
Modified molecular matrix model for predicting molecular composition of naphtha☆
2017-05-28 19:46KunWangShiyuLi
Kun Wang,Shiyu Li*
School of Chemical Engineering and Technology,Tianjin University,Tianjin 300354,China
1.Introduction
The re fining industry today has to comply with higher product quality specifications and more stringent environmental regulation,with more emphasis on the molecular composition of re fining products[1].The opportunity to generate the most value from down-stream assets requires the right molecule to be in the right place,at the right time and at the right price[2],which called molecular management.This is not an easy work,the key to realize molecular management is to get the molecular composition information of complex petroleum fraction.
A great deal of works have been carried out in predicting the molecular composition,such as the Stochastic Reconstruction(SR)method proposed by Neurock[3,4],Monte Carlo method put forward by Klein[5].Geem et al.[6]predicted the molecular composition of cracking feedstock naphtha according to the Entropy Maximum method.Jaffe et al.[7]raised the Structure Oriented Lumping(SOL)idea to describe the composition,reaction and properties of complex hydrocarbon mixtures.Ghosh and Jaffe[8,9]utilized the SOL model to estimate the octane number of 1471 kinds of gasoline,the results show that the prediction error is less than 2%[10].Zhang Lijun[11]developed a method to characterize petroleum naphtha by solving equation set established with industry regular physical parameters,such as distillation curves,density,PONAvalue etc.,the results consistent with the actualvalue approximately.Peng[12]proposed the molecular type homologous series(MTHS)matrix to describe the petroleum fraction.Zhang[13]developed an approach to transfer bulk properties into molecular composition.Wu and Zhang[14]accomplished the molecular characterization of gasoline and diesel streams based on MTHS molecular matrix.Bai and Li[15]optimized the model proposed by Wu,which improved the prediction accuracy of molecular composition of gasoline.
“Molecular management”is crucialto re fineries'survival,and the first step of molecular managementis to develop a methodology to characterize a petroleum fraction in the form of getting detailed molecule composition.Based on the MTHS Matrix model previously proposed,this research expands the MTHS representation matrix for naphtha,modifies the distribution assumption of the prediction model and generalizes distribution parameters constraints.Through prediction data ofeightgroups ofnaphtha samples and eightgroups ofgasoline samples,itis verified that the normaldistribution hypothesis is more applicable than gamma distribution hypothesis for the prediction model.And predict the molecular composition of the same naphtha sample with original and modified model respectively,the prediction data show that the improved model enhances the prediction accuracy,and it can be utilized to estimate the molecular composition of naphtha approximately.
2.MTHS Matrix Prediction Model
2.1.The principle of MTHS molecular matrix prediction model
On the basis of the two assumptions,we build a mathematical model.With the bulk properties as input condition,this mathematical model optimized by means of the genetic algorithm transforms bulk properties into molecular composition.The calculation procedure of the mathematical model is shown in Fig.1.

Fig.1.The calculation procedure of the mathematical model.
2.2.Objective function
The significant part of the modeling is to build an objective function.By seeking the optimal solution of the objective function we can obtain the distribution parameters of each homologous series in the molecular matrix,thereby completing the molecular composition prediction.The objective function is mainly composed of two parts of VTMSD(measured bulk properties)and VTPRED(bulk properties calculated by mixing rules),as shown in Eq.(1),and the calculation flowchart of objective function is shown in Fig.2.where T,P stand for distillation curve temperature and physical properties,respectively.V is the property.Superscripts of MSD denote bulk properties measured or estimated by correlations;PRED represents the bulk properties calculated by mixing rules;ω is the weight factor of each property in the objective function.In this research,the weight factors of each property are assumed to be the same.

There are different mixing rules for different properties,the mixing rules used in the calculation is shown in Table 1.
From explanation of the principle of MTHS molecular matrix prediction model above,it can be obtained that this method mainly consists of representation matrix construction and transformation methodology of bulk properties into molecular composition based on corresponding distribution assumption.So the study to improve the calculation model focuses on building a more detailed and better MTHS representation matrix for naphtha and seeks the more applicable distribution assumption for naphtha composition within each homologous series.
3.Improved Model
3.1.Extended molecular matrix
Through in-depth analysis of the naphtha composition data,the is oparaff in and naphthene homologous series can be divided into two columns respectively.Table 2 illustrates the new MTHS representation matrix for naphtha.The molecules with the same homologous series and carbon number are lumped into one entry of the matrix.Each number in the table represents the quantity of real molecules lumped into a virtual molecule,there are total of 202 kinds of real molecules in the matrix(all databases can be found in Aspen).In the table,np,mp,ip,o,n5,n6 and a represent n-paraffin,single methyl iso-paraffin,multi-methyl iso-paraffin,ole fins, five-membered ring alkane,sixmembered ring alkane and aromatic hydrocarbons respectively.
The establish ment of the property library of extended molecular matrix is completed based on the collection of 15 kinds of physical data of the 202 types ofpure substances,such as the critical compression factor,hydrocarbon ratio,and aniline point.These properties of each lumped molecule in the matrix are calculated according to Eq.(2).

where P is the property of matrix lumped molecule Piis the property of real molecules,and n is the number of real molecules lumped into this matrix molecule.
1992年,邓小平南方谈话后,改革开放的步子提速,环境保护的国际合作进入快车道。在加拿大等国政府的支持下,1992年成立中国环境与发展国际合作委员会(“国合会”),除吸收国外专家对中国环境保护与经济发展的建议外,也将中国的环境保护政策与态度向国际社会传播。市场导向的体制改革在1998年取得突破性进展,国务院机构改革撤销了一些工业制造业例如冶金、纺织等行业主管部委,但将副部级的国家环境保护局升格为正部级的国家环境保护总局,职能进一步强化。
3.2.Improved distribution assumption
3.2.1.Gamma distribution
In the calculation model,it is extremely important to determine the distribution form of molecular composition within each homologous series follows against a certain property.Based on distribution assumption and limitations of the distribution parameters,the calculation efficiency and the prediction accuracy of the model can be improved.Previous research assumed that the molecular composition of the entries within each homologous series is consistent with a Gamma distribution against its boiling point(or its molecular weight).Its probability density distribution function is shown as Eq.(3).Constraints of distribution parameters are exerted with the form of Eq.(4)in the optimization calculation(take the aromatic homolog as an example).

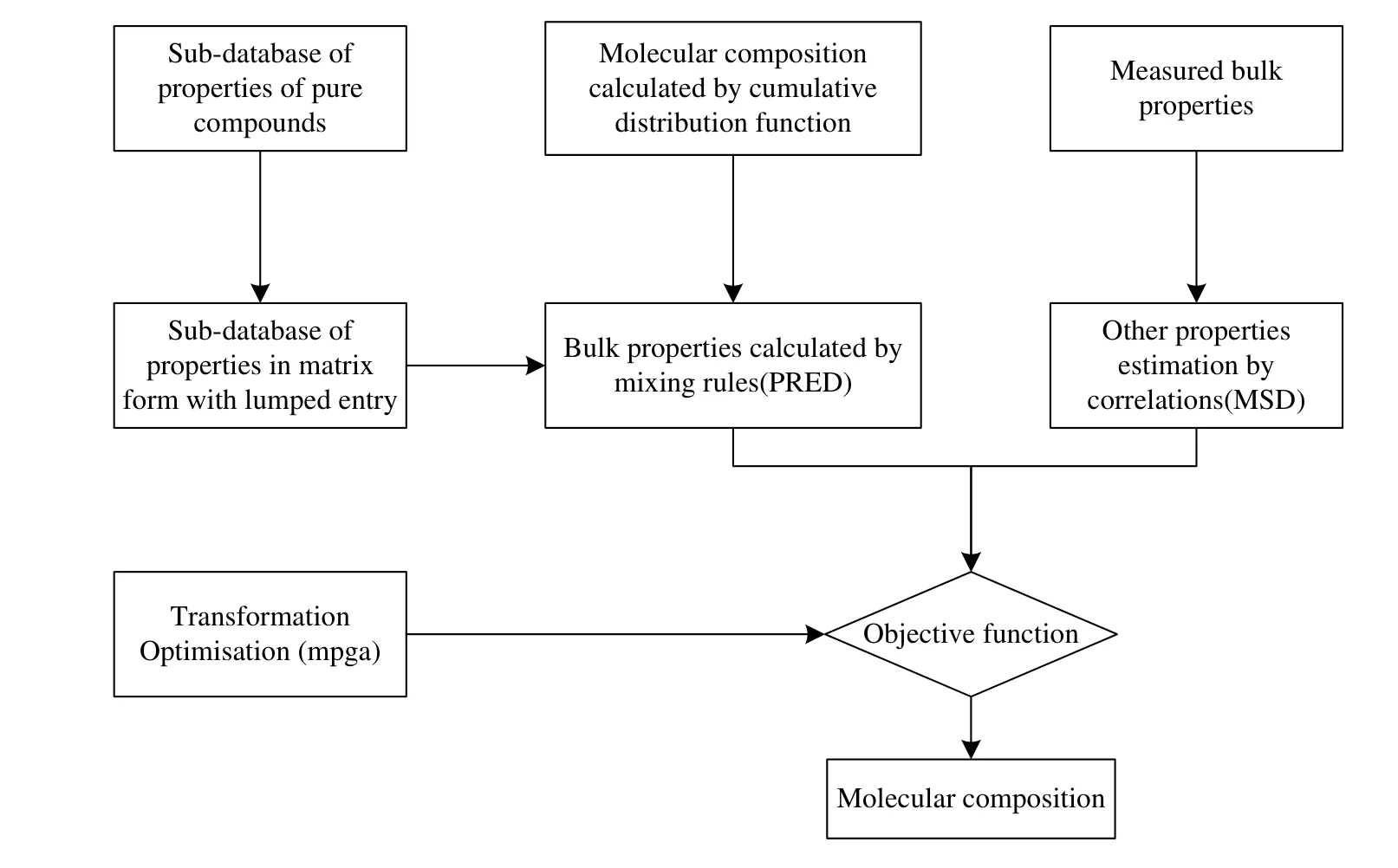
Fig.2.Calculation flowchart of objective function.
whereΡ(x)is the probability density function of gamma distribution;x is the boiling point of lumped molecules in each column of the molecular matrix; α,β and η are three parameters of Gamma distribution,which represent shape parameter,scale parameter,and position parameter respectively;Γ(α)is the gamma function;Ais the aromatic homologs;andare the boiling points of the corresponding matrix molecules in the aromatic column when the carbon number is 8 and 9 respectively.
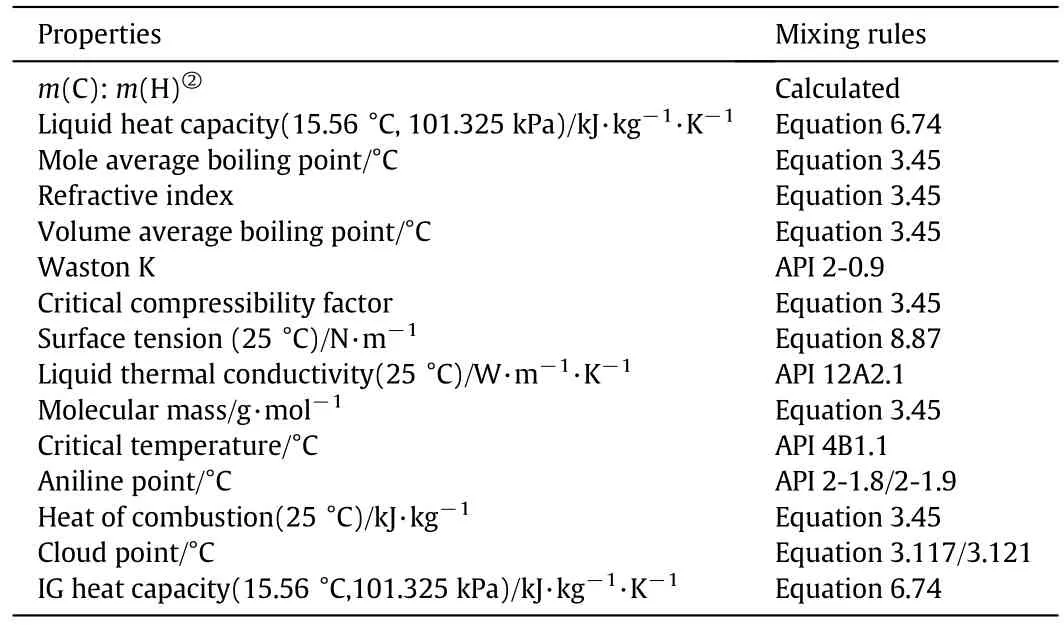
Table 1 Mixing rules for calculating bulk properties of mixture①

Table 2 Extended MTHS representation matrix for naphtha
The advantage of Gamma distribution lies in its excellent flexibility in statistics.Not only can describe the peak position and hump shape of statistical data,but also reflect the tailing situation of the data sensitively.Three-parameter gamma distribution has great diversity and flexibility,while also leading to the difficulty in parameter estimation[18].In the calculation model,the data points that can be used to fit the distribution curve are few,and the constraints are imposed on three together.In this case,their sensitive reactions to different tailing situations affect the extrapolation of the model,and gives rise to the difficulties in optimization process.
3.2.2.Normal distribution

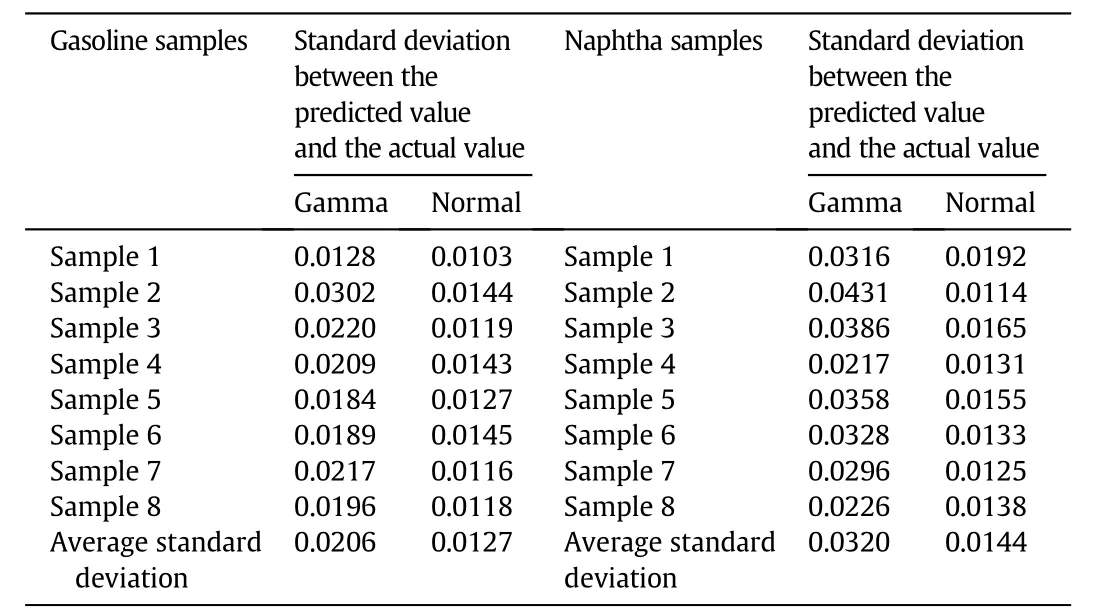
Table 3 Comparison of prediction standard deviation of gasoline and naphtha samples before and after distribution improvement
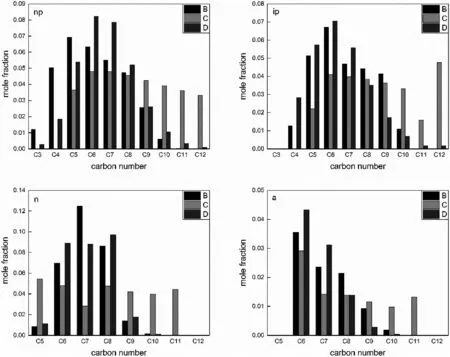
Fig.3.Comparison of the seventh group naphtha sample molecular composition B-measured value;C-gamma distribution model predicted value;D-normaldistri bution modelpredicted value.
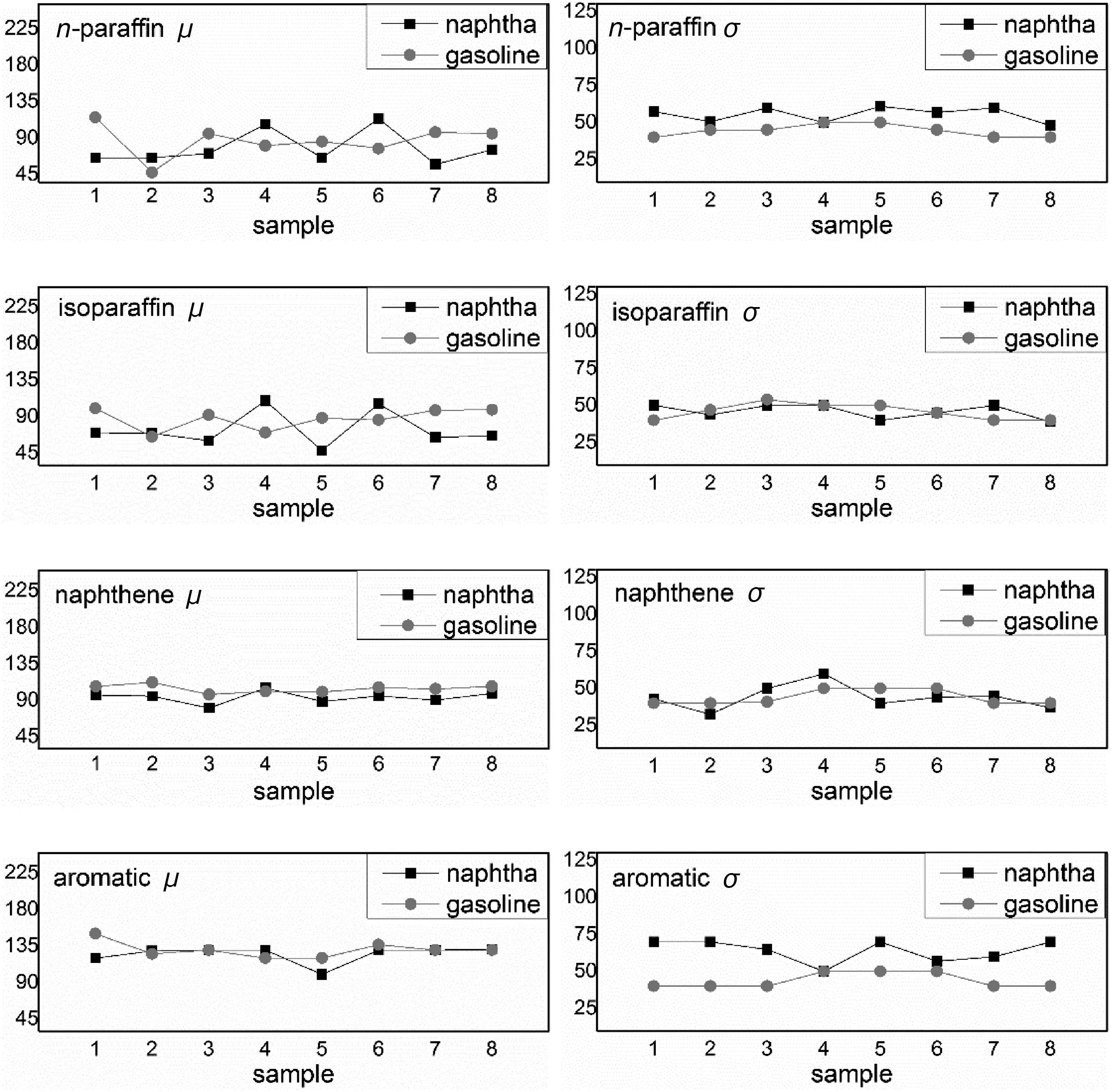
Fig.4.Normal distribution parameters μ,σ for gasoline and naphtha samples.
The probability density function of the normal distribution is shown in Eq.(5).where Ρ(x)is the probability density function of normal distribution;x is the boiling point of lumped molecules in each column of the molecular matrix; σ and μ are two parameters of normal distribution,representing the scale parameter and location parameter,respectively.The normal distribution can accurately describe the peak position and the hump shape of statistical data,which is sufficient for the molecular matrix calculation model.
As we can see,for each homologousseries,there are 3 parameters of gamma distribution(α,β,η)and 2 parameters of normal distribution(μ,σ).For the new extended molecular matrix,it has seven column homologs,so there are 21 distribution parameters estimated in Gamma distribution hypothesis and 14 distribution parameters are estimated in normal distribution hypothesis.It's obvious that the normal distribution modelcan reduce the unknown quantities in the optimization calculation process,which is useful for improving the computational efficiency too.
?
3.2.3.Improved results
Through the calculation of a large number of data,the higher adaptability of the normal distribution hypothesis for the model has been verified.The molecular components of 8 groups of gasoline samples[15]and 8 groups of naphtha samples[19-22]are predicted through the Gamma distribution hypothesis model and normal distribution hypothesis model respectively.The prediction results before and after the distribution modification are listed in Table 3 for the comparison.As shown in the table, the prediction deviation of the molecular components under the normal distribution hypothesis is relatively smaller than gamma compared with the actual composition. The standard deviation between the predicted value and the measured value of the gasoline samplewas reduced from0.0206 to 0.0127. The standard deviation of the naphtha sample is reduced from 0.0320 to 0.0144.
Select the seventh group naphtha sample as example,Fig.3 is The prediction results of Gamma distribution hypothesis model and normal distribution hypothesis model compared with the actual composition.

Table 4 Constrain ranges of normal distribution parameters
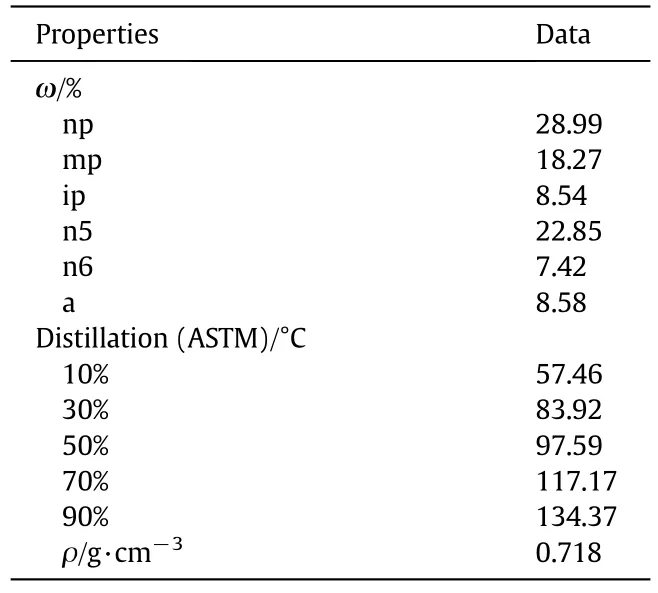
Table 5 The conventional physical property data of the naphtha sample
3.3.Distribution parameters constraints
The model adopts multi-population genetic optimization algorithm.With imposing constraints on parameters,the workload and calculating time of optimization process can be reduced greatly.The points in Fig.4 represent the normal distribution parameters μ ,σ of gasoline and naphtha samples in Table 3.As seen,n-paraffins of 16 samples have very close values of two parameters μ and σ,and homologous series of is oparaffins,naphthenes,and aromatics have the similar phenomenon,which means that the range of parameters μ,σ values of each homolog can be summarized in Table 4.
When the prediction calculation starts,the initial value of distribution parameters is generated automatically in this range and is optimized by MGPA in this range too.By this way,we can guarantee that the initial value and optimal value of distribution parameters are obtained in the correct range,which could decrease the predicting error largely.
4.Naphtha Composition Prediction Results
Table 5 shows the bulk properties of the seventh group naphtha sample in Table 3.Since the ole fin content in naphtha is small,negligible.The improved novel molecular matrix prediction model is utilized to predict the composition of this naphtha sample with its known conventional physical property.
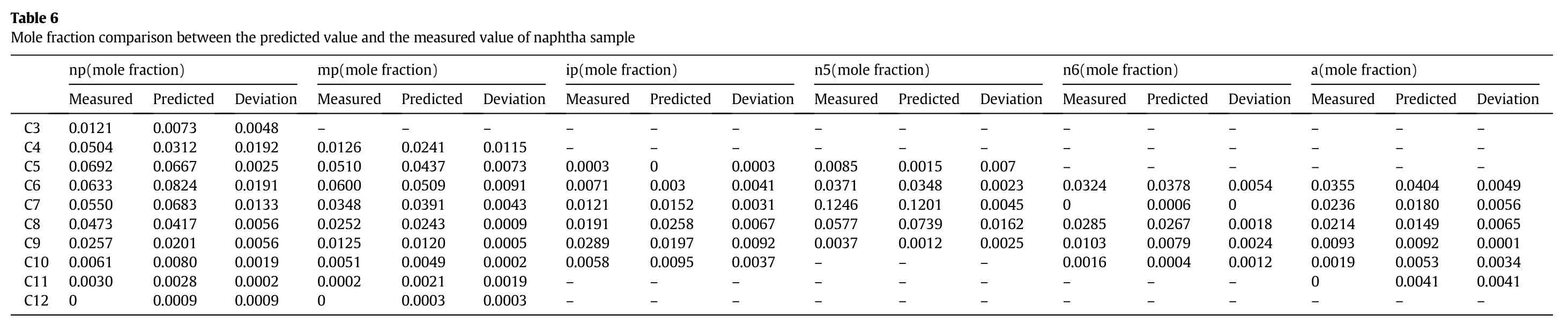
Table 6 and Fig.5 show the mole fraction comparison between the predictive value and measured value of the naphtha sample.The standard deviation between the predicted value and the measured value is 0.0104.

Fig.5.Predicted value and measured value of the molecular composition of naphtha sample B—measured value;C—predicted value.
5.Conclusions
(1)Improving solutions are proposed for the original naphtha composition prediction model based on MTHS molecular matrix:①Expand the molecular matrix for characterizing the naphtha composition.②Propose the normal distribution hypothesis which is more suitable for describing the molecular composition distribution within each homologous series in the molecular matrix.③Summarize the restrain range of distribution parameters in normal distribution model.
(2)The expansion of the molecular matrix facilitates the realization of predicting more detailed information about the naphtha composition.Eight groups of gasoline samples and eight groups of naphtha samples are predicted via the prediction model with improved distribution hypothesis.As the results indicate,the normal distribution hypothesis reduces from0.0206 to 0.0127 for the standard deviation between the predicted value and the actual value of the gasoline samples,and from 0.0320 to 0.0144 for the standard deviation of the naphtha samples.Therefore,it is obvious that the normal distribution hypothesis can improve the accuracy of the prediction model.
(3)By analyzing the prediction calculation results of eight groups of gasoline samples and eight groups of naphtha samples,this paper summarizes the constraints of distribution parameters for prediction model.Through applying the novel molecular matrix model with the improved molecular matrix size and distribution hypothesis,the composition of the naphtha samples in the seventh group is predicted.It is observed that the composition prediction accuracy of the naphtha sample achieves 0.0104 for the standard deviation between the actual value and predicted value.
(4)Based on the MTHS molecular matrix model,any naphtha sample can be characterized effectively only by its ordinary industrial physicochemical properties.And the major advantage of this model than others is that it proposes more appropriate distribution assumption for naphtha,which better solves the problem that different molecular compositions could be obtained with the same physicochemical properties.Through calculation of naphtha sample,the predicted resultachieves 0.0104 for the standard deviation between the actual value and predicted value,compared with the standard deviation 0.0320 of the original model,the accuracy has been increased significantly.Hence,it is believed that the novel model can be adopted to approximately estimate the molecular composition of naphtha.
[1]M.I.Ahmad,N.Zhang,M.Jobson,Molecular components-based representation of petroleum fractions,Chem.Eng.Res.Des.89(4)(2011)410-420.
[2]M.S.Aye,N.Zhang,A novel methodology in transformation bulk properties of re fining streams into molecular information,Chem.Eng.Sci.60(23)(2005)6702-6717.
[3]M.Neurock,A Computational Chemical Reaction Engineering Analysis of Complex Heavy Hydrocarbon Reaction Systems,University of Delaware,Delaware,1992.
[4]M.Neurock,A.Nigam,D.Trauth,M.T.Klein,Molecular representation of complex hydrocarbon feedstocks through efficient characterization and stochastic algorithms,Chem.Eng.Sci.59(1994)4755-4763.
[5]M.Neurock,C.Libanati,A.Nigam,Monte Carlo simulation of complex reaction systems:molecular structure and reactivity in modeling heavy oils,Chem.Eng.Sci.45(8)(1990)2083-2088.
[6]K.M.V.Geem,D.Hudebine,M.F.Reyniers,Molecular reconstruction of naphtha steam cracking feedstocks based on commercial indices,Comput.Chem.Eng.31(9)(2007)1020-1034.
[7]R.J.Quam,S.B.Jaffe,Structure-qriented lumping:describing the chemistry of complex hydrocarbon mixtures,Ind.Eng.Chem.Res.3(1992)2483-2497.
[8]P.Ghosh,K.J.Hickey,S.B.Jaffe,Development of a detailed gasoline compositionbased octane model,Ind.Eng.Chem.Res.45(1)(2006)337-345.
[9]P.Ghosh,Predicting the effect of cetane improve on disel fuels,Energy Fuel 22(2)(2008)1073-1079.
[10]T.Qiu,J.C.Chen,Z.Fang,Molecular reconstruction model for petroleum fractions based on structure oriented lumping,J.Tsinghua Univ.(Sci.Technol.)56(4)(2016)424-429.
[11]L.J.Zhang,Y.G.Zhang,G.Q.Wang,Research on prediction of naphtha composition based on commercial indices,Chem.Ind.Eng.Prog.30(2)(2011)278-283.
[12]B.Peng,Molecular Modeling of Petroleum Process,UMIST,Manchester,1999.
[13]Y.Zhang,A Molecular Approach for Characterization and Property Predictions of Petroleum Mixtures with Application to Re finery Modeling(Ph.D.Thesis)Institute of Science and Technology,University of Manchester,Manchester,1999.
[14]Y.W.Wu,N.Zhang,Molecular characterization of gasoline and diesel stream,Ind.Eng.Chem.Res.49(24)(2010)12773-12782.
[15]Y.Y.Bai,S.Y.Li,MTHS molecular matrix model for predicting molecular composition of gasoline,Petrochem.Technol.44(12)(2015)1433-1438.
[16]M.R.Riazi,Characterization and Properties of Petroleum Fractions,ASTM International,Philadelphia,PA,2005.
[17]Technical Data Book-Petroleum Re fining,sixth ed.American Petroleum Institute,Washington,D.C.,1997
[18]L.Y.Jiang,Estimation of the Parameters of the Generalized Gamma Distribution,Master Thesis,Southwest Jiaotong University,Chengdu,2014.
[19]J.Wang,F.Jiao Guo,X.Zhou,Prediction of naphtha composition based on conventional physical properties,Pet.Process.Petrochem.44(12)(2014)84-87.
[20]Y.Ding,M.X.Cheng,Q.Zhu,Research on method of composition prediction of naphtha based on online raman spectrometer,Transducer Microsyst.Technol.31(12)(2012)69-75.
[21]Y.L.Bao,W.M.Guo,X.D.Sun,Gas chromatography assay naphtha group composition,Inn.Mong.Petrochem.Ind.20(3)(1999)116-119.
[22]G.Song,T.Qiu,L.Tian,A method to predict naphtha detailed composition based on normal physical characteristics,Comput.Appl.Chem.28(11)(2011)1367-1371.
猜你喜欢
江苏科技报·E教中国(2022年5期)2022-05-11
江苏科技报·E教中国(2022年5期)2022-05-11
江苏科技报·E教中国(2022年5期)2022-05-11
江苏科技报·E教中国(2022年5期)2022-05-11
新传奇(2017年26期)2017-09-03
中国环境监察(2016年9期)2016-10-24
中国环境监察(2016年11期)2016-10-24
 Chinese Journal of Chemical Engineering2017年12期
Chinese Journal of Chemical Engineering2017年12期
- Chinese Journal of Chemical Engineering的其它文章
- Transport properties of dilute ammonia-noble gas mixtures from new intermolecular potential energy functions
- Solid-liquid equilibrium of dimethyl terephthalate(DMT),dimethyl isophthalate(DMI)and dimethyl phthalate(DMP)in melt crystallization process
- Analogy between adsorption and sorption:An elementary mechanistic approach.I.Monolayer adsorption and sorption without solvent cluster formation
- Permeation properties of CO2 and CH4 in asymmetric polyethersulfone/polyesterurethane and polyethersulfone/polyetherurethane blend membranes
- An efficient green route for hexamethylene-1,6-diisocyanate synthesis by thermal decomposition of hexamethylene-1,6-dicarbamate over Co3O4/ZSM-5 catalyst:An indirect utilization of CO2☆
- Pt-H2SO4/Zr-mont morillonite:An efficient catalyst for the polymerization of octamethylcy-clotetrasiloxane,poly methylhydrosiloxane and hexamethyldisiloxane to low-hydro silicone oil☆