
排列熵与核极限学习机在滚动轴承故障诊断中的应用*
2017-03-10 00:56:58孙国栋王祖达王建国
组合机床与自动化加工技术 2017年2期
秦 波,孙国栋,陈 帅,王祖达,王建国
(内蒙古科技大学 机械工程学院,内蒙古 包头 014010)
排列熵与核极限学习机在滚动轴承故障诊断中的应用*
秦 波,孙国栋,陈 帅,王祖达,王建国
(内蒙古科技大学 机械工程学院,内蒙古 包头 014010)
针对极限学习机(Extreme Learning Machine, ELM)隐含层节点数需要人为设定,致使滚动轴承故障分类模型精度低、稳定性差,提出基于排列熵(Permutation Entropy, PE)与核极限学习机(Kernel Extreme Learning Machine, K-ELM)的滚动轴承故障诊断方法。首先,将测得信号经集合经验模态分解(Ensemble Empirical Mode Decomposition, EEMD)处理后得到一系列IMF本征模态函数,并提取各分量的排列熵PE值组成高维特征向量集;其次,在利用高斯核函数的内积来表达ELM输出函数,从而自适应确定隐含层节点数;最后,将所得高维特征向量集作为K-ELM算法的输入建立核函数极限学习机滚动轴承故障分类模型,进行滚动轴承不同故障状态的分类辨识。实验结果表明:K-ELM滚动轴承故障分类模型比SVM、ELM故障分类模型具有更高的精度、更强的稳定性。
滚动轴承;排列熵;极限学习机;核函数
0 引言
滚动轴承是机械系统中最关键的零部件之一,其运行状态直接关系到设备能否正常运转。由于实际中工况复杂,轴承故障振动信号常呈现出非线性、非平稳性的特征,而传统的时频域分析方法大多针对线性、稳态信号的分析,因此难以精确、稳定地识别轴承的故障。
为了精确、稳定地识别轴承的故障类型,国内外科研工作者提出了一系列的方法。在状态识别方面:文献[1]以滚动轴承信号小波分解后的能量熵作为特征,通过BP神经网络对滚动轴承故障进行识别、诊断。文献[2]提出一种GA和LM组合优化BP神经网络的故障诊断方法,实验结果表明,组合优化后的BP神经网络具有更高的诊断效率和精度。虽然上述方法具有一定有效性,但BP神经网络易陷入局部最优,网络结构参数选取基于经验,解不唯一。与BP相比,支持向量机基于结构风险最小化原则克服了解不唯一、易陷入局部最优。文献[3]采用主成分分析结合支持向量机实现了滚动轴承故障的准确诊断。实验结果证明针对四种轴承状态,识别率达到90%,提出的结合PCA-SVM是一种有效的滚动轴承故障诊断方法。但是其在实际应用中也存在一些缺点:①支持向量机具有一定的稀疏性,但是支持向量数会随着训练样本数的增加线性增加;②需要对一些模型参数进行优化,如果这些模型参数取值不当,将大大影响其性能,从而增加额外的计算量。对此,Huang提出的极限学习机,表现出运算速度快,泛化能力强,不易过拟合的优点,但ELM算法对最优神经元个数的选择只能通过试凑法来获得,鲁棒性差。Cao Jiu-wen等[4]利用自适应DE算法优化ELM模型的输入权重和隐层阈值,具有较好的全局搜索能力,更强的泛化能力,但收敛速度慢。吕忠等[5]运用遗传算法对极限学习机的输入权值与隐含层阈值进行优化,从而提高模型的预测精度。但遗传算法属于随机性智能优化算法,稳定性差,不能处理连续优化问题。2015年王续林等[6]基于PSO聚类和ELM神经网络机床主轴热误差建模,该模型具有计算简便、预测精度高、结构简单等优点,但容易陷入局部极小值而找不到全局最优解。
针对以上问题,提出基于排列熵与K-ELM的滚动轴承故障诊断方法。为避免噪声对特征提取的影响,先将测得信号经集合经验模态分解处理后得到一系列IMF本征模态函数,并提取各分量的排列熵PE值组成高维特征向量集;其次,在利用高斯核函数的内积来表达ELM输出函数,从而自适应确定隐含层节点数;最后,将所得高维特征向量集作为K-ELM算法的输入建立核函数极限学习机滚动轴承故障分类模型,进行滚动轴承不同故障状态的分类辨识。
1 排列熵
排列熵是通过对比相邻数据去度量时间序列的复杂性,相比于其他的熵值,排列熵具有计算速度快,抗干扰能力强的优点,只用熵对信号进行排列,能够克服非线性信号失真问题,可以用来提取轴承信号的特征。其基本原理如下[7]:
给定一个时间序列信号{x(i),i=1,2,…,n}进行相空间重构。根据延迟嵌入定理得到重构信号:

(1)
式中:
∑—延迟时间
Y—嵌入维数
重构后i的值最大为:n-(y-1)σ。
将式(1)中的元素按升序排列,得到:
x(i+(j1-1))σ≤x(i+(j2-1))σ≤…≤x(i+(jy-1))σ
(2)
其中:j1,j2,…,jy表示x(i)中元素的位置。如果x(i)中存在相等的元素,则在重新排列时按j的大小进行排列,因此x(i)总能找到如下序列模式:
K(l)=(j1,j2,…jy)
(3)
其中:l=1,2,…,m,m≤y!。y个元素的向量最多可以有y!种排列模式;K(l)表示其中一种排列模式。设一种排列模式的出现概率为:
(4)
故信号排列模式的熵为:
(5)
对Hp=(y,σ)进行归一化处理,得排列熵为:
(6)
以上可以看出,Hp的取值范围为[0,1],Hp值的大小表示时间序列的复杂和随机程度。Hp值越小,则时间序列越规则,反之时间序列越接近随机。因此Hp的变化能够反映并放大时间序列的细微变化。
2 核函数极限学习机辨识模型构建
2.1 极限学习机
极限学习机[8-9]的结构如图1所示,由输入层、隐含层和输出层组成,层与层之间通过神经元连接。n个隐含层节点,ωi和βi分别为连接输入层和隐含层、连接隐含层和输出层的权重矩阵,xi,yi分别为输入和输出,bi是隐含层的阈值,ωi和βi定义如下:
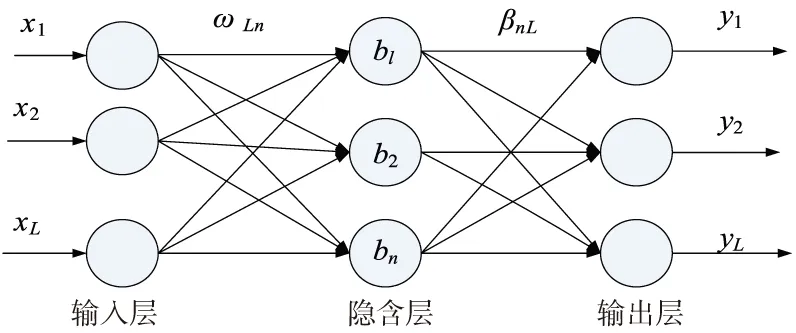
图1 ELM的结构图
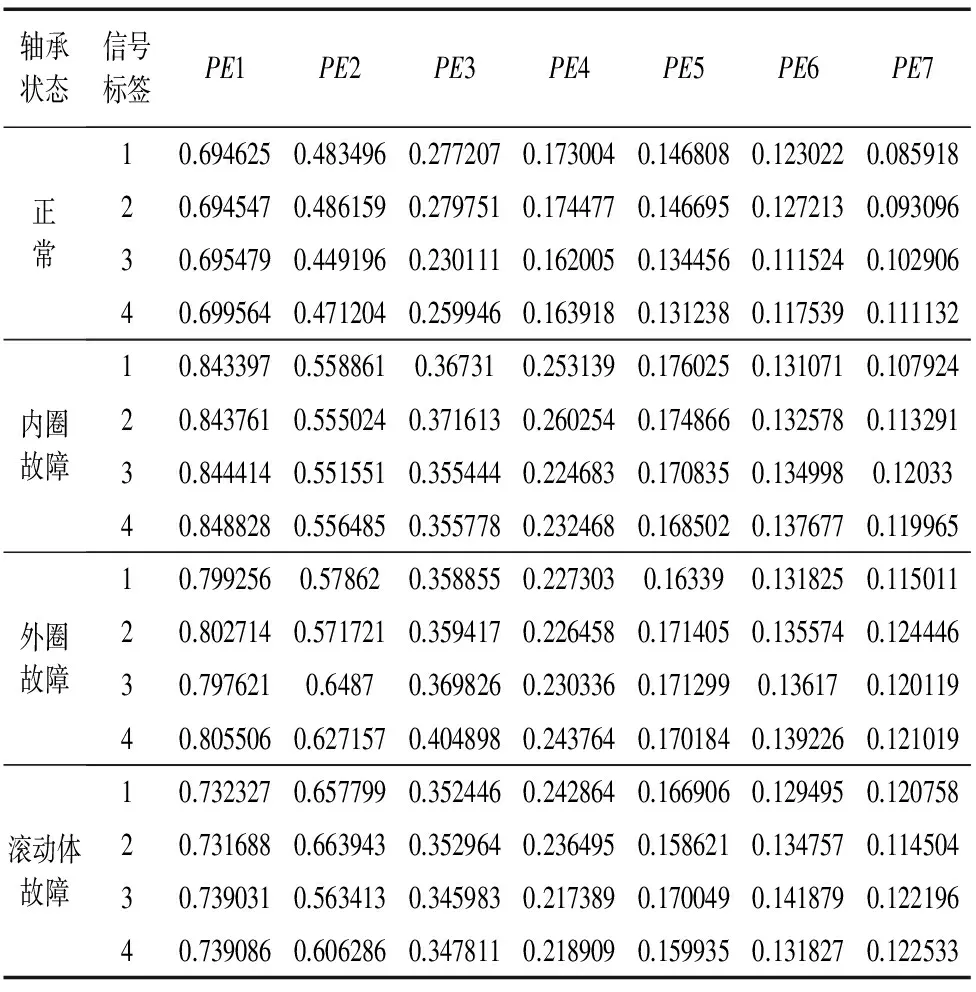
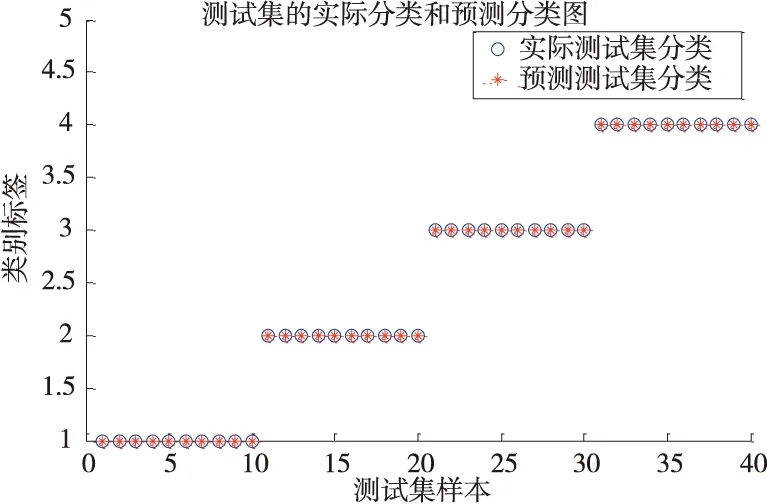
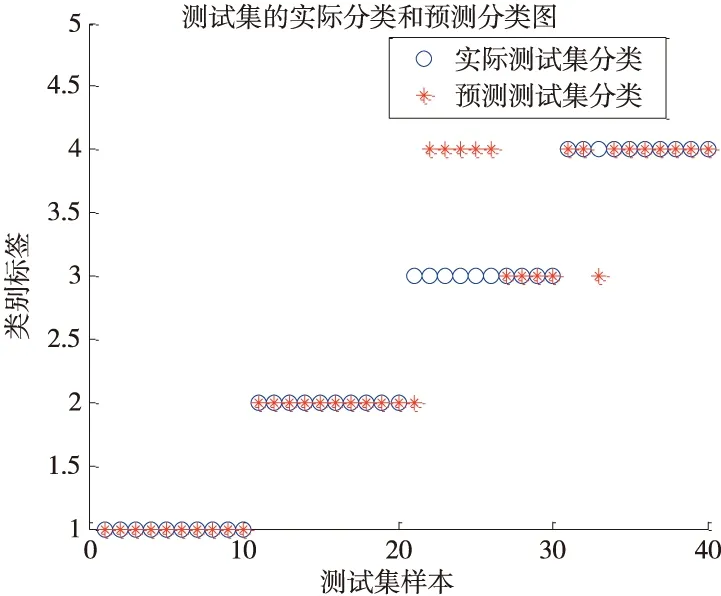
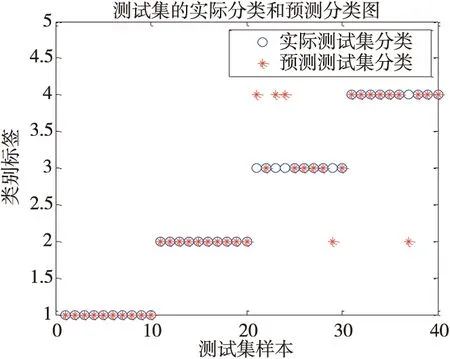
对于给定L个不同数据样本(xi,ti),其中xi=[xi1,xi2,…,xiL]T∈RL,ti=[ti1,ti2,…,tiL]T∈RL,具有n个隐含层节点(n (7) 如果其激活函数g(x)是无限可微的,那么就能够零误差的逼近输入样本的真实输出值,用公式可以表达为: (8) 上式可以简化为: Hβ=T (9) 其中H为隐含层输出矩阵,其定义如下: (10) 输出权值向量βi可以通过式(9)的最小二乘βi=H+T来获得。其中,在求解Moerr-Penrose广义逆H+=HT(HHT)-1时,因为数据样本可能存在复共线性问题,造成HHT非奇异,从而影响最终结果。因此,在对角矩阵HHT中引入一个参数1/c,把它加到HHT的主对角线上,使HHT的特征根偏离零值,以此求出权值向量βi值,表达式如下: (11) 2.2 核函数极限学习机 对于低维空间线性不可分问题,通过引入核函数把输入空间样本数据映射到可分的高维特征空间,进行内积运算将不可分转变为可分来处理数据。本文采用的高斯核函数满足Mercer核理论[10]可以应用到极限学习机中,其表达式如下: (12) 在ELM算法中隐含层节点输出函数g(x)是未知的,利用核函数能够把g(x)用内积的形式表示出来,所以核ELM算法中,隐含层节点输出函数g(x)的具体形式不用给出,只需要知道核函数K(x,xi)的具体形式就可以求出输出函数的值,且隐含层节点数能够自适应确定。ELM算法中的公式用核矩阵形式表示为: KELM=HHT:KELM=g(xi)·g(xj)=K(xi,xj) 故核函数极限学习机算法可概括为:给定一个含有L个样本的训练样本集(xi,yi),xi表示输入向量,yi表示相应的输出,i=1,2,…,L,及核函数K(x,xi)。则输出的方程为: (13) 核极限学习机算法的流程图如图2所示。 图2 核极限学习机算法的流程图 实验设备为美国Spectra Quest公司DDS动力传动故障诊断综合实验台见图3。该实验台的动力传动系统由1个二级行星齿轮箱,1个二级平行齿轮箱以及变速驱动电机和电机控制器等组成,其平行齿轮箱传动结构见图4。实验中,测点布置见图3,其中测分别位于垂直径向、水平径向与轴向。 图3 动力传动故障诊断综合实验台 图4 平行齿轮箱的传动结构简图 实验中,对轴承的正常、外圈故障、内圈故障、和滚动体故障4种状态分别采样,获取各30组数据,每组数据包含5120个采样点。随机抽取每种状态的20组数据作为训练样本,剩余的10组作为测试样本。首先对轴承的内圈故障信号进行EEMD分解,对所得IMF分量提取排列熵。同理把其余三种状态的样本进行上述处理,所得结果见表1滚动轴承四种状态部分排列熵值。 表1 轴承四种状态的特征向量 将上述数据样本的随机选取20组作为的训练样本,利用K-ELM算法对模型进行训练,建立滚动轴承的故障诊断模型;剩余的10组数据样本作为测试样本完成测试,其分类结果见图5,从图中可以看出K-ELM对轴承故障的分类精度达到100%。 图5 K-ELM的测试集分类结果 为了验证所提方法的优越性。分别将训练样本与测试样本输入到SVM和ELM中进行训练与测试,其测试结果见图6和图7。从图6中看出SVM对轴承故障分类精度达到82.5%:从图7中看出ELM对轴承故障分类精度达到87.5%。上述三种方法的对比结果见表2,与SVM和ELM分类模型相比,K-ELM的轴承故障诊断模型具有更高的精度。 图6 SVM的测试集分类结果 图7 ELM的测试集分类结果 算法种类训练样本组数测试样本组数测试精度%正常内圈故障外圈故障滚动体故障SVM20101001004090ELM20101001006090K⁃ELM2010100100100100 针对极限学习机隐含层节点数需要人为设定,致使滚动轴承故障分类模型精度低、稳定性差,本文提出基于排列熵与K-ELM的滚动轴承故障诊断方法。将提取的各IMF分量的排列熵作为本模型的输入,进行轴承故障的分类和识别。通过实验结果分析,得出的结论如下: (1)排列熵对信号的突变特别敏感,对于滚动轴承不同振动信号的复杂性不同,排列熵值也不同,因此排列熵用来提取故障特征效果明显。 (2)核函数极限学习机的隐含层节点数能自适应确定。提高了故障诊断模型的分类精度和稳定性。 [1] 胡耀斌,厉善元,胡良斌.基于神经网络的滚动轴承故障诊断方法的研究[J].机械设计与制造,2012(2):187-189. [2] 钟小倩,马文科,宋萌萌. 基于GA和LM组合优化BP神经网络的滚动轴承故障诊断方法[J].组合机床与自动化加工技术,2014(12):91-95. [3] 张沛朋,郭飞燕.基于PCA-SVM的滚动轴承故障诊断研究[J]. 组合机床与自动化加工技术,2015(11):88-90. [4] Cao Jiuwen,Lin Zhiping,Huang Guang-Bin. Self-adaptive evolutionary extreme learning machine[J].Neural Processing Letters, 2014, 36:285-305. [5] 吕忠,周强,周棍,等.基于遗传算法改进极限学习机的变压器故障诊断[J].高压电器,2015(8):49-53. [6] 王续林,顾群英,杨昌祥,等. 基于PSO聚类和ELM神经网络机床主轴热误差建模[J]. 组合机床与自动化加工技术,2015(7):69-73. [7] Bandt C,Pompe B. Permutation Entropy: a Natural Complexity Measure for Time Series[J]. Physical Review Letters, The American Physiological Society, 2002, 88(17): 174102(1-4). [8] 尹刚,张英堂,李志宁.运用在线贯序极限学习机的故障诊断方法[J].振动、测试与诊断,2013,33(2):325-329. [9] 苑津莎,张利伟,王瑜. 基于极限学习机的变压器故障诊断方法研究[J].电测与仪表,2013,50 (12):21-26. [10] 张晓平,赵玛,王伟,等.基于最小二乘支持向量机的焦炉煤气柜位预测模型及应用[J].控制与决策,2010, 25(8):1178-1183. (编辑 李秀敏) Application of Permutation Entropy and Kernel Extreme Learning Machine in Fault Diagnosis of Rolling Bearing QIN Bo, SUN Guo-dong, CHEN Shuai, WANG Zu-da, WANG Jian-guo (School of Mechanical Engineering, Inner Mongolia University of Science & Technology, Baotou Inner Mongolia 014010, China) The number of nodes in the hidden layer of the extreme learning machine needs to be artificially set and the fault classification model of the rolling bearing is of low accuracy and poor stability, rolling bearing fault diagnosis method based on permutation entropy and nuclear kernel extreme learning machine. First, the measured signal by set of empirical mode decomposition treated by a series of IMF the intrinsic mode functions and extraction of various components of the permutation entropy PE value high dimensional feature vector set. Second, in the inner product by Gauss kernel function to express the ELM output function to adaptively determine the number of the hidden layer nodes; After that, the high dimension feature vector set is used as the input of the K-ELM algorithm to establish the kernel function limit learning machine rolling bearing fault classification model, and the classification and identification of different fault states of rolling bearings are carried out. The experimental results show that the K-ELM rolling bearing fault classification model is better than ELM, and the SVM fault classification model has higher accuracy and stronger stability. rolling bearing;permutation entropy;extreme learning machine;kernel function 1001-2265(2017)02-0073-04 10.13462/j.cnki.mmtamt.2017.02.018 2016-06-18; 2016-07-19 国家自然科学基金(51565046);内蒙古自然科学基金(2015MS0512);内蒙古科技大学创新基金(2015QDL12) 秦波(1980—)男,河南南阳人,内蒙古科技大学讲师,工学硕士,研究方向为复杂工业过程建模、优化及故障诊断,(E-mail) nkdqb@163.com;通讯作者:孙国栋(1992—),男,山东聊城人,内蒙古科技大学硕士研究生,研究方向为机电系统智能诊断,(E-mail) sgdyl121115@163.com。 TH166;TG659 A
3 仿真实验


4 结论
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22 06:39:32
哈尔滨轴承(2022年1期)2022-05-23 13:13:24
哈尔滨轴承(2021年2期)2021-08-12 06:11:46
哈尔滨轴承(2021年1期)2021-07-21 05:43:16
测控技术(2018年10期)2018-11-25 09:35:26
自动化学报(2018年2期)2018-04-12 05:46:21
制造技术与机床(2017年4期)2017-06-22 11:17:32
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:53
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
