
针对SAR图像的树形稀疏表示结构识别算法研究
2017-09-01 15:54陈春林刘学军
计算机技术与发展 2017年8期
陈春林,张 礼,刘学军
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
针对SAR图像的树形稀疏表示结构识别算法研究
陈春林,张 礼,刘学军
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
为了提高SAR图像的目标识别能力,在一般稀疏表示方法的基础上,提出了一种基于树形稀疏表示结构识别算法—稀疏表示树,以提高目标型号的识别准确率。稀疏表示树是由多个节点组成的树形分类器,在每个节点上设计针对该节点设计的稀疏表示字典和分类器。在单个节点上利用稀疏表示算法求解未知样本的特征向量,并按照重构误差最小原则实现目标型号识别。稀疏表示树方法根据父节点识别结果,将稀疏表示结果相似的样本型号作为子集传递到子节点,并设计新的字典和分类器进行识别。在MSTAR SAR图像数据集上的实测结果表明,所构建的稀疏表示树与数据集数据分布情况一致,并且将目标型号识别率提高至84%,与传统的稀疏表示分类器方法相比,在不增加太多时间开销的条件下可有效提高目标型号的识别准确率。
SAR目标识别;型号识别;树形信息字典;稀疏表示;字典学习
1 摘 要
自动目标识别(Automatic Target Recognition,ATR)在社会安全、环境监测、国土防御等军用和民用领域扮演着重要角色。合成孔径雷达(Synthetic Aperture Radar,SAR)因其能突破光照、天气、时间限制,获得高分辨率的目标图像等优势,成为现代目标感知探测的重要手段,也是可靠的目标识别数据来源[1-2]。在实际应用中,SAR图像对目标与雷达视角的方位关系非常敏感,同一目标在不同视角下会有很大差异,传统方法在目标识别性能方面仍然不够理想。如何利用SAR图像鉴别目标仍然是当前研究的热点和难点。
目前的雷达目标识别方法主要依照两种思路:基于模版的方法[3]和基于模型的方法[4]。基于模版的方法需要收集目标在各个不同视角下的图像样本,构成目标图像模版库,直接计算待识别样本和模版库中样本的相关性来识别目标。这种思路由于样本收集困难和比对过程计算开销太大,难以适应现代目标识别需求。而基于模型的方法通过实现有效特征提取,减少了样本收集对识别的影响。提取特征的方法包括主成分分量分析(Principal Component Analysis,PCA)[5]、线性判别分析(Linear Discriminant Analysis,LDA)[6]、高斯过程隐变量模型[7](Gaussian Process Latent Variable Model,GPLVM)等。这些方法能够克服目标图像背景变化、相干噪声的问题,获得较好的特征表示结果。
稀疏表示作为一种有效的信号表示方法,在多个领域得到应用,如目标跟踪[8]、人脸识别[9]、表情识别[10]等图像识别领域,以及信号去噪、图像重建、雷达成像[11]、雷达目标识别等信号处理领域。在雷达目标识别应用中,稀疏表示方法相比于其他特征提取方法,可以摆脱识别过程中对目标姿态估计的需要,避免目标姿态对特征表示的影响。最简单的方法是直接使用训练集中样本归一化后构成信息字典,根据最小重建误差原则构造分类器,进行目标识别[12]。在该方法的基础上,有学者提出先对SAR图像进行2DPCA降维,解决稀疏表示识别算法存在的高维问题[13],提高识别精度。除了直接使用训练样本构成稀疏表示字典,还有学者提出通过字典学习的方法,从训练集中学习出稀疏表示字典。这种方法同时降低了字典的冗余性和稀疏表示求解的运算量,达到了更好的识别效果。
传统的SAR目标识别算法主要研究目标类型的识别,将同一种类型不同型号的目标识别为同一类型的目标。由于同类目标在配置结构有一定差异,比如同种坦克是否加装有机关枪、是否展开天线,同种步战车是否加装炮筒等,即同种目标存在多个变体,这使得目标识别更加困难。如何处理存在型号变体导致的识别误差一直是研究的重点。型号变体的存在带来两种问题,一是变体目标的类型识别,二是变体型号的识别。战场环境下,变体型号的识别能够提供更多的战场感知信息,对战事预判有重要的意义,因此获得了越来越多的关注。
为了应对变体型号识别困难的问题,提出了树形结构的稀疏表示分类器—稀疏表示树(Tree-structure sparse coding classifier)。根据根节点识别结果将样本映射到不同的子节点,每个子节点上的字典和分类器是针对该节点样本设计的,用来对根节点上具有相似结构的同种类型不同型号的样本重新分类。MSTAR数据集上的验证结果表明,稀疏表示树结构与样本分布情况一致,并获得了比一般稀疏表示方法更高的型号识别准确率。
2 方 法
2.1 稀疏表示相关背景
稀疏表示是使用一组基上很少的元素线性组合,求得样本的近似表示。通过计算一个样本的稀疏表示向量,对输入数据进行编码,能够获得比统计模型对噪声和缺失数据更加鲁棒的特征表示向量[13]。对单个信号xRp,给定字典DεRp×k,稀疏表示向量αεRk,当满足如下条件:
(1)
或者
(2)
其中,‖α‖0表示l0范数,计算α中非零元素的个数;ε表示重构允许误差上限;T表示稀疏系数。
式(1)或式(2)表示寻找字典D中的最小原子集近似线性表示原信号x。由于求解方程(1)或(2)中需要计算非零元素个数,这是一个NP-hard问题,可以通过将l0范数软化成l1范数,然后使用松弛算法(如基追踪)或者贪婪算法(如匹配追踪、正交匹配追踪)求解[14]。
稀疏表示的关键问题是字典基构造,用于稀疏表示的基叫做字典,既可以是基于分析的固定的字典,如常用的傅里叶基、小波基,也可以是源于数据的构造字典,比如直接由样本组成的字典,或者通过对样本集进行训练获得的更加具有针对性的字典[15]。通过KSVD[16-17]算法求解如下方程获得从样本中学习的字典:
(3)
其中,D表示需要学习的字典;α表示样本X的稀疏表示矩阵。
KSVD是由K-means扩展而来的基于聚类思想的字典学习方法,通过迭代方法逐步更新字典中每个原子,在严格的稀疏度约束条件下获得源数据最佳稀疏表示。每次迭代中首先假设字典D固定,使用MP、OMP方法寻找X在D上的稀疏表示矩阵α,然后根据α通过SVD分解找到更好的字典D。每次迭代在不超过T个原子线性组合的条件下降低‖X-Dα‖的误差,直到最终收敛。
文献[12]指出,利用稀疏表示进行目标识别的原理是,同样一个目标的SAR图像取决于雷达和目标之间的角度和方位,因而同类别目标的SAR图像分布在一个维度远低于图像维度的流形结构中,未知样本可以用与其来自同一个流形结构的局部样本线性表示。因此未知标号的测试样本在由同类样本重构时获得最优表示。寻找未知样本在不同标号样本构成的字典上重构误差最小的标号,作为目标识别结果。给定稀疏表示字典集合:
D=[D1,D2,…,Dn]=[d1,1,d1,2,…,dn,K]
其中,Di表示第i个类型样本学习出的字典;di,k表示第i个类型中的第k个原子。
求解最小重构误差完成测试样本的类别判断:

(4)
其中,δc(α)=[0,…,0,αi,1,αi,2,…,αi,k,0,…,0]表示,除了字典原子对应类标号为i的原子系数不为零,其他系数为零。
2.2 稀疏表示树
在一般稀疏表示方法中,未知样本经过稀疏编码获得稀疏表示,作为特征向量输入分类器,得到分类结果。在稀疏表示过程中,相似类别的样本往往会有相同或相似的稀疏表示向量,比如同种类型的目标由于其结构相似,会有相似的稀疏表示结果。稀疏表示树在每个节点上建立稀疏表示字典和分类器,根据分类结果对发生混淆的目标建立新的节点继续分类,以及输出不发生混淆的目标识别结果。
稀疏表示树是从上而下建立的,每个节点的建立分为三个过程:学习稀疏字典;设计分类器;根据分类器输出结果派生子节点,确定子节点分类目标。详细过程如下:
(1)字典学习:根据该节点的分类目标,从训练集中选取对应的样本学习稀疏表示字典。比如根节点对所有型号进行识别,因此选取训练集中所有样本作为字典学习输入数据;子节点识别某几种具体型号,选择训练集中这部分型号样本作为训练数据,学习相应稀疏表示字典。字典学习可通过求解式(3)获得稀疏表示字典。
(2)分类器设计:利用步骤(1)中学习的字典求解样本稀疏表示向量,输入分类器识别。分类方法选用稀疏表示分类器、SVM等常用分类器。
(3)传递规则判断:分析分类器识别结果,将分类结果中混淆在一起的类别作为新的分类要求,派生到子节点,对不发生混淆的类别直接输出分类结果。
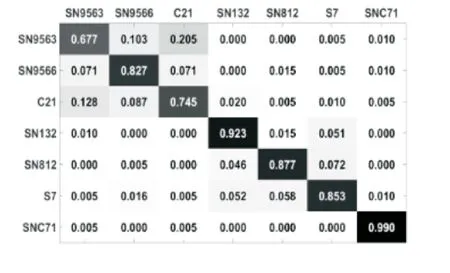
如图1 所示,左侧为根节点识别6×6混淆矩阵示意图,灰色阴影的深浅程度表示样本数目多少。图中上面两种,中间三种出现两个明显的阴隐块区域,表示这两个区域的样本发生混淆,右下角只有一个色块,表示不与其他类别发生混淆。判断传递规则的时候,分成三个组别,如右侧从上到下三个子混淆矩阵,右侧上面两个组由多个型号组成,分别派生子节点,子节点使用这些型号样本设计新的稀疏字典和稀疏表示分类器。右下角代表的组由于只有一种类别,因此直接输出识别结果。
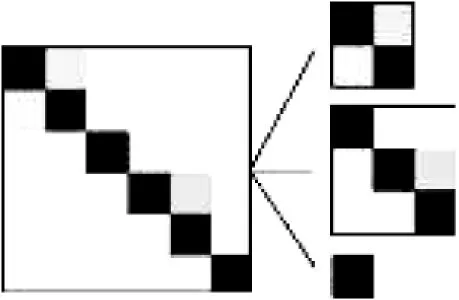
图1 稀疏表示树传递规则展示
稀疏表示树建立过程如算法1所示。
算法1:稀疏表示树建立算法:
输入:SAR目标图像X
根节点字典学习:

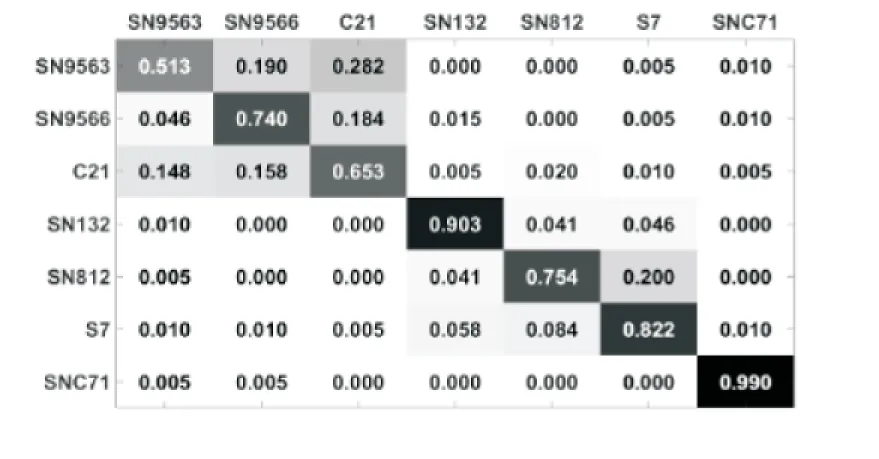
s.t. ∀i,‖αi‖0 根节点分类器: G←Cij: Cij为根节点分类结果混淆矩阵 G←{g1,g2…},gi表示属于该分组的样本标号集合 子节点字典学习: s.t. ∀i,‖αi‖ 输出:Droot,Dg,G 使用稀疏表示树进行目标识别时,给定一个测试样本,首先计算该未知样本在根节点的稀疏表示字典上的稀疏表示向量,然后经过根节点的分类器识别出该样本所属的目标型号。如果识别结果显示该目标型号所在组中只有一个型号,则直接输出识别结果,否则将该样本派生到对应的识别节点上,重新用此节点上稀疏表示字典计算稀疏表示向量,并使用该节点上分类器识别型号并输出结果。 3.1 MSTAR数据集 现有的SAR目标识别文献,多使用MSTAR[18]数据集对其方法进行验证。为了方便与现有方法进行比较,也使用该数据集验证稀疏表示树的识别结果。MSTAR数据集是美国国防部高级研究计划署和空军研究室提供的移动和静止目标获取与识别计划(Moving and Stationary Target Acquisition and Recognition,MSTAR)录取的地面军事车辆聚束式SAR图像数据集。MSTAR数据集中提供了三种类型的车辆:BMP2步兵战车,BTR70、T72两种主战坦克。其中BMP2步兵战车下有SN9663、SN966、SNC21三种型号;T72主战坦克下有SN132、SN812、SNS7三种型号。每个型号都提供17°和15°两种视角下的0°~360°方位角下若干图像样本。每个样本的像素分辨率为128×128像素,尺寸分辨率为0.3×0.3 m。 数据库信息统计见表1。 表1 实验数据集信息汇总 对数据集进行截取预处理,用来减少目标区域周围的背景杂波以及后续处理的运算量。通过截取,保留所需要识别的整个目标,将原始128×128图像缩小成64×64的小幅图像,得到最终识别使用的图像。 3.2 建立稀疏表示树 统计稀疏表示树建立过程中的根节点识别结果,做出的混淆矩阵如图2所示,其中每一行表示测试集中一个型号的全部样本识别结果。 图2 根节点识别结果 从图中看出,SN9563、SN9566、SNC21三种型号彼此发生混淆,比如SN9563的所有测试样本有98.5%被识别成这三种型号,只有1.5%的样本被识别成这三种之外的型号。因此建立传递规则时,将SN9563、SN9566、SNC21这三种型号的样本派生到新建立的子节点,由子节点继续识别具体型号。同样对彼此发生混淆的SN132、SN812、S7三种型号目标建立子节点识别,而SNC71直接输出识别结果。 对比稀疏表示树结构与数据集,可以发现SN9563、SN9566、C21这三种型号同属BMP2步兵战车类型,SN132、SN812、S7同属T72坦克类型,而SNC71属于BTR70坦克类型。因为相似的外形和结构,同类目标具有很强的相似性,如果只利用根节点稀疏表示字典,会得出相似的稀疏表示,不能提供更多的型号分类信息,因而需要建立子节点,提供更加特异的稀疏表示字典进行进一步识别。 3.3 稀疏编码树验证 图3中展示了构造的稀疏表示树结构,该稀疏表示树中拥有三个节点,其中一个根节点,两个子节点。根节点的输入为全部型号测试样本,根据根节点识别结果的不同派生到不同的子节点,或者直接输出识别结果,子节点1作为SN132、SN812、S7三种型号识别节点,子节点2作为SN9563、SN9566、SNC21三种型号识别节点。 图3 稀疏表示树 以一个SN9563型号的样本识别过程为例,说明稀疏表示树的识别原理。未知样本在根节点分类结果显示,由第一个或第三个型号字典分别重建。而比较这两个重建结果,由第三类别重建的误差最小,重建结果优于第一个型号字典单独重建结果,因此输出类标号为C21,属于SN9563、SN9566、C21构成的组合,因此派生到子节点2上继续识别。而在使用子节点2上的稀疏字典计算稀疏表示向量并计算重建误差输出型号识别结果。子节点上重建结果显示,使用子节点中第一种型号样本训练字典进行重建的误差最小,输出最终类标号SN9563。 图4是稀疏编码树识别结果,对比图4和图2的SN812样本的识别结果。 图4 子节点识别结果统计 图4中,样本识别准确率为74.5%,另外共有24.1%的样本被错分成T72其他型号。通过派生子节点继续识别型号,将准确率提高到87.7%,而错分到T72其他型号的样本降低到11.4%。统计其他型号的识别准确率,对比根节点均有不同幅度提高。 为比较不同方法识别目标型号的能力,选取SRC、KSVD-SRC以及TREE-KSVD-SRC,统计识别结果如表2所示。其中,SRC方法设置使用训练集中所有样本构成字典,以及每种型号选取与其他方法字典原子相同个数的样本构成稀疏表示字典。结果显示,全部样本构成稀疏字典的识别方法结果最好,但是识别全部测试样本所需的时间是其他几种方法的六倍以上,不能满足实际使用中在对雷达目标识别的时效性要求,因而实际使用价值不大。 表2 目标识别不同方法对比 对比使用部分训练集构成字典的SRC方法与KSVD-SRC方法,使用经过学习的字典比直接使用样本构成字典,稀疏表示效果更有效。结合使用全部训练样本构成字典的SRC方法,当数据样本足够多时,直接使用训练样本构成的稀疏表示字典和使用字典学习方法学习的字典,两种方法稀疏表示性能差别不大;而当样本数量不足时,学习得到的字典能够比直接构成的字典提供更多的分类信息,这验证了字典学习的有效性。对比稀疏表示树方法与其他方法可以发现,经过子节点校正后,所有型号识别准确率比KSVD-SRC方法和部分样本构成稀疏字典的SRC方法高,接近使用全部样本的SRC方法的准确率,识别全部样本所需时间比SRC、KSVD-SRC方法花费时间多一半,但远低于使用全部样本的SRC方法消耗时间。因此稀疏表示树在增加部分时间开销的情况下,有效提高了型号识别准确率。 为了改进目标型号识别算法,在稀疏表示的基础上提出一种基于树形稀疏表示结构的SAR目标识别算法。通过构造多个分类节点,组成树形结构分类器,利用子节点对父节点上由于稀疏表示结果相似造成的型号识别错误校正,提高型号识别准确率。在每个节点上,利用字典学习方法学习稀疏表示字典,稀疏表示分类器作为目标型号识别分类器,进行目标识别。实验结果表明,所建立的稀疏表示树与实验所用数据集数据分布相吻合,将同种目标类型不同型号的样本派生到子节点继续识别,在增加部分识别时间的代价下,有效提高了目标型号识别准确率。 在该方法中,稀疏表示树的构造依赖先验信息,需要先确定分类的组别个数;而且稀疏表示树有两层,只包含一层子节点结构,对于子节点上具有相似稀疏表示结果的相似样本未做处理,限制了稀疏表示树的识别准确率。下一步将会探索利用分类结果学习派生规则,构造更加复杂的树形结构,提高识别准确率。相比于简单的稀疏表示方法,该方法需要对相似样本重新计算稀疏表示向量,识别时间是其1.5倍,还需要探索如何缩短识别时间,提高目标识别时效性。另外,该方法对目标型号的识别准确率为84%,还达不到完全准确识别目标型号的目的,后续工作还需对稀疏表示和字典学习方法进行深入研究,并改进稀疏表示字典和分类器学习方法,提高目标识别效率。 [1] Bhanu B,Dudgeon D E,Zelnio E G,et al.Guest editorial introduction to the special issue on automatic target detection and recognition[J].IEEE Transactions on Image Processing,1997,11(1):1-6. [2] Zhao Q,Principe J C.Support vector machines for SAR automatic target recognition[J].IEEE Transactions on Aerospace Electronic Systems,2001,37(2):643-654. [3] Novak L M,Owirka G J,Brower W S.Performance of 10-and 20-target MSE classifiers[J].IEEE Transactions on Aerospace & Electronic Systems,2000,36(4):1279-1289. [4] Huang Y,Peia J,Yanga J,et al.Neighborhood geometric center scaling embedding for SAR ATR[J].IEEE Transactions on Aerospace & Electronic Systems,2014,50(1):180-192. [5] Mishra A K,Mulgrew B.Radar signal classification using PCA-based features[C]//IEEE international conference on acoustics,speech and signal processing.[s.l.]:IEEE,2006. [6] Huan R,Liang R,Pan Y.SAR target recognition with the fusion of LDA and ICA[C]//International conference on information engineering and computer science.[s.l.]:[s.n.],2009:1-5. [7] Zhang X R,Gou L M,Li Yangyang,et al.Gaussian process latent variable model based on immune clonal selection for SAR target feature extraction and recognition[J].Journal of Infrared & Millimeter Waves,2013,32(3):484-493. [8] 贲 敏,邓 萍,王保云.基于l1/2正则化的稀疏表示目标跟踪算法的研究[J].计算机技术与发展,2015,25(1):82-86. [9] 谢文浩,翟素兰.基于加权稀疏近邻表示的人脸识别[J].计算机技术与发展,2016,26(2):22-25. [10] Chen K,Comiter M,Kung H,et al.Sparse coding trees with application to emotion classification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops.[s.l.]:IEEE,2015:77-86. [11] Wu Q,Zhang Y D,Ahmad F,et al.Compressive-sensing-based high-resolution Polari metric through-the-wall radar imaging exploiting target characteristics[J].IEEE Antennas & Wireless Propagation Letters,2014,14:1043-1047. [12] Thiagarajan J J,Ramamurthy K N,Knee P,et al.Sparse representations for automatic target classification in SAR images[C]//4th international symposium on communications,control and signal processing.[s.l.]:IEEE,2010:1-4. [13] 王燕霞,张 弓.基于特征参数稀疏表示的SAR图像目标识别[J].重庆邮电大学学报:自然科学版,2012,24(3):308-313. [14] Mairal J,Bach F,Ponce J,et al.Online dictionary learning for sparse coding[C]//International conference on machine learning.[s.l.]:ACM,2009:689-696. [15] Tosic I,Frossard P.Dictionary learning[J].IEEE Signal Processing Magazine,2011,28(2):27-38. [16] Aharon M,Elad M,Bruckstein A.K-SVD:an algorithm for designing overcomplete dictionaries for sparse representation[J].IEEE Transactions on Signal Processing,2006,54(11):4311-4322. [17] 周飞飞,李 雷.广义贝叶斯字典学习K-SVD稀疏表示算法[J].计算机技术与发展,2016,26(5):71-75. [18] Yang Y,Qiu Y,Lu C.Automatic target classification-experiments on the MSTAR SAR images[C]//International conference on software engineering,artificial intelligence,networking and parallel/distributed computing.[s.l.]:[s.n.],2005:2-7. Investigation on Identification Algorithm of Tree-structure Sparse Representation for SAR Target CHEN Chun-lin,ZHANG Li,LIU Xue-jun (College of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,Nanjing 211106,China) In order to improve the ability of identifying SAR target series with sparse representation,a tree-structure sparse coding recognition algorithm is proposed,which is employed to lift the recognition accuracy of target models.The sparse representation tree is a tree-like classifier composed of multiple nodes,each of which has a sparse representation dictionary and a classifier for the node.The sparse representation algorithm is used to solve the eigenvector of unknown sample on a single node,realizing the target type identification according to the minimum principle of reconstruction error.The root node is employed to direct input SAR images with similar sparse results to children nodes,which have more specialized dictionaries and classifiers to identify these target series.Experiments on MSTAR target dataset show that it is suitable for the sample distribution and has improved target recognition rate up to 84%,and that compared with the traditional sparse coding method,it has got effective improvement on the target series recognition accuracy without more time expenditure. SAR automatic target recognition;series recognition;tree-structure information dictionary;sparse representation;dictionary learning 2016-09-10 2016-12-13 网络出版时间:2017-07-05 中国航空科学基金(20151452021,20152752033) 陈春林(1992-),男,硕士研究生,研究方向为机器学习、雷达目标识别;张 礼,博士,讲师,研究方向为机器学习、模式识别;刘学军,教授,通讯作者,研究方向为机器学习。 http://kns.cnki.net/kcms/detail/61.1450.TP.20170705.1651.060.html TP391 A 1673-629X(2017)08-0020-05 10.3969/j.issn.1673-629X.2017.08.005
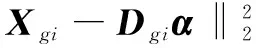
3 实 验

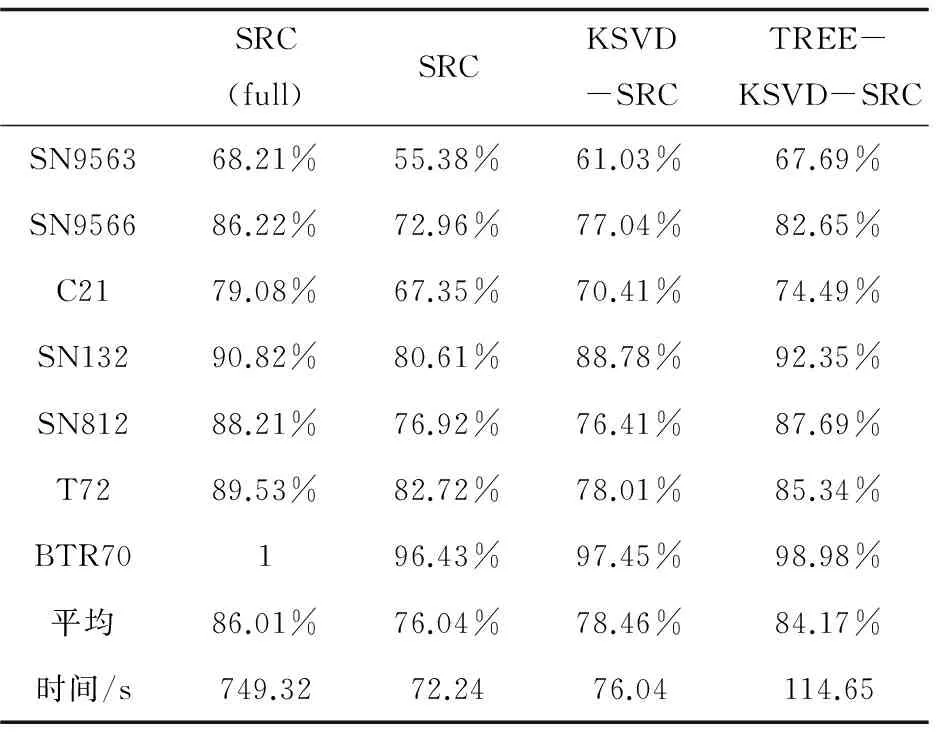
4 结束语
猜你喜欢
军民两用技术与产品(2021年12期)2021-03-09航天工业管理(2020年11期)2021-01-04航天工业管理(2020年9期)2020-12-28航天工业管理(2020年4期)2020-06-16电子技术与软件工程(2019年18期)2019-11-18小学阅读指南·低年级版(2019年11期)2019-07-01中国惯性技术学报(2018年4期)2018-11-08小天使·一年级语数英综合(2017年11期)2017-12-05电子技术与软件工程(2017年14期)2017-09-08读者(2016年14期)2016-06-29
