分为两个子任务,第一是推理现象识别,第二是文本蕴涵识别。
在之前的工作中,我们提出了一种推理现象识别方法[10],该方法选取了NTCIR RITE-3评测任务中的22类推理现象,并利用随机森林建立了一个推理现象和文本蕴涵识别的联合识别方法。实验表明,该方法在一定程度上改进了文本蕴涵识别的性能。
然而,这一工作存在一定的局限性:在NTCIR的文本推理语料中,部分推理现象,如同义词、同位语等推理现象的语料比较丰富,而列举、指代等推理现象的语料则较为缺乏,即语料存在不平衡问题,这将导致学习模型存在性能偏置,从而影响总体性能。黄衍等也指出,随机森林在不平衡问题的分类性能上要显著低于支持向量机(SVM)[11]。为此,本文提出一种基于支持向量机的推理现象识别方法,并应用于文本蕴涵联合,其架构如图2所示。

图2 基于推理现象的文本蕴涵识别架构
在该方法中,我们采用一对多识别方法(1 vs rest),即为每一类推理现象指派一个支持向量机,每个支持向量机识别一种推理现象。然后,将每个推理现象识别结果作为特征放入一个基于支持向量机的蕴涵识别模型,用于最终判断。这一方案的好处在于,能够在一定程度上避免不平衡问题导致的性能下降,同时保证了模型的泛化性能。
基于推理现象识别的答案抽取算法如图3所示。

算法:答案抽取算法输入:问句q,检索句子集S输出:答案文本步骤:1.对于每一:1)根据问句类型分析,将q及s中符合条件的片断用占位符代替;2)使用每一推理现象识别模型SVMi(i,∈[1,n]n为推理现象个数)分析其中是否存在第i类推理现象,并将识别结果作为特征放入SVMF中;3)将SVMF输出结果利用Sigmoid映射到[0,1],作为蕴涵度;2.对于全部句子,根据其蕴涵度分值进行排序,对于排名在前K位的检索句子,找出句子中被占位符替换的原始文本,作为答案候选。
图3答案抽取算法
Sigmoid函数计算方法为:

(1)
这里x即为SVMF的输出结果,s(x)即为蕴涵度分值。
在答案验证阶段,我们将答案填入问句中,然后对问句与答案句进行文本蕴涵识别,即判断答案句是否在意义上包含了问句。这一过程仍可利用答案抽取模型中的文本蕴涵识别模型。
3.特征集合
本文采用三类特征应用于答案抽取模型。第一类是推理现象专用特征,其中每一个特征用于识别一类推理现象。例如,上位词特征用于识别(T, H)文本对中存在上下位关系的词,其具体方法为:若H中某个词为T中某个词的上位词,则该特征值加1;若不存在这样的词,该特征值为0。第二类是推理现象通用特征,这类特征与推理现象专用特征一起用于识别文本中的推理现象。采用这类特征的动机是,推理现象本质上是复杂语义关系的组合,准确描述推理现象不仅需要利用人工总结的知识,如词典和匹配规则,还需要考虑推理现象所在文本片断与上下文的关系。例如,为识别修饰语省略现象,需要从句法角度考察修饰成分和中心词的关系。第三类是蕴涵识别特征,这类特征与推理现象识别结果一起用于识别总体蕴涵关系。采用这类特征的动机是,推理现象特征仅是局部特征,其识别结果不能作为最终的推理判断,而是需要与各类蕴涵识别全局特征一起进行总体蕴涵识别。

表1 推理现象通用特征
推理现象专用特征采用[10]中提出的特征,共22种,包括16种蕴涵现象特征和6种矛盾现象特征。通用蕴涵识别特征采用[12]中提出的特征,共15种,包括字串重叠特征、相似度特征、结构特征和语言学特征。对于推理现象通用特征,我们定义了10种特征,主要用于考察局部字串和结构上下文的一致性和相似性,如表1所示。其中, 和 分别为T和H中的成分, 为布尔值,表示 和 是否一致, 为取值范围在[0,1]的重叠度,计算方法为集合 和 中相同元素的个数与 和 中全部元素(去重)的个数之比。
三、实验结果及分析
本文实验数据选取NTCIR-5提供的中文问答语料,包括200个中文问题。文档集来自NTCIR提供的CIRB040r中文语料,共901,446篇文档。测试集中包含9类陈述型问题。实验还选取了NTCIR国际评测会议提供的RITE-3中文评测语料,用于推理现象识别的训练和测试。该语料包括581对训练数据和1200对测试数据。每条数据包括一个语段T和一个假设H,并标注了一个推理现象和整体蕴涵关系(蕴涵/非蕴涵)。
本实验采用NTCIR-5的评测指标,即正确率(Acc.)和MRR值。正确率的评价标准是排名第一的候选答案的正确率,MRR值则用于评价前n个结果的排序是否正确。R表示答案正确,且该答案所在的文档能够让用户正确得出该答案;U表示答案正确,但该答案所在的文档不支持该答案,即该文档提供的信息不足以让用户得出正确答案。
实验设置了三个系统,第一个系统(svm)直接利用通用特征和SVM分类器进行答案抽取;第二个系统(svm+lpf+gf)利用一个SVM分类器对全部推理现象进行识别,并进行文本蕴涵识别以获取答案句;第三个系统(this paper)首先利用多个SVM分类器对每一推理现象进行识别,再利用一个SVM分类器进行答案抽取,即本文方法。为进行比较,实验还设置了一个基准系统(baseline),该系统为NTCIR参赛系统[13],采用模式匹配方法抽取答案,并为每个类型的问题定义了一系列模板。

表2 答案抽取结果
本实验中,我们分别测试了第一个答案和前五个答案的正确率和MRR,实验结果如表2所示。
实验结果表明:
1)推理现象识别能够有效改进答案抽取的性能。当考虑答案和所在文档均正确时,本文方法比基准系统的正确率高出7.5%,MRR值高出8.42%;当仅考虑答案正确时,前者比后者的正确率高出7%,MRR值高出7.57%,显示出本文方法显著优于基准系统。从svm+lpf+pf和svm两个实验系统的性能对比上看,当考虑答案和所在文档均正确时,前者的正确率比后者高出2%,MRR值高出2.05%;当仅考虑答案正确时,前者的正确率比后者高出1.5%,MRR值高出1.68%,说明仅在现有模型中加入推理现象识别过程也能够在一定程度上改进答案抽取的性能。
2)基于文本蕴涵识别的答案抽取方法优于基于模式匹配的方法。从svm和baseline两个系统的性能对比上看,当考虑答案和所在文档均正确时,前者比后者的正确率高出4%,MRR值高出1.07%;当仅考虑答案正确时,前者比后者的正确率高出5%,MRR值高出5.63%。
3)与整体识别方案相比,分步识别推理现象和文本蕴涵关系效果更好。这一结论体现在本文方法和svm+lpf+gf两个实验系统的性能对比,当考虑答案和所在文档均正确时,前者比后者的正确率高出1.5%,MRR值高出1.07%;当仅考虑答案正确时,前者比后者的正确率高出0.5%,MRR值高出0.26%。另一方面,从性能上看,两个系统的差异并不十分明显,其原因在于,尽管采用了串行方法有助于更好地识别推理现象,但这一过程可能存在错误扩散问题,导致性能提升比较有限。
四、结论
本文提出一种基于推理现象识别的答案抽取方法。该方法通过分析问句和检索候选句间的推理现象,来判断两个句子间的蕴涵关系,并据此抽取候选答案。在推理现象识别阶段,我们为每一推理现象设置一个分类器,并利用推理现象特征进行识别;在答案排序和验证阶段,我们将推理现象识别结果作为特征,同时加入文本蕴涵识别特征,对问句和答案句进行蕴涵分类。实验结果表明,识别推理现象能够有效提高答案抽取的性能;同时,采用串行方案识别推理现象与文本蕴涵类别,能够在一定程度上改进总体蕴涵识别性能。
[1] 任函. 文本蕴涵识别及其在问答系统中的应用[D]. 武汉: 武汉大学计算机学院, 2011.
[2] 吴友政, 赵军, 段湘煜, 等. 问答式检索技术及评测研究综述[J]. 中文信息学报, 2005, 19(3): 1~13.
[3] Harabagiu S and Hickl A. Methods for Using Textual Entailment in Open-Domain Question Answering//In proceedings of ACL 2006. 2006.
[4] Androutsopoulos I and Malakasiotis P. A Survey of Paraphrasing and Textul Entailment Methods[J]. Journal of Artificial Intelligence Research, 2010, 38(1): 135~187.
[5] Dagan I and Dolan B. Recognizing textual entailment: Rational, evaluation and approaches[J]. Natural Language Engineering, 2009, 15(4): i-xvii.
[6] Magnini B and Cabrio E. Combining Specialized Entailment Engines[M]. Proceedings of LTC'09. 2009.
[7] Bentivogli L, Cabrio E, Dagan I, et al. Building textual entailment specialized data sets: a methodology for isolating linguistic phenomena relevant to inference[J]. Proceedings of the International Conference on Language Resources and Evaluation. 2010: 3542~3549.
[8] Kaneko K, Miyao Y and Bekki D. Building Japanese Textual Entailment Specialized Data Sets for Inference of Basic Sentence Relations. In proceedings of the 51st Annual Meeting of the Association of Computational Linguistics 2013.273~277.
[9] Sammons M, Vydiswaran V G V and Roth D. "Ask not what Textual Entailment can do for you..."//Proceedings of the Annual Meeting of the Association for Computational Linguistics. 2010: 1119~1208.
[10] 任函, 冯文贺, 刘茂福, 等. 基于语言现象的文本蕴涵识别[J]. 中文信息学报, 2017, 31(1): 184~191.
[11] 黄衍, 查伟雄. 随机森林与支持向量机分类性能比较[J]. 软件, 2012, 2012(6): 107-110.
[12] Ren H, Wu H, Tan X, et al. The WHUTE System in NTCIR-11 RITE Task//Proceedings of the 11th NTCIR Conference. 2014.
[13] Ren H, Ji D, He Y, et al. Multi-Strategy Question Answering System for NTCIR-7 C-C Task//Proceedings of the 7th NTCIR Workshop. 2008: 49~53.
责任编辑:吴惠娟
TP391
:A
2095-4654(2017)04-0132-04
2017-03-10
猜你喜欢
当代陕西(2021年18期)2021-11-27
中华养生保健(2020年7期)2020-11-16
吉林大学学报(理学版)(2020年3期)2020-05-29
作文大王·低年级(2019年4期)2019-05-13
商周刊(2017年5期)2017-08-22
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
中学生数理化·八年级数学人教版(2016年3期)2016-04-13
少儿科学周刊·少年版(2015年2期)2015-07-07
