
Hadoop环境下图像内容检索方法的研究
2017-07-19 10:05:52石祥滨钟刘倍张德园
沈阳航空航天大学学报 2017年3期
石祥滨,钟刘倍,张德园
(1.沈阳航空航天大学 计算机学院,沈阳 110136;2.辽宁大学 信息学院,沈阳 110036)
信息科学与工程
Hadoop环境下图像内容检索方法的研究
石祥滨1,2,钟刘倍1,张德园1
(1.沈阳航空航天大学 计算机学院,沈阳 110136;2.辽宁大学 信息学院,沈阳 110036)
近年来,随着互联网技术的发展,图像数据呈现爆炸式增长,图像检索已成为广泛关注的热点问题。提出一种基于Hadoop和ElasticSearch的多特征融合图像检索方案。为实现分布检索,该方案给出了视觉词典生成、图片向量化和多维倒排索引的构建方法。为了提高检索精度,设计了RootSIFT、颜色矩、Gabor特征,给出了三种特征融合方法。在Corel-1000标准图像库和ILSVRC2015数据集上的实验结果表明,该方案在分布式平台上具有较快的响应速度以及较高的检索精度。关键词: 云平台;特征融合;CBIR;分布式计算
作为一种常见的、内容丰富的数据存储形式,图像中所蕴含的信息往往比文字描述所包含的信息要更丰富直观。随着互联网和多媒体技术的不断发展,图像数据呈现爆发式增长态势,图像检索技术[1]已成为大数据时代的重要课题。传统单一节点图像检索方法的研究对精度和速度都有所提高,如文献[2]中结合了反映局部区域变化的像素点颜色复杂度,对子块颜色直方图进行加权处理;文献[3]中提出一种使用改进的倒排索引、相关性反馈和区域加权的基于区域的图像表示和比较的框架。但随着数据规模的爆发式增长,单节点架构的图像检索系统出现并发性差、速度慢、稳定性和实时性无法保障等问题[4]。因此,一种能够实现海量图像中精确而快速检索的图像检索技术成为研究热点。
云计算的发展过程一直与大数据处理密切相关,因此利用云计算平台来实现大规模的图像检索技术是一个非常有潜力的方向[5]。王梅等人提出一种基于Hadoop的图像检索方法,将图像检索技术与MapReduce框架相结合,图像特征库存储于分布式文件系统HDFS(Hadoop Distributed File System)中,计算节点采用基于Hadoop的分布式存储调度算法,增强对多数据的并发处理能力[6]。Raju[7]等基于MapReduce框架实现了LTrPs(Local Tetra Patterns)算法,提高了检索效率。但Hadoop强大的分布式计算能力更加适合离线数据的处理,在实时检索方面有所欠缺,文献[6-7]中都没有充分发挥集群分布式的效果,如文献[6]中当数据量达到80万图像时,4个节点的检索效率为单节点的2.21倍,与理论上最高效率4.0倍有不少差距。针对这个问题,本文在Hadoop中引入了ElasticSearch,共享HDFS分布式文件系统,实现分布式的实时检索。
单一特征很难表达出图像所包含的丰富信息,如颜色特征对图像本身尺寸、方向、视角依赖较小,但是只能描述图像的颜色分布,忽略了其他信息。综合利用颜色、纹理、形状和空间关系等特征可以有效解决这个问题。Kong[8]提出的基于颜色直方图特征和颜色共生矩阵纹理特征的融合算法与Sudhir等[9]提出的基于小波变换组合颜色特征和纹理特征,都是在特征级进行融合,提高了检索精度。张永库等[10]提出一种基于底层特征综合分析算法(CAUC,Comprehensive Analysis based on the Underlying Characteristics)的特征融合算法,在保证较高检索速度的同时提高查准率与查全率。虽然这些特征融合方案提高了检索效率,但是在融合生成新的特征过程中对原特征信息有所破坏,对此本文提出一种基于决策层的图像特征融合算法,主要研究多特征融合过程中权值分配的问题。朱为盛[11]等人使用SURF(Speeded Up Robust Features)特征,提出了一种基于传统视觉词袋模型和MapReduce计算模型的大规模图像检索方案,该方案具有优良的加速比、扩展率以及数据伸缩率。史亚东[12]等人使用SIFT(Scale Invariant Feature Transform)特征,实现了基于Hadoop的并行化图像检索方法,相对于传统图像检索在效率上有所提高。
综上,针对图像检索问题,为了在检索精度较高的情况下提高图像检索的效率,本文提出一种基于Hadoop+ElasticSearch云计算平台的多特征融合图像检索方案。
1 系统结构
本文图像检索系统结构如图1所示,主要分为两个部分,分别是MapReduce图片特征预处理和ElasticSearch构建多维倒排索引实现检索。检索前对图片库中的图片提取RootSIFT特征、颜色矩特征、Gabor特征;对提取的特征分别聚类生成各自的视觉词典并且对图片进行向量化;然后利用ElasticSearch建立三维倒排索引,每一维对应一种图像特征,在索引的层次上进行特征融合。检索时,先利用视觉词典将待检索图片向量化,然后通过倒排索引返回相似图片的结果。
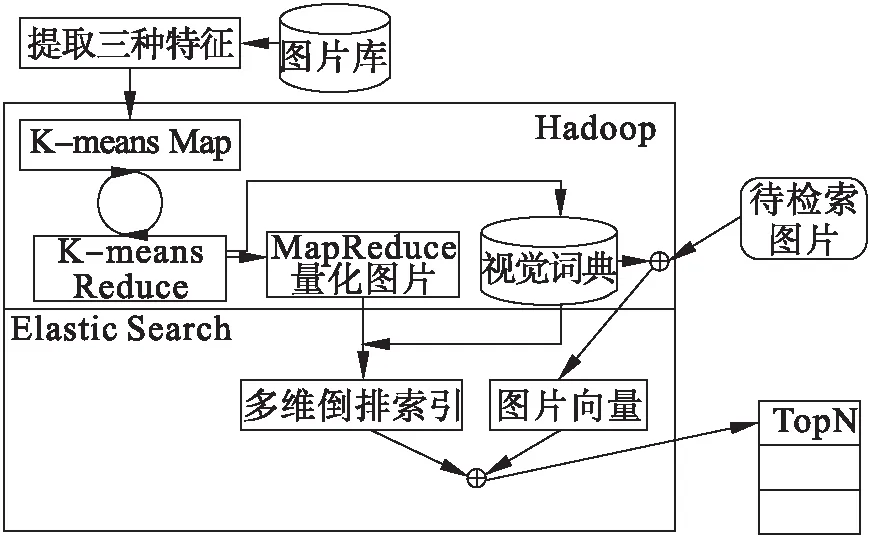
图1 系统结构
2 特征提取
特征的质量和匹配识别能力对图像检索的性能有很大的影响,为了提高检索精度,本文设计使用多特征融合的检索方案,采用RootSIFT特征、颜色矩特征、Gabor小波变换分别表示图像的梯度、颜色和纹理,在决策层进行特征融合。
2.1 RootSIFT特征
David G.Lowe提出了一种具有尺度不变性、旋转不变性、亮度不变性的局部图像特征,即尺度不变特征转换SIFT[13-14]。SIFT特征是一个比较成熟的图像局部特征,能够描述图像的局部梯度信息分布,在图像检索与分类、目标跟踪、图像拼接等领域都有着出色的表现。
针对传统的SIFT特征,在相似度度量的过程中使用欧氏距离的计算方式,在图像检索时会造成一定的匹配偏差和性能损失的问题。Arandjelovic和Zisserman[15]提出了一种SIFT特征的变体,即RootSIFT特征,RootSIFT特征向量在欧氏距离空间内的计算等价于SIFT特征在Hellinger核空间的巴氏距离计算,更具鲁棒性且具有更优的视觉匹配性能。SIFT特征到RootSIFT特征的转换可以简单方便地实现,计算算法如下所示。
Step 1:计算SIFT描述符
Step 2:L1归一化每个SIFT特征向量。
Step 3:取SIFT向量中每个元素的平方根。
Step4:L2归一化所得向量。
最终得到的RootSIFT特征是一个128维的向量,其表示形式为TR=(k1,k2,…,k128)。
本文采用欧式距离作为两个RootSIFT特征向量之间的相似性度量。
2.2 颜色矩特征
颜色矩[16]是由Stricker和Orengo所提出的一种非常简单而有效的颜色特征。其思想是图片的颜色信息主要集中在低阶矩中,故用颜色的一阶均值矩、二阶方差矩和三阶斜度矩表示图像的颜色分布。三个颜色矩的数学定义如公式(1)~(3)所示。
(1)
(2)
(3)
其中,pi,j表示彩色图像第i个颜色通道分量中灰度为j的像素出现的概率,N表示图像中的像素个数。相对于其他颜色空间,HSV颜色空间更能表达出人类肉眼观察到的主观色彩信息,本文采用HSV颜色空间下的颜色矩作为颜色特征,三个颜色分量的三阶矩组成的特征形式为Tc=(μ1,σ1,s1,μ2,σ2,s2,μ3,σ3,s3)。本文使用曼哈顿距离进行颜色矩相似度度量。
提取颜色矩特征时,为了解决颜色空间分布较散的问题,本文将图像分为5*5个子图像,然后每个子图像分别计算颜色矩作为局部特征。每一个子图像的特征反映了颜色的局部分布信息,而所有块的空间分布,又反映了图像内容的颜色结构,相对于使用全局的颜色矩特征,分块颜色矩更能反映出图像的颜色布局。
2.3 Gabor小波变换的纹理特征
对于图像纹理内容,本文选择使用频谱法提取图像的纹理特征,主要以傅里叶变换、小波变换、Gabor变换等频域变换为基础,在频域中使用能量分布相关属性形成纹理特征向量,以此来描述图像的纹理特征。傅里叶变换只能从整体上分析信号的特征,缺乏对局部特征的分析能力,而Gabor变换可以很好地获取图像时域信号的局部特征,也能更好地符合人类的视觉感知,有助于提高图像检索的准确性。
因此本文使用具有多分辨率分析能力的Gabor滤波器提取纹理特征,用于特征融合以获取更多的图像内容信息。本文实验中,考虑了5种不同的尺度和6种不同的方向,最后形成的纹理特征向量为TG=(μ00,σ00,μ01,σ01,…,μ45,σ45)。
其中,μmn和σmn表示变换系数能量分布的均值和标准差,m∈[0,M-1],n∈[0,N-1]。本文中,M=5和N=6分别对应5种尺度和6种方向。每张图像提取Gabor纹理特征时,都先几何分块,分为4*4个子图像,然后分别进行Gabor滤波提取特征作为图像的局部特征。
(4)
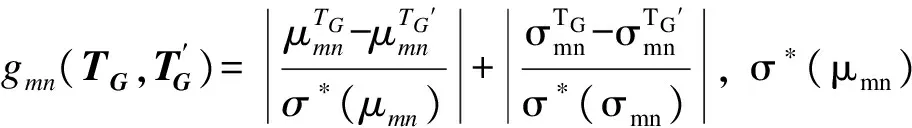
3 分布式多特征图像检索
针对大规模图像检索问题,本文在传统Hadoop基础上引入ElasticSearch,实现基于Hadoop+ElasticSearch的多特征融合系统。
3.1 视觉词典生成
通常图像特征都是多维的,如RootSIFT特征128维,而每张图像通常包含成百上千甚至上万个局部特征向量,在进行相似度度量时,计算量非常庞大。为了简化计算,提高运算效率,通过聚类算法对特征向量数据进行聚类,用聚类中的一个簇表示视觉单词,所有聚类中心簇的集合表示视觉词典[17](码本),然后每一张图像用一个码本矢量来描述。本文采用K-means算法分别对三个特征进行聚类,生成各自的特征库。目标函数如公式(5)所示。
(5)
其中E表示最小化误差,E值越小则簇类特征相似度越高。dist(ci,x)表示聚类中心集合中第i个聚类中心与待聚类点x的距离,实验中即表现为两个特征之间的距离度量。不同的特征之间度量方式不同,具体如第4节所示。
算法的流程主要包括,首先随机选择集合中的k个点作为初始的聚簇中心,再根据将集合中的每个点分配到距离它最近的聚簇中,最后根据每个聚簇中的数据点更新聚簇中心,如此反复地执行后两个步骤直到算法收敛。通过调用MapReduce任务来实现重复的迭代过程,每调用一次Map/Reduce计算对应一次迭代。K-means聚类的MapReduce算法如算法1所示:

算法1K⁃means聚类的MapReduce算法 输入:图片库中提取的任意一种特征向量集 输出:图片包含特征及其特征所属聚类中心的描述文件a和视觉词典描述文件b step1:Map每读取一个特征向量与所有中心点(初始中心点为随机选取的K个特征向量)对比,求出该向量对应的中心点,输出
其中cluster_id代表视觉单词编号,簇中心cluster_vector即代表视觉单词,所有的cluster_vector合在一起构成视觉词典。
3.2 图片的向量化
图片的向量化就是将每一张图片表示成一个向量,向量的每一个分量对应视觉词典中的视觉单词,分量的值表示该视觉单词在该图片中出现的次数。利用聚类后生成的描述文件通过Map/Reduce实现不断的迭代将原始文件中的每个特征用其所属的视觉单词表示,并用类似直方图统计的方式用一个K维的向量表示一张图片。

算法2图片的向量化 输入:图片任意一种特征向量集及相应描述文件a 输出:相应特征的图片特征库 step1:Map读取图片向量及算法1中生成的描述文件a,找出该向量对应的视觉单词; step2:用视觉单词向量替换原特征向量,输出
3.3 ES构建索引
ElasticSearch[18-19]用倒排索引的结构来做快速的全文搜索。倒排索引由在文档中出现的唯一的单词列表,以及对于每个单词在文档中的位置组成。

算法3ES创建索引 输入:视觉词典描述文件b和图片向量化后文件 输出:索引文件 step1:从HDFS中获取视觉词典描述文件b和图片向量化后文件; step2:对视觉词典分词解析生成Field对象; step3:对图片向量化后文件构建Document对象; step4:IndexWriter使用addDocument方法创建索引。
索引分片依赖于集群状态,会对查询效率造成影响。本文设计为分片个数与集群节点数相同,分片均匀分配至各节点中。索引副本个数设计为2,保证系统的可靠性、数据的安全性。考虑到三个特征向量需要分别计算相似度,故采用三维倒排索引,每个维度对应一种特征的视觉单词。
3.4 多特征融合
本文实现的是决策级的图像特征融合,即在检索时对待检索的图像提取三种图像特征,与特征库中相应的特征向量分别计算相似度,最后对三种特征的相似度计算结果进行加权整合,得到综合的相似度。对于RootSIFT特征、颜色矩特征、Gabor纹理特征,设待检索图片Q和图像库中图片I之间的相似度分别是DistR(Q,I)、DistC(Q,I)、DistG(Q,I)。
考虑到不同图像特征所描述的图像内容和物理意义各不相同,因此在特征融合之前需对DistR(Q,I)、DistC(Q,I)、DistG(Q,I)进行归一化操作,以消除不同特征量纲之间的差异对检索结果所造成的干扰。
研究结果表明,单个特征作用于图像检索时,RootSIFT特征的识别与匹配能力最强,颜色矩特征其次,Gabor纹理特征的区辨能力较弱。为了突出不同种类的图像特征对检索重要程度的差异性,本文在图像特征融合时加以权重,对应于每种特征的重要性,特征的融合权重越大,说明该特征的匹配能力越强,对于检索越重要。相似度融合公式如公式(6)所示。
Dist(Q,I)=w1×DistR(Q,I)×DistC(Q,I)+w2×DistG(Q,I)
(6)
其中w1+w2=1。公式(6)中的DistR(Q,I)、DistC(Q,I)采用相乘的方式是为了限制匹配的条件,如果两个图像是相似的,很大程度上必须要求这两张图像同时在RootSIFT特征和颜色矩特征上都是相似的。本文中之所以DistG(Q,I)以相加而不是相乘的方式融合其他两种特征,是因为考虑到图像纹理特征的匹配较弱,造成错误匹配的概率大,同时图像中纹理特征信息一般也没有梯度信息和颜色信息丰富。如果DistG(Q,I)也采用相乘的方式进行融合,那么这样的图像匹配的条件则过于苛刻,会导致图像检索的召回率过低的问题。
为了使得检索精度达到最大求得合适权重值,针对权重w1进行分析,观察权重w1取值的变化对平均检索精度的影响,由于w1与w2相互约束,w2的取值随之相应变化。本次使用Corel-1000标准图像库[20]作为测试,实验结果表明随着w1的取值从0,0.1,0.2,到1.0的变化,平均检索精度呈现出先上升后下降的趋势,求得最合适权重值即求平均检索精度最高时对应的w1。
从Corel-1000标准图像库的10类图片中,每类图片随机选取30张共300张作为预处理测试图片,设定初始w1值,通过不断迭代和反馈,调整w1值,直至达到最优或者局部最优的w1值为止,实验得权重分配值w1=0.768,w2=0.232。
不同的实验数据集采用特征融合公式时对应不同的权值分配,对于不同的数据集,应采用上面的方法对其进行预处理,求出相应的合适权值。
4 实验与分析
本文构建了基于Hadoop+ElasticSearch的多特征融合检索原型系统。实验数据集为Corel-1000标准图像库和ILSVRC2015数据集,分别在查准率、检索效率和加速比三个方面对原型系统进行了分析。
4.1 实验环境
本实验硬件配置为两台Intel Xeon CPU、32G内存的电脑,为实现多节点的分布式环境,实验时在每台电脑上安装两个虚拟机,共四个虚拟节点。每个节点都采用64位CentOS系统,内存设置为16G,Hadoop版本采用hadoop2.6.2,ElasticSearch版本为elasticsearch1.4.4,JDK为jdk1.7.0_80。
4.2 查准率
在图像检索领域,精度(又叫查准率)是非常重要的检索性能评价指标。精度的数学表达形式如公式(7)所示:
(7)
其中,TP表示相关且被正确返回的图像数,FP表示不相关但被错误返回的图像数。
本次实验采用Corel-1000标准图像库,Corel-1000分为人脸、沙滩、建筑等10类,其中每类中各包含100张相似图像,共1 000张图片,取数据集的30%作为测试数据,即每类30张图片,共300张。然后统计本类别图像的平均查准率作为检索性能的评价指标,检索结果按相似度降序排序,每次检索时向用户返回NR张最相似的图像作为检索结果,本次实验中NR设置为20。
从图2中观察可得,单个特征检索时,RootSIFT特征在三个特征中的识别能力最强,颜色矩特征其次,Gabor纹理特征最弱,特征融合后的检索精度明显有所提升。本文中设计的特征融合方案能够较好地发挥各个特征的特性,在图像检索方面性能优异。
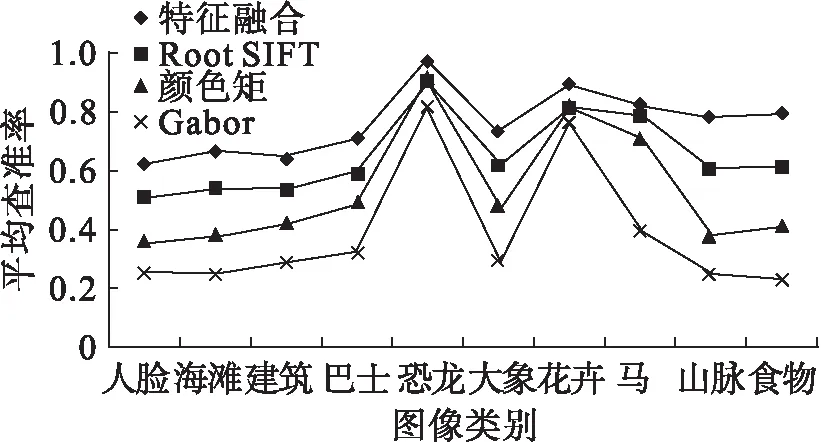
图2 单一特征与多特征融合图像检索的查准率对比
4.3 时间性能
实验数据来源于ILSVRC2015数据集,ILSVRC2015分为1 000类,130万张训练图片集,10万张测试图片集。本次实验分别从中随机选取10万、20万、40万、60万、80万作为训练数据集。根据不同规模的图像库及节点数的情况,图像检索消耗的时间如图3所示。
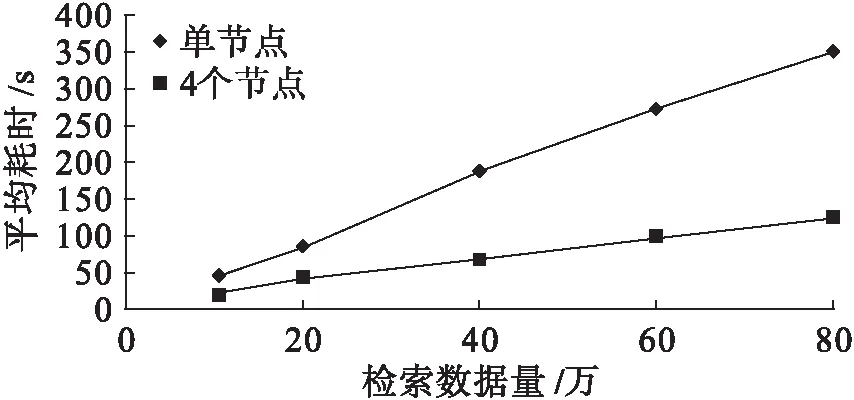
图3 不同节点下的检索时间对比
加速比定义为同一任务在单个计算节点运行时间与多个计算节点运行时间之比,用来衡量并行系统或程序并行化的性能和效果,即在计算节点个数相同时,加速比越大表示系统的并行化效率越高。文献[6]中同样实现了在四个节点的Hadoop集群上的图像检索,表1表示的是文献[6]中hadoop框架下图像检索的加速比和本文中引入ElasticSearch后的分布式检索算法加速比的比较。
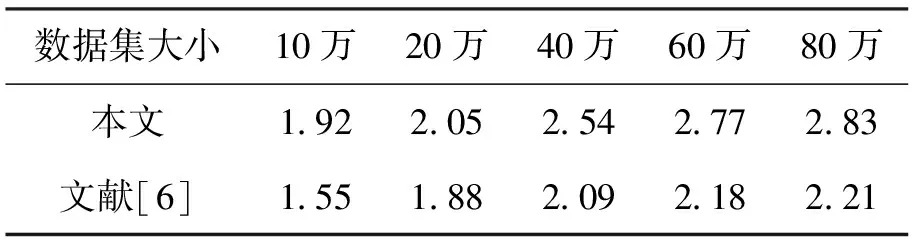
表1 本文方法与文献[6]中方法加速比比较
从图3观察可得,随着数据集的增大,分布式计算平台相对于单节点计算的检索效率优势越发明显。数据量为10万时,四个节点检索消耗的时间为单节点消耗时间的52.17%,随着数据量增长到80万,检索时间对比为35.33%,这说明本文设计方案能大幅度提升图像检索的效率;从表1可观察出,两种方法的加速比均随着数据集的增大而有所增加,但是本文中设计的方法在各个大小的数据集中均表现出比文献[6]中的方法加速比更大,即本文中引入ElasticSearch的云计算平台相对于传统的hadoop框架在图像检索方面更能发挥集群分布式并行计算的优势。
5 结束语
随着图像数据量的不断增长,传统图像检索方式在处理海量图像时存在效率低、可靠性差等缺陷,基于此提出了基于hadoop+ElasticSearch的多特征融合图像检索方法。实验结果表明,在Hadoop中引入ElasticSearch实现分布式的多特征融合算法,提高了检索效率,获得较好的加速比且相对于传统Hadoop框架下的分布式图像检索算法更能发挥集群的优势。由于hadoop是为海量数据处理做的平台,使得系统处理海量数据成为可能,受实验条件所限,对更大规模的数据分析有待于进一步研究。未来的工作重点将根据图像检索需求进一步优化多特征融合算法,提高检索精度,并从改善集群本身的性能入手,进一步提高检索效率。
[1]DATTA R,JOSHI D,LI J,et al.Image retrieval:ideas,influences,and trends of the new age[J].ACM Computing Surveys(Csur),2008,40(2):1-6.
[2]JING F,LI M,ZHANG H J,et al.An efficient and effective region-based image retrieval framework[J].IEEE Transactions on Image Processing,2004,13(5):699-709.
[3]王向阳,杨红颖,郑宏亮,等.基于视觉权值的分块颜色直方图图像检索算法[J].自动化学报,2010,36(10):1489-1492.
[4]WANG F,ERCEGOVAC V,SYEDA-MAHMOOD T,et al.Large-scale multimodal mining for healthcare with mapreduce[C]//Proceedings of the 1st ACM International Health Informatics Symposium.ACM,2010:479-483.
[5]DEAN J,GHEMAWAT S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[6]王梅,朱信忠,赵建民,等.基于Hadoop的海量图像检索系统[J].计算机技术与发展,2013(1):204-208.
[7]RAJU U S N,GEORGE S,PRANEETH V S,et al.Content based image retrieval on Hadoop framework[C]//Big Data(BigData Congress),2015 IEEE International Congress on.IEEE,2015:661-664.
[8]KONG F H.Image retrieval using both color and texture features[C]//Machine Learning and Cybernetics,2009 International Conference on.IEEE,2009,4:2228-2232.
[9]SUDHIR R.An Efficient CBIR Technique with YUV Color Space and Texture Features[J].Computer Engineering & Intelligent Systems,2011,2(6):78-84.
[10]张永库,李云峰,孙劲光.基于多特征融合的图像检索[J].计算机应用,2015,35(2):495-498.
[11]朱为盛,王鹏.基于Hadoop云计算平台的大规模图像检索方案[J].计算机应用,2014,34(3):695-699.
[12]史亚东,李勋.基于Hadoop平台的图像检索方法研究[J].兰州交通大学学报,2016,35(1):30-35.
[13]LOWE D G.Object recognition from local scale-invariant features[C]//Computer Vision,1999.The proceedings of the seventh IEEE international conference on.IEEE,1999,2:1150-1157.
[14]LOWE D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[16]STRICKER M A,ORENGO M.Similarity of color images[C]//IS&T/SPIE's Symposium on Electronic Imaging:Science & Technology.International Society for Optics and Photonics,1995:381-392.
[17]ZHENG L,WANG S,ZHOU W,et al.Bayes merging of multiple vocabularies for scalable image retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2014:1955-1962.
[18]GORMLEY C,TONG Z.Elasticsearch:The Definitive Guide[M].Sebastopol:O′Reilly Media,Inc,2015.
[19]DIVYA M S,GOYAL S K.ElasticSearch:An advanced and quick search technique to handle voluminous data[J].Compusoft,2013,2(6):171.
[20]LI J,WANG J Z.Automatic linguistic indexing of pictures by a statistical modeling approach[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2003,25(9):1075-1088.
(责任编辑:刘划 英文审校:赵亮)
Research on the method of retrieval of image content based on Hadoop
SHI Xiang-bin1,2,ZHONG Liu-bei1,ZHANG De-yuan1
(1.College of Computer Science,Shenyang Aerospace University,Shenyang 110136,China;2.School of Information,Liaoning University,Shenyang 110036,China)
In recent years,with the development of internet technology,the image data shows explosive growth while the image retrieval has become hot in research field.In this paper,an image retrieve scheme based on cloud platform and multi-feature fusion was proposed.In order to achieve distributed parallel retrieval,the construct methods such as visual dictionary generation,image vectorization and multi-dimensional inverted index were provided by this scheme.To increase the accuracy of retrieval,we applied the RootSIFT feature,color matrix feature and Gabor feature by using a new method to fuse these three features.The experimental results on the Corel-1000 standard image library and the ILSVRC2015 dataset show that the proposed scheme can provide fast response speed and high retrieval precision on the distributed platform.
cloud platform;multi-feature fusion;CBIR;distributed computing
2017-02-20
国家自然科学基金(项目编号:61170185、61602320);辽宁省博士启动基金(项目编号:20121034、201601172);辽宁省教育厅科学研究一般项目(项目编号:L2014070、L201607)
石祥滨(1963-),男,辽宁大连人,教授,主要研究方向:分布式虚拟和现实、图像与视频理解、无人机协同感知与控制,E-mail:199630824@qq.com。
2095-1248(2017)03-0063-07
TP391.9
A
10.3969/j.issn.2095-1248.2017.03.009
猜你喜欢
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
软件导刊(2016年11期)2016-12-22 21:47:07
科学与财富(2016年15期)2016-11-24 13:30:27
中国市场(2016年36期)2016-10-19 04:43:09
中国新通信(2016年16期)2016-10-18 10:45:11
企业导报(2016年11期)2016-06-16 15:36:34
系统工程与电子技术(2016年2期)2016-04-16 05:16:58
企业导报(2016年5期)2016-04-05 14:19:22
