
基于SSDBSCAN的跨项目缺陷预测数据筛选方法
2017-09-13 01:09伍蔓张建升马传香安格格余啸
湖北大学学报(自然科学版) 2017年5期
伍蔓,张建升,马传香,安格格,余啸
(1.湖北大学计算机与信息工程学院,湖北 武汉 430062;2.湖北省教育信息化工程研究中心,湖北 武汉 430062;3.武汉大学软件工程国家重点实验室,计算机学院,湖北 武汉 430072)
基于SSDBSCAN的跨项目缺陷预测数据筛选方法
伍蔓1,2,3,张建升1,2,马传香1,2,安格格3,余啸3
(1.湖北大学计算机与信息工程学院,湖北 武汉 430062;2.湖北省教育信息化工程研究中心,湖北 武汉 430062;3.武汉大学软件工程国家重点实验室,计算机学院,湖北 武汉 430072)
针对跨项目软件缺陷预测中大量不相关的跨项目数据损害了缺陷预测模型性能的问题,提出了一种基于SSDBSCAN(semi-suppervised density-based clustering)的跨项目缺陷预测数据筛选方法——SSDBSCAN filter.首先,SSDBSCAN filter结合少量带类标号的本项目历史数据、跨项目历史数据和大量不带类标号的本项目数据;然后,利用SSDBSCAN算法对这些数据进行聚类发现子簇;最后,收集子簇中的跨项目数据,不属于任何簇的跨项目数据被作为噪声数据而丢弃.实验使用15个公开的PROMISE数据集,3种分类器和4种性能度量指标.实验结果表明,相比于目前已有的Burak filter和DBSCAN filter方法,SSDBSCAN filter在提高了预测率的同时降低了误报率,且G-measure与AUC度量值更佳.
跨项目缺陷预测;数据筛选;SSDBSCAN
0 引言
软件缺陷是计算机软件或程序中存在的某个破坏正常运行能力的问题、错误以及隐藏的功能缺陷.随着软件系统在工程应用中的不断扩大,软件缺陷导致的经济损失日益增加.因此,高效的软件缺陷预测技术越来越受到研究者的关注.目前,已有很多高效的软件缺陷预测方法被提出[1-4],但它们通常基于项目内缺陷预测,当有足够的历史数据可用来建立缺陷预测模型时,本项目缺陷预测效果最佳.但对于一些新的项目来说,项目内的历史数据非常有限,本项目缺陷预测很难顺利进行.跨项目缺陷预测通过利用一个或多个已有的其他项目(跨项目)的历史数据来训练预测模型,然后将模型应用到本项目的缺陷预测中,从而解决本项目没有足够的历史数据来训练模型的问题.Zimmermann使用12个项目构建622个跨项目组合,对这些跨项目缺陷预测模型的性能进行评估,发现由于跨项目数据与本项目数据的数据分布不同,大量不相关的跨项目数据损害了缺陷预测模型的性能[5].因此在使用跨项目数据构建缺陷预测模型之前,对跨项目数据进行数据筛选,找出与本项目数据最相关的数据尤为必要.
近年来,有研究人员提出了一些跨项目缺陷预测数据筛选方法.Turhan提出了Burak Filter,利用K近邻过滤器筛选跨项目数据中与本项目数据最相似的数据作为训练样本[6].实验证明,使用Burak Filter筛选的跨项目数据构建的预测模型,其误报率大大降低.Peter提出了Peter Filter跨项目数据筛选方法,不同于Burak Filter方法仅使用了K近邻算法, Peter Filter将K近邻算法与K-Means聚类算法相结合[7].实验结果表明Peter Filter方法取得了更佳的预测性能.Burak Filter和Peter Filter方法操作简单、容易理解,但其筛选数据的效果容易受到设定的K值的影响,若K值设定太小,会丢失大量相关的数据实例;若K值设定太大,近邻中又可能包含太多的不相关的数据实例.随后,聚类算法渐渐被运用到跨项目数据筛选中.Kawata等尝试使用更为先进的DBSCAN算法进行跨项目数据的筛选,提出了基于DBSCAN的跨项目数据筛选方法 (DBSCAN Filter)[8].DBSCAN Filter将跨项目数据和本项目数据混合,依据DBSCAN算法进行聚类,最后丢弃不包含本项目数据的子簇,收集剩余子簇的跨项目数据.实验选取56个项目数据,将DBSCAN Filter与Peter Filter和Burak Filter两种方法进行了对比.结果表明,该方法在AUC和G-measure度量上明显优于Burak Filter和Peter Filter方法.但是DBSCAN Filter对邻域密度阈值和阈值半径这两个参数的定义是敏感的,若选取不当将造成聚类质量下降.且由于参数是全局唯一的,当簇之间的密度相差较大时,容易造成差别很大的聚类.
近年来,一些基于迁移学习的跨项目预测方法被提出,Ma提出了TNB (Transfer Naive Bayes) 跨项目缺陷预测方法,依据跨项目数据与本项目数据的相似度赋予跨项目数据不同的权重,然后在已加权的跨项目数据基础上构建预测模型[9].Jing指出源公司数据与目标公司数据度量属性通常是异构的,因此提出了本公司和跨公司数据统一度量表示方法,并将典型相关分析(CCA)算法运用到跨项目缺陷预测中[10].
以上的跨项目缺陷预测方法都是基于本项目没有任何历史数据的情况.事实上,如果项目内存在少量带类标号的历史数据,这些数据不足以进行基于项目内缺陷预测,但可以充分利用这些数据进一步提升跨项目缺陷预测模型的性能.
Turhan尝试将本项目历史数据与跨项目历史数据混合,使用混合数据进行缺陷预测模型的构建,实验结果表明当本项目历史数据极少时,混合数据构建的缺陷预测模型也能达到很好的性能[11].Chen提出了名为DTB(Double Transfer Boosting)的跨项目缺陷预测方法[12].该方法利用少量本项目历史数据,通过缩小跨项目数据和本项目数据的数据分布差异,实现了较好的跨项目缺陷预测性能.当本项目数据的极少时,DTB方法构建的跨项目缺陷预测模型的性能甚至可以与本项目缺陷预测模型相媲美.Yu等人针对DTB方法中会出现负迁移的问题提出了基于多源动态TrAdaBoost算法的跨项目缺陷预测方法[13].该方法利用少量本项目历史数据,通过从多个跨项目数据中学习多个弱缺陷预测模型,然后结合这些模型组合为一个强缺陷预测模型,依赖多个跨项目数据避免了负迁移,实现了较好的性能.
SSDBSCAN算法是一种最新的半监督聚类算法,仅需要一个领域密度阈值参数就能自动发现簇结构,适用于没有全局密度参数的情况,且聚类过程不需要用户干预.相比于DBSCAN算法,当簇之间的密度相差较大时,SSDBSCAN算法也能依据自然簇的密度发现自然簇结构.为了提升跨项目数据筛选能力,本文基于SSDBSCAN算法提出了跨项目数据筛选方法——SSDBSCAN Filter.本文中提出的SSDBSCAN Filter同样能充分利用少量带有类标号的本项目数据,进一步去除跨项目中的不相关数据,从而提升预测模型性能.实验结果表明,相比前两种数据筛选方法(Burak Filter和DBSCAN Filter),SSDBSCAN Filter显著提高了预测模型的性能.
接下来的内容共分为五个部分:第一部分是对算法部分的相关约定;第二个部分是对SSDBSCAN Filter的详细说明;第三部分为实验数据集、实验环境、性能度量指标以及实验步骤等的介绍;第四部分为实验结果分析;第五部分为对全文的总结和对未来的展望.
1 相关约定
定义1ε邻域.若实例x∈D,实例x的ε邻域是指以x为中心,以为ε半径的空间.
定义2 邻域密度阈值.若实例x∈D,且为核心对象,则邻域密度阈值MinPts即为x的ε邻域所需包含的对象的最小数目.
定义3 核心距离.若实例x∈D,x的核心距离cDist(x) 为满足邻域密度MinPts的最小半径值.
2 SSDBSCAN Filter

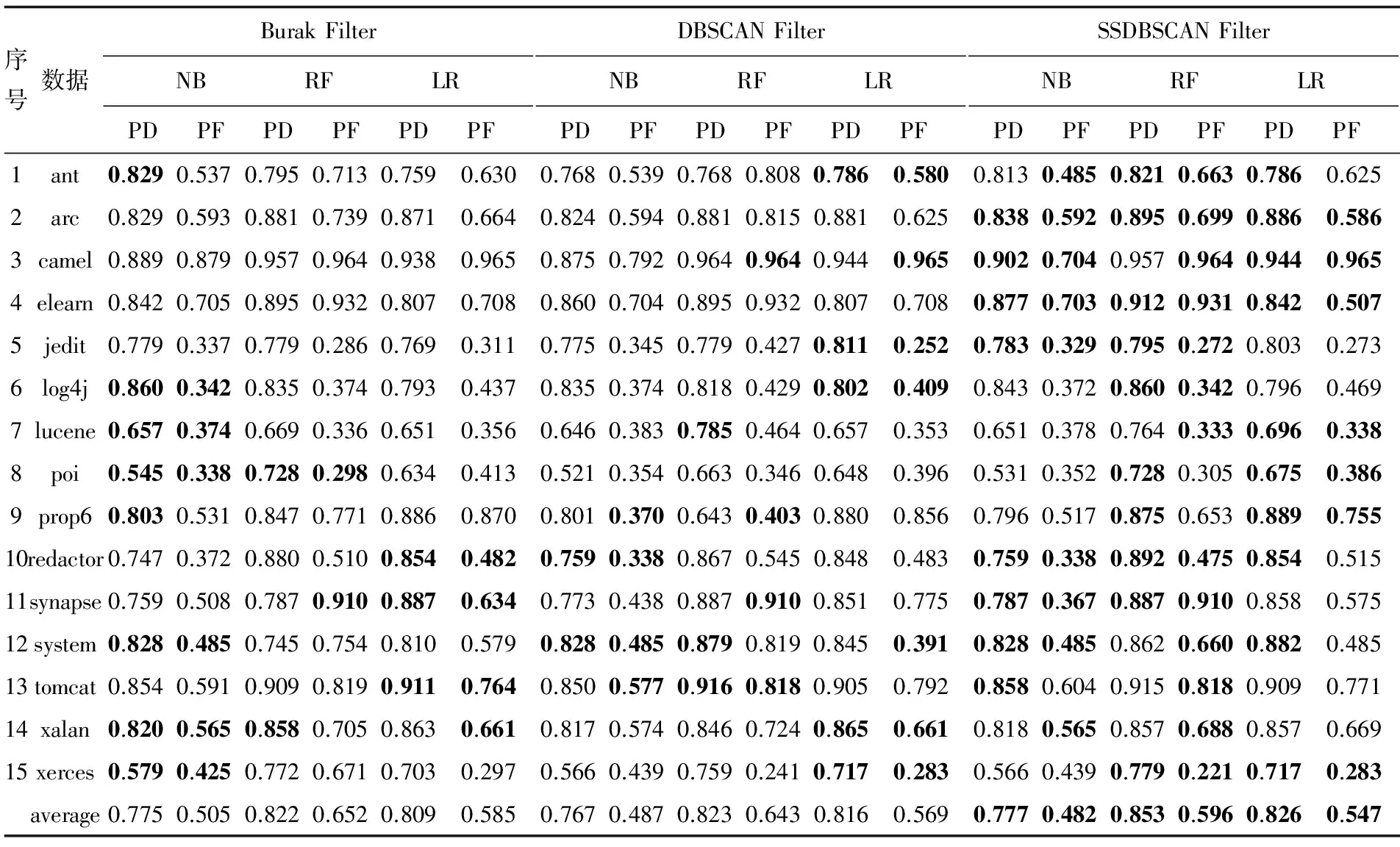
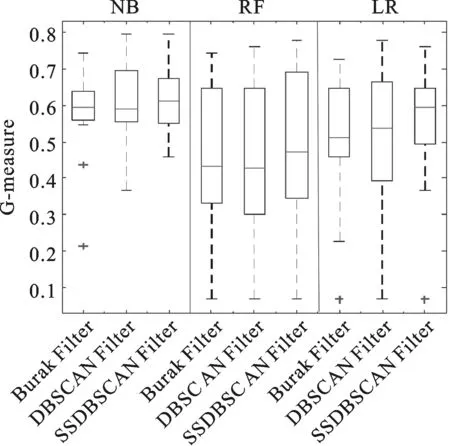
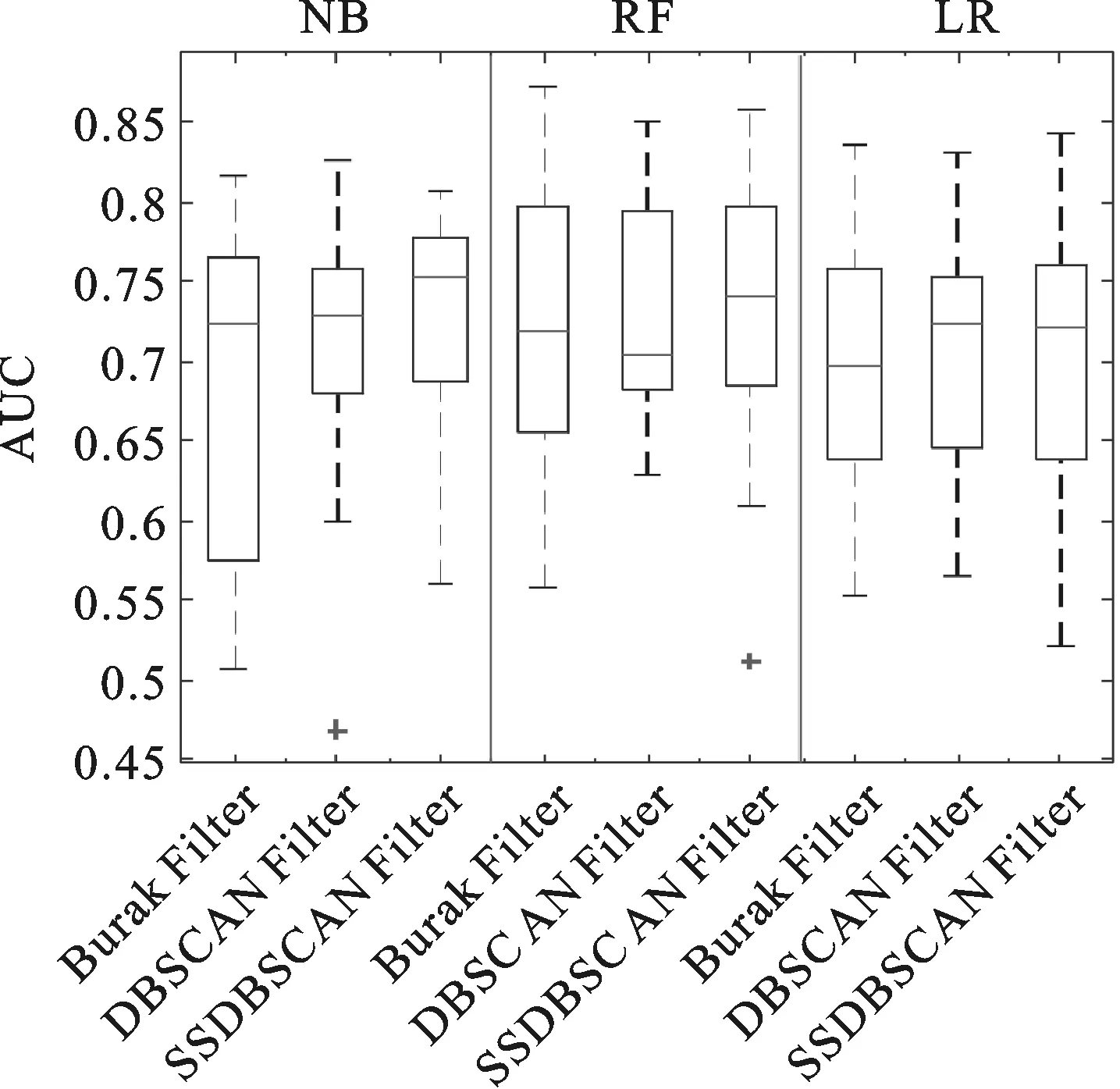
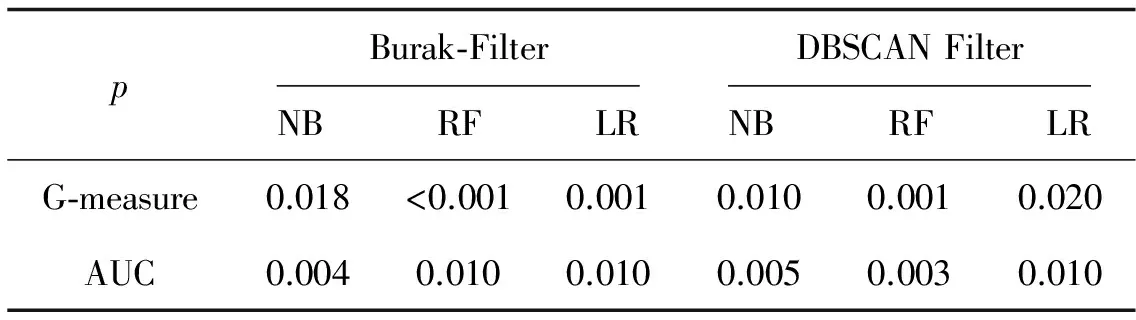
算法1:SSDBSCANFilter 输入:跨项目历史数据集DCP、无类标号本项目数据集DWP、带类标号本项目历史数据集DL、邻域密度阈值MinPts 输出:筛选后的跨项目数据集 1.将DCP、DWP以及DL混合于D 2.标记所有D中实例为unvisited 3.foreachunvisited实例pinDL 4. foreachunvisited实例qinD 5. key[q]=+∞; 6. endfor 7.key[p]←0; 8.创建簇C; 9.Q←D; 10.whileQ≠∅ 11.{ 12. 找到Q中key值最小实例r; 13. ifr∈DL且cLp≠cLr 14. 输出簇C中与本项目数据类标号一致的跨项目数据实例,将簇中实例均标记为visited,break; 15. 将r插入簇中,并将r从Q中移除; 16. foreach实例xinQ 17. ifrDist(r,x) 为了充分利用少量带有类标号的本项目数据,进一步提升缺陷预测模型的性能,我们提出了SSDBSCAN Filter用于跨项目数据筛选. SSDBSCAN Filter首先将本项目数据和跨项目数据混合.本项目数据中包含少量带有类标号的数据和大量不带有类标号的数据;然后开始聚类过程,每次迭代以带有类标号且未被访问的本项目数据为起点,扩充过程中不断更新邻域各点到簇中各实例的边界权值,每一次迭代时寻找邻域中边界权值最小实例添加进簇.边界权值是由SSDBSCAN算法给出的实例连接到簇中的最短路径,详细定义参见定义4.由于文章篇幅原因,本文不对为何每次将边界权值最小实例添加进簇的原因进行详细描述,详见文献[14];当出现不同类标号的本项目数据,则停止簇的扩充,循环结束,以另一个未被访问过的带类标号本项目数据实例为起点继续另一个簇的扩充;随后,当所有带有类标号的本项目数据都包含在簇中,聚类过程终止;最后,聚类生成的子簇中包含大量数据分布相近的实例,收集子簇中的与本项目数据一致的跨项目数据,即得到筛选后的跨项目数据. 图1 SSDBSCAN filter结果图 SSDBSCAN filter的聚类结果如图1所示,我们约定:“○”表示类标号为Y的跨项目数据,“□”表示类标号为N的跨项目数据,“△”表示类标号为Y的本项目数据,“☆”表示类标号为N的本项目数据,“+”表示无类标号的本项目数据.依据SSDBSCAN filter进行聚类得到3个子簇:C1、C2、C3.聚类过程由带类标号的本项目数据实例4、9、12、13开始.聚类完成之后,子簇中可能包含的实例有相同类标号的本项目实例、相同类标号的跨项目实例、不同类标号的跨项目实例以及无类标号的本项目实例.我们仅收集子簇中与本项目实例类标号相同的跨项目实例.因此,簇C1的筛选结果保留跨项目数据实例1、实例2和实例3,实例5因类标号与本项目数据不同而被舍弃.簇C2、C3的数据筛选同C1,簇中实例的类标号应与带类标号的本项目数据一致,因此舍弃跨项目实例5和跨项目实例16.子簇之外的实例19、20、21和22为噪声数据.最后筛选出的跨项目实例有:实例1、实例2、实例3、实例7、实例8、实例11、实例14、实例15、实例17和实例18. 3.1 实验数据与环境 为了验证本文方法SSDBSCAN filter在跨项目软件缺陷预测的性能,本文从PROMISE库[15]选取15个常用公开数据集,数据集详细信息如表1所示.实验均在Intel(R) Core(TM) i5-4210M CPU @ 2.60 GHz,内存4 GB 的PC机上完成的.采用Java语言的开发平台Eclipse,并使用了Weka工具包. 表2 混淆矩阵 3.2 实验度量标准 为了评价跨项目缺陷预测模型的性能,本文选择了四种常用的度量指标:PD、PF、G-measure以及AUC.除PF之外,其他度量指标值越大表示模型性能越佳.这些度量值首先要用到表2的混淆矩阵.混淆矩阵中TP指被正确预测的有缺陷模块数;TN指被正确预测的无缺陷模块数;FP指被错误预测为有缺陷的无缺陷模块数;FN指被错误预测为无缺陷的有缺陷模块数.混淆矩阵定义如下: 1)PD(预测率)是指正确被预测为有缺陷的模块数与实际有缺陷的模块数的比率. (1) 2)PF(误报率)是指正确被预测为有缺陷的模块数与预测为有缺陷的模块数的比率. (2) (3) (4) 3.3 实验步骤 实验共采用15个PROMISE数据集,将其中1个作为本项目数据,剩余14个作为跨项目数据,共15种数据集组合.为便于模型的性能度量,实验数据均带有类标号. 我们将本文方法与Burack Filter方法[5]和DBSCAN Filter[9]对比.对于Burak Filter方法,每个本项目实例从跨项目数据中选取K个最近邻实例组成训练数据集,与文献[3]一致,取K=10.对于DBSCAN Filter,相比于文献[7],由于使用数据集不同,本文中将参数调整为MintPts=5,radius=5.考虑到公平性,SSDBSCAN Filter的参数MintPts同样设为5. 3种数据筛选方法均使用每种组合全部的本项目数据和跨项目数据.由于SSDBSCAN Filter可以使用少量的带有类标号的本项目数据,因此将本项目数据进一步划分为两个部分:10%带类标号的本项目数据和 90%不带类标号的本项目数据,应用于SSDBSCAN Filter. 构建跨项目缺陷预测模型时,我们采用3种分类方法:朴素贝叶斯、随机森林和逻辑回归在Weka上实现.SSDBSCAN Filter已使用10%的本项目数据的类标号,为公平起见,在对模型进行性能度量时,使用剩余的90%本项目数据.实验重复进行20次,取性能度量的均值. 4.1 PD与PF结果分析 表3记录了PD与PF的实验结果.为了使结果更加清晰,表格首先被划分为3个区域,从左到右依次为3种数据筛选方法:Burak Filter、DBSCAN Filter和SSDBSCAN Filter.紧接着,实验使用了3种最常用的构建预测模型的方法:朴素贝叶斯(NB)、随机森林(RF),以及逻辑回归(LR).在使用朴素贝叶斯构建预测模型的情况下,SSDBSCAN Filter的PF值在大部分数据集上均有下降,相比于Burak Filter方法,PF值下降幅度达到4.6%,此外过半数的数据集PD值提高;在使用随机森林构建预测模型的情况下,SSDBSCAN Filter在13个数据集上PF值降低,10个数据集上PD值升高,直接显示出性能的优越;在使用逻辑回归构建预测模型的情况下,约半数数据集显示,SSDBSCAN Filter在降低PF值的同时提高了PD值.综合表3可以看出,SSDBSCAN Filter区域的最优值居多,且选择3种分类器的任意一种构建缺陷预测模型,15组数据的PD、PF度量指标的平均结果均在SSDBSCAN Filter处取得最佳.结果表明,相比于Burak Filter和DBSCAN Filter,SSDBSCAN Filter在PD、PF度量上显示出其优势. 表3 跨项目缺陷预测PD与PF结果对比 图2 G-measure结果对 图3 AUC结果对 从图2可以看出,对于朴素贝叶斯分类器,SSDBSCAN Filter的G-measure值的中位数高于其他两种方法,最小值与最大值均有相应提升.Burak Filter的数据最集中,但是相对而言SSDBSCAN Filter使得G-measure值有一段幅度的提升;对于随机森林分类器,SSDBSCAN Filter的G-measure值的最小值和下四分位数与其他两种方法基本持平,但从中位数、上小四分位数和最大值的角度来看,G-measure性能较佳;对于逻辑回归分类器,SSDBSCAN Filter的G-measure值分布集中,且中位数、最小值、下四分位数明显高于其他方法,显示出最佳的性能. 由图3 可见,在朴素贝叶斯作为分类器的情况下,SSDBSCAN Filter的AUC度量中位数明显提高,上下四分位数之间的差距缩小;对于随机森林,AUC值的中位数明显高于其余两种方法,最小值也有一定的提升.结合图1和图2可知,相比于Burak Filter和DBSCAN Filter, SSDBSCAN Filter总具有较好的G-measure与AUC性能. 综上所述,从选择的4种性能度量PD、PF、G-measure和AUC的结果来看,在大部分的数据集上,SSDBSCAN Filter提高预测率的同时降低了误报率.且使用不同的分类方法:朴素贝叶斯、随机森林或逻辑回归,筛选后的跨项目数据所构建的预测模型总具有较好的性能度量结果.显然, SSDBSCAN Filter最大限度地利用了本项目数据信息,较好地解决了大量不相关的跨项目数据影响预测的问题,显著提高了跨项目缺陷预测性能. 4.3 显著性检验 统计学研究中,p值常用于反映两者间差别有无统计学意义.p值越小,越有理由认为对比事物间存在差异.p>0.05称“不显著”;p≤0.05称“显著”,p≤0.01称“非常显著”.从显著性检验的角度,我们将SSDBSCAN Filter与Burak Filter、DBSCAN Filter分别进行p检验,得到以下结果: 表4 p值结果对比 由上表易知,结果中所有p值均≤0.05,少部分p值≤0.01,因此有理由认为本文提出的SSDBSCAN Filter与Burak Filter、DBSCAN Filter的差别具有显著的统计学意义. 本文中针对跨项目数据中存在大量不相关数据的问题,提出了SSDBSCAN Filter用于跨项目数据筛选.该方法的优势在于可利用少量带有类标号的本项目数据进一步提升筛选效果.实验结果表明,相比于前人提出的Burak Filter和DBSCAN Filter,利用本文中提出的SSDBSCAN Filter所筛选的跨项目数据,在朴素贝叶斯、随机森林、逻辑回归这3种分类器上所构建的跨项目缺陷预测模型的性能均有明显提高. 在后续工作中,我们将收集更多的数据来验证我们提出方法的通用性.同时,将进一步考虑采用更为高效的半监督聚类算法对跨项目数据进行数据筛选. [1] 李勇. 结合欠抽样与集成的软件缺陷预测[J].计算机应用,2014,34(8):2291-2294. [2] 王培,金聪,葛贺贺.面向软件缺陷预测的互信息属性选择方法[J].计算机应用,2012,32(6):1738-1740. [3] Liu M, Miao L, Zhang D. Two-stage cost-sensitive learning for software defect prediction[J]. IEEE Transactions on Reliability, 2014, 63(2): 676-686. [4] Jing X Y, Ying S, Zhang Z W, et al. Dictionary learning based software defect prediction[C]// Proceedings of the 36th International Conference on Software Engineering. New York: ACM,2014: 414-423. [5] Zimmermann T, Nagappan N, Gall H, et al. Cross-project defect prediction: a large scale experiment on Cross-project defect prediction: a large scale experiment on data vs. domain vs. process[C]// Proceedings of the the 7th joint meeting of the European software engineering conference and the ACM SIGSOFT symposium on The foundations of software engineering. New York: ACM, 2009: 91-100. [6] Turhan B, Menzies T, Bener A B, et al. On the relative value of cross-company and within-company data for defect prediction[J]. Empirical Software Engineering, 2009, 14(5): 540-578. [7] Peters F, Menzies T, Marcus A. Better cross company defect prediction[C]// Mining Software Repositories (MSR). San Francisco: IEEE, 2013: 409-418. [8] Kawata K, Amasaki S, Yokogawa T. Improving Relevancy Filter Methods for Cross-Project Defect Prediction[M]// Applied Computing & Information Technology. Springer International Publishing, 2016: 1-12. [9] Ma Y, Luo G, Zeng X, et al. Transfer learning for cross-company software defect prediction[J]. Information and Software Technology, 2012, 54(3): 248-256. [10] Jing X, Wu F, Dong X, et al. Heterogeneous cross-company defect prediction by unified metric representation and cca-based transfer learning[C]// Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. New York: ACM, 2015: 496-507. [11] Turhan B, MiSiRLi A T, Bener A. Empirical evaluation of the effects of mixed project data on learning defect predictors[J]. Information and Software Technology, 2013, 55(6): 1101-1118. [12] Chen L, Fang B, Shang Z, et al. Negative samples reduction in cross-company software defects prediction[J]. Information and Software Technology, 2015, 62: 67-77. [13] Yu Xiao,Liu Jin, Fu Mandi, et al. A Multi-Source TrAdaBoost Approach for Cross-Company Defect Prediction[C]// The 28th International Conference on Software Engineering & Knowledge Engineering. San Francisco Bay, California, USA,2016: 237-242. [14] Lelis L, Sander J. Semi-supervised density-based clustering[C]// 2009 Ninth IEEE International Conference on Data Mining. Miami: IEEE, 2009: 842-847. [15] Boetticher G, Menzies T, Ostrand T. PROMISE Repository of empirical software engineering data[J]. West Virginia University, Department of Computer Science, 2007. (责任编辑 江津) A data filtering method based on SSDBSCANfor cross-project defect prediction WU Man1,2,3, ZHANG Jiansheng1,2, MA Chuanxiang1,2, AN Gege3, YU Xiao3 (1.School of Computer Science and Information Engineering, Hubei University, Wuhan 430062, China;2.Educational Informationalization Engineering Research Center of Hubei Province, Wuhan 430062,China;3.State Key Lab of Software Engineering, Computer School, Wuhan University, Wuhan 430072, China) Since massive irrelevant cross-project data degrades the performance of cross-project defect prediction model in cross-project defect prediction, a data filtering method based on SSDBSCAN (i.e., SSDBSCAN filter) was proposed for cross-project defect prediction. Firstly, the method combined limited amount of labeled within-project data, cross-project data and unlabeled within-project data. Secondly, sub-clusters were found by using SSDBSCAN algorithm. Finally, cross-project data in the sub-clusters was collected and some cross-project data which did not belong to any sub-clusters was discarded as noisy data. The experiments were conducted on 15 public PROMISE datasets using three different classifiers with four performance metrics. Compared with Burak Filter and DBSCAN Filter, the experimental results showed that SSDBSCAN Filter increasedPDvalue, reducedPFvalue and achieved higher G-measure andAUCvalues. academic cross-project defect prediction; data filter; SSDBSCAN 2017-01-28 湖北省自然科学基金(2011CDB072)和湖北大学《数据挖掘》精品课程经费资助 伍蔓(1996-),女,本科生; 马传香(1971-),女,通信作者,教授,博士,主要研究方向为数据挖掘、云计算,E-mail:mxc838@hubu.edu.cn 1000-2375(2017)05-0550-08 TB324.1 A 10.3969/j.issn.1000-2375.2017.05.021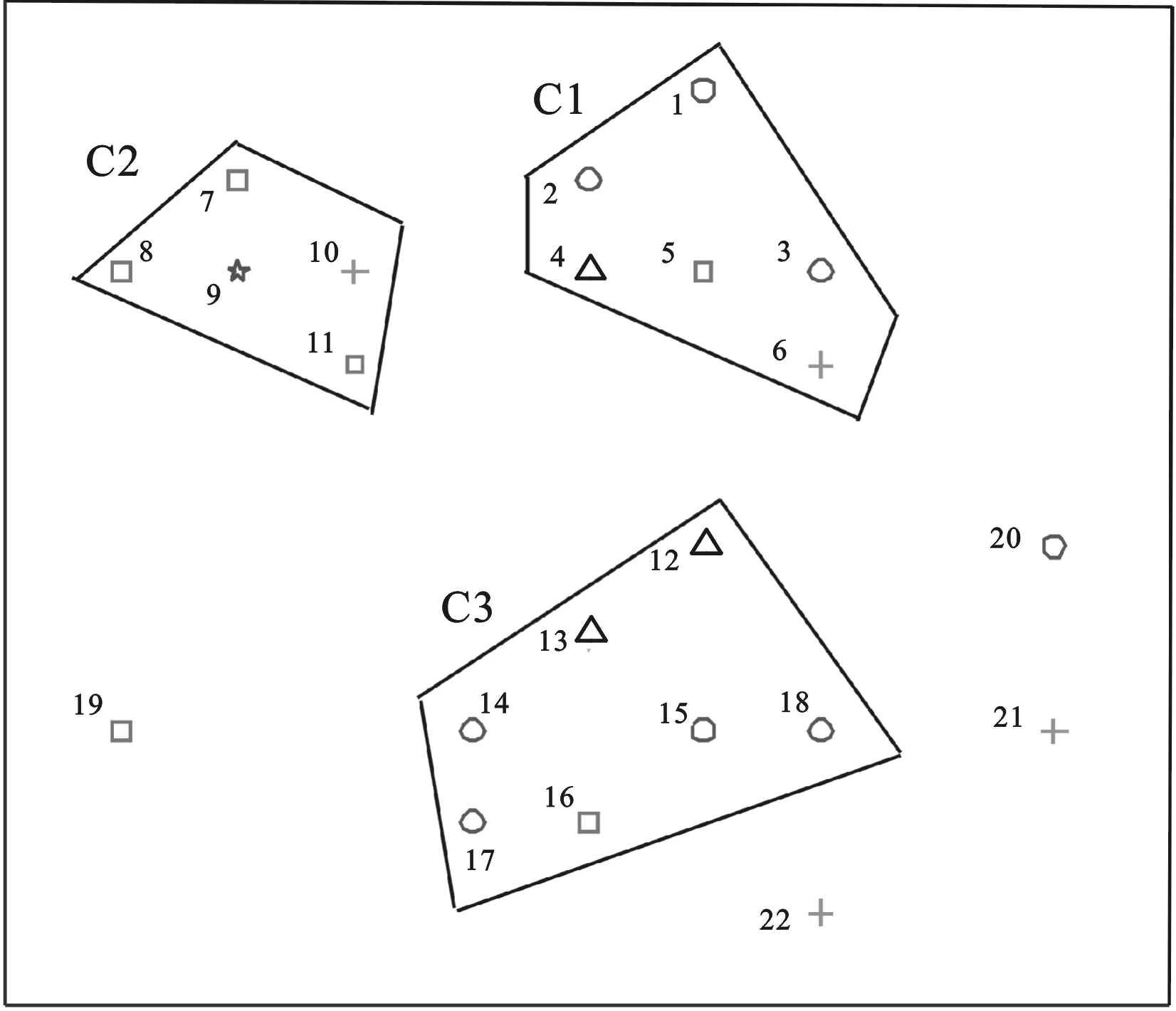

3 实验方法

4 实验结果分析
5 结论
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学物理学报(2020年3期)2020-07-27
数学年刊A辑(中文版)(2019年3期)2019-10-08
新疆钢铁(2016年3期)2016-02-28
中国学术期刊文摘(2016年1期)2016-02-13
中山大学学报(自然科学版)(中英文)(2015年5期)2015-06-08
唐山学院学报(2015年6期)2015-02-22
天津师范大学学报(自然科学版)(2014年2期)2014-11-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
