
基于MapReduce框架的航班串编制算法
2017-03-29 05:00:18王伟杰
计算机技术与发展 2017年3期
张 康,喻 瑛,王伟杰
(上海大学 机电工程与自动化学院,上海 200072)
基于MapReduce框架的航班串编制算法
张 康,喻 瑛,王伟杰
(上海大学 机电工程与自动化学院,上海 200072)
为解决小规模航班串编制问题,提出一种简单的非分布式算法,并在单机运行平台进行测试。然而,随着民航企业的迅速发展,航班数量不断增加,非分布式的航班串编制算法已经无法满足实际生产需求。为解决大规模航班串编制问题,提出另外两种基于MapReduce框架的分布式航班串编制算法。第一种算法将简单的非分布式算法扩展到MapReduce框架,解决大规模航班串编制问题;第二种算法在第一种算法的基础上进一步改进,优化Map和Reduce的处理流程,删除第一种算法中的迭代过程,充分发挥MapReduce框架的批处理优势。搭建Hadoop平台进行验证,实验结果表明,提出的两种分布式算法中,第二种算法即改进后的分布式算法,较之简单的非分布式算法和第一种分布式算法,能够有效提高大规模航班串编制效率。
MapReduce框架;Hadoop平台;航班串编制;大数据
0 引 言
飞机排班是民航企业制定生产计划的一项基本内容,排班人员根据航班计划和飞机维修计划以及商务部提供的航班连线信息、航站信息、飞机本身信息等,给出飞机调度决策,为每个运营航班指定一架具体执行的飞机。2010年以来,随着中国经济的快速发展,在市场需求旺盛和人民币持续升值的双重利好下,中国民航经历了新一轮的发展高峰。单就2015/2016年冬春航季,根据中国民航排定的航班计划,在国内航班方面,国内39家航空公司每周共安排的航班数量高达54 956班次,比2014/2015年冬春航季增长6.2%。
航班串编制[1-2]是飞机排班的核心工作。随着航班规模逐年扩大,民航企业传统上使用的非分布式航班串编制的方法已经无法满足实际生产需求,从而需要一种更高效的计算机技术处理大规模航班串编制问题。近年来,Hadoop分布式计算平台在处理大规模数据问题上表现出了显著优势,吸引了产业界、政府和学术界的广泛关注。
Hadoop[3-5]是Apache软件基金会旗下的一个开源分布式计算平台,已成为大数据分析的主流框架。针对Hadoop的研究与应用的相关工作正在积极展开。文献[6]探讨了蚁群算法的几种并行方式与适用场景以及结合MapReduce编程框架的可行性。文献[7]利用MapReduce并行编程模式,提出了一种基于Hadoop平台的高效、可扩展并行挖掘算法,节省了因大数据挖掘过程中产生的大量数据通信、中间数据以及执行大量交集操作而产生的时间耗费。文献[8]给出了基于MapReduce的计算等价类的数据约简算法与朴素贝叶斯分类算法,实现了气象数据挖掘研究。文献[9]利用Hadoop平台对医保数据进行挖掘,利用MapReduce编程方法实现并行挖掘,基于Hadoop平台的医保数据挖掘。文献[10]基于列存储数据库Hbase的存储模型,提出了一种MapReduce框架下的分布式关联规则挖掘算法(MCM-Apriori算法),并进一步将改进MCM-Apriori算法应用于基于Hadoop云平台的网上图书销售系统。
文中研究了基于MapReduce框架的航班串编制问题,提出一种简单非分布式算法,并与两种分布式算法进行对比。搭建一主两从Hadoop平台,分别进行不同规模的航班串编制,比较三种算法的性能。
1 相关理论
1.1 航班串编制数学模型
作如下定义(以下所有定义的变量均考虑的是一个排班周期内,规定一天为一个排班周期):
U为航班集合,ui为U中第i个航班;
Q0为航班串集合;
Qui为以航班ui为起始航班的航班串,Qui∈Q0;
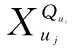
qk为航班串中的第k个航班;
taqk为航班qk的到港时间;
tdqk为航班qk的离港时间;
aaqk为航班qk的到港机场;
daqk为航班qk的离港机场;
t0为完成一次过站作业所需的最短时间。
航班串编制数学模型可以描述为:
(1)
s.t.
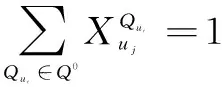
(2)
taqk+t0≤tdqk+1
(3)
aaqk=daqk+1
(4)

1.2 Hadoop平台
Hadoop基于Java语言开发,运行在Linux操作系统之上,核心是HDFS和MapReduce。其中HDFS负责的是大规模数据的存储,MapReduce负责数据的并行计算。Hadoop基于主从式架构,通过Namenode、Datanode、Jobtracker和Tasktracker管理,主要特性是移动计算,而不是移动数据。计算前,Namenode分析程序需要的数据存储在集群中的哪些Datanode节点;Jobtracker将MapReduce计算任务分配给这些节点上的Tasktracker;Tasktracker启动Map程序,开启计算任务;经过Combiner、Shuffle等过程,在Reduce阶段生成计算结果[11]。
1.3 MapReduce框架
MapReduce[11-12]分布式编程模型允许用户在不了解分布式系统底层细节的情况下开发并行应用程序。作为一种海量数据处理的并行编程模型,MapReduce将分布式编程分为Map(映射)和Reduce(归约)两个阶段,Map函数负责分块数据的处理,Reduce函数负责对分块数据处理的中间结果进行归约。
MapReduce框架运行应用程序的过程如下:
(1)输入文件被分成固定大小(默认为64 MB,用户可以调整)的M个分片(split)。Master节点会尽量将任务分配到离输入分片较近的节点上执行,以减少网络通信量。
(2)在Map阶段,MapReduce模型以一组(key1,value1)作为Map函数的数据输入,经过映射,聚合所有具有相同的key值的中间结果,产生一组中间结果list(key2,value2),中间结果存储在本地磁盘上。
(3)在Reduce阶段,所有Map中输出的数据经过分区、混洗、排序后都传入到Reduce函数,函数把具有相同key值的中间结果进行合并产生结果(key2,list(value2)),最终生成输出文件。
2 航班串编制算法
文中提出的三种航班串编制算法如下:
算法1:不使用MapReduce框架的简单算法。
算法2:基于MapReduce框架对算法1进行扩展。
算法3:在算法2的基础上进行改进。
使用的原始航班数据中包括航班号、离港机场、到港机场、离港时间和到港时间等航班信息。为方便起见,使用表1中的形式。其中,离港时间“0725”,表示该航班的离港时间为7点25分。
航班衔接需要考虑两个约束关系。约束1为机场衔接约束,即同一航班串中的前一航班的到港机场必须是下一航班的离港机场。约束2为过站时间约束,即同一航班串中的后一航班的离港时间与前一航班的到港时间之差必须大于等于飞机完成一次过站操作的时间。
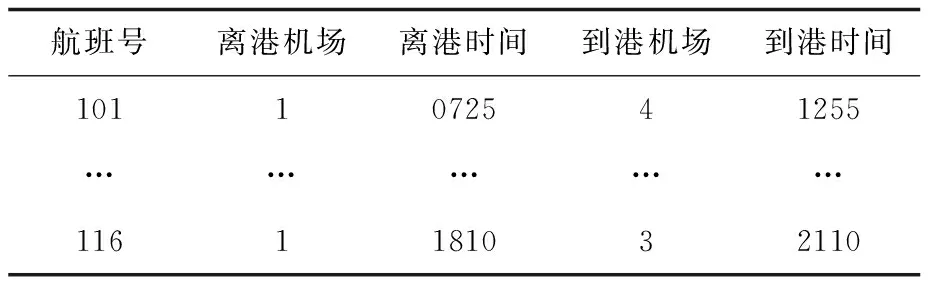
表1 原始航班数据
文中某个航班的后续航班指与该航班同时满足约束1与约束2,即该航班组成航班串的航班;后续航班集合为该航班所有后续航班的集合。
定义n为U中的航班数量,ui为U中的第i个航班;Qui为以航班ui为起始航班的航班串;Fui为航班ui的后续航班集合;子函数followFlightSet生成后续航班集合;子函数generate生成航班串。
2.1 算法1
算法1的航班串编制模型,输入文件为表1所示的原始航班数据。首先,航班集合U中的航班,均要从航班集合中选择与该航班同时满足约束1和约束2的航班,生成该航班的后续航班集合。然后,对U中的航班依次调用递归函数generate。generate中,依次判断航班集合中的航班是否属于该航班的后续航班集合;如果是,则将搜索到的航班加入以该航班为起始航班的航班串中,同时,将搜索到的航班标记为当前航班,继续调用递归函数generate;直至搜索完航班集合中的航班。
算法1的具体步骤如下:
(1)i=1;
(2)调用子函数followFlightSet(ui,U),生成ui的后续航班集合Fui;
(3)i=i+1;
(4)如果i≤n+1,转到(2);
(5)i=1;
(6)q=ui,j=1,U'=U;
(7)调用子函数generate(Qui,q,j,U'),生成以航班ui为起始航班的航班串Qui;
(8)i=i+1;
(9)如果i≤n+1,转到(6);
(10)输出航班串集合;
(11)算法结束。
2.1.1followFlightSet函数的伪代码
输入参数:航班ui、航班集合U;
输出参数:ui的后续航班集合Fui、followFlightSet(ui,U)。
begin
Fui=∅;
j=1;
whilej≤ndo//搜索U中所有的航班uj
ifuj与ui同时满足约束1和约束2then//如果uj是ui的后续航班
Fui=Fui∪{uj}; //将uj加入Fui中
endif
j=j+1;
endwhile
returnFui;
End
使用子函数followFlightSet对表1所示的原始航班数据进行处理,生成如表2所示的数据形式,即生成各个航班的后续航班集合。

表2 预处理后的航班数据
2.1.2generate函数的伪代码
输入参数:q为待处理航班串Qui中的当前尾航班;j为U中航班编号;航班集合U',U'=U;
输出参数:ui为起始航班的航班串Qui;generate(Qui,q,j,U')
begin
whilej≤ndo//搜索U'中所有的航班uj
ifuj∈Fqthen//如果航班uj是Fq中的航班
Qui=Qui∪{uj}; //将航班uj加入航班串集合Qui中
U=U/{uj}; //集合U去掉航班uj
q=uj; //更新航班串Qui中的当前尾航班
j=1;
U'=U;
generate(Qui,q,j,U'); //继续调用generate函数
else//如果航班uj不是Qui中的航班,继续判断下一个航班
j=j+1;
endif
endwhile
end
2.2 算法2
算法2使用MapReduce框架对算法1进行扩展。将算法1的步骤进行拆分,算法1中生成各个航班的后续航班集合的步骤,在算法2中的预处理中实现;算法1中生成航班串的步骤,在算法2的Reduce函数中实现。
(1)Main函数。
算法2的Main函数包含四个步骤。第一步,对原始航班数据进行预处理,生成各航班的后续航班集合;第二步,分配Map函数;第三步,分配Reduce函数;第四步,输出航班串。
(2)Map函数。
Map函数,输入格式为
(3)Reduce函数。
Reduce函数,输入数据为MapReduce框架对Map阶段输出的中间结果进行分区、混洗、排序后的数据,即键相同的值的集合。Reduce函数的输入格式为
具体步骤如下:
(1)i=1;
(2)q=ui,j=1,U'=U;
(3)调用子函数generate(Qui,q,j,U'),生成以航班ui为起始航班的航班串Qui;
(4)i=i+1;
(5)如果i≤n+1,则转到(2),否则,进入下一步;
(6)Reduce函数输出航班串集合;
(7)结束。
2.3 算法3
算法3在算法2的基础上进一步改进,去除算法2中的递归等操作,简化Reduce函数,降低运算时间。
(1)Main函数。
Main函数中,首先对原始航班数据进行预处理,初始flag=0。然后,判断标记flag,如果flag==1,则需要继续分配Map和Reduce函数;否则,不需要分配新的Map和Reduce函数。具体步骤如图1所示。
(2)Map函数。
Map函数,输入格式为
(3)Reduce函数。
Reduce函数,输入数据为MapReduce框架对Map阶段输出的中间结果进行分区、混洗、排序后的数据,即键相同的值的集合。Reduce函数的输入格式为
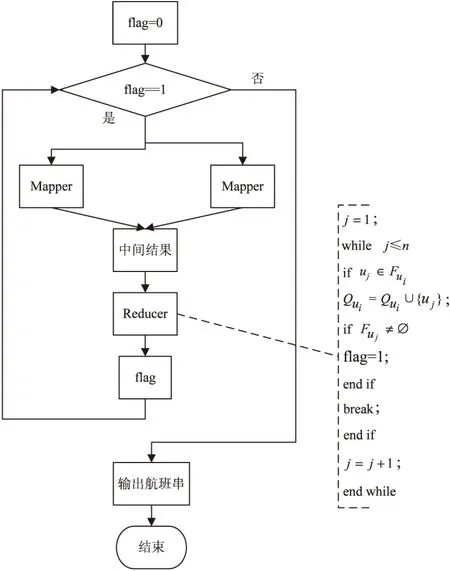
图1 算法3的流程图
3 算例分析
文中搭建的Hadoop集群,主节点(Namenode)命名为master,从节点(Datanode)分别命名为node1和node2,如图2所示。三台计算机内存均为2G,使用的Linux版本为Ubuntu-14.04.2desktop,Java版本为jdk-6u45-linux-x64,Hadoop版本为hadoop-2.6.0。
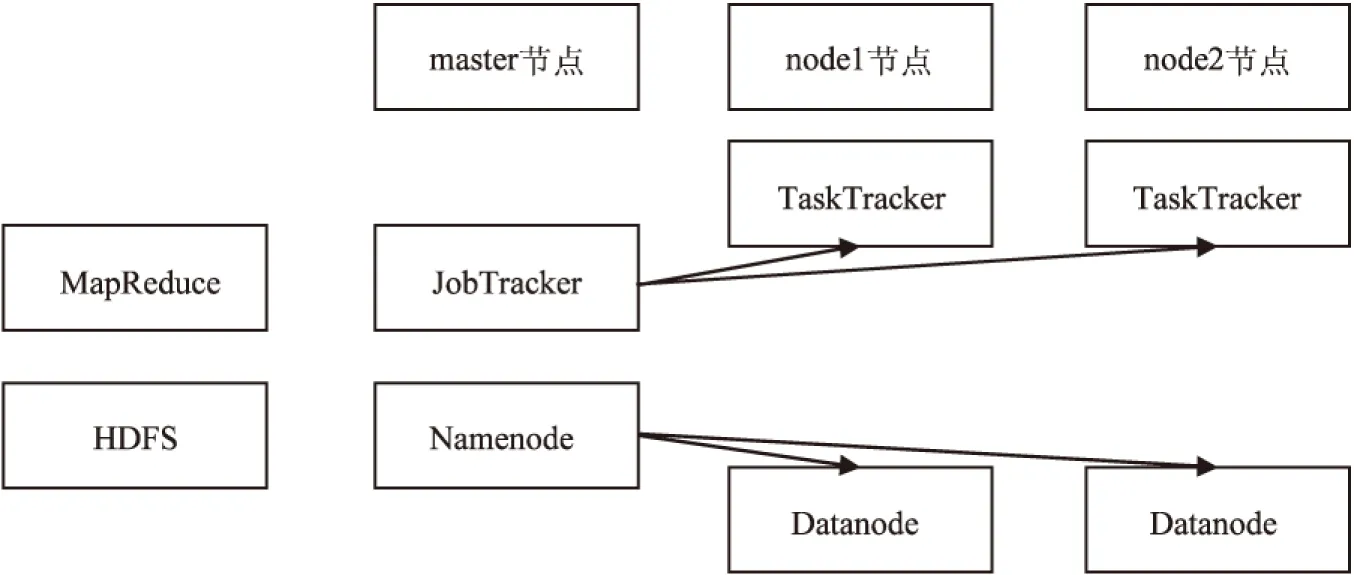
图2 一主两从Hadoop架构
分别实现三种航班串编制算法,测试相同航班数量下的运行时间。然后,逐步扩大航班规模,测试三种算法的运行时间。实验结果如表3所示。
从表3可知,算法1只适用于处理航班数量低于3 000时的航班串编制问题,当航班规模为4 000时,编制航班串的运算时间大于9个小时,是实际生产中无法接受的。算法2中,由于Reduce函数逻辑复杂,当航班数量为4 000时,消耗的时间为8 530 844ms,虽然少于算法1,但是远高于算法3。当航班数量小于1 000时,算法3的运算时间大于算法1和算法2;当航班数量大于2 000时,算法3的运算时间小于算法1和算法2;尤其当航班数量大于4 000时,算法3的运算时间远小于算法1和算法2。由此说明算法3在航班数量较大时,运算时间少,运行效率高。
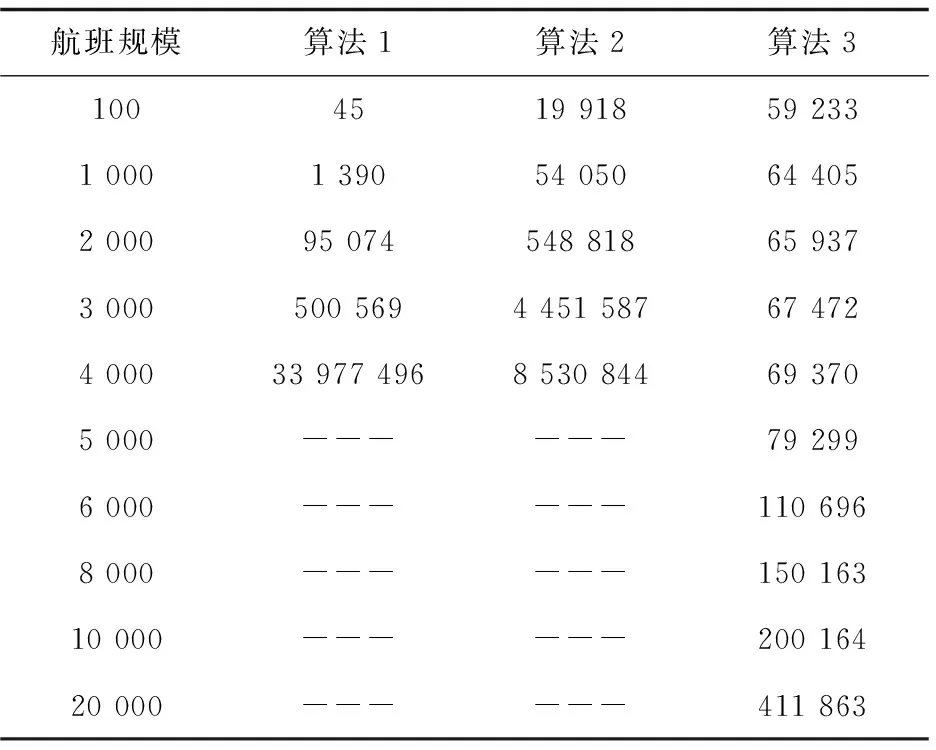
表3 不同算法的运行时间 ms
4 结束语
文中提出了三种航班串编制算法。算法1为不使用分布式框架的简单算法,编制小规模航班串的效率高于算法2和算法3,但是不适用于编制大规模航班串。算法2在算法1的基础上进行扩展,使用分布式MapReduce框架,将算法1的步骤拆分,利用了其处理大数据的特点,编制大规模航班串的效率高于算法1。算法3对算法2进行改进,去除了递归过程,简化了Map和Reduce阶段的流程,编制大规模航班串的效率远高于算法1和算法2。算法3充分发挥了MapReduce框架批处理和大数据处理的优势,做到了扬长避短,提高了大规模航班串的编制效率,为民航企业进行航班串编制提供了一种切实可行的方案。
[1] 李耀华,谭 娜,郝贵和.飞机排班航班串编制模型及算法研究[J].系统仿真学报,2008,20(3):612-615.
[2] 付维方,张伟刚,孙春林.航班排班中航班串生成与筛选问题的算法与实现[J].中国民航学院学报,2006,24(5):4-6.
[3]WhiteT.Hadoop权威指南[M].周敏奇,王晓玲,金澈清,等,译.第2版.北京:清华大学出版社,2011.
[4]RangerC,RaghuramanR,PenmetsaA,etal.EvaluatingMapReduceformulti-coreandmultiprocessorsystems[C]//Highperformancecomputerarchitecture.[s.l.]:[s.n.],2007:13-24.
[5]DeanJ,GhemawatS.Mapreduce:aflexibledataprocessingtool[J].CommunicationsoftheACM,2010,53(1):72-77.
[6] 王诏远,李天瑞,易修文.基于MapReduce的蚁群优化算法实现方法[J].计算机科学,2014,41(7):261-265.
[7] 吕婉琪,钟 诚,唐印浒,等.Hadoop分布式架构下大数据集的并行挖掘[J].计算机技术与发展,2014,24(1):22-25.
[8] 张晨阳,马志强,刘利民,等.Hadoop下基于粗糙集与贝叶斯的气象数据挖掘研究[J].计算机应用与软件,2015,32(4):72-76.
[9] 梁 瑜.基于Hadoop平台的医保数据挖掘[D].沈阳:东北大学,2012.
[10] 郭 健,任永功.云计算环境下的关联挖掘在图书销售中的研究[J].计算机应用与软件,2014,31(11):50-53.
[11]DeanJ,GhemawatS.MapReduce:simplifieddataprocessingonlargeclusters[J].CommunicationsoftheACM,2008,51(1):107-113.
[12]DeanJ,GhemawatS.MapReduce:simplifieddataprocessingonlargeclusters[C]//Proceedingsofthe6thconferenceonsymposiumonoperatingsystemsdesign&implementation.Berkeley,CA,USA:USENIXAssociation,2004.
Flight String Compilation Algorithm Based on MapReduce Frame
ZHANG Kang,YU Ying,WANG Wei-jie
(Institute of Electromechanical Engineering and Automation,Shanghai University,Shanghai 200072,China)
A simple algorithm without distribution is proposed to solve the small scale flight string compilation problem and tested on stand-alone operation platform.However,with the rapid development of civil aviation enterprises and the rising number of flights,the simple algorithm has been unable to meet the requirement of practical production.Two new distributed flight string compilation algorithms based on MapReduce frame are proposed.The first one is extended from the simple algorithm to solve the large scale flight string compilation problem.And the second is made further improvements on the basis of the former where the processes of Map and Reduce are simplified and the iteration is deleted.A Hadoop platform is constructed to verify these algorithms.Results shows that compared to the simple algorithm and the first distributed algorithm,the second improved algorithm could effectively improve the efficiency of compiling flight string with large scale flights.
MapReduce framework;Hadoop platform;flight string compilation;big data
2016-04-16
2016-08-10
时间:2017-02-17
上海市2015年度“科技创新行动计划”高新技术领域项目(15511109700)
张 康(1991-),男,硕士研究生,研究方向为项目调度;喻 瑛,副教授,通讯作者,研究方向为不确定理论及其应用、项目优化调度、可靠性研究。
http://www.cnki.net/kcms/detail/61.1450.TP.20170217.1623.020.html
TP305
A
1673-629X(2017)03-0142-05
10.3969/j.issn.1673-629X.2017.03.029
猜你喜欢
环球时报(2023-01-12)2023-01-12 15:13:44
价值工程(2022年15期)2022-07-13 05:37:08
金桥(2021年10期)2021-11-05 07:23:10
金桥(2021年8期)2021-08-23 01:06:24
金桥(2021年7期)2021-07-22 01:55:10
中国民航大学学报(2020年6期)2021-01-21 13:58:38
能源(2017年10期)2017-12-20 05:54:07
环球时报(2017-12-11)2017-12-11 06:24:20
能源(2017年5期)2017-07-06 09:25:54
雷达与对抗(2015年3期)2015-12-09 02:38:50
