
热门B2C购物门户用户评论质量影响因素分析研究
2017-04-14 00:59付晓东刘利军
计算机应用与软件 2017年3期
刘 杰 付晓东 刘 骊 刘利军
(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
热门B2C购物门户用户评论质量影响因素分析研究
刘 杰 付晓东*刘 骊 刘利军
(昆明理工大学信息工程与自动化学院 云南 昆明 650500)
用户的在线评论可以有效地帮助用户选择在线商品或服务。然而,热销商品的用户评论数量极其庞大,同时,这些评论的质量参差不齐。因此,评估评论质量并挑选出高质量的评论变得尤为迫切。目前网站采取邀请用户人工标注的方式评估评论的质量,需耗费用户大量的时间和精力。为解决这个问题,提出了一个自动化评估评论质量的方法。该方法通过应用基于评论与评论者两类特征的支持向量机(SVM)分类器实现。在国内著名在线购物网站京东的评论数据上测试了提出的方法。实验结果表明评估识别高质量评论的准确率达到了87.5%。通过实验发现,能够表征评论信息量的词语数量和语句数量特征很好地评估了评论质量。而由于来自用户对商品的反馈信息的贫乏,能够表征用户反馈的有用性投票数量和回复数量特征并不能很好地评估评论质量。在同时结合评论和评论者特征的基础上,评估评论质量的表现最佳。
在线评论 评论质量 支持向量机(SVM)
0 引 言
越来越多的网站支持用户发表评论来分享他们的观点和经验。评论的价值在于其中所包含的描述商品质量与属性信息。文献[1-2]研究表明评论能够有效地帮助用户选择在线商品或服务。用户通常在购买商品后就会发表评论。因此,热销商品的评论会达到成千上万条。然而,由于缺乏对评论内容和格式的明确限制,评论的质量也是参差不齐。例如,一些用户在评论中虚夸或诋毁一些商品,一些用户发表一些与商品无关的评论。用户很难快速地从大量的质量不一的评论中获取有用信息。因此,网站迫切需要对评论质量进行评估并挑选优质的评论以提升用户的在线体验。大多数网站通过要求用户人工标记评论质量来解决这个问题。然而,由于用户不愿意花费大量的时间和精力去人工标记评论质量,很多评论并没有用户的手动标记结果。在文献[3]中还提到了人工手动标记评论质量的其他缺点,如标注的不平衡偏向,优胜循环和早循环偏向。
评论质量的评估越来越受到重视。文献[4]为了实现对亚马逊的评论质量自动评估,主要考量了元数据特征和词典句法特征等。通过实验发现,评论的长度和评分级别是影响评估评论质量的主要特征。文献[5]用类似的方法研究了在线论坛的评论质量评估,并发现了词汇特征对评论质量评估影响最大。文献[6]针对亚马逊网站的图书商品,通过比较普通评论与最佳评论之间的差距来评估评论的质量。文献中的最佳评论是由一些评论中的高频词汇和表征典型特征的词汇组成的评论。文献[7]通过结合经济理论分析和主观观点分析去评估亚马逊网站的评论质量,并发现主观观点分析能够有效地帮助评估评论的质量。文献[8]将用户在社交网络中的属性列入了评估评论质量的特征依据,发现用户社交特征能够提升评论质量评估的效果。文献[9]通过人工的有用性标注来评估评论质量。文献[10]将商品类型作为评估评论质量的特征依据,发现对于搜索类商品,评论的深度对于评论质量评估的影响效果要胜于其对体验性商品评论质量的评估。文献[11]运用复杂网络理论分析了评论有用性与用户需求的关系,其基础仍然是评论文本的语义。文献[12]研究了智能移动设备上的评论内容(被定义为轻型评论)与传统评论的异同点,得出文本中的情感信息对评论的质量影响最大。
现阶段另一方面的研究则集中在低质量的评论检测。文献[13]通过语言学和心理学特征检测发表虚假观点的欺诈评论。文献[14]从欺诈者的角度分析了虚假评论的特征属性。文献[15,16]通过定义的非正常模式检测由欺诈团体发布的虚假评论。文献[17]通过特定时间模式来识别单独的虚假评论。
在现有的评论研究领域,对于评论质量评估方面,研究大都局限于考虑评论内容本身的词典或语义等属性特征,并且存在评论内容特征考虑不全或太过冗杂的情况。而对于低质量评论检测方面,研究则局限于考虑评论者的行为属性特征。
本文提出了同时考虑评论内容本身和评论者两方面属性特征的,基于支持向量机(SVM)分类器的自动化评论质量评估方法。而且全面考虑了评论内容本身的各种属性特征,对于冗杂的属性特征通过主成分分析进行了精简。本文还在京东网站的数据上测试了提出的方法评估评论质量的效果。并分析了不同属性特征在评论质量评估过程中的效果。
1 属性特征定义
为了实现基于不同属性特征的评论质量的自动化评估,并分析不同属性特征在评估评论质量过程中的效果,本文从评论和评论者两方面考量属性特征。
1.1 评论特征
评论特征是指与评论相关的属性特征,包括与评论文本内容独立的元数据以及通过文本分析后得到的评论文本数据。

时间间隔TP(Time Period):用户选购商品的时间以及发表评论的时间均被记录在网站内。这里定义用户发表评论与购买商品之间的时间差作为时间间隔TP。时间间隔TP的数值为天数的差值。这表明,时间间隔TP数值越大,用户发表评论与购买商品之间间隔的时间越久。通常,用户在购买并体验商品一段时间后,才会发表出高质量的评论内容。
有用回复数值HRN(Helpful votes and Reply Numbers):有用性投票(helpful votes)是用户在阅读评论后,认为评论是有用高质量的,并对评论质量手动标注为有用的行为。其数值是标注评论为有用的用户的数量。因此,有用性投票可以作为表征评论质量的一个属性特征。回复评论(reply numbers)是用户在阅读评论后,对评论内容感兴趣,予以回复互动的行为。其数值为评论获得回复的数量。因此,评论回复数量也可以作为表征评论质量的一个属性特征。
然而,由于手动标注需要耗费用户大量的时间和精力,大量的评论并没有获得任何有用性投票或回复数量。在京东数据集中,只有38%的评论获得了用户的有用性投票。而且,只有32%的评论获得了用户的评论回复。评论的有用性投票和回复数量的分布图分别如图1和图2所示。
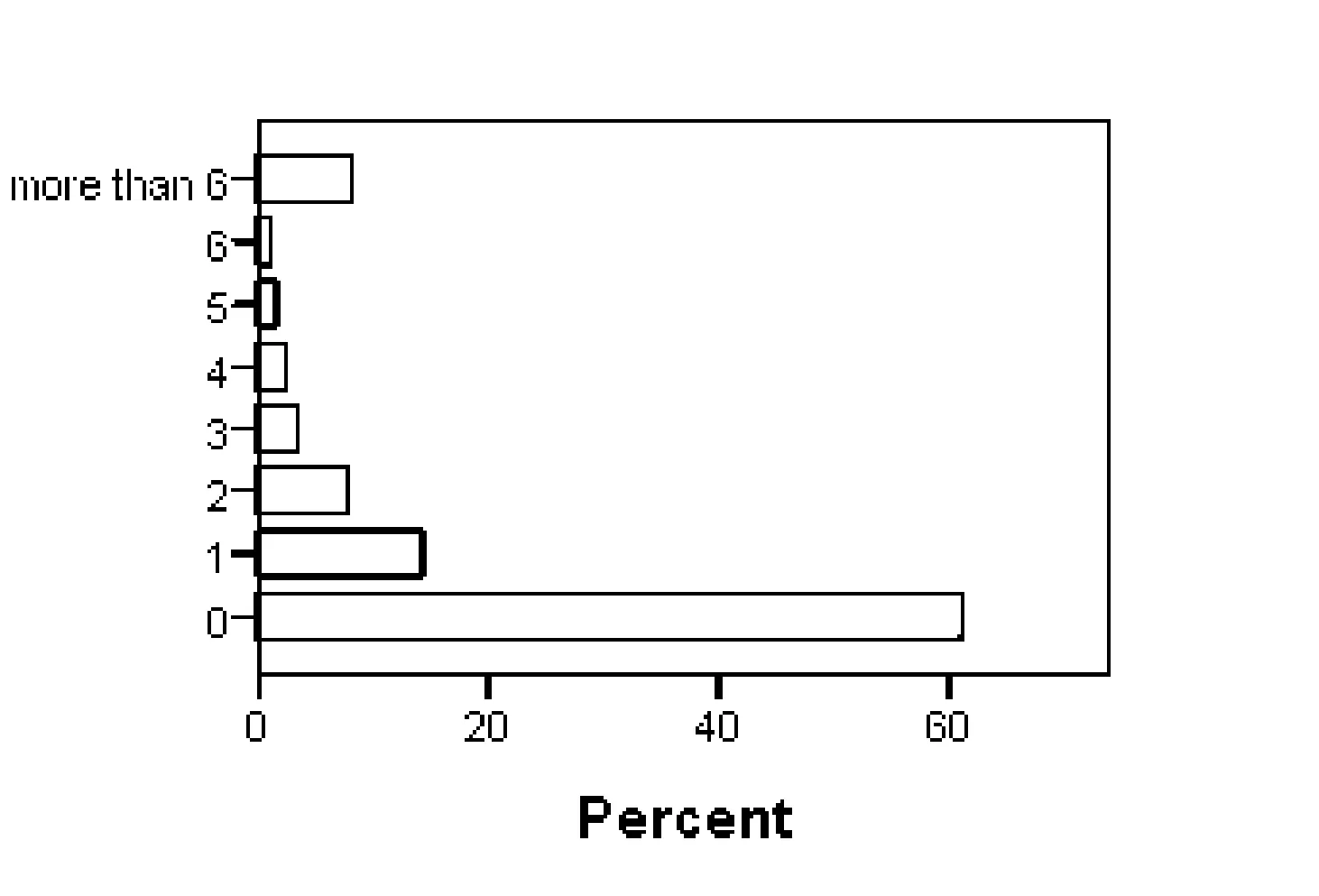
图1 有用性投票分布图

图2 回复数量分布图
据此,猜测有用性投票数量和回复数量具有关联性,并通过在实验数据集上进行一个关联测试来验证此猜测。测试结果如表1所示,该测试结果表明了有用性投票和回复数量具有关联性。对于已经获得有用性投票或评论回复的评论,其有用性投票或回复数量数值大多数都未超过6。由于有用性投票和回复数量具有关联性,而且数值都较小,定义有用性投票与回复数量的和值作为有用回复数值HRN。
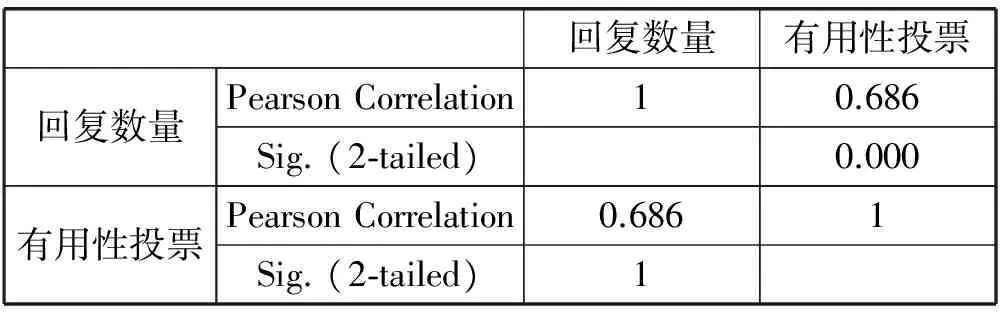
表1 有用性投票与回复数量的关联性测试
词语与语句数量WSN(Words numbers and Sentences Numbers):词语数量是指评论中包含的各种词语的数量总和。词语种类包括名词、形容词、动词和副词等,词语和语句数量属性特征的具体定义及含义如表2所示。语句数量是指评论中包含的语句数量。评论中包含的词语和语句数量越多,用户从中能获取的信息也越多。

表2 词语数量和语句数量属性特征

续表2
由于统计类型数据是由句法类型数据计算得到的,统计型数据与句法型数据具有一定的关联性。为了消除这些属性特征之间的关联性,使其变得独立,对这些属性特征进行主成分分析,经过分析后的主成分之间具有独立性。统计型和句法型数据属性特征的主成分分析结果如表3所示。由表可知,统计型和句法型属性特征经过主成分分析得到两个主成分。其中,第一成分为不同词性词语数量与语句数量成分,第二成分为叹词数量成分。然而,在数据集中,超过95%的评论中并不包含任何叹词。因此,我们省掉第二成分(叹词数量成分)对评估评论质量的影响。对于第一成分(不同词性词语数量和语句数量成分),词语数量WN包含了不同词性词语(如名词数量MN,形容词数量AN和动词数量VN等)。据此,定义词语数量WN与语句数量SN的和作为词语与语句数量WSN的值。
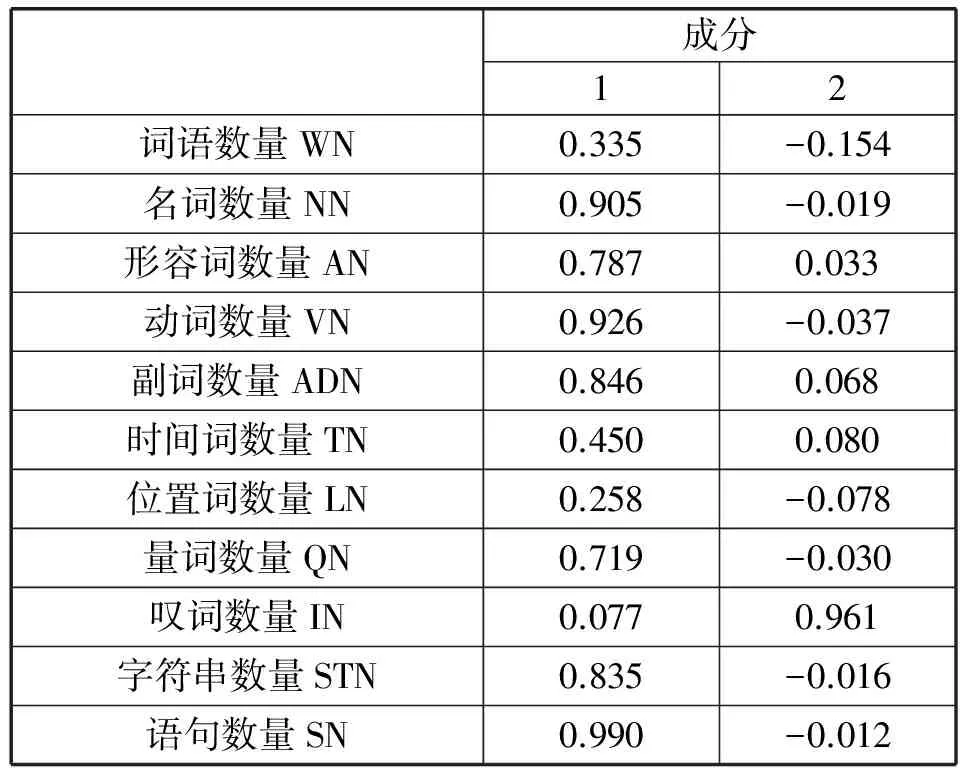
表3 成分矩阵
1.2 评论者特征
评论是由评论者(用户)发表的,因此,评论的质量也与评论者有着关联性。为了更好地评估评论质量,需要同时考量评论和评论者两方面属性特征。评论者特征是指与评论者(用户)本身有关的属性特征。
2 数据集
为了测试基于评论和评论者属性特征的评论质量评估效果,并分析不同特征在评估过程中的重要性,本文爬取了京东购物网站的用户商品评论数据。数据的采集是在开源爬虫软件Heritrix的辅助下实现的。首先将包含评论的页面以HTML的格式保存下来,然后通过HTMLParser解析页面中包含的评论相关的内容,并将其保存到SQL Server数据库中。共采集了来自499 253 件商品的用户评论,其中,由14 250名用户对6 022件商品发表的21 501条评论被京东网站标记为优质评论。
对于每一条评论,获取以下相关数据:
(1) 用户对商品的评分,用于计算评分SR
(2) 用户购买商品以及发表评论的时间,用于计算时间间隔TP
(3) 评论获得的有用性投票以及回复数量,用于计算有用回复数值HRN
(4) 评论本身的文本内容,用于计算词语与语句数量WSN、情感词语数量SWN和描述性词语数量DWN
(5) 用户评价的商品的优点以及缺点
(6) 用户对商品标注的标签
(7) 商品的类别以及名称(包括商品编号)
(8) 用户名(包括用户编号)以及用户级别,用于计算用户级别UL
为了获得评论文本内容的统计型和句法型数据,通过ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)对评论文本进行分词处理。评论内容的情感词语分析是基于一个包含情感词语集的HowNet语料库实现的。在该语料库中,包含积极与消极的感情,以及积极与消极的评论共四类情感词语。这里从以下两个维度分析评论的情感:积极的情感词语(包含积极的感情和评论)与消极的情感词语(包含消极的感情与评论)。
为了分析评论文本中的描述性词语,由以下三部分词语集组成描述词语库:用户评定的商品优缺点文本中包含的名词、用户标注的商品标签文本中包含的名词以及评论文本内容中的高频名词。这些名词描述了商品的品质特征以及其他用户关注的商品属性。
3 评论质量评估
评论质量的评估是通过基于评论和评论者属性特征的支持向量机(SVM)分类器实现的。支持向量机(SVM)的基本思想是:对于线性不可分的情况,通过定义适当的核函数,将低维空间线性不可分的样本转化为高维特征空间,使其线性可分。它是基于结构风险最小化理论之上,在特征空间中构建最优分割超平面,使得学习器得到全局最优化。核函数的引入,避免了“维数灾难”,减小了计算量,可以有效处理高维输入。支持向量机避免了局部极小点,并能够解决过学习问题,具有良好的推广性和较好的分类精确性。
在数据集中,有部分评论被京东网站标记为优质的。本文假定被京东标记为优质的评论确实为高质量的评论,而未被京东标记为优质的评论不是高质量的评论。在此前提下,评估京东网站的评论质量转变为判断评论是否高质量的分类任务。
根据之前章节对评论和评论者属性特征的定义,将每一个评论都转化为一个基于评论及评论者属性特征的向量。并将未在定义时标准化取值范围为0至1的属性特征数值标准化为0至1的取值范围。

通过网格搜索获取参数C(惩罚系数,控制最大分类间隔和最小分类错误率之间的平衡。C越大,表示主要把重点放在减少分类错误上;C越小,表示主要把重点放在分离超平面上,避免过学习问题)和γ(径向基核函数的一个参数,影响SVM性能优劣)的最优值并执行了十折交叉验证。利用训练获取的模型进行测试与预测。
4 实验结果
在不同属性特征组合情况下,评论质量评估交叉验证的平均准确率如表4所示。从表中结果可以得到,词语和语句数量WSN属性特征在单个属性特征评估评论质量的过程中表现最佳。说明了评论文本中包含的信息量最能直接影响评论质量的评估。在单个属性特征评估评论质量的过程中,评分SR、情感词语数量SWN和用户级别UL也表现良好。
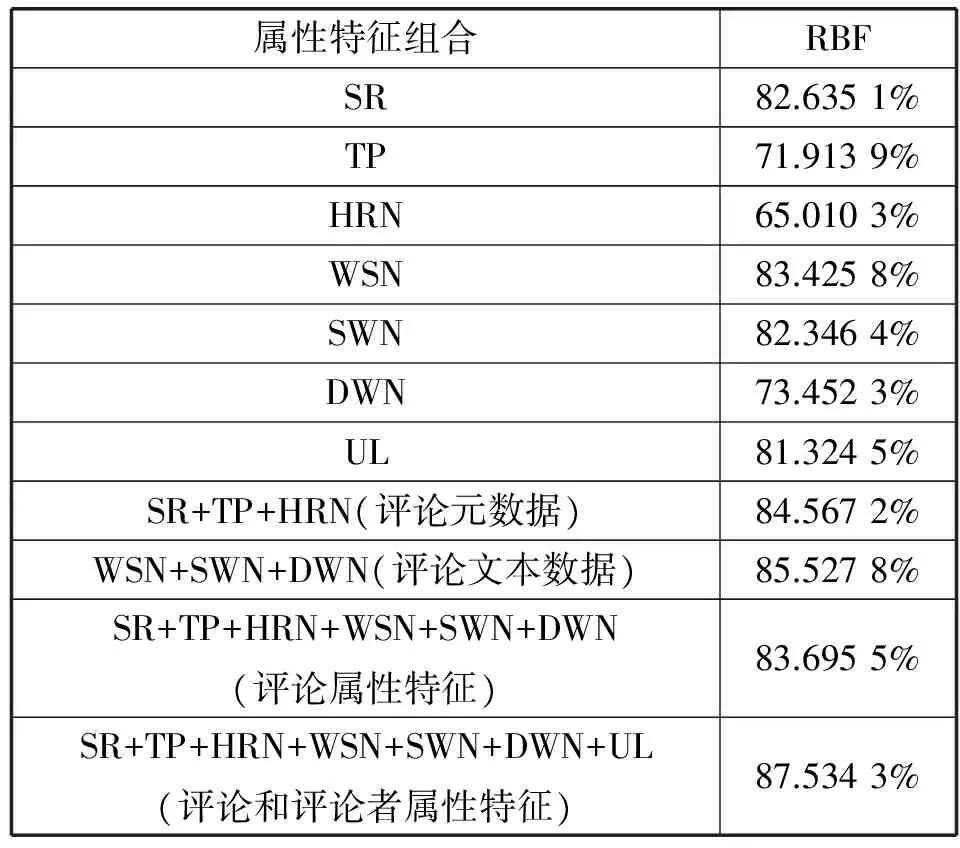
表4 不同属性特征组合情况的评估正确率
然而,有用性投票和回复数量HRN属性特征相比较其他属性特征则表现不佳。有用性投票和回复数量HRN属性特征表征着用户对评论的回馈情况。由于用户手动标注评论有用性以及回复评论行为耗时,评论获得的有用性投票以及回复数量数据稀疏。从而导致有用性投票和回复数量HRN属性特征表现欠佳。将评论的各元数据SR、TP和HRN综合以及将各文本数据WSN、SWN和DWN综合的情况下,评论质量评估的效果相比较考虑单独属性特征的效果有所提升。然而,将以上元数据与文本数据再综合考虑时,效果却比单独元数据或文本数据组合的情况要差。其原因是因为部分评论的元数据属性特征与文本属性特征表征的用户对商品的态度有偏差。在综合评论和评论者属性特征情况下,评估评论质量的表现有了显著的提高。说明评论者属性特征对于提升评论质量的评估有显著效果。
5 结 语
网站中充斥着大量质量不一的评论内容。因此,迫切需要评估评论的质量并挑选出优质的评论以改善用户体验。然而,大多数网站目前采取了耗时的邀请用户人工手动标注评论质量的方式来解决上述问题。
本文提出了一种自动化的评论质量评估方法。该方法通过基于若干评论和评论者属性特征的支持向量机(SVM)分类器来实现。文中通过京东购物网站的部分数据训练了SVM参数,并在剩余数据上做了测试。测试结果表明,该方法在评估评论质量方面达到了87.5%的准确率。本文还分析了不同属性特征在评估评论质量过程中的重要性。经过分析得出,单独的属性特征在评估评论质量过程中,词语和语句数量属性特征表现最佳。其他的评分、情感词语数量和用户级别属性特征也表现良好。然而,有用性投票和回复数量属性特征由于缺乏用户的回馈而表现一般。总之,在同时考虑了评论和评论者大量属性特征的情况下,评估评论质量的表现最优。
本文能够帮助读者更好地了解不同属性特征在评估评论质量过程中的效果。基于不同属性特征在评估评论质量过程中的重要性,可以有效地对待评估的评论质量进行评估。本文主要研究对象为搜索性商品,未来考虑将研究对象转变为体验性商品,并比较评估体验性商品与搜索性商品的评论过程中,不同属性特征的效果。
[1]ChevalierJA,MayzlinD.Theeffectofwordofmouthonsales:Onlinebookreviews[J].Journalofmarketingresearch,2006,43(3):345-354.
[2]DabholkarPA.Factorsinfluencingconsumerchoiceofa“ratingWebsite”:Anexperimentalinvestigationofanonlineinteractivedecisionaid[J].JournalofMarketingTheoryandPractice,2006,14(4):259-273.
[3]LiuJ,CaoY,LinCY,etal.Low-QualityProductReviewDetectioninOpinionSummarization[C]//EMNLP-CoNLL,2007:334-342.
[4]KimSM,PantelP,ChklovskiT,etal.Automaticallyassessingreviewhelpfulness[C]//Proceedingsofthe2006Conferenceonempiricalmethodsinnaturallanguageprocessing.AssociationforComputationalLinguistics,2006:423-430.
[5]WeimerM,GurevychI.Predictingtheperceivedqualityofwebforumposts[C]//ProceedingsoftheConferenceonRecentAdvancesinNaturalLanguageProcessing(RANLP),2007:643-648.
[6]TsurO,RappoportA.RevRank:AFullyUnsupervisedAlgorithmforSelectingtheMostHelpfulBookReviews[C]//ICWSM,2009.
[7] Ghose A,Ipeirotis P G.Designing novel review ranking systems:predicting the usefulness and impact of reviews[C]//Proceedings of the ninth international conference on Electronic commerce.ACM,2007:303-310.
[8] Lu Y,Tsaparas P,Ntoulas A,et al.Exploiting social context for review quality prediction[C]//Proceedings of the 19th international conference on World wide web.ACM,2010:691-700.
[9] Danescu Niculescu Mizil C,Kossinets G,Kleinberg J,et al.How opinions are received by online communities:a case study on amazon.com helpfulness votes[C]//Proceedings of the 18th international conference on World Wide Web.ACM,2009:141-150.
[10] Mudambi S M,Schuff D.What makes a helpful review? A study of customer reviews on Amazon.com[J].MIS quarterly,2010,34(1):185-200.
[11] 姜巍,张莉,戴翼,等.面向用户需求获取的在线评论有用性分析[J].计算机学报,2013,36(1):119-131.
[12] 张林,钱冠群,樊卫国,等.轻型评论的情感分析研究[J].软件学报,2014,25(12):2790-2807.
[13] Ott M,Choi Y,Cardie C,et al.Finding deceptive opinion spam by any stretch of the imagination[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies-Volume 1.Association for Computational Linguistics,2011.
[14] Lappas T.Fake reviews:The malicious perspective[M]//Natural Language Processing and Information Systems.Springer Berlin Heidelberg,2012:23-34.
[15] Mukherjee A,Liu B,Wang J,et al.Detecting group review spam[C]//Proceedings of the 20th international conference companion on World Wide Web.ACM,2011:93-94.
[16] Mukherjee A,Liu B,Glance N.Spotting fake reviewer groups in consumer reviews[C]//Proceedings of the 21st international conference on World Wide Web.ACM,2012:191-200.
[17] Xie S,Wang G,Lin S,et al.Review spam detection via temporal pattern discovery[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2012:823-831.
[18] Hsu C W,Chang C C,Lin C J.A practical guide to support vector classification[J].Mehdi Namdari,2003.
ANALYSIS ON QUALITY INFLUENCING FACTORS OF USER REVIEWSON POPULAR B2C SHOPPING SITE
Liu Jie Fu Xiaodong*Liu Li Liu Lijun
(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,Yunnan,China)
Users’ online reviews are helpful for users to choose products or service online. However, hot sale products hold a large number of reviews which vary considerably in quality. Thus, it’s urgent to assess the quality of reviews and pick out the high-quality ones. It’s a great waste of time and effort for users who are invited by sites to assess the quality manually at present. In order to solve this problem, a method for automatically assessing the quality of reviews is proposed. The method would be implemented with SVM classifier which is based on reviews and reviewers respectively. The review data on popular domestic online retailer JD.com is chosen to be tested. Experimental results show that the accuracy of high-quality reviews assessing has achieved 87.5%. The experiment proves that the quantity feature of words and sentences which can characterize the amount of information could help assess the reviews’ quality well. However, the performance of usable votes and reply quantity feature didn’t help a lot for its lack of feedback from users. It performs the best when combining both review feature and reviewer feature.
Online review Quality of review Support vector machine (SVM)
2016-02-22。国家自然科学
71161015,61462056,61462051,81560296)。刘杰,硕士生,主研领域:服务计算。付晓东,教授。刘骊,副教授。刘利军,讲师。
TP3
A
10.3969/j.issn.1000-386x.2017.03.012
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
数学小灵通(1-2年级)(2021年10期)2021-11-05
新闻研究导刊(2021年17期)2021-11-02
小天使·一年级语数英综合(2020年4期)2020-12-16
小学生学习指导(低年级)(2019年3期)2019-04-22
小型微型计算机系统(2018年11期)2018-11-15
新媒体研究(2016年9期)2016-10-14
小猕猴智力画刊(2016年6期)2016-05-14
传奇故事(破茧成蝶)(2015年7期)2015-02-28
新闻前哨(2012年1期)2012-03-27
