
开放式大规模阵列处理系统多核DSP矩阵设计
2017-06-22 14:25:04刘可
无线电工程 2017年7期
刘 可
(中国西南电子技术研究所,四川 成都 610036)
开放式大规模阵列处理系统多核DSP矩阵设计
刘 可
(中国西南电子技术研究所,四川 成都 610036)
为了满足大规模阵列处理系统对运算处理速度和总线带宽日益增长的需求,基于VPX(VITA46)架构构建了一种多核DSP矩阵,其中若干个基本处理单元模块经由高速串行总线开关联结形成所需的系统拓扑结构,并结合通信中间件技术和DSP自定义自举加载技术来实现高性能的松耦合并行处理系统。这种处理阵列具有开放式体系结构,支持新任务、新技术的插入,可在系统全寿命周期内响应不断扩展的外部需求。目前多核DSP矩阵已在航空电子领域多个工程项目中得到应用,为系统的滚动迭代发展奠定了坚实基础。
VPX架构;多核DSP矩阵;阵列处理;开放系统
0 引言
大规模阵列处理系统(雷达、声纳和图像处理等方向)都是信号处理密集型应用,严重依赖数字信号处理算法的高效实现,对系统的运算处理速度、总线带宽和工作环境等需求日益增长。传统的嵌入式信息处理系统多基于分时共享总线和单核处理器阵列来构建[1]。分时共享总线受限于固定的总传输带宽,无法满足快速增加的处理器阵列通信单元之间的高速信息传输需求。单核处理器受到芯片尺寸、功耗和成本等因素限制,运算处理能力已达极限。因此,传统的嵌入式平台已不适用于当今的大规模阵列处理系统。
随着总线技术的发展,嵌入式系统总线现今已进入到采用差分电平、点对点传输方式和交换开关的高速串行总线时代,其集大成者非VPX(VITA46)架构莫属[2]。VPX架构可支持多种总线协议,如PCIE、SRIO和以太网等,散热好,结构灵活坚固。而受益于半导体制造工艺的进步,集成电路芯片尺寸越来越小,容纳的晶体管越来越多,工作速度越来越高,这些都促使处理器从单核向多核进化。典型如TI公司多核DSP芯片TMS320C6678,其处理能力较单核器件有数倍的提升。TMS320C6678支持二级自举加载,并允许任意层级的用户自定义自举方式[3]。
本文介绍了一种基于VPX架构和通信中间件技术的多核DSP矩阵设计和应用,并在国内大规模阵列处理工程应用领域创新性地引入了“硬总线”和“软总线”概念。多核DSP矩阵支持放式体系结构,理论上使系统具备了不受限的功能升级和扩展能力。
1 基本处理单元总体设计方案
多核DSP矩阵基本处理单元模块按照联合标准航空电子系统结构委员会(ASAAC)发布的模块化综合航空电子(IMA)系统通用功能模块(CFM)技术标准进行设计[4]。模块通用化设计是系统实现资源开放、软件重构的基础。系统中众多模块通过开放式、可扩展的交换网络“硬总线”任意互联,为软件重构部署提供基础硬件设施。硬件模块作为交换网络的节点,其内部的故障、升级和更改仅限于模块内部,不对系统其他部分造成影响。交换网络支持任意数目的模块节点和分布式网络,可以方便地插入新的可扩展模块,新增加的模块不对系统的其他部件造成影响。通用功能模块标准结构如图1所示。
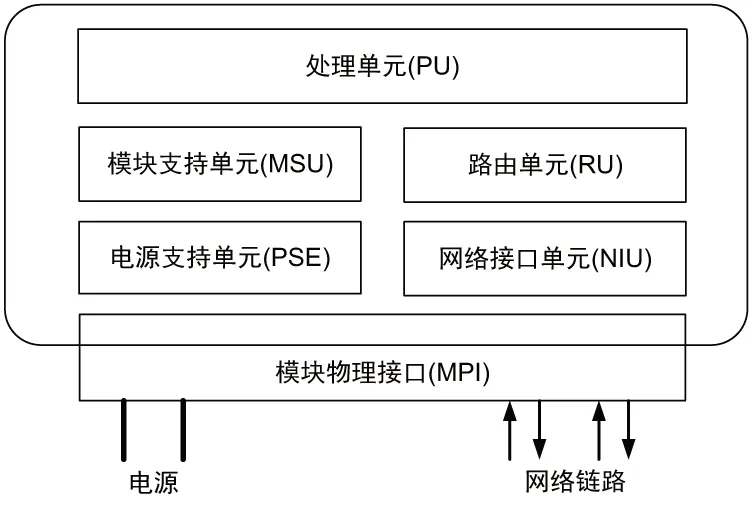
图1 通用功能模块标准结构
在通用功能模块中,处理单元PU负责信号/数据的运算、交换和存储,并可承担部分系统控制任务[5]。模块支持单元MSU主要负责控制和监视模的运行,提供模块的系统管理、内/外部通信和模块板级管理。MSU可由处理单元底层软件实现,也可由独立的微控制器或可编程逻辑实现[6]。网络接口单元NIU为模块内部网络和模块外部网络提供通信连接。路由单元RU提供模块内部的网络接口单元、处理单元和模块支持单元之间的通信路由功能。电源支持单元PSE提供外部统一电压转换至模块内部电压的功能。模块物理接口MPI定义模块的插座和结构件规范。
1.1 基本处理单元硬件设计
多核DSP矩阵基本处理单元模块遵循VPX架构模块通用设计要求,在满足基本功能要求的前提下为算法及软件的设计提供最大的灵活性及便利,其电路框图如图2所示。

图2 基本处理单元模块组成
基本处理单元模块的PU即是多核DSP芯片TMS320C6678。TMS320C6678是基于Key Stone多核结构的高性能定点和浮点数字信号处理器,内部集成8个C66x内核。在1.25 GHz工作频率时每个C66x内核的定点运算能力为40 GMAC,浮点运算能力为20 GFLOP。按照目前的集成设计能力,1个6U构型的模块可集成4片多核DSP,每片DSP可通过DDR3、EMIF、I2C等集成外设接口挂接DRAM、FLASH、NVRAM等类型存储器,用于保存通信协议栈、应用代码以及固件信息。TMS320C6678内部集成了NIU,可提供4路1X SRIO高速串行接口或1路4X SRIO接口。基本处理单元模块的RU选用的是IDT公司的SRIO总线交换芯片80HCPS1848。80HCPS1848交换芯片是18端口、48通道、低延迟的第二代SRIO总线交换芯片,支持240 Gbps持续峰值吞吐能力[7]。在基于FR4印制板并跨越2个连接器的传输系统中,80HCPS1848交换芯片的SRIO信号传输距离可达1 m。该款交换芯片接收和路由的数据包都符合SRIO 2.1规范,且数据包基于优先级方式来设定[8]。基本处理单元模块中所有多核DSP皆通过1路4XSRIO总线连接到交换芯片80HCPS1848从而形成单星形拓扑结构,交换芯片自身也以1路4X SRIO总线经由MPI和机箱背板接入系统高速串行交换网络,如此可实现系统级的多核DSP并行运算。基本处理单元模块的MSU可选择TI公司的TMS320F28235。TMS320F28235操作简单,接口丰富,适宜于实现模块监控和管理。
1.2 基本处理单元软件设计
多核DSP矩阵软件架构分为3层,从下往上分别是平台驱动层、通信中间件层和应用层(功能软件和系统软件),如图3所示。

图3 多核DSP矩阵软件架构
平台驱动层是系统的基础操作环境,包括操作系统(BIOS)、板级支持软件包(BSP)以及硬件接口的软件驱动(SW)。
通信中间件层位于操作系统之上,应用软件之下。向上通过中间件服务接口为应用软件提供通信和平台资源管理服务,并在系统维护模式下提供可视化的系统监控服务;向下通过硬件抽象适配层,与平台硬件操纵与控制驱动层软件接口,便于系统底层硬件的插入,实现系统软件与系统硬件之间的松耦合设计。公共对象请求代理体系架构(CORBA)是一种标准的面向对象的应用程序体系规范,解决了分布式处理环境中硬件和软件系统的互连问题[9]。
在应用层中,功能软件实现系统设计功能项的算法以及相应功能线程的控制接口,主要功能在基本单元模块DSP处理器中完成。系统软件的核心任务则是工作模式和工作状态管理:前者根据外部指令形成系统的功能需求,后者收集系统软硬件运行状态及功能需求的满足情况。此外,系统软件还要负责接口管理,包括默认端口间的直接转换、数据包的接收解析以及拆分和组包发送。
多核DSP矩阵应用层软件采用构件化设计方法,将功能及对外接口关系封装在构件内部,构件对外接口为“虚”通道[10]。各软件构件之间通过具有开放性、可扩展特征的“软总线”互联,可部署在系统任意指定的硬件节点上。构件内部的故障、升级和更改不对系统其他部件造成影响。“软总线”支持任意数目的软件构件节点数量,可以方便地插入新的扩展模块,新加的功能构件不对系统的其他模块造成影响。
2 基本处理单元关键技术
多核DSP矩阵基本处理单元模块通过加载不同的应用程序和配置参数来实现不同的信号处理功能。动态加载是指模块按照系统指令为PU加载不同的应用程序,代码更新则是指模块接收系统下发的应用程序代码并固化在本地非易失性存储器中。DSP芯片是信号处理的核心器件,也是应用程序动态加载和代码更新的主控器。
2.1 多核DSP动态加载技术
TMS320C6678是8核数字信号处理器,内核编号为0~7。在DSP自举加载过程中,内核0是主核,内核1~7是从核,从核由主核负责加载。TMS320C6678片内有一块128 KB容量的ROM,芯片出厂时ROM中即驻留有一段软件代码ROM Boot Loader (RBL)。RBL的作用是将用户程序搬移到DSP内存中并执行[11]。基本处理单元模块的所有DSP均以硬件方式设置为从EMIF接口NOR FLASH自举加载内核0。为了支持模块动态加载和代码更新功能,DSP需引入二级自举加载程序(即应用管理程序),加载流程如下:
① EMIF接口CS2空间挂接的NOR FLASH中保存应用管理程序镜像文件,镜像文件保存格式为BOOT TABLE。在DSP每一次上电或全局复位后,RBL会从EMIF接口CS2空间基地址处执行,即将应用管理程序搬移到DSP内存中并由内核0执行。在这一过程中,其他内核处于IDLE(空闲)状态。
② 内核0执行应用管理程序,从FLASH中读取需在内核1上执行的应用程序代码,分段加载到内核1的L2 SRAM中,并将应用程序入口地址写入专用寄存器,最后向内核1发送IPC中断。内核1被唤醒后自动执行应用程序代码。内核2~内核7的加载过程与内核1相同。
③ 内核0上运行的应用管理程序最后的任务是加载自身,即将FLASH中保存的应用程序代码分段读入内核0的L2 SRAM中,最后跳转执行。至此,DSP自举加载过程全部结束。
基本处理单元模块DSP需要动态加载时,系统通过控制总线向模块MCU发送动态加载指令。MCU收到指令后复位DSP,启动DSP自举加载流程。DSP立即停止运行当前应用程序,经由RBL跳转到应用管理程序开始执行。应用管理程序解析MCU中保存的动态加载指令信息,从FLASH中相应存储分区查找对应的代码并加载内核,新加载的程序在DSP片内程序存储区覆盖原来的用户程序。加载和校验完成后,DSP通过MCU回复系统动态加载操作已完成,然后跳转到新应用程序入口地址处开始执行。多核DSP动态加载流程如图4所示。
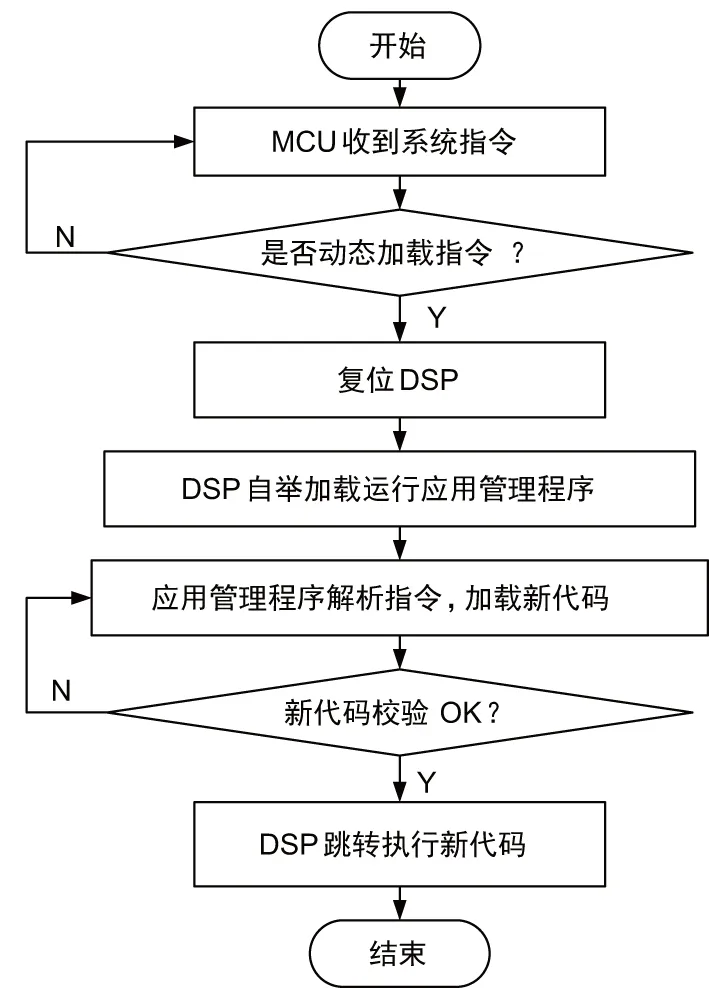
图4 多核DSP动态加载流程
2.2 多核DSP代码更新技术
基本处理单元模块中存储的功能程序代码可用2种方式来更新。调试状态下DSP可挂接仿真器运行FLASH烧写程序,通过集成开发环境将保存在计算机上的程序代码烧录到FLASH中。在系统联试和维护状态下,模块功能程序代码需要更新时,系统通过控制总线向模块MCU发送代码更新指令。MCU接收指令后复位DSP,启动DSP代码更新流程。DSP立即停止当前运行的功能程序,经由RBL跳转到应用管理程序并执行。应用管理程序解析MCU中保存的代码更新指令,通过Rapid IO总线接收主机传来的新程序代码,然后将新版程序烧录到FLASH中相应存储分区覆盖原有程序。烧写和校验完毕后,DSP过MCU回复系统代码更新操作已完成,然后跳转到新功能程序入口地址处开始执行,或者驻留在应用管理程序等待系统后续指令。多核DSP代码更新流程如图5所示。
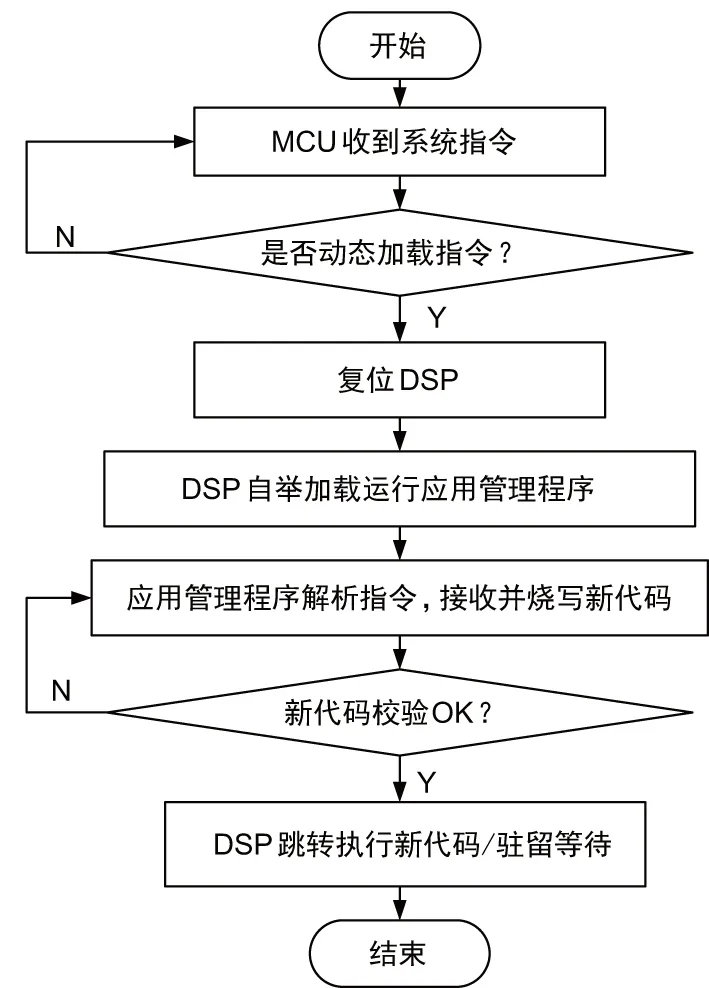
图5 多核DSP代码更新流程
3 应用分析
某型机载雷达主动探测系统通用信号处理平台采用了VPX架构+网络化高速信号分配+通用信号处理模块池的硬件架构,其中通用信号处理模块池由8~10块多核DSP矩阵基本处理单元构成。基本处理单元单模块集成4片8核DSP,每片DSP内核主频为1 GHz,单核定点和浮点处理能力分别达到32 GMACs和16 GFLOPs,所以通用信号处理模块池总的定点运算能力不低于
32 GMACs*8*4*8=8 192 GMACs,总的浮点运算能力不低于16 GFLOPs*8*4*8=4 096 GFLOPs。基本处理单元每个模块对外提供一路4x模式2.5 Gbps串行RapidIO链路接入系统高速信号分配网络,故通用信号处理平台网络化高速交换总能力不小于2.5 Gbps*4*8=80 Gbps。
这种硬件架构支持多任务、多功能线程并发工作,可根据系统任务需要,采用本地加载或远程加载方式,灵活调度平台信号处理、I/O及存储资源,动态部署相应的功能软件,在基本处理单元模块上实现各种数字信号处理算法,任务切换响应时间不大于5 s。
传统的“联合式”系统以各个独立设备为基本单元来构建系统,一旦建成很难加入新的功能,系统不具备扩展、升级和成长能力[12]。而多核DSP矩阵采用开放式体系结构,以“硬总线”和“软总线”连接各个硬件和软件模块,通过软件或硬件模块的扩展来实现系统的升级和重构。多核DSP矩阵可任意扩展物理硬件模块和软件功能模块,且对系统已有部件不造成影响,系统内部运行的各功能线程之间无竞争关系。受益于通信中间件技术,系统具备软硬件隔离能力,即硬件升级时功能软件不受影响,软件升级时底层硬件不受影响。当模块出现故障时,故障仅限于模块内部,而不影响系统其他部分。系统能快速实现新功能部署,新功能插入时无需对系统整体重新测试,只需对新增模块进行功能测试。
4 结束语
多核DSP矩阵支持开放性和可扩展性设计,其核心思想是当新功能、新模块插入时与先前的功能线程无关,不对已有的功能线程造成任何影响。基于多核DSP矩阵的大规模阵列处理系统目前已在航空电子领域多个工程项目中得到应用,为系统的滚动迭代发展奠定了坚实的基础。
[1] 宋玉霞,李贵,甘峰,等.基于TMS320C667x和VPX的雷达处理系统设计及应用[J].无线电工程,2016,46(11):71-74.
[2] 张峰.嵌入式高速串行总线技术[M].北京:电子工业出版社,2017:23-25.
[3] TexasInstruments.TMS320C6678 Datasheet[S],2011.
[4] 陈颖,苑仁亮,曾利.航空电子模块化综合系统集成技术[M].北京:国防工业出版社,2013:102-105.
[5] 陈颖,陈德志.航空传感器综合处理机的开放式体系架构[J].电讯技术,2005,42(2):107-110.
[6] 李典,陈颖,邹传云.下一代交换机总线技术的研究与设计[J].电视技术,2007,31(2):52-54.
[7] IDT.CPS-1848 Datasheet[S],2011.
[8] 吕鹏.基于SRIO总线的全交换路由设计与实现[J].无线电通信技术,2017,43(2):87-89.
[9] 孙学.基于Fabric网络平台的中间件设计[J].电讯技术,2011,51(11):79-83.
[10] JOHN H,FRANCIS B.SCA Deployment Management:Bridging the Gap in SCA Deployment[M].Zeligsoft Inc,2006.
[11] TexasInstruments.KeyStone Architecture DSP Bootloader User Guide[S],2013.
[12] 杰夫-凯尔斯.分布式网络化作战:网络中心战基础[M].北京:北京邮电大学出版社,2006.
Design on a Multicore DSPs Matrix in Open System of Large-scale Array Signal Processing
LIU Ke
(SouthwestChinaResearchInstituteofElectronicTechnology,ChengduSichuan610036,China)
To meet the increasing requirements for high processing speed and I/O bandwidth of large-scale array signal processing systems,a multicore DSP matrix can be built based on VPX (VITA46) architectures.In this matrix,several basic processing element modules are connected through high-speed serial RapidIO switches to construct a required system topology structure.Combined with RapidIO communication middleware and customized DSP bootloading techniques,a multicore DSP matrix becomes into high performance and a loosely coupled parallel processing system with high performance is realized.This processing array has open architecture,supports the insertion of new tasks and up-to-date techniques,and can satisfy upgrading system requirements during the whole product life cycle.The multicore DSP matrix has been used in several avionics projects and provided strong support for system iterations and evolvements.
VPX architecture;multicore DSP matrix;array signal processing;open system
10.3969/j.issn.1003-3106.2017.07.23
刘可.开放式大规模阵列处理系统多核DSP矩阵设计[J].无线电工程,2017,47(7):94-98.[LIU Ke.Design on a Multicore DSPs Matrix in Open System of Large-scale Array Signal Processing[J].Radio Engineering,2017,47(7):94-98.]
2017-03-29
TN911
A
1003-3106(2017)07-0094-05
刘 可 男,(1978—),硕士,工程师。主要研究方向:航空电子设备高性能通用数字信号处理平台的开发和应用。
猜你喜欢
现代装饰(2022年4期)2022-08-31 01:41:24
净水技术(2022年1期)2022-01-13 00:45:28
今日农业(2021年9期)2021-07-28 07:08:36
科技资讯(2021年10期)2021-07-28 04:04:53
环境卫生工程(2021年3期)2021-07-21 05:34:36
广东通信技术(2020年7期)2020-08-13 06:01:42
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
信号处理(2018年5期)2018-08-20 06:16:02
信号处理(2018年5期)2018-08-20 06:16:00
