
阵列处理器中改进几乎空白子帧算法的并行化实现*
2017-04-26 11:09李雪婷崔朋飞
电讯技术 2017年4期
李雪婷,蒋 林,张 新,崔朋飞,张 艳
(西安邮电大学 a.计算机学院;b.电子工程学院;c.通信与信息工程学院,西安 710121)
阵列处理器中改进几乎空白子帧算法的并行化实现*
李雪婷a,蒋 林*b,张 新b,崔朋飞b,张 艳c
(西安邮电大学 a.计算机学院;b.电子工程学院;c.通信与信息工程学院,西安 710121)
两层异构网络中出现的小区间干扰协调是当前异构网络干扰问题研究的热点。针对软件实现增强小区调度几乎空白子帧(ABS)的干扰方案存在处理数据量大、速度慢的缺点,基于可重构阵列结构提出了一种动态ABS干扰协调的并行化硬件实现方案。该算法在增强小区内根据用户数动态分配ABS比例,以改善小区边缘用户的信道容量,通过流水线的方式使用多个轻核处理元(PE)实现并行计算以提高运算效率。测试结果表明,使用12个PE同时调度实现算法的映射,运行1 983个周期,其性能比单个PE提升77.03%,该算法的并行计算能力得到显著提升,宏基站用户的吞吐量可以达到4.76 Mbit/s。
异构网;小区间干扰协调;可重构阵列处理器;几乎空白子帧;增强小区
1 引 言
进入4G移动通信时代,人们对移动通信终端的数据传输和处理能力要求越来越高,这些都对无线通信的硬件实现提出了更高的要求。因此,可重构阵列结构可以根据应用的需求优化电路设计,降低能耗,逐渐成为无线通信研究热点。可重构阵列结构不仅体现了软件的通用性、硬件的高效性,还具有FPGA的低风险、灵活性和快速上市的特点,以及定制芯片不具有的可配置特性。在进行大量密集型计算时,通用处理器(General Purpose Processors,GPP)的处理能力有限,计算速度较低,很难达到处理要求;专用处理芯片(Application Specific Integrated Circuit,ASIC)虽然能满足需求,但其缺点是只适应特定的应用场合,体系结构不能修改、升级,配置灵活性差,开发周期长[1]。文献[2]指出,若将软件中关键部分移到可重构硬件上执行,平均能量将节省35%~70%。
随着LTE-A技术不断发展,异构网络以其能够扩大覆盖范围并支持热点地区高速率传输的优点成为研究热点[3]。随着移动通信系统的不断演进,网络规模呈现爆炸式的增长。统计表明,移动数据流量的爆发式增长,使得未来80%~90%的系统吞吐量将发生在室内和热点场景,传统蜂窝网络简单的宏(Macro)基站模式已经难以跟上数据的增长[4]。为了解决上述问题,LTE-A架构提出了异构网络,就是在宏基站覆盖的小区内,部署发射功率和覆盖范围较小的低功率节点,如微(Pico)基站、家庭基站(Femtocell)、中继节点(Relay)等,以此满足移动带宽的指数增长,达到提高系统容量的目的。在相关文献的研究工作中,文献[5]提出在通用移动通信系统(Universal Mobile Telecommunications System,UMTS)下一种基于预编码的下行干扰避免方法,Pico用户性能略微下降,系统容量得到提升;文献[6-7]给出了在增强小区(Cell Range Expansion,CRE)技术下,几乎空白子帧(Almost Black Scheme,ABS)干扰协调技术对系统容量的影响,以牺牲Macro用户的性能来换取Pico用户性能的提升,虽然可以达到降低干扰的目的,但是却没有指出如何确定ABS所占的比例。
基于上述研究工作,本文基于邻接互连可重构阵列处理器的结构,分析设计了改进ABS算法并行化实现方案,提出了在CRE内根据用户数动态分配ABS比例的干扰协调方法。该结构不仅结合了GPP的可编程灵活性和ASIC的运算高效性,能够满足大规模的数据并行操作,弥补了GPP和ASIC的不足,而且可以满足算法的性能,改善小区边缘用户的信道容量和增强小区用户数据传输率的平衡,提高了网络的整体性能,改善了信道利用率,提高了用户的平均吞吐量。
2 ABS算法及并行化实现
2.1 基于可重构阵列处理器的算法并行化实现
笔者所在研究团队提出了包含1 024个轻核处理元(Processing Element,PE)邻接互连的可重构阵列结构。该结构包含64个簇,每个簇由4×4的PE组成,每个PE采用load/store模式的RISC架构,按照取指、译码、执行、写返回4级流水线结构进行执行。该可重构系统包括全局指令存储器、输入存储器、输出存储器、可重构阵列处理器与视频接口,如图1所示。

图1 可重构结构图
阵列处理器的每个PE都具有相同的结构,采用相同的配置方式,支持相同的运算操作,这样的设计可以更容易地进行算法映射和调度,也有利于自动编译工具的实现。该结构的设计是基于数据并行计算的单指令多数据流(Single Instruction Multiple Data,SIMD)和指令并行计算的多指令多数据流(Multiple Instruction Multiple Data,MIMD),以解决并行化和非并行化运算的高效性和编程的灵活性[8]。换句话说,就是利用算法中存在的数据级和任务级并行性来提高程序的性能。为了解决无线通信信息数据量大、难以存储和传输等问题,处理器采用的通信机制是邻接互连的网络拓扑结构和“逻辑共享、物理分布”统一编址的无Cache分布式共享存储结构共享寄存器。在阵列处理器上实现算法的映射时,采用邻接互连的共享寄存器对数据进行访存,这样的编程方式体现了处理器的灵活性及相邻PE之间的数据交互访问能力。跨PE的访问采用多Bank的并行存储技术,实现数据级并行计算和指令级并行计算的同时,且支持簇内数据的全访问。
2.2 ABS算法描述
为了满足无线数据业务量以指数方式增长的趋势,Pico基站作为一种改善蜂窝网络中用户密集地区的吞吐量和数据速率的方法,引起了广泛的关注。由于传统的移动蜂窝网络只部署了Macro基站,故存在信号盲区、室内信号差以及热点区域容量不足等问题,因此,引入ABS技术用于解决控制信道的干扰问题。相对于Macro基站而言,Pico基站发射功率低,这种网络部署方式拉近了基站和终端的距离,网络容量得到提升,信号盲区、热点区域的通信质量得到改善,但Pico小区边缘用户干扰严重。为了提高小区边缘用户的网络容量,通过扩大Pico基站的覆盖范围,分担Macro基站的用户数,提高用户吞吐量。
在异构网中,传统的ABS算法是Macro基站与Pico基站分别接收固定的资源块,这样带来的问题是干扰大,功率低。传统算法中Macro基站的发射功率比Pico基站大得多,如果仍按照最大信干噪比(Signal to Interference plus Noise Ratio,SINR)进行接入,将导致大部分用户自动接入到Macro基站中。Pico基站服务的用户则较少,且Pico基站覆盖边缘的大部分用户仍选择接入Macro基站,不利于Pico基站分流Macro基站的负荷,大大降低了Pico基站能为系统带来的容量增益,不符合异构网的设计初衷[9]。为了解决这个问题,对ABS算法提出改进,根据Macro基站用户资源块进行动态调整,将用户数分流给Pico基站,以此来提高Macro基站的系统容量。为了使用户尽可能地接入Pico基站,提高LTE-A系统两层异构网络中的下行信道利用率,本文基于小区增强覆盖技术提出了一种动态调度ABS算法。该方案的原理是旨在用户测量得到Pico基站发送的信干噪比ρ上增加一个正的偏置值,将这个结果与Macro基站发送的信干噪比φ进行比较,选择接入相对较大的基站。其公式(1)如下:

(1)
通过在小区选择过程中加入一个λ的偏置值,使Pico基站的覆盖范围扩大,让原本接入Macro基站的部分用户被强行接入到Pico基站。在Pico基站信号强度低于Macro基站时,用户选择接入Pico基站,达到分担Macro基站负荷的目的。
2.3 改进ABS算法的并行化实现

此时,单位带宽下接入Macro基站的用户总人数的系统容量(单位为bit/s·Hz-1)可以表示为λ的函数,即
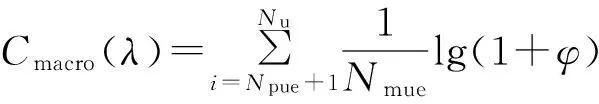
(2)
式中:Nmue=Nu-Npue。定义用户接入Pico中心小区的信干噪比为ρabs,接入Pico增强小区的信干噪比为ρnabs,Pico基站的系统容量可以表示为λ的函数,即

(3)
ABS算法具有高计算密集型的特点,并且数据之间的并行性很高,同一时刻存在大量的相同操作,因而符合阵列处理器所具有的SIMD模式并行计算的特点。按照算法的执行顺序,对算法进行划分,将可并行的部分进行整合,从而缩短了解决整个算法所需的计算时间。因此,我们对ABS算法进行分块处理,将不同类型的数据块存放在不同的PE上,以减少算法的计算过程和内存之间数据的搬运次数,进而优化ABS算法运算所需的计算周期,使得算法在不同的小区偏置值下的系统容量和下行信道利用率可以得到有效的均衡。图2是在可重构阵列结构上实现改进的ABS算法映射方案,以4个PE为一组,首先在小区选择参数中加入一个λ的偏置值,根据用户在两层异构网络中信干噪比的差值,判断用户是接入Macro基站还是Pico基站,以边缘用户数与总用户数的比值作为ABS的动态配置比率。

图2 算法在阵列结构映射数据流图
下面是算法的具体映射步骤。
Step 1 分别选取一段Macro基站的信干噪比φ和Pico基站的信干噪比ρ存入可重构阵列结构PE01、PE13、PE20的共享寄存器中。
Step 2 使用PE01(PE13、PE20)根据接入的信干噪比差γ作为判决门限进行基站的选择,通过邻接互连可由相关PE00(PE03、PE30)、PE02(PE23、PE10)、PE11(PE12、PE10)访问。对公式(1)改进,推导得到公式(4):

(4)
如果φ-ρ>λ,将值存入到PE00的共享寄存器中,统计接入Macro基站的用户数和系统容量;如果0<φ-ρ≤λ,则存入到PE11的共享寄存器中,统计接入边缘小区的Pico基站边缘用户数和系统容量;如果是φ-ρ≤0,则存入到PE02共享寄存器中,并统计接入中心小区的Pico基站中心用户数和系统容量。
Step 3 PE00、PE02、PE11三个轻核处理元,当每次从PE01收到判决的用户数时,对接入的用户统计用户数和系统容量。在这个过程中PE00、PE01、PE02、PE11是并行操作的,这样可以提高算法运行速度,效率更高。当PE00(或者PE02、PE11)收到PE01邻接互连传来的数据时,统计接入Macro基站的用户数(或者Pico基站的用户数),并根据接收到的数据计算系统容量。4个PE为一组进行一次统计,如果选用的PE数增加,运行周期成倍数降低。
3 实验结果与分析对比
根据可重构阵列结构的设计原理,搭建建模仿真平台,时钟周期为20 ns。在该建模仿真平台上,对改进的ABS算法采用并行化操作的方式实现算法映射,首先对系统配置的仿真参数进行设置,仿真参数是依据LTE-A标准制定的,如表1所示。
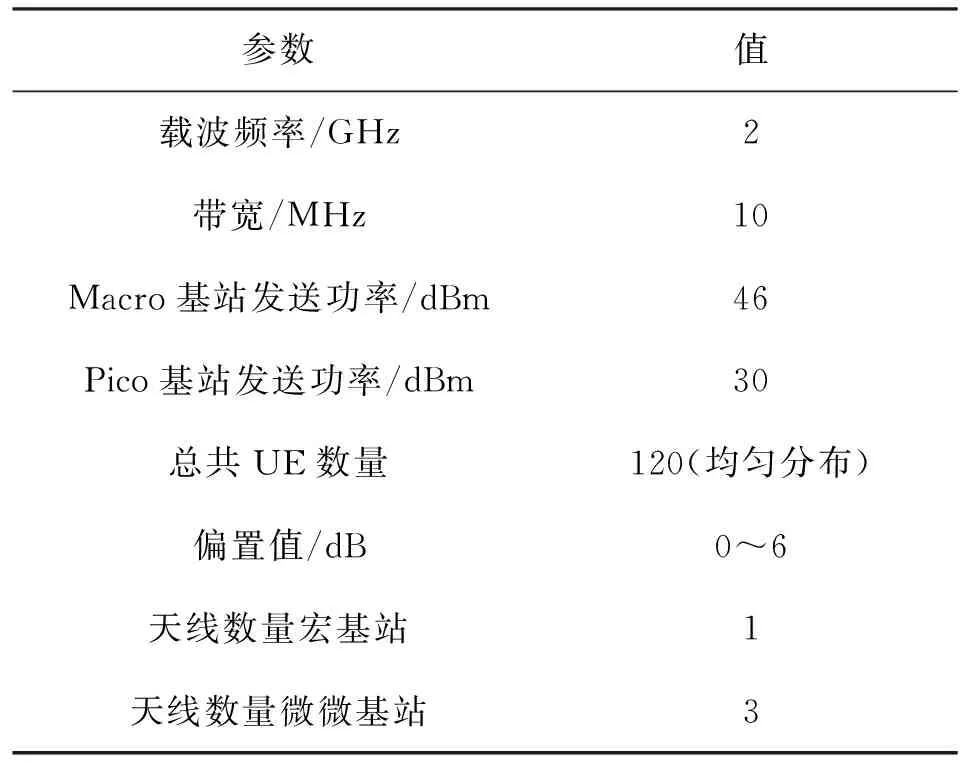
表1 仿真参数设置
基于不同的CRE值,分别仿真了不同ABS配置情况下的系统性能。用户采用最强接收信号功率准则进行接入,调整CRE动态的分配用户资源,使得接入Pico基站的用户数增加,分担Macro基站的系统容量。随着CRE的增大,Pico基站的用户数不断增加,如图3所示。所以,在LTE-A异构网中有必要改变小区切换和重选策略,让更多移动终端选择驻留在Pico基站为服务小区,以保证小区分裂增益的最大化,提升全网总体性能。Pico基站可以利用受保护的子帧进行数据传输,提升其边缘用户的吞吐量;由于Macro基站在ABS子帧上不能调度任何用户数据,会造成Macro基站的容量损失。

图3 Pico-h-User用户变化趋势
由Macro-Pico构成的两层异构网络中,Macro-Pico网络混合部署时,当接入Pico小区的用户达到20%时,与单独部署Macro基站相比节能可高达60%[10]。从算法实现角度分析,本文所提出的方法,随着CRE的增加,Macro基站的系统容量不断降低,用户数降低,Pico基站分担了Macro基站的负载。当偏置值CRE=3 dB时,接入Macro基站的用户数大约只有45%,Pico基站分担的接入用户数可以达到22%。此时,异构网络系统容量的整体性能达到最佳,Pico基站可以使系统网络性能获得有效的增益。
为了评估本文所改进的ABS算法,与文献[11]对比,表2为偏置值CRE=3 dB的系统性能。本文方案与文献[11]对比,虽然Macro用户的平均吞吐率和Macro基站吞吐量具有相似的结果,但是相比于文献[11],本文提出的方案可以获得更好的性能。

表2 基于改进的ABS算法方案的系统性能比较
从硬件实现角度对算法进行简单的性能分析。在算法映射时采用不同的处理器核数进行测试,最后得到的结果如表3所示。根据性能提升计算公式[12]

(5)
可以得出整体处理器的性能提升百分比如表3所示。从表3可以看出,使用的处理器PE数增加,算法的整体运算速度明显提高。这是因为算法的并行化程度高,处理器PE数越多,并行化程度越高,可以同时处理数据,对处理器提升算法的性能影响比较大。对于多核阵列处理器而言,12个处理器同时调度映射算法的设计,使得算法的并行化程度最高且处理器的性能提升最大,充分体现了阵列处理器的优点。

表3 性能分析表
4 结束语
本文研究了LTE-A系统下两层异构网络中的下行信道利用率,分析了CRE技术,提出了一种动态调度ABS的算法。从硬件实现角度分析,在可重构阵列处理器上实现改进的ABS并行化实现方案,使用12个轻核处理元PE进行大规模的数据并行,极大地提高了算法的执行时间,算法的运算周期大幅降低,性能提升77.03%。从算法性能角度分析,所设计的方法能够更合理地利用资源,Macro基站吞吐量提高到4.76 Mbit/s,不仅提高了系统总容量,同时也实现了资源的合理利用,能够满足无线通信设备要求提供的高带宽、高速度、大容量的无线接入要求。在未来工作中,我们将考虑其他无线通信算法在阵列处理器上的映射以提高算法的性能。
[1] CERVERO T.Survey of reconfigurable architectures for multimedia applications[J].Proceedings of SPIE,2009,7363(1):363-381.
[2] STITT G,VAHID F,NEMATBAKHSH S. Energy savings and speedups from partitioning critical software loops to hardware in embedded systems[J].ACM Transactions on Embedded Computing Systems,2004,3(1):218-232.
[3] GHOSH A,RATASUK R,MONDAL B. LTE-advanced:next-generation wireless broadband technology[J].IEEE Wireless Communications,2010,17(3):10-22.
[4] 张永忠,唐玮俊,冯穗力. 基于先进小区干扰协调技术的异构网络联合资源分配[J].电讯技术,2016,56(6):597-604. ZHANG Yongzhong,TANG Weijun,FENG Suili.Joint resources allocation for enhanced inter-cell interference coordination in heterogeneous networks[J].Telecommunication Engineering,2016,56(6):597-604.(in Chinese)
[5] HOU Y,LIANG X W,NAMP P C,et al.A downlink interference coordination scheme for heterogeneous network based on pre-coding[J].Radio Engineering,2014(5):1-5.
[6] GUVENC I. Capacity and fairness analysis of heterogeneous networks with range expansion and interference coordination[J].IEEE Communications Letters,2011,15(10):1084-1087.
[7] GUVENC I,JEONG M R,DEMIRDOGEN I,et al.Range expansion and inter-cell interference coordination(ICIC) for picocell networks[C]//Proceedings of 2011 IEEE Vehicular Technology Conference.Budapest,Hungary:IEEE,2011:1-6.
[8] SHEN X B,SUN L.The unification research for computing paradigm[J].Chinese Journal of Computers,2014,37(7):1435-1444.
[9] 黄德华. LTE-A异构网中的负载均衡与增强型小区间干扰协调技术研究[D].广州:华南理工大学,2015. HUANG Dehua.Research on inter-cell interference coordination in LTE-Advanced heterogeneous networks[D].Guanghzou:South China University of Technology,2015.(in Chinese)
[10] CLAUSSEN H,HO L T W,PIVIT F.Effects of joint macrocell and residential picocell deployment on the network energy efficiency[C]//Proceedings of 2008
IEEE International Symposium on Personal,Indoor and Mobile Radio Communications.Cannes,French Riviera,France:IEEE,2008:1-6.
[11] AL-RAWI M,SIMSEK M,JANTTI R.Utility-based resource allocation in LTE-Advanced heterogeneous networks[C]//Proceedings of 2013 IEEE Wireless Communications and Mobile Computing Conference.Cagliari,Italy:IEEE,2013:826-830.
[12] QIAN B,LI T,HAN J,et al. Design of a thread manager in a polymorphic parallel processor[J].Application of Electronic Technique,2014(2):30-32.
Parallel Implementation of Improved Almost Blank Subframes Algorithm on Array Processor
LI Xuetinga,JIANG Linb,ZHANG Xinb,CUI Pengfeib,ZHANG Yanc
(a.School of Computer Science;b.School of Electronic Engineering;c.School of Communication and Information Engineering,Xi′an University of Posts and Telecommunications,Xi′an 710121,China)
Inter-cell interference(ICI) coordination appears in the two-layer heterogeneous networks is a hot topic in the current research on heterogeneous network interference. The software implementation of cell range expansion control almost blank subframes(ABS) scheme has the weakness of large amount of data processing and slow speed. Based on the reconfigurable array processor,a dynamic interference coordination method is presented which is ABS parallel implementation hardware implementation scheme. In the cell range expansion,this algorithm dynamically allocates ABS ratio according to the number of users in order to improve the channel capacity of the cell edge users.By pipelining processing between multiple Processing Element(PE) parallel computing,the operation efficiency of the algorithm is improved. The test results show,when 12 PEs are used and scheduled to realize mapping,in 1 983 operation cycle,the performance enhances 77.03% in comparison with single PE.The parallel computing capability of the algorithm is significanty improved and the macro base station user throughput can reach 4.76 Mbit/s.
heterogeneous network;inter-cell interference coordination;reconfigurable array processor;almost black subframes;cell range expansion
10.3969/j.issn.1001-893x.2017.04.013
李雪婷,蒋林,张新,等.阵列处理器中改进几乎空白子帧算法的并行化实现[J].电讯技术,2017,57(4):444-449.[LI Xueting,JIANG Lin,ZHANG Xin,et al.Parallel implementation of improved almost blank subframes algorithm on array processor[J].Telecommunication Engineering,2017,57(4):444-449.]
2016-07-28;
2016-12-15 Received date:2016-07-28;Revised date:2016-12-15
国家自然科学基金资助项目(61272120,61634004,61602377);陕西省自然科学基金资助项目(2015JM6326);陕西省科技统筹创新工程项目(2016KTZDGY02-04-02)
TN925
A
1001-893X(2017)04-0444-06

李雪婷(1989—),女,山西太原人,硕士研究生,主要研究方向为计算机技术;
Email:18292861351@163.com
蒋 林(1970—),男,陕西杨凌人,教授,西安邮电大学副校长,主要研究方向为专用集成电路设计;
Email:jl@xupt.edu.cn
张 新(1968—),女,陕西西安人,西安邮电大学教授,主要研究方向为异构网络;
崔朋飞(1990—),男,河南安阳人,硕士研究生,主要研究方向为电子与通信;
张 艳(1988—),女,陕西榆林人,主要研究方向为通信与信息系统。
*通信作者:jl@xupt.edu.cn Corresponding author:jl@xupt.edu.cn
猜你喜欢
小学教学研究(2022年5期)2022-04-28
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
电信工程技术与标准化(2015年10期)2015-12-22
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
电信科学(2014年8期)2014-03-26
电信科学(2014年2期)2014-03-25
电信科学(2013年6期)2013-03-25
