
基于排序模式相异性分析的轴承健康监测
2017-04-07 09:07江国乾李继猛
中国机械工程 2017年6期
江国乾 谢 平 王 霄 何 群 李继猛
燕山大学电气工程学院,秦皇岛,066004
基于排序模式相异性分析的轴承健康监测
江国乾 谢 平 王 霄 何 群 李继猛
燕山大学电气工程学院,秦皇岛,066004
排序模式分析方法通过相空间重构将一维振动时间序列映射到排序模式概率分布,来揭示序列内部结构的复杂性变化,为微弱信号特征提取提供了一种新视角。将排序模式分析和信息散度相结合,提出一种排序信息散度指标,用于对设备不同运行状态下的振动信号在高维相空间中排序模式概率分布的差异性进行量化分析,并用于轴承内圈不同损伤程度评估和轴承全寿命退化趋势分析。结果表明,与传统的时域统计指标及小波熵、近似熵、排序熵等非线性复杂度指标相比较,所提出的排序信息散度指标具有较好的故障程度量化分析性能,对轴承早期故障退化更加敏感,且稳定性好、计算效率高,利于工程实现。
排序模式分析;信息散度;状态监测;滚动轴承
0 引言
滚动轴承是旋转机械设备的关键部件,广泛应用于电力、石化、冶金、机械、航空航天等行业。在机械设备的长期运行过程中,磨损、疲劳、腐蚀、过载等原因都可能造成滚动轴承的失效或局部损伤故障,从而导致设备无法正常运行,甚至会出现灾难性事故,因此,有必要对轴承的运行状态进行实时、连续监测,准确评估其健康状态,以便及早发现异常行为或潜在故障,进而及时采取维修维护措施,保证设备安全可靠运行。轴承故障往往经历一个从产生到发展、从轻微到严重的渐变过程,在故障的发生发展过程中,其动力学特性往往呈现出复杂性和非线性,振动信号也随之表现为非平稳性。如何从非平稳非线性振动信号中提取合理有效的状态监测指标/参数,实现设备状态的定量评估及趋势分析,一直是设备状态监测与诊断的难点。
目前,在工程实际中,均值、有效值、峰值和峭度值等时域统计指标已经被广泛用来监测包括轴承在内的设备的运行状态,然而这些特征量的计算都是在信号是平稳的假设前提下得到的,难以准确挖掘设备状态信号中的非线性特征信息,因此状态监测及评估效果不佳。近年来,随着小波理论和非线性科学的发展,各种新的特征参数/指标相继被提出并成功应用于机械设备状态监测与故障诊断领域,实现设备或部件的早期故障检测、故障程度评估和状态趋势分析。文献[1]提出小波相关特征尺度熵来提取机械故障预测特征信息;文献[2]将小波熵引入机械故障诊断领域,实现了转子运行状态的趋势分析;文献[3]在关联维的基础上提出偏关联积分参数用于轴承的状态诊断和预测;文献[4]将近似熵作为新的监测指标用于轴承状态的健康监测和评估;文献[5-6]将多尺度熵引入机械故障诊断领域,指出多尺度熵相对于单一尺度熵指标的在故障识别方面的优势。上述研究从不同角度丰富了传统状态特征参数提取方法,取得了不错的应用效果,但为满足工程实际需求,仍然需要继续探索研究计算简单、对故障敏感的监测新指标。
排序模式分析作为一种新兴的非线性时间序列分析方法,由BANDT等[7]于2002年提出,该方法具有计算简单、速度快,抗噪能力强等优点,近年来已被广泛应用于经济、气候、生物、神经科学等领域的时间分析[8]。该方法也为振动信号状态参数特征提取提供了一种新的分析视角,通过挖掘信号的内部模式结构变化,能够放大信号的微弱变化,具有更强的故障检测能力。文献[9]将排序熵作为一种非线性统计参数用于旋转机械状态监测,取得了不错的效果;文献[10]结合小波相关滤波和排序熵提出小波相关排列熵并成功用于强噪声背景的滚动轴承早期故障诊断;文献[11]基于经验模态分解提出本征时间尺度排序熵以实现振动信号不同时间尺度上的复杂度量化分析,从而识别不同轴承故障状态;文献[12]引入多尺度排列熵,从不同时空尺度挖掘故障信息,实现轴承故障分类诊断。上述研究都是基于排序模式分析理论,利用不同的信号分解或多尺度处理方法来增强排序熵指标的故障特征提取及量化分析能力,然而由于信号分解或计算过程复杂,不利于工程应用。
当系统状态发生变化时,系统的输出响应也会相应发生变化,因此,振动响应信号的排序模式分布特性也会随着系统状态的改变而改变。通过分析健康状态与故障状态振动信号的排序模式分布特性,揭示高维相空间中内在动力学特征的差异性,能够捕捉系统早期故障时信号特征的微弱变化。本文从时间序列相似性角度提出排序模式相异性分析方法,结合信息散度定义了一种新的监测指标——排序信息散度,用来对设备不同运行状态间排序模式概率分布的差异性进行量化分析,并将其用于轴承损伤程度评估和全寿命退化趋势分析,验证了所提新指标的有效性。
1 排序模式分析理论
排序模式分析方法的主要思想是将一维观测时间序列重构到m维相空间,并将其等分为m!个排序区域,然后对时间序列排序模式分布进行统计分析,从而得到对应时间序列的排序模式概率分布。
1.1 基本原理
对于给定一维时间序列x={x(i),i=1,2,…,N}(N为序列长度),对其进行排序模式分析步骤如下:
(1)相空间重构。选取嵌入维数m和延迟因子τ,对序列x进行相空间重构,得到状态向量
X(i)=(x(i),x(i+τ),…,x(i+(m-1)τ))
(1)
(2)排序模式映射。将向量X(i)中的元素按照升序重新进行排序,若序列中存在某两个值相等则按照相应i的大小来进行排序。因此,在m维相空间中的每个状态向量X(i)都能唯一映射到排序模式π(i),共有m!种排序模式。如在3维状态向量空间,x(i)、x(i+)和x(i+2)间可定义6种排序模式,如图1所示。

图1 嵌入维数m=3时的6种排序模式Fig.1 Ordinal patterns at embedding dimension m=3
(3) 排序模式概率分布统计。将所有排序模式相同的向量归为一组,统计计算每一种排序模式出现的次数C1,C2,…,Cm!,就可以得到每一种排序模式出现的概率P1,P2,…,Pm!,计算如下:
(2)
根据步骤(1)~步骤(3)即可得到时间序列x的排序模式概率分布,它能够反映时间序列x在m维空间中的排布模式分布特性。排序模式分析也可以看作是一种符号时间序列分析方法。
为了进一步量化式(2)计算得到的排序模式概率分布,BANDT等[7]基于香农熵定义了排序熵如下:
(3)
当Pi=1/m!时,H(m,τ)就达到最大值ln(m!)。为了方便,通常用ln(m!)将H(m,τ)进行归一化处理,即
(4)
由上述计算过程可以看出,排序模式分析方法不同于ARMA模型、功率谱、小波变换等传统时间序列分析方法,它不直接使用时间序列的实际数据值,只需知道相邻数据点的大小次序关系即可,因此该方法具有概念简单、运算速度快、抗噪能力强等优点,非常适合于线性和非线性序列的实时在线分析。
1.2 不同时间序列的排序模式分析
为了说明排序模式理论在时间序列分析方面的特点和优势,选取正弦序列、高斯白噪声序列、非线性logistic混沌序列和轴承故障仿真冲击序列等典型时间序列进行分析,其时域波形和排序模式概率分布结果分别见图2和图3。每个序列包含2048个采样点,嵌入维数m取4,延迟时间τ取1,则共有24排序模式。
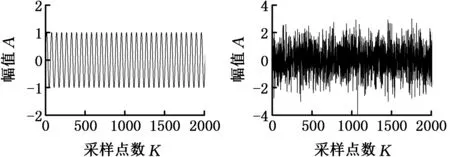
(a)正弦序列(b)高斯白噪声序列

(c)logistic序列(d)轴承故障仿真冲击序列图2 不同时间序列时域波形Fig.2 Waveforms of different time series

(a)正弦序列(b)高斯白噪声序列

(c)logistic序列(d)轴承故障仿真冲击序列图3 不同时间序列排序模式概率分布Fig.3 Ordinal pattern probability distribution of different time series
从图3中可以看出,不同时间序列具有不同的排序模式概率分布。其中,对于规则的正弦序列,第1种和第24种模式出现的概率最高,而其他几种模式几乎不出现;而对于随机的高斯白噪声序列,各排序模式出现的概率几乎相同,但由于数据长度的影响,每种模式发生的概率在理想值1/24附近波动;对于logistic混沌序列,排序模式集中在少数几个模式,且各模式发生的概率明显不同,这是由序列本身复杂的非线性结构决定的;对于轴承故障仿真冲击序列,排序模式也集中在少数几个模式,但与logistic序列不同的是,这几种排序模式主要以两种概率出现,这也是由信号周期性衰减冲击特征决定的。可见,排序模式分析能够将一维时间序列通过高维相空间重构映射到直观简单的排序模式概率分布,从而可以清晰地揭示不同序列或信号内部结构的差异性和变化。该方法为揭示不同状态振动信号的差异性和内部模式变化提供了一种新的分析视角。
2 排序信息散度监测方法
轴承的故障往往经历一个从产生到发展、从轻微到严重的渐变过程。在早期故障发生时期,系统状态与正常状态偏差小、征兆不完全,再加上测试装置等引入的误差及强背景噪声的干扰,早期微弱故障信息提取存在很大困难,轴承性能退化评估更加难以实现。机械系统或设备在运行中出现异常或故障时,振动信号往往因统计特征有序的正常信号中混杂了不一致的异常信号而变得相对复杂。利用排序模式分析理论可以将复杂的振动信号映射到高维相空间,通过分析排序模式分布特性的变化,可以揭示并放大轴承由正常向故障发生过程中的微弱复杂变化过程,从而实现故障的早期检测和健康状态评估。为了量化轴承发生故障时与健康状态下振动信号的差异性,在排序模式分析理论的基础上,本文从时间序列相似性角度出发,引入信息散度(information divergence)[13]来描述不同状态下排序模式概率分布的差异,从而定义一种新的监测指标——排序信息散度,用以量化分析设备当前状态与历史健康参考状态的排序模式相异性,从而实现对轴承故障程度/性能退化程度的评估。
2.1 排序信息散度
给定轴承监测振动信号x={x1,x2,…,xL}和健康状态参考振动信号y={y1,y2,…,yL},L为信号长度,按照图4所示的流程计算排序信息散度指标,主要包括2个步骤:

图4 排序信息散度计算流程图Fig.4 Flowchart of ordinal information divergencecalculation
(1)根据式(1)~式(2)分别计算信号x和信号y在m维相空间中的排序模式概率分布Px和Py,且Px和Py的和都是1;
(2)结合信息散度[13]概念,量化Px和Py之间的差异,定义信号x和信号y的排序信息散度指标如下:
(5)
式中,m!为时间序列在m维相空间中映射的排序模式个数。
显然,式(5)描述了时间序列x相对于时间序列y在排序模式结构分布的变化。当x和y的概率分布Px和Py完全一致时,D为最小值0;当概率分布Px和Py完全不同时,D为最大值1。
D可以看作是两个时间序列在高维相空间内排序模式概率分布相似程度的测度,能够反映设备状态偏离正常运行状态的程度,可用于实现轴承或其他机械部件的损伤检测和健康评估。显然,当系统仍处于完好状态时,Px和Py基本相同,此时D的值接近于0;当系统或设备发生损伤时,系统振动响应信号在相空间中的排序模式分布情况将发生变化,损伤前后信号的Px和Py也将存在一定的差异,导致D偏离0点,根据其偏离程度即可判定轴承故障程度情况。
同时,D继承了排序模式分析方法计算简单高效的优点,无需经过复杂的信号去噪和增强(如小波相关滤波)等预处理过程,只需将当前状态与历史健康状态进行相异性分析,然后根据D的大小判断系统的状态,因此该指标非常适合用于轴承的早期故障检测和损伤程度评估。
2.2 参数讨论
由排序信息散度指标的计算过程可知,其计算结果与N、m和τ三个参数有关,不同的参数选择将影响排序信息散度指标的性能。显然,如果数据长度过短,分析就不具有统计意义;而数据长度过长则不适用于实时分析的需求。对于m,如果取值过小,则生成的模式数目太少,难以捕获振动信号微小的变化,而过大的m则会使重构相空间维数增大,增加计算成本,不适合实际应用。因此,选取一组轴承正常运行状态下的实测振动信号来讨论参数的合理选取问题。
图5给出了20次重复试验情况下得到的D与N的关系。其中,m=5,τ=1。图中,中心点曲线对应20次重复试验计算的均值,每个中心点延伸出的直线部分对应标准差。标准差越小,说明指标越稳定。可以看出,当数据长度太短时,D明显大于0且波动很大;当数据长度足够大(N>4000)时,D接近于0且波动很小,因此,为了保证指标的稳定性,在后文的计算过程中,N选为4096。

图5 排序信息散度指标与数据长度的关系Fig.5 Relation between ordinal information divergence and data length

图6 排序信息散度指标与延迟因子和嵌入维数的关系Fig.6 Relations between ordinal information divergence and time delay and embedding dimension
图6给出了D与τ和m的关系,与图5一样,也进行了20次重复试验计算。可以看出,随着τ的增大,D几乎无变化,说明τ对D影响较小;而随着m的增大,D取值开始波动,逐渐偏离0,估计精度降低。为了保证能够有效地捕获振动信号模式变化和降低计算成本,综合考虑,选择m为4或5,τ取为1即可。
3 实验分析
3.1 电机轴承内圈损伤程度评估
将所提出的新指标用于轴承损伤程度定量评估。实验数据来自Case Western Reserve University(CWRU)的轴承数据中心[14]。测试轴承型号为SKF6205-2RS,轴承状态包括正常、内圈故障、外圈故障和滚动体故障4种类型。采用电火花技术在轴承内圈、外圈和滚动体上分别人工加工局部损伤,损伤直径分别为0.18 mm、0.36 mm和0.54 mm,分别用于模拟轴承内圈、外圈和滚动体的轻度损伤、中度损伤和重度损伤3种不同损伤程度。振动加速度数据在4种工况下采集,分别为工况A(转速1797 r/min,功率0)、工况B(转速1772 r/min,功率0.75 kW)、工况C(转速1750 r/min,功率1.5 kW)、工况D(转速1730 r/min,功率2.25 kW),采样频率为12 kHz。
以内圈损伤程度评估为例进行分析,为了说明所提新指标对损伤程度评估的优势,选取文献[5]中的近似熵(Ha)、文献[9]中的排序熵(Hp)和文献[2]中的小波熵(Hw)进行比较分析。图7为不同工况下轴承健康状态和内圈不同损伤程度的评估结果直方图。每一种指标均选取20个数据样本来进行重复计算,并将平均值作为最终结果。其中,如前文所述,对于排序信息散度指标,嵌入维数取为5,延迟因子取为1;对于小波熵,选取db4为母小波,分解层数为4;对于近似熵,嵌入维数取为2,相似容限取为0.2σ(σ为原信号的标准差);排序熵的参数和排序信息散度参数选择相同。

(a)近似熵 (b)小波熵
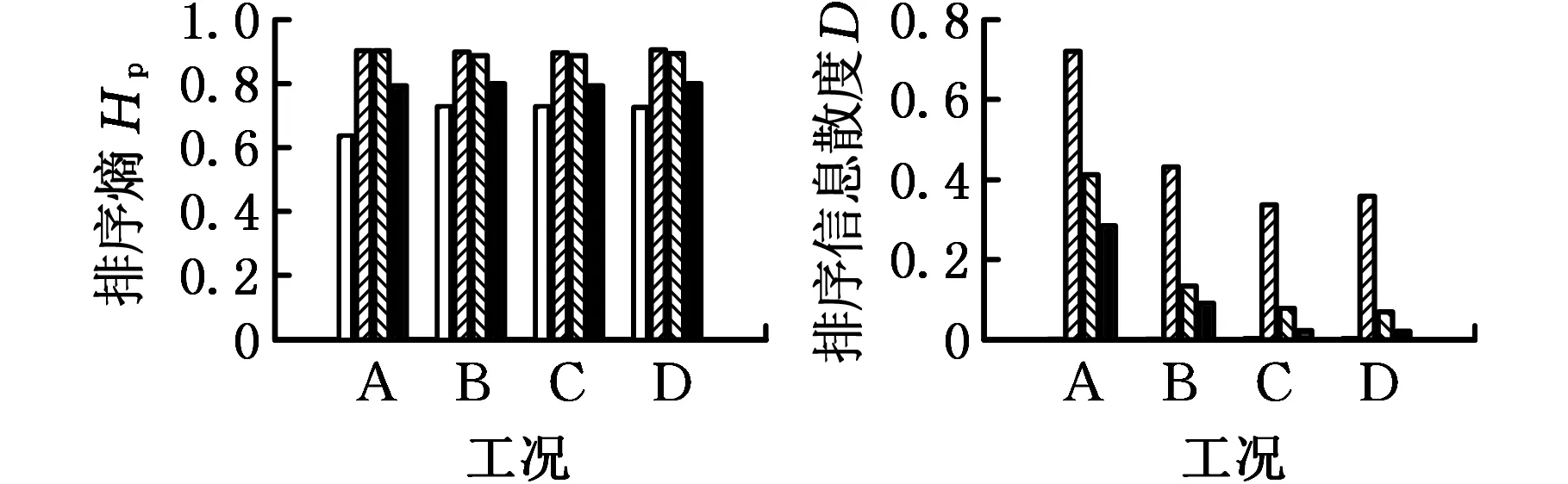
(c)排序熵(d)排序信息散度图7 轴承内圈损伤程度不同指标评估结果Fig.7 Results of different indicators on damage assessment of bearing inner race
从图7中可以看出,健康状态与内圈损伤状态下各指标值存在明显差异,总体看来损伤状态下各指标值均高于健康状态下的指标值,其原因是:故障发生时,信号成分会变得复杂并可能产生新的频率分量,导致信号复杂度变大,各指标值也相应增大,因此各指标能够反映故障发生时振动信号内部复杂性的变化。进一步,相比其他3种指标,排序信息散度在健康状态下指标值几乎为0,而不同损伤程度下指标值要远大于0,更容易区分健康与故障状态。对比不同损伤程度评估效果可知:随着损伤程度的加深,各指标在数值上呈现出逐渐减小的趋势,这是由于随故障程度加深振动信号的冲击性分量会更加明显,信号确定性增大,从而复杂度降低,各指标值也相应减小。因此,利用小波熵和排序熵将难以区分轻微损伤和中度损伤,近似熵则能够相对较好地区分它们;而本文所提的排序信息散度指标能够很明显地区分3种不同损伤程度,具有更佳的损伤程度评估能力。
3.2 轴承全寿命退化趋势分析

图8 轴承试验台结构简图Fig.8 Schematic of bearing test rig

图9 轴承外圈磨损实物图Fig.9 Picture of bearing outer race defect
进一步,将所提出的指标用于轴承全寿命退化趋势分析,验证其对轴承全寿命退化过程的评估效果。实验用到的数据来自美国NSFI/UCR的智能维护系统中心[15]的全寿命周期加速实验台,实验装置和传感器安装位置如图8所示。实验时,在一个轴上安装了4个轴承,轴的转速固定在2000 r/min, 26 700 N径向载荷用弹性系统加载在轴和轴承上。通过在轴承壳体水平和垂直方向安装加速度传感器来采集振动数据,数据采集从2004-02-12 10:32:39开始,至2004-02-19 06:22:39结束,期间每10 min采集一组数据,数据长度为20 480,采样频率为20 kHz,共记录984个数据文件。实验结束后,发现轴承1发生外圈磨损(图9)失效,这说明该实验记录了轴承从正常工作状态到故障失效状态的全寿命过程信息。本文选取轴承1垂直方向的振动数据进行分析。
首先,选取工程中常用的时域统计指标(包括均方根值Hrms、峰峰值Hpp、峭度Hskur和偏度Hskew)来监测全寿命轴承振动数据的变化过程,如图10所示。可以看出,各时域指标的变化曲线在很长一段时间内变化比较平稳,然后开始出现微小上升趋势,说明轴承开始出现异常,之后开始上下波动,轴承性能进一步恶化,直到最后各曲线出现骤变,这是由于轴承外圈发生严重磨损导致的。观察发现,各时域指标的变化曲线能够大致反映轴承运行的全寿命过程,由于各指标对故障的敏感性差异和计算特性差异,各指标在轴承全寿命退化过程中未能呈现出一致的变化趋势,前三个指标呈上升趋势,而斜度指标则表现为下降趋势。

(c)峭度(d)偏度图10 传统时域统计指标曲线Fig.10 Curves of traditional time domain statistical indicators
在轴承早期退化阶段,故障信号特征非常微弱,更容易被各种噪声和其他振动源淹没,时域统计指标难以捕获该阶段信号的微弱变化,对早期故障不敏感。研究表明,包括近似熵、小波熵和排序熵等在内的复杂度指标对信号的微弱变化敏感,能够更容易地挖掘早期微弱故障特征的变化。因此,为了对比研究,选取近似熵、小波熵和排序熵算法以及本文方法分别评估轴承全寿命退化过程。各指标参数的选取与内圈损伤程度实验参数选取相同。4种复杂度指标评估结果如图11所示。对比图10和图11 发现,相比于时域统计指标,上述复杂度指标能够清晰地揭示全寿命退化过程中信号的复杂动态变化,尤其在早期退化阶段,能够看到指标值明显下降或上升趋势,可以表征轴承早期性能退化的过程。

(a)近似熵 (b)小波熵

(c)排序熵(d)排序信息散度D图11 复杂度指标曲线Fig.11 Curves of complexity measure indicators

(a)归一化时域统计指标
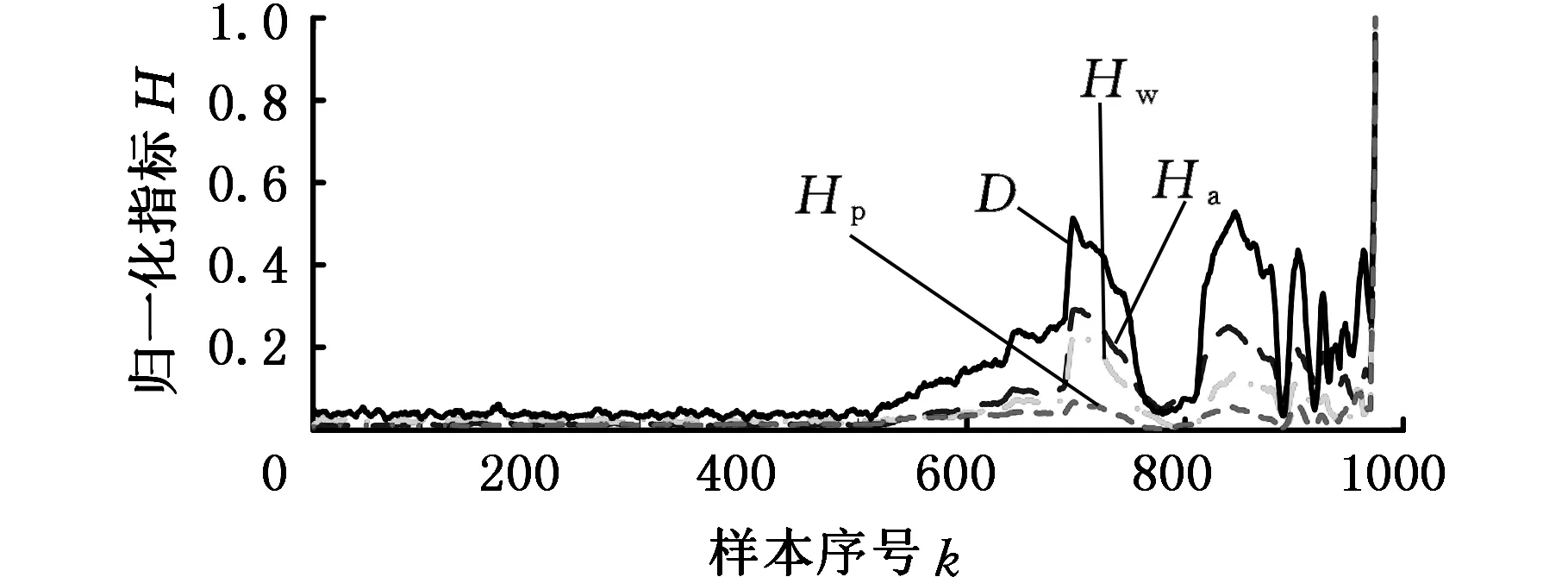
(b)归一化复杂度指标图12 各指标比较结果Fig.12 Comparison results of different indicators
然而,图10和图11中各指标值具有不同的尺度范围,无法进行公平精确的比较。为此,对所有指标进行趋势一致性处理和最大值最小值归一化处理,图12给出了处理后各归一化指标的变化曲线,每组数据都进行了5点平滑处理。从图12中可以看出:相比于传统时域统计指标和复杂度指标,本文所提的排序信息散度指标对早期故障更加敏感,在样本序号500~700时间段内呈现出更大的变化斜率,说明该指标对轴承早期退化过程具有更强的刻画和表征能力,能够更加准确地检测早期故障的发生与退化,并提前预警,使得工作人员提前做好检修准备和制定维修时间;另外,各指标在最后阶段突然增大,说明轴承已发生严重故障,与实际外圈磨损相吻合。
进一步,从指标的稳定性和计算效率两方面对各复杂度指标进行比较。选取正常运行下的前400个数据文件对各指标进行计算,结果见表1。其中,每个数据文件选取4096个采样点进行计算,重复进行20次实验。所有算法和计算过程均在主频为2.0GHz双核CPU、内存6GB的台式计算机上实现,使用的是MATLAB2012b软件平台。

表1 不同指标稳定性和计算效率对比
监测指标的稳定性主要由其标准差来反映,标准差越小,指标波动越小,指标越稳定。从表1中对比发现,排序信息散度指标的稳定性最好,其次为排序熵和小波熵,近似熵的稳定性最差。从计算时间上来看,排序熵的运算时间最短,其次为本文提出的排序信息散度指标,它保留了排序模式分析的计算简单高效的优势,而近似熵和小波熵则由于运算过程复杂和分解过程耗时,计算效率较低。
4 结论
(1)从时间序列相似性分析角度出发,基于排序模式分析理论和信息散度,定义了一种新的排序信息散度指标作为轴承运行状态的监测指标,用以实现轴承不同损伤程度评估和全寿命退化趋势评估,本文所提新指标是对现有状态监测指标的有力补充。
(2)与传统时域统计指标及近似熵、排序熵、小波熵等指标比较发现,排序信息散度指标能够更加有效地量化不同损伤程度,对早期故障退化更加敏感,稳定性更好。
(3) 排序信息散度继承了排序模式分析方法概念简单、运算量小的优点,因此,其计算复杂度也大大降低,运算速度更快,非常适合于轴承运行状态的实时监测和在线故障检测与健康评估。
下一步研究计划是对所提新指标进行更多健康评估实验验证,并构建预测模型开展机械设备剩余寿命预测研究。
[1] 曾庆虎, 刘冠军, 邱静. 基于小波相关特征尺度熵的预测特征信息提取方法研究[J]. 中国机械工程, 2008,19(10): 1193-1196. ZENG Qinghu, LIU Guanjun, QIU Jing,et al. Researchon Approach of Prognostics Feature Information Extraction Based on Wavelet Correlation Feature Scale Entropy [J]. China Mechanical Engineering,2008,19(10):1193-1196.
[2] 印欣运, 何永勇, 彭志科, 等. 小波熵及其在状态趋势分析中的应用[J]. 振动工程学报, 2004, 17(2): 165-169. YIN Xinyun, HE Yongyong, PENG Zhike,et al. Study on Wavelet Entropy and Its Applications in Trend Analysis[J]. Journal of Vibration Engineering, 2004, 17(2): 165-169.
[3] JANJARASJITT S, OCAK H, LOPARO K A. Bearing Condition Diagnosis and Prognosis Using Applied Nonlinear Dynamical Analysis of Machine Vibration Signal[J]. Journal of Sound and Vibration, 2008, 317(1): 112-126.
[4] YAN R, GAO R X. Approximate Entropy as a Diagnostic Tool for Machine Health Monitoring[J]. Mechanical Systems and Signal Processing, 2007, 21(2): 824-839.
[5] 孟宗,胡猛, 谷伟明, 赵东方. 基于LMD多尺度熵和概率神经网络的滚动轴承故障诊断方法[J]. 中国机械工程, 2016, 27(4): 433-437. MENG Zong, HU Meng, GU Weiming, et al. Rolling Bearing Fault Diagnosis Method Based on LMD Multi-scale Entropy and Probabilistic Neural Network[J]. China Mechanical Engineering, 2016, 27(4): 433-437.
[6] 谢平, 江国乾, 武鑫, 等. 基于多尺度熵和距离评估的滚动轴承故障诊断[J]. 计量学报, 2013, 34(6): 548-553. XIE Ping, JIANG Guoqian, WU Xin,et al. Rolling Bearing Fault Diagnosis Based Multiscale Entropy and Distance Evaluation[J]. Acta Metrologica Sinica,2013, 34(6): 548-553.
[7] BANDT C, POMPE B. Permutation Entropy: a Natural Complexity Measure for Time Series[J]. Pysical Review Letters, 2002,88(17): 1-4.
[9]YANR,LIUY,GAORX.PermutationEntropy:aNonlinearStatisticalMeasureforStatusCharacterizationofRotaryMachines[J].MechanicalSystemsandSignalProcessing, 2012, 29: 474-484.
[10] 冯辅周, 司爱威, 饶国强, 等. 基于小波相关排列熵的轴承早期故障诊断技术[J]. 机械工程学报, 2012, 48(13): 73-79.FENGFuzhou,SIAiwei,RAOGuoqiang,etal.EarlyFaultDiagnosisTechnologyforBearingBasedonWaveletCorrelationPermutationEntropy[J].JournalofMechanicalEngineering, 2012, 48(13): 73-79.
[11] 谢平, 江国乾, 李兴林, 等. 本征时间尺度排序熵及其在滚动轴承故障诊断中的应用[J]. 燕山大学学报, 2013, 37(2): 179-184.XIEPing,JIANGGuoqian,LIXinglin,etal.IntrinsicTimeScalePermutationEntropyandItsApplicationtoBearingFaultDiagnosis[J].JournalofYanshanUniversity,2013, 37(2): 179-184.
[12] 郑近德, 程军圣, 杨宇. 多尺度排列熵及其在滚动轴承故障诊断中的应用[J]. 中国机械工程, 2013, 24 (19): 2641-2646.ZHENGJinde,CHENGJunsheng,YANGYu.MultiscalePermutationEntopyandItsApplicationtoBearingFaultDiagnosis[J].ChinaMechanicalEngineering,2013, 24 (19): 2641-2646.
[13]TOPSØEF.SomeInequalitiesforInformationDivergenceandRelatedMeasuresofDiscrimination[J].InformationTheory, 2000, 46(4): 1602-1609.
[14]TheCaseWesternReserveUniversityBearingDataCenterWebsite.BearingDataCenterSeededFaultTestdata[EB/OL].(2008-01-01)[2010-11-05].http://csegroups.case.edu/bearingdatacenter/pages/download-data-file.
[15]QIUH,LEEJ,LINJ,etal.WaveletFilter-basedWeakSignatureDetectionMethodandItsApplicationonRollingBearingElementBearingPrognostics[J].JournalofSoundandVibration,2006,289:1066-1090.
(编辑 苏卫国)
Bearing Health Monitoring Based on Ordinal Pattern Dissimilarity Analysis
JIANG Guoqian XIE Ping WANG Xiao HE Qun LI Jimeng
School of Electrical Engineering,Yanshan University,Qinhuangdao,Hebei,066004
Ordinal pattern analysis might map one-dimensional vibration time series into probability distribution of ordinal patterns in the high-dimensional phase space, and then reveal the internal tiny variations in ordinal pattern structures. It provided a new research view for the weak vibration signal feature extraction. A new monitoring indicator named ordinal information divergence was proposed herein based on ordinal pattern analysis and information divergence, to quantitatively describe the ordinal pattern distribution difference of vibration signals in the high-dimensional phase space between the current status and the reference health status. Two experiments, including the damage degree assessment of bearing inner race and the run-to-failure bearing degradation trend analysis, were used to validate the effectiveness of the proposed new indicator. The comparative studies were performed with the traditional statistics and several existing nonlinear indicators including wavelet entropy, approximate entropy and permutation entropy. Experimental results demonstrate that the proposed new indicator presents better quantitative ability for different damage degrees and is more sensitive to the incipient fault and more stable and efficient in computation, thus easy to implement in engineering applications.
ordinal pattern analysis; information divergence; condition monitoring; rolling bearing
2016-04-05
河北省高等学校科学技术研究重点项目(ZD20131080);国家自然科学基金资助项目(51505415);河北省自然科学基金资助项目(F2016203421);中国博士后科学基金资助项目(2015M571279)
TP206DOI:10.3969/j.issn.1004-132X.2017.06.013
江国乾,男,1987生。燕山大学电气工程学院博士研究生。主要研究方向为机械设备健康监测及诊断。发表论文6篇。E-mail:jgq870706@126.com。谢 平,女,1972年生。燕山大学电气工程学院教授、博士研究生导师。王 霄,男,1982年生。燕山大学电气工程学院博士研究生。何 群,男,1969年生。燕山大学电气工程学院副教授。李继猛,男,1984年生。燕山大学电气工程学院讲师。
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
四川大学学报(自然科学版)(2021年4期)2021-07-15
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
装甲兵工程学院学报(2017年3期)2017-07-05
