
语音信号的分块稀疏表示分类研究
2017-03-29 04:59冯玉田李园辉
计算机技术与发展 2017年3期
毕 超,冯玉田,李园辉,王 瑞
(上海大学 通信与信息工程学院,上海 200444)
语音信号的分块稀疏表示分类研究
毕 超,冯玉田,李园辉,王 瑞
(上海大学 通信与信息工程学院,上海 200444)
传统稀疏表示分类算法(SRC)在处理复杂多维的向量的时候,需要对稀疏后的每个信号单独处理求残差,会导致处理时间过长,无法有效地运用于实际的工程应用中。为解决这一问题,提出将图像处理的分块稀疏应用于语音稀疏表示分类的方法。该方法在传统稀疏表示分类的基础上,引入分块稀疏思想,将语音信号按指定的长度处理,从而将若干个稀疏系数组成稀疏组来进行进一步分类识别。验证实验表明,源于图像处理的分块稀疏表示分类法同样适用于语音信号的处理。实验结果表明,在识别率接近的情况下,语音信号分类识别所花费的时间比图像处理明显降低。这是因为图像稀疏分类的系数之间相关性较强,因而分类的识别率较高;而语音信号是典型的非平稳过程,各种特征参数随时间快速变化,因而根据长度分类的相关性显著减少。因此,语音信号识别的准确率虽然会有所降低,但其效率显著提升。
稀疏表示分类;分块稀疏;声频传感器;语音信号处理
0 引 言
传统的信号采集来源于模拟系统,采集的信号是一个连续的模拟信号,传统的奈奎斯特采样定理需要根据原始信号的带宽大小决定采样频率,而随着信息技术的飞速发展,数据量的急剧增大,带宽也不断变大,因此对于设备的要求也越来越高,迫切需要一种新的信号采集方法。在这样的背景下,压缩感知理论一经提出便受到了广泛研究,研究信号的稀疏表达的目的是寻求信号在某一特定空间下的某种基的最优逼近,将原来的连续信号转化成只有若干个参数的信号,通过降维来提供一种直接、简便的分析方式。信号变换的本质就是透过不同角度不同方式去观察和认识一个信号。信号的稀疏表示就是在变换域上用尽量少的基函数来表示原始信号。而分类问题一直是机器学习和模式识别研究的一个焦点问题,各种研究成果层出不穷。近年来,由于压缩感知技术的提出和研究的深入,产生了一种新的基于稀疏表示的分类方法,即稀疏表示分类[1](SRC)。该方法一经提出,立刻在图像识别领域产生了巨大影响,并引入到了音频[2]等多个领域。但是稀疏表示分类方法更多地用于科学研究过程中,在实际应用中并不广泛,主要是因为这种方法在处理大样本时运算复杂度过高,耗费的时间过长。
文中在稀疏表示分类的基础上,对原始的训练样本,采用分块稀疏的思想,将训练样本和测试样本按照预先设定好的分块数量进行等大小地划分,对各个分块进行稀疏表示分类。实验中,通过在原始样本中取不同的组长度进行分块后,结合语音信号样本,再对各种稀疏表示方法的实验比较来证明分块稀疏表示分类对于语音信号分类的有效性和合理性。
1 SRC算法
稀疏表示分类算法的本质是用尽可能少的能包含原始信号绝大多数信息的非零系数构成的矩阵来表示原始信息。这是基于压缩感知理论引申而来的一种算法,由Wright J等[1]在图像领域最先提出,并取得了不错的实验效果,其基本原理如下:
(1)输入一个包含L个类的训练矩阵D=[D1,D2,…,DL]∈RM×N,再输入一个训练样本y∈RM,以及一个可选的容错度ε,其中ε>0。
(2)归一化D的列,得到单位2范数。
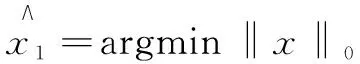
(1)
由于N>M,此式是个无穷解问题,即NP问题,难以求得满足条件的最稀疏解。E.Candes[3]提出,在满足一定条件下,可以用1代替0,由于求解1是一个凸松弛的问题,可以采用线性算法进行求解。所以式(1)也能转化成解决1范数最小化的问题:
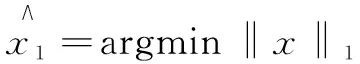
(2)
在实验中考虑到误差的影响,求解式变为:
(3)
SRC算法将原始数据进行特征提取之后,将训练集构成冗余字典,实现测试集的稀疏表示,得到了不错的识别效果。但是对于整个算法的步骤进行观察分析可以发现,在将测试集映射到训练集的过程中,需要遍历训练集的每个向量来计算残差,使得计算复杂度非常高,无形中也增加了将稀疏表示分类算法推广到实际工程领域的困难度。
近些年,由于结构化稀疏思想的提出,将训练集和测试集按照一定的结构进行处理,再将其用于稀疏重构领域中,获得了比稀疏重构更理想的效果。
文中基于结构化稀疏的思想,将分块和若干稀疏重构算法相结合,配合稀疏表示分类算法,得到若干种分块稀疏表示分类算法。通过实验将这些分块稀疏表示分类算法与传统的未分块稀疏表示分类的识别率和识别速度进行对比,以显示其优越性。
2 分块稀疏表示分类
2.1 分块稀疏思想
传统的稀疏表示分类将稀疏性作为唯一的先验信息,而忽略了样本之间的内在联系。而在实际中,非零元的出现往往是相关的,结构化稀疏正是利用了这一点,将结构先验的知识运用到这一领域。通过结构化稀疏,将若干具有相似结构的向量,通过取某个特征或者某种计算方法,构成一个新的向量来代替原始向量组,从而缩减解的自由度,减少计算复杂度。目前基于结构化稀疏的研究并不多,主要集中于分块稀疏、树稀疏和组稀疏[4-5]。
分块稀疏是结构化稀疏中最简单的一种,它将若干个连续向量捆绑在一起组成一个块,最终的稀疏结果必然是非零元成块出现,如图1所示[6]。

图1 分块稀疏
在实际中也能找到这样的例子,如图2所示的多频带信号。原始的窄带信号经过高频载波调制以后,窄带信号的频谱相对于高频载波信号是稀疏的,但是每个窄带信号都要占据一段连续的频段[7]。三个载波频率不同的原始射频信号,在接收方会看成是一个多频带的通信信号,实际中信号包含6个频带,而现有的信号发射器的调制技术只确定了最大预期带宽B,而没有考虑到窄带信号内部的这种连续性,这些都为分块稀疏的研究提供了现实意义。
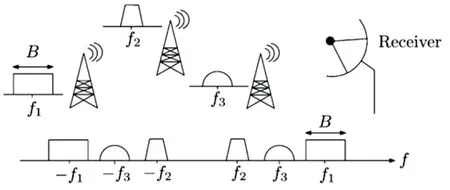
图2 分块稀疏实例(多频带通信信号)
2.2 分块稀疏模型
假设稀疏向量x∈Rn,取块长度为d,d需要满足能被n整除的条件,即n=d×N。这时,就将测试向量分成N块,即:
(4)
显然,当d取1时,分块稀疏就和传统意义上的稀疏一样,因此传统稀疏可以看作是分块稀疏的一种特例。与此同时,也将冗余字典按照d的长度来分块,即将原始的冗余字典A∈Rm×n分解成N个矩阵,每个矩阵的大小是m×d,即:
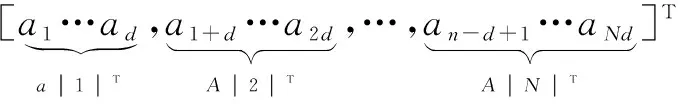
(5)
类似于传统稀疏表示问题,从欠定方程y=Ax寻找x向量的稀疏表示,分块稀疏求解的问题变成了从欠定方程y=Ax中求解块的某个特征值的非零元最小个数。EldarYC[8]等提出了基于块2范数的0范数的优化问题,即
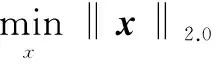
(6)
2.3 分块稀疏方法
文中采用的分块稀疏方法,将原有的训练样本和测试样本按照统一的d进行划分后,以块为单位,和各种稀疏重构算法进行结合,通过和原始测试向量的比较,不断迭代寻找最小的残差,找到模拟识别的类别,最后看与原始训练向量的类别是否相同。经过多次实验,对于声音信号,对该方法的识别率和识别速度相较于未分块稀疏表示分类进行比较。
3 实验与分析
分块稀疏提出在图像处理中[10],为了证明这种方法与声音信号结合后有非常好的效果,文中特别将其用于声频信号处理。实验数据集来源于国防高等研究计划署DARPA/IXOsSensIT计划于2001年9月在美国加州进行的真实世界无限分布传感网络实验时采集的传感器数据,其中包含了两种军事车辆,履带车(AAV)和重型轮式卡车(DW)的声波、地震波和红外波数据[11],该实验通过对声波数据进行处理来对车辆进行识别。
在原始数据样本中,每次独立实验各个样本点的数据并不完全。为保证实验的准确性,文中选取了两类车辆相同车次和相同采样点的数据作为实验原始数据,即取第三辆到第十一辆车的第51,52,53,54,55,56,58,59,60,61个采样点,共180个采样数据,其中采样频率为4 960Hz。由于原始数据过长,这里选择截取前7 000个数据作为改进后的原始数据。实验采用了文献[2]中的声音信号特征提取方法,即梅尔频率倒数(MFCC)提取特征信号。为了证明实验的有效性,将长度D取不同的值,再与传统的贪婪重构算法结合分块稀疏的方法进行对比,以比较其计算效率。
下面简单介绍实验中用到的各种贪婪重构算法:
(1)块正交匹配追踪算法(BOMP)。
正交匹配追踪(OMP)和分块相结合的算法[12],所不同的是将测试样本与分块过后的训练字典以块为单位进行匹配,再进行最小二乘法得出与测试样本最接近的训练块,并一直循环迭代下去,直到误差小于某个设定的值。
(2)组正交匹配追踪算法(GOMP)。
组稀疏又称群稀疏,与传统OMP[13]相比,其主要不同点在于对稀疏系数(向量)进行分组,每组的大小可人为划分。一般的处理方法是先标记后分群,每次迭代取一个群向量绝对值的平均值。
(3)正则化组正交匹配追踪算法(REGOMP)。
这是由正则化正交匹配追踪算法(ROMP)[14]引申出来的一种分块稀疏算法。正则化正交匹配追踪算法流程与OMP的最大不同之处在于选择列向量的标准。OMP每次只选择与残差内积绝对值最大的那一列,而ROMP则是先选出内积绝对值最大的K列(若所有内积中不够K个非零值,则将内积值非零的列全部选出),然后再从这K列中按正则化标准再选择一遍,即为本次迭代选出的列向量(一般并非只有一列)。正则化标准意思是选择各列向量与残差内积绝对值的最大值不能比最小值大两倍以上,且能量最大的一组,因为满足条件的子集并非只有一组。
(4)分段式组正交匹配追踪(STGOMP)。
这是由分段式正交匹配追踪算法(STOMP)[15]引申出来的一种分块稀疏算法。STOMP算法采用分阶段的思想,首先根据相关原则筛选向量,利用阈值的方法从向量集合中选择和迭代余量匹配的向量。与OMP算法不同的是,它并不是每次固定选择一个匹配向量,而是根据输入门限来决定选择向量的范围,同时降低了匹配效率[16]。
最后进行分类实验,在进行实验之前,将待分类样本中的前90个编号设为1,而后90编号设为2。实验中可以将N个值设置为训练样本,那么另外的90-N样本则为测试样本。分类识别具有很大的偶然性,为了尽量避免这种偶然性,实验中采取多次测量求平均值的方法。
将特征提取后的信号在固定的块长度D下分别进行稀疏表示分类,即分别取D=2,D=5和D=10,实验结果如表1~3所示。
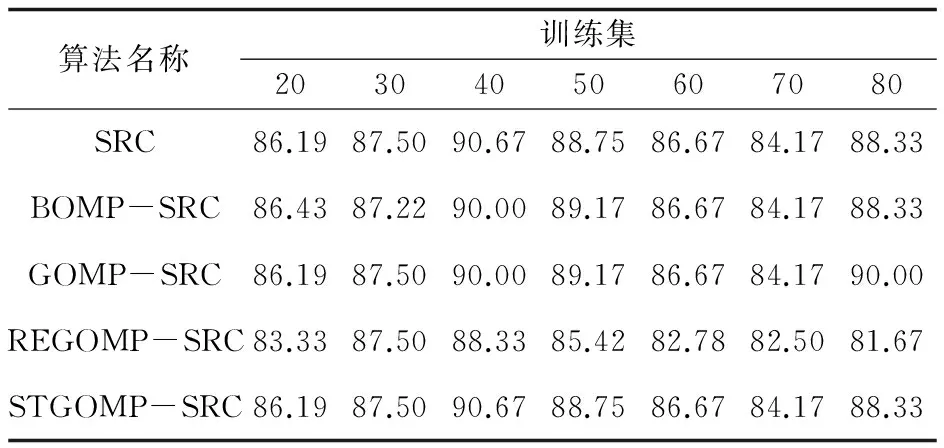
表1 分块稀疏表示分类下的识别率(D=2) %
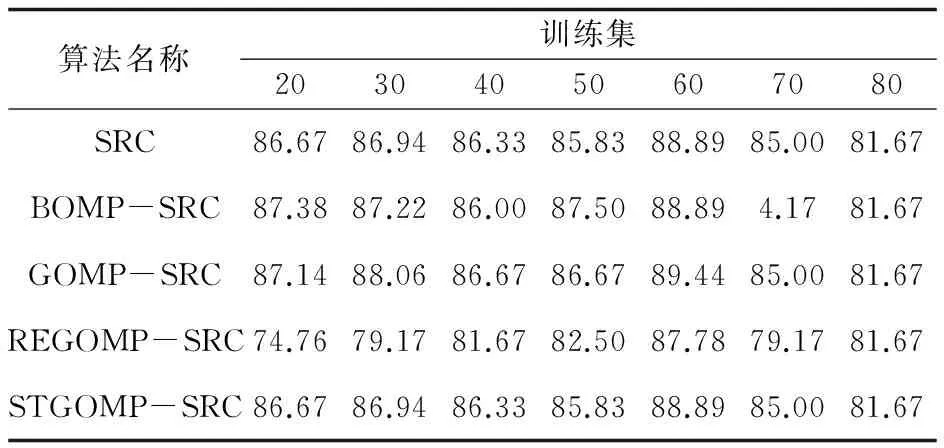
表2 分块稀疏表示分类下的识别率(D=5) %
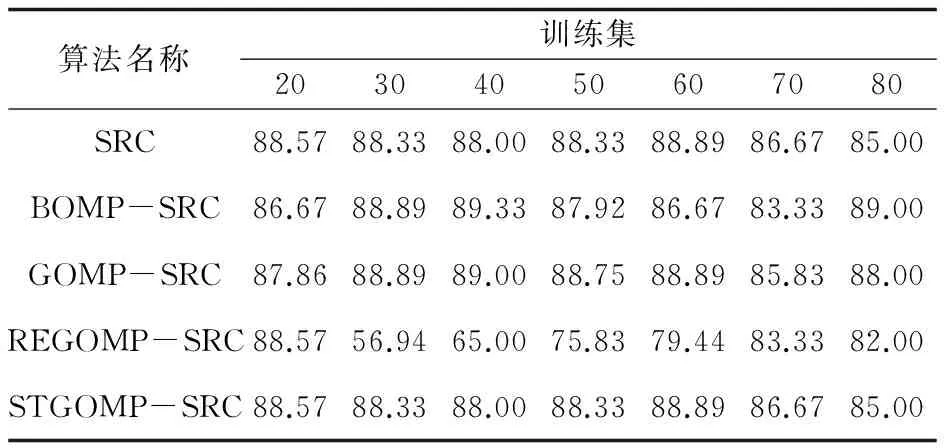
表3 分块稀疏表示分类下的识别率(D=10) %
从实验结果可以看出,除了REGOMP-SRC与原始的SRC算法识别效率差距过大以外,其他的分块稀疏表示分类算法和原始的稀疏表示分类识别效率相近,分块的大小对于识别效率的影响不明显。所以用分块稀疏表示分类来代替传统的稀疏表示分类,从识别效率上看是没有任何问题的。
表4显示了各种分块识别算法相对于原始稀疏表示分类算法在计算时间上的差别。

表4 分块稀疏表示分类下的识别率 s
从表4可以清楚地看出,分块稀疏表示分类所花费的时间相比稀疏表示分类大大下降,这与前面提到的分块可以降低解的自由度相吻合。而且随着块长度D的增加,分块稀疏表示分类的计算时间明显下降。这里可以把原始的SRC看成D=1的方法,则随着D的增加,块的数量减少,遍历的组数减少,自然导致了计算复杂度的下降。其中STGOMP算法由于本身遍历的条件不是误差小于某个固定值,而是有固定的迭代次数,所以这里的计算时间相对变化不大。这也可以看出,迭代次数是影响稀疏表示分类计算复杂度的主要因素。而分块稀疏表示分类正是通过减少迭代次数的方法来提高识别速度的。
4 结束语
文中提出了将分块稀疏思想与声音信号结合加以分类的方法,以解决稀疏表示分类对于实际应用场合识别速度过慢,难以应用到工程项目中的问题。实验结果表明,虽然短时平稳特性使声音信号的相关性相比于图像信号大打折扣,但是通过分块稀疏和多种重构算法相结合的稀疏表示分类算法,大大降低了算法的复杂度,在不降低识别率的情况下,提高了计算效率,十分适合实际工程应用。
[1]WrightJ,YangAY,GaneshA,etal.Robustfacerecognitionviasparserepresentation[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2009,31(2):210-227.
[2]WangK,WangR,FengY,etal.Vehiclerecognitioninacousticsensornetworksviasparserepresentation[C]//IEEEinternationalconferenceonmultimediaandexpoworkshops.[s.l.]:IEEE,2014:1-4.
[3]CandesEJ,RombergJK,TaoT.Stablesignalrecoveryfromincompleteandinaccuratemeasurements[J].CommunicationsonPureandAppliedMathematics,2006,59(8):1207-1223.
[4] 刘 芳,武 娇,杨淑媛,等.结构化压缩感知研究进展[J].自动化学报,2013,39(12):1980-1995.
[5] 曾 辉.压缩感知块稀疏信号重构算法研究[D].湘潭:湘潭大学,2014.
[6] 邹 健.分块稀疏表示的理论及算法研究[D].广州:华南理工大学,2012.
[7]MishaliM,EldarYC.Blindmultibandsignalreconstruction:compressedsensingforanalogsignals[J].IEEETransactionsonSignalProcessing,2009,57(3):993-1009.
[8]EldarYC,MishaliM.Robustrecoveryofsignalsfromastructuredunionofsubspaces[J].IEEETransactionsonInformationTheory,2009,55(11):5302-5316.
[9]ElhamifarE,VidalR.Robustclassificationusingstructured
sparse representation[C]//IEEE conference on computer vision and pattern recognition.[s.l.]:IEEE,2011:1873-1879.
[10] 殷爱菡,姜辉明,朱 明.改进的BOMP算法在人脸识别中的应用[J].计算机工程与应用,2014,50(6):175-178.
[11] Duarte M F,Hu Y H.Vehicle classification in distributed sensor networks[J].Journal of Parallel and Distributed Computing,2004,64(7):826-838.
[12] Eldar Y C,Kuppinger P,Bölcskei H.Block-sparse signals:uncertainty relations and efficient recovery[J].IEEE Transactions on Signal Processing,2010,58(6):3042-3054.
[13] Lozano A C,Swirszcz G,Abe N.Group orthogonal matching pursuit for logistic regression[C]//International conference on artificial intelligence and statistics.[s.l.]:[s.n.],2011:452-460.
[14] Needell D,Vershynin R.Uniform uncertainty principle and signal recovery via regularized orthogonal matching pursuit[J].Foundations of Computational Mathematics,2009,9(3):317-334.
[15] Donoho D L,Tsaig Y,Drori I,et al.Sparse solution of underdetermined systems of linear equations by stagewise orthogonal matching pursuit[J].IEEE Transactions on Information Theory,2012,58(2):1094-1121.
[16] 杨真真,杨 震,孙林慧.信号压缩重构的正交匹配追踪类算法综述[J].信号处理,2013,29(4):486-496.
Investigation of Voice Signal Classification with Block Sparse
BI Chao,FENG Yu-tian,LI Yuan-hui,WANG Rui
(School of Communication and Information Engineering,Shanghai University,Shanghai 200444,China)
In dealing with complex multidimensional vector,traditional Sparse Representation Classification (SRC) has spent too much time on computing the residual error by sparse signal after each individual treatment,which is unable to be applied in practical engineering effectively.In order to solve this problem,the block sparse method of image processing has been introduced to the voice of the sparse representation classification,which is based on the traditional sparse representation classification and merged with idea of block sparse.Audio signal is treated via given length so that a sparse group has been constructed with several sparse coefficients for further classification in the voice field.Validation experiments have been conducted and its results show that block sparse representation classification stemmed from image processing can be applied in speech signal processing and that time consumption of audio signal classification is less than image processing under the condition of the same recognition rate,due to high correlativity among the coefficients of image sparse classification and thus high recognition rate.This is also because speech signal is classical non-stationary process and its characteristic parameters vary with time rapidly,thus the correlativity of classification with length has been reduced significantly.Therefore,although accuracy of speech signal recognition could decrease,recognition efficiency would be exalted notably.
sparse representation classification;block sparse;audio sensor;voice signal processing
2016-05-09
2016-08-11
时间:2017-02-17
国家青年科学基金项目(61301027)
毕 超(1991-),男,硕士研究生,研究方向为压缩感知、语音信号处理;冯玉田,副教授,研究方向为水声学、压缩感知。
http://www.cnki.net/kcms/detail/61.1450.TP.20170217.1632.080.html
TP391.4
A
1673-629X(2017)03-0044-04
10.3969/j.issn.1673-629X.2017.03.009
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
房地产导刊(2022年4期)2022-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用与软件(2020年5期)2020-05-16
新生代(2019年10期)2019-10-18
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
