
用于特征提取的小尺寸事件型卷积处理器*
2017-04-21 06:53:48卢成业高志远徐江涛天津大学电子信息工程学院天津300072
传感技术学报 2017年4期
卢成业,高志远,徐江涛(天津大学电子信息工程学院,天津 300072)
用于特征提取的小尺寸事件型卷积处理器*
卢成业,高志远*,徐江涛
(天津大学电子信息工程学院,天津 300072)
设计了一款用于动态视觉传感器数据特征提取的小尺寸事件型卷积处理器,该卷积处理器包含了32×32的累加阵列、用于存储卷积核的RAM阵列、左/右移位模块、控制模块和异步的事件读出模块。为了减小面积,设计了2 bit的32×32的RAM阵列来存储所需的卷积核;在累加阵列中,采用7 bit的二进制计数器代替传统的加法器来实现卷积核的累加操作,在0.18 μm CMOS工艺下,每个卷积单元的面积为37.5 μm×40 μm,对于每个事件输入输出的最小延时为17 ns,能够处理的最大事件率为12.5 Meps。基于该卷积处理器搭建了一个识别系统,利用16个卷积处理器来提取特征,利用脉冲神经网络实现了分类识别。实验结果表明,使用2 bit卷积核的小尺寸卷积处理器能够准确完成对输入事件的卷积操作,而且基于该卷积处理器所搭建的识别系统对MNIST数据库的识别效率可以达到90.57%。
动态视觉传感器,地址事件表示,小尺寸芯片,卷积芯片,MNIST,脉冲神经网络
在传统的人工视觉处理系统中,卷积运算被广泛用于边缘检测、特征提取以及目标识别等领域。近些年,随着人工神经计算的发展,卷积神经网络成为当前图像领域的研究热点之一,得到了广泛的应用[1-2]。由于卷积运算的计算量大,运算时间长,硬件开销大,因此传统的卷积运算并不能很好满足对图像实时处理的要求[3]。
1991年,Caltech实验室首次提出地址-事件表达(AER)方式[4],AER 是一种仿生的图像采集、处理模式,现在被广泛应用于图像传感器领域[5-6]。AER图像传感器是一种特殊的图像传感器,与传统的帧扫描式图像获取机制不同。在AER图像传感器中,各个像素之间独立工作,当某个像素单元检测到光强变化超过设定阈值后,就会触发事件响应,分别用ON事件和OFF事件来代表光强的增强和减弱。如果有多个像素单元同时触发事件响应,就通过仲裁模块依次输出事件脉冲。AER图像传感器的输出只包含了事件发生的地址(x,y)和属性(ON/OFF),从而具有低冗余、低延时、高实时性等优点[7]。因此,研究与AER图像传感器相适应的处理模块就可以对输出事件进行实时处理,摆脱“帧”的束缚,可以实现更高的处理速度。
1997年,瑞士的 Venier 团队首次硬件实现了基于事件的卷积处理[8]。2006年塞维利亚大学的Rafael Serrano-Gotarredona等人提出了基于AER的数模混合神经形态卷积芯片[9]。2011年,Luis Camuas-Mesa等人研究设计出了32×32像素阵列的全数字的卷积芯片[10],设计了6bit的RAM来存储卷积核,18 bit的累加器,该芯片中单个像素单元的面积为95.6 μm×101.3 μm。2012年,塞维利亚大学的Luis Camuas-Mesa小组设计出了64像素×64像素阵列的事件卷积芯片,使用纯数字电路设计,且其卷积核的形状和尺寸可以改变[11]。在该芯片的设计中,采用了4 bit的RAM和6 bit的累加器,单个像素单元的面积为58 μm×53.8 μm。在卷积芯片的设计中,用来存储卷积核的RAM和实现累加运算的累加器占据了芯片的大部分面积。因此,在保证卷积效果的同时使用尽量少的卷积核RAM可以有效缩减事件型卷积处理器的芯片面积。
卷积芯片的一个重要作用是用来提取特征,提取的特征经过一定的学习算法可以实现目标的分类识别等。脉冲神经网络作为第3代神经元模型,相比传统的神经元模型具有更高的计算效率。脉冲神经网络应用精确定时的脉冲序列对神经信息进行编码和处理,非常适用于AER事件的处理识别。此外,脉冲神经网络也易于硬件实现,已经报道了很多脉冲神经网络的硬件实现平台,比如IFAT(Integrate and Fire Array Transceiver)[12]和Hierarchical AER-IFAT[13]。本文设计了一个32×32的事件卷积处理器,设计了2 bit的RAM来存储卷积核,7 bit的计数器来实现累加功能,并对该结构的卷积效果进行了仿真验证。此外,为验证该卷积处理器在特征提取方面的特性,本文利用脉冲神经网络搭建了一个识别系统,对经过卷积后的特征进行了分类识别。经过仿真验证,在该识别系统中,本文设计的卷积处理器可以以较低的存储器深度实现相类似的识别效率,在满足提取特征的要求的前提下,缩减了芯片面积。
1 基于事件的卷积算法
在图像处理中,卷积计算是一种广泛应用的计算方式。基于事件的卷积计算是通过在卷积阵列中实现卷积核权值的不断累加实现的。AER图像传感器产生的每个事件都包含了事件的地址信息和属性,当对该事件进行卷积操作时,就以该事件的地址为中心,将卷积核累加到卷积阵列中。
图1显示了传统的卷积算法与基于事件的卷积算法的不同,图1(a)是传统的基于帧的卷积计算过程,图中输入图像是5×5的矩阵,卷积核是一个3×3的矩阵,卷积结果如图所示,计算过程包含了乘法和加法运算,计算过程较为复杂。图1(b)显示了基于事件的卷积过程,当(2,2)地址处的事件到来时,就以(2,2)地址为中心将卷积核累加到卷积阵列中,(3,3)和(4,4)地址的事件到来时也完成相应的累加过程。基于事件的卷积过程只包含了累加运算,相比传统的基于帧的卷积算法,计算更为简单,更加易于硬件实现。

图1 卷积算法对比
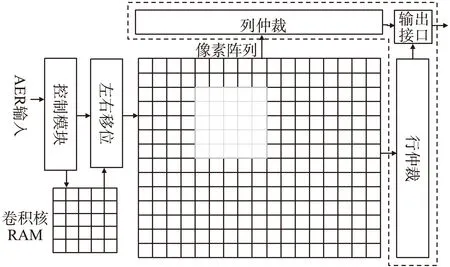
图2 卷积处理器结构
2 事件卷积架构设计
基于事件卷积算法的基本原理,本文设计的事件卷积处理器的结构如图2所示,处理器包含了一个32×32的卷积像素阵列、行列仲裁、一块用于存储卷积核的RAM阵列、控制模块、左/右移位模块和异步的事件读出模块。初始状态下,卷积像素阵列处于复位状态,卷积核存储在RAM阵列中,当卷积芯片接收到输入事件时,控制模块读取RAM中存储的卷积核,同时控制模块也会根据输入事件的地址信息,产生像素阵列的行选信号,通过判断卷积核左移或者右移的位数,卷积核被移位模块移动到对应的数据总线上,在时钟驱动下在卷积阵列中逐行完成卷积核的累加。由于卷积核的尺度的不同,完成累加操作需要的时钟周期也不相同,在本文的设计中完成一个输入事件的卷积操作,共需要2+Nk个时钟周期,Nk为卷积核的行数。当卷积阵列中某像素点累加的值超过预先设定的阈值时,该像素点就会发出输出请求,经过仲裁模块的运算和选通,最后通过异步事件读出模块产生事件输出,同时卷积阵列中该位置被置零,等待重新开始新的累加过程。

图3 像素单元结构和AER_out电路结构
2.1 像素阵列设计
为了减小芯片的面积,本文设计中采用了2 bit的RAM来存储卷积核,设计了7 bit计数器来代替累加器实现累加操作。像素单元的结构如图3(a)所示,共包含了开关模块(witch block)计数器(OUNTER)阈值比较模块和AER输出接口电路。
控制模块根据输入事件的地址信息,产生相应的行选信号Enable,卷积核的权值才能进入被选通行的像素中,通过计数器完成累加功能。图中阈值比较模块实现阈值的比较,采用两个异或门(XOR),通过最高位与选取数据位的异或操作,来判定达到正阈值或负阈值,通过SEL信号端和多路选择器(MUX)来选择输出。累加单元达到选定的阈值时,通过AER输出接口电路向外围的仲裁电路发出请求,在收到确认信息后,输出像素信息并将此像素复位。由于本文的设计中采用2 bit的卷积核,其中最高位为符号位,因此设计二进制的可逆计数器就能够满足功能的需求,AER输出接口由一个D锁存器(D_latch)和异步接口(AER_out)构成。图3(b)显示了AER_out模块的电路结构,该模块采用了文献[11]的类似结构,当阈值比较模块有脉冲产生时,会触发AER_out模块产生行输出请求,此时Rqst被拉至高电平,外围电路接受请求后会产生响应信号Ack(低电平),此时根据卷积核的符号位,将Pulse-或者Pulse+拉至低电平,产生列请求信号。
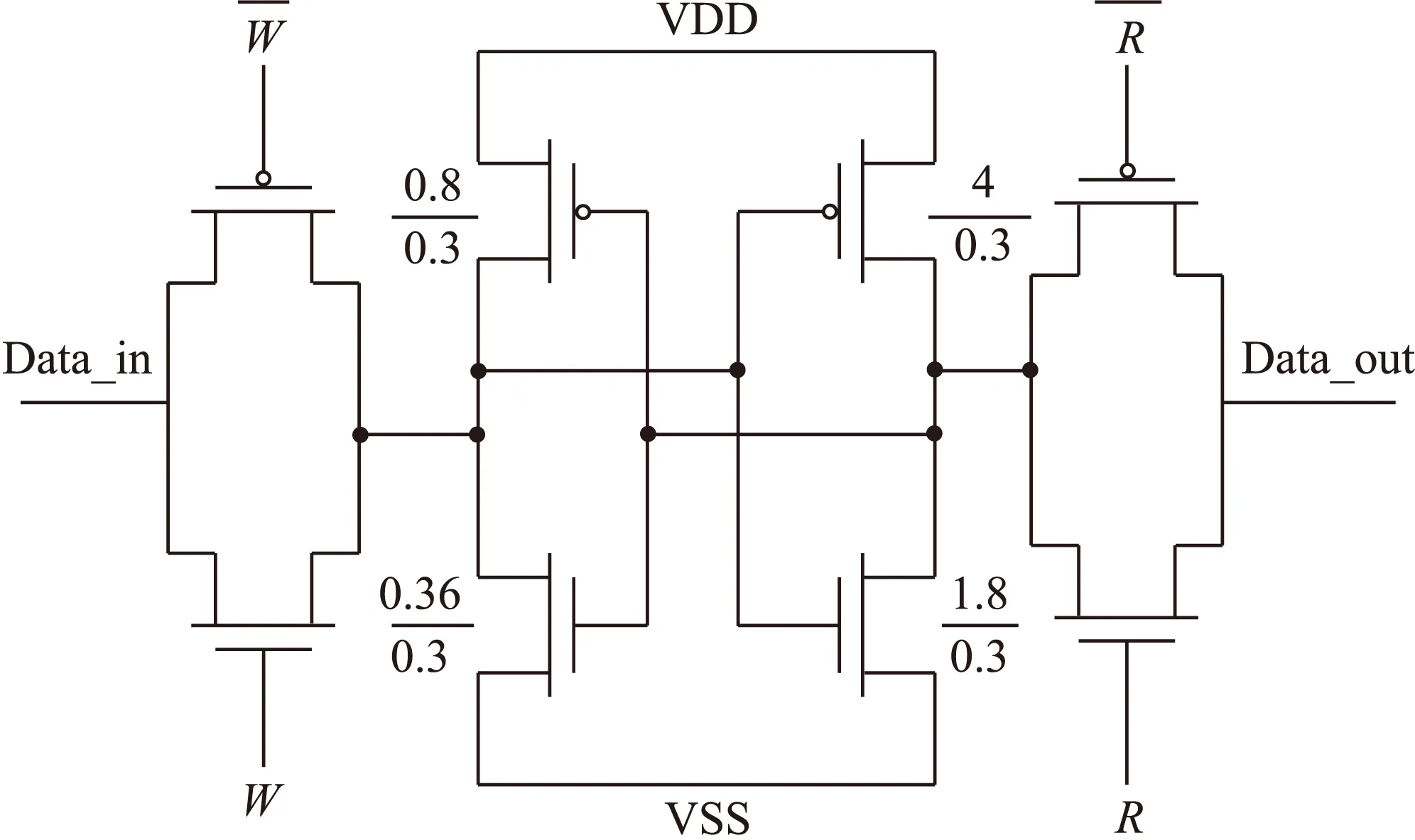
图4 RAM存储单元结构
2.2 卷积核RAM和移位模块设计
卷积核被预先存储起来,当有事件到来时,通过控制模块来选择读取相应的卷积核到总线上并累加到像素阵列中,因此通过设计静态RAM即可满足功能要求。在事件卷积处理器设计中,SRAM 的写入速度并不重要,但对于高速产生的事件,SRAM读取的速度就显得比较重要,因此需要设计具有较高读取速度的SRAM[14]。本文设计了2 bit的RAM来存储卷积核,单个存储单元的结构如图4所示,该结构中包含了两个反向器,一个“弱”反向器和一个“强”反向器,构成了锁存器结构。本文利用如图4所示的存储单元,搭建了一个32×32的存储阵列,该存储阵列能够存储多种卷积核,通过控制模块的控制信号,可以选择读取不同的卷积核。
由于卷积核在RAM中存储的位置与输入事件的地址会有一定的偏移,因此需要设计移位模块来实现移位功能。移位模块可以根据输入事件的地址实现卷积核的左移或者右移,将卷积核移动到相应的坐标处。移位模块的结构如图5所示,该结构可以保证选定的卷积核在一个时钟周期即可完成多条总线的移动,实现卷积处理的高速进行。在该移位模块中,每列卷积核RAM的总线在竖直、向左或向右45°方向上进行延伸,互连矩阵中每个总线交叉结点都包含了两个三态门来控制信号通路的流通方向。两个三态门分别连接两个水平方向输入的移位信号,分别控制左移和右移。
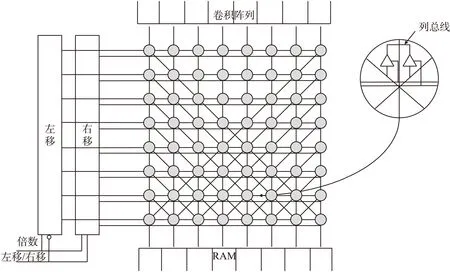
图5 移位选择模块
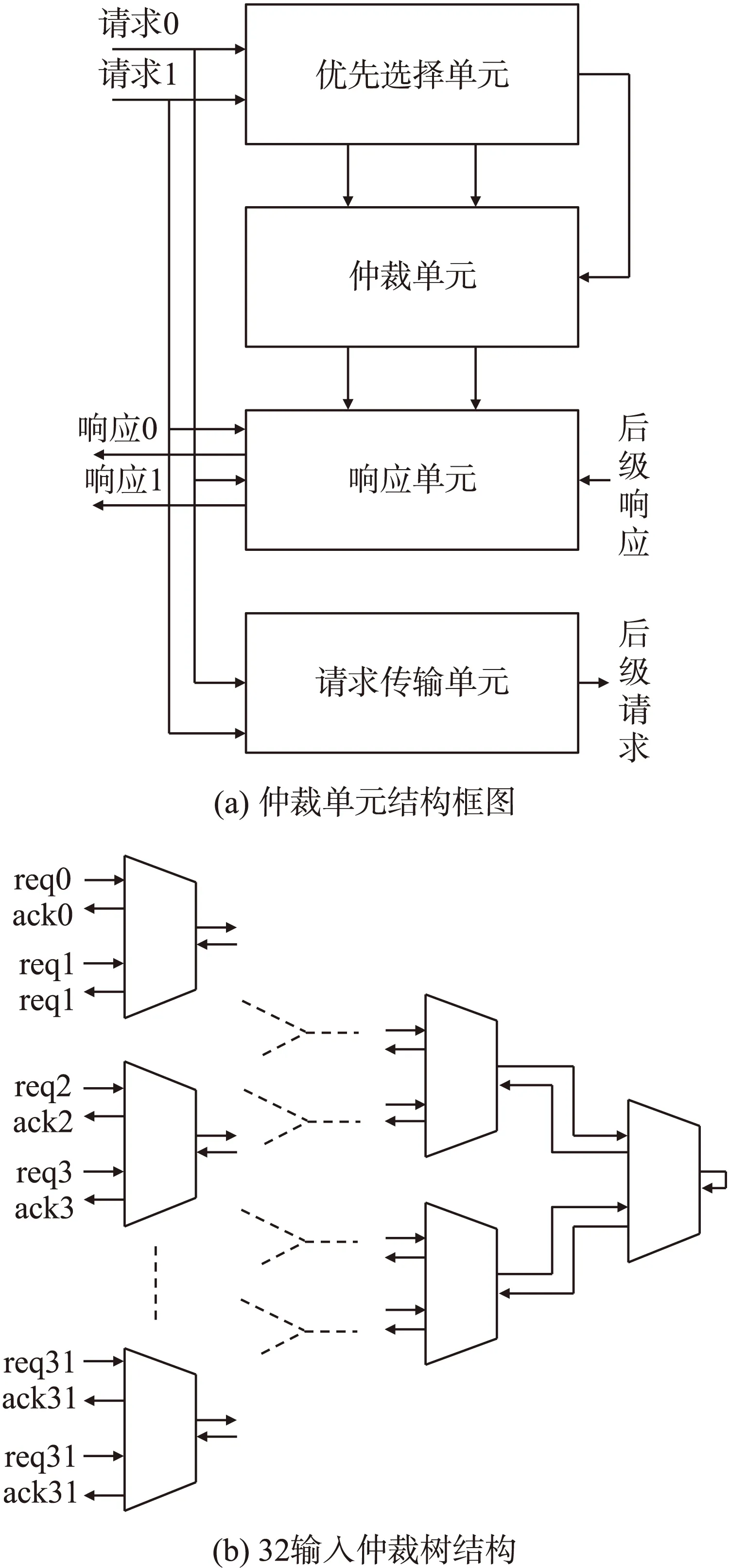
图6 仲裁单元结构框图和仲裁树结构
2.3 裁单元设计
本设计中的仲裁模块采用优先级可切换的“仲裁树”结构[15]。每个仲裁单元由四部分构成,如图6(a)所示,优先选择单元,仲裁单元,响应单元及请求传递单元。在树状结构中,每经过一层,请求信号就会被屏蔽掉一半,然后经过层与层之间的传递,最后交给顶层仲裁单元进行汇总。顶层单元汇总请求信息,不会再产生请求信号,产生应答信号,向下层逐层反馈,最终到达请求信号发生的初始节点。
由于本文设计了一个32×32的卷积阵列,因此设计32输入的仲裁树结构,就能够满足仲裁的需求,图6(b)显示了该仲裁树结构。
3 基于事件卷积的识别系统
AER卷积处理器的一个重要的应用是实现特征提取,构建目标识别系统。本文利用上述卷积处理器构建了一个基于事件的识别系统。该识别系统由两部分构成,特征提取部分和识别部分,如图7所示。

图7 识别系统结构图
特征提取层主要实现特征的提取,数据流可以概括为:输入事件→S1层→C1层。
S1层为卷积层,对输入事件进行卷积操作,使用本文所设计的卷积处理器模型。S1层采用Gabor函数计算的卷积核来提取特征,计算公式如(1)所示:
(1)式中:μ和υ分别代表像素中水平方向和垂直方向的坐标,λ为波长,θ参数指定了Gabor函数的方向,它的取值为0到360°,γ为长宽比空间纵横比,决定了Gabor函数形状,σ为有效的带宽。在特征提取层中共包含16个卷积模块,分别选取了3×3,5×5,7×7和9×9共4种尺度的卷积核,每种尺度下又分别选取了4种角度0°,45°,90°和135°。
C1层主要完成MAX操作,在传统的图像处理中,MAX算法常用来实现子采样的过程,在事件卷积过程中采用MAX操作也可以实现类似的“子采样”过程。这种操作是一种非线性的过程,每个卷积阵列都被划分成相邻的不重叠的区域,在该区域只有最大值会被保留下来。MAX操作进一步压缩了数据量,将更加显著的特征信息提取出来。
识别层主要包括了两个模块,TFS(Time-to-FirstSpike)转换模块和脉冲神经网络模块SNN(SpikingNeuralnetworks)。TFS模块可以将模拟量转化为脉冲发放的时间,在本文TFS编码策略中,刺激越强产生的脉冲越早,产生的脉冲较晚就表明刺激较弱。
脉冲神经网络模块来实现分类识别,脉冲神经网络把时间信息的影响也考虑在内,以脉冲序列的方式对输入数据进行处理,特别适用于AER事件的处理。本文采用简化的LIF神经元模型确保每个输出脉冲只能由兴奋性输入脉冲触发,而不会由亚阈值膜电势触发。当一个脉冲输入到达神经元时,该神经元的膜电势只能由上次更新后的时间和上次更新后的状态决定,因此只需要更新收到脉冲的神经元的电势。神经元可以组成多层的网络,当一个神经元收到前一层神经元来的脉冲时,该神经元的更新方式如下所示[16]:
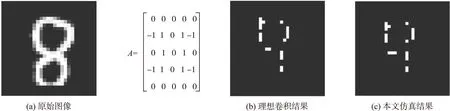
图8 “189”样本卷积结果对比
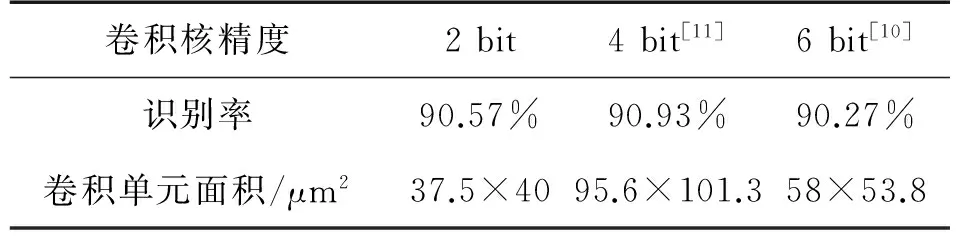
如果ti-tlastspike (2) 当Vmi≥Vthresh时Vmi←0,tlastspike←ti产生新的脉冲输出,同时该神经元的膜电势被复位到预设状态,式(2)中是ti第i个脉冲到达神经元的时间,tlastspike是当前神经元产生上一个脉冲的时间,trefr是神经元的不应期,Vmi是第i个脉冲输入后该神经元的膜电势,Il是漏电流,Cm是膜电容,ωi是突触权值,Vthresh是当前神经元的阈值电压。Tempotron学习算法是一种脉冲神经网络监督学习算法,该算法只需要调整较少的参数,就可以达到理想的训练识别效果,具有高效性。在本文提出的识别系统中,采用Tempotron学习算法来训练权值,并参照文献[17]来设置相关参数。 本文设计的事件卷积结构中采用了32×32 2bit的RAM阵列来存储卷积核,设计了7bit的计数器来实现累加,可以有效减小芯片的面积,在0.18μmCMOS工艺下每个像素单元的面积为37.5μm×40.0μm,卷积处理器于每个事件输入输出的最小的延时为 17ns,最大事件率为 12.5Meps。 为了分析其卷积效果,本文还对卷积效果进行了仿真验证。为了模拟AER图像传感器产生的事件序列,本文采用了频率编码(Rate-Coding)的方式将灰度图像转成AER事件序列,然后将每个事件编码成15bit的二进制数据,包括12bit的事件地址(x,y),2bit的卷积核选取标志位,一共可以选取4种卷积核,还有1bit代表事件的属性,“0”代表输入为正事件(ON),“1”代表输入为负事件(OFF)。 本文实验使用MNIST数据库进行验证。MNIST是一个手写数字样本集,该样本集包含10组数字的灰度图像,从数字0到9,每个图像的分辨率为28×28,共70 000幅图像。随机选取了第189个样本,采用频率编码方式,将其转成事件序列,产生了117个事件,然后将产生的事件转化成15bit的二进制数据,输入到本文设计的卷积处理器中。图8(a)显示了第189个样本的灰度图像,卷积核A用来提取垂直特征信息,经过卷积核A的卷积操作,图8(b)为该样本在Matlab上仿真的理想卷积结果,图8(c)显示了经过本文设计的卷积处理器处理的仿真结果。通过实验结果对比可得,本文设计的卷积结构对输入事件能够实现比较理想的卷积结果,如图8(c)所示很好的提取出了垂直特征。图9(a)显示了第200个样本的灰度图像,经过卷积核B的卷积操作,卷积核B用来提取水平方向特征信息,图9(b)和图9(c)分别显示了理想的卷积结果和本文的仿真结果。 图9 “200”样本卷积结果对比 最后,利用搭建的识别系统,分析了利用2bit的卷积核来提取特征时,系统的识别率。将原始样本被划分为训练样本和测试样本,将训练样本输入到该系统中,经过卷积层16个卷积模块的卷积操作,提取特征,利用Tempotron学习算法对脉冲神经网络的权值进行更新,最后利用测试样本,测试系统的识别准确率。本文通过实验分析了为卷积模块配置不同的卷积核精度时,该系统的识别率的变化,实验结果如表1所示。 表1 别率和面积对比 根据表1中的实验结果,本文采用2 bit的卷积核精度实现了90.57%的识别率。对比文献[10-11]中设计的卷积核精度,对于该识别系统,采用本文2 bit的卷积核的卷积处理器不仅能够获得与高位数相似的识别效果,而且卷积单元的面积远小于高位数结构。 本文根据事件型卷积处理器的工作特点,搭建了一个用于特征提取的小尺寸事件型卷积处理器。在该卷积处理器中包含了一个32×32的卷积像素阵列和一块2 bit的32×32卷积核RAM。本文提出的卷积处理器不仅使用低至2 bit的卷积核,还使用计数器替代了原有的加法器结构,芯片面积大幅缩减。经过仿真验证,该卷积结构可以根据输入事件的地址,将卷积核准确累加到卷积阵列中,实现特征提取。最后,本文搭建了一个识别系统,在该识别系统中配置了16个卷积模块来提取特征,使用脉冲神经网络来进行识别,并利用该识别系统验证了本文工作与传统卷积处理器使用的卷积核精度对该系统识别率的影响,实验结果表明本文提出的采用2 bit卷积核的小尺寸的卷积处理器可以有效完成特征提取。 [1] Lecun Y,Bottou L,Bengio Y. Gradient-Based Learning Applied to Document Recognition[J]. Proceedings of the IEEE,1998,86(11):2278-2324. [2] Garcia C,Delakis M. Convolutional Face Finder:A Neural Architecture for Fast and Robust Face Detection[J]. IEEE Tran Pattern Anal Mach Intell,2004,26(11):1408-1423. [4] Sivilotti M. Wiring Considerations in Analog VLSI Systems with Application to Field-Programmable Networks[D]. California Institute of Technology,Pasadena CA,1991. [5] Zamarreno R C,Linares B A,Serrano G T,et al. Multicasting Mesh AER:A Scalable Assembly Approach for Reconfigurable Neuromorphic Structured AER Systems[J]. IEEE Transactions on Biomedical Circuits and Systems,2013,7(1):82-102. [6] Zamarreno R C,Kulkarni R,Silvamartinez J,et al. A 1.5 ns OFF/ON Switching-Time Voltage-Mode lvds Driver/Receiver Pair for Asynchronous AER bit-Serial Chip Grid Links with up to 40 Times Event-Rate Dependent Power Savings[J]. IEEE Transactions on Biomedical Circuits and Systems,2013,7(5):722-731. [7] 闫石,徐江涛,高志远. 基于地址-事件表示的高速二值连通域标记方法[J]. 传感技术学报,2016,29(3):362-367. [8] Venier P,Mortara A,Arreguit X. An Integrated Cortical Layer for Orientation Enhancement[J]. IEEE Journal of Solid-State Circuits,1997(32):177-186. [9] Serrano-Gotarredona R,Serrano-Gotarredona T,Acosta-Jimenez A,et al. A Neuromorphic Cortical-Layer Microchip for Spike-Based Event Processing Vision Systems[J]. IEEE Trans Circuits SystI,Reg Papers,2006,53(12):2548-2566. [10] Camunas-Mesa L,Acosta-Jimenez A,Zamarrefio-Ramos C,et al. A 32×32 Pixel Convolution Processor Chip for Address Event Vision Sensors with 155 ns Event Latency and 20 Meps Throughput[J]. IEEE Trans Circuits Syst I,Reg Papers,2011,58(4):777-790. [11] Camunas-Mesa L,Zamarreno-Ramos C,,et al. An Event-Driven Multi-Kernel Convolution Processor Module for Event-Driven Vision Sensors[J]. IEEE Journal of Solid-State Circuits,2012,47(2):504-517. [12] Goldberg D H,Cauwenberghs G,Andreou A G. Probabilistic Synaptic Weighting in a Reconfigurable Network of VLSI Integrate-and-Fire Neurons[J]. Neural Netw,2001,14(6):781-793. [13] Park J,Yu T,Maier C. Live Demonstration:Hierarchical Address-Event Routing Architecture for Reconfigurable Large Scale Neuromorphic Systems[C]//IEEE International Symposium on Circuits and Systems,2011. [14] Serrano-Gotarredona R,Serrano-Gotarredona T,Acosta-Jimenez A,et al. On Real-Time AER 2-D Convolutions Hardware for Neuromorphic Spike-Based Cortical Processing[J]. IEEE Trans Neural Netw,2008,19(7):1196-1219. [15] Aung Myat Thu L,Do Anh T,Chen S. Adaptive Priority Toggle Asynchronous Tree Arbiter for AER-Based Image Sensor[C]//IEEE 19th International Conference on VLSI and System-on-Chip,2011:66-71. [16] Orchard G,Meyer C,Etienne-Cummings R,et al. HFirst:A Temporal Approach to Object Recognition[J]. IEEE Trans Pattern Anal Mach Intell,2015,37(10):2028-2040. [17] Zhao B,Ding R,Chen S. Feedforward Categorization on AER Motion Events Using Cortex-Like Features in a Spiking Neural Network[J]. IEEE Trans Neural Netw Learn Syst,2014,26(9):24-31. 卢成业(1989-),男,天津大学硕士研究生,主要从事视觉传感器研究,tju_lcx@tju.edu.cn; 高志远(1987-),男,博士后,主要从事CMOS图像传感器、视觉传感器研究,本篇论文通讯作者,gaozhiyuan@tju.edu.cn; 徐江涛(1979-),男,副教授,硕士生导师,主要从事 CMOS图像传感器和图像处理芯片研究,在相关领域主持国家自然科学基金、教育部博士点基金等项目。 A small Size Event-Based Convolution Processor for Feature Extraction* LU Chengye,GAO Zhiyuan*,XU Jiangtao This paper presents a small size event-based convolution processor for feature extraction of the data generated by dynamic vision sensors(DVS). It consists of a 32 pixel×32 pixel array,a RAM array that stores the convolution kernel,a left/right shift block,a control block,and an asynchronous event readout block. In order to reduce the area of convolution chip,a kernel RAM of 32×32 2 bit word is implemented to store the kernels. In each pixel unit,a 7bit counter is used to accomplish the accumulation instead of a traditional accumulator for smaller pixel size. In the 0.18 μm CMOS technology,each convolution unit occupies 37.5 μm×40 μm. The minimum latency between input and output event flows can be nearly 17 ns. Input event throughput can reach 12.5 Meps. Furthermore,a categorization system is established based on this convolution module,which consists of 16 assembled convolution modules for feature extraction and a spiking neural networks(SNN)for recognition. The experimental results show that the proposed convolution processor can achieve ideal convolution results. With the recognition system,the experimental results of MNIST show that the convolution module configured with 2 bit kernel weights resolution can also complete the feature extraction which achieves a recognition rate of 90.57%. dynamic vision sensors,address event representation,small chip size,convolution chip;MNIST;spiking neural networks 项目来源:国家自然科学基金项目(61604107,61434004) 2016-10-17 修改日期:2016-11-20 TN47 A 1004-1699(2017)04-0535-07 C:7230 10.3969/j.issn.1004-1699.2017.04.0094 实验结果分析

5 总结



(School of Electronic and Information Engineering,Tianjin University,Tianjin 30072,China)
猜你喜欢
中学生数理化·八年级物理人教版(2023年11期)2023-12-26 07:50:10
数学物理学报(2022年3期)2022-05-25 13:33:28
自然杂志(2021年6期)2021-12-23 08:24:46
现代装饰(2018年5期)2018-05-26 09:09:01
中成药(2017年12期)2018-01-19 02:06:54
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
电子设计工程(2015年12期)2015-02-27 12:06:20
汽车零部件(2014年1期)2014-09-21 11:41:11
小青蛙报(2014年1期)2014-03-21 21:29:39
