
GJR-CAViaR模型的贝叶斯分位数回归
——基于Gibbs抽样的MCMC算法实现
2017-07-05 08:11张颖傅强
中央财经大学学报 2017年7期
张 颖 傅 强
一、引言
目前,常用的分位数回归模型的估计方法分为两类。一类是直接进行优化求解,如单纯形法和内点法。另一类是借助于贝叶斯原理进行参数估计。
直接优化求解属于频率学派的范畴,是传统的经典统计学方法。经典估计方法将参数视为固定常数,然后利用最小二乘或极大似然等方法计算参数的估计值,得到参数的渐近分布和统计性质,并进行假设检验。贝叶斯学派与经典统计法在参数估计的原理上存在不同。贝叶斯学派将待估参数视为随机变量,利用贝叶斯原理和观测样本得到参数的后验分布。在无法得到参数后验分布的具体表达形式时,采用重复抽样技术解决参数的估计问题。因此,相对于传统统计对样本量的敏感,贝叶斯统计在小样本情形下也能得到可靠的参数信息。与经典统计方法的另一区别是贝叶斯方法在估计中加入了参数的先验信息。合适的先验分布可提高估计的精度。而当无先验信息可提供时,参数后验分布的估计会和最小二乘估计量一致,并不会影响到估计量的良好的统计性质。
总之,贝叶斯估计可以充分利用样本信息以及参数的先验信息,是简单有效地获得参数后验分布的方法。从损失函数最小化出发,Koenker和 Machado(1999)[1]将分位数回归与贝叶斯统计推断相结合,首次建立了服从非对称拉普拉斯分布ALD(Asymmetric Laplace Distribution)的误差项和目标参数的似然函数之间的关系。Yu和Moyeed(2001)[2]完善了这一方法,并详细证明了求损失函数最小等价于误差项服从ALD时最大化似然函数。
在分位数回归的CAViaR模型中,贝叶斯方法的应用也越来越普遍。基于不对称拉普拉斯分布,Hsu(2010)[3]讨论了CAViaR模型中参数的先验选择,并利用MCMC方法完成了对模型的贝叶斯分析。曾惠芳(2011)[4]利用三阶傅里叶级数来拟合CAViaR模型中的非参部分,研究了上证综指周数据的在险价值VaR。基于Chou(2005)[5]提出的日内极差(CARR)模型,Chen等(2012)[6]建立了极差以及阀值范围值(TRV,Threshold Range Value)的CAViaR模型。他们采用亚太经济合作体的五国的市场指数数据(S&P500,Nikkei225,TAIEX,HIS,KOSPI) 以及两国汇率数据(欧元对美元和日元对美元),发现贝叶斯CAViaR模型比传统的CAViaR能更准确地预测市场风险VaR,且优于历史模拟法及参数模型(GARCH和RiskMetrics) 方法。陈磊等(2013)[7]对布伦特原油价格的实证表明,贝叶斯CAViaR模型比传统的CAViaR模型对油价风险VaR的预测更好,根据平均相对偏差和市场风险资本要求发现,不对称CAViaR模型可以有效刻画油价VaR的动态变化。王新宇等(2013)[8]构建了有变点的CAViaR模型,提出变点的SAV和IGARCH模型的贝叶斯推理及MCMC实现,并检验了创业板指数市场风险因首次限售解禁而发生的结构改变。这些研究表明,与传统的优化求解相比,贝叶斯方法能更好地估计CAViaR模型的参数。
张颖等(2012)[9]提出GJR-CAViaR模型研究收益对风险的不对称影响,弥补了AS-CAViaR和TARCH-CAViaR模型设定中在参数限制上的不足,并利用实证指出在GJR、AS及TARCH三种CAViaR模型中,GJR-CAViaR模型的样本内预测结果总体效果较好。但是,尚未有文献提出如何进行GJR-CAViaR模型参数的贝叶斯推断。GJR-CAViaR模型属于递归的分位数回归方程,模型的非线性及半参性造成贝叶斯估计比较复杂,而且,不对称拉普拉斯分布属于非标准的分布,只有将模型参数的满条件分布转化为常用已知分布,才能借助于Gibbs抽样来估计参数。因此,有必要对如何解决这类模型的贝叶斯估计提出分析框架。本文提出GJR-CAViaR模型的贝叶斯估计的算法实现,并基于Gibbs抽样建立上证综指日收益率的GJR-CAViaR模型参数估计。
二、分位数回归的贝叶斯估计理论基础
(一)分位数回归理论
Koenker和 Bassett(1978)[10]提出了分位数回归理论,该理论是对中位数回归的扩展。假设线性回归方程为:

定义误差项u的损失函数ρ(u)如式(2)所示。其中,I(u)为指示函数,0<τ<1。

分位数回归估计的目标是损失函数最小,其目标函数表示如式(4)。

可以看出,分位数回归对正负误差项赋予了不同的权重。当τ=0.5时,式(4)的目标函数将简化为误差项的绝对值之和最小(least absolute deviation,LAD),也就是传统上的中位数回归。
目标函数式(4)不可微,因此无法得到模型的解析解。这个时候只能通过线性规划或者贝叶斯的方法来求解。
(二)贝叶斯分位数回归
Yu和Moyeed(2001)[2]的研究是该领域最重要的文献之一。他们给出贝叶斯分位数回归的原理,并基于不对称拉普拉斯分布建立分位数回归模型的贝叶斯估计框架。
拉普拉斯分布以皮埃尔—西蒙·拉普拉斯的名字命名。标准的对称的拉普拉斯分布是由两个具有同样的位置参数的独立同分布的指数分布背靠背拼接在一起,也被称为双指数分布。一般化的拉普拉斯分布考虑了分布的非对称性,Yu和Moyeed(2001)[2]给出服从不对称拉普拉斯分布的随机变量x的概率密度函数表示,如式(5)。

式(5)中,σ>0是尺度参数(scale parameter),μ是位置参数(location parameter),0<p<1是偏度参数(asymmetrc parameter),ρp(x-μ)是损失函数,定义如式(2)。x满足不对称拉普拉斯分布,记作x~ALD(μ,σ,p) 。
随机变量x的分位数函数为
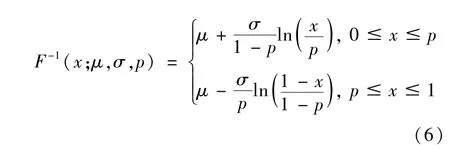
可以看出,

式(7)说明随机变量x的p分位数等于其位置参数μ,这个就是ALD分布可作为分位数回归模型的误差分布的依据。而偏度参数p就是式(2)中的分位数水平τ。
对于线性回归模型yi=x'iβ+ui,假定模型的残差项u服从不对称拉普拉斯分布,ui~ALD(0,σ,τ)。根据拉普拉斯分布的线性变换性质,yi~ALD(x'iβ,σ,τ) 。则因变量y的概率密度函数可表示成式(8)。

则样本y=(y1,y2,…,yn)的似然函数可表示成式(9)。

其中,

可以看出,求分位数回归的损失函数最小化等价于式(9)的似然函数的最大化。贝叶斯分位数回归的关键就是利用误差项的非对称的拉普拉斯分布,将对损失函数的求解转化为对似然函数的求解。
Yu和Moyeed(2001)[2]还证明了即使待估参数β的先验分布是不真实的分布(Improper distribution),只要β满足p(β)∝1,那么β的后验分布就是真实分布(Proper distribution)。也就是说,β的后验密度函数p(β|y)存在,y是观测值。即:

MCMC模拟所必须遵循的原则就是参数的后验分布是真实分布,但对参数的先验分布并没有这个要求。所以,在贝叶斯分位数回归中,即使参数的先验分布设定为均匀分布,得到的后验分布也是真实的,不会对MCMC的估计结果造成影响。
三、GJR-CAViaR模型的贝叶斯估计理论
张颖等(2012)[9]提出的GJR-CAViaR模型是基于CAViaR模型的不对称收益模型,就正负收益对市场风险VaR的不对称性建模,并定量描述此影响的不对称程度。模型的设定如下:

当利用如式(15)的目标函数估计参数β的时候,也就是执行分位数回归的时候,gt(β)就是yt的τ条件分位数(τ是分位数水平),即在险价值VaR。但是,我们并不知道gt(β)的具体形式,只知道gt(β)的演化方程如式(13)。

下面讨论GJR-CAViaR模型的Gibbs抽样。Gibbs抽样是将多变量抽样转化为对满条件分布进行单变量抽样的算法,重点是如何推断出条件分布。以不对称拉普拉斯分布为基础的半参的分位数回归模型CAViaR模型的贝叶斯推断很难得到参数的解析后验分布,也就是说,无法得到参数解析的满条件分布,不能直接使用Gibbs抽样来实现对模型的模拟。因此,需要引入其他标准的分布来得到模型参数解析的满条件分布,并实现模型的Gibbs抽样。文献中主要通过两种方式解决这个问题。其一,利用混合正态分布与有偏的拉普拉斯分布(skewed-laplace)的等价关系(Tsionas,2003[11]),推导出不同参数的后验边缘分布,解决拉普拉斯分布对应的贝叶斯分位数回归问题。其二,把不对称拉普拉斯分布表示成标准指数分布和标准正态分布的组合,实现贝叶斯分位数回归(Kozumi和 Kobayashi,2011[12])。不对称拉普拉斯分布和常用的正态分布及指数分布存在如下关系。假设随机变量ε服从于不对称拉普拉斯分布,z服从标准指数分布z~E(1),u是标准正态分布,u~N(0,1)。则有式(16)成立。

其中,

式(17)与(18)中的τ就是式(15)分位数回归中的分位数水平τ。Kozumi和 Kobayashi(2011)[12]指出 Tsionas(2003)[11]的方法有两点不足。其一,算法会产生高度相关的抽样点从而降低有效性;其二,当样本量很大的时候运算速度慢。故本文选择 Kozumi和 Kobayashi(2011)[12]的方法来处理不对称拉普拉斯分布的问题。根据式(12),假设随机变量ε服从不对称拉普拉斯分布,则GJR-CAViaR模型可等价表示为
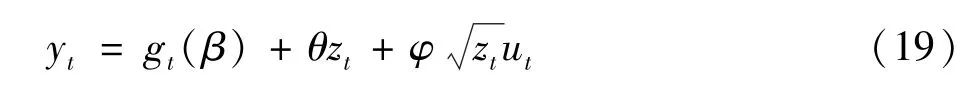
当引入尺度参数σ时,上式可改写为

令vt=σ zt,则vt~E(σ),上式重新写作

在给定vt的时候,yt服从均值为gtβ()+θ vt,方差为φ2σ vt的条件正态分布。此时,可求得y=(y1,…,yn)的联合密度函数为

假定参数β的先验分布为正态分布,σ的先验分布为逆伽马分布,σ~IG(n0/2,s0/2),其中,n0,s0为固定常数,则β的满条件分布也是正态分布,并可推导出下面的结论:vt的满条件分布为逆高斯分布。

其中,

同时,σ的满条件分布为逆伽马分布。

其中,

从上述推导结果可以看到,模型各个参数的满条件分布都服从常用的已知分布。这时,就可以利用Gibbs方法模拟并构造马尔科夫链,具体步骤如下:
第一步,选择参数的初始值,β0=
第二步,从条件正态密度函数f(β0|y,σ,v)中抽取随机数,记作β1。
第三步,从条件逆伽马密度函数f(σ|y,β1,v)中抽取随机数,记作σ1。
第四步,从条件逆高斯密度函数f(v|y,β1,σ1)中抽取随机数,记作v1。
由此成功完成一次状态转移,参数变为(β1,σ1,v1)。利用这个新值,重复步骤1到步骤4,完成新的参数的迭代。如此重复N次,直到得到稳定的马尔科夫链,就可以得到参数的后验分布及估计结果。
四、GJR-CAViaR模型的参数估计结果
王新宇等(2010)[13]以及邸俊鹏(2013)[14]都利用模拟数据证明了在分位数回归贝叶斯推理中,估计量依赖于尺度参数的设置。将尺度参数σ参数化,可以降低参数估计值的标准差,提高被估系数的估计精度。这里,我们不再构造模型进行模拟分析,直接将尺寸参数σ看作待估变量。在实证部分,利用同花顺软件下载上证综指的日收盘价数据,计算日收盘指数的对数收益率。

自1996年12月16日开始,中国股市开始实行涨停板制度。样本区间选择为:1996年12月16日至2014年12月31日。因为方差很大的正态分布可近似为均匀分布,设定参数的先验分布为方差大的正态分布,β0~N(0,100),尺度参数σ的先验分布服从逆伽马分布,σ~IG(10-5,10-5)。Gibbs抽样共模拟20 000次,去掉前面10 000个抽样值,利用后面的10 000个点计算参数估计值。本文涉及的抽样方法通过R软件和WinBUGS软件实现。
(一)不同置信水平下GJR-CAViaR模型的参数估计
在样本区间内,选择最近的300个样本①对于贝叶斯推断,估计结果对样本量的大小不太敏感。在邸俊鹏(2013)[14]的论文中,当样本量大于200时Gibbs抽样估计的参数的偏误和标准差都比较小。因此,基于充足样本量的考虑,本文选取最近的300个上证综指日收益率的数据。,即:2013年7月25日至2014年12月31日的收益率数据,计算99%置信水平下GJR-CAViaR模型的参数估计值。表1列出了估计参数的后验均值、标准差、蒙特卡洛误差以及95%的贝叶斯置信区间。
对Gibbs抽样算法的结果进行评价有三种方式:接受率、收敛性以及抽样的精度。我们的实证以收敛性作为判断的标准。若马尔科夫链收敛,则我们认为Gibbs模拟值是真实后验分布的合理近似。简单地,可以从抽样值轨迹直观地对抽样分布进行检验。如果抽样值估计在某值附近上下波动,则该马尔科夫链收敛。另外,抽样值的相关性太强将导致算法无法到达参数的整个空间。若随着滞后阶数的增加,自相关系数趋于零,该马尔科夫链收敛。

表1 99%置信水平下模型参数的Gibbs抽样估计值
图1至图5是样本容量为300时,不同参数在0.01分位点下的抽样轨迹和核密度图。图中显示不同参数的抽样序列都比较集中,在小范围内上下波动,因此抽样值构成的马尔科夫链均收敛。

图1 β0的MCMC抽样值轨迹和核密度图

图2 β1的MCMC抽样值轨迹和核密度图

图3 β2的MCMC抽样值轨迹和核密度图

图4 β3的MCMC抽样值轨迹和核密度图

图5 σ的MCMC抽样值轨迹和核密度图
图6和图7分别给出了样本容量为300时,在0.01分位点下,各参数抽样值的自相关图。从图中可以看出,随着滞后期的增加,自相关系数逐渐趋近于零。

图6 β0,β1的自相关图

图7 β2,β3的自相关图
由于马尔科夫链收敛,因此各参数的估计结果可靠。基于同样的样本,我们还计算了0.05分位点下各参数的Gibbs抽样算法的估计值。实验结果表明,0.05分位点的各参数的抽样值轨迹以及自相关图与0.01分位点的结果类似,马尔科夫链均收敛。参数的抽样值估计图及自相关图略。表2给出了0.05分位点下各参数的Gibbs抽样的估计值。
从表1和表2的估计结果看,1%VaR以及5%VaR的GJR-CAViaR模型的所有参数的后验均值都位于95%的后验置信区间内,说明在5%显著性水平下各参数是显著的。也就是说,中国证券市场VaR具有自回归的特征,即当前风险的大小会受到前一期风险的影响。且存在收益对风险的不对称效应,负收益对VaR的影响更大。

表2 95%置信水平下模型参数的Gibbs抽样估计值
(二)不同样本容量的估计结果
为了考察不同样本容量的贝叶斯估计结果,对于全样本区间内的数据,分别选择最近的500个、800个、1 000个以及2 000个样本估计GJR-CAViaR模型的参数,并计算99%置信水平以及95%置信水平下的参数估计值。

表3 99%置信水平下不同样本容量的参数的Gibbs抽样估计值

续前表
参数的MCMC抽样轨迹以及抽样值的自相关性显示,所有的参数抽样构成的马尔科夫链都是收敛的,参数的估计结果都是可靠的。
从表3和表4的MCMC参数估计结果看,所有参数的后验均值都落在95%的后验置信区间内,因此,5%显著性水平下各参数是显著的。β1的值都比较高,β2是正数,且β3显著大于零。说明在小样本的情况下,仍然可以得出与大样本相同的结论,即中国证券市场VaR具有自回归的特征,当前风险的大小受前一期风险值的影响较大。且存在收益对风险的不对称效应,负收益对VaR的影响更大。而且,95%和99%置信水平下模型参数的估计结果显示,所有估计参数的标准差都比较小。由于参数采用的是近乎无信息先验的正态分布,计算出的GJR-CAViaR模型的参数标准差都比较小,也说明了贝叶斯方法的有效性。
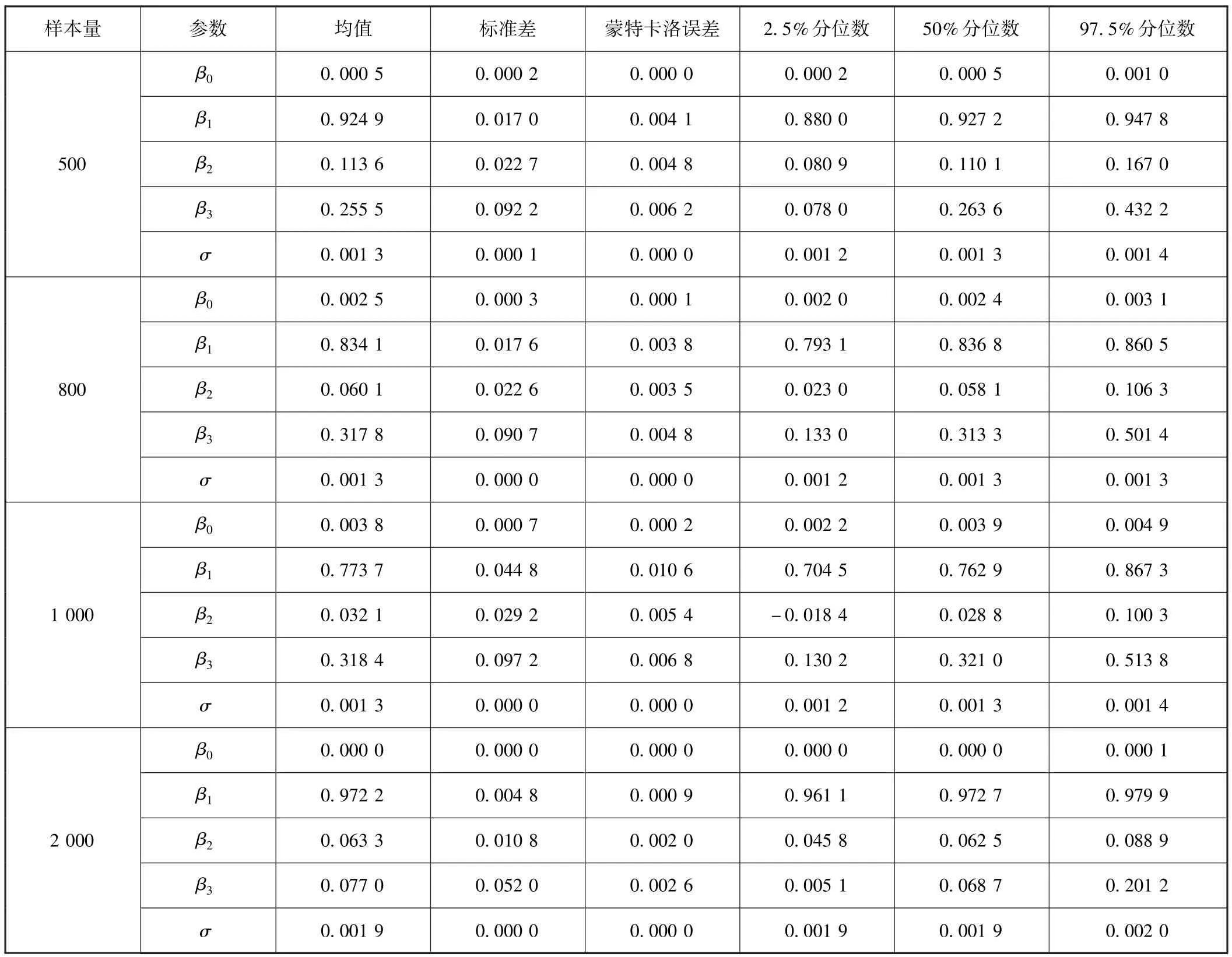
表4 95%置信水平下不同样本容量的参数的Gibbs抽样估计值
五、结论
通过不对称拉普拉斯分布,本文探讨了基于Gibbs抽样的GJR-CAViaR模型的MCMC的算法实现,并利用上证综指的日收益率数据进行实证分析,发现中国证券市场VaR具有自回归性质,且呈现出收益对风险的不对称特征,且该性质不受样本容量和置信水平的影响。
本文关于不同样本容量的Gibbs抽样估计值的讨论为参数的结构变化提供了思路。在样本分布不变的情况下,随着样本量的增加,参数的估计精度会随之提高。当我们的样本从500、800、1 000增加到2 000的时候,参数的抽样分布的标准差并未出现随着样本量增加而越来越小的情况。而且,不同的样本容量下,参数的估计值也有不同。如样本量从1 000增加到2 000的时候,5%VaR的参数估计值的差异比较大。因此,在这个区间样本的分布并不是保持不变的。此时,选择基于样本容量为1 000的GJR-CAViaR模型去估计第1 001个交易日的VaR,或者选择基于样本容量为2 000的GJR-CAViaR模型去估计第1 001个交易日的VaR是值得思考的问题。在样本分布没有发生改变的情况下,样本容量2 000的模型应该是更好的选择。如果样本在这个区间内发生了比较大的结构变化,也许样本容量较小而日期更近的模型会有更不错的结果。在CAViaR模型的估计样本区间内是否需要加入结构参数,如何确定区间内样本是否产生结构变化的问题,将是我们未来的研究方向。
[1]Koenker R,Machado J A.Goodness of fit and related inference processes for quantile regression[J].Journal of The American Statistical Association,1999,94(448):1296-1310.
[2]Yu K,Moyeed R A.Bayesian quantile regression[J].Statistics& Probability Letters,2001,54(4):437 -447.
[3]Hsu Y H.Applications of quantile regression to estimation and detection of some tail characteristics [D].University Of Illinois At Urbana-Champaign,2010.
[4]曾惠芳.基于MCMC算法的贝叶斯分位回归计量模型及应用研究 [D].湖南大学,2011.
[5]Chou R Y T.Forecasting financial volatilities with extreme values:the conditional autoregressive range(CARR)model [J].Journal of Money,Credit And Banking,2005,37(3),561-582.
[6]Chen C W S,Gerlach R,Hwang B B K,Mcaleer M.Forecasting Value-at-Risk using nonlinear regression quantiles and the intra-day range [J].International Journal of Forecasting,2012(3),557-574.
[7]陈磊,杜化宇,曾勇.基于贝叶斯CAViaR模型的油价风险研究 [J].系统工程理论与实践,2013(11),2757-2765.
[8]王新宇,吴祝武,宋学锋.变点CAViaR市场风险测量模型及创业板应用 [J].中国矿业大学学报,2013(03),506-512.
[9]张颖,孙和风,张富祥.中美股票市场风险差异的新解释——收益对市场风险不对称效应的CAViaR模型与实证 [J],南开经济研究,2012(05),111-120.
[10]Koenker R,Bassett,G.Regression Quantiles [J].Econometrica,1978,46(1),33 -50.
[11]Tsionas E G.Bayesian quantile inference [J].Journal of Statistical Computation And Simulation,2003,73(9),659 -674.
[12]Kozumi H,Kobayashi G.Gibbs sampling methods for Bayesian quantile regression [J].Journal of Statistical Computation And Simulation,2011,81(11),1565-1578.
[13]王新宇,宋学锋,吴瑞明.基于AAVS-CAViaR模型的股市风险测量研究 [J].系统工程学报,2010(03),326-333.
[14]邸俊鹏.分位数回归的贝叶斯估计与应用研究 [D],南开大学,2013.
猜你喜欢
山西大学学报(自然科学版)(2021年4期)2021-08-31
新世纪图书馆(2021年12期)2021-01-19
筑路机械与施工机械化(2020年7期)2020-08-20
数学大世界(2020年19期)2020-08-05
卷宗(2020年2期)2020-03-23
科教导刊·电子版(2020年36期)2020-02-25
中国商论(2018年22期)2018-09-10
价值工程(2017年19期)2017-07-12
雷达学报(2017年6期)2017-03-26
现代计算机(2016年11期)2016-02-28
