
面向微博的PageRank算法的改进与应用
2017-04-14 00:46田丽华
计算机应用与软件 2017年3期
原 野 李 晨 田丽华*
1(西安交通大学软件学院 陕西 西安 710049)2(新浪网技术(中国)有限公司 北京 100000)
面向微博的PageRank算法的改进与应用
原 野1,2李 晨1田丽华1*
1(西安交通大学软件学院 陕西 西安 710049)2(新浪网技术(中国)有限公司 北京 100000)
从海量数据下的社会化网络中识别出各个领域下产出高质量内容的具有一定影响力的专家,进行具有针对性的广告推荐与决策支持,已经成为微博数据挖掘亟待解决的问题之一。从微博的用户特征和行为特征出发,确定了采集博文的规则与互动量计算公式,并应用PageRank算法对微博用户影响力计算时存在的数据陈旧性和主题不相关性的问题进行了改进,最后分别基于MapReduce和Spark的并行计算框架对算法进行了实现。实验结果表明,该挖掘方法具有较好的准确性,在Spark并行计算框架下表现出较高的性能,尤其适合大规模数据集的场景。
微博 用户影响力 PageRank Spark 大数据
0 引 言
微博是一种典型的Web 2.0社交网络服务SNS(Social Networks Service)应用[1]。它以短文本、图片、小视频等方式拓展了用户的交流途径,创建了一个类似传统社区的网络虚拟圈。新浪微博由于其对产品的精准定位,在竞争中脱颖而出,领先于国内同类产品,已经融入到社会生活的方方面面,成为了获取实时信息的最佳平台。其拥有高达1.4亿的日活跃用户数,每天有数百GB甚至TB级别的结构化数据入库。因此,从海量数据下的社会化网络中识别出各领域下的专家和具有一定影响力的用户,进而利用这些识别出的专家和用户进行具有针对性的推荐,已经成为亟待解决的问题。
对于高影响力微博用户的挖掘,不少研究从PageRank算法和评估模型入手,进行了影响力评估[2-5]。这些研究专注于某个模型或者算法的改进,为建立用户评价模型提出了多种思路,但均没有考虑挖掘数据的规模、可应用性和可扩展性,无法产生实际的应用价值。其中,文献[3]结合用户潜在的影响力和博文传播影响力,提出了一种基于PageRank的影响力评估指标,具有一定的合理性和有效性。但这些指标缺乏通用性,只能描述特定的少量用户,因此,其计算的范围被局限,不能针对海量的用户进行计算与应用。针对用户推荐与挖掘,也有一些研究从其他方面入手,利用聚类、链接分析、标签预测等方法提出了一系列描述用户兴趣和影响力的方法及模型[6-8]。这些模型从不同的角度对用户影响力进行了建模及实验分析,每种方法都有各自的侧重点,但同样缺乏对海量数据集下的实证。如文献[7]从链接分析和用户行为两个角度衡量用户的影响力,提出了微博用户影响力指数模型。但该模型以整体用户为对象,没有考虑微博用户的聚类化,即在不同领域下分别进行影响力指数的计算,使用户间的对比更有意义。
本文通过分析微博的互动机制,进而将用户的行为量化,基于PageRank提出了一种微博用户影响力计算方法。该方法改进了PageRank的主题陈旧性,引入了时间区间,限定分析的数据为最新数据。同时,方法还对领域进行了区分,针对领域内用户而不是整体微博用户进行计算,大大改善了算法的主题不相关特点。该算法兼顾了挖掘的覆盖度和准确性,并针对并行计算框架做了设计与应用,使得用户影响力计算方法能够在大数据规模下高效运行,具有很高的可应用性和可扩展性。
1 PageRank算法
PageRank算法,又称为佩奇排名算法,是谷歌用来衡量网页重要性、标识网页等级的一种方法[9]。PageRank算法的基本思想是:确立一个评估网页的权重值(PR值),该值标志着一个网页的相关性和质量。在揉合考虑多个特征元素之后,评估指向某个网页的其他网页的重要性,再给出这个网页的重要性。即“被越多优秀的网页所指向的网页,它是优质网页的概率会更大”。
PageRank算法在入链数的基础上考虑了网页质量的因素,提出了两个基本的假设:
(1) 数量假设:在网页图模型中,如果某个页面得到的入链数数目越多,则证明其具有更高的重要性。
(2) 质量假设:在网页图模型中,如果指向某个页面的多个页面的质量越高(PR值越大),则该页面的重要性就会越高。
PageRank算法类似于一个投票系统,每个人拥有一定的初始权值,PageRank算法是公平的,因此此权重值在开始时是一致的,并不会考虑其他元素的影响。随后令每个人对其他人进行投票,且可以将自己的票按照一定的比例分别投给多个人。在一轮投票完毕后,每个用户会得到汇总后的投票数,该投票数就是其新一轮开始投票时具有的票数(权值)。如此反复投票N次,直到每个人获得的投票数保持稳定的时候,结束运算,每个人的最终得票值即为其重要性。
在网页中,某些网页是没有网页指向的,也有某些网页是没有任何链接的,这些孤立网页会在迭代计算的过程中逐渐降低得分直至为0或者在某次排名中丢失,出现“排名泄漏”和“排名下沉”。因此,PagRank中存在一个阻尼系数,来防止这些情况的出现,如式(1)所示:
(1)
其中,P1,P2,…,Pn是被研究的页面,N是所有页面的数量,L(Pj)是Pj链出页面的数量,M(Pi)是Pi链入页面的数量,q为阻尼系数。
2 微博互动机制
以新浪微博为例,互动主要由某些特定的用户发布博文来引发,整个互动过程是一对多的,以某个用户的博文或话题为中心,层层传播,带动起大量普通用户的参与。因此要观察研究微博互动的机制,就需要从用户特征和行为特征两个方面出发。
1) 用户特征
通过观察分析新浪微博近3个月的热门微博榜数据,可以发现榜单上的用户构成主要如图1所示,其中微博会员是微博的一种收费机制,主要作用在于提升微博用户发表博文的传播力。一般来说,微博会员活跃度高,内容产出质量也较高,其占据了12.35%的热门微博数。橙V与蓝V用户,由于其经过官方认证,具有更高的权威性和可靠性,因此其影响力更大,传播范围更广,分别占据了15.60%与7.23%的热门微博数。对于人气草根来说,一般是因为某些特殊事件或引发群体关注的博文而被大家关注,这类用户未来产生高影响力的可能性非常大。由上述微博会员、橙V、蓝V、人气草根构成了一个能力用户集合,该集合内用户具备长期稳定输出高质量内容的能力。同时,集合需要排除一部分用户,即少量转发抽奖、营销等账号。该类用户能够上榜往往是由投入了大量资金而出现短暂性爆发的关注度,其下的用户一般不具备长期稳定输出高质量内容的能力。由此,确定了博文采集数据源的集合为上面提到的能力用户集合,而将其他类用户排除在外。

图1 热门微博用户构成
2) 行为特征
微博用户间的互动特征在很大程度上是由用户发布消息的属性特征所显现出来的[10]。互动行为可以细化和归结为多个种类,但从博文的影响力和扩散性而言,互动行为主要分为转发、评论、赞等三种用户行为,用户间互动的中心可以是话题、博文或者评论,以原创博文为中心的对话环状结构如图2所示。其中原创博文外第一圈为第一层传播者,影响力较高,此时也存在赞行为,但更为注重的是其转发和评论,虚线表示原创博文用户有时会回转第一层传播者的评论以获得新一轮的关注。下面是针对三种用户行为的具体介绍。
① 转发。该行为是指某个用户在阅读了一篇博文(长博文或短博文)之后产生了强烈的共鸣或反对情绪。其表现出该用户对该博文产生了较强的关注且急于抒发自己的直观感受。转发数的高低反映了消息扩散程度和传播覆盖面的广度。
② 评论。评论是阅读博文后有所感触,由此产生的意见和看法。评论数的高低反映了消息在扩散中引发的反响程度,也直接的体现了消息的影响力。
③ 赞。此行为只是单纯的表达对一条博文是否认同,其用户主观性比转发和评论都要弱。赞的数目只能间接的反映一条博文的影响力。
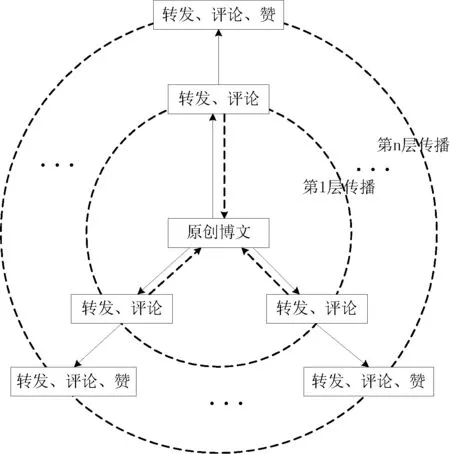
图2 以原创博文为中心的环状传播
3) 数据源过滤规则与互动行为量化
根据对用户特征与行为特征的分析,可以确定微博用户影响力计算过程中使用的博文数据源的过滤规则,并可以得出用户互动量的计算公式。
① 过滤规则。以博文为中心,就要先提取出各个领域下的高质量博文,这里采用用户特征属性来过滤这些博文。以新浪微博提供的API为例,博文数据源分为5个等级,橙V用户博文、微博会员博文、高质量可信用户博文、普通用户博文以及营销信息等低质量博文。根据规则,确定普通用户及以上等级的博文为数据源,之所以采用普通用户博文,是由于某些普通用户可能潜在内容输出能力,进而成为新的微博人气草根。确定用户特征后,根据博文的原创标识字段,进一步确定博文是原创博文,所有转发以及二次原创博文都将被排除在外。确定了过滤规则后,经过过滤筛选的博文成为初始数据源。
② 互动行为量化。本文提出了相应的用户间的互动行为的量化,阐述如下。在T1到T2时间段内,某用户对另一用户的所有博文所产生的互动行为的总和,称为该用户对单个用户的互动行为量,如式(2)所示:
(2)
而在T1到T2时间段内,某用户对另一个用户的互动行为量占其某时间段内总行为量的占比,称为用户对单个用户的互动行为概率,如式(3)所示:
(3)
其中,确定转发、评论、赞行为的影响力因子分别为a、b、c,三个因子之和为1。T1、T2为时间点,所有博文的转发、评论、赞的总次数分别为c_repo、c_cmt、c_like。
3 基于PageRank的微博用户影响力计算方法
在以博文为中心的环状传播中,若某用户的博文产生的转发、评论、赞的数目越大,则其更容易出现在微博头条之上,也代表其重要性和影响力更大。如果在与某条微博发生互动行为的用户当中,具有高影响力和权重的高质量用户数量更多,则表明该博文的用户影响力更大。因此,微博的互动机制完全符合PageRank算法的基本条件,可以采用PageRank算法来进行微博用户影响力的计算。针对PageRank算法应用于微博时存在的问题,本文在其对微博影响力的计算方面进行了相应的改进。
1) 数据陈旧性
在PageRank算法的基本原理中,网页的PR值均匀地分配给链出的网页,这样会造成存在时间比较久的旧网页被链接次数明显高于新网页,从而使得旧网页PR值高但内容陈旧,新网页PR值低但内容重要[11]。本文提出的在微博中应用的PageRank算法通过引入时间区间的方法,来解决了这个问题。引入算法进行计算的用户博文数据,限定在一定时间段内,这样一来,由用户产生的互动量就被限制在了最新区间内,可以实时、动态反映用户最新的影响力情况。
2) 主题相关性
PageRank应用在网页链接排名中的另一个缺点是忽略了主题性,导致结果的相关性和主题性降低[12]。而本文以博文为中心的影响力的计算是限定在一定领域内的。多个领域下的数据可以混合并同时进行运算,一个领域下的能力不对另一个领域下的能力产生任何影响,由此,在确定了领域的同时又保证了计算的公平性和准确性。
根据上述结论,本文确定了以博文为中心,以用户博文的互动量为用户影响力的评价标准,具体流程如图3所示。

图3 微博用户影响力计算流程图
1) 初始权值和概率转移矩阵的建立
在得到了互动量计算公式之后,就可以考虑将其应用到PageRank算法之中了。应用PagekRank算法最重要也是最基本的流程为两步:第一步建立概率转移矩阵,上述用户对单个用户的行为概率就是概率转移矩阵中的概率值。第二步初始化权值,对不同领域下的用户按照一定的规则赋初值。规则如下:
① 用户数在1千万以下的领域:用户初始权值为1/E。这里E为该领域下的总数。
② 用户数在1千万以上的领域:用户初始权值为1/E。这里一般取E>107,才能保证算法收敛时,所得权值不至过大而给后续计算带来问题。
2) 迭代计算过程
将初始权值与概率矩阵相乘,相乘得到的结果为新一轮的权值,之后将新权值继续与概率矩阵相乘,重复迭代计算至两次结果差值小于ε,得到最终计算结果。
此处伪代码如下,其中X为权值(x1,x2,…,xn),A为概率转移矩阵:
R=AX;
while(true ) {
if(|X-R|<ε) {
//如果最后两次的结果近似或者相同,返回
return R;
} else{
X=R;
R=AX;
}
}
4 算法并行化实现及结果分析
根据算法的设定,取某一时间段的博文进行处理分析与计算,一般来说,离线分析取时间跨度在2个月以上的博文数据较为合适,而每天在微博全领域下产生的博文经过过滤后数据量仍在千万级别,即需要处理2个月近亿条(TB级别)的数据,而这只是博文数据。在计算互动量时,针对每一条博文都有数十万的转发、评论、赞,数据量的规模已经远远超过了单机所能处理的范围。因此,必须采用分布式系统下的分布式计算框架,才能够满足算法运行的需求。本文从两种最流行的分布式计算框架出发,对算法进行了并行化设计,并在之后对其进行性能分析比较,最终确定出适合的运算框架。
4.1 MapReduce与Spark计算框架下的迭代计算设计
1) 数据采集与格式
本文通过使用新浪微博内部API以及数据仓库来获取新浪微博的用户数据,所有数据均为线上真实数据。数据的格式、初始权值及概率转移矩阵的全部数据以行文本格式出现。通过多级hive操作及MapReduce程序的清理转化,得到了参与计算的初始数据集合。其中,某领域下初始权值的文本存储格式如表1所示,邻接矩阵的文本存储格式如表2所示。借助加入标签与用户uid组合,可以将用户加入到不同领域的计算中去,如果某用户在多个领域下均存在内容输出能力,在这种方式下由于标签的存在,用户在各领域下的计算就不会产生相互影响。

表1 初始权值文本存储格式示例

表2 初始邻接矩阵文本存储格式示例
2) MapReduce下的迭代计算设计
在使用python编写的MapReduce代码中,不能将全部的初始权值、矩阵载入内存后做矩阵乘法。因为数据量的规模巨大,集群中在高负荷运算下没有一个单点的内存可以载入全部的用户权值集合。因此,将每一个用户的权值分别乘以矩阵中的它对应的那一行的概率值(即某个点的全部出度的值),对整个矩阵做了这样的操作后,得到一个临时矩阵TMP_MATRIX。该矩阵为概率值乘以权值得到的矩阵,其每一列(即某个点的全部入度对应的值)相加后的值的和,就是要得到的这一轮迭代的某个用户下的新权值,再将新权值作为输入返回迭代计算(见图4中“迭代计算”部分所示)。这样一来,就将庞大的矩阵计算拆分成了多个可以并行计算的任务,而这些任务之间又相互没有任何依赖关系,可以很轻松地将其转化为MapReduce程序进行计算。在编写MapReduce程序时,需要巧妙地利用HadoopStreamming将第一列认定为进入shuffle阶段的键值的特性,通过拆分、合并、转化标签类别TagCategory和uid来实现迭代的两个步骤。
MapReduce下的计算过程如图4所示。

图4 MapReduce框架下微博用户影响力计算过程
3) Spark计算框架下的迭代计算设计
Spark框架计算过程使用与MapReduc计算相同的数据作为输入源。根据使用的初始权值数据和概率转移矩阵数据,Spark从HDFS上读取文件进入内存并创建了两个不同的弹性数据集rdd_pr_value和rdd_pr_relation,得到初始rdd后,经过对两份数据的join、mapToPair、flatMapToPair、reduceByKey、mapValues等数据集的转化操作后,最终以saveAsHadoopFile激活操作将得到的结果数据集存入到HDFS中去。其整个过程都以内存计算为主,除了开始读入数据与最终写出数据,整个计算过程基本不会与磁盘发生I/O行为,计算效率非常高。
在创建RDD(弹性数据集)之后,Spark会尽可能地将任务并行化、管道化,按照组织的数据来划分阶段(Stage)。PageRank算法的过程有固定Stage和变化Stage,其中准备邻接矩阵、准备初始权值以及最终存入HDFS三个逻辑任务为固定不变的Stage,随着数据量的扩大其处理的并行任务会增加但Stage并不增加。而只有迭代次数的不断增加,才会带来Stage数目的不断增加,增加的次数要根据迭代部分的复杂程度来确定。在程序划分好阶段后,会产生DAG(有向无环图)作为逻辑执行计划。在执行的过程中,每个阶段又可能被分为多个任务接受调度。详细的RDD转化过程如图5所示。
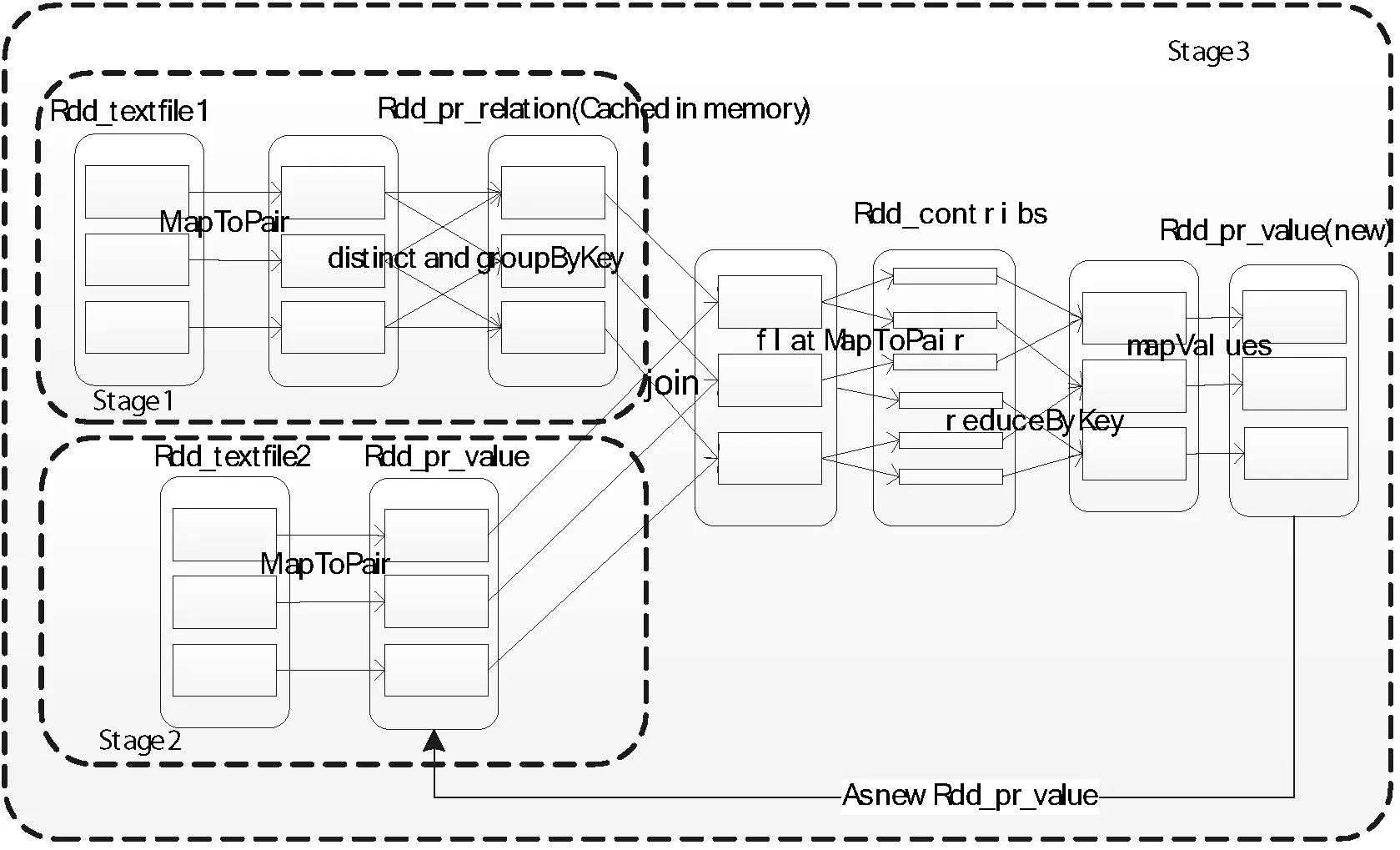
图5 Spark框架下的PageRank计算RDD转化过程
4) 动态选择并行计算框架
在性能对比上,Spark的性能远远好于MapReduce,但这是以消耗巨大内存为前提的。弹性数据集意味着如果内存不足,那么有部分数据会被刷写到磁盘之上,在这种情况下,Spark的速度与稳定性均会降低,尤其是速度上并不比MapReduce快很多。因此,将挖掘中的全部任务都由MapReduce替换为Spark是不明智的,它会消耗大量资源,并引起资源调度的不稳定。只有针对核心的、耗时较大的迭代任务,采用Spark才是高效的。结合集群使用情况来看,当Spark迭代任务与HadoopMapReduce任务同时运行在集群之中时,集群的负荷增大。通过监控WebUI可以得知,非高峰期整体内存使用率在92%至96%之间,处于正常运行状态,但高峰期时,使用Spark进行迭代计算将因为集群内存不足节点数增加而导致部分任务被挂起等待,集群利用率下降。
由此,确定了只有迭代计算部分的任务采用Spark进行计算。且计算时采用动态选择机制:设置Spark作为默认迭代计算框架,当启动Spark迭代任务时,若集群整体内存充足,任务顺利启动进行计算;若内存空闲量足够启动的节点数不足,导致Spark任务无法启动,返回错误代码,脚本切换至HadoopMapReduce框架进行计算,整体切换流程如图6所示。

图6 动态切换计算框架流程图
本文算法的执行涉及到超大规模数据集(8 100万条接近4 TB的初始数据),因此,在分析采用何种大规模分布式计算框架时,就会涉及到性能、数据量和稳定性上的考虑。Spark将常用数据贮存于内存之中的机制,大大改善了MapReduce框架的运算性能,减少了大量的I/O开销,但同时,这种内存计算框架也存在着大量消耗内存、调度不稳定易崩溃的缺点。本文将两种框架结合、根据集群当前使用情况进行动态选择,以内存节点是否充足、Spark任务是否能正常启动作为切换的条件。当内存充足,集群压力正常的情况下,选择Spark可以大大提升运行的效率;而在内存不足,集群压力较大的情况下,选择MapRedcue则更为稳定,其稳定性上的优势完全弥补了速度上的不足,在多人共用的集群环境下尤为明显。
4.2 微博用户影响力计算实验结果及分析
实验运行与测试均在相同的集群环境之下完成,具体情况如下:
(1) 集群节点全部部署Hadoop CDH4(Cloudera版本,对应Hadoop2.0),并以Spark on Hadoop方式部署Spark-0.9.4版本。
(2) 集群规模:600台节点,共计28 TB总内存,CPU总核心数约1.5万个,磁盘约1 800 TB。
挖掘任务在集群各节点上运行情况如图7所示。

图7 平台基本运行情况示意
根据上一节中不同并行计算框架下的设计,编写了MapRedce程序和Spark程序并运行在集群上,典型的用户得分权重收敛情况如图8所示,大部分用户在迭代20次时归于收敛,而迭代达到40次时,全部数据归于收敛。

图8 随迭代次数增加用户权值收敛情况
上述集群环境下,进行了多次用户影响力计算实验,总体计算时间保持在1个小时20分钟之内,整体运行时长如表3所示。

表3 挖掘运行性能统计 min
经过对数据的采集和预处理,并利用动态选择的分布式框架对近3个月的来自于新浪微博的真实线上用户数据进行微博用户影响力计算,得出了最终的用户影响力。在计算结果覆盖的若干领域中,以热门领域“健康医疗”为例分析与说明挖掘对象的能力输出。表4为采用本算法和计算框架后得出的“健康医疗”领域下前8名用户的得分及排名情况,通过将此结果与微博影响力排行榜对应医疗领域下的榜单进行对比发现,其中8人中有6人上榜,且排名顺序一致。这里,微博影响力排行榜来源于微风云网站,这个第三方公司服务与新浪微博、百度、Discovery等多家公司,其数据具有一定的权威性[13]。

表4 健康医疗标签下排名前8的用户情况统计
经过对实验结果的分析,可以得出,若某一时间段内,用户的互动量上升,则该用户的权重值会由于PageRank权重的上升而增加。这一改进的计算策略有效地改善了传统PageRank算法挖掘能力用户的陈旧性缺点,而引入时间区间与领域区分后,挖掘排名的动态性和准确度均得到了提高。
根据挖掘的结果,本文经过展示系统将各领域下的高影响力用户(高权重值)进行了分类与整理,并设定了条件进行筛选,如图9所示。本文的用户挖掘覆盖了大多数社会生活领域,挖掘的结果具有较高的准确性和可用性,可以支持广告推荐与群组推荐。
为了进一步验证算法的性能,我们比较了本文的改进算法与文献[3]及文献[5]中改进的PageRank算法对于相应领域下的新浪微博用户的挖掘结果,如表5所示。通过结果可以看出本文挖掘的健康医疗领域下的用户与文献[3]、文献[5]相比,排名趋势基本一致,但从数据规模上说,文献[3]与文献[5]通过用户活跃度和关注度对数据集进行了筛选,限制了最终参与挖掘的数据的广度,那么一次可挖掘的主题较为有限,而本文算法直接对于所有用户的数据进行挖掘,规模更大,挖掘出的主题覆盖度更高。这是由于本文算法的研究重点在于覆盖各个领域下的用户,并采用并行架构提升结果的实时性和动态性。而文献[3]的重点在于从话题和博文的影响力进行PageRank计算,文献[5]则是从活跃度和关注度进行计算,它们挖掘的结果是全局性的影响力排名及分析,没有讨论数据规模和覆盖度相关的问题。本文挖掘使用的数据规模在TB级别,讨论的是大规模集群挖掘下的相关问题,因此挖掘的方法具有更高的应用性。
5 结 语
根据对用户特征和行为特征的分析,本文针对PageRank算法在微博用户影响力的计算上做了改进,引入了时间区间和领域区间,给出了用户影响力的量化计算公式。基于PageRank改进的用户影响力算法,分别在MapReduce和Spark计算框架下进行了微博用户影响力迭代计算。实验结果表明,基于PageRank改进的用户影响力计算方法具有较好的准确性,在采用Spark并行化计算框架进行迭代计算时性能较高,比较适合大规模数据集合的挖掘场景。
[1] 吴根平.我国政府微博发展现状及对策[J].信息化建设,2011(10):23-27.
[2] Weng J,Lim E,Jiang J,et al.Twitterrank:finding topic-sensitive influential twitters[C]//WSDM,2010.
[3] 吴少华,马晓娟,胡勇.基于改进PageRank算法的微博用户影响力评估[J].四川大学学报(自然科学版),2015(5):1040-1044.
[4] 陈少钦.基于PageRank的社交网络用户实时影响力研究[D].上海交通大学,2013.
[5] 欧卫,欧缤忆,谢赞福,等.一种基于PageRank的微博用户影响度评估算法[J].计算机与现代化,2013(12):34-37,40.
[6] 杨尊琦,张倩楠.基于k-means算法的微博用户推荐功能研究[J].情报杂志,2013(8):142-144,131.
[7] 原福永,冯静,符茜茜.微博用户的影响力指数模型[J].现代图书情报技术,2012(6):60-64.
[8] 邢千里,刘列,刘奕群,等.微博中用户标签的研究[J].软件学报,2015(7):1626-1637.
[9] Page L.The PageRank Citation Ranking:Bringing Order to the Web[C]//Stanford InfoLab,1999:1-14.
[10] 夏雨禾.微博互动的结构与机制—基于对新浪微博的实证研究[J].新闻与传播研究,2010(4):60-69.
[11] 周奇峰.基于用户兴趣的PageRank算法改进策略[J].网络安全技术与应用,2014(6):52-53.
[12] Pedroche F,Moreno F,González A,et al.Leadership groups on Social Network Sites based on Personalized PageRank[J].Mathematical & Computer Modelling,2013,57(s7/8):1891-1896.
[13] 微博影响力评估平台.微博影响力排行榜[EB/OL].2015.http://www.tfengyun.com/rankings.php.
IMPROVEMENT AND APPLICATION OF PAGERANK ALGORITHM FOR MICRO-BLOG
Yuan Ye1,2Li chen1Tian Lihua1*
1(SoftwareEngineeringSchool,Xi’anJiaotongUniversity,Xi’an710049,Shaanxi,China)2(SinaCorporation,Beijing100000,China)
It has been one of the urgent problems of micro-blog mining to identify experts with ability to produce high-quality content and high influence under various fields in social network with massive data, and make targeted advertising recommendation and decision support. In this paper, on the basis of user features and behavior features, the rules of selecting article in micro-blog and interaction calculation formula are determined, and the obsolescence of data and irrelevance of theme have been improved by PageRank algorithm. Finally, the algorithm is implemented respectively in the parallel computing framework of MapReduce and Spark. Experimental results show that the proposed method has high accuracy and great performance under Spark, especially under large-scale dataset scene.
Micro-blog User Influence PageRank Spark Big data
2016-01-25。国家自然科学
61403302)。原野,硕士生,主研领域:数据挖掘。李晨,讲师。田丽华,高级工程师。
TP301.6
A
10.3969/j.issn.1000-386x.2017.03.006
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
作文大王·低年级(2022年3期)2022-03-19
邮电设计技术(2021年2期)2021-03-13
成都信息工程大学学报(2021年6期)2021-02-12
计算机与数字工程(2019年11期)2019-11-29
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
小学生作文·小学低年级适用(2018年12期)2018-04-11
计算机测量与控制(2018年3期)2018-03-27
中学科技(2016年7期)2017-05-16
