
Steady-State Performance Evaluation of Linux TCPs versus TCP Wave over Leaky Satellite Links
2017-05-09 03:03AhmedAbdelsalamCesareRosetiFrancescoZampognaro
China Communications 2017年3期
Ahmed Abdelsalam, Cesare Roseti, Francesco Zampognaro
Department of Electronics Engineering, University of Rome “Tor Vergata” Via del Politecnico 1, Rome, 00133, Italy
I. INTRODUCTION
With the commercial penetration of Ka-band broadband satellite systems, nowadays IP access is also possible through satellite platforms. Several commercial services are available and provide performance competing with fixed terrestrial access, as discussed in [1][2][3][4][5]. Performance of TCP-based application can be impaired because of the joint effect of large latency and possible transmission errors due to either harsh physical conditions or variable/dynamic network configurations.Satellite latency is in the order of 250 ms oneway over a GEO satellite link, so that a TCP sender actually experiences a Round-Trip Time (RTT) of around 500 ms. Such a RTT value is much higher than the ones measured on terrestrial-only paths (typically in the range 10-80 ms). As largely studied [6], high RTT impairs the performance of the ACK-clocked TCP congestion control, slowing the achievement of the steady-state. On the other hand, as for every wireless link, satellite links can be affected by transmission errors that result in a TCP-level Packet Error Rate (PER) higher than zero. Traditional TCP versions, i.e. Tahoe,Reno, NewReno [7], interpret losses as a sig-nal of congestion, decreasing the transmission rate. Therefore, if one of the network segments is a leaky broadband satellite link, sub-optimal TCP performance can be expected. As a general reference, the estimated theoretical TCP throughput limit as a function of overall RTT and PER can be obtained through Mathis’ formula [8]:
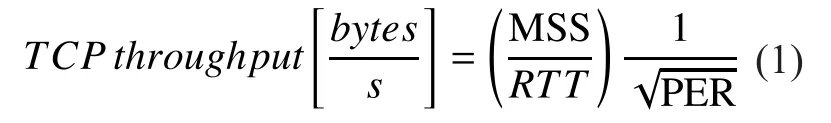
where MSS (bytes) stands for Maximum Segment Size and represents the maximum TCP segment size. The inverse proportionality relationship between TCP throughput and both RTT and PER values provides a straightforward benchmarking indicator for the addressed issue.
Usually, satellite service providers overcame the above limitation by introducing the Performance Enhancing Proxy (PEP) network element [9] at the edges of the satellite links.PEPs optimize TCP performance at the cost of violating the end-to-end principle. Brie fly,PEPs either alter or even terminate TCP endto-end connections and implements optimized protocols/methods for an efficient data transport over satellite. TCP-PEP solutions are useful for the performance optimization but they may introduce some drawbacks in terms of security, flexibility, scalability, and reliability. In addition, the need for TCP-PEP makes the integration of satellite systems in heterogeneous network much harder. Most of TCP-PEP proposals are designed with several scenario-specific drivers, limiting their adoption between PEPs and/or over specific link con figurations and not compatible with possible network changes. For instance, the solution presented in [10] requires SDN-based nodes and only addresses the problem of the TCP initial cwnd setting. PEPSal, described in [11], inherits the disadvantages to use a fixed stateful proxy agent at the edges of the satellite link. Finally,[12] proposes to transfer flow and rate control functions to an UDP-based application protocol, so intermediate agents are needed when the standard end-systems uses TCP. Definitively, these examples of PEP-based solutions are tailored for a target scenario, whereas they are not applicable as alternative end-to-end protocols. This limitation is in conflict with the recent network views such as 5G, where the satellite network can be transparently and dynamically present as complementary and/or of floading link, and more in general, the endto-end path can vary over time [13].
For all these reasons, the optimization of TCP performance without PEPs is of paramount importance in the modern integrated networks.
In the recent years, Linux has proved itself as a very popular, stable, and reliable operating system. A big effort from the Linux development community has been focused on the enhancement of network stack, with a particular attention to the TCP performance. Accordingly, several non-standard TCP congestion control algorithms and experimental RFCs beyond the traditional TCP specifications have been included with the specific goal to improve the connection throughput and to reduce the effect of segment loss events. The recent version of Linux kernel (4.4 [14]) includes the following TCP congestion control algorithms,manually selectable by the user: TCP Reno[1], TCP Bic, TCP Cubic [15], TCP DCTCP[16], TCP Westwood+ [17], TCP Highspeed[18], TCP Hybla [19], TCP HTCP [20], TCP Vegas [21], TCP Veno [22], TCP Scalable[23], TCP LP [24], TCP Yeah [25], and TCP Illinois [26].
A first objective of this paper is to evaluate performance of a selected sub-set of end-toend Linux TCP schemes over a communication scenario where satellite can be a possible option for backhauling data from user access network to the core network. In fact, we believe that most of the common negative assumptions about end-to-end TCP performance over satellite are not more applicable when using the current TCP implementations, because of the drastic differences from the standard TCP algorithms [27]. Therefore, the TCP model considered by the Mathis formula might be completely outdated and not useful to provide a state of the art view about the realistic TCP performance. The reference scenario is presented in Figure 1. It consists of an application client connected to a LAN, powered with a twofold satellite-terrestrial wireless external interfaces. Selection of the most suitable interface is out of the scope of this paper, but it is herein important to remark that application client can download a file from a remote server located on the public Internet transparently exploiting one of the available backhaul links.
Once the network link is selected, this basic scenario allows to perform the target TCP protocol’s evaluation as a function of two varying inputs: TCP end-system configuration and overall PER. Therefore, a fully configurable TCP/IP stack in Linux is envisaged on the end-systems and PER over satellite/terrestrial backhauling link is arbitrarily varied for testing purposes.
In addition, we want to add to the evaluation a novel transport protocol approach,namely TCP Wave, (not implemented in the existing versions of Linux OS), which represents a cutting-edge alternative to the traditional window-based congestion control followed by other TCP implementations available in the Linux OS. TCP Wave design principles[28][29][30] have been tailored to assure an optimal performance under time-varying network topologies and physical conditions,adaptation to wide bandwidth and/or delay changes, acceleration of small transfers, quick achievement of high throughput and an efficient handling of transmission errors. Finally,its design allows the interworking with ACKs generated by the standard TCP receivers to guarantee a full protocol interoperability in the current and future communication scenarios.For all these reasons, we considered its promising application in the target scenario.
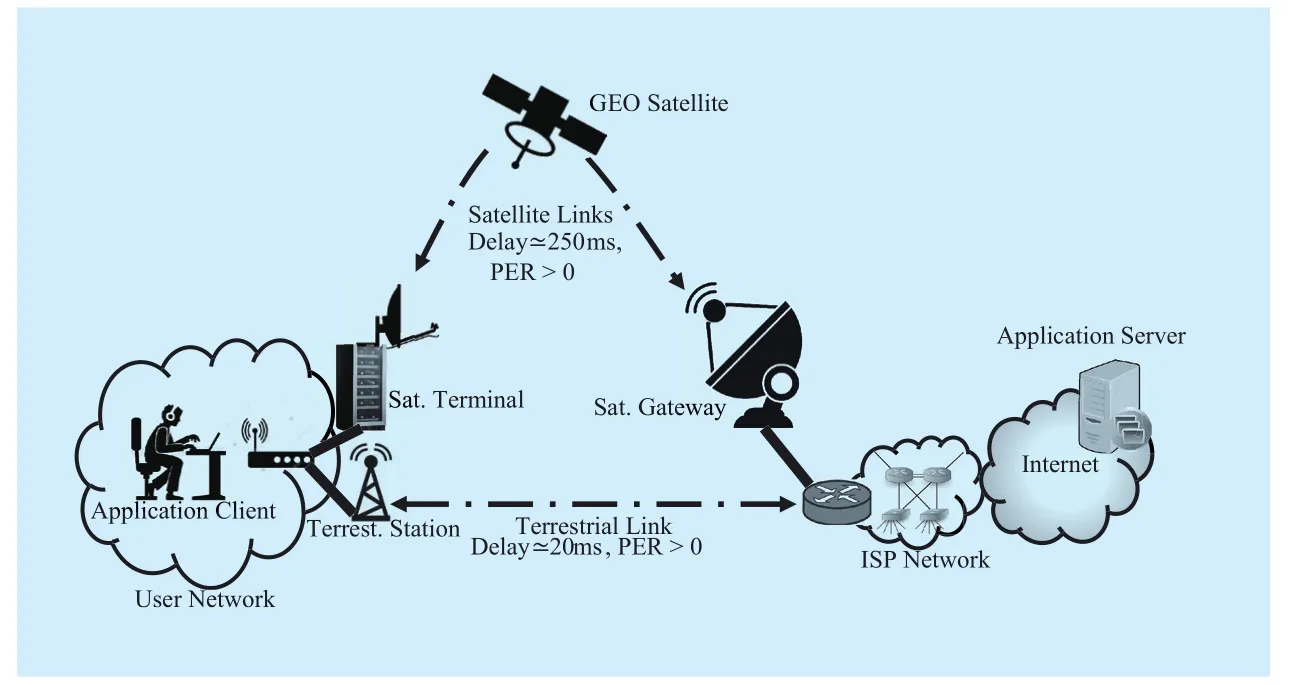
Fig. 1 Reference scenario for testing
II. LOSS RECOVERY IN LINUX TCP
Due to the high number of supported congestion control algorithms in Linux, we decided to evaluate the following representative subset with the aim to address the most peculiar loss recovery strategies:
• TCP Reno (historically, the default congestion control and often referred as standard TCP);
• TCP Cubic (default TCP version in modern Linux systems);
• TCP Hybla (designed for large latency environments);
• TCP Vegas (designed to discriminate congestion losses from transmission losses);
• TCP Westwood (designed to cope with leaky channels)
TCP Reno [1] sender detects segment losses by the reception of duplicated acknowledgments (dupACKs) that are generated by the TCP receiver when receiving out-of-order segments. Upon receiving three dupACKs,the sender retransmits the lost segment (fastretransmit algorithm) and halves its transmission parameters (fast-recovery algorithm),namely the slow-start threshold (ssthresh) and the congestion window (cwnd). As a consequence, the overall transmission rate is halved,in line with the design assumption that losses are signals of congestion. In case of multiple losses, it might not be possible to generate enough dupACKs to trigger consecutive fast retransmit/fast recovery cycles. In this case,TCP Reno most likely encounters a Retransmission Timeout (RTO), which sets ssthresh to half of current bytes in flight and resets cwnd to a single segment.
TCP Cubic strategy leverages on a binary search algorithm, which implements a cwnd variation as a function of time since the last loss event and taking the cwnd value prior to the loss as the convergence point. Therefore,cwnd value grows at the optimal transmission rate depending on the distance/ frequency of the loss events and not on the experienced RTT value. More details can be found on [15].
TCP Hybla [19] is actually an extension of TCP Reno, where the cwnd increase method is modified to help connections running over high-latency link, taking as a reference a RTT0value of 25 ms. TCP connections experiencing higher RTT, accelerate the cwnd growth of a factor RTT/RTT0.
TCP Vegas [21] aims to actively sense the network congestion status through monitoring of RTT. Accordingly, the reaction to losses detected through dupACKs depends on the current RTT estimation, avoiding the excessive deduction of cwnd in case of spurious losses that are not caused by a congestion status.
Last, TCP Westwood [17] performs an estimation of the end-to-end bandwidth by monitoring the ACKs reception rate. Upon a loss event, the sender uses the estimated bandwidth as a reference to properly reset both cwnd and ssthresh, rather than blindly halving these values as in TCP Reno.
Simultaneously, Linux implements and enables by default many options to be used in combination with all the above-mentioned congestion control schemes, to better manage loss recovery [31].
The first key option is the Selective ACK(SACK)[32]. SACK improves the traditional cumulative ACK mechanism, because SACK segments explicitly report the list of the successfully received out of order segments in case of multiple losses. This allows TCP sender to detect and retransmit multiple lost segments at once within a single RTT. In combination with SACK, Linux also supports the Duplicate-SACK (DSACK)[33] option,to allow the receiver to report any duplicate segments received, i.e., due to unnecessary retransmission of delayed or out-of-order segment(s). As a further enhancement, Linux also implements the Forward-ACK (FACK)algorithm. FACK basically performs more accurate estimation of the outstanding segments during the recovery phase in order to avoid the generation of large bursts upon the reception of dupACKs. Details on FACK can be found in [34]. Then, Linux has a detection mechanism to mitigate the spurious Retransmissions Time Outs (RTO) called Forward RTO-Recovery algorithm (F-RTO) [35], which envisages the monitoring of the ACK flow during RTO recovery. If the sender receives only a cumulative ACK for all segments sent before the timeout event, it considers such a timeout unnecessary and immediately restores the normal transmission parameters. Proportional Rate Reduction for TCP (PRR, RFC 6937[36]) is another option aimed to make TCP loss recovery phase more efficient. PRR rules the number of segments to be sent per ACK during recovery trying to keep cwnd value close to the ssthresh by the end of the recovery phase. The RTT measurements involved in the loss detection mechanisms (RFC 6298[37]) are enhanced in Linux by enabling TCP timestamps to be attached to every segment.Finally, the initial congestion window (ICW)is increased to 10 segments by default in order to accelerate the initial slow-start phase, in case of large bandwidth-delay products.
As a common consideration for all the above loss recovery algorithms and options,we remark a cross-interaction between the loss management and rate control. In fact, cwnd is usually reduced in a loss recovery phase leading to a corresponding rate reduction. Without going in details on specific loss recovery dynamics of each selected TCP variant, we are interested to assess the efficiency of such a cwnd-based management versus the newly burst-based approach implemented by the TCP Wave, described in the next section.
III. LOSS RECOVERY IN TCP WAVE
TCP Wave’s loss recovery algorithm is initiated, as for all other TCPs (referenced hereafter as “standard TCP”), by either the absence of ACKs or the reception of dupACKs, which are generated by the standard TCP receivers in case of out-of-sequence segments. As for standard TCP, TCP Wave sender performs segment retransmission when it receives three dupACKs referred to the same segment but,in contrast to the standard TCP, TCP Wave sender manages a Fast Retransmission (FR)process in parallel to the regular transmission(i.e., not reducing the cwnd). At the start-up,TCP Wave sends bursts of segments (while available from the application) in a pre-deifned configuration: initial burst size BURST0and initial spacing TxTime0. As soon as ACKs are received, TCP Wave sender measures both ACK dispersion and RTT, and uses such values as inputs to properly update its upcoming TxTime. As detailed in [28], the computed TxTime value aims to achieve a transmission rate equal to the available bottleneck capacity.These adjustments are performed continuously on a ACK train basis, following a proactive approach.
The control of transmission rate relies on two algorithms: Tracking Mode and Adjustment Mode. The algorithm selection depends on the comparison between the averaged value of the current RTT and a predefined protocol threshold, namely β, which represents the maximum buffering time tolerated on the end-to-end path. The higher is β, the larger is the required buffer size on the bottleneck link.Details on such algorithms and on the default parameter settings are presented in [28][29],where these parameters are carefully explained also considering the friendliness with the standard TCP.
TCP Wave handles retransmissions as a process that is completely uncorrelated from the rate control, in order to maintain the overall efficient burst transmission structure. Differently from standard cwnd-based approach,TCP Wave proactively adjusts the rate in order to prevent congestion, so that losses are no more considered as congestion signals. Then,Fast Retransmission (FR) and Retransmission Time Out (RTO) algorithms have been properly reviewed to recover from losses without significant interactions with the rate control algorithms.
In particular, FR allows the sender to retransmit the lost segment(s) in parallel to the regular burst transmission, upon reception of 3 dupACKs. In order to keep the overall transmission rate unchanged, BURST size of the next scheduled burst is reduced of the number of retransmitted segment(s). The proactive and continuous burst transmission, also during FR, always allows the generation of enough dupACKs to address the recovery of multiple losses. Such an assumption is not true in the traditional TCP approach, where the transmission of “fresh” segments that allows the generation of further dupACKs, is always constrained by the current cwnd value.
In case the retransmitted segment is lost again, the sender will continue to receive dupACKs referred to the same segment. Therefore, FR is not able to detect the second loss of the same segment and retransmission timer will inevitably expire, as for standard TCP,triggering the RTO algorithm. Mostly, TCP Wave triggers RTO under two specific circumstances: a segment is lost twice or ACK flow is interrupted. In both cases, TCP Wave assumes a serious problem in the network, either severe congestion or even a temporary disconnection,adopting a quite conservative RTO recovery strategy: the sender resets the BURST size and the TxTime to the initial values BURST0and TxTime0respectively, assuming that network conditions are not well known yet. Then, retransmission restarts in bursts from the latest acknowledged segment before the RTO expiration with the aim of carefully discovering new network conditions. RTO recovery ends when all the transmitted segments before RTO expiration are acknowledged. In the meanwhile, FR is disabled so that further losses during RTO recovery will cause consecutive timeouts.
IV. SIMULATIONS
The error recovery model of TCP Wave, compared with different Linux TCP implementations, is validated and analysed using the ns-3 network simulator (ver. 3.23) [38] in two different scenarios: one with a large latency(including a satellite link) and one with low latency (compliant to typical terrestrial links).The Direct Code Execution (DCE) module[39] is used to support the execution of the kernel-space network protocols within ns-3,allowing to con figure the TCP variants available in the Linux kernel. In particular, we used the latest stable version of Linux kernel (ver.4.4, released 10thJanuary 2016 [14]). All TCP Linux options described in the Section 2 are enabled. TCP Wave was coded directly leveraging on ns-3 networking models as reported in [29].
The basic simulation topology shown in Figure 2 consists of two intermediate routers(R1 and R2) connected by a bottleneck link.
The sender node is connected to R2 through a high-speed link simulating optical carriers in compliancy with OC-768 standard [40],then allowing up to about 40 Gbit/s. This configuration models the ISP network, where a Web server acts as a TCP sender in the target scenario. On the other bottleneck link side, a receiver node (i.e. Web browser) is connected to a high-speed access network having R1 as a default gateway. Without loss of generality,the capacity is set to 2.4 Gbit/s that is nominal throughput in case of 802.11ac ultra-highend product [41]. As far as the R1-R2 link con figuration is concerned, we have addressed two main test cases: Ka-band satellite link and terrestrial wireless link, respectively. As a baseline configuration for both options, we assume a bandwidth value of 4 Mbit/s as a slice of the overall physical bandwidth, dedicated to a specific connectivity service [1][2].Of course, higher bandwidth values in fluence TCP start-up performance then affecting the overall average throughput. In addition, the higher BDP leads to work with larger cwnd,which in turn is involved in the loss recovery mechanisms. For these reasons, we consider an additional satellite con figuration where all the available bandwidth is intended for the target service. As a reference, the KA-SAT heaviest bandwidth use pro file envisages that a single terminal can deliver speeds up to 50 Mbit/s downstream and 20 Mbit/s upstream[42]. Then, such values are used in the second satellite test case.
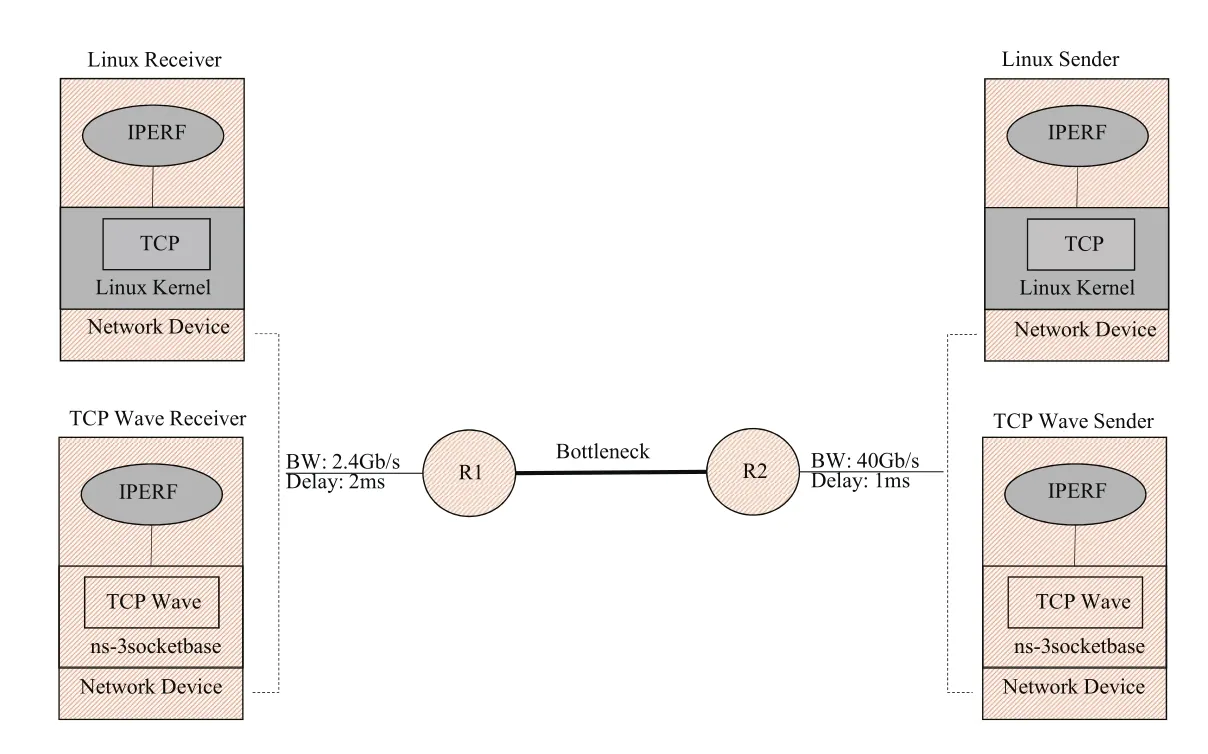
Fig. 2 Simulation setup (Grey: Linux components)
A Droptail queue scheme is attached on the bottleneck channel, equal to double the Bandwidth Delay Product (BDP) of the bottleneck link, accordingly to the different simulation configurations. The traffic is generated and terminated using a real IPERF application [43]through DCE, to execute real stacks/applications over the simulated networks. The server node sends IPERF traffic over TCP to the user node with connection parameters tailored to achieve the maximum bottleneck capacity. For example, the default values for TCP send and receive buffer in Linux OS (wmem_max and rmem_max) =160 Kbytes, would limit the TCP throughput on the con figured channel to only 2.6 Mbit/s. Hence, we changed the maximum buffer size to 4.0 Mbytes, that allows the TCP sender to achieve the maximum bottleneck capacity in the target simulation scenarios. Table 1 summarizes the most significant simulation parameters.
For an exhaustive analysis of correlation between link errors and TCP performance, the bottleneck link is configured with randomly generated losses that produce an overall packet error rate (PER) ranging from 10-6up to 5·10-2. We run tests for both the Linux TCP variants and TCP Wave over the PER range,with a transfer duration of 600 s and with each run repeated 10 times to cover the effect of loss events timing on TCP throughput. To obtain randomness across multiple simulation runs, the Linear Random Number Generator(LRNG) is initialized using varying “seed values”. Finally, the simulation output evaluates two different performance parameters:
- TCP average goodput, meant as the throughput at the net of retransmissions(obtained from IPERF receiver statistics).It indicates the effective reception rate of“fresh” segments and provides TCP protocol capability to exploit available capacity;
- Average RTT over the connection, which indicates the level of congestion introduced in the bottleneck link to achieve the measured goodput.
Therefore, performance assessment needs a joint evaluation of the above parameter, since the best case is represented by a full utilization of the channel keeping RTT close to its minimum value (no buffering/congestion at the bottleneck).

Table I Simulation parameters
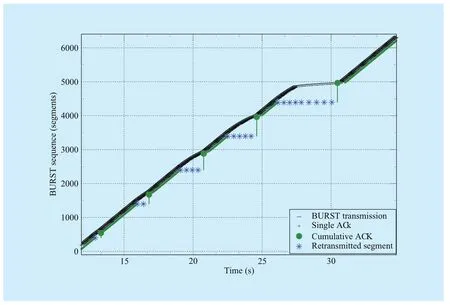
Fig. 3 TCP wave FR recovery mechanism
4.1 Analysis of the TCP wave loss response
Initial simulations were run to characterize TCP Wave overall response to losses, before addressing the performance evaluation. For convenience, we considered the simulation setup with large latency in order to highlight loss recovery timing. Figure 3 shows the FR strategy in TCP Wave to recover from multiple losses. In particular, we forced an increasing number of consecutive losses (1 – 2 – 4 – 5– 10 segments) at different times in the bottleneck link.
First, we remark that for each segment loss,TCP Wave sender performs the fast retransmission immediately upon the reception of the third dupACK. In addition, each retransmission needs 1 RTT to be concluded, so that N consecutive losses require an overall recovery time of NRTTs. Up to 5 consecutive losses,transmission rate remains almost unchanged as shown by the slope of the transmitted segments in Figure 3, demonstrating the decoupling between transmission rate and error control. The very slight variations are due to effect of the higher RTT samples carried by the retransmitted segments that triggers sporadic Adjustment Mode cycles (average RTT> β). In fact, retransmitted segments have an RTT in flated by a multiplicative factor G, with G representing the position of the retransmitted segment within the set of consecutive losses. This dynamic is emphasized in the case of 10 consecutive losses, where the Adjustment Mode is triggered for several seconds implying a visible rate reduction.
To allow this FR recovery behaviour without incurring an unnecessary RTO expirations,the measured RTT values are considered in computation of the RTO timer. This ensures that the computed RTO value is always consistent with the actual RTT. Thus, TCP Wave does not incur in any RTO expiration unnecessarily. The end of the FR recovery phase is always characterized by a cumulative ACK that acknowledges all segments received during the recovery phase.
However, permanent congestion or network disconnections can still lead to RTO expiration. Figure 4 shows a practical example of TCP Wave RTO recovery in case of link disconnection lasting for 2 s (from 30 s to 32 s of the simulation time). In absence of ACKs at 30 s, TCP Wave sender continues its proactive burst transmission. This behaviour continues until RTO expires after about 1 s (second 31)from the interruption of ACK flow. Then, TCP Wave sender starts the retransmissions from the first unacknowledged segment, using the initial transmission parameters: BURST0and TxTime0.
Although the first two bursts are retransmitted when the link is still interrupted, the third burst is successfully received, which triggers a cumulative ACK acknowledging a given number of segment that were received but not acknowledged before RTO expiration.
This cumulative ACK is used to update TCP Wave sender statistics, allowing to trigger Tracking Mode algorithm and speed up the retransmissions according to the channel capacity. The RTO recovery continues until the sender receives a new ACK that is higher than the last transmitted segment before the RTO expiration (at 33.75 s).
4.2 Steady-state test on a leaky satellite link
In this test, we first consider a satellite link with a dedicated connectivity service, that is assigned to a single commercial user terminal.Thus, the R1-R2 bottleneck link is con figured with a bandwidth of 4 Mbit/s and an overall delay of 250 ms. This testing scenario is very challenging for TCP, since optimal BDP is large enough to experience multiple losses within a single cwnd. Additionally, possible RTO expirations due to multiple losses lead to the retransmission of a high number of segments. As a consequence, the TCP connection spends a long time for recovery, which greatly affects the overall throughput.
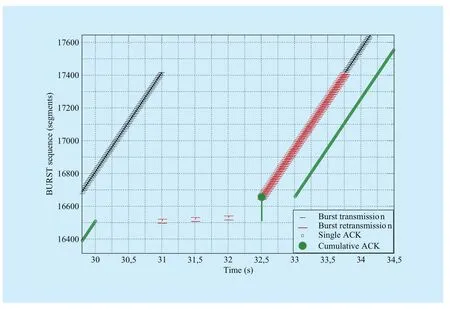
Fig. 4 TCP wave RTO recovery mechanism
As a general reference, the estimated theoretical throughput limit as function of the PER is provided through the Mathis formula[8] upper bounded by the net capacity of the bottleneck link (evaluated considering lower layer overhead represented by the ratio MSS/MTU) as in Eq. 2.
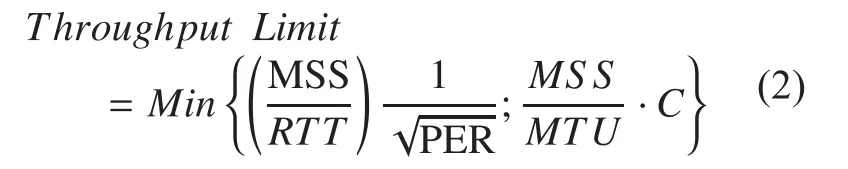
This limit is referred to a standard TCP implementation (AIMD based) without any Linux enhancement enabled. In this test case,for PER2·10-5the maximum goodput is constrained by the channel capacity, then a steep decay appears for higher PER values.Simulation results are summarized in Figure 5 and Figure 6, where average goodput and RTT are shown respectively. The theoretical expected performance from Eq. 2 is drawn in Figure 5 with a dashed line: we assume an ideal theoretical trend where only physical delay contributes to the RTT. In Figure 6 instead the dashed line represents the physical delay. TCP Reno (see cross marks), which implements a standard congestion control, shows a goodput similar to the theoretical trend. For PER2·10-5, results show a performance gain that is due to the effect of the enabled TCP enhancement options implemented in the Linux, and in particular of SACK option, which allow a better efficiency in recovering multiple losses.The maximum goodput gain for TCP Reno is observed in the rangewhere we measured an increase of about 500 kbit/s with regard to the theoretical line.
TCP Reno pays the almost optimal goodput with a significant RTT increase, up to three times its minimum value (see Figure 6).This is an intrinsic effect of the standard TCP congestion control scheme that envisages a continuous TCP growth until a loss event occurs (over flow). Of course, higher PER values lead to a more frequent cwnd decrease upon each loss recovery phase, reducing also the measured RTT, which converges to a value of about 680 ms.
TCP Vegas (see dash marks) performs a bit slower than TCP Reno in term of goodput, but still better than theoretical curve for higher PER values. On the other hand, TCP Vegas congestion control algorithms based on RTT measurements allows to keep RTT controlled to about 680 ms, then limiting the generated congestion on the bottleneck link. Thus, TCP Vegas brings a better trade-off between goodput and RTT with respect to TCP Reno.
TCP Westwood (circle marks) leverages on the estimated bandwidth to reset cwnd after each loss recovery. This behaviour appears too conservative for the lower PER values where the goodput results are the worst with respect all the other TCP versions. In fact, with PER2·10-4goodput is below 3.5 Mbit/s and far enough from the theoretical maximum one. To opposite, as the PER increases, the goodput decay is slower than both TCP Reno and TCP Vegas, then achieving a gain up to 1.3 Mbit/s around PER = 10-3. In addition, TCP Westwood, presents an RTT lower than TCP Reno,although applying the same Additive Increase Multiplicative Decrease (AIMD) congestion control strategy, resulting less aggressive in terms of buffer occupancy.
TCP Cubic improves on previous examined protocols by achieving a quite constant goodput up to a PER = 3·10-4. Here, the performance drawback is the very high RTT, which indicates that TCP Cubic works at the steady state keeping the bottleneck buffer full and potentially unfriendly to other protocols in these circumstances. With PER > 3·10-4, it starts its decay but with an overall trend better than the previous TCP protocols.
The last of Linux TCPs considered, TCP Hybla, “amplifies” the behaviour observed with TCP Cubic in both pros and cons. Basically, it is able to maintain an acceptable goodput of about 3.5 Mbit/s up to PER = 3·10-3. In parallel, the measured RTT is very high (even higher then TCP Cubic) revealing a very aggressive behaviour in terms of congestion. The reason relies on the Hybla acceleration of the cwnd growth, taking 25 ms as a reference for RTT0[19]14]. Therefore, since physical RTT is about 500 ms, the acceleration factor is equal to 20.
Last but not least, TCP Wave with its burstbased transmission and tailored loss recovery mechanisms is almost resilient to errors up to PER = 10-3, achieving the optimum transmission rate. Simultaneously, TCP Wave rate control allows to keep RTT very close to the minimum value (physical RTT). This means that actual transmission rate at the sender side exactly matches the available bandwidth at the bottleneck link, during the whole connection lifetime. For higher PER, also TCP Wave experiences a reduced goodput, because the higher number of losses implies some RTO events, which differently from normal loss recovery based on dupACKs/SACK, lead to a full transmission reset. TCP Wave greatly outperforms the other TCP versions, with the exception of TCP Hybla, in terms of goodput.Nonetheless, such a performance reduction against Hybla is compensated by an optimum RTT value, always close to the physical one.As an example, with PER = 10-2, which represents the working point of maximum gap between TCP Wave and TCP Hybla, the latter achieves a goodput of about 1.3 Mbit/s higher,but at the same time it introduces an extra delay contribution of 400 ms.
For additional analysis, the satellite-related test has been extended by increasing the bottleneck capacity between R1 and R2 in order to reproduce a satellite channel that is exclusively dedicated to the target service.In this case, TCP sender can exploit up to 50 Mbit/s to send segments over the forward link,while a capacity 20 Mbit/s is available to support ACK flow over the satellite return link.From TCP point of view, this is an extremely challenging scenario because of the very large BDP (> 3 Mbytes). Accordingly, cwnd higher than 2080 segments must be achieved to match the maximum allowed throughput.
In this test case, the theoretical throughput estimated by Mathis formula is constrained by PER and RTT only. In fact, for the lowest envisaged PER value (10-6), the maximum expected throughput is around 23 Mbit/s out of the 50 Mbit/s available bandwidth. With such a theoretical reference, Figure 7 summarizes simulation results achieved by the selected TCP versions.
TCP Reno, TCP Vegas and TCP Westwood present trends similar enough, relatively close to the theoretical line for all PER values. In more details, goodput is slightly below the theoretical limit for the lower PER values(< 3-4·10-6) and then it overcome the limit as the PER increases.
Both TCP Cubic and TCP Hybla outperform the previous TCP versions as well as Mathis’s limit for all the PER values. In particular, TCP Cubic achieves better performance for lower PER (up to 28 Mbit/s), while TCP Hybla is more resilient to the highest PER values (>10-4).
Finally, TCP Wave shows a great capability to achieve a data rate close to the available bandwidth when PER is limited. As an upper bound, a goodput of about 48 Mbit/s is measured when PER=10-6. Then, TCP Wave goodput decreases for the higher PER values,but still it presents a great improvement with respect to the other TCP versions while PER< 10-5. For higher PER values, TCP Wave curve is in between those of TCP Cubic and TCP Hybla. Differently, to all the cwnd-based protocols, TCP Wave works with a large number of segments in flight, proportionally to the available bandwidth and independently from the PER, because of its proactive burst transmissions. This implies that the number of inflight packets lost is higher than in the other TCP versions, which usually reduce cwnd at the steady-state proportionally to the PER value. Such a dynamic is the main cause of the sudden goodput decay affecting TCP Wave for the higher PER values.
4.3 Steady-state test on a leaky terrestrial link
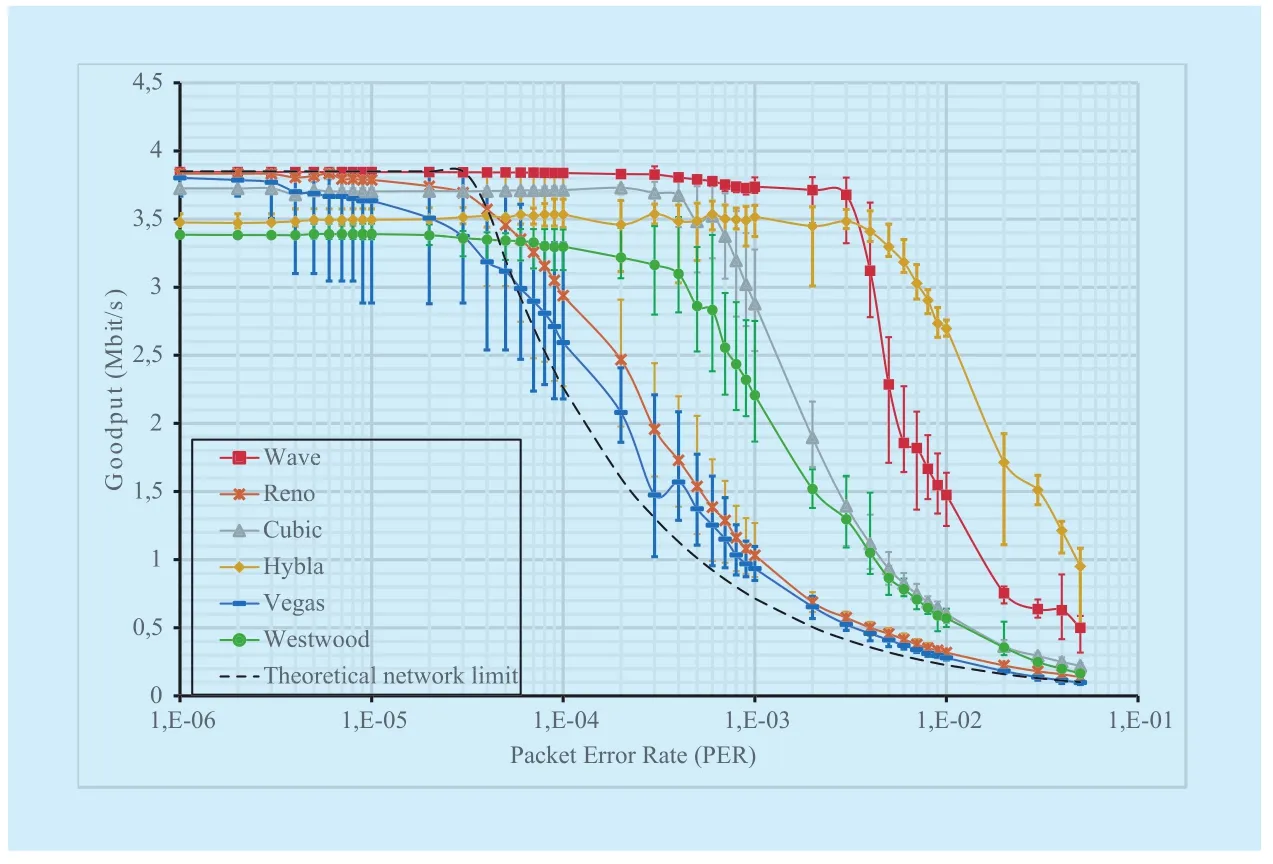
Fig. 5 Goodput vs PER (Bottleneck Bandwidth C= 4Mbps, RTT = 500ms)
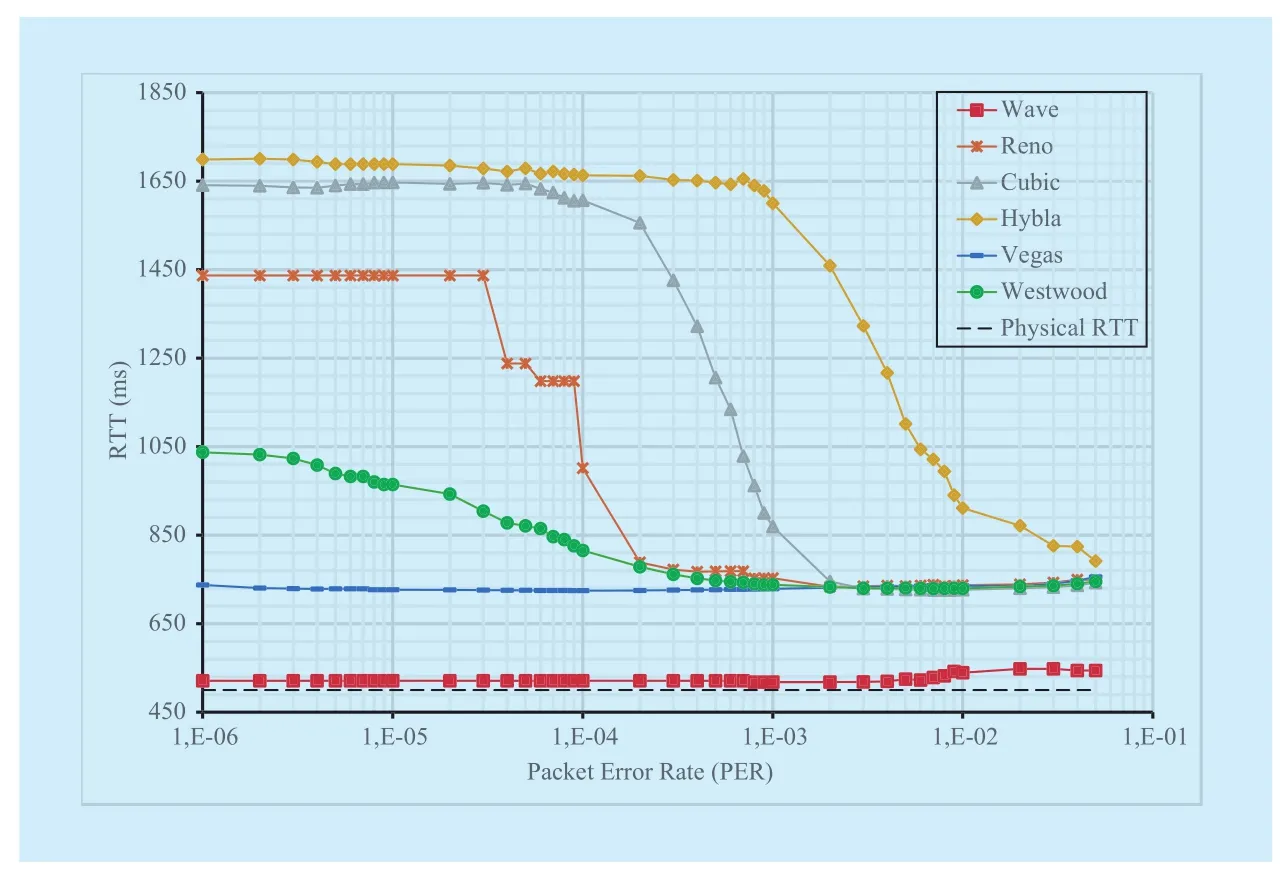
Fig. 6 RTT vs PER (Bottleneck BW= 4Mbps, RTT = 500ms)
Since TCP runs at end-devices, and since in accordance to the considered scenario the endto-end path can change depending on the user terminal Point-of-Attachment (PoA) to the edge network, it is of paramount importance that TCP responses validated on satellite links are confirmed also over typical terrestrial links. TCP Wave has been designed to operate on common Internet scenarios as well as all the other TCP versions (installed on Linux OS). Therefore, we decided to analyse the effect of PER on TCP performance over terrestrial networks. In the simulation setup described above, we changed the physical RTT for the bottleneck between R1 and R2 from 500 ms (typical of GEO satellite links) to 40 ms, which is a good average value for the current broadband terrestrial networks, without changing the con figurations of tested protocols. The corresponding results are shown in Figure 8 and Figure 9. The lower latency improves goodput of all the tested protocols.With the exception of TCP Vegas, all the TCP variants match the maximum goodput up to a PER = 2·10-3. For higher PER values, goodput decay starts with TCP Wave outperforming all the other TCPs. Nevertheless, the most important achievement consists on the RTT trends, which confirms again how TCP Wave is able to maximize goodput while keeping bottleneck buffer empty. On the other hand,other TCP versions, based on cwnd-based congestion control, probe available bandwidth by creating congestion in order to achieve a suitable set of cwnd.
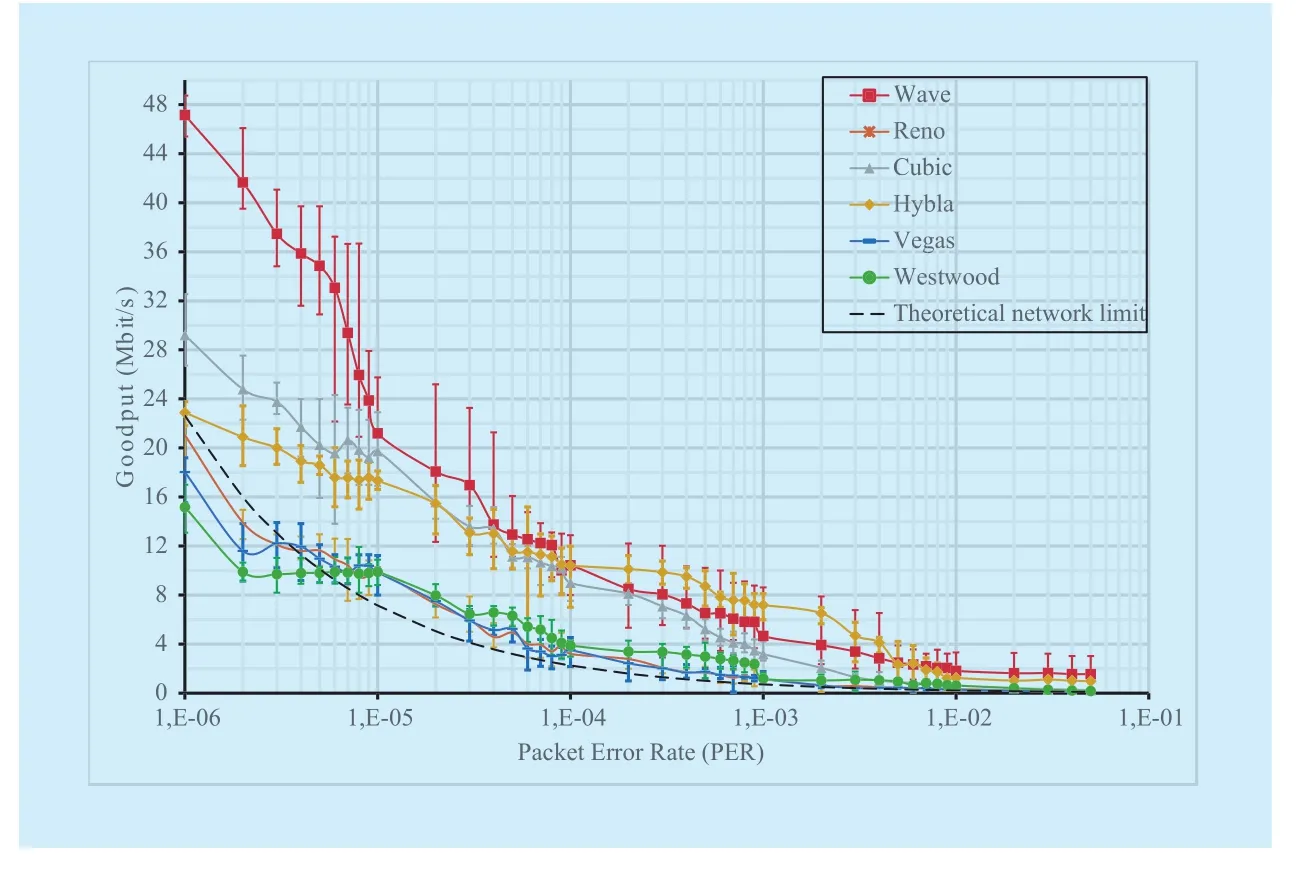
Fig. 7 Goodput vs PER (Bottleneck BW= 50Mbps / 20Mbps, RTT = 500ms)
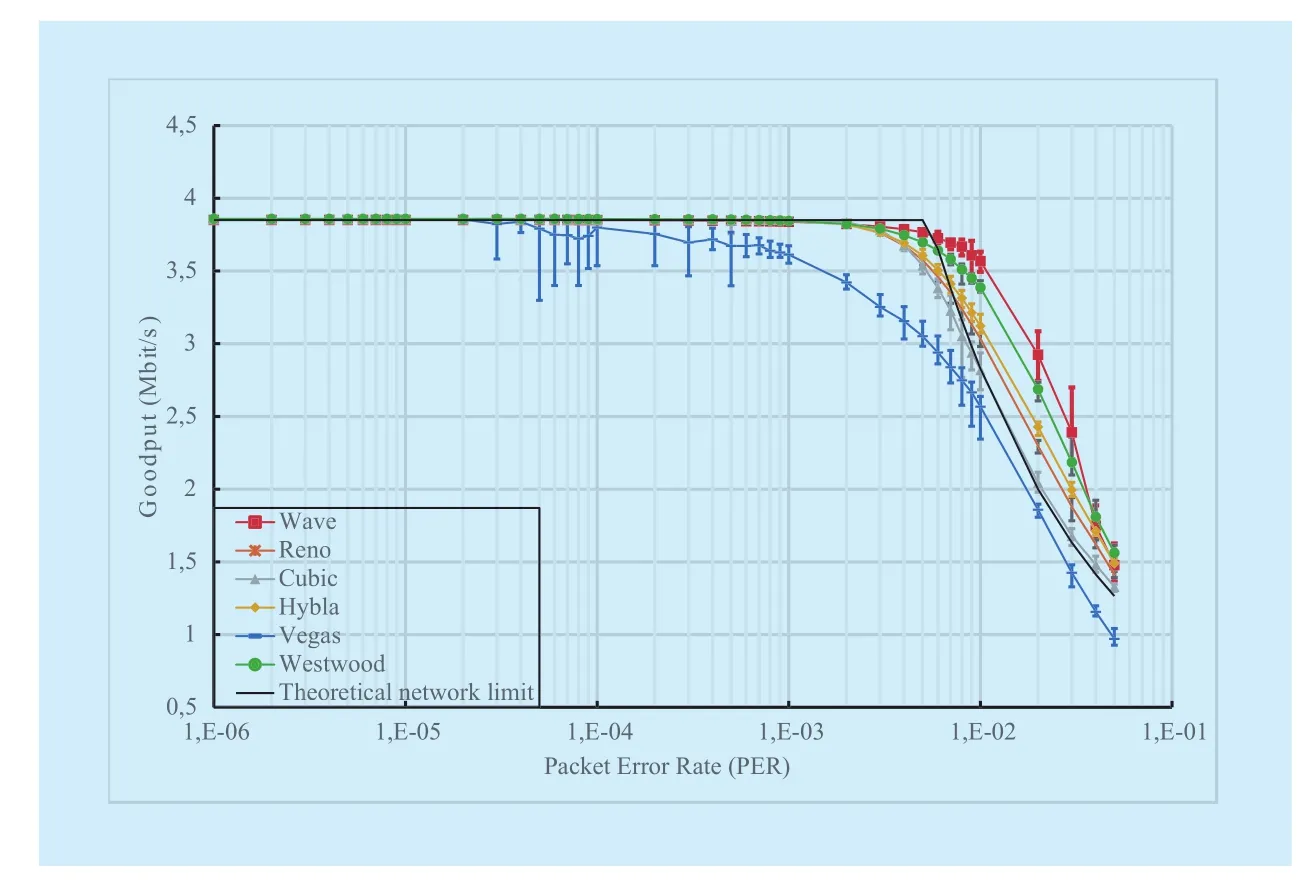
Fig. 8 Goodput vs PER (Bottleneck Bandwidth C = 4Mbps, RTT = 40ms)
V. CONCLUSION
Test results allowed to gather a set of useful hints and considerations about possible TCP amendments or configuration aimed at new scenarios characterized by possible large delays and losses without the use of PEPs.First, we confirmed that simple theoretical TCP models are not applicable to real systems because of the plenty of TCP variants,enhancements and options, which lead to actual protocols behaviour quite different from the expected one. Specifically, real TCP implementations on Linux O.S. outperform throughput achieved through the Mathis formula, which can be considered a lower bound in almost all the cases. As a general result, all the considered Linux TCPs provide, in terms of goodput, performance acceptable also in the target scenarios over a large set of PER values,but as a main drawback, they present an aggressive pushing of segments in the bottleneck buffer. This behaviour can cause congestion on the network impairing the network efficiency and friendliness in presence of competing real-time flows. In addition, cwnd-based TCPs present a limitation in achieving a goodput higher than 28 Mbit/s (TCP Cubic) when assuming a very high bottleneck link capacity,satellite-like latency and PER≥10-6. TCP Wave instead, leveraging on an innovative burst-based transmission paradigm, is able to optimize performance in terms of both bandwidth utilization and congestion. In case of bottleneck capacity of 4 Mbit/s, TCP Wave recovers from losses with a marginal impact on the achieved rate up to a PER of 10-3. For higher PER values, it is subject to a goodput decay,like the other TCP variants, but still guaranteeing good performance. At the same time,irrespective from PER and physical RTT, TCP Wave rate control allows to keep RTT always close to the minimum value, making it much more effective with the respect to the current Linux TCPs. Increasing the bottleneck capacity to 50 Mbit/s, TCP Wave achieved a goodput that is very close to the maximum bottleneck capacity for the lowest PERs, whereas its performance becomes similar to the other TCP variants as the PER increases.
As a final conclusion, although all Linux TCP versions considered in the study provide good goodput for low/normal PER values on satellite links, only TCP Wave fully guarantee to both limit the bottleneck congestion and achieve very high data rate, then representing a potential alternative to establish end-to-end satellite connections without the use of PEPs.
As future work, authors intend to extend the analysis considering different realistic traffic patterns, and then accurately accounting the TCP start up efficiency for different values of the bottleneck bandwidths.
Reference
[1] L. Carniato, F. Fongher, M. Luglio, W. Munarini,C. Roseti and F. Zampognaro, “Traffic analysis and network dimensioning through simulation and emulation for Ka band high capacity satellite systems”,2013 IEEE 18th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks(CAMAD), Berlin, 2013, pp. 223-227.
[2] L. Carniato, F. Fongher, M. Luglio, W. Munarini,C. Roseti and F. Zampognaro, “Efficient network resources utilization for Ka-band high capacity satellite systems”,2014 12th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt),Hammamet, pp. 105-111, 2014.
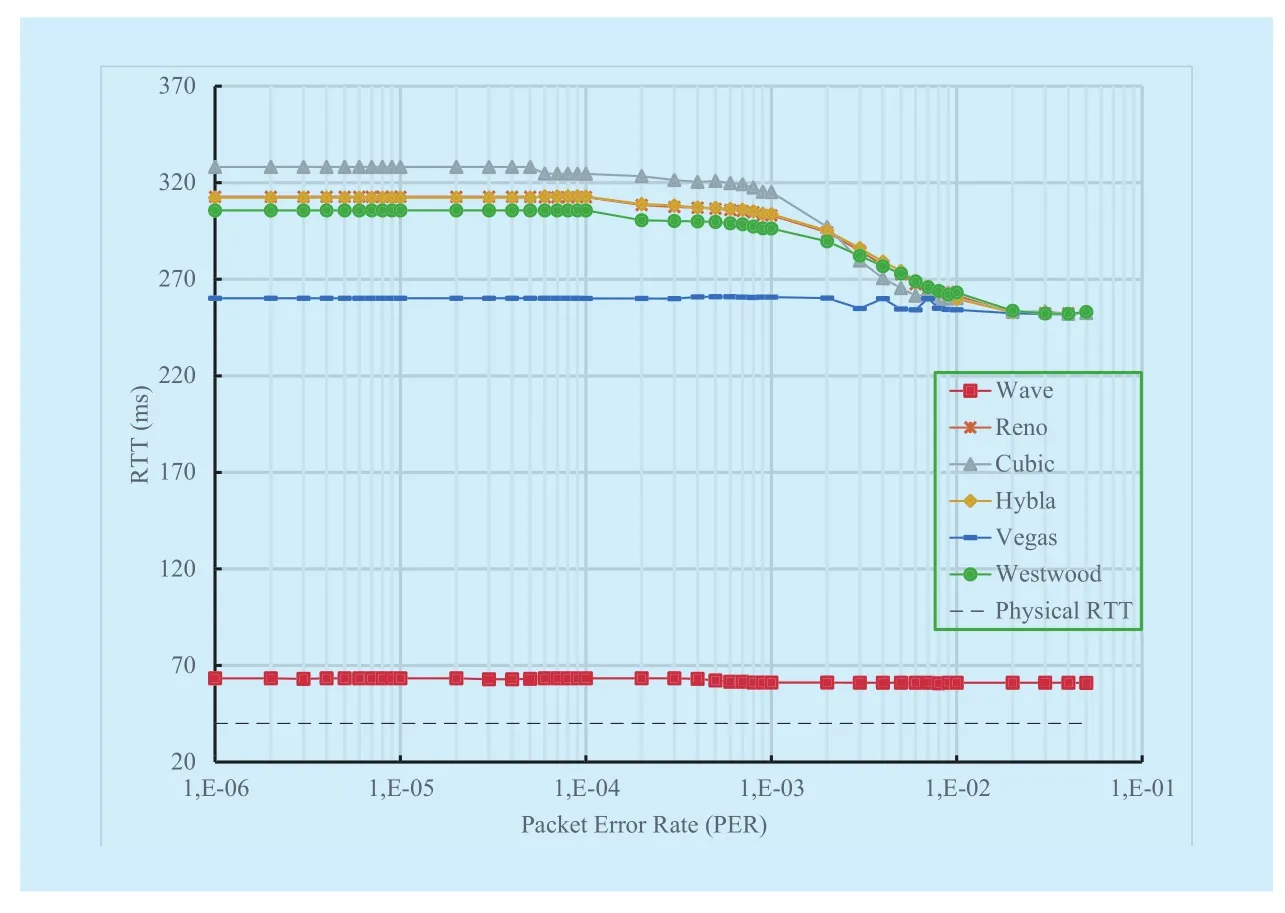
Fig. 9 RTT vs PER (Bottleneck Bandwidth C= 4Mbps, RTT = 40ms)
[3] “World’s Fastest Satellite Internet Connection Studied”,Scince Daily, Nanyang Technolog-ical University, October 19, 2009, https://www.sciencedaily.com/releases/2009/10/091014210602.htm, (last connected January 10,2017).
[4] H. Saito, T. Fukami, H. Watanabe, T. Mizuno, A.Tomiki, and N. Iwakiri, “World Fastest Communication from a 50kg Class Satellite”,IEICE Communications Society, GLOBAL NEWSLETTER, Vol.39, No. 2, 2015.
[5] W. Wagner, R. Brazil David, A. García Zaballos,“The Provision of Satellite Broadband Services in Latin America and the Caribbean”, 2016.
[6] M. Luglio, C. Roseti, F. Zampognaro, Performance evaluation of TCP-based applications over DVB-RCS DAMA schemes,International Journal of Satellite Communications and Networking, Volume 27 Issue 3, Pages 163 – 191,Mar 2009.
[7] S. Floyd, and T. Henderson, “The NewReno Modi fication to TCP’s Fast Recovery Algorithm”,RFC 2582, April 1999.
[8] M. Mathis, J. Semke, J. Mahdavi, and T. Ott, “The macroscopic behavior of the TCP congestion avoidance algorithm”,ACM SIGCOMM Computer Communication Review, 27(3), pp.67-82,1997.
[9] “I nteroperable PEP (I-PEP) transport extensions and session framework for satellite communications”,Air Interface Specification, Oct. 2005.
[10] Z. Jiang, Q. Wuand, H. Li, “NTCP: Network assisted TCP for long delay satellite network”,IEEE/CIC International Conference on Communications (ICCC Workshops), pp. 1-5, July, 2016.
[11] C. Caini, R. Firrincieli, and D. Lacamera, “Comparative performance evaluation of tcp variants on satellite environments”,IEEE International Conference on Communications, pp.1-5, June,2009.
[12] K.T. Murata, P. Pavarangkoon, K. Suzuki, K. Yamamoto, T. Asai, T. Kan, N. Katayama, M. Yahata, K. Muranaga, T. Mizuhara, and A. Takaki, “A high-speed data transfer protocol for geostationary orbit satellites”,International Conference on Advanced Technologies for Communications(ATC), pp. 425-430, December, 2016.
[13] “Satellite role in 5G Eco-System & Spectrum identification for 5G some perspectives”,5G Radio Technology Seminar. Exploring Technical Challenges in the Emerging 5G Ecosystem, London, pp. 1-16, 2015.
[14] “The Linux Kernel Organization”,https://www.kernel.org/, (last connected November 10th 2016).
[15] I. Rhee, and L. Xu, “CUBIC: A new TCP-friendly high speed TCP variant”,PFLDnet 2005, February 2005.
[16] M. Alizadeh, A. Greenberg, D. A. Maltz, J. Padhye, P. Patel, B. Prabhakar, S. Sengupta, and M.Sridharan, “DCTCP: Efficient packet transport for the commoditized data center”,Microsoft Research publications, January 2010.
[17] S. Mascolo, C. Casetti, M. Gerla, M. Sanadidi, R.Wang, “TCP Westwood: End-to-End Bandwidth Estimation for Efficient Transport over Wired and Wireless Networks”,Proceedings of ACM Mobicom 2001, Rome, Italy, July 2001.
[18] S. Floyd, “HighSpeed TCP for Large Congestion Windows”, IETF RFC 3649, Dec 2003.
[19] C. Caini, and R. Firrincieli. “TCP Hybla: a TCP enhancement for heterogeneous networks.”,International journal of satellite communications and networking, 22.5 547-566, 2004.
[20] L. Doug, and R. Shorten, “H-TCP: TCP congestion control for high bandwidth-delay product paths”.draft-leith-tcp-htcp-06, 2008.
[21] S. Lawrence, and L. Peterson, “TCP Vegas: End to end congestion avoidance on a global Internet.”,IEEE Journal on selected Areas in communications, 13.8 (1995): 1465-1480.
[22] F. Cheng Peng, and C. Soung Liew, “TCP Veno:TCP enhancement for transmission over wireless access networks.”,IEEE Journal on selected areas in communications, 216-228, 21.2.2003.
[23] Kelly, Tom, “Scalable TCP: Improving performance in highspeed wide area networks.”,ACM SIGCOMM computer communication, Review 33,no. 2 (2003): 83-91.
[24] A. Kuzmanovic, and E.W. Knightly, “TCP-LP:A distributed algorithm for low priority data transfer.”, INFOCOM 2003.Twenty-Second Annual Joint Conference of the IEEE Computer and Communications, IEEE Societies, Vol. 3, pp.1691-1701, 2003.
[25] A. Baiocchi, A.P. Castellani, and F. Vacirca, “Ye-AH-TCP: yet another highspeed TCP.”,PFLDnet,Vol. 7, pp. 37-42, Feb., 2007.
[26] S. Liu, T. Başar, and R. Srikant, “TCP-Illinois: A loss-and delay-based congestion control algorithm for high-speed networks”,Proceedings of the 1st international conference on Performance evaluation methodolgies and tools(valuetools‹06), 65(6), pp.417-440, 2006.
[27] C. Caini, R. Firrincieli, and D. Lacamera, “PEPsal:a Performance Enhancing Proxy for TCP satellite connections.”,IEEE Aerospace and Electronic Systems Magazine, 22(8), pp.7-16, 2007.
[28] A. Abdelsalam, M. Luglio, C. Roseti, F. Zampognaro, “TCP Wave: a new reliable transport approach for Future Internet”,Computer Networks(2016), doi: 10.1016/j.comnet.2016.11.002.
[29] A. Abdelsalam, M. Luglio, C. Roseti, and F. Zampognaro, “TCPWave Resilience to Link Changes- A New Transport Layer Approach Towards Dynamic Communication Environments.”,International Conference on Data Communication Networking (DCNET), p.p72-79, 2016.
[30] A. Abdelsalam, M. Luglio, C. Roseti and F. Zampognaro, “A burst-approach for transmission of TCP traffic over DVB-RCS2 links.”,Computer Aided Modelling and Design of Communication Links and Networks (CAMAD), 2015 IEEE 20th International Workshop on, Guildford, pp. 175-179, 2015.
[31] P. Sarolahti, A. Kuznetsov, “Congestion Control in Linux TCP”,USENIX Annual Technical Conference (FREENIX track), Monterey California, USA,2002.
[32] M. Mathis, J. Mahdavi, S. Floyd, and A. Romanow, “TCP selective acknowledgment options”,RFC 2018, 1996.
[33] S. Floyd, J. Mahdavi, M. Mathis, M. Podolsky, “An extension to the selective acknowledgement(SACK) option for TCP.”,RFC 2883, 2000.
[34] M. Mathis, J. Mahdavi, “Forward acknowledgement: Refining TCP congestion control.”,ACM SIGCOMM Computer Communication Review,Vol. 26. No. 4. ACM, 1996.
[35] P. Sarolahti, M. Kojo, K. Raatikainen, “F-RTO: an enhanced recovery algorithm for TCP retransmission timeouts.”,ACM SIGCOMM Computer Communication Review, 33(2), pp.51-63.
[36] M. Mathis, N. Dukkipati, Y. Cheng, “Proportional Rate Reduction for TCP”,RFC 6937, 2013.
[37] V. Paxson, M. Allman, J. Chu, M. Sargent, “Computing TCP’s retransmission timer”,RFC 6298,2011.
[38] “ns-3 discrete-event network simulator”,https://www.nsnam.org/, (last connected November 10th 2016).
[39] H. Tazaki, F. Uarbani, E. Mancini, M. Lacage, D.Camara, T. Turletti, and W. Dabbous, “Direct code execution: revisiting library OS architecture for reproducible network experiments”,9th ACM conference on Emerging networking experiments and technologies, pp. 217-228, Decembe,2013.
[40] “Synchronous Optical Network (SONET)”.WebProForums. International Engineering Consortium. Archived from the original on 2007-05-02.Retrieved 2007-05-25.
[41] 802.11ac: The Fifth generation of WiFi, Technical White Paper, March 2014, issued by Cisco,http://www.cisco.com/c/en/us/products/collateral/wireless/aironet-3600-series/white_paper_c11-713103.pdf(last connected January 8th,2017)
[42] KA-SAT professional services brochure,http://www.eutelsat.com/files/contributed/news/media_library/brochures/ka-sat-professional-services.pdf(last connected January 10th, 2017).
[43] “iPerf - The ultimate speed test tool for TCP,UDP and SCTP”,http://iperf.fr, (last connected January 10th, 2017).

- China Communications的其它文章
- Adaptive Application Offloading Decision and Transmission Scheduling for Mobile Cloud Computing
- Multi-Gradient Routing Protocol for Wireless Sensor Networks
- Smart Service System(SSS): A Novel Architecture Enabling Coordination of Heterogeneous Networking Technologies and Devices for Internet of Things
- Efficient XML Query and Update Processing Using A Novel Prime-Based Middle Fraction Labeling Scheme
- Degree-Based Probabilistic Caching in Content-Centric Networking
- Direction of Arrivals Estimation for Correlated Broadband Radio Signals by MVDR Algorithm Using Wavelet