
基于贝叶斯网络数据挖掘的蔬菜质量安全分析
2017-03-17 11:25方永美熊俊涛杨振刚廖鉴康
湖北农业科学 2016年23期
方永美+熊俊涛+杨振刚+廖鉴康

摘要:蔬菜是人们日常生活的必须品,也是容易出现质量安全问题的产品。影响蔬菜质量安全的一个重要因素就是农药残留问题。以蔬菜农药残留检测数据为对象,利用贝叶斯网络进行数据挖掘,得到不同品种蔬菜的农药残留含量分布,以及同一品种在不同时间的分布趋势,经过可信度分析,该结论可信。该结果可为蔬菜的生产者、消费者以及监管人员提供一定的决策依据。
关键词:数据挖掘;贝叶斯网络;农药残留;质量
中图分类号:TS201.6;R857.3 文献标识码:A 文章编号:0439-8114(2016)23-6253-05
DOI:10.14088/j.cnki.issn0439-8114.2016.23.063
Abstract: Vegetable is one of the necessities of peoples daily life. It is also prone to occurring quality and safety issues. It is pesticide residue that was one of the important factors which effects on the vegetable quality and safety. Bayesian network of data mining technology is applied to mining the limited assay information of vegetable. It got to pesticide residues distribution for varieties of vegetables, and the same vegetable distribution trends in different months. The results are credible and can offer some decision for producers, consumers and supervisors of vegetable quality and safety.
Key words: data mining;bayesian network;pesticide residue;quality
隨着社会的发展和生活水平的提高,人们对蔬菜产品安全的关注与日俱增,影响蔬菜质量安全的一个重要因素就是农药残留问题。以蔬菜农药残留监测为基础的蔬菜安全风险分析作为现代蔬菜安全管理工作的发展方向,正逐步成为各国遵循的准则和行为规范[1]。Li等[2]研究认为,中国食品安全保障体系的标准陈旧且执行不严谨。Rudder[3]通过对蔬菜的销售渠道进行研究发现,农民把蔬菜卖给生产厂商来降低安全责任。
周洁红等[4]以经济学为理论基础,提出了以批发市场为核心实施蔬菜质量安全可追溯体系是现阶段建设蔬菜质量安全管理的最有效方法。刘中华[5]认为供货商对蔬菜质量管理意识的缺乏以及对供货商的约束力不足导致出现差异。樊红平等[6]用系统理论分析了农产品检验检测体系构成及其功能。樊孝凤[7]从信息不对称理论的角度,着重解释了中国蔬菜农残普遍超标的现象。许宇飞[8]认为,对食品安全状态评价应根据各污染物的限量标准进行逐级评价;秦燕等[9]提出运用控制图方法来监测食品安全质量是否处于控制状态。王志刚[10]利用Probit模型对影响消费者农产品质量安全的认知和购买行为的主要影响因素进行了解析。
大部分研究采用传统方法,难以满足对蔬菜农药残留检测数据的深度分析需求。国内开展对DMKD(数据挖掘和知识发现)的研究稍晚,没有形成整体力量[11]。有关蔬菜质量安全方面应用数据挖掘技术的研究鲜见报道[12]。陈晨等[13]采用贝叶斯分类算法,以玉米生长环境和质量数据库为对象,对新生长环境下玉米的生长质量进行挖掘。刘春玲等[14]认为,在农业领域积累的大量农业数据信息中运用数据挖掘是极具应用前景的方案。本研究以山东省烟台市的蔬菜检测数据为对象,运用贝叶斯网络方法进行数据挖掘,得出蔬菜质量安全的规律以及趋势,以期为蔬菜农药残留检测数据分析提供参考。
1 数据获取
数据均来自烟台蔬菜质量安全信息网,数据的时间覆盖范围是从自2006年7月到2013年2月(除2009年9、10月外),共78期抽检信息。记录项目包括检测时间、检测地点、品种、平均酶抑制率和平均合格率。
平均酶抑制率是决定了蔬菜农药残留的量化标准,根据国家颁布的农药残留检测条例,如果检测得出酶抑制率超过50%则认定为农药残留超标,评定结果为不合格。使用Weka3.6[15]作为数据挖掘工具,在对数据进行挖掘前,要对收集的数据进行集中、整合、清理。
对收集的每月原始数据进行集中、整合。把整合后的数据转换成XLS文件,并由XLS文件转换成Weka能识别的CSV文件;通过Weka的Explorer运行CSV文件,并将其另存为ARFF文件。图1是Explorer运行CSV文件后成功读取数据的结果。从图1中可以看到,该文件中数据数量为3 768。
2 数据处理
2.1 属性选择
通过分析原始实例得到5个属性值。
1)地点属性:文化路市场、三环市场、大世界市场、红利市场、前进路市场、新桥市场、烟大市场、祥和市场、宏达市场、其他地点,共10个可取值,是名词性属性,没有残缺值。
2)品种属性:韭菜、黄瓜、生菜、油菜、茼蒿、芹菜、芸菜、菠菜、其他蔬菜,共9个可选值,是名词性属性,没有残缺值。
3)时间属性:2006年7月~2013年2月(除2009年9、10月外),以月为单位,共78个可选值,没有残缺值。
4)平均酶抑制率和平均合格率属性都是数值性属性,区间在[0,100],单位是百分比。
5)平均酶抑制率是根据抽检单位抽检统计而来的直接数据。平均合格率只是平均酶抑制率的另一个反映,因此,平均合格率是冗余属性,在处理过程中不考虑,通过Weka中的Remove按钮删除。处理后,得到4个属性,分别为品种、地点、时间和平均酶抑制率。
2.2 数据清理
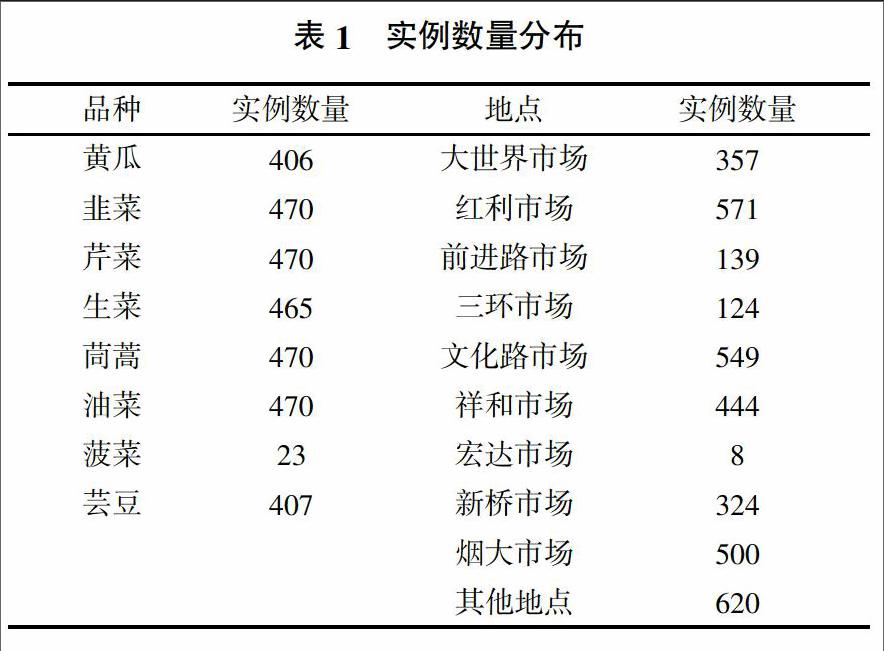
经过检查,实例集中一共有109个残缺值,约占2.9%,且其属性均为平均酶抑制率。黄瓜和芸豆中的平均酶抑制率的残缺值最多,并且多集中在烟大市场、文化路市场;其原因是这两个品种的供应量很少,导致抽检量也少。平均酶抑制率作为类属性,其值的缺失使得该实例失去了参考意义。因此,删除这两个市场的黄瓜和芸豆实例,实例数量分布如表1所示。
對于连续抽检实例集,还需考察各个属性的实例数量比例情况。表1中所示的品种为菠菜、地点为宏达市场的实例数较少,分别只有23个和8个。这2种实例会给挖掘算法带来较大的误差率。通过查初始数据得知,菠菜的抽检只在2006年7月到2006年10月进行,而宏达市场的抽检则只在2007年8月进行。在一共78个抽检月里,这些实例属于少数,从实例的健壮性考虑,删除地点是宏达市场和品种是菠菜的实例。
2.3 属性离散
在进行相关数据挖掘前,对平均酶抑制率进行离散化。由于平均酶抑制率为50%是一个阈值,因此只需进行等区间划分,使用过滤器Discretize功能实现,结果如表2所示。区间内数值的单位是百分比。平均酶抑制率越小,代表其农药残留成分越低。由于平均酶抑制率大于或等于50%的蔬菜不能食用,对区间进行修正。首先,将50以上的三个区间合并成一个区间;其次,要把“-∞”替换成最小值“0”,把“∞”替换成最大值“100”。得到一个四区间的分布。为方便起见,把区间[0,16.666 667)、[16.666 667,
33.333 333)、[33.333 333,50)、[50,100]分别称为A类、B类、C类、D类。A类代表农药残留水平是最低,其次是B类,两者都是可以放心食用的类别。C类是一个警戒的农药残留水平;对于D类,平均酶抑制率超过50%,不能食用。
2.4 数据转换
通过数据转换,得到2个一样的实例集:数值型版本实例集和名词型版本实例集。除了表现形式,其他方面完全一样。名词型版本中,包括品种、地点、年份、月份、平均酶抑制率5个属性;数值型版本中,共有40个属性,其中品种有9个、地点有10个、年份有8个、月份有12个以及平均酶抑制率。得到这2个实例集后,将这些实例的顺序随机打乱,将排序的影响降到最小。用Randomize过滤器进行顺序随机化。
3 蔬菜质量安全趋势的数据挖掘
3.1 运行贝叶斯网络
贝叶斯网络是一种基于统计理论,具有较强理论根基,采用图解方式表达概率分布的方法。贝叶斯网络画出的图形就像是节点网络图,每个节点代表一个属性,节点间用有方向的连线连接着,却不能形成环,是一个有向无环图[15]。
在Weka当中,选取贝叶斯网络分类器(Bayes Net),将初始累计值alpha设置为0.5以避免零频率;选择K2算法并将最大父辈节点数量设为1;在useADTree中选择true,以减少搜索算法重复搜索这个实例集的次数。点击OK按钮,算法开始工作。选择visualize graph,查看到网络结构,如图2所示。
分别运行图2中的平均酶抑制率节点、月份节点、地点节点、品种节点、年份节点,将会出现各属性的概率密度。点击平均酶抑制率节点,出现总体实例集在各个区间的分布概率,其在A类(0,16.666 667)的概率是0.268,B类[16.666 667, 33.333 333)的概率是0.586,C类[33.333 333,50)的概率是0.144,D类[50,100]的概率是0.002。实例大部分处于A、B类,说明蔬菜农药残留程度总体上不高。
3.2 可信度分析
点击Summary,得到贝叶斯网络的基础评估信息,其相关系数达到84.2%,Kappa统计量是70.1%。从正确的肯定率来看,贝叶斯网络对A类的正确肯定率为69.3%,其对A类的错误肯定率只有4.9%。对B类、C类的正确肯定率则较高,分别达到92.6%和78.6%。ROC Area方面,在A类、B类、C类均达到了91%以上,取得比较好的效果。
3.3 蔬菜质量安全分析
3.3.1 单个属性分析 运行图2中的月份节点,得到关于平均酶抑制率在不同月的概率密度,结果如图3所示。从图3分析得到,7、8月的总体平均酶抑制率最高,以其为中轴,其他月的情况逐渐好转。7、8月C类的概率较高;5、6月D类的概率较高。总体来讲,从5月到9月,属于C、D类的概率较大,说明蔬菜的农药残留水平超标的风险增加。这是因为这个时间段气温转高、湿度适宜,是害虫的发育阶段,危害最为严重,相应地,菜农对蔬菜的用药量也大幅度提高。处于一年中的年首和年尾的蔬菜农药残留较低。
运行图2中的地点节点,得到关于平均酶抑制率在不同地点的概率密度,结果如图4所示。从图4可以看出,对于地点而言,祥和市场蔬菜的总体平均酶抑制率偏低。祥和市场中,A类的概率密度远远高于其他市场,其次是烟大市场、新桥市场、大世界市场。高危的是红利市场、文化路市场,在这些地点平均酶抑制率偏高的概率密度较大。尤其是红利市场,C类的实例占到了一半以上。D类的5个实例中有2个就属于红利市场,2个是文化路市场,1个是新桥市场。
运行图2中的品种节点,得到关于平均酶抑制率在不同蔬菜品种间的概率密度,结果如图5所示。从图5可以看出,平均酶抑制率较低的分别是芸豆、生菜、茼蒿以及其他蔬菜;平均酶抑制率较高的分别是韭菜、油菜、黄瓜、芹菜。韭菜属于C类的概率密度超过其他品种。
对于叶菜类蔬菜,如油菜,容易生虫子,对这类虫害的处理方法一般是叶面喷洒农药;因此,叶菜类一般比根茎类蔬菜的农药残留多。黄瓜作为瓜果类蔬菜的一种,比较特殊,由于生长的环境湿度较大,容易生病,对其用药量一般较大。一般认为,像韭菜这类辛辣类蔬菜或者鳞茎类蔬菜具有较好的抗虫害能力;实际上,韭菜的农药残留问题一般比较严重。因为韭菜会受到韭蛆的危害,为了消灭地下的虫害,不得不使用更多剂量的农药;一些菜农甚至采用大面积、大剂量地使用有毒的有机磷农药灌地,从而导致农药残留的情况比较严重。
3.3.2 综合分析 对品种属性与地点属性的关系,以及品种属性与月份属性的关系进行分析。设总体实例关于平均酶抑制率的概率为Pr(总体)(表3),不同蔬菜品种在不同地点的概率为Pr(地点/品种),关于品种的概率为Pr(品种),按照条件概率计算并作归一化处理,分别得到每个市场的各个蔬菜品种的概率。以红利市场为例,分析结果如表3所示。
在红利市场上,韭菜、黄瓜在C类(排名分别为1、2)和D类(排名分别为2、1)排名靠前,而在A类(排名分别为8、7)、B类(排名分别为7、7)的排名靠后,说明这些品种的蔬菜农药残留水平较高,而生菜、芸豆、茼蒿等则相反。
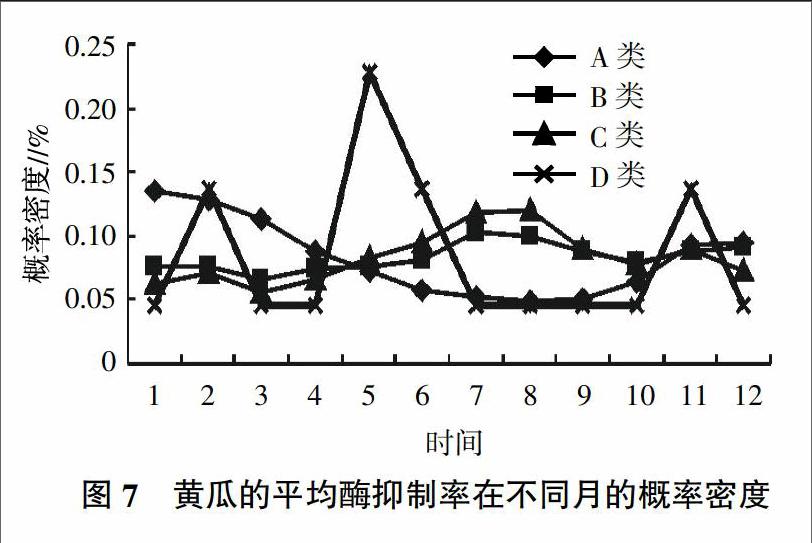
韭菜所含的农药残留总体水平较高,但并不是所有市场上的韭菜的农药残留都高。点击地点、品种属性,从其运行结果中摘录得到韭菜所含农药残留水平在不同市场的分布,如图6所示。从图6可以看出,韭菜实例在祥和市场上属于A类的比例最多,其次是烟大市场。而红利市场最差,其主要属于C类和D类。这表明,即使是同一品种的蔬菜,其在不同市场的平均酶抑制率水平也不相同。
另外,总体较安全的蔬菜,并不是在任何时期都很安全。相同品种的蔬菜,在不同月农药残留水平也不一样。设Pr(总体)、Pr(月份︳品种)和Pr(品种),进行条件概率运算,然后做归一化处理。以黄瓜为例,其趋势如图7所示。从图7中可知,黄瓜的平均酶抑制率在A类的概率从一月开始逐渐下降,一直到8月达到最低,之后呈升高趋势;B类和C类随着时间的变化呈上升趋势。说明,黄瓜的安全性越来越低,其原因是夏季蔬菜上市的季节,同时也是虫害多发季节,菜农使用农药增多。
4 小结
通过贝叶斯网络的数据挖掘工具的分析,得出如下结论:①在品种分类问题上一些蔬菜如生菜、芸豆等的酶抑制率水平相对较低,而韭菜等则处于一个非常警戒的水平;②在以地点作为分类,祥和市场、烟大市场等市场的平均酶抑制率水平比较低,而其他地点、文化路市场、红利市场等其平均酶抑制率水平则相对较高;③在时间方面,平均酶抑制率呈现出较大的季节性规律,每年的5月平均酶抑制率开始升高,直到9月开始回落;④在品种与地点之间的联系上,通过分析韭菜在其他地点的平均酶抑制率分布区间的概率密度发现,即使韭菜总体被认为农药残留水平较高的蔬菜,在祥和市场还是值得信赖;⑤在品种和时间之间的联系,通過对蔬菜在各月的平均酶抑制率水平变化情况进行分析,探讨其季节规律,以黄瓜为例,分析其在受到季节因素影响的大小;⑥在品种和地点、时间的联系,以韭菜为例,结合了地点和时间,分析了对韭菜最佳的选取方案。
参考文献:
[1] 李泰然.中国食源性疾病现状及管理建议[J].中华流行病学杂志,2003,24(8):651-653.
[2] LI B,MA C L,GONG S L,et al. Food safety assurance systems in China[J].Food Control,2007(18):480-484.
[3] RUDDER A.Food safety and the risk assessment of ethnic minority food retail businesses[J].Food Control,2006(17):189-196.
[4] 周洁红,张仕都.蔬菜质量安全可追溯体系建设:基于供货商和相关管理部门的二维视角[J].农业经济问题,2011(1):32-39.
[5] 刘中华.蔬菜质量安全可追溯体系建设研究[D].青岛:中国海洋大学,2012.
[6] 樊红平,王 敏,王 芳,等.中美农产品质量安全检验检测体系比较研究[J].家畜生态报,2008,29(6):1-5,12.
[7] 樊孝凤.我国生鲜蔬菜质量安全治理的逆向选择研究[D].武汉:华中农业大学,2007.
[8] 许宇飞.沈阳市主要农产品污染调查及防治途径的研究[J].农业环境保护,1996,15(1):32-35.
[9] 秦 燕,李 辉,李 聪.控制图分析在食品安全预警中的应用[J].中国公共卫生,2004,20(9):1089-1090.
[10] 王志刚.食品安全的认知和消费决定:关于天津市个体消费者的实证分析[J].中国农村经济,2003(4):41-48.
[11] 陈卓民.数据挖掘技术在国内外的研究和发展现状[J].青年文学家,2009(16):122-123.
[12] 邢平平,施鹏飞,熊范纶.数据挖掘技术在农业数据中的有效应用[J].计算机工程与应用,2001,37(2):4-6.
[13] 陈 晨,董 倩,吴玉洁.基于贝叶斯分类的农作物产品质量挖掘研究[J].安徽农业科学,2011,39(12):7448-7449.
[14] 刘春玲,崔凌云,贾冬青,等.数据挖掘技术在农业领域的应用[J].农机化研究,2010(7):201-204.
[15] WITTEN I H,FRANK E.数据挖掘实用机器学习技术[M].北京:机械工业出版社,2012.
猜你喜欢
电力与能源(2017年6期)2017-05-14
科技资讯(2016年25期)2016-12-27
南水北调与水利科技(2016年5期)2016-12-27
现代农业科技(2016年20期)2016-12-20
现代园艺(2016年17期)2016-10-17
计算技术与自动化(2015年3期)2015-12-31
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
