
基于LASSO回归模型与百度搜索数据构建的流感疫情预测系统
2017-06-05 14:20郝元涛
中国卫生统计 2017年2期
郭 貔 王 力 郝元涛
·论著·
基于LASSO回归模型与百度搜索数据构建的流感疫情预测系统
郭 貔1王 力1郝元涛2,3△
目的 探讨基于LASSO回归模型与百度搜索数据构建流感疫情预测系统的可行性。方法 采用Bagging方法和模型性能的多指标优化评估策略,对传统LASSO回归模型进行改进,构建性能提升的集成LASSO回归模型,将其应用于中国大陆地区季节性流感流行趋势的预测研究。结果 与传统LASSO回归模型相比,本研究所构建的集成LASSO回归模型对2011年至2015年中国大陆地区流感流行趋势的预测偏差更小,说明集成LASSO回归模型的外部推断能力更强,适合于流感疫情的预测分析;本研究开发了开源的R软件程序包SparseLearner,方便用户进行调用和进一步开发研究。结论 Bagging方法和多指标优化评估策略相结合所构建的集成LASSO回归模型,有效地增强了传统LASSO回归模型的性能。本研究所构建的预测模型可以应用于流感等传染病疫情的预测研究。
Bagging LASSO 流感 预测
流感的流行和暴发是中国大陆地区面临的重要公共卫生问题之一[1-4]。为了更好地预防和控制季节性流感在大规模人群范围内暴发和流行,研究者们已经开展了一些前沿的科学研究,利用社交媒体和搜索引擎等电子信息,以对流感的暴发和传播提供近似实时的监测[5-8]。Ginsberg 等(2006)[7]最早开始研究利用Google搜索数据对美国地区流感的流行趋势进行预测,且证实这种近似实时监测的方法对流感暴发的准确预测比传统哨点疫情监测方法提早了一周。
Marcel等(2013)[7]在著名的《新英格兰医学杂志》上讨论以社交网络和搜索引擎数据为媒介对传染病暴发进行实时或者近似实时的预测的“电子流行病学”(digital epidemiology)的发展,并认为这种方法能够有效地补充和完善传统的疾病监测方法。由于百度搜索引擎是目前中国大陆地区最为广泛使用的互联网搜索引擎,因此百度关键词的搜索量可以准确地反映中国互联网用户的网络搜索行为的主要特征。在2013年,Yuan等(2013)[9]首次探讨了采用百度搜索数据对中国大陆地区季节性流感流行趋势预测的方法学问题,根据百度用户搜索关键词的频次构建预警模型,证明了该方法能有效地对季节性流感的流行水平进行准确估计。该方法[9]需要事先使用不同权重对众多搜索词进行加权,构建一个复合的预测因子,并采用线性回归模型进行预测。实际上,使用搜索关键词构建预测模型,需要分析的搜索关键词的数目往往较多,这种处理方式使模型无法对每个关键词的贡献进行估计。另外,基于线性回归模型对流感流行与暴发进行预测的稳健性仍有待进一步提高。
我们以往研究(2015)[10]表明基于随机Bootstrap抽样方法构建的LASSO回归模型能够准确地识别关键变量并估计其效应。另外,在传染病监测应用领域,对传染病暴发期进行预测,我们需要根据不同的模型评价指标,全面地评估所构建模型对传染病流行与暴发的预测效果。因此,在构建传染病预测模型时,有必要综合多个评价指标对模型预测效果进行评估,从而使得所构建模型的预测效果在多个指标上同时达到最优。
本研究拟采用Bagging(1993)算法[11]结合多指标优化评估策略(2007)[12]对传统LASSO回归模型进行改进,探讨构建一种基于百度搜索数据的流感预测系统,使得模型预测的准确性和稳健性均有所提高,并将其应用于中国大陆地区季节性流感流行与暴发的估计。
原理与方法
1.LASSO线性回归模型
假设现有数据(Xi,yi),i=1,2,…,N,这里Xi=(xi1,…,xip)T和yi分别表示第i个观察值对应的自变量和因变量。在观察值彼此独立的前提下,该线性模型表示如下:
(1)
早在1995年,Breiman[13]提出变量收缩和系数估计同步进行的Nonnegative Garrote方法。该方法可表示为:
(2)

在此基础上,Tibshirani(1996)[14]提出了LASSO估计方法,弥补其缺陷。在线性回归模型的情况下,LASSO方法给出的系数估计表示为:
(3)

2.结合Bagging算法与多指标优化评估策略构建的集成LASSO回归模型
(1)Bagging算法的基本原理
Bagging算法将很多基础模型Ci进行集成产生一个复合预测模型,其通过对原有的训练数据进行Bootstrap重复抽样[15],从样本大小为n的原有数据中随机抽取nb个样本,构造一份Bootstrap样本。本研究采用有放回等样本抽样方法构造Bootstrap样本。进行多次Bootstrap抽样,产生多份Bootstrap样本数据,利用这些抽样数据训练基础模型Ci,最终将所有Ci的预测结果进行平均,形成稳定的预测结果。
(2)模型预测性能的多指标优化评估策略
实际上,基于多个指标确定一个最优模型是属于多指标优化的问题,其原理是每个单独指标根据自身取值大小对所有比较模型进行排序。假设以Li表示在指标i上所有模型的排序序列。这样对于K个指标而言,我们可以得到K个排列的模型序列L1,L2,…,LK,每个序列Li的长度代表所比较的模型的个数。因此,多指标评估便转化为整合分析上述K个排序的序列,以寻找一个最优的模型序列,使其与所有K个序列之间的距离最小。加权排序融合技术[16]可以用于求解这类多指标评估的优化问题。
上述寻找最优模型序列是一个经典的组合优化问题,可以采用加权排序融合技术进行求解。首先,定义一个目标函数:
(4)
在式(4)中,m是评估指标的数目,Li是模型排序列表中任何一个长度为k的已知的模型序列,δ是目标函数的可能解,wi是权重因子,而d是衡量任何两个序列之间相似程度的距离函数[17]。
那么,在所有可能的解中寻找一个最优的解δ*需要满足:
(5)
式(5)表示所要找的最优解将使得δ*与其他所有序列Li之间的距离最小。
加权排序融合技术用于寻找模型序列δ*,使δ*尽可能地逼近已知的模型序列Li,这个δ*就是目标函数(5)的一个最优解。所谓序列之间尽可能的“逼近”,其实质是选择合适的距离函数d测量任何两个序列之间的近似程度。通常地,距离函数d可以由斯皮尔曼简捷距离[18]或者其加权的形式描述。
假设现有一个已知序列Li,rLi(A)表示元素A在序列Li中的秩。对于任意序列δ而言,序列δ和Li之间的斯皮尔曼简捷距离定义为:
(6)
这里,序列δ和Li之间的斯皮尔曼简捷距离代表两个序列中所有不同元素秩序差值的绝对值总和。S(δ,Li)越小,表示二者的相似程度越高。当两个序列中元素的秩序完全不一致时,该距离达到最大值,表示二者之间相似程度很低。
若已知某个评估指标得分值,我们可以利用这部分信息定义一个加权形式的斯皮尔曼简捷距离[16]。假设Mi(1),…,Mi(k)表示序列Li中每个元素对应的指标分值(在我们的研究中,可以是灵敏度、特异度、AUC等评估指标取值),Mi(1)表示最优的分数,Mi(2)为次优的分数,依次类推。那么,任意两个序列δ和Li之间的加权斯皮尔曼简捷距离则表示为:
(7)
考虑到提高算法运算效率,本研究采用互熵蒙特卡洛方法求解寻找目标函数(5)的最优解δ*,以构建适合预测变量数目较大的流感疫情预测系统,其方法学原理详见文献[19]。
(3) 集成LASSO回归模型
结合Bagging与多指标优化评估策略,本研究改进传统LASSO回归模型,构建集成LASSO回归模型,应用于流感疫情的预测。下面给出集成LASSO回归模型的具体算法:
输入:
•(X,Y):原有数据包含n个样本和p个预测变量,(X,Y)∈n×(p+1)
•B:有放回Bootstrap重抽样次数
•nBootstrap:每次有放回Bootstrap重抽样的样本量
•M:子模型序列的长度
•K:子模型性能评估指标
•RP:预测变量随机子集的大小
•δ:子模型排序序列初始值
•d(.):子模型序列之间的距离函数
输出:模型最终预测ψaverage
1:forb=1toBdo
2:产生Bootstrap样本L=(Xb,Yb)∈nBootstrap×(p+1)
4:form=1toMdo
5:从原有预测变量集Xb中随机选择RP个变量

10:fork=1toKdo

12:end
13:end
15:根据矩阵VK×M产生模型性能排序序列{Ri=(C(1),C(2),…,C(M))i,i=1,…,K}
17:使用互熵蒙特卡洛方法求解该目标函数,得到目标函数的最优解
19:end

21:使用模型平均法实现模型的最终预测ψaverage=E[C(1)(R*)]
本研究构建的集成LASSO回归模型所采用的性能评估指标包括相对误差指标和绝对误差指标两大类,即相对误差(relative error,RE)、均方根误差(root mean square error,RMSE)、平均绝对误差(mean absolute error,MAE)和对称的平均绝对比例误差(symmetric mean absolute percentage error,SMAPE)。它们各自的定义如下:
(8)
(9)
(10)
(11)

在构建的集成LASSO回归模型中,我们采用非参数置换方法[23]客观地评估每个预测变量的重要性。在采用Bootstrap技术对原有数据集进行随机抽样时,我们使用袋外样本数据Xoob对集成LASSO回归模型进行评估。具体过程是:在利用袋外样本Xoob测度变量Xi重要性时,对该变量进行置换操作,并基于置换后的Xi与其余变量构建Bagging模型。如果置换变量的袋外样本预测错误率比未置换变量的预测错误率明显增大,说明该变量非常重要。
我们采用公式(12)测度Bagging模型中变量的重要性:
(12)
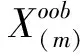
在上述理论与方法的基础上,我们开发了一个开源的R程序宏包SparseLearner(https://cran.r-project.org/web/packages/SparseLearner/index.html),其中集成LASSO回归模型主要由函数Bagging.LASSO实现。
实例分析
本研究中国大陆地区2011年1月至2015年5月之间的季节性流感发病病例数来自中国疾病与预防控制中心。联合百度指数网站(http://index.baidu.com/)和百度搜索关键词挖掘网站(http://s.tool.chinaz.com/baidu/words.aspx)初步确定100个与“流感”相关的检索词作为候选预测变量。在此基础上,通过文献[9]介绍的变量过滤规则进一步筛选得到58个预测变量。由于潜在影响因素对流感流行趋势可能存在延迟效应,考虑影响因素延迟一个月的效应,且将流感每月病例数作为自回归项纳入模型建模。这种做法是传染病统计建模分析常用的方法。最终,本研究纳入预测建模分析共有117个预测变量。由于预测变量的个数比样本量53大得多,此时使用最小二乘方法对模型系数进行估计是失效的。因此,有必要采用LASSO等稀疏估计方法建立模型,对流感流行趋势进行预测,分析其影响因素。
1.流感病例与百度搜索关键词数据
本研究使用中国大陆地区2011年1月至2015年5月之间的季节性流感发病病例数(表1)对集成LASSO回归模型和传统LASSO回归模型的预测效果进行比较和评估。关于百度搜索关键词数据,通过相关检索初步确定100个与“流感”相关的检索词作为候选预测变量。进一步过滤,筛选得到58个预测变量(表2)。同时将每月流感病例数作为模型的自回归项以及考虑预测变量的延迟效应,纳入预测建模分析共有117个预测变量。
2.两种模型预测效果的比较
本研究将2011年1月至2015年5月之间的流感病例数据拆分为两部分,以2011年1月至2014年12月时期的流感病例数据训练模型,分别拟合集成LASSO回归模型和传统LASSO回归模型,对2015年1月至2015年5月时期的流感病例数据进行预测。结果显示:集成LASSO回归模型的预测误差指标RMSE、MAE、RE和SMAPE的取值分别是4393.83、3590.16、24.16%和23.87%,小于LASSO回归模型的对应的预测误差(6326.23、5429.72、35.85%和39.60%)。图1给出了集成LASSO回归模型对该时期的流感流行趋势进行预测,集成LASSO回归模型给出的由第10百分位数和第90百分位数所构造的预测区间能够准确地覆盖该时期内季节性流感实际的流行曲线。

散点表示实际的流感病例数,绿色曲线表示拟合值,上段灰色曲线和下段灰色曲线分别表示第10百分位数和第90百分位数取值,灰色区域表示模型拟合时期范围(2011-01至2014-12),浅绿色区域表示模型预测时期范围(2015-01至2015年05)
图1 集成LASSO回归模型对流感流行趋势的预测
3.预测变量重要性测度
集成LASSO回归模型对预测变量的重要性进行测度。与季节性流感流行趋势最密切的前5个百度检索词分别是:“a型流感”、“话说甲型h1n1流感(延迟1个月效应项)”、“猪流感死亡人数”、“甲型流感 症状(延迟1个月效应项)”和“话说甲型h1n1流感”。根据预测变量重要性测度结果,我们可以判断在流感流行期间,人们通常采用这些检索词了解流感疫情。

表1 2011年1月至2015年5月中国季节性流感病例数
*:粗体的预测变量表示在第一步被剔除;斜体的预测变量表示在第二步被剔除;粗体加斜体的预测变量表示在第三步被剔除。
第一步:所选择的关键检索词的含义比较明确,能代表影响流感流行的因素;第二步:所选择的关键检索词是由特定时间单位(每月,每周或每日)构成的序列;第三步:所选择的关键检索词序列与流感病例序列的交叉相关系数≥0.4。
讨 论
本研究首先介绍了Bagging方法和模型预测性能的多指标优化评估策略的基本原理,在此基础上改进了传统LASSO回归模型,与百度搜索数据结合,构建了适合于流感疫情预测的集成LASSO回归模型。研究结果证实了所构建的集成LASSO回归模型有效地改善了传统LASSO回归模型的预测效果,能够为疾病监测与预警方法研究提供新的思路。
本文所构建的集成LASSO回归模型适用于因变量服从正态分布的数据。当数据样本量较小和变量相关性较强时,该模型对变量的选择和模型系数的估计具有较强的稳健性。基于百度搜索数据构建传染病疫情预测系统,需要综合地评估大量的检索词,利用有效的检索词对传染病流行趋势作出预测。正是由于集成LASSO模型对模型系数进行收缩估计,使得一些弱相关的预测变量不被纳入模型,提高了模型的整体预测效果。另外,本研究构建的集成LASSO回归模型是综合多个评价指标对模型预测效果进行评估,从而使所构建模型的预测效果在多个指标上同时达到最优。因此,本研究所提出的方法也适用于对模型预测效果进行综合评估的情况。
[1]Cowling BJ,Jin L,Lau EH,et al.Comparative epidemiology of human infections with avian influenza A H7N9 and H5N1 viruses in China:a population-based study of laboratory-confirmed cases.Lancet,2013,382(9887):129-37.
[2]Qi X,Qian YH,Bao CJ,et al.Probable person to person transmission of novel avian influenza A(H7N9) virus in Eastern China.BMJ,2013,347:f4752.
[3]Li Q,Zhou L,Zhou M,et al.Epidemiology of human infections with avian influenza A(H7N9) virus in China..N Engl J Med,2014,370(6):520-532.
[4]Feng L,Wu JT,Liu X,et al.Clinical severity of human infections with avian influenza A(H7N9) virus,China,2013/14.Euro Surveill.2014,19(49):20984.
[5]Chew C,Eysenbach G.Pandemics in the age of Twitter:content analysis of Tweets during the 2009 H1N1 outbreak.PLoS One,2010,5(11):e14118.
[6]Signorini A,Segre AM,Polgreen PM.The use of Twitter to track levels of disease activity and public concern in the U.S.during the influenza A H1N1 pandemic.PLoS One,2011,6(5):e19467.
[7]Ginsberg J,Mohebbi MH,Patel RS,et al.Detecting influenza epidemics using search engine query data.Nature,2009,457(7232):1012-1014.
[8]Doornik,JA.Improving the timeliness of data on influenza-like illnesses using Google search data.In 8th OxMetrics User Conference.George Washington University,Washington DC.2010.
[9]Yuan Q,Nsoesie EO,Lv B,et al.Monitoring Influenza Epidemics in China with Search Query from Baidu.Plos One,2013,8(5):e64323-e64323.
[10]Guo P,Zeng F,Hu X,et al.Improved Variable Selection Algorithm Using a LASSO-Type Penalty,with an Application to Assessing Hepatitis B Infection Relevant Factors in Community Residents.Plos One,2015,10(7).
[11]Leo Breiman.Bagging Predictors.Machine Learning,1996,24(2):123-140.
[12]Pihur V,Datta S,Datta S.Weighted rank aggregation of cluster validation measures:a Monte Carlo cross-entropy approach. Bioinformatics,2007,23(13):1607-1615.
[13]Leo Breiman.Better Subset Regression Using the Nonnegative Garrote.Technometrics,1995,37(4):373-384.
[14]Tibshirani R.Regression shrinkage and selection via the LASSO.Journal of the Royal Statistical Society.Series B(Methodological),1996,267-288.
[15]Efron B,Tibshirani R.An introduction to the Bootstrap.1993,Chapman and Hall.
[16]Pihur V,Datta S,Datta S.Weighted rank aggregation of cluster validation measures:a Monte Carlo cross-entropy approach.Bioinformatics,2007,23(13):1607-1615.
[17]Lin S,Ding J,Zhou J.Rank aggregation of putative microRNA targets with Cross-Entropy Monte Carlo methods.Preprint,presented at the IBC 2006 conference,Montreal.
[18]Fagin R,Kumar R,Sivakumar D.Comparing top k lists.SODA ′.03 Proceedings of the fourteenth annual ACM-SIAM symposium on Discrete algorithms,2003:28-36.
[19]Rubinstein RY.Optimization of computer simulation models with rare events.European Journal of Operational Research,1997,99(1):89-112.
[20]Hoens TR,Chawla NV.Generating Diverse Ensembles to Counter the Problem of Class Imbalance.Advances in Knowledge Discovery and Data Mining,2010,6119:488-499.
[21]Tin Kam Ho,Bell Labs,Murray Hill.IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(8):832-844.
[23]Breiman L.Random forests.Mach Learn,2001,45(1):5-32.
(责任编辑:郭海强)
Building a Prediction System of Influenza Epidemics with LASSO Regression Model and Baidu Search Query Data
Guo Pi,Wang Li,Hao Yuantao
(DepartmentofPreventiveMedicine,ShantouUniversityMedicalCollege(515041),Shantou)
Objective To evaluate the performance of a prediction system built with LASSO regression model and Baidu search query data.Methods Based on a strategy using a combination of Bagging and multi-measure optimization method,this study proposed an ensemble LASSO regression model which had an obviously improved performance,and applied it to predict the epidemics of influenza in China.Results The results showed that the improved model had significantly smaller prediction error rates than that of the conventional LASSO regression model for influenza cases during the study period of 2011-2015.This study designed an open source R package,SparseLearner,which was conveniently used and further developed.Conclusion The combination of Bagging and multi-measure optimization method is an efficient strategy to improve the performance of LASSO regression model.The proposed ensemble LASSO regression model in this study can be applied for the prediction of infectious diseases epidemics.
Bagging;LASSO;Influenza;Prediction
1.汕头大学医学院公共卫生与预防医学教研室(515041)
2.中山大学公共卫生学院医学统计与流行病学系
3.中山大学卫生信息中心、广东省卫生信息学重点实验室
△通信作者:郝元涛
猜你喜欢
早期教育(家庭教育)(2022年5期)2022-07-02
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
Defence Technology(2020年4期)2020-07-02
好孩子画报(2020年4期)2020-05-14
中国生殖健康(2019年2期)2019-08-23
青年与社会(2018年2期)2018-01-25
小猕猴智力画刊(2017年7期)2017-08-09
新高考·高二数学(2014年7期)2014-09-18
太空探索(2014年4期)2014-07-19
