
基于浅层句法分析和最大熵的问句语义分析*
2017-08-16 11:10李冬梅
计算机与生活 2017年8期
李冬梅,张 琪,王 璇,檀 稳
1.北京林业大学 信息学院,北京 100083
2.中国人民大学 信息学院,北京 100872
基于浅层句法分析和最大熵的问句语义分析*
李冬梅1+,张 琪1,王 璇2,檀 稳1
1.北京林业大学 信息学院,北京 100083
2.中国人民大学 信息学院,北京 100872
为了使中文问答系统能够准确高效地识别问句的语义,在构建生物医学领域本体的基础上,提出了一种基于浅层句法分析和最大熵模型的语义分析算法。该算法首先对自然语言问句进行语义块识别,如果识别成功,则形成问句向量,然后利用本体进行SPARQL查询;如果识别失败,则调用最大熵模型,判断问句的语义角色。最大熵模型利用标注好语义的熟语料进行训练,提取语义组块特征,从而判断出最可能的句型,形成问句向量,然后再利用本体进行查询,获取答案。通过实验与其他方法相比,新算法具有更高的查准率和召回率。
中文问答系统;本体;浅层句法分析;最大熵;SPARQL查询
1 引言
随着互联网的迅速发展,网络上的信息越来越丰富,而传统的搜索引擎只能返回与关键字信息相关或符合分类主题的网页。近年来,随着人工智能的崛起,问答系统的应用越来越广泛,它允许用户利用自然语言进行提问,然后通过相应的算法从数据库中提取出较为全面、准确的答案反馈给用户[1]。根据系统所能接受的问题领域,问答系统可以分为开放领域的问答系统和限定领域的问答系统[2]。例如,PowerAqua是一个较为典型的开放领域的问答系统[3],但因其知识库来自于不同的领域知识,数据总体噪音较大,使得其答案质量较低。AskHERMES则是一个基于医学领域的问答系统[4],通过对病人给出的较为复杂的问题进行语义分析,系统能够自动给出较为满意的答案,提高了诊断效率。因此,在实际应用中,构建一个特定领域的问答系统更具有使用价值。文献[5]通过构建医院信息本体,利用SPARQL(simple protocol and RDF query language)[6]查询技术在本体中进行查询,从而得到答案。在基于SPARQL查询技术的问答系统中,其难点在于将用户所使用的自然语言问句转化为基于逻辑的语义表示[7],即如何让计算机理解用户的查询目的,这就涉及到问句语义理解的问题。在计算机语言学中,对语言语义的分析一直以来都追求的是“全面”和“深层”,如文献[8]设计了一个依赖深度语言分析的问句系统,该系统首先手动为给定的本体构造描述其语义的词典,然后利用该词典来处理语义上比较复杂的问题。由于深层语义分析需要得到句子完整的句法树[9],分析效率较低。而与之相对,浅层句法分析追求的是“片面”和“浅层”,该方法只需要标注句子中的部分成分,不必详细地对整个句子进行语义分析,摒弃了深层成分和繁复的关系,从而在现实的语料环境下能够迅速分析,获得比深层分析更高的正确率[10-11]。文献[5]在问句的语义分析中采用了浅层句法分析,但其问句句型匹配不够丰富,匹配的正确率较低,而最大熵模型可以在一定程度上改进这种问题。
最大熵模型最先由DellaPietra等人引入到自然语言处理中,其包容性与灵活性以及处理结果的优异性吸引了许多研究人员的关注。近年来,最大熵模型被广泛地应用于多种语言的文本分类、纠错和词义标注等[12-15]。最大熵模型的基本思想是建立与已知事实一致的模型,对未知因素不作任何假设,从而可使未知因素尽可能地保持均匀分布。将最大熵模型的思想应用于问句分析中,可以使问句的匹配率有所提高,使问答系统能够匹配更丰富的问句类型。文献[16]将最大熵模型用于语义角色标注中,但在标注时因为没有结合句法分析,所以需要预测每一个随机事件的概率分布。为了提高预测的准确率,通常需要保留尽可能多的不确定性事件,因此算法的执行效率较低。
基于文献[5,16],本文提出了一种基于浅层句法分析和最大熵的中文问句语义分析算法SAM_SPME(semantic analysis method based on shallow parsing and maximum entropy)。该算法首先对问句进行浅层句法分析,识别失败后再调用最大熵模型进行分析,由于部分问句在浅层句法分析阶段就可提前正确识别,从而无需利用最大熵进行处理,这样便在一定程度上解决了最大熵执行效率较低的问题。将SAM_SPME算法用于自行构建的基于医学本体的中文问答系统中进行验证,实验结果表明,将浅层句法分析和最大熵相结合进行问句语义分析,有更高的查准率和召回率。
2 SAM_SPME算法
本文提出的SAM_SPME算法以自然语言为接口,利用医学本体,先采用浅层语义分析技术,将生物医学问句根据语义块定义规则和语义块判定规则进行语义块识别,若识别成功则生成问句向量,然后利用本体进行SPARQL查询;若识别失败,则调用最大熵模型,首先利用标注好语义的熟语料对最大熵模型进行训练,提取问句的语义组块特征,然后计算出特征的概率分布,通过建立的模型判断问句最可能的句型,将形成的问句向量送入到SPARQL查询模块中。如果依然没有成功识别句型,则将查询语句传至网页信息检索模块,网页信息检索模块调用Google Custom SearchAPI检索谷歌数据库。
2.1 浅层句法分析
句法分析的含义是:在识别问句句法结构以及辨析句中词义的基础上,推导出能反映该句语义的形式化表示。同面向开放领域的中文问答系统相比,针对特定领域的问答系统要进行查询的信息通常会限定在特定的范畴内,并且所输入的问句在特定领域内的特性将被强化,这些特性主要包括用词、语序等。下面给出定义生物医学信息领域的问句特征语义块以及语义块的识别规则。
2.1.1 语义块定义及识别
首先给出以下定义。
定义1(语义角色标注)根据生物医学领域的词义分类的标注集对句子中的各种成分做出相应的语义标记。
定义2(问句类型)根据问句疑问块的语义类型,将其分为不同的类型,记为QT。
定义3(语义块)问句中具有固定的语义,并且位置相对固定的部分语块,记为三元组[Block,Type,Value],其中:
(1)Block为所属语义块的名称,用相应英文简称标识;
(2)Type为所属的语义块类型(子块);
(3)Value在问句标记中,表示问句中该块的具体值。
语义块定义片段如表1所示。
在表1所列语义块定义原则的基础上,本文为语义块识别先建立领域词表,这样在识别问句信息时,可以采取词表匹配方法。如例句:“消化系统消化道呈现出恶心症状是得了什么病?”经过分词后,得到的结果如下:消化系统|消化道|恶心|得了什么病,然后进行语义块识别,得到4个语义块如下:
(1)[Block=AB,Type=AB_xt,Value=“消化系统”]
(2)[Block=AB,Type=AB_qg,Value=“消化道”]
(3)[Block=AVB,Type=AVB_bx,Value=“恶心”]
(4)[Block=QT,Type=cause,Value=“得了什么病”]
上例中[Block=AB,Type=AB_xt,Value=“消化系统”]块中,语义块为属性块AB,语义块类型(子块)为属性-发病系统AB_xt,其值为“消化系统”。[Block=AB,Type=AB_qg,Value=“消化道”]块中,语义块为属性块AB,语义块类型(子块)为属性-发病部位AB_qg,其值为“消化道”。[Block=AVB,Type=AVB_bx,Value=“恶心”]块中,语义块为属性块AVB,语义块类型(子块)为属性值-发病症状AVB_bx,其值为“恶心”。[Block=QT,Type=cause,Value=“得了什么病”]块中,语义块为问句类型块QT,语义块类型(子块)为问句类型cause,其值为“得了什么病”。
2.1.2 问句向量的生成
问句向量是利用基于特定规则的形式化语言来表示问句,不同的领域对问句向量的生成有着不同的要求。如上例在经过前期的相关处理后,可以得到语义块信息,再对信息进行分析,问句中的已知信息为“发病部位是消化系统中的消化道,具体症状为恶心”,未知信息为“cause(疾病名称)”。最后可生成问句向量QV,表示如下:
QV=(AB_xt=消化系统,AB_qg=消化道,AVB_bx=恶心,cause=?)

Table1 Semantic block definition fragments表1 语义块定义片断
在语义块能够正确识别并形成问句向量的情况下,可以利用其中的已知信息和未知信息执行第2.3节的SPARQL查询,如果不能正确识别则调用第2.2节的最大熵模型算法。
2.2 最大熵模型算法
最大熵模型在处理自然语言分类问题上的优势在于它可以联系上下文信息,其特征集不需要深层的语言学知识却仍然可以有效地近似表示语言关系的复杂性[17]。因此,本文利用最大熵模型来判断问句的语义角色,而进行语义角色标注最关键的工作是要构建出合适的问句特征库。本文根据生物医学领域的一般问句构造语料库,语料库中的每一行都是一条规则,每条规则包括多列数据,规则Rule形式化描述如下:
Rule::=〈Label〉〈FieldList〉
〈Label〉::=cause|symptom|drug|prevent_cure
〈FieldList〉::=interrogative|interro_noun|verb_interro_noun
上述规则中各个符号的含义如下:
Label位于规则的第一列,代表问句类型;
cause代表问句为病因类型,即询问疾病名称或者询问病因,已知信息可能有疾病的具体症状等;
symptom代表问句为症状类型,即询问某种疾病发病的具体症状或者其发病规律等;
drug代表问句为用药类型,即询问针对特定疾病应该使用的药物;
prevent_cure代表问句为防治类型,即询问针对特定疾病应该采取的预防或者治疗方法;
FieldList位于规则的第2至最后一列,为导致此结果产生的各个特征条件;
interrogative表示仅包括“疑问词;
interro_noun表示包括疑问词和名词;
verb_interro_noun表示包括动词、疑问词和名词。
在问句特征库中,每一条规则就等同于一个特征分布,可以通过总结训练语料库中的各种规则,抽取出问句特征的概率分布。给定一个训练语料库,定义变量Y={y1,y2,…,ym}为语义角色类型,即前文所提到的Label,变量X={x1,x2,…,xn}为一些特征条件因素所构成的向量,即FieldList,设num(xi,yj)为训练语料库中二元组(xi,yj)出现的次数,可以用式(1)进行概率估计:
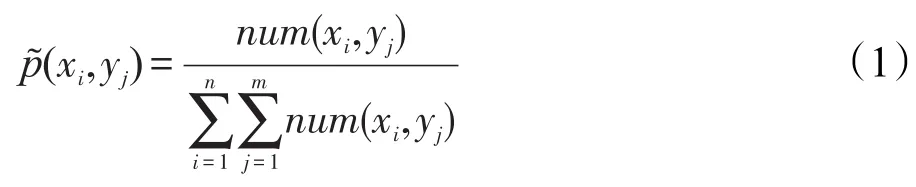
假设p(y|x)表示在系统中把某一句子成分判断为某一语义角色的概率值。最大熵模型的原理是找到一个p(y|x)在满足一定约束条件(由所给语料库中的信息计算出的特征概率分布)的情况下,熵必须取得最大值的模型,用式(2)描述:
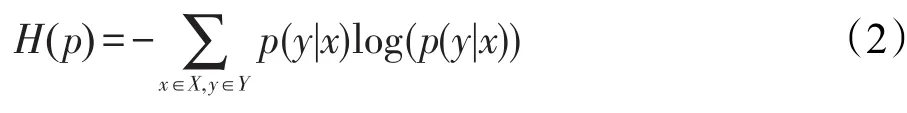
求解满足最大熵原则的概率分布分公式用式(3)描述:
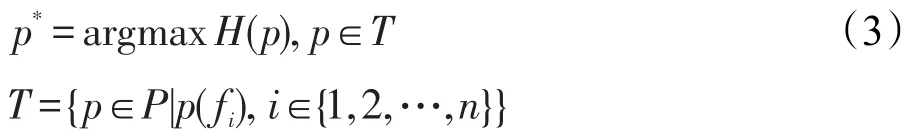
其中,p*为求解满足最大熵原则的概率分布;T表示所有可能满足约束条件的概率分布模型的集合;n为特征集中所有特征的总数;fi为特征函数。
在计算过程中,约束指的是最终预测出的结果句型的分布都必须满足之前对各个特征统计出的概率分布,具体约束条件如下:
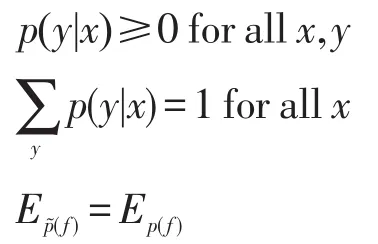
其中,Ep(f)为特征函数fi相对于经验概率p(x,y)分布的期望值;Ep(f)为特征函数fi相对于模型p(y|x)的期望值。这样最终的结果才能导致系统的熵最大,而最大熵只是保证了最终的预测结果符合之前计算出的所有概率约束。根据最大熵原理,通过拉格朗日乘数法,即可求出最优概率分布。概率值p(y|x)的取值符合式(4)描述的指数模型:
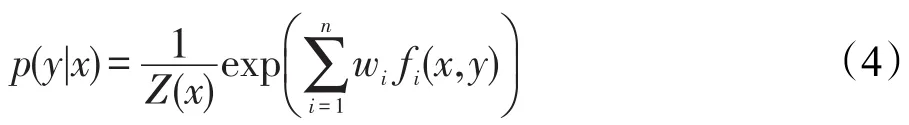
其中,Z(x)为归一化因子,如式(5)所示:
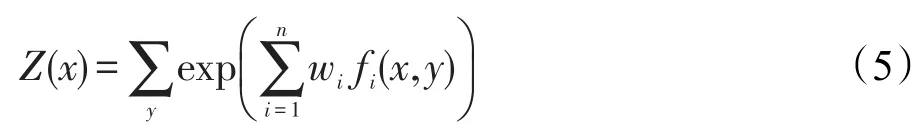
fi(x,y)为特征函数,用来表示向量(特征集)x语义角色(结果句型)y之间的关联,用式(6)描述:

wi(拉格朗日乘子)为权重,表示二值特征函数对于模型的重要程度,用式(7)描述。本文利用Darroch和Ratcliff迭代算法[18]求解参数值。
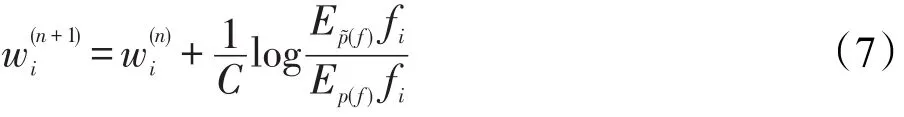
n为特征集中所有特征的总数。参数C等于语料库中某一规则所包含的最多特征数。Ep(f)表示特征函数fi(x,y)相对于经验概率分布p(x,y)的期望值,其计算方法如式(8)。Ep(f)表示特征函数fi(x,y)相对于模型分布p(y|x)的期望值,其计算方法如式(9)和式(10)。
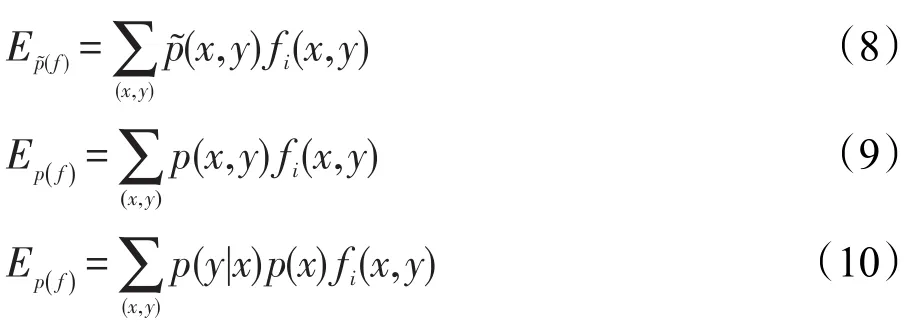
在给定语料库的特征集后,首要任务是基于语料库训练并计算每个特征的期望值,包括经验期望值和模型期望值,在所有满足限制条件的概率分布模型中,选取满足能够使熵值最大化的概率分布。
2.3 答案的抽取
在本文系统中,主要使用的答案抽取技术是借助Jena工具的Java API来实现的,通过Jena[19]调用SPARQL对生物医学领域本体进行基于RDF三元组的查询。
2.4SAM_SPME算法步骤
步骤1输入问句,由分词模块进行分词处理,并将处理结果传到语义分析模块。
步骤2语义分析模块首先根据分词的结果进行浅层句法分析,如果语义块正确识别,则执行步骤4,否则,执行步骤3。
步骤3调用最大熵模型算法,利用语义标注好的熟语料对最大熵模型进行训练,从而提取出问句的语义组块特征,然后计算出特征的概率分布建立模型,判断出最可能的句型。
步骤4判断句型是否匹配,匹配成功则执行步骤5,否则,执行步骤6。
步骤5形成问句向量,执行SPARQL查询,通过结果反馈模块将查询结果传递给用户。
步骤6将查询语句传至网页信息检索模块,网页信息检索模块调用Google Custom Search API检索Google数据库,通过结果反馈模块将答案传递给用户。
具体的SAM_SPME算法流程如图1所示。
3 实验结果及分析
3.1 实验指标的选取
一般中文问答系统的评估主要选用查准率(Precision)和召回率(Recall)两个实验指标,它们是语义查询过程中两个十分重要的度量值。除此之外,本文还选择了另一个度量指标——F测度值(F-Measure,又称为F-Score)来评估SAM_SPME算法的有效性,F测度值是Precision和Recall加权调和的平均值,其综合了Precision和Recall的结果,当F测度值较高时则说明实验方法比较有效。3个实验指标的计算公式如下:
(1)查准率

在式(13)中,一般令参数α=1,即F0是最常见的情况,如式(14)所示:

3.2 实验结果分析
本文从百度知道抽取cause、symptom、drug、prevent_cure 4类共476个生物医学问句作为标准测试集来进行实验,其中prevent_cure型93个,drug型124个,cause型134个,symptom型125个。对浅层句法分析与最大熵模型算法结合的查询效果进行展示,以说明本文算法的有效性。在实验过程中,为式(4)设置阈值0.75,即计算出的概率需大于0.75才能判定为最终句型,实验结果如表2所示。
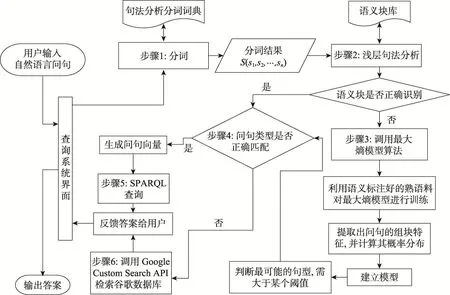
Fig.1 Flow chart of SAM_SPME algorithm图1 SAM_SPME算法步骤流程图
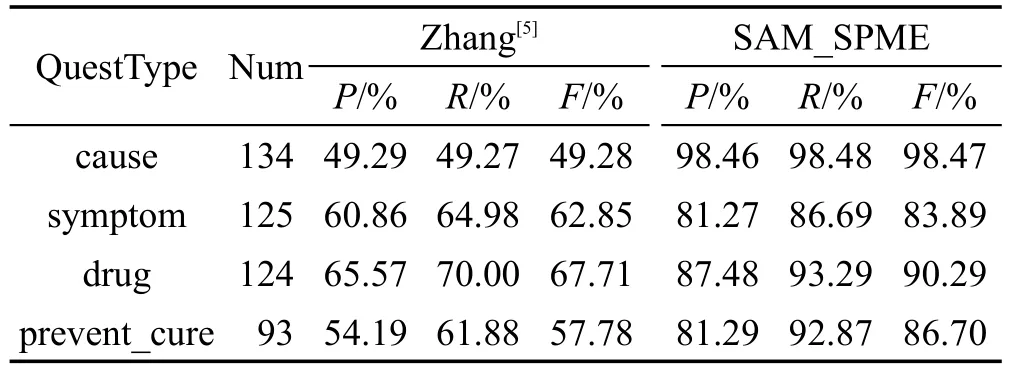
Table2 Experimental results表2 实验结果
表2中,“QuestType”表示问句类型;“Num”表示该种类型问句的数量;“Zhang”表示文献[5]浅层语义分析算法的实验结果;“P”表示实验结果的查准率;“R”表示实验结果的召回率;“F”表示测度值。为了便于更加直观地观察SAM_SPME算法的有效性,将文献[5]的浅层句法分析算法与本文的SAM_SPME算法的F测度值进行对比,其对比结果的柱状图如图2所示。从表2的计算结果中可以看出,本文将浅层句法分析与最大熵模型结合的算法十分有效,与文献[5]的浅层句法分析算法相比,SAM_SPME算法针对4类问句类型的查准率和召回率都在80%以上,两者都高于文献[5]的实验结果。综合考虑查准率和召回率再计算出F测度值,SAM_SPME算法针对4类问句类型的F测度值都在80%以上,也高于文献[5]。由此可见,SAM_SPME算法通过调用最大熵模型弥补了文献[5]问句句型匹配不够丰富,匹配的正确率较低的不足,而通过提前利用浅层句法分析进行识别,又可改进最大熵模型执行效率较低的缺点。浅层句法分析和最大熵模型相结合提高了语义查询过程中的查准率和召回率,且可以为用户所接受。
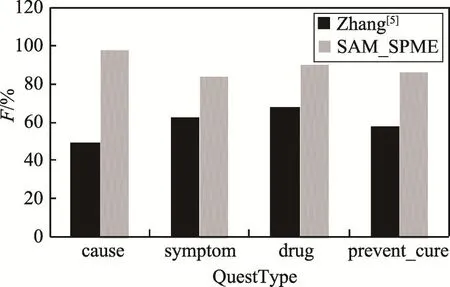
Fig.2 Comparison of F-Measure图2 F测度值对比
由表2可以看出,prevent_cure型问句和symptom型问句的查准率、召回率要低于cause型问句和drug型问句,出现这种现象的原因分析如下:
(1)训练集不够大,提取特征不够全面,导致调用最大熵模型时判断句型出现错误。
(2)cause型问句和drug型问句本身的特征要比prevent_cure型问句和symptom型问句更鲜明,更容易获取。
4 结束语
本文以生物医学领域数据为研究对象,在文献[5,16]的基础上提出了一种基于浅层句法分析和最大熵模型的语义分析算法,并将该算法用于基于医学本体的中文问答系统中进行验证。实验表明该算法可行,对自动问答系统的设计具有借鉴意义和深入研究的价值。今后的研究重点将放在如何集成各种知识,包括词性、语义、搭配和共现等,以提高短语识别的查全率和精确率。因为最大熵方法善于将各种不同的知识结合起来,所以希望能通过知识的集成,在最大熵方法的框架下,达到更好的识别效果。
[1]Hirschman L,GaizauskasR.Natural language question answering:the view from here[J].Natural Language Engineering,2001,7(4):275-300.
[2]Mao Xianling,Li Xiaoming.Asurvey on question and answering systems[J].Journal of Frontiers of Computer Science and Technology,2012,6(3):193-207.
[3]López V,Fernández M,Motta E,et al.PowerAqua:supporting users in querying and exploring the semantic Web[J].Semantic Web,2012,3(3):249-256.
[4]Cao Yonggang,Liu Feifan,Simpson P,et al.AskHERMES:an online question answering system for complex clinical questions[J].Journal of Biomedical Informatics,2011,44(2):277-288.
[5]Zhang Wei,Chen Junjie.Application of shallow semantic analysis and SPARQL in question answering system[J].Computer Engineering andApplications,2011,47(2):118-120.
[6]W3C.SPARQL query language for RDF[EB/OL].(2006)[2017-03-10].http://www.w3.org/TR/rdf-sparql-query.
[7]MoussaA M,Abdel-KaderR F.QASYO:a question answering system for YAGO ontology[J].International Journal of Database Theory andApplication,2011,4(2):99-112.
[8]Unger C,Cimiano P.Pythia:compositional meaning construction for ontology-based question answering on the semantic Web[C]//LNCS 6716:Proceedings of the 16th International Conference on Applications of Natural Language to Information Systems,Alicante,Spain,Jun 28-30,2011.Berlin,Heidelberg:Springer,2011:153-160.
[9]Ballesteros M,BohnetB,Mille S,et al.Deep-syntactic parsing[C]//Proceedings of the 25th International Conference on Computational Linguistics,Dublin,Ireland,Aug 23-29,2014.Stroudsburg,USA:ACL,2014:1402-1413.
[10]Sun Zhijun,Zheng Quan,Yuan Jing,et al.Semantic retrieval based on shallow semantic analysis technology[J].Computer Science,2012,39(6):107-110.
[11]Devadath V V,Sharma D M.Significance of an accurate sandhi-splitter in shallow parsing of dravidian languages[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics-Student Research Workshop,Berlin,Germany,Aug 7-12,2016.Stroudsburg,USA:ACL,2016:37-42.
[12]El-HaleesA M.Arabic text classification using maximum entropy[J].The Islamic University Journal:Series of Natural Studies and Engineering,2015,15(1):157-167.
[13]Murata M,Uchimoto K,Utiyama M,et al.Using the maximum entropy method for natural language processing:category estimation,feature extraction,and error correction[J].Cognitive Computation,2010,2(4):272-279.
[14]Straková J,Straka M,Hajic J.Open-source tools for morphology,lemmatization,POS tagging and named entity recognition[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics:System Demonstrations,Baltimore,USA,Jun 22-27,2014.Stroudsburg,USA:ACL,2014:13-18.
[15]Lv Yuanyuan,Deng Yongli,Liu Mingliang,et al.Automatic error checking and correction of electronic medical records[C]//Proceedings of the 2015 International Conference on Fuzzy System and Data Mining,Shanghai,Dec 12-15,2015:32-40.
[16]Liu Ting,Che Wanxiang,Li Sheng.Semantic role labeling with maximum entropy classifier[J].Journal of Software,2007,18(3):565-573.
[17]Xu Yanyong,Zhou Xianzhong,Jing Xianghe,et al.Chinese sentence parsing based on maximum entropy model[J].Acta Electronica Sinica,2003,31(11):1608-1612.
[18]Darroch J N,Ratcliff D.Generalized iterative scaling for log-linear models[J].The Annals of Mathematical Statistics,1972,43(5):1470-1480.
[19]BRESTOL.Jena2:a semantic Web framework[EB/OL].(2008)[2017-03-10].http://Jena.Sourceforge.net.
附中文参考文献:
[2]毛先领,李晓明.问答系统研究综述[J].计算机科学与探索,2012,6(3):193-207.
[5]张巍,陈俊杰.浅层语义分析及SPARQL在问答系统中的应用[J].计算机工程与应用,2011,47(2):118-120.
[10]孙志军,郑烇,袁婧,等.基于浅层语义分析技术的语义检索[J].计算机科学,2012,39(6):107-110.
[16]刘挺,车万翔,李生.基于最大熵分类器的语义角色标注[J].软件学报,2007,18(3):565-573.
[17]徐延勇,周献中,井祥鹤,等.基于最大熵模型的汉语句子分析[J].电子学报,2003,31(11):1608-1612.
Semantic Analysis of Question Based on Shallow Parsing and Maximum Entropy*
LI Dongmei1+,ZHANG Qi1,WANG Xuan2,TAN Wen1
1.School of Information Science and Technology,Beijing Forestry University,Beijing 100083,China
2.School of Information,Renmin University of China,Beijing 100872,China
+Corresponding author:E-mail:lidongmei@bjfu.edu.cn
LI Dongmei,ZHANG Qi,WANG Xuan,et al.Semantic analysis of question based on shallow parsing and maximum entropy.Journal of Frontiers of Computer Science and Technology,2017,11(8):1288-1295.
In order to improve the accuracy and effectiveness of question semantic recognition in question answering system,this paper presents a semantic analyzing algorithm combining shallow parsing and the maximum entropy on the basis of constructing biomedical domain ontology.Firstly,natural language questions are identified by semantic blocks.If the recognition is successful,the question vectors are formed,and then the SPARQL query is performed on the ontology.Otherwise,the maximum entropy model is invoked to judge the semantic role of the question.The maximum entropy model is used to train annotated corpus,which extracts the semantic block features to determine the most probable sentence pattern and form question vector,and then query through ontology to get the answers.Finally,compared with other methods,the novel algorithm has higher precision and recall rate.
Chinese question answering system;ontology;shallow parsing,maximum entropy;SPARQL query
2017-04,Accepted 2017-06.

ZHANG Qi was born in 1991.She is an M.S.candidate at School of Information Science and Technology,Beijing Forestry University.Her research interests include intelligent information retrieval and natural language processing.张琪(1991—),女,山东滨州人,北京林业大学信息学院硕士研究生,主要研究领域智能信息检索,自然语言处理。

WANG Xuan was born in 1992.She is an M.S.candidate at School of Information,Renmin University of China.Her research interest is data mining.王璇(1992—),女,江苏淮安人,中国人民大学信息学院硕士研究生,主要研究领域为数据挖掘。

TAN Wen was born in 1994.Now he is an M.S.candidate at School of Information Science and Technology,Beijing Forestry University,and the member of CCF.His research interests include machine learning and knowledge graph.檀稳(1994—),男,安徽安庆人,北京林业大学信息学院硕士研究生,CCF会员,主要研究领域机器学习,知识图谱。
A
:TP274
*The Fundamental Research Funds for the Central Universities of China under Grant No.TD2014-02(中央高校基本科研业务费专项资金);the National Natural Science Foundation of China under Grant No.61602042(国家自然科学基金).
CNKI网络优先出版:2017-08-02,http://kns.cnki.net/kcms/detail/11.5602.TP.20170802.1631.002.html
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2017/11(08)-1288-08
10.3778/j.issn.1673-9418.1706033
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
猜你喜欢
建材发展导向(2021年24期)2021-02-12
装备制造技术(2020年3期)2020-12-25
矿产勘查(2020年11期)2020-12-25
环境影响评价(2020年5期)2020-12-02
现代电子技术(2018年16期)2018-08-21
电机与控制学报(2018年9期)2018-05-14
现代电子技术(2017年23期)2017-12-20
科技视界(2016年19期)2017-05-18
计算机应用(2016年10期)2017-05-12
中国工程咨询(2017年3期)2017-01-31
