
基于划分的聚类在交通规划小区中的应用
2017-08-28 14:59刘彦斌温熙华刘云鹏程元晖方志远
物流科技 2017年8期
刘彦斌,智 伟,温熙华,刘云鹏,程元晖,方志远
(中电海康集团研究院,浙江 杭州 310012)
基于划分的聚类在交通规划小区中的应用
刘彦斌,智 伟,温熙华,刘云鹏,程元晖,方志远
(中电海康集团研究院,浙江 杭州 310012)
城市交通系统庞大而复杂,为保证交通管理的灵活性及鲁棒性,必须划分交通小区分而治之。针对现有的基于划分的聚类算法应用于交通规划小区存在的问题,文章基于交通特性定义了聚类有效性指标,进而设计了将模糊C均值聚类与K均值聚类相结合的交通小区划分算法。以吴江区为例,结合17万余条出租GPS数据,搭建GIS平台划分交通小区,验证了算法的有效性,进而可视化地分析了小区之间的交通OD,为城市交通运营、规划部门决策提供重要参考和依据。
交通小区;K均值聚类;模糊C均值聚类;聚类有效性指标;交通OD
0 引 言
城市交通系统是一个非线性、强耦合、离散、并具有随机特性的复杂大系统[1],很难直接对其建模分析。在这种情况下,交通小区应运而生,采用分而治之的思想:将复杂交通网络解耦为若干个交通子区,分别对每个子区进行诱导和控制,从而实现对整个交通的协调优化。这种内部具有一定交通关联度和交通相似度的交通子区就被定义为交通小区[2]。根据决策的层级不同,交通小区可分为面向交通控制的交通小区、面向交通诱导的交通小区以及面向交通规划的交通小区。交通小区的诞生一方面保证了交通管理的灵活性,可因地制宜地根据小区间的不同交通特性制定差异性的管理策略;同时也保证了整个交通系统鲁棒性,避免了单一控制中心瘫痪可能引发的灾难性损失。因此,交通小区划分在降低系统复杂性、提高交通管理效率方面具有重要的意义。
然而,现有的对交通小区的研究多停留在应用层面,缺乏对于交通小区划分理论的深入研究。目前交通小区的划分带有很大的主观性,往往根据行政单元或路网物理特性划分,而忽略了内在交通特征的影响。本文关注面向交通规划的交通小区,依据交通特征的空间分布特性,采用基于划分的聚类方法进行交通小区的自动划分,进而可视化地展现了小区间的OD,方便城市交通运营、规划部门宏观地了解居民出行分布状况,为公共交通线路规划、站点设置提供重要参考和依据。
1 基于划分的聚类方法介绍
聚类是机器学习中一种重要的非监督学习方法,其目的是将数据集中的样本划分为若干个通常不相交的子集,每个子集称为一个“簇”,每个“簇”可能对应一个潜在的概念。而基于划分的聚类又是聚类方法中的重要分支[3],其核心思想是定义代价函数来描述划分的进程,通过不断的试错,调整样本划分,将使得代价函数最小的划分作为最终的聚类结果。在划分中我们希望簇内样本比较相似,而簇间样本差异较大,代价函数则是定量表述这一目标的工具,不失一般性的,给出如下所示的代价函数:

其中:n为数据集样本个数;c为指定划分的簇个数;xj表示第j个数据样本;ci表示第i个簇的中心;d( ci, xj)表示第j个数据样本到第i个簇中心的“距离”,有闵可夫斯基距离、马氏距离及切比雪夫距离等;J表示代价函数,是c个簇的代价函数之和;Ji表示第i个簇的代价函数,其物理含义是数据集所有对象与第i个簇中心的加权距离;uij表示样本j归属于簇i的隶属度,自然的有:

至此,基于划分的聚类已抽象为一个带有约束条件的最优化问题了。然而,样本到簇中心“距离”的定义通常很复杂,式(1)属非凸优化问题,很难直接求得全局最优。因此,我们通常采用启发式算法,如最大期望算法(Exception Maximization Algorithm)、梯度下降法(Gradient Descent)等,来求得局部最优解。
在基于划分的聚类算法中,样本j归属于簇i的隶属度uij是一个很重要的参数,根据其设置的不同,基于划分的聚类可分为硬聚类及软聚类两大派系。在硬聚类中隶属度uij的取值非0即1,也就是说每个样本被硬性地划分到唯一一个簇中,具备“非此即彼”的特性,因而产生的簇不会发生重叠。在软聚类中隶属度uij可取0到1间的任意实数,也就是说样本以不同的概率被划分到各个簇中,这种“模糊”划分的特性就导致了产生的簇可能会发生重叠。
2 交通小区划分
交通小区是具有一定交通关联度和交通相似度的节点或连线的集合,同一小区内的交通状态应比较相近,而不同小区间的交通状态则应相差较大。居民出行的起讫点(Original&Destination points,OD)恰恰是交通小区作用下的外在表现,因而可以根据起讫点的集聚特性进行聚类操作,挖掘OD数据背后隐藏的交通小区分布规律。
常用的K均值聚类(K-means)属于硬聚类,这种硬性地簇划分是符合对于交通小区划分的需求的[4],然而K-means算法在实际应用中存在两大问题:一是聚类个数无法事先确定,也就是说待规划交通小区个数的选取具有盲目性;二是K-means算法严重依赖初始聚类中心的选取,不同的初始化参数直接导致聚类结果的不同,而事实上是无法提前获知交通小区的中心的。两方面的原因导致了以K-means为代表的硬聚类在交通小区划分中的局限性。
常用的模糊C均值聚类(FCM)属于软聚类,这种软性的划分虽运行速度较快,且不需要额外的初始化参数[5],但同样需事先指定小区个数,而且分类结果具有二义性,其产生的重叠的聚类结果不符合规划交通小区的需求,这也限制了以FCM为代表的软聚类在交通小区划分领域的应用。
可见,无论软聚类还是硬聚类都无法完全满足划分交通小区的需求。基于此,本文设计了将K-means与FCM相结合的改进算法。其基本思想是先利用FCM做初步划分,以此形成K-means的初始化参数,进而再由K-means做进一步精细划分。
本文采用的数据源为吴江2017.3.1~2017.3.7为期一周的出租车GPS数据,共177 927条记录。剔除异常记录,包括经纬度为空或为0、行程终点时间早于起点时间等明显异常的记录后,剩余153 035条有效数据,对应306 070个起讫点。之所以选择出租GPS数据作为数据源,一方面是因为,作为非通勤性出行的工具,出租车本身就代表性地反应了区民多样的出行需求;另一方面,利用出租的GPS数据可自动化地获取大量的OD,节省人工调查成本的同时保证了数据精度。
2.1 基于FCM的交通小区划分
FCM引入模糊聚类指数m来控制算法的柔性,本文中取定为2。将第j个数据样本到第i个簇中心的“距离”简记为dij,将隶属度 uij(c×n)记为隶属度矩阵U,则式(1)转化为:

同时,FCM需要满足式(2)所示的约束条件。为求解这个约束条件下的最优化问题,本文引入拉格朗日函数:
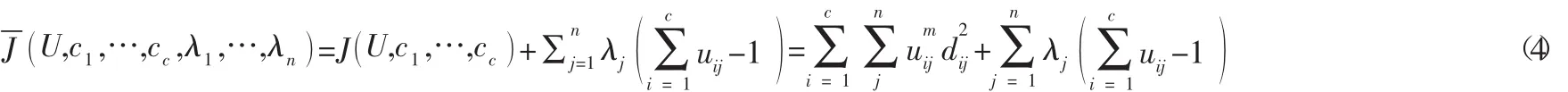
其中:λj是n个约束条件的拉格朗日乘子。对上式所有参量求导,得到代价函数J取极小值的必要条件:

至此,可以得到利用FCM进行交通小区划分的处理流程:
步骤一:在式(2)的约束条件下随机初始化起讫点的隶属度矩阵U。
步骤二:利用式(5)求解c个交通小区的中心。
步骤三:利用式(3)计算代价函数。如果代价函数相较于上一次运算的结果改变不大(差别小于给定阈值),则转至步骤五,否则进行步骤四。
步骤四:利用式(6)计算起讫点的隶属度矩阵U,其中dij取为欧式距离,结合步骤二中得到的交通小区中心位置容易求得。之后,返回步骤二。
步骤五:利用起讫点的隶属度矩阵U判定其所属的交通小区,结束算法。判定原则是:如果起讫点属于某交通小区的隶属度达到最大,则判定其属于该小区。
利用FCM划分交通小区,指定不同的交通小区个数,得到的结果如图1所示:
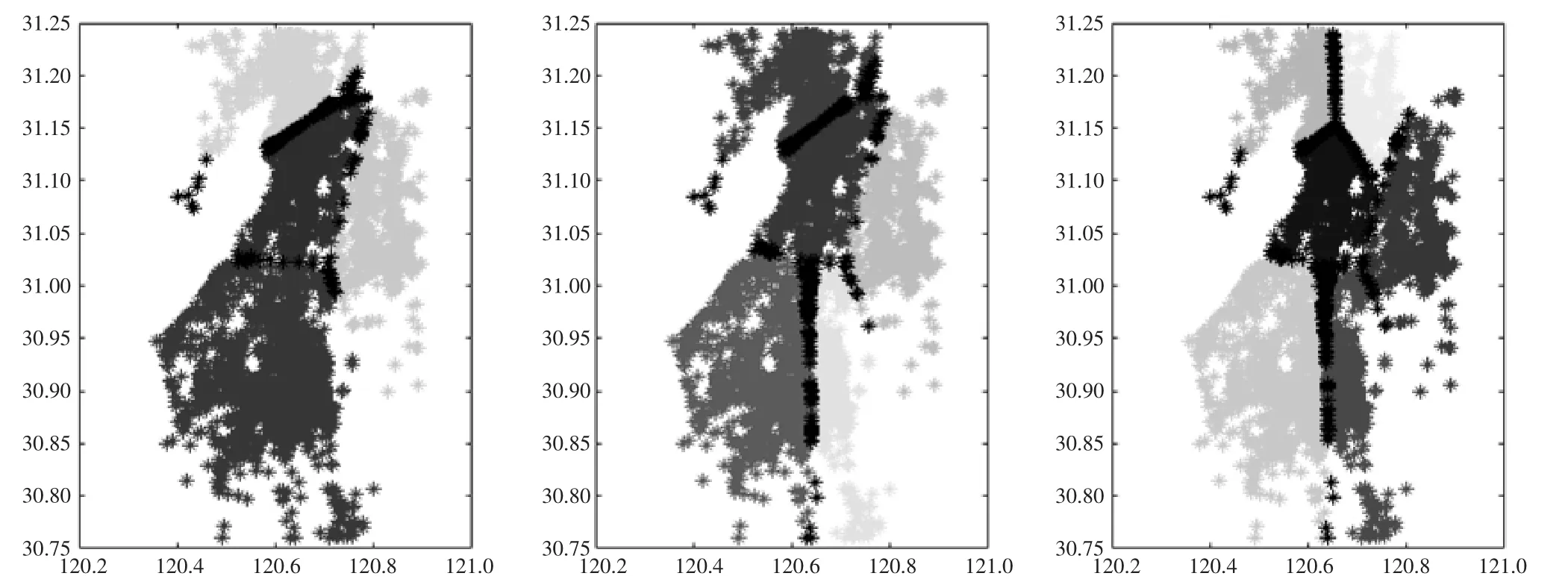
图1 吴江出租起讫点在不同交通小区个数下的FCM聚类结果
图1中每个星号点都代表一个真实的出租起讫点(横坐标为经度,纵坐标为纬度),利用FCM进行聚类,得到每个起讫点所属的交通小区,以不同颜色标识。该算法运行速度较快,且不需要额外参数。但是算法也存在两个问题,一是划分结果依赖交通小区个数的选取,如图1所示,从左至右依次给出了交通小区个数为4~6的划分结果,而在现实情况下,小区的个数很难事先确定;二是划分结果具有二义性,如上图黑色点标识的样本,由于在两个小区间的隶属度相等,算法判定其同时属于2个交通小区。换言之,算法产生了重叠的交通小区,不满足本文的应用场景。
2.2 基于K-means的交通小区划分
K-means中隶属度uij只能取0或1,为了加以区别定义二元指标rij∈ 0,{1,}表征样本j是否隶属于簇i,由式(2)不难得出:

式(1)中,样本和簇中心的距离取为欧式距离,则式(1)特化为:

要在式(7)的约束条件下使得J最小,已被证明为NP难问题,采用最大期望算法,得到迭代公式:

至此,可以得到利用K-means进行交通小区划分的处理流程:
步骤一:随机初始化c个交通小区的中心。
步骤二:利用式(9)求解二元指标rij,其物理含义即根据样本与各小区中心的距离判定其所属的小区。
步骤三:利用式(8)计算代价函数。如果代价函数相较于上一次运算的结果改变不大(差别小于给定阈值),则终止算法,否则进行步骤四。
步骤四:利用式(10)更新交通小区中心。之后,返回步骤二。
利用K-means划分交通小区,指定不同的交通小区个数、初始中心得到的结果如图2、图3所示。
该算法对所有起讫点做“非此即彼”的明确划分,但是也存在两个问题,一是划分结果依赖交通小区个数的选取,如图2所示,从左至右依次给出了交通小区个数为4~6的划分结果,而在现实情况下,小区的个数很难事先确定;二是划分结果额外依赖初始交通小区中心的选取,图3给出了不同初始化参数下的聚类结果,差异较大,因此为了避免K-means收敛到不同的局部最优解,必须合理地给出交通小区中心的初始化算法。
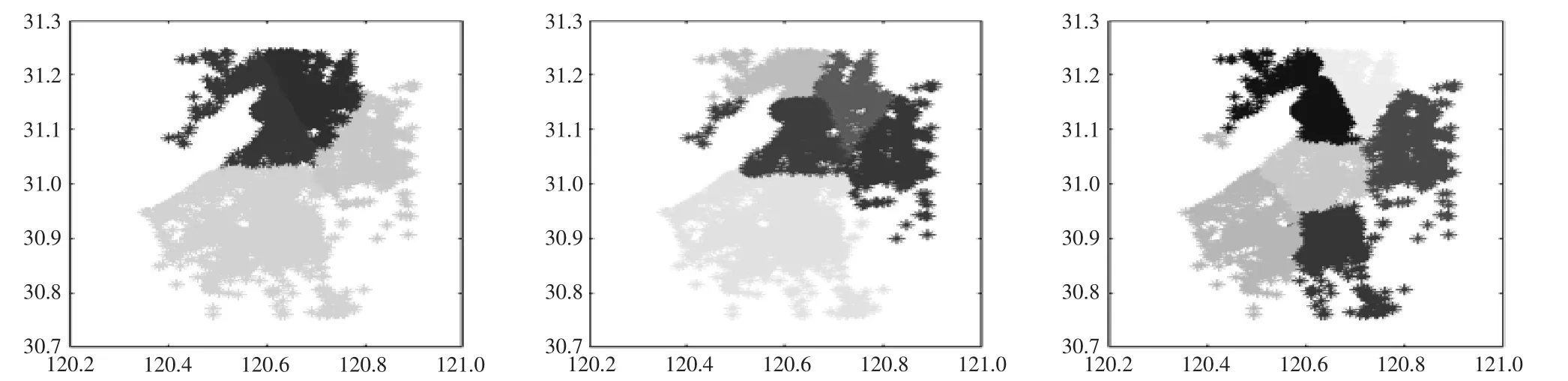
图2 吴江出租起讫点在不同交通小区个数下的K-means聚类结果
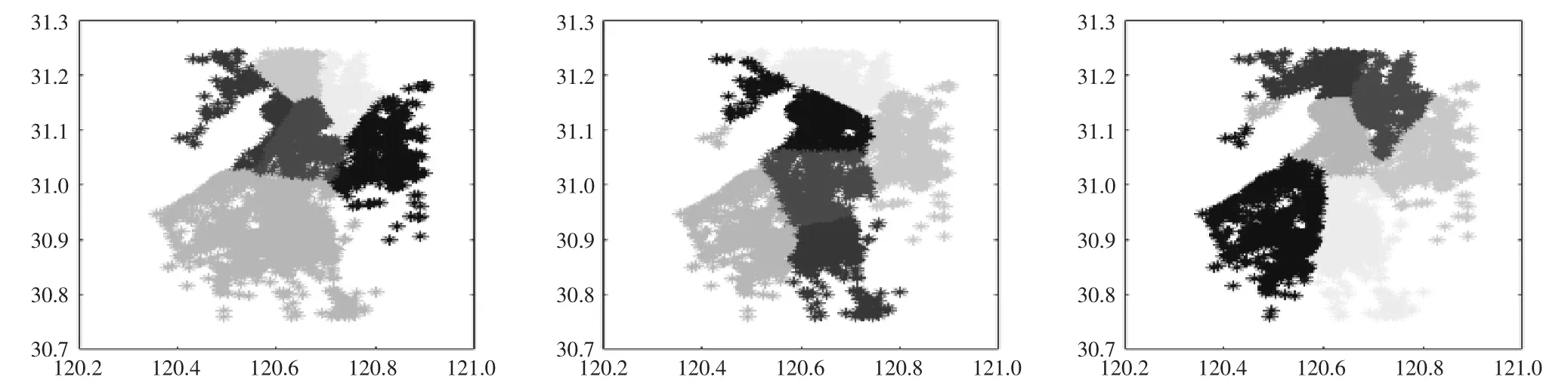
图3 吴江出租起讫点在不同初始交通小区中心下的K-means聚类结果
2.3 FCM与K-means相结合的交通小区划分
2.3.1 基于FCM确定交通小区的个数及中心。为了评价不同的聚类结果,首先要定义聚类有效性指标。常用有效性指标有:Calinski-Harabasz(CH)指标、Davies-Bouldin(DB)指标、以及Silhouette(S) 指标等,但上述指标的设计并未考虑交通特性,单纯的基于样本几何结构的评价并不适用于本文的应用场景。因此,定义了“划分系数”S作为有效性指标,综合考虑了区内通行量,区内及区间通行距离等因素,如式(11)所示:

其中:dij表示样本i到小区j中心的距离,nj为第j个交通小区内起讫点的个数,Rj为第j个交通小区的平均半径,n为全部起讫点的个数,可以看出Rinner是对Rj按通行量的加权平均,用于描述小区内部起讫点的紧密度,表征小区内交通的相似性。
pij为小区i中心与小区j中心的距离,Router是全部小区中心两两距离之和,用于描述各小区间的分离度,表征小区间交通的差异性。
我们希望划分的交通小区具有这样的特性:在同一小区内,交通特性应有很强的相似性,即Rinner要小;同时,不同小区间的交通特性应有足够的差异性,即Router要大,因此“划分系数”S越小,表征所对应的划分结果越优秀。
根据交通小区划分的相关文献[6]、结合小区划分的经验常识,给定吴江区交通小区个数的待选范围 2,1[ ] 0,利用FCM在不同的交通小区个数条件下进行聚类,并利用“划分系数”评价各聚类结果,得到图4。
可以看出,在2个小区的情况下,划分系数相对较大;随着交通小区个数的增加,划分系数迅速下降,当小区个数增至6时,划分系数取到极小值,表征最优的划分结果;继续增加小区个数,划分系数已不会明显变化,甚至增大。因此,本文选定吴江区交通小区的划分个数为6,此时FCM得到的6个交通小区中心如表1所示:

表1 FCM初步规划6个交通小区中心位置
2.3.2 基于K-means精细划分各个交通区。选定交通小区个数为6,并将FCM得到的6个交通小区中心位置作为K-means聚类的初始化参数,对吴江出租全部起讫点进行聚类,得到图5。
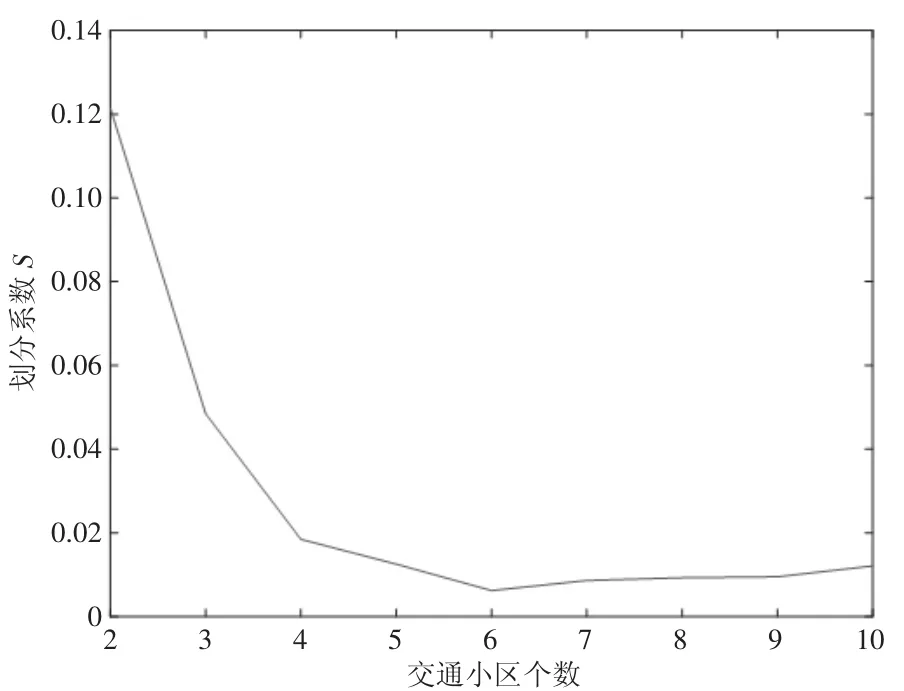
图4 FCM聚类划分系数随交通小区个数变化图

图5 以FCM得到的小区中心初始化K-means聚类结果
将上述改进算法与传统的FCM及K-means进行有效性对比,得到表2。由于传统K-means聚类结果依随机初始值的不同而变化,导致划分系数相应的波动,表中是多次聚类后的平均划分系数。

表2 不同聚类方法有效性对比
可以看出,改进算法对应的划分系数最小,意味着该划分得到的交通小区内具有相似的交通属性,同时不同小区之间的交通差异性也相对明显,因而是相对较优的算法。
2.3.3 搭建GIS平台生成交通小区边界。在聚类完成后,我们得到了所有起讫点所属的小区(以不同颜色标识),进而需要解决小区边界标定的问题。文献[4]提出基于样本与聚类中心的距离生成边界的算法,但方法过于粗糙,存在漏划区域,且默认所有小区都采用同样边数的多边形,显然不符合真实场景。
为保证划分的合理性,如无漏划、道路不被切割等,搭建GIS平台,通过纠偏将出租起讫点定位到地图上,以充分展示每个起讫点周围的道路属性,进而根据聚类结果精细划分小区边界。其划分原则是:由城市路网生成小区边界,且其内尽可能多的包含隶属于该小区的起讫点。将不同小区的起讫点以不同颜色标识在地图上,将地图放大至道路级别,筛选不同颜色起讫点的分界路段作为交通小区边界,如图6所示。
3 实例分析
针对吴江2017.3.1~2017.3.7为期一周的出租车GPS数据,采用本文所述的FCM与K-means相结合的交通小区划分算法,对全部起讫点做聚类分析,得到其隶属的小区ID;进而利用java搭建GIS平台,通过纠偏将全部讫点定位到地图上,根据起讫点周围的道路属性精细生成交通小区边界,得到图7(仅保留吴江区域):

图6 根据起讫点周围的道路属性生成交通小区边界

图7 吴江交通小区划分
划分交通小区后,利用出租车OD数据即可宏观分析城市居民出行分布状况,了解交通需求的空间特性,计算交通小区间的OD矩阵,得到表3。
表3内容的第i行第j列的元素表示由小区i到小区j的出行量。例如,第3行第5列的元素为4 758,表示一周内由小区3出发,到小区5的出租乘客共有4 758位。为了更直观地展示交通流量的空间流动特性,本文采用了弦图,如图8所示。
弦图的各弧代表各个小区,弧的角度大小代表以该小区为起点的OD量,弧被分为6种颜色,体现6个小区的交通属性。弦图的各弦代表两个小区之间的交通往来,如小区3、小区5间的弦,与小区3相连的一端代表小区3到小区5的OD量,与小区5相连的一端代表小区5到小区3的OD量,弦被分为36种宽度,一一对应于OD矩阵的每一个元素。因此,可以直观地看出:小区5是出行量最大的交通小区,小区4次之、小区6再次;小区5、6之间,小区3、5之间以及小区2、4之间的通行量相对较大。以上基于出租OD数据的聚类结果结合吴江土地利用布局也不难解释:吴江区委区政府所在地松林镇隶属小区6,苏嘉杭高速、沪苏浙高速、苏州绕城高速穿境而过,属交通枢纽;“丝绸重镇”盛泽镇坐落于小区4,很多国内外的商人需要来这里做交易;“中国特色商业街”永康路位于小区5,服装店、首饰店、购物中心林立其中,产生巨大的交通吸引。
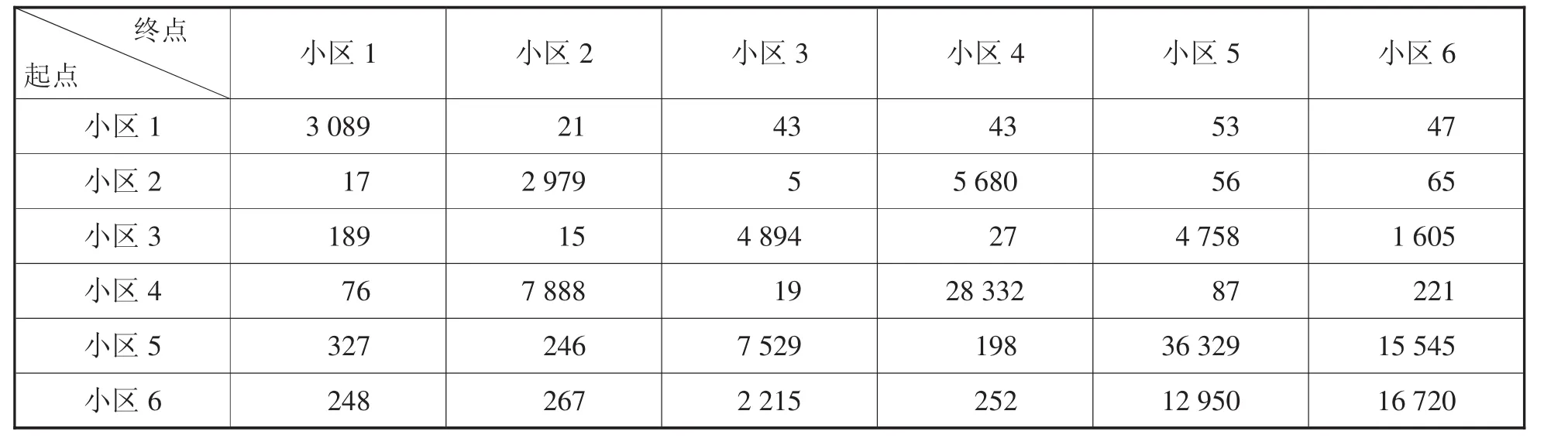
表3 交通小区间OD矩阵
因此,建议吴江区交管部门参考本文给出的交通小区划分结果,分区进行差异性地交通诱导和控制。同一小区内的交通特性较为相似,因而可以将全区的交通信号整合到一个系统,以保证全区的整体控制效益;不同小区间的交通特性相差较大,因而可针对性的选择定时式脱机操作或感应式联机操作等不同的控制系统。这种分而治之的策略,保证交通管理灵活性的同时,避免了单一控制中心瘫痪可能引发的灾难性损失。
另外,基于交通小区的交通特性分析还可为交通运营部门合理规划公交、公共自行车站点以及出租候客泊位提供依据,同时也可对交通规划部门进行公共交通线路规划、站点设置等提供参考。以吴江区为例,针对小区4、小区5这样出行流量较大的区域,可考虑增加公共自行车、出租车的分配比重以减缓出行压力,达到供需的动态平衡;针对小区5、6之间,小区3、5之间存在大流量区间通行的状况,可考虑规划相应的公交专线,以满足居民在不同小区间的出行需求。

图8 交通小区间OD弦图
4 结束语
交通小区划分是区域交通诱导控制以及城市规划的基础,是解析复杂城市交通网络的有利工具。居民出行的起讫点是交通小区作用下的外在表现,因而可以根据起讫点的集聚特性进行聚类,挖掘OD数据背后隐藏的交通小区分布规律。本文重点研究了基于划分的聚类方法,以K均值聚类为代表的硬聚类严重依赖初始聚类中心的选取,而以模糊C均值聚类为代表的软聚类可能产生重叠的交通小区,均不能完全契合划分交通小区的需求。
因此,本文设计了将模糊C均值聚类与K均值聚类相结合的交通小区划分算法。首先,指定交通小区个数的范围,对全部起讫点在不同小区个数的条件下进行模糊聚类,得到一系列聚类结果;然后,综合考虑区内通行量、区内及区间通行距离等因素,定义聚类有效性指标“划分系数”,对每个聚类结果评价其有效性,并选择有效性最高的聚类数作为最佳小区划分个数;最后,利用最佳聚类数、最佳模糊聚类中心初始化K-means算法,使其迅速收敛,克服了传统K-means算法需要人工定义交通小区个数以及小区中心初始值的盲目性。
以吴江区为例,结合17万余条出租GPS数据,搭建GIS平台,并利用上述算法划分交通小区。对比分析表明,所设计算法的划分系数为0.0048,明显优于传统的模糊C均值聚类及K均值聚类算法,从而验证了算法的有效性。在此基础上,可视化地分析了所划分的交通小区间的OD,可为城市交通运营、规划部门决策提供重要参考和依据。
[1] Richardson I E.Video Codec Design:Developing Image and Video Compression Systems[S].John Wiley&Sons Inc,2002.
[2] 李晓丹,杨晓光,陈华杰.城市道路网络交通小区划分方法研究[J].计算机工程与应用,2009,45(5):19-22.
[3] 包颖.基于划分的聚类算法研究与应用[D].大连:大连理工大学(硕士学位论文),2008.
[4] 吕玉强,秦勇,贾利民,等.基于出租车GPS数据聚类分析的交通小区动态划分方法研究[J].物流技术,2010,29(9):86-88.
[5] 刘乙霏.基于模糊聚类的交通小区划分方法研究[J].物流科技,2011,34(9):25-28.
[6] 郭峤枫.浅析交通小区划分问题[J].黑龙江科技信息,2010(28):270.
Application of Partition-based Clustering to Traffic Zone Planning
LIU Yanbin,ZHI Wei,WEN Xihua,LIU Yunpeng,CHENG Yuanhui,FANG Zhiyuan
(CETHIK Group Corporation Research Institute,Hangzhou 310012,China)
Nowadays,urban transport system is becoming ever more complex.In order to ensure the flexibility and robustness of traffic management,traffic zone must be divided so that it can be ruled separately.This article addresses problems on the application of partition-based clustering to traffic zone planning.The clustering validity index based on traffic characteristics is firstly defined,and then the algorithm for traffic zone division,combining fuzzy C-means cluster and K-means cluster,is proposed. Taking Wujiang district as an example,based on more than 170 000 GPS data of taxis,GIS platform is constructed to divide traffic zone,which verifies the effectiveness of the proposed algorithm.Finally,the traffic OD matrix between traffic zones is analyzed visually,as the outcome the important reference and basis for urban transportation operation and planning department could be obtained.
traffic zone;K-means cluster;FCM cluster;clustering validity index;traffic OD
F570
A
1002-3100(2017)08-0072-06
2017-06-05
工信部2016年工业转型升级(中国制造2025)项目,项目编号:0714-EMTC02-5737/5。
刘彦斌(1986-),男,湖南株洲人,中电海康集团研究院,车联网技术总监,硕士,研究方向:交通大数据、交通运输管理、交通流建模与仿真、交通系统分析。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
电子测试(2017年15期)2017-12-18
三月三(2017年9期)2017-09-27
三月三(2017年9期)2017-09-27
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
