
适用于大规模信息网络的语义社区发现方法*
2017-04-17 01:39沈桂兰贾彩燕杨小平
计算机与生活 2017年4期
沈桂兰,贾彩燕,于 剑,杨小平
1.北京联合大学 商务学院,北京 100025
2.中国人民大学 信息学院,北京 100087
3.北京交通大学 计算机与信息技术学院,北京 100044
适用于大规模信息网络的语义社区发现方法*
沈桂兰1,2+,贾彩燕3,于 剑3,杨小平2
1.北京联合大学 商务学院,北京 100025
2.中国人民大学 信息学院,北京 100087
3.北京交通大学 计算机与信息技术学院,北京 100044
对节点带有内容的信息网络进行语义社区发现是新的研究方向。融合节点内容增加了算法的复杂度。提出了一种在线性时间内进行语义社区发现的标签传播算法,用LDA(latent Dirichlet allocation)主题模型表示节点内容,以节点内容相似度和传播影响力的乘性模型作为标签传播的策略,在归一化过程中,自然融合节点内容和网络结构信息,标签迭代过程中,采用节点与绝大部分邻居节点内容不相同才进行更新的策略,保证算法的运行效率。通过在不同规模的12个真实数据集上进行实验,以模块度和纯度作为度量标准,验证了算法在语义社区发现上的有效性和可行性。
语义社区发现;LDA主题模型;内容相似度;标签传播策略;传播影响力
1 引言
信息技术及互联网技术的发展,节点带有信息内容的复杂网络日益增多。根据节点所承载信息的类型,这些网络可以分为Web网络、邮件网络、引文网络、科学家合作网络、社交媒体网络等,人们将其统称为信息网络。信息网络是一种节点带有明显语义特征的现实复杂网络。信息网络在宏观上具有网络的链接关系属性,在微观上每个节点具有语义内容属性。节点内容属性的增加给社区发现带来了新的内涵。有意义的社区应是节点链接紧密,且内容一致的语义社区。语义社区发现是信息网络研究的良好扩充和发展,对于分析信息网络的拓扑结构,理解网络的功能,发现隐藏的规律和预测信息网络的行为有着非常重要的理论意义,在实际应用中对智能信息检索、个性化服务、社会推荐等信息管理领域的技术发展和应用具有深刻的促进作用。
目前,对信息网络语义社区进行发现的研究主要集中在以下三方面:(1)单纯利用网络拓扑结构;(2)单纯利用节点内容属性;(3)融合节点属性和网络拓扑结构。
第一类方式是目前语义社区发现的主流方法,基于紧密链接的节点趋于具有相同的兴趣爱好或主题内容的前提假设,以发现链接紧密的社区结构为目标。根据社区定义及其潜在原理,这些方法可分为以下几类:(1)以社区质量作为目标函数进行优化的方法,目前广泛采用的社区质量的衡量标准是2004年Newman等人[1]提出了模块度函数Q,可用贪心[2]、迭代启发[3]、谱优化[4]、模拟退火[5]等方案进行优化,从而发现社区;(2)节点聚类的方法,这类方法把社区看作节点相似度高的簇,采用谱图理论[6]或根据节点的结构相似度[7]进行聚类,从而发现社区结构;(3)图分割的方法,此类方法选取具有某些特性的边或者节点,并将其全部删除,以实现社区发现,选取策略包括边介数大的优先[4]、边聚集系数小的优先[8]等;(4)动态的方法,如采用标签传播[9]或马尔科夫随机游走[10]的方法进行社区发现。另外,也有一些研究将社区发现转化为统计推理问题[11-12]。基于网络拓扑结构进行社区发现的方法虽然总能发现链接紧密的社区结构,却忽略了节点内容对语义社区质量的改善作用,无法保证社区节点在语义上的一致性。
第二类方法则把社区看作节点相似度高的簇,基于节点的内容相似度矩阵发现社区。如Newman[13]采用自底向上的层次聚类方法发现社区,Nguyen等人[14]则采用LDA(latent Dirichlet allocation)模型从博客中提取社区,并对每个主题下的单词聚类,进而提取元社区。这类方法本质上可归结为文本聚类问题,可发现内容一致的节点集合,但忽略了节点间真实链接关系,无法保证社区在链接上的紧密性。
第三类方法基于节点内容有助于提高社区发现质量的假设,将节点内容和网络拓扑结构统一起来,采用属性图聚类的方法或概率组合模型的方法。如SA-Cluster算法[15]是一种属性图聚类的方法,该算法首先构建属性增广图,然后利用自动学习结构相似度和属性相似度共享率的邻居随机游走模型来计算属性增广图中两点之间的距离,算法以随机游走距离为基础进行图聚类,聚类后的结果是具有同质属性节点且紧密连接的子图,即语义社区。同样基于马尔科夫随机游走的策略,并结合局部扩充的思想,辛宇等人[16]采用LDA模型将节点内容进行语义空间量化,采用语义坐标的内积Eij=mi·mj作为节点di和节点dj的语义相似度。其中mi是节点di在语义空间中的坐标,可以通过di的Ni个关键字的加权均值形式表达,内积越大,节点语义的相似度越高,据此构造语义社会网络的加权邻接矩阵E,将其行向量归一化后加权邻接矩阵作为随机游走策略的一步转移概率矩阵E,从网络中选择语义影响力大的节点s作为出发点,经过l次转移后最终到达节点di的概率为,该概率值超过某个阈值,就将节点di与节点s划在同一个社区,由此检测语义社区。PCL-DC[17](popularity-based conditional link model-discriminative content)是概率组合模型方法的代表。该方法把链接模型和内容模型通过一个隐藏变量连接起来发现语义社区。
与前两类方法相比,这类方法综合考虑了节点的内容属性和网络结构两方面的特征,所划分的社区结构是基于节点内容相似性的,其划分的结果更具有内聚性。但因节点的语义信息内容多以文本分析为基础,通常会带来节点属性维数灾难,算法复杂度普遍高等问题,仅适合分析规模比较小的信息网络。
为实现链接紧密且语义一致的研究目标,在语义社区发现中融合节点内容属性和网络拓扑结构已成为一个研究趋势。亟待解决两个关键问题:一是节点内容属性和网络拓扑结构融合;二是如何保证算法的效率,使其适用于大规模的信息网络。
本文在稳定标签传播算法的基础上,用LDA主题概率模型对节点内容进行主题建模,根据节点内容的相似度进行标签传播,在传播概率的归一化过程中,将内容属性和网络的拓扑结构自然融合。此外,算法在标签传播策略中加入节点传播影响力的作用,保证语义社区链接紧密且语义一致的特征。在标签传播迭代时,设置条件更新策略,保证了算法的运行效率。以模块度和纯度作为标准评价,在12个不同规模的真实信息网络上进行实验,验证了本文算法在语义社区发现上的有效性和可行性。分析表明,与标签传播算法相比,本文算法虽然增加了节点内容属性,但没有增加算法复杂度,适用于大规模的信息网络。
2 节点内容的表示
本文主要考虑节点内容为文本的信息网络。经典的向量空间模型采用TF-IDF(term frequency-inverse document frequency)的方法表示文本内容,常具有高维稀疏性。采用LDA主题概率模型对节点内容进行主题建模,把节点的内容从词向量空间映射到主题向量空间,可以极大地降低内容属性维数。
2.1 LDA主题建模
LDA[18]是由Blei等人在2003年提出的一种三层贝叶斯概率模型,包含文档-主题-词三层结构,文档到主题服从Dirichlet分布[19],主题到词服从多项式分布。LDA主题模型的突出优点是具有清晰的层次结构,且LDA主题模型参数空间的规模与训练文档数量无关,适合处理大规模语料库。
图1为LDA概率模型图。其中M为文档集的个数;α和β分别是文档-主题概率分布和主题-单词概率分布的先验知识;Nm是第m个文档的单词数;T是主题数;Zm,n是第m个文档中第n个词的主题;Wm,n是第m个文档中的第n个词。在LDA中,集合中的每篇文档代表了潜在主题所构成的一个概率分布,而每个主题又代表了很多词汇所构成的一个概率分布。该模型可以对文档集进行建模,并可以将文档表示为由特定数目的潜在主题信息组成。
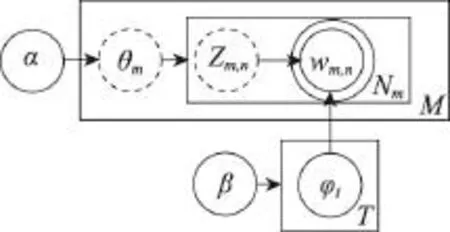
Fig.1 LDAprobability model图1LDA概率模型图
图1中的单圈实线圆表示固定值,由用户事先指定,双圈实线圆表示可观测的数据,单圈虚线圆表示隐藏参数。文档的隐藏参数需要通过概率推导求解,通常采用Gibbs采样法近似求解隐藏参数θ和φ。
LDA主题模型将潜在语义相同的词划归在同一主题下,降低了文本内容的表示维数。
2.2 节点的内容相似度
用LDA主题模型提取K个主题作为K维语义空间的基,节点的内容表示为主题的概率分布,用KL距离(Kullback-Leibler divergence,KL)度量两个节点的内容相似度,KL距离越小,表明两个概率分布的相似度越大。
假设两节点u和v内容的主题分布为P和Q,P(ti)表示节点u的文本内容在第i个主题上的概率,Q(ti)表示节点v的文本内容在第 j个主题上的概率,则两节点的内容相似度Sim(u,v)归一化形式表示为:
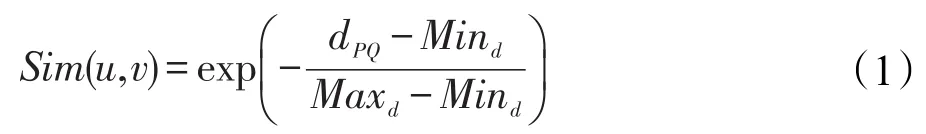
其中,Mind是所有节点对中KL距离的最小值;Maxd是最大值。因KL距离是非对称性的,故dPQ用下列形式表示:
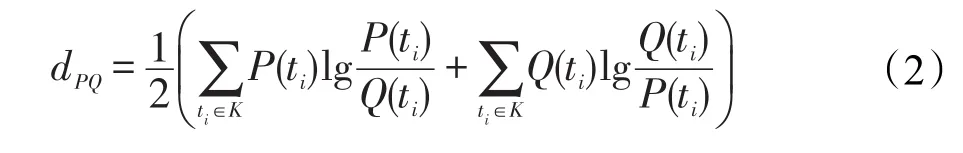
3 基于语义的标签传播
3.1 标签传播算法
标签传播算法LPA[9]是在线性时间O(m+n)内发现社区的经典算法,效率高,便于处理大规模的网络,但算法具有随机性的因素,社区发现的结果不稳定。LabelRank[20]是Xie等人2013年基于改进MCL(Markov clustering algorithm)提出的稳定的标签传播社区发现算法,算法以模块度作为目标函数,为每个节点存储、传播和排序标签,通过传播(propagation)、膨胀(inflation)、剪枝(cutoff)、条件更新(conditional update)4个算子,进行循环同步标签传播及标签更新,直到标签更新稳定时,将具有同一标签的节点划分为同一个社区。
算法用观察到邻居节点的概率初始化节点的标签分布:

传播算子表示为A×P,在传播过程中,每个节点向其邻居节点传播自己的标签分布。为了有效地控制标签的传播过程,使概率高的标签更易于传播,LabelRank在标签分布矩阵P上应用了膨胀算子Γin,并引入剪枝算子Φr,移除阈值低于r的标签,以便减少标签的存储空间,降低算法的空间复杂度,且算法性能对r的取值不明显,实现时无需调参。算法第四步是条件更新算子Θ,规定只有当节点标签和其邻接节点标签明显不同时,才进行标签更新。
LabelRank算法的每轮迭代运行时间和网络的边的数量m呈线性关系,时间复杂度为O(n+m+4tm),可近似看作O(n+m),运行效率较高,输出的社区结构具有稳定性。另外,LabelRank节点的标签更新只和局部信息相关,可以并行处理,适用于大规模的网络。
但LabelRank算法是基于拓扑结构进行社区发现的方法,节点的标签分布取决于其观测到邻居节点的概率,没有考虑节点与其邻居节点在语义上的相似性,无法规避链接结构中噪声的干扰。本文改进了LabelRank算法,在节点标签传播过程中,综合考虑节点的内容属性和网络的拓扑结构特性,便于挖掘链接紧密且内容一致的高质量语义社区。
3.2 基于内容相似度的标签传播策略
标签传播策略直接影响社区的划分结果。基于节点内容有助于提高社区发现质量的假设,在语义社区的发现中,标签按照节点的内容相似度进行传播比单纯地按照节点的链接结构进行传播更能发现语义一致的社区。首先,标签在传播时,易向内容与其相近的邻居节点传播。把节点的语义相似度作为节点标签的传播概率,考虑了节点的内容属性特征;其次,在将邻居节点标签的传播概率进行归一化过程中,自然地融入了网络的结构特征。以图2(a)所示的网络结构为例,分析不同的标签传播策略对节点分配标签的影响。
在LabelRank中,标签根据节点观测到邻居节点的概率进行传播。以节点4为例,从结构特性出发,将每条连接边的权重设为1,则节点4以同样的概率观测到邻居节点1、5、6、7,如图2(b)所示,其归一化的观测概率如图2(d)所示,节点4观测到每个邻居节点,即邻居节点向节点4传递标签的概率均为0.25,没有体现出邻居节点与节点4在内容上的差异。将节点对之间的语义相似度作为每条连边的权重,如图2(c)所示,其归一化的观测概率如图2(e)所示,节点1向节点4传播标签的概率0.08远小于节点6向节点4传播标签的概率0.34。显然,针对节点4,接收节点6的标签的概率大于接收节点1的概率,更加符合社区节点语义一致性的特征。
3.3 基于传播强度的标签传播策略
如前所述,节点标签分布在归一化过程中,融合了网络的结构特征,这只涉及邻居节点,即节点的度,因此融合的网络特征是局部的,没有全面考虑整个网络结构对标签传播的影响作用,易形成链接较为松散的社区结构。
节点的标签是否会向其他节点传播取决于它们是否有连接,但是传播的难易程度则取决于节点之间的语义相似度以及节点之间的距离。节点的亲近度[21]是该节点i到网络中其他所有节点 j距离之和的倒数,表示为式(4),其中n为网络中节点的数量,可度量节点在整个网络中的全局影响力。亲近度越大的节点在网络中的全局影响力越大,向其他节点传播的能力越强;反之,亲近度越小的节点在网络中的全局影响力越小,向其他节点传播的能力越弱。

显然,在标签传播过程中,全局影响力大的节点的标签显然更易于向全局影响力小的节点传播。这里定义了节点的传播影响力Inf(j,i),表示节点 j的标签向节点i的传播能力,值越大,表明节点 j的标签越容易传播给节点i。
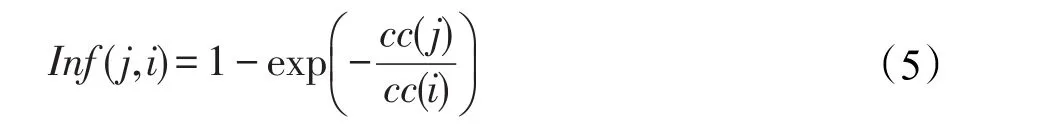
结合节点的内容相似度,用乘性模型定义节点 j对节点i的标签传播强度:
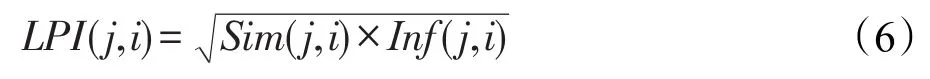
为便于叙述,本文将以节点的标签传播强度为传播策略的算法定义为simInfLPA,将以节点的内容相似度为传播策略的算法定义为simLPA。
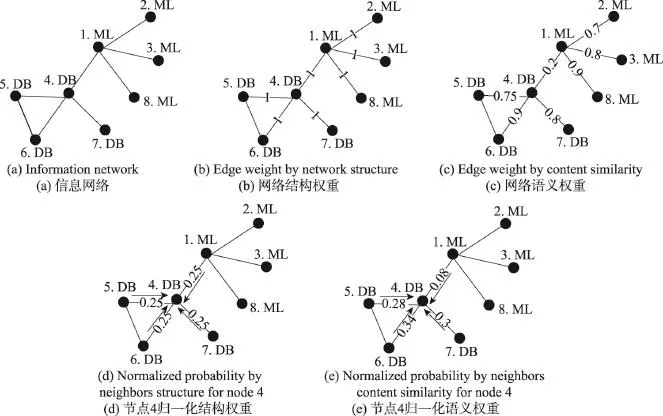
Fig.2 Influence of different label propagation strategies for an information network图2 信息网络中不同标签传播策略的影响示例图
在simInfLPA中,节点的初始化标签分布定义为观测到其邻居的标签传播强度的概率,即:
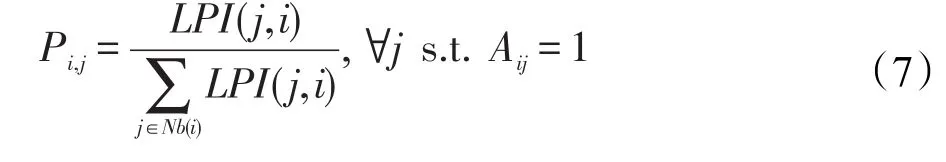
在传播过程中,每个节点按照传播强度向其邻居节点传播标签,为保证算法的稳定性,节点接收到的标签只有满足与绝大部分邻居节点在语义内容上不相似时,才进行标签的更新。该条件形式化为:
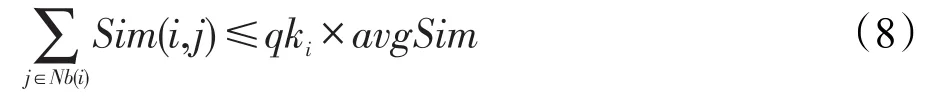
其中,Sim(i,j)是节点i和其邻居节点 j的内容相似度;avgSim是节点i与其所有邻居节点内容相似度的平均值;ki是节点i的度;q是[0,1]之间的参数。
标签更新函数如式(9)所示:
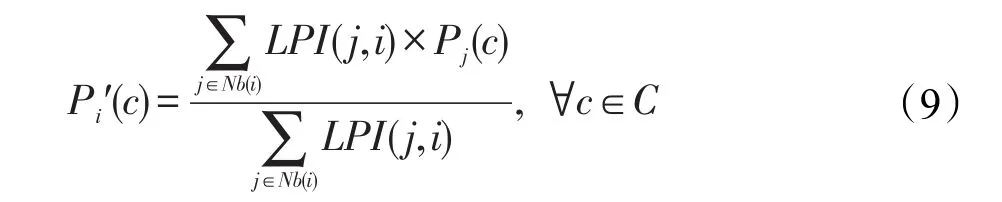
图2(a)所示的网络中各节点的亲近度如表1所示,节点之间的标签传播强度如表2所示。节点标签强度综合了网络的结构特性和节点的语义特性,从表2中显示的归一化标签分布数值来看,目标节点更易于接收高影响力且内容相似度高的源节点传播过来的标签。
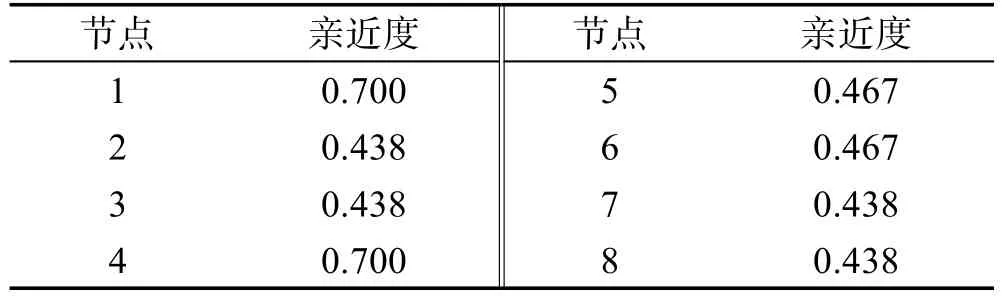
Table 1 Closeness for nodes表1 网络节点亲近度
4 评价标准
对信息网络的社区划分质量既要考虑链接结构的紧密性,又要考虑社区语义的一致性,用Newnan提出的经典的模块度Q函数[1]度量结构紧密性,具体定义为:
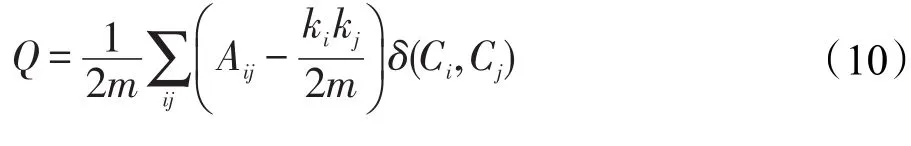
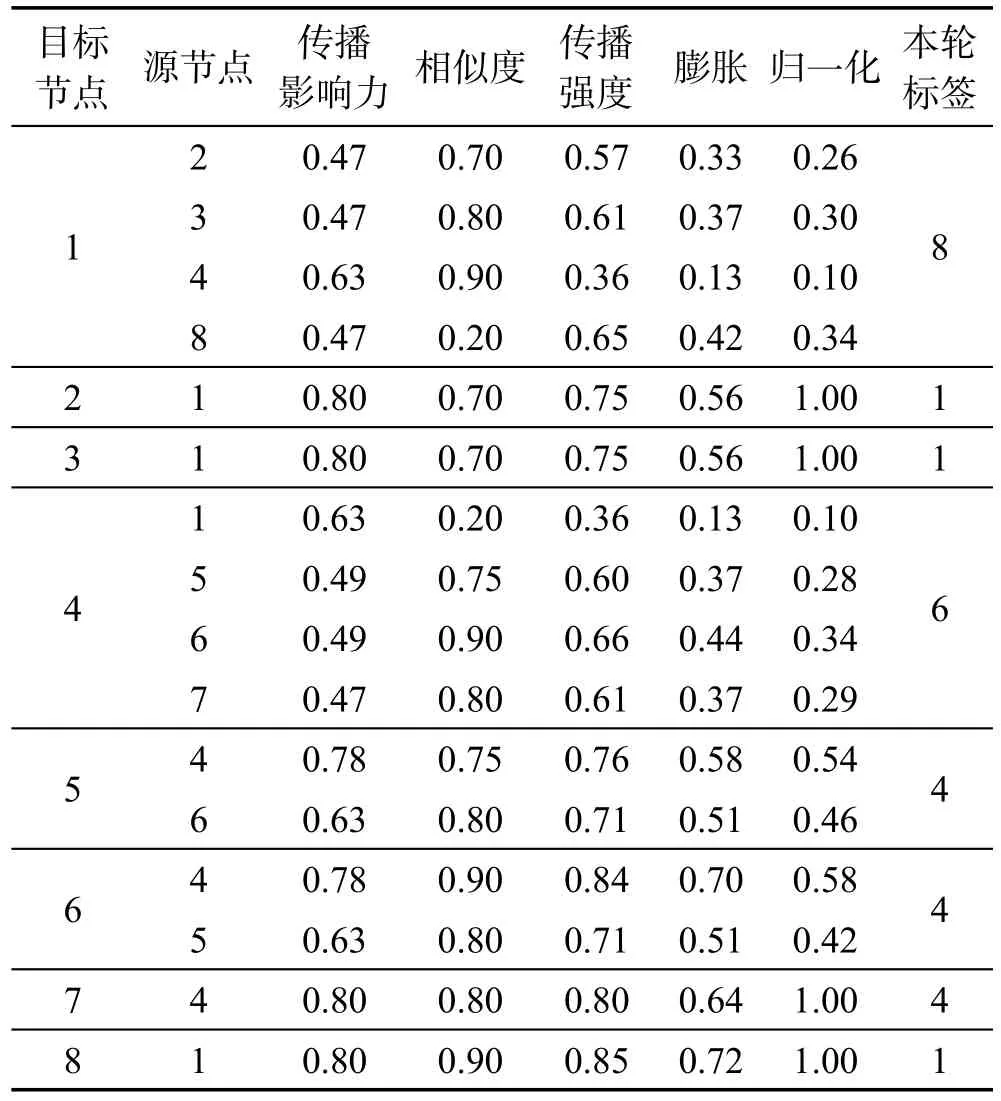
Table 2 Propagation intensity for labels表2 标签的传播强度
其中,m为网络中的边数;A是网络的邻接矩阵,Aij=0表示节点i和节点 j之间没有边;节点i的度表示为ki;节点i所在的社区为Ci,如节点i和 j在同一社区,则δ(Ci,Cj)=1,否则δ(Ci,Cj)=0,模块度的大小取决于网络的社区划分情况C,值越接近1,表明网络划分出的社区结构的质量越好。
度量社区语义的一致性,用文献中的评价方法[22],以真实社区群组作为参照,利用纯度(purity)对社区发现的结果进行评价。把信息网络数据集中真实社区集合G={G1,G2,…,GS}作为标准社区集合。算法生成的社区集合为C={C1,C2,…,CS},生成社区Ci的纯度定义为:
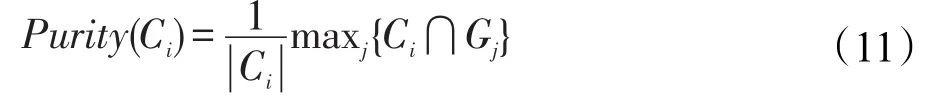
测试社区可能包含属于不同标准社区的样本,生成社区集合和各个标准社区集合求交,取最大纯度作为最终纯度。式(11)反映了生成社区中包含应划分在该社区的成员分布情况,纯度越高,说明越接近标准社区集合。最终社区的质量用社区的平均纯度来度量,即:
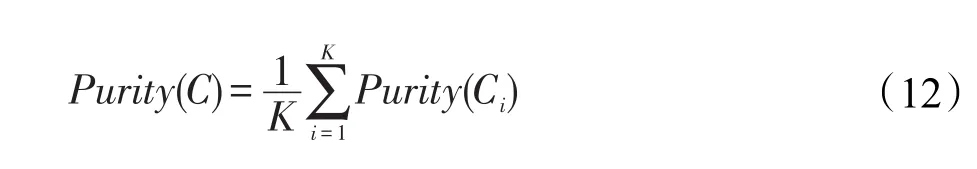
5 实验及结果分析
本文对不同规模的真实数据集进行了实验,分别验证了算法中膨胀因子的取值对社区度量标准的影响,不同的标签传播策略对社区质量的影响,不同膨胀因子下算法的时间性能分析以及simInfLPA与经典算法在社区评价标准上的对比分析。
5.1 数据集
选取包括Cora[23]、WebKB[24]、Wiki[24]和CiteSeer[23]在内的12个真实的数据集,为简化操作,把所有的数据集形成的网络均看作无向图。
WebKB是数据集包含了4所大学Cornell、Washington、Wisconsin和Texas计算机系5个类别的Web页面,剔除重复节点和互引的重复边,实验中共用到859个节点,1 388条边之间的引用关系。
Cora数据集是引文网络,涉及9大领域,其中有标注的文献30 144篇,引用关系714 266条,分别提取了Information Retrieval、Data Structure、Network、Programming、Database、Machine Learning共6个领域的文献及其引文关系,并剔除内容属性为空或重复的节点及其引用关系,构成最终的数据集。
Wiki数据集包括2009年10月7日至21日期间出现在属性列表中的维基百科中的文档,这些文档涉及19个类别,文档之间的超链接构成了网络的连边。
CiteSeer数据集是计算科学领域的引文网络,与Cora相同,节点表示文献,文献涉及6个子领域。该数据集具有438个独立的连通子图,节点的平均度为2.78,明显有别于常见引文网络。
上述数据集的基本统计信息如表3所示。
实验预处理阶段,对节点的文本内容进行LDA主题建模,为便于处理,将所有的数据集的主题数均设为30。
5.2 膨胀因子的取值分析
与MCL聚类算法相同,simInfLPA中膨胀因子的取值越大,算法收敛的速度越快,但是膨胀因子越大,形成社区的规模越小。为了验证膨胀因子的取值对社区的模块度和纯度的影响,本文选用了Cora中的Information Retrieval、Data Structure以及Web-KB中的Texas数据集对膨胀因子的取值进行分析。实验中,膨胀因子共取了12个值,包括1到10,考虑到膨胀因子在区间[1,2]中的取值敏感性,本实验增加膨胀因子取1.2和1.5的验证,实验结果如图3所示。
Table 3 Statistical information of datasets表3 各数据集统计信息
从图3中可以看出,针对社区结构比较明显的网络结构,像引文网络Information Retrieval和Data Structure,如图3(a)和图3(c)所示,膨胀因子在1附近取值,社区模块度即可达到最优值,社区模块度则随膨胀因子增加呈逐渐下降的趋势。而对Texas这样类似星型网络结构,当膨胀因子取值较小时,sim-InfLPA算法检测出来的社区结构并不明显,增加膨胀因子可提升社区模块度,如图3(e)所示;当膨胀因子小于4时,检测出来的社区模块度小于0.3,社区特征不明显;当膨胀因子大于4时,社区模块度则随膨胀因子的增加而缓慢增加。
在实际应用中,膨胀因子的取值影响了社区模块度的大小,需根据不同的网络结构选择合适的膨胀因子。但从实验结果分析来看,膨胀因子的取值对社区纯度的影响甚微,如图3(b)、(d)和(f)所示。膨胀因子小于2时,检测出的社区纯度有所波动;当膨胀因子大于2以后,任意网络结构的社区纯度都缓慢增加趋于稳定;当膨胀因子大于4以后,社区纯度对膨胀因子的取值不敏感,算法在膨胀因子的参数取值上具有鲁棒性。综合算法性能和膨胀因子对社区质量的影响,在实验中,统一将膨胀因子取值为4。
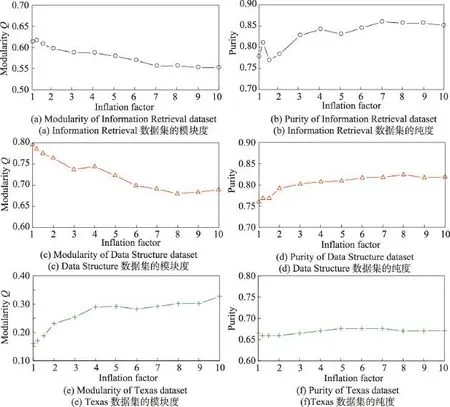
Fig.3 Results of 3 datasets with varying inflation factor图3 3个数据集中膨胀因子取值分析
5.3 不同标签传播策略的分析
LabelRank是以观测到邻居节点的概率进行标签传播,simLPA是以节点对之间的内容相似程度为概率进行标签传播,simInfLPA是以节点对之间的传播强度为概率进行标签传播。本组选取了Cora中6个领域的数据集和Wiki数据集,验证了不同的标签传播方式对在语义社区度量指标上的区别。在实验中,膨胀因子In取4,q取0.6,r取0.1,实验结果如图4和图5所示。
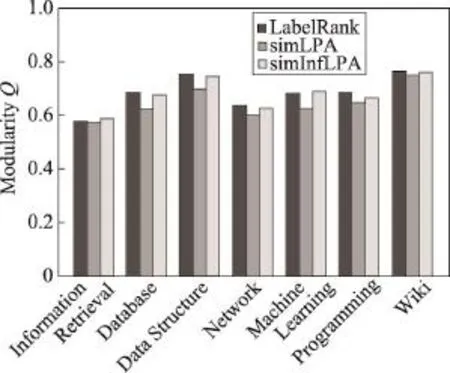
Fig.4 Comparison of modularity for different label propagation strategies图4 不同标签传播策略检测出社区的模块度比较
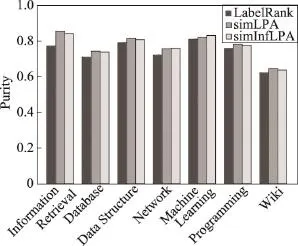
Fig.5 Comparison of purity for different label propagation strategies图5 不同标签传播策略检测出社区的纯度比较
从图4所示的实验结果可以看出,在社区结构紧密度上,LabelRank算法检测出来的社区在模块度的度量指标上整体要优于simLPA和simInfLPA,而simLPA检测出的社区模块度最低。因增加了传播影响力,simInfLPA则在simLPA的基础上提升了模块度,接近LabelRank的社区检测效果。在一些网络结构上,如Information Retrieval和Machine Learning数据集,社区模块度的质量甚至优于LabelRank的检测效果。
从图5的实验结果可以看出,在社区语义一致性上,simLPA算法检测出来的社区在纯度的度量指标上性能最好,LabelRank性能最差,simInfLPA的性能则均优于LabelRank方法,普遍接近simLPA的检测效果。在一些网络结构上,如Network和Machine Learning数据集,社区纯度的质量甚至优于simLPA的检测效果。
综合图4和图5所示的实验结果可以看出,在标签传播过程中,仅考虑节点的链接属性,发现的社区在语义一致性上性能较差;仅考虑节点对内容相似性,易打散网络结构,形成的社区较为松散;综合节点的内容相似性和传播影响力,即考虑传播强度,有助于平衡社区的紧密性和语义一致性,具有好的语义社区的检测效果。
5.4 算法性能分析
本实验选取了Wisconsin、Data Structure和Machine Learning数据集进行测试,通过比较simInfLPA和LabelRank算法的迭代运行时间来分析simInfLPA算法是否因标签传播过程中增加了节点的语义相似度和传播影响力而增加了标签算法的运行复杂度。
因LabelRank算法的运行效率和膨胀因子In的取值有关,针对每个数据集,测试了膨胀因子In在区间[1,10]中取不同值时LabelRank和simInfLPA的迭代收敛时间,具体的实验结果如图6所示。
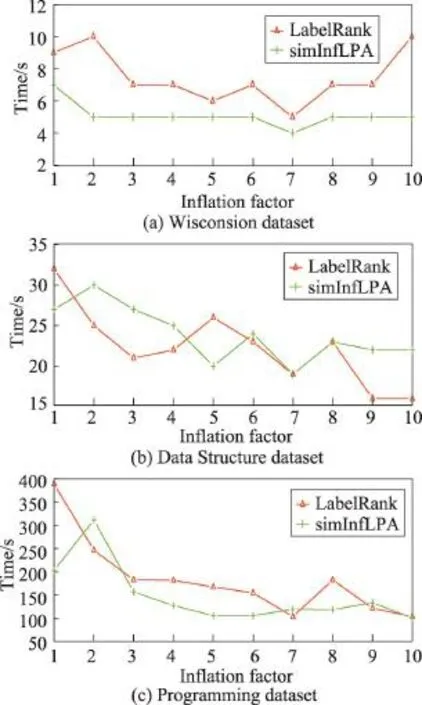
Fig.6 Running time with variation of inflation factor图6 不同膨胀因子取值时算法运行时间比较
从实验结果来看,相对LabelRank而言,simInf-LPA引入的节点的传播强度,没有增加算法运行的复杂度,在多数情况下还加速了算法的收敛,且算法迭代收敛时间趋于稳定,受膨胀因子的影响较小,具有鲁棒性。
5.5 信息网络社区发现的经典算法比较分析
本实验在表2所示的全体数据集上,选取了标签传播算法LPA[9]、马尔科夫随机游走算法WalkTrap[10]、基于模块度最大化的快速贪心算法[2]、稳定标签传播算法LabelRank[20]、文本聚类K-Means算法与simInfLPA算法进行对比,分析语义社区的划分质量。实验中,LPA算法运行10次,社区质量的度量指标取10次运行结果的平均值。WalkTrap中步长设置为4。KMeans聚类算法中的K值分别设置为每组数据集中真实的类别个数,如Data Structure数据集中K设为9。K-Means算法因不适于模块度的度量,本实验中仅进行社区纯度度量。在LabelRank和simInfLPA算法中,r取0.1,In取4,q取0.6。
从表4和表5中可以看出,simInfLPA在模块度的指标上,性能略差于基于拓扑结构的社区发现方法,但依然保证了语义社区链接紧密的结构特性。在纯度的指标上,除CiteSeer数据集,simInfLPA算法的性能都优于单纯的基于拓扑结构和单纯基于内容的社区发现算法。而在CiteSeer数据集上性能较差,因为该数据集缺失链严重,而simInfLPA中的传播强度采用乘性模型无法有效处理缺失链较多的网络。
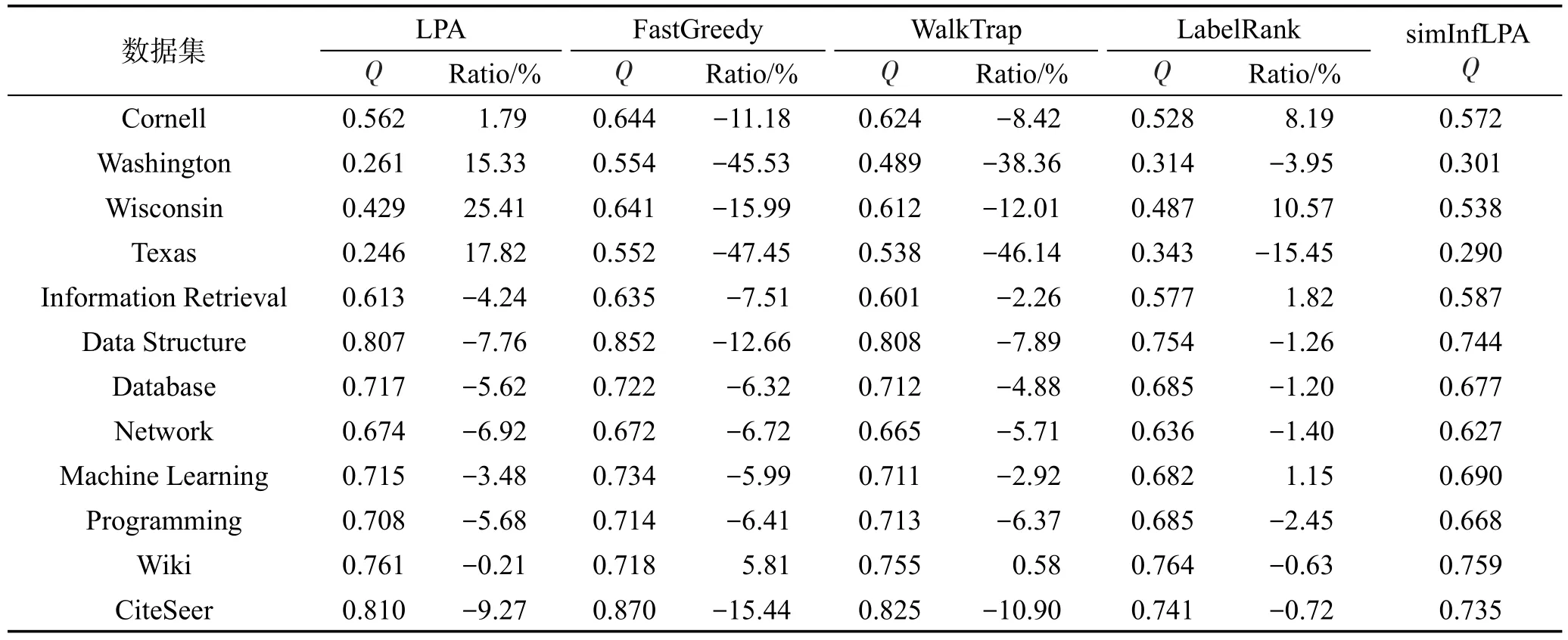
Table 4 Comparison of different community detection algorithms on modularity metric表4 不同算法在社区模块度上的比较结果
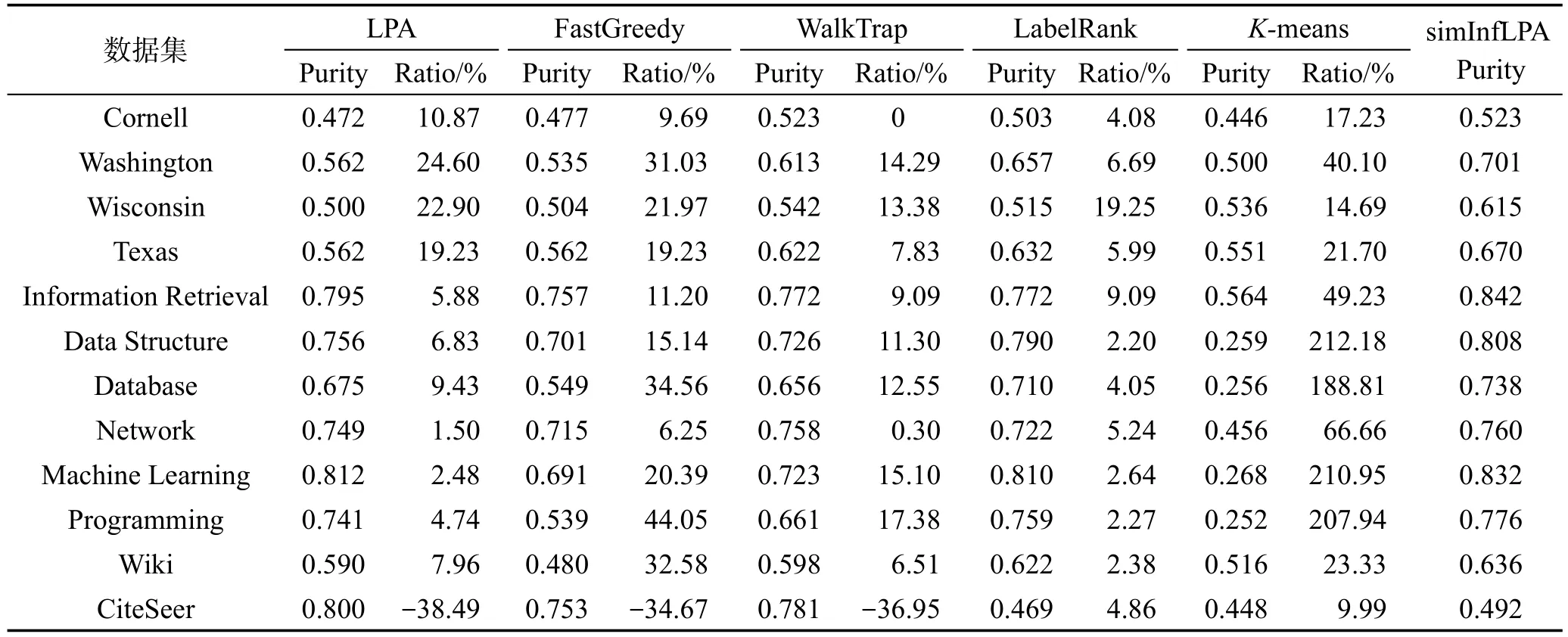
Table 5 Comparison of different community detection algorithms in purity metric表5 不同算法在社区纯度上的比较结果
5.6 实验总结
从上述四方面实验分析,得到如下结论:
(1)simInfLPA算法中,膨胀因子的取值对社区模块度有影响,对社区纯度影响甚微,考虑语义社区的特征,膨胀因子可设置为4。
(2)simLPA用节点对的内容相似度指导标签传播,可以极大地提高社区的纯度,却降低了社区的模块度指标。
(3)simInfLPA兼顾了社区模块度和纯度两个指标,更适合语义社区的发现。
(4)在面向信息网络进行语义社区发现时,sim-InfLPA相对于经典的基于拓扑结构和基于内容的方法更有效。
(5)simInfLPA在标签传播过程增加了节点对的内容相似度和传播影响力的因素,并没有增加原始标签传播算法的复杂度。
(6)对各类型的信息网络,除缺失链接较多的情况外,simInfLPA具有普适性。
6 结束语
在大规模信息网络的语义社区发现研究中,为解决节点内容属性维数灾难和融合节点内容属性增加算法复杂度两个挑战,采用LDA主题模型表示节点属性内容可以有效地降低节点的内容属性维数,利用线性时间的标签传播算法可以有效地控制算法的整体复杂度。本文在稳定的标签传播算法Label-Rank的基础上,用LDA主题模型表示节点的内容属性,融合节点的内容相似度和节点在网络中的影响力,改进了节点标签的传播策略,引入了标签的传播强度,有效地融合了节点的内容属性特征和节点之间的链接结构特征,可以发现结构紧密且内容一致的语义社区。同时与原始LabelRank算法相比,标签传播强度的引入,并没有增加算法复杂度,算法迭代只和节点的局部信息有关,可采用并行计算,适用于大规模的网络。
但标签传播需要依据网络原始的拓扑结构,传播的前提是节点之间有链接,本文利用乘法模型计算标签传播强度并没有很好处理节点之间链接缺失的情况,采用加法模型可避免缺失链带来的噪声,但如何设置调节加权参数是今后进一步研究的方向。
[1]Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69 (2):026113.
[2]Newman M E J.Fast algorithm for detecting community structure in networks[J].Physical Review E,2004,69(6): 066133.
[3]Blondel V D,Guillaume J L,Lambiotte R,et al.Fast unfolding of communities in large networks[J].Journal of Statistical Mechanics:Theory and Experiment,2008,10: P10008.
[4]Newman M E J.Modularity and community structure in networks[J].Proceedings of the National Academy of Sciences of the United States of America,2006,103(23):8577-8582.
[5]Massen C P,Doye J P K.Identifying communities within energy landscapes[J].Physical Review E,2005,71(4):046101.
[6]Donetti L.Detecting network communities:a new systematic and efficient algorithm[J].Journal of Statistical Mechanics: Theory and Experiment,2004,10:P10012.
[7]Xu Xiaowei,Yuruk N,Feng Zhidan,et al.SCAN:a structural clustering algorithm for networks[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Jose,USA,Aug 12-15,2007.New York:ACM,2007:824-833.
[8]Zhang Peng,Wang Jinliang,Li Xiaojia,et al.Clustering coefficient and community structure of bipartite networks[J]. Physical A:Statistical Mechanics and its Applications, 2008,387(27):6869-6875.
[9]Raghavan U N,Albert R,Kumara S.Near linear time algorithm to detect community structures in large-scale networks[J].Physical Review E,2007,76(3):036106.
[10]Pons P,Latapy M.Computing communities in large networks using random walks[J].Physical Review Letters, 2004,92(11):118701.
[11]Hastings M B.Community detection as an inference problem[J].Physical Review E,2006,74(3):035102.
[12]Karrer B,Newman M E J.Stochastic blockmodels and community structure in networks[J].Physical Review E,2011, 83(1):016107.
[13]Newman M E J.Detecting community structure in networks [J].The European Physical Journal B-Condensed Matterand Complex Systems,2004,38(2):321-330.
[14]Nguyen T,Phung D,Adams B,et al.Hyper-community detection in the blogosphere[C]//Proceedings of the 2nd ACM SIGMM Workshop on Social Media,Firenze,Italy,Oct 25-29,2010.New York:ACM,2010:21-26.
[15]Zhou Yang,Cheng Hong,Yu J X.Graph clustering based on structural/attribute similarities[J].Proceedings of the VLDB Endowment,2009,2(1):718-729.
[16]Xin Yu,Yang Jing,Xie Zhiqiang.A semantic overlapping community detecting algorithm in social networks based on random walk[J].Journal of Computer Research and Development,2015,52(2):499-511.
[17]Yang Tianbao,Jin Rong,Chi Yun,et al.Combining link and content for community detection:a discriminative approach [C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Pairs,Jun 28-Jul 1,2009.New York:ACM,2009:927-936.
[18]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003,3:993-1022.
[19]Galligan M C,Saldova R,Campbell M P,et al.Greedy feature selection for glycan chromatography data with the generalized Dirichlet distribution[J].BMC Bioinformatics,2013, 14(1):155.
[20]Xie Jierui,Szymanski B K.LabelRank:a stabilized label propagation algorithm for community detection in networks [C]//Proceedings of the 2nd IEEE International Workshop on Network Science,New York,Apr 31-May 1,2013.Piscataway,USA:IEEE,2013:138-143.
[21]Sabidussi G.The centrality index of a graph[J].Psychometrika,1966,31(4):581-603.
[22]Strehl A,Ghosh J,Mooney R.Impact of similarity measures on Web-page clustering[C]//Proceedings of the 17th National Conference on Artificial Intelligence,Austin,USA,Jul 30-Aug 3,2000.Menlo Park,USA:AAAI,2000:58-64.
[23]Cora research paper classification[EB/OL].(2015-04-13) [2016-01-07].http://www.datatang.com/data/28850.
[24]LINQS[EB/OL].(2015-10-12)[2016-01-07].http://linqs. umiacs.umd.edu/projects/projects/lbc/index.html.
附中文参考文献:
[16]辛宇,杨静,谢志强.基于随机游走的语义重叠社区发现算法[J].计算机研究与发展,2015,52(2):499-511.

SHEN Guilan was born in 1979.She is a Ph.D.candidate at Renmin University,associate professor at Beijing Union University,and the member of CCF.Her research interests include semantic community detection and Web text mining,etc.
沈桂兰(1979—),女,河南信阳人,中国人民大学信息学院博士研究生,北京联合大学副教授,CCF会员,主要研究领域为语义社区发现,Web文本挖掘等。

JIA Caiyan was born in 1976.She received the Ph.D.degree from Institute of Computing Technology,Chinese Academy of Sciences in 2004.Now she is an associate professor and Ph.D.supervisor at Beijing Jiaotong University. Her research interests include data mining,complex network analysis and bioinformatics technology,etc.
贾彩燕(1976—),女,湖南人,2004年于中国科学院计算技术研究所获得博士学位,现为北京交通大学副教授、博士生导师,主要研究领域数据挖掘,复杂网络分析,生物信息学等。

YU Jian was born in 1969.He received the Ph.D.degree from Peking University in 2000.Now he is a professor and Ph.D.supervisor at Beijing Jiaotong University.His research interests include machine learning,computational intelligence and data mining,etc.
于剑(1969—),男,山东人,2000年于北京大学获得博士学位,现为北京交通大学教授、博士生导师,主要研究领域为机器学习,计算智能,数据挖掘等。

YANG Xiaoping was born in 1956.He received the Ph.D.degree from Renmin University in 2003.Now he is a professor and Ph.D.supervisor at Renmin University.His research interests include Web text mining,E-government and information system engineering,etc.
杨小平(1956—),男,福建福州人,2003年于中国人民大学获得博士学位,现为中国人民大学信息学院教授、博士生导师,主要研究领域为Web文本挖掘,电子政务,信息系统工程等。
Semantic Community DetectionAlgorithm for Large Scale Information Network*
SHEN Guilan1,2+,JIACaiyan3,YU Jian3,YANG Xiaoping2
1.Business School,Beijing Union University,Beijing 100025,China
2.School of Information,Remin University,Beijing 100087,China
3.School of Computer and Information Technology,Beijing Jiaotong University,Beijing 100044,China
+Corresponding author:E-mail:s_gl@163.com
Information network is a kind of complex network with semantic information.The semantic community detection of information network is a new research direction.The complexity of community detection algorithm is increased by considering the node content.Therefore this paper proposes a label propagation algorithm which is suitable for dealing with large scale information network in linear time.Firstly,the latent Dirichlet allocation topic model is used to represent the node content.Secondly,the multiplicative model of content similarity and propagation influence is taken as the label propagation strategy.And the content and the network topology are combined naturally in the normalization.Thirdly,the algorithm updates the node label while the node and the vast majority of neighbors are not the same.Extensive experiments on 12 real-world datasets with varying sizes and characteristics validate the proposed method outperforms other baseline algorithms in quality.
semantic community detection;latent Dirichlet allocation topic model;content similarity;label propa-gation strategy;influence propagation
10.3778/j.issn.1673-9418.1603050
A
TP181;TP391.1
*The National Natural Science Foundation of China under Grant Nos.71572015,71271209(国家自然科学基金);the New Start Project of Beijing Union University under Grant No.Zk10201506(北京联合大学新起点项目).
Received 2016-02,Accepted 2016-04.
CNKI网络优先出版:2016-04-28,http://www.cnki.net/kcms/detail/11.5602.TP.20160428.0914.004.html
SHEN Guilan,JIA Caiyan,YU Jian,et al.Semantic community detection algorithm for large scale information network.Journal of Frontiers of Computer Science and Technology,2017,11(4):565-576.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
中国卫生(2015年12期)2015-11-10
