
Degree-Based Probabilistic Caching in Content-Centric Networking
2017-05-09 03:03:38MengZhangJianqiangTangYingRaoHongbinLuoHongkeZhang
China Communications 2017年3期
Meng Zhang, Jianqiang Tang, Ying Rao, Hongbin Luo, Hongke Zhang
School of Electronics and Information Engineering, Beijing Jiaotong University, Beijing, China
I. INTRODUCTION
With the ongoing expansion of network scale,the global Internet traffic has increased eightfold in the past five years [1], and the annual traffic will surpass the zettabyte (i.e., 1,000 exabytes) threshold in 2016 [2]. The growth of Internet traffic far exceeds the growth of both the network equipment amounts and the device processing speed, and has motivated the increasing demand for highly efficient distribution of content [3-4]. In this context,Content-Centric Networking (CCN [5], also known as Named Data Networking (NDN)[6]) has emerged as a promising candidate for the future Internet architecture.
CCN has attempted to redesign the Internet to be information-centric and developed a possible network architecture which is more suitable for accessing and distributing content effectively by naming content at the network layer. In CCN, contents are retrieved by the location independent content names, rather than by the endpoint node addresses. Consequently, users subscribe to contents by forwarding requests to the network and then the network routes the requests to the nearby copies of desired contents by using the content names.This in turn makes it attractive for CCN to leverage ubiquitous in-network caching since doing this can reduce both the user access latency and network traffic [7-8].
We summarize the basic operations of in-network caching as follows. i) A router (or called Content Router (CR) in CCN terminology) can hold one copy when it forwards a content, which can be carried by any protocol(not restricted to a special protocol like HTTP)and may come from any source, including the Internet Content Provider (like CDNs) and network users (like P2P networking). ii) The CR can directly respond a request if it has cached the corresponding content. iii) When a CR’s caching capacity is insufficient, the cached content can be replaced in line-speed[9] by using some cache replacement algorithms (e.g., the Least Recently Used (LRU)replacement algorithm [10-11] and the Least Frequently Used (LFU) replacement algorithm [12]). In-network caching can heavily affect the content delivery performance. First,by fetching the content from the nearby CRs,in-network caching can reduce the access latency and bandwidth consumption, thereby decreasing network traffic and alleviating congestion. Second, because of the reduction in network traffic, those non-cached contents can also be retrieved relatively faster than without caching. Final, it reduces the workload of the remote content source by disseminating content among the CRs over the wide area network.
In this paper, the authors propose a novel implicit cooperative caching scheme to efficiently reduce the caching redundancy and improve the cache resources utilization.
But there is a common understanding that the CCN default caching scheme faces the problem of low efficiency because the CR indiscriminately holds a copy of every incoming content as long as possible [10] (called “Cache Everything Everywhere (CEE)” or “homogenous caching [13]”). As a result, every CR along the path from the content source to the requester caches the same content, which results in the caching redundancy. Simultaneously, it is easy for the cache resource to be occupied by some unpopular contents (i.e., the infrequently accessed contents), leading to a low cache hit ratio.
In this paper, we are devoted to building a novel implicit cooperative caching scheme and make the following contributions.
Firstly, we develop a mathematical model of caching system and get some innovative,interesting and thought-provoking conclusions.
Secondly, according to the conclusions, we design an implicit cooperative caching scheme that is flexible and easy to deploy with the aim of reducing the caching redundancy and hence improving the cache resources utilization.
Finally, we establish simulations on OMNeT++ and prove that our design performs better in comparison with the typical caching schemes.
It should be noted that we use “CRs” and“caches” interchangeably to refer to the cacheequipped CCN content routers. The rest of this paper is organized as follows. Section II provides an overview of the related work. Section III discusses the caching system model and basic designs of the degree-based probabilistic caching scheme. Section IV describes the simulation environment and corresponding results. Finally, we analyze our findings and make a conclusion in Section V.
II. RELATED WORK
To lay the foundation for the following indepth discussions, this section covers the introduction of CCN, some tipical caching schemes and models, and relevant problems analysis.
2.1 CCN overview
Different from the original IP addresses, CCN introduces a hierarchical namespace structure which is similar to the current Uniform Resource Locators (URLs). Each fragment of content (or called content chunk) that may be published in the network has a hierarchically structured name and each component of the name can be anything, like a string or a hash value. In addition, a CCN name is always human-readable (e.g., www.bjtu.edu.cn/logo.jpg,where the slash denotes the delimiter between different components of a name). The naming can make it possible for users to remember the content names and, to some extent, to establish the mapping between a content name and what the user wants.
CCN should be able to locate a content based on its name, which is called name-based routing. Two types of packets are defined in CCN: Interest Packet and Data Packet. Each CR maintains three major data structures: the Pending Interest Table (PIT), the Forward-ing Information Base (FIB), and the Content Store (CS). The FIB which is created based on the name routing protocol, is used to forward Interest packets toward the content source(s).The PIT keeps track of Interest packet so that the returned Data Packet can be sent to its original requester(s). The CS holds a copy of the arriving Data packet according to the caching scheme and replaces the cached Data packet by using the cache replacement algorithms.
We now illustrate how to retrieve content in CCN, as illustrated in Fig. 1, and assume that a given user (i.e., the User A in Fig. 1)requests for the content (i.e., www.bjtu.edu.cn/logo.jpg, WL for short). When a CR (e.g.,R1) receives the Interest packet, it consults its FIB to send the Interest packet to the potential content source, as illustrated by (1) in Fig. 1.If an entry is matched, the Interest’s content name and incoming interface are recorded in an entry of its PIT and it is pushed to the CR R2indicated by the FIB, as illustrated by (2) in Fig. 1. R2queries its FIB and adds a new entry for the content name in its PIT, then forwards the Interest packet to the content source, as illustrated by (3) and (4) in Fig. 1. Simultaneously, once the PIT discovers an entry for the specific content name, it will record the incoming interface and aggregate the Interest packets.
If R2receives the Data packet, the Data packet will be cached in the CS and forwarded based on the recorded interface. After that,R2deletes the corresponding entry from its PIT, as illustrated by (5) in Fig. 1. It should be noted that the CR will respond to an Interest packet directly if there exists a copy of the particular Data packet in its CS. For example,when R2receives the subsequent Interest packet for the same Data packet, it responds to the Interest packet and sends the cached copy to the requester.
2.2 Non-cooperative caching
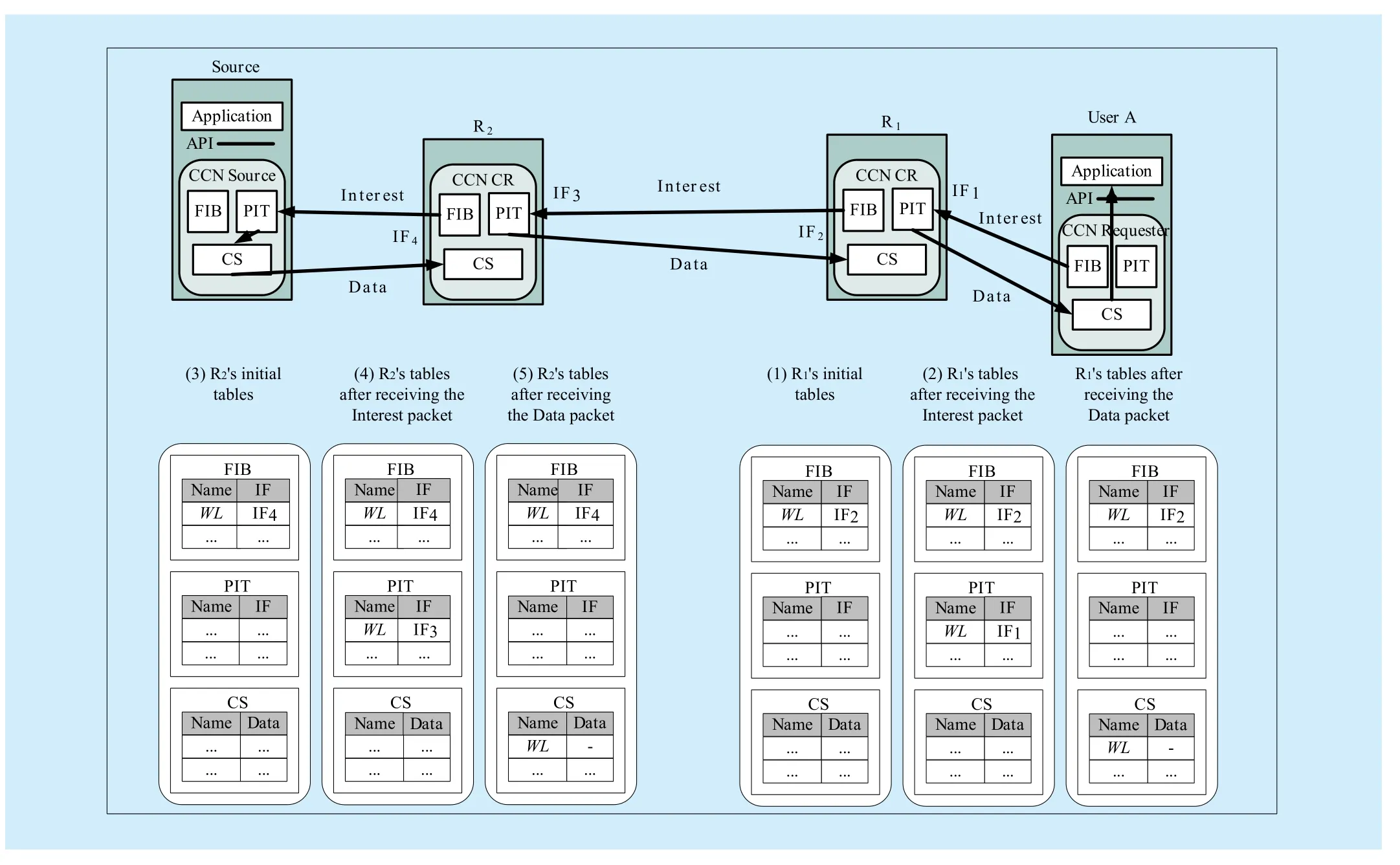
Fig. 1 Illustration for content retrieval in CCN. IF stands for Interface
In recent years the networking community has proposed many caching schemes and some of them are classified into the non-cooperative caching scheme. Specifically, in the non-cooperative caching scheme a CR independently decides whether to cache the arriving Data packet or not, rather than cooperates with other CRs. Below we describe three typical non-cooperative caching schemes.
CEE is the CCN/NDN default caching scheme, where CRs are required to remember the arriving Data packet as long as possible[10]. All CRs along the downloading path between the content source and the requester can be considered as the caching points which indiscriminately cache the incoming Data packet. As a result, the same copies of a given Data packet are cached at every CR along the downloading path. Prob(p) [14] is another typical non-cooperative caching scheme which requires CRs to cache the arriving Data packet with the probability ρ. In Prob(p), the more times that a Data packet passes through a CR,the higher probability it would be cached at this CR. Prob(p) can effectively promote the cache resources to be occupied by the popular Data packet, thus improving the caching efficiency.
The heterogeneous provisioning has recently become a focus that attracts great attention from the researchers. Different from the traditional homogenous cache provisioning methods where all CRs possess the same cache size, the authors of [13] have proposed a novel concept that a series of graph-related central indicators are used to determine the cache size of each CR when the overall network cache size is fixed.
2.3 Explicit cooperative caching
In the explicit cooperative caching, CRs work cooperatively by using the cache state advertisement mechanism which can advertise the information of cached content. For example,Intra-AS Co [15] is a typical explicit cooperative caching scheme and it requires a CR to advertise the information of cached content (or called cache summary in [15]) to the directly connected neighbors. But due to the frequent replacement of some cached contents, this explicit cooperation needs to control the advertisement cost. Unfortunately, to the best of our knowledge, we did not notice such work at present.
2.4 Implicit cooperative caching
Different from the explicit cooperative caching, the implicit cooperative caching realizes the cooperation without advertising the information of cached contents. For instance, LCD[14] is a typical implicit cooperative scheme and aimed at reducing the caching redundancy. In LCD, the higher the access count of a particular Data packet is, the more copy of this Data packet will be hold by the network caches, thus the popular one (i.e., the frequently accessed Data packet) can be cached at network edge. Probcache [8] is another implicit cooperative caching scheme. If the CR is close to the user, the Data packet will be cached with high caching probability. Conversely, if the CR is far from the user, the Data packet has little chance of being cached. This scheme can quickly push the copy to the network edge and meanwhile reduce the caching redundancy.
2.5 Caching models
In order to make best usage of in-network caching, the networking community has also proposed many caching models in recent years. For example, by using Markov chain for cache system modeling, the proportion of time for a specific Data packet to be cached by a CR is given in [16]. The main disadvantage of this method is that it only considers the case of the LRU replacement algorithm.
III. DEGREE-BASED PROBABILISTIC CACHING
3.1 The cache system modeling
As we know, CCN divides a large content into many small Data packets and each cached Data packet corresponds to a space block of CS. Assuming that the R1’s CS has N-1 space blocks, we use S (S=1, 2, ..., N) to denote the state of the space block (denoted by Bj) which caches the particular Data packet (this Data packet is denoted as Di). For example, state 1 implies that Dihas been just cached or updated(via cache hit) in the block Bj. When another new Data packet is cached in other space blocks, we add the state of Bjby one. State N means that Diis replaced and evicted from the block Bj. It should be noted that in order to optimize the cache system modeling, we only consider the Data packets which influence the Markov chain state.
The Markov chain model of the block Bjis presented with the help of Fig. 2. We assume that the Data packet Diarrives at R1with the rate λ (now the state S has a transition to state 1), while the other uncached Data packets arrive at R1with the rate μ. It is worth mentioning that the so-called “other uncached Data packets” can be classified into two categories,the recently cached Data packet which replaces the particular Data packet Di(its arrival rate is denoted by μr) and the Data packet which replaces the other cached contents (its arrival rate is denoted by μc. μ = μr+μc). We also assume that the other cached Data packets arrive at R1with the rate ν.
In particular, since the state S transfers to state 1 when the Data packet Diarrives, the probability for other chain states to be transferred to state 1 is λ/(λ+μ+ν). Similarly, the state S transfers to the state S+1 with the probability μc/(λ+μ+ν) and transfers to state N with the probability μr/(λ+μ+ν). The Markov chain and its transition probabilities are shown in Fig. 2.
The transition probability matrix is shown as follows:
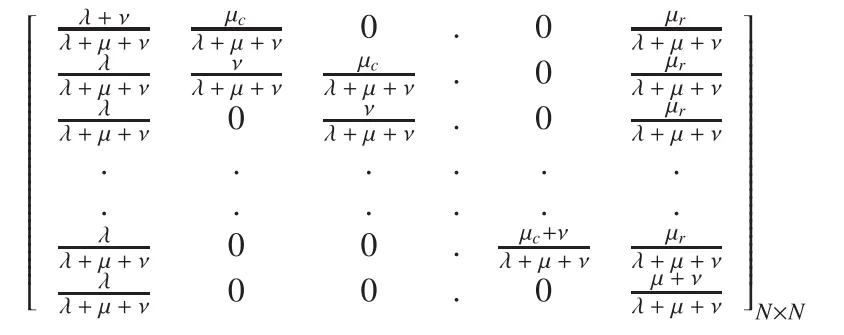
The equilibrium probability of state N is:
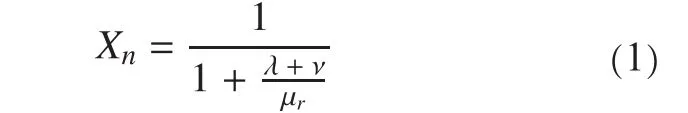
This equation gives the proportion of the time that Diis not in the R1’s CS. According to Eq. (1), we know that improving the CR’s cache size will reduce the value of μrand then reduce the value of Xn.
Conclusion 1:Improving the cache size of routers can make the Data packet that has been cached remain longer.
3.2 Probabilistic caching
When a CR caches the Data packet with the probability ρ, the Markov chain and its transition probabilities are illustrated with the help of Fig. 3.
The transition probability matrix is as follows:
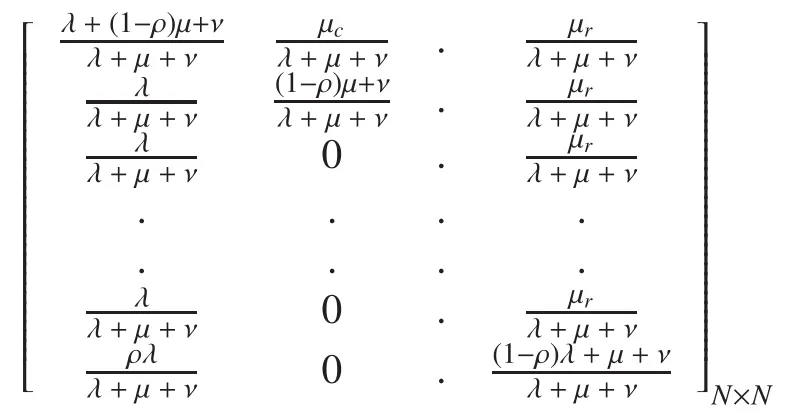
The equilibrium probability of state N is:
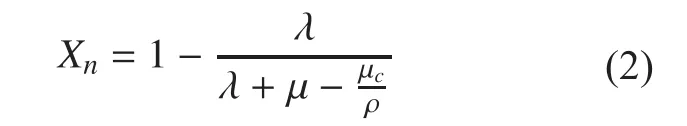
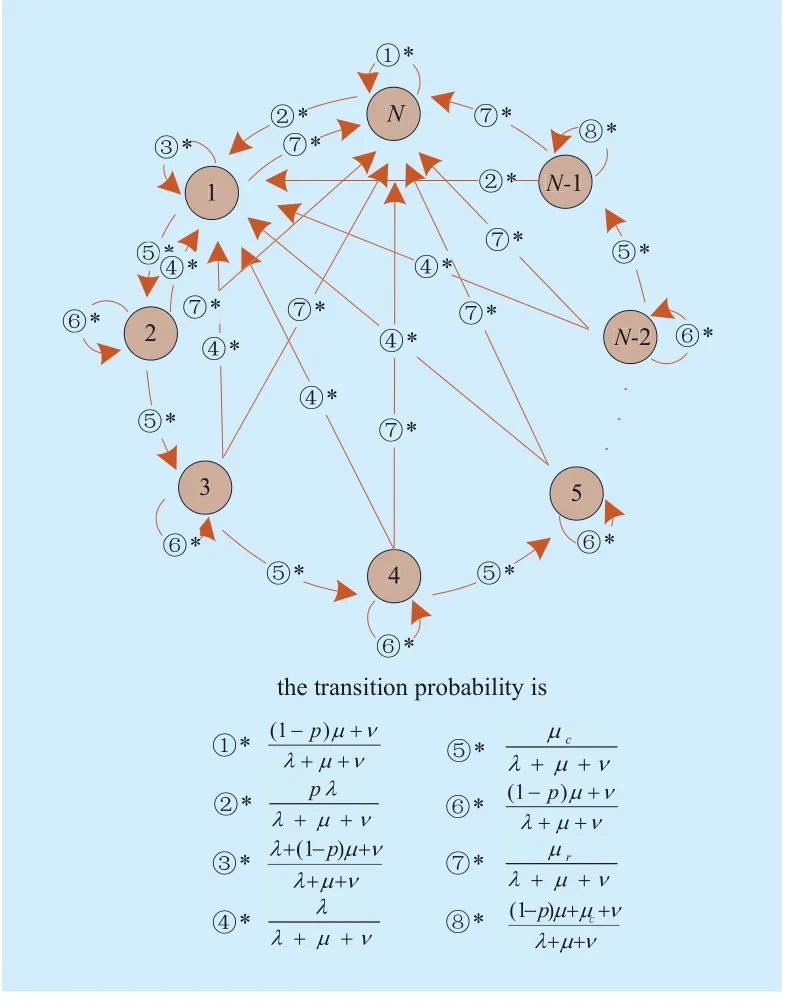
Fig. 2 The Markov chain model of Bj
From Eq. (2), we can get the additional conclusion that the smaller the caching probability of the heavily loaded router which has a higher value of μ is, the lower the equilibrium probability of state N (i.e., Xn) will be. That is to say, the cached Data packet can be remained for a longer time by the heavily loaded CR which has a smaller caching probability.Meanwhile, reducing the caching probability can make the cache space to be occupied by the popular Data packet.
Conclusion 2:Reducing the caching probability of heavily loaded router can make the popular Data packet that has been cached remain longer.
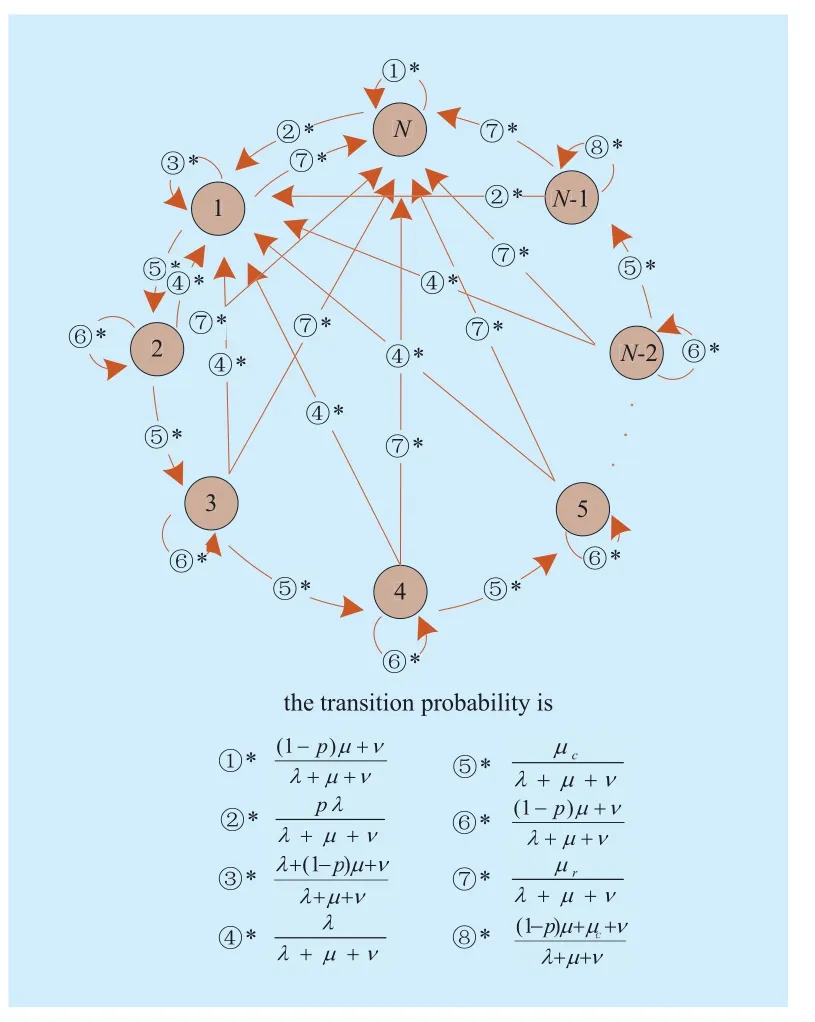
Fig. 3 The Markov chain model of Bj when the CR caches the Data packet with the probability p
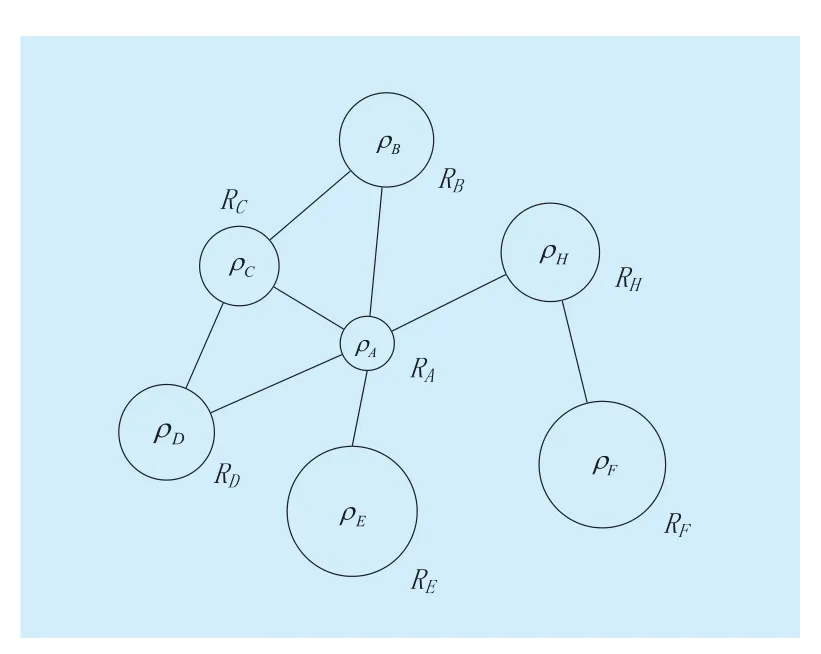
Fig. 4 The example of CRs’ caching probability.The circle area stands for the caching probability,i.e., the larger the area is, the greater the probability will be
The heavily loaded node is considered“important” since it usually has a high node degree centrality. It therefore needs to play a central role in caching scheme and intuitively should cache the arriving Data packet as far as possible. But Conclusion 2 shows that the heavily loaded CR is supposed to have a small caching probability and the popular Data packet can be cached longer by this CR.
Based on Conclusion 2, we propose a new implicit cooperative caching scheme, called Degree-Based Probabilistic Caching (DBPC),to improve the efficiency of cache resource and be easier to deploy in large networks. In DBPC, CRs cache the arriving Data packets with different caching probabilities and the one with a high degree centrality has a small probability. The following subsection details the basic design of DBPC.
3.3 Basic Designs
From Conclusion 2, we know that the network operator should allocate a small caching probability to the heavily loaded CR. An ideal scene is that each CR’s caching probability is calculated online according to the real-time traffic. However, the problem with this approach is that it’s difficult to deploy experimental work on the Internet. Therefore, DBPC requires that each CR’s caching probability should be pre-calculated offline according to the topological information. When the adjacent link number of a particular CR is relatively high, the caching probability it gets through calculation will be smaller, shown as Fig. 4.
The node degree is defined as the number of links that are connected with the node(Here, we consider an undirected graph). Let G (V, E) be an undirected graph with VCRs and Eedges. DBPC uses the node degree to calculate the caching probability of each CR(denoted by prob(r), r∈V), as illustrated by Eq. (3).
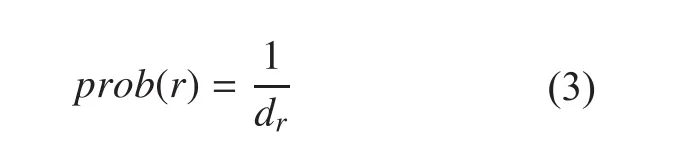
3.4 Core benefits
Three benefits are reaped from DBPC:
1) Efficient cache utilization
Different from the CCN default caching scheme, DBPC can reduce the caching redun-dancy efficiently and make CRs store various Data packets so as to satisfy much more Interest packets, thus improving the caching efficiency. In addition, with the increase of access count, the popular Data packet is inclined to be cached by CRs in DBPC, bringing about a higher cache hit ratio. Compared to Prob(p),DBPC can push the popular Data packets to network edge quickly. And compared to Probcache, it calculates the caching probability in a flexible manner and sets the probability in advance.
2) Stable cached contents
The popular Data packet that has been cached by the heavily loaded CRs is replaced more quickly in the existing solutions. DBPC applies a new caching scheme to distinguish the caching probabilities of different CRs. The popular Data packet tends to be cached for a longer time at heavily loaded CRs and difficult to be replaced by the unpopular Data packet.Therefore, by reducing the cache replacement rate, the Interest packets for popular Data packet can be satisfied potentially by the “important” CRs that have a high degree centrality.
3) Explicit cooperation
In DBPC, by using the implicit cooperation the caching probability of each CR is pre-calculated offline based on the topological information and available for determining whether to cache an arriving Data packet or not. Since the implicit cooperation has no advertisement cost, DBPC is easy to deploy in large scale network.
IV. PERFORMANCE EVALUATION
4.1 Experimental setup
We perform simulation experiments on the AS-3967 topology [17]. The simulation topology and the partial AS-3967 topology (the part located in the United States) are illustrated in Fig. 5(a) and (b), respectively. Table I lists the simulation parameters and their values.Among these parameters, the cache size is set to be the total relative size of all contents available in the content source. We assume a scenario consisting of 180 clients which are randomly attached to CRs, and one content source which is attached to the egress router and can store 100,000 chunks with each size at 10KB.
We implement the simplified CCN architecture in a custom C++ simulator using the OMNeT++ framework. In the simulations, CRs support the chunk-based caching, per-chunk request, and request aggregation through such three basic data structures as CS, PIT and FIB.By convention, we suppose that the CCN architecture uses the shortest-path-routing. The content source advertises the availability of content that it holds, and responses with Data packets when it receives Interest packets. The client access patterns are assumed to follow the Zipf distribution with the Zipf parameter set to 1 [18]. In the simulations, we assume that the arrival process of Interest packets at each CR follows a Poisson process and each CR has the same cache size.
Fig. 5 The simulation topology and the partial AS-3967 topology
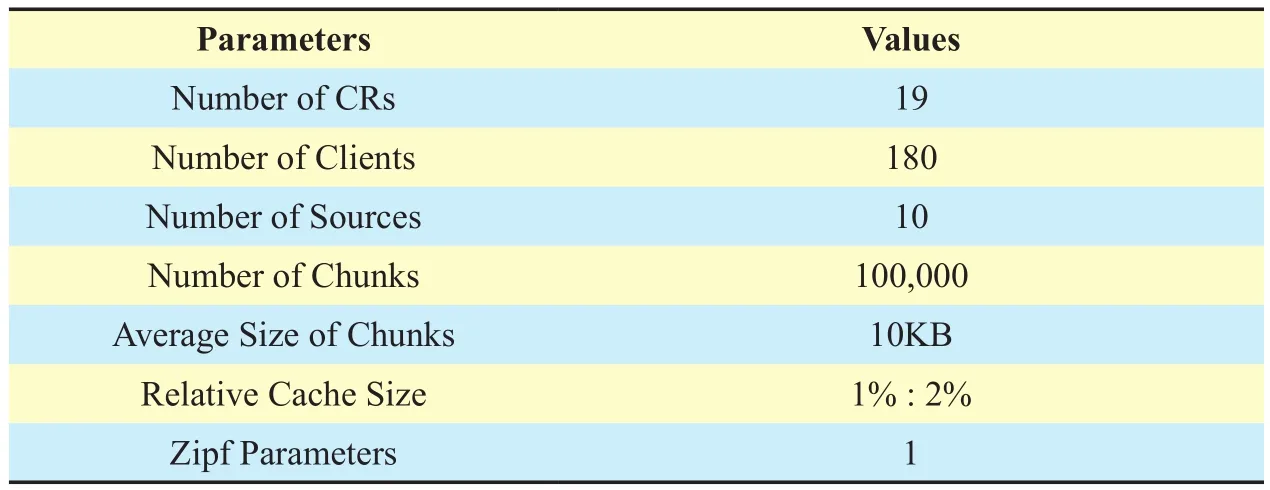
Table I Simulation parameters
In our simulations, we implement some typical non-cooperative and implicit cooperative caching schemes as follows:
■ CEE: CEE requires that Data packets should be cached at each CR that they pass through.
■ LCD: When an Interest packet arrives at the content source or CRs which already have a copy of the corresponding Data packet(the answering node is denoted by x), the Data packet is cached only at the x’s first downstream CR, while the other CRs along the path between the node N and the requester simply forward the Data packet without caching,avoiding redundant copy of this Data packet along the downloading path.
■ Prob(p): Prob(p) requires CRs to cache the Data packet with a given probability ρ(i.e., do not cache with the probability 1–ρ).After a Data packet passes a CR n times, the probability for this CR to have a corresponding copy of the Data packet is 1–(1–ρ)n. It is worth mentioning that in our simulations, the caching probability in Prob(p) is random.
■ Probcache: Probcache adds a Time Since Inception (TSI) field in the Interest packet header, and a TSI field and a Time Since Birth(TSB) field in the Data packet header. When a CR forwards an Interest packet, it increases the TSI value of the Interest packet by one.When a content source sends out a Data packet, it sets the TSB value to be zero and sets the TSI value being the one carried in the corresponding Interest packet. In contrast, when a CR forwards a Data packet, it increases the TSB value of the Data packet by one while keeping the TSI value unchanged. Probcache calculates the caching probability of each CR according to the TSI value and TSB value of Data packet.
Besides, based on DBPC we implement an additional caching scheme (denoted by DBPC*) for comparing and testifying the caching performance. In DBPC*, each CR still caches the arriving Data packet with a specific probability which is determined by the probability of this CR in DBPC. For example, we assume that the caching probability of a given CR is p in DBPC, then the probability of it in DBPC* is 1–ρ.
In simulations, we analyze the relative caching performance of different schemes with respect to two key metrics, including the cache hit ratio and average cache hit distance.In addition, we study the effect of different cache replacement algorithms on caching performance, such as the LRU replacement algorithm and the LFU replacement algorithm.
4.2 Caching performance measures
We use the following two key metrics to measure the caching performance.
Cache hit ratio: We introduce two basic concepts at first. One is “a cache hit”, which means an Interest packet is satisfied by a CR.Another one that is contrary to “a cache hit”is “a cache miss”, implying that an Interest packet is responded by a content source. Accordingly, the cache hit ratio is defined as the ratio of the number of cache hits to the sum of cache hits and cache misses.
Average hit distance: We assume there exists an Interest packet for a given content chunk, denoted as i, and we use H(i) to stand for the distance from the requester to the CR that answers the Interest packet with the corresponding Data packet. Then the average cache hit distance is defined as the average of H(i)over all Interest packets.
4.3 Cache hit ratio optimization
Fig. 6 depicts the impact of cache size on the cache hit ratio of different caching schemes.We focus primarily on the results for the LRU replacement algorithm. The results show that the hit ratio increases with the increase of cache size. This is because that a larger cache size indicates a higher chance to answer an Interest packet by a CR. More importantly,from Fig. 6(a) we observe that DBPC achieves the highest cache hit ratio among these caching schemes. For example, at cache size 1%,the cache hit ratios are 6.55%, 8.20%, 9.75%,14.48% and 18.07% for CEE, Prob(p), Probcache, LCD and DBPC, respectively., Probcache, LCD and DBPC, respectively. As the cache size increases from 1% to 2%, the cache hit ratio in DBPC is increased from 18.07%to 33.64%, while in CEE it is increased only to 17.03%. This is because the popular Data packet is inclined to be cached by CRs in DBPC, bringing about a higher cache hit ratio.Besides, the popular Data packet tends to be cached for a longer time at the heavily loaded CRs and difficult to be replaced by the unpopular Data packet. Moreover, LCD achieves the second highest cache hit ratio, since it can also cache the popular Data packets at the network edge. We also observe that the cache hit ratios for both Probcache and Prob(p) are lower because neither Probcache nor Prob(p) can make the popular Data packet that has been cached remain longer. Similarly, CEE incurs the lowest cache hit ratio due to its ubiquitous caching. We also observe that DBPC*performs poorly in the cache hit optimization.The reason behind this is that popular Data packet can hardly be cached by the “important”CRs for a long time, as discussed in Section 3.4. Therefore the simulation results show that using DBPC can improve the cache hit ratio.
Next, we investigate the impact of different replacement algorithms in more detail.The LRU replacement algorithm is a recency-based algorithm that orders cached Data packet based on recency of use only. When a replacement decision is required, LRU removes from the cache the Data packet that has not been referenced for the longest period of time. The LFU replacement algorithm is a frequency-based policy that tries to keep popular Data packets in the cache. When space is needed for a new Data packet in the cache,LFU removes the cached Data packet with the least access count. Fig. 6(b) illustrates the cache hit ratios of different caching schemes when LFU is used. We observe that DBPC also achieves the highest cache hit ratio among these caching schemes. Besides, we notice that LFU can improve the cache hit ratio and exhibit a better optimization effect on CEE when given the same simulation environment. For example, at cache size 2%, the cache hit ratio in CEE that uses the LFU replacement algorithm will increase by 25% compared with the situation using LRU, while DBPC that uses LFU can only improve the cache hit ratio by 18%. The reason is that both DBPC and LFU are inclined to cache the popular Data packets,as discussed in Section 3.4.
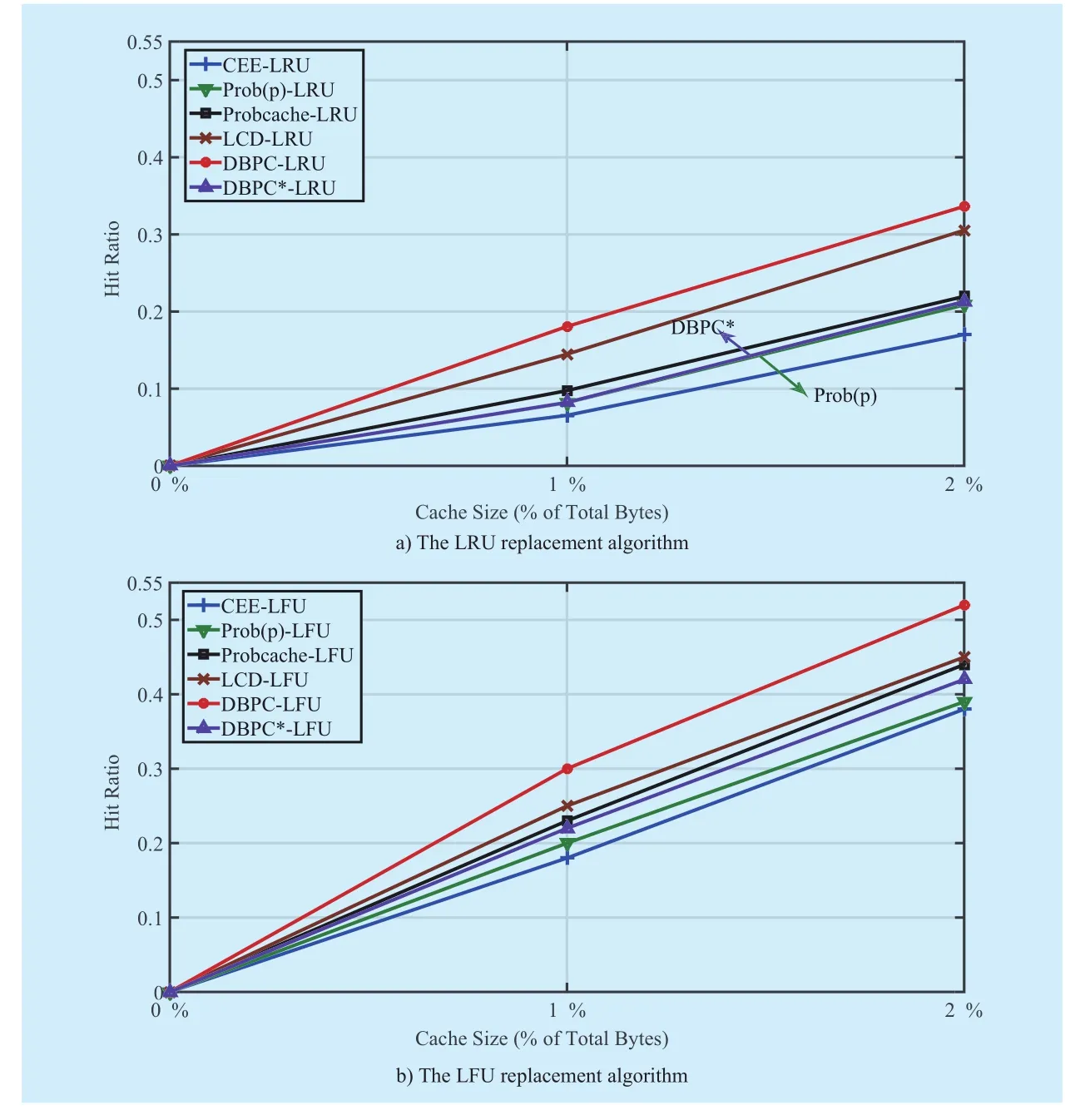
Fig. 6 The average cache hit ratio with varying cache size
4.4 Cache hit distance optimization
Fig. 7(a) presents the average cache hit distance in the caching schemes. We observe that as the cache size increases, the cache hit distance diminishes accordingly. In addition,DBPC still achieves the optimal caching performance for effectively reducing the cache hit distance. For example, at cache size 2%,the average hop counts of cache hit distance are 4.06, 4.03, 3.99, 3.86 and 3.71 for CEE,Prob(p), Probcache, LCD and DBPC, respectively. The result shows that DBPC has the minimum hop count of cache hit distance because the Interest packets for popular Data packets can be satisfied potentially by the“important” CRs. We observe that the cache hit distance in LCD is longer than that of Prob(p),but the cache hit ratio is higher. The reason is that the diffusion of popular Data packets is too slow and some of them are replaced in the diffusion process in LCD. This implies that LCD intends to increase the cache hit ratio but fails to reduce the hit distance.
Fig. 7(b) displays the average hit distance when different cache replacement algorithms are used. We can observe that the LFU replacement algorithm is more helpful in improving the caching performance than the LRU replacement algorithm is and DBPC also achieves the shortest cache hit distance among these caching schemes.
V. CONCLUSIONS
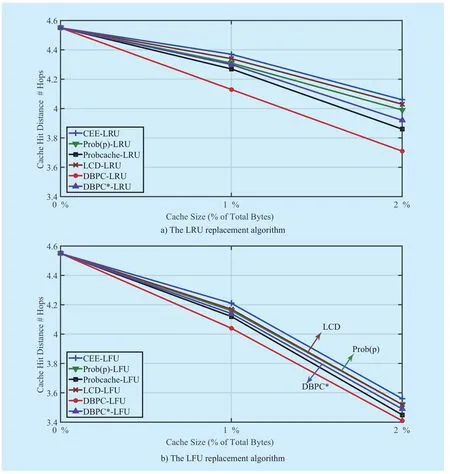
Fig. 7 The average hop count of cache hit distance with varying cache size
In this paper, we study the caching problems in CCN by the means of calculating the caching probability according to the node degree.Our simulation results prove that DBPC can improve the cache hit ratio and reduce the cache hit distance. Three benefits are reaped from DBPC: releasing cache resources from redundant copies of the same Data packets,making cache resources to be occupied by the popular Data packets and realizing zero advertisement cost for the cache cooperation.
In addition, there are still lots of researches waiting to be investigated further. On one hand, we can test and verify the caching performance of DBPC by putting it practically into large-scale topology. On the other hand,we will explore the cooperative content retrieval in caching system.
ACKNOWLEDGEMENTS
This work was supported in part by the 973 Program under Grant No. 2013CB329100,in part by NSFC under Grant No. 61422101,62171200, and 62132017, in part by the Ph.D.Programs Foundation of MOE of China under Grant No. 20130009110014, and in part by the Fundamental Research Funds for the Central Universities under Grant No. 2016JBZ002.
[1] Index C V N. Forecast and methodology, 2011-2016[J]. 2012.
[2] Index C V N. Forecast and methodology, 2013-2018[J]. 2014.
[3] J. Pan, S. Paul, R. Jain. A survey of the research on future internet architectures[J]. IEEE Communications Magazine. vol. 49, no. 7, pp. 26–36,Jul. 2011.
[4] G. Xylomenos, C. Ververidis, V. Siris, et al. A survey of information-centric networking research[J]. IEEE Communications Surveys & Tutorials, vol. 16, no. 2, pp. 1024-1049, Jul. 2013.
[5] Content Centric Networking project. [EB/OL].http://www.ccnx.org/
[6] NSF Named Data Networking project. [EB/OL].http:// www.named-data.net/
[7] G. Tyson, S. Kaune, S. Miles, et al. Taweel. A trace-driven analysis of caching in content-centric networks[C]. in Proc. of IEEE 21st International Conference on Computer Communication and Networks, Munich, Germany, 2012, pp.1-7.
[8] I. Psaras, W. K. Chai, and G. Pavlou. Probabilistic in-network caching for information-centric networks[C]. in Proc. of the 2nd ACM SIGCOMM workshop on Information-centric networking(ICN), Helsinki, Finland, 2012, pp. 55-60.
[9] S. Arianfar, P. Nikander, and J. Ott. On content-centric router design and implications[C].in Proc. of the Re-Architecting the Internet Workshop, Philadelphia, USA, 2010, p. 5.
[10] V. Jacobson, D. K. Smetters, J. D. Thornton, et al.Networking named content[C]. in Proc. of 2009 ACM CoNEXT conference. Rome, Italy, 2009, pp.1-12.
[11] G. Rossini and D. Rossi. A dive into the caching performance of content centric networking[C].in Proc. of IEEE 17th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD’12),Barcelona, Spain, 2012, pp. 105-109.
[12] S. Wang, J. Bi, and J. Wu. Collaborative caching based on hash-routing for information-centric networking[J]. ACM SIGCOMM Computer Communication Review, vol. 43, no. 4, pp. 535-536,Oct. 2013.
[13] D. Rossi and G. Rossini. On sizing ccn content stores by exploiting topological information[C].in Proc. of IEEE 31st International Conference on Computer Communications Workshops, Orlando, USA, 2012, pp. 280-285.
[14] N. Laoutaris, H. Che, and I. Stavrakakis. The lcd interconnection of lru caches and its analysis[J].Performance Evaluation, vol. 63, no. 7, pp. 609-634, 2006.
[15] J. Wang, J. Zhang, and B. Bensaou. Intra-as cooperative caching for content-centric networks[C]. in Proc. of the 3rd ACM SIGCOMM workshop on Information-centric networking(ICN), Hong Kong, China, 2013, pp. 61-66.
[16] I. Psaras, R. Clegg, R. L, et al. Modelling and evaluation of CCN-caching trees[J]. Lecture Notes in Computer Science, pp. 78-91, 2011
[17] N. Spring, R. Mahajan, D. Wetherall. Measuring ISP topologies with Rocketfuel[J]. ACM SIGCOMM Computer Communication Review. vol.32, no. 4, pp. 133–145, Oct. 2002.
[18] M. Busari and C. Williamson. Simulation evaluation of a heterogeneous web proxy caching hierarchy[C]. in Proc. of IEEE Modeling, Analysis and Simulation of Computer and Telecommunication Systems. Cincinnati, USA, 2001, pp. 379-388.

- China Communications的其它文章
- A Novel Low Density Parity Check Coded Differential Amplitude and Pulse Position Modulation Free-Space Optical System for Turbulent Channel
- Direction of Arrivals Estimation for Correlated Broadband Radio Signals by MVDR Algorithm Using Wavelet
- Signal Path Reckoning Localization Method in Multipath Environment
- Adaptive Application Offloading Decision and Transmission Scheduling for Mobile Cloud Computing
- Efficient XML Query and Update Processing Using A Novel Prime-Based Middle Fraction Labeling Scheme
- Smart Service System(SSS): A Novel Architecture Enabling Coordination of Heterogeneous Networking Technologies and Devices for Internet of Things