
音色变换音频信号的篡改检测技术研究
2017-03-09 02:45何朝霞
中国测试 2017年2期
何朝霞,潘 平,罗 辉
(1.长江大学工程技术学院,湖北 荆州 434023;2.贵州大学计算机科学与信息学院,贵州 贵阳 550025;3.哈尔滨工业大学计算机科学与技术学院,黑龙江 哈尔滨 150001)
音色变换音频信号的篡改检测技术研究
何朝霞1,潘 平2,罗 辉3
(1.长江大学工程技术学院,湖北 荆州 434023;2.贵州大学计算机科学与信息学院,贵州 贵阳 550025;3.哈尔滨工业大学计算机科学与技术学院,黑龙江 哈尔滨 150001)
针对音色变换软件带来的社会安全问题,提出一种音频信号篡改检测方法。首先根据语音信号的混沌特性和人耳的听觉特性,利用美尔频率倒谱系数(Mel frequency cepstral coefficients,MFCC)特征提取原理,提取待测音频的杜芬频率倒谱系数(Duffing frequency cepstral coefficients,DFCC),然后将特征参数的幅度进行提升,利用支持向量机(SVM)将特征参数与语料库里的特征进行分类。分类成功的情况下,根据幅度提升的大小判断待测音频信号是否经过篡改;同时根据幅度提升的大小和待测音频的性别判断说话人的真实性别。大量的实验结果表明,该方法在音频信号的篡改检测和音频信号说话人的真实性别判断方面均具有较高的准确率,并且性能稳定。
篡改检测;特征提取;杜芬频率倒谱系数;支持向量机
0 引 言
音色变换是指改变一个说话人的语音个性特征,使之具有另外一个说话人的语音个性特征。音色变换在数字娱乐领域有着广泛的应用,例如AV VCS[1]软件,可以对语音进行某种变换使之产生性别和音色个性上的变化,包括在男声、女声、老年人声和童声之间互相转换,从而达到伪装的效果;在通信领域,手机客户端也可以便捷地下载使用变声软件达到音色变换的效果。音色变换一方面娱乐了大众,但也对社会安全产生了一定的威胁,例如,犯罪分子在绑架或诈骗中,语音聊天时通过变声软件改变自己的音色和音调,隐藏其真实身份,给侦查和取证带来了极大的困难。因此针对说话人音色变换的音频信号篡改检测技术的研究有着重要的意义。目前国内外针对音色变换的音频信号篡改检测的研究相对较少,尤其是自动检测技术。
文献[2-3]针对提高或者降低音调、手掩口、捏鼻子等伪装方法,提出用美尔频率倒谱系数(Mel frequency cepstral coefficients,MFCC)及其差分等特征鉴别音频信号是否伪装,其中文献[3]以12阶MFCC及其一阶差分作为分类特征,用支持向量机(support vector machine,SVM)对特征进行分类,取得了较好的检测效果;文献[4]针对利用算法进行语音变换的音频信号,通过比较相邻的基音同步帧的相似度检测音频信号是否经过了篡改。文献[5]针对利用变声软件进行语音变换的音频信号,提取音频信号的声道参数及相关统计量等特征参数,然后使用SVM进行特征分类,判断音频信号是否进行了音色变换。文献[6]提出一种基于线性预测系数(linear predictive coefficient,LPC)和SVM的语音改变篡改检测方法。
本文试图根据语音信号的混沌特性和人耳的听觉特性,利用MFCC特征参数提取原理,提取语音信号的DFCC(Duffing frequency cepstral coefficients)参数及其一阶差分,利用SVM对变换语音的特征进行分类,检测语音信号是否经过音色变换,如果是则判别变换语音说话人的真实性别。同时与文献[3]中的方法比较,验证本论文方法的有效性。
1 基于Duffing方程的篡改检测原理
1.1 音色变换原理
人类的语音是由说话人的发音器官各部分协同动作所产生的,例如声带颤动而产生的声带音是通过喉腔、咽腔、口腔、唇腔和鼻腔这5个共振腔才传到人的耳朵里。空气流经过声带时,如果声带是绷紧的,则声带将产生张弛振动,即声带将周期性地开启和闭合。声带开启时,空气流从声门喷射出来,形成一个脉冲,声带闭合时相应于脉冲序列的间隙期。因此,在这种情况下,声门处产生一个准周期脉冲状的空气流。该空气流经过声道后最终从嘴唇辐射出声波,这个准周期脉冲的周期即为基音周期[7]。基音频率是由声带张开闭合的周期所决定的。男性的基音频率一般为50~250Hz,女性的基音频率为100~500Hz。说话人的个性化音色就是和基音频率和共振峰频率的分布有关。在进行性别变声时,主要考虑基频和共振峰频率的变化。当基频伸展,共振峰频率也同时伸展时,可由男声变成女声,女声变成童声;反之,基频收缩,共振峰频率也同时收缩时,则由童声变女声,女声变男声[8]。目前市面上的语音变换软件如AV VCS等几乎都是基于基频移动的原理实现的。
由原理可知,如果设计一种方法能够检测出音色变换语音信号的基音频率和移动频率,就可以判断出语音信号是否经过音色变换,根据基音频率可以估计出说话人的真实性别。
1.2 基于Duffing方程的语音特征提取
语音信号,特别是摩擦音与爆破音之类的送气音,会在声道边界产生涡流,并最终形成湍流,而这种湍流则是一种混沌,因此可以考虑建立混沌模型来处理语音信号[9]。1918年,Duffing在经典力学中引入了一个具有摆动的非线性振动方程,现称为Duffing方程,该方程是混沌现象的一个典型例子。本文从Duffing方程着手,同时结合人耳的听觉特性,建立非线性系统的数学模型,实现对说话人语音信号的特征提取。
Duffing方程[10]的一般形式为
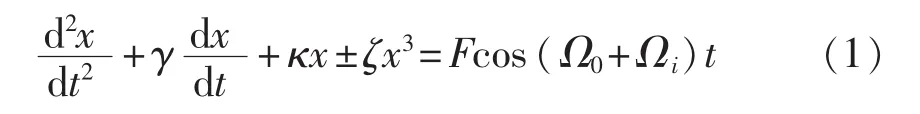
式中:γ——阻尼系数;
κ、ζ——常数;
Fcos(Ω0+Ωi)t——系统的外力项;
Ω0+Ωi——外力项频率,在这里,Ω0表示基音频率,Ωi表示移动的频率。
考虑有外力驱动的情况,当 2πfi=Ω0+Ωi时,系统发生共振。在t(0+)时刻输入一个脉冲响应δ(t),Duffing共振系统的时域函数为h(t),由δ(t)·h(t)= x(t),可以得出H(s)=X(s),即h(t)=x(t)。
阻尼系数在一定程度上决定了脉冲响应的衰减速度,与滤波器的带宽有关。由此可以得到系统的时域表达式[11]为
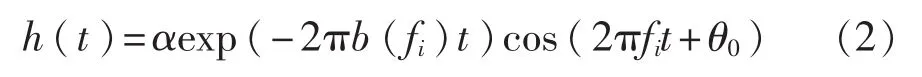
式中:α——滤波器增益;
b(fi)——滤波器的带宽,-2πb(fi)<0,说明该系统具有稳定性。
语音信号通过该系统可以检测出Ω0和Ωi。
同时考虑到人耳的听觉特性,由于人耳基底膜的横纤维长短不同,靠近蜗底较窄,靠近蜗顶较宽,犹如一部竖琴的琴弦[12],其长短呈非线性变化,所有的音按自然七声音阶排列。可以认为人耳基底膜的振动实质上是由多个Duffing模型的线性叠加组合而成。每一个Duffing模型,构成一个听觉共振点,其输出就是该共振点的频率,所以该系统是由一个滤波器组实现的。
同时,由于钢琴的十二声调式体系是由同主音6个自然七声调式混合而成,考虑将声乐的十二韵律[13]运用到滤波器的频率特性中。
十二韵律是通过连续的乘法每次上一频率乘得出下一频率的结果。同理,只要确定了第一通道滤波器的中心频率f0,就可以确定各通道滤波器的中心频率fi。
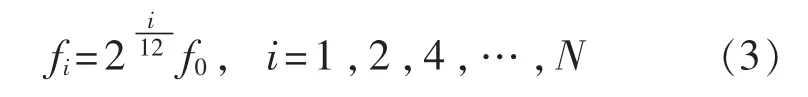
式中N为滤波器组的通道数。
每个滤波器带宽可由式(4)确定。
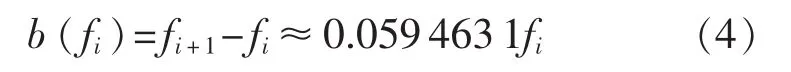
只要确定了滤波器的中心频率fi,滤波器的特性就可以确定。图1所示是中心频率为1 000 Hz Duffing滤波器的时域响应波形。

图1 中心频率为1000Hz的Duffing滤波器时域冲激响应
将其进行傅里叶变换就可以得到频率响应特性。不同中心频率的Duffing滤波器的幅频响应曲线如图2所示。

图2 不同中心频率Duffing滤波器的幅频响应
由于说话人语音信号频率的覆盖范围一般为60~3500Hz,选定最低频率f0=60Hz,按照式(4)可求得各通道滤波器的中心频率,共需72通道(表1)才能够覆盖整个频率范围。图3为72通道Duffing滤波器组(每4个通道取一条曲线)的幅频响应曲线。表1中,当前通道数k=(n-1)×12+m,表格中的数据表示当前通道滤波器的中心频率。

图3 72通道Duffing滤波器组的幅频特性

表1 各通道滤波器的中心频率 Hz
2 音频信号特征提取
MFCC特征参数提取是将语音信号加窗分帧后用快速傅里叶变换(FFT)转化为频域信号,然后通过Mel频率滤波器组得到Mel频谱,最后进行DCT变换获得Mel倒谱系数。利用MFCC特征参数提取原理,音频信号DFCC特征参数提取流程如图4所示,具体步骤如下:
1)语音信号经过抗混叠、预加重等预处理后,分帧加窗,128点作为一帧,帧移40个点,加汉明窗。
2)将加窗分帧后的短时信号,用快速傅里叶变换(FFT)转化为频域信号,求出频谱平方,即能量谱。
3)将短时能量信号通过第1节设计的Duffing滤波器组,并通过对数能量的处理得到对数频谱。
4)将上述对数频谱经过离散余弦变换(DCT)得到L个Duffing频率倒谱系数。DFCC系数为
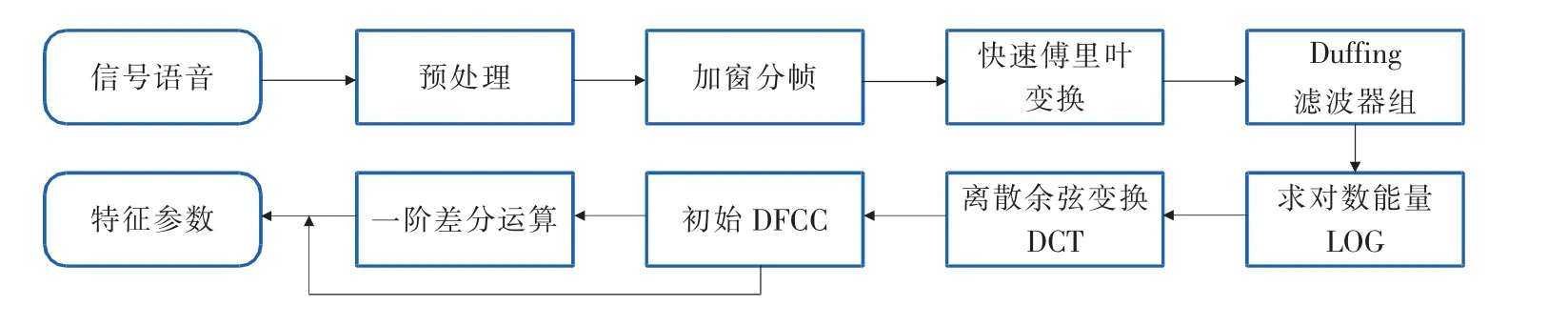
图4 音频信号特征提取流程
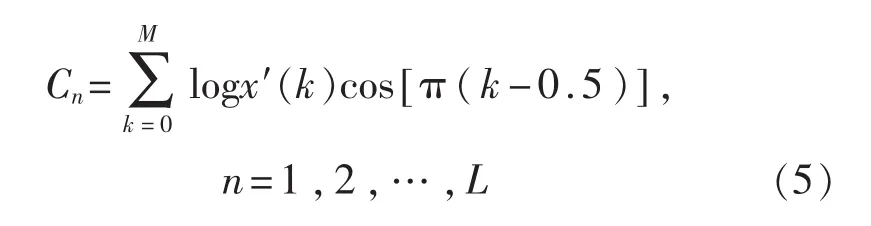
其中x′(k)为短时能量信号。滤波器组的通道数为72,上式中的L为72。
5)将这种直接得到的DFCC特征作为静态特征,再将这种静态特征做一阶差分,得到相应的动态特征。
6)对提取出的DFCC静态特征、一阶差分,合并作为音色变换篡改检测的特征参数。
3 实验和分析
3.1 实验可行性分析
有5段待测音频,都为同一女生的录音,内容均为“你好”。分别命名为“自然音”、“女性”、“男性”、“男孩”、“男老人”。 其中,“自然音”是采用语音编辑软件Cool Edit Pro V2.1简体中文版录制的自然语音;“女性”、“男性”、“男孩”、“男老人” 均采用AV VCS软件录制的变换语音。图5是以“自然音”的特征参数为基准,音频信号的特征参数对比图;图6是以“男孩”语音的特征参数为基准,音频信号的特征参数对比图。由于Duffing带通滤波器有72通道,所以特征参数为72维,图5和图6均只取了其中的第一维特征参数进行比较,其中横坐标为语音帧,纵坐标为特征参数的幅度。
观察图5,由于说话人为女性,其中“自然音”和“女性”变换音的特征参数极其相似,并且幅度接近;而“自然音”与“男性”、“男孩”和“男老人”等变换音的特征参数虽然波形相似,但是幅度相差较大。
对比图5和图6,发现相同性别的变换音的特征参数波形和幅度的近似程度较大,而不同性别的变换音的特征参数幅度相差较大。
在本实验的基础上,又将特征参数的其他维进行了测试,所得结果与图5、图6的结果基本吻合。由于变声器是通过调整输入音频信号的基频参数,改变声音的音色、音调,使输出声音在感官上与原声音不同。基频参数的改变压缩或者扩展了语音频谱中的谐波成分,而短时谱包络和时间尺度保持不变。本文提出的DFCC参数包含了说话人的个性特征,能够检测出语音信号的说话人基音频率和移动的频率。呈现在特征参数图形上就是:变换语音的特征参数与自然语音的特征参数在波形上有较大的相似性,但是不同性别年龄的变换音与自然语音特征参数的幅度相差不一样。
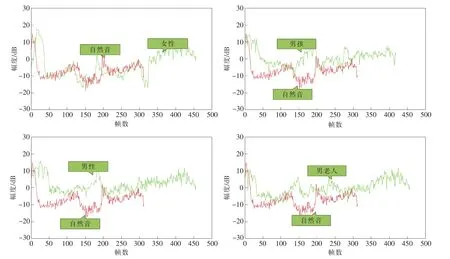
图5 以“自然音”的特征参数为基准,音频信号的特征参数对比图

图6 以“男孩”的特征参数为基准,音频信号的特征参数对比图
因此,为了检测待测音频信号是否经过篡改,可以将该音频信号的DFCC特征参数的幅度进行提升(可正可负),然后将提升后的特征参数与该说话人的自然语音的DFCC特征进行比较,如果相似程度较大,则是该说话人的语音,从而检测说话人的真实性别;同时根据幅度提升的大小判断待测音频信号是否经过语音变换。
3.2 语音转换检测和分析
为了进一步的验证实验,又进行了大量的测试。测试的基础是庞大的语料库,语料库的音频都是由语音编辑软件Cool Edit Pro V2.1简体中文版录制的说话人自然语音,总共有50个女性和50个男性。每个说话人都训练了10段语音,根据第2节的内容提取其特征,作为语料库的样本。待测信号有1000段,都是语料库中的说话人利用AV VCS软件或Cool Edit Pro V2.1简体中文版录制的音色变换音频信号或自然语音音频信号。
音色变换检测和说话人真实性别判断的具体步骤如下:
1)按照第2节的步骤获取待测音频信号的特征参数,赋初值m=-10。
2)待测音频信号的特征参数+m,利用SVM将该特征参数和语料库中自然语音音频信号的特征进行比较分类。
3)如果分类失败,m=m+0.1,重复 2),如果m>20,结束,识别失败。
4)如果分类成功,根据待测音频的性别和当前m的大小判断待测音频信号的说话人性别。如果m∈[-0.5,0.5],待测音频信号没有进行音色变换,如果m∉[-0.5,0.5]则待测音频信号进行了语音变换。
待测音频的性别、当前m值和识别结果之间的关系如表2所示。
待测音频信号音色变换篡改检测准确率如表3所示。
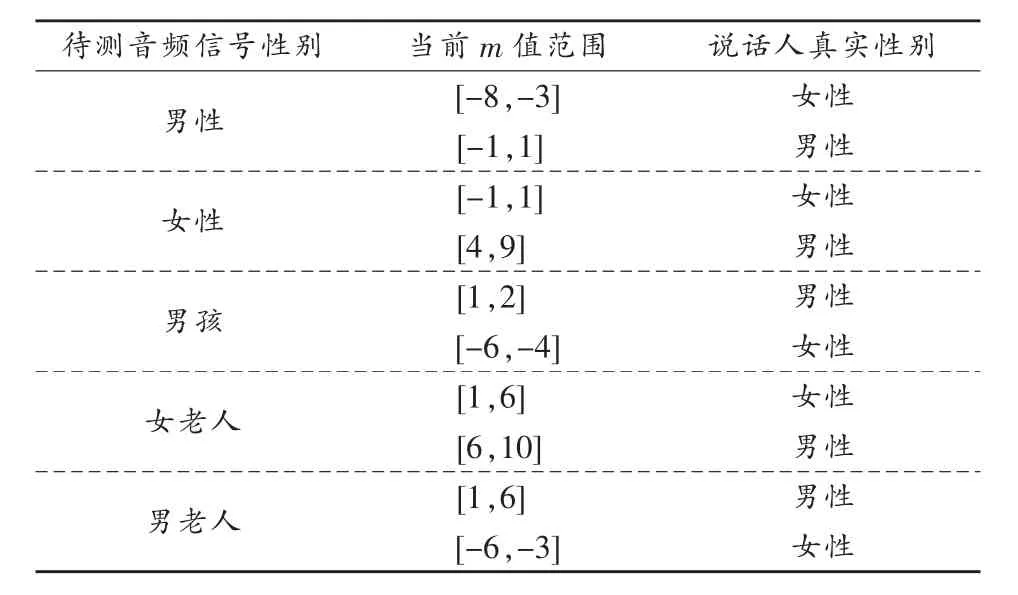
表2 待测音频的性别、当前m值和识别结果之间的关系
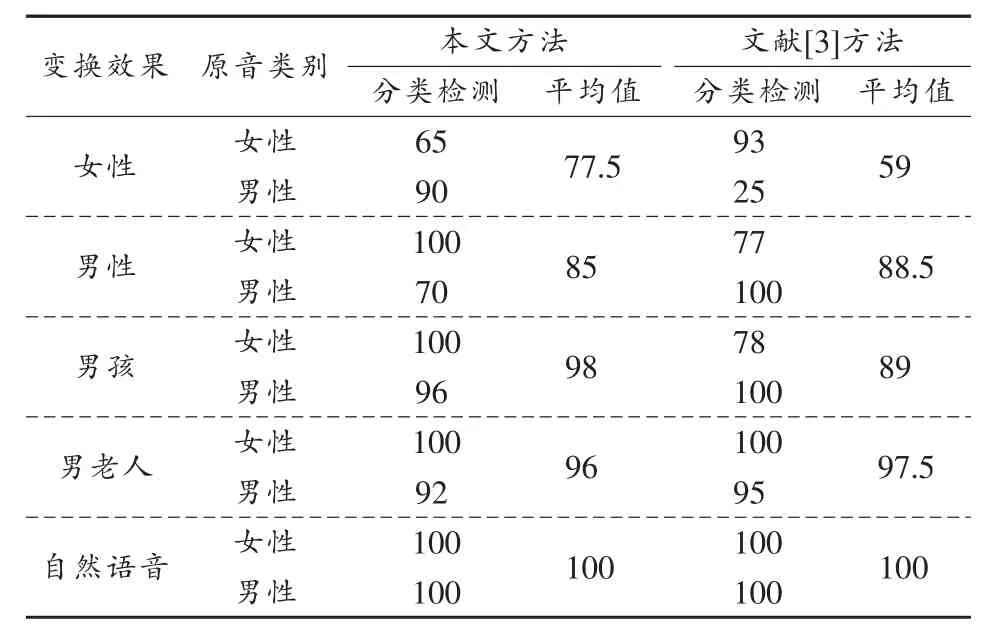
表3 待测音频信号的篡改检测准确率 %
观察表3,虽然文献[3]的方法在变换音性别与说话人性别相同时,具有较高的准确率,但整体性能不够稳定,特别是对于女性变换效果的平均检测准确率偏低,缘于MFCC特征参数及其一阶差分对说话人的个性特征比较敏感。本文方法待测音频信号的篡改检测平均准确率在75%以上,性能比较稳定,这是因为DFCC参数在提取过程中既考虑了语音的混沌特性,同时也考虑了人耳的听觉特性,可以较准确地检测出说话人语音的基频和移动频率,是一种很好的说话人个性特征,并且对外界的影响不敏感。
待测音频信号的说话人性别判断准确率如表4所示。
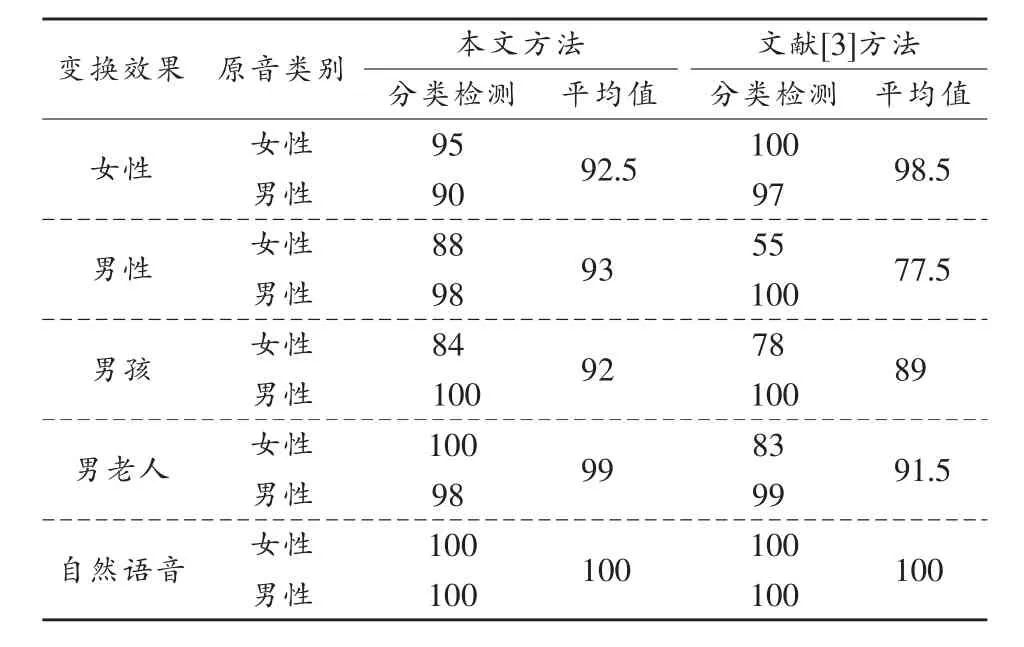
表4 待测音频信号的说话人性别判断准确率 %
从表4平均准确率来看,本文方法对各种效果的说话人真实性别判断准确率均大于90%,性能非常的稳定。文献[3]方法对于说话人性别和变换语音性别相同时的检测准确率略高于本文方法,但是对于男性变换效果的平均检测准确率偏低。表明DFCC及其一阶差分是一个稳定的能够表述说话人个性的特征参数,在说话人性别的识别中仍然具有较大的优势。
4 结束语
本文提出了一种针对音色变换的音频信号篡改检测方法,首先根据语音信号的混沌特性和人耳的听觉特性,利用MFCC特征提取原理,提取待测音频的DFCC特征参数,然后将特征参数的幅度进行提升,利用SVM将特征参数与语料库里的特征进行分类,如果分类失败,则此次识别不成功,无法检测是否有篡改;如果分类成功,则根据幅度提升的大小判断待测音频信号是否经过篡改,同时根据幅度提升的大小和待测音频的性别判断说话人的真实性别。从实验结果来看,DFCC特征参数稳定,对外界影响不敏感,是一种重要的说话人个性特征,将它运用到音色变换音频信号的篡改检测中具有较高的准确率,为音色变换的音频信号篡改检测提供了一个新的思路。
[1]AV voice change software[EB/OL].(2005-01-01)[2009-06-08].http:∥www.audio4fun.com/voice-changer.html.
[2]PERROT P,MOREL M,RAZIK J,et al.Vocal forgery inforensic sciences[J].Forensics Intelecommunications, Information and Multimedia,Lecture Notes ofthe Institute for Computer Sciences Social Informatics and Telecommunications Engineering,2009,8(1):179-185.
[3]PERROT P,CHOLLET G.The question of disguised voice[J].The Journal of the Acoustical Society of America,2008,123(5):3878.
[4]SHEN Y F,JIA J,CAI L H.Detection on PSOLA-modified voice by seeking out duplicated fragments[C]∥IEEE International Conference on Systems and Informatics,2012:2177-2182.
[5]丁琦,平西建.针对语音变换的语音篡改检测[J].数据采集与处理,2012,27(1):57-62.
[6]王飞.基于语谱图和基音同步的音频信号篡改检测方法[D].大连:大连理工大学,2013.
[7]晁浩,宋成,彭维平.基于发音特征的声效相关鲁棒语音识别算法[J].计算机应用,2015,35(1):257-261.
[8]陆成刚.语音性别变换的实时实现[J].电声技术,2009,33(12):50-53.
[9]孙颖,姚慧,张雪英,等.基于混沌特性的情感语音特征提取[J].天津大学学报(自然科学与工程技术版),2015,48(8):681-685.
[10]王海波.Duffing方程非线性振动特性的计算与分析[D].西安:西安建筑科技大学,2009.
[11]何朝霞,潘平.基于非线性共振的说话人特征提取研究与仿真[J].科学技术与工程,2012,12(25):6507-6510.
[12]胡航.语音信号处理 [M].哈尔滨:哈尔滨工业大学出版社,2009:42-136.
[13]志扬.一位科学家对音乐的贡献[J].乐器,1990(2):36.
(编辑:刘杨)
Study on tamper detection technology for voice transformation
HE Zhaoxia1,PAN Ping2,LUO Hui3
(1.College of Technology&Engineering,Yangtze University,Jingzhou 434023,China;2.Computer Science and Information Institute,Guizhou University,Guiyang 550025,China;3.School of Computer Science and Technology,Harbin Institute of Technology,Harbin 150001,China)
To address the social security issue brought up by voice transformation software,a method for sound signal tamper detection is proposed.Firstly,with the extraction method of Mel frequency cepstral coefficients(MFCC),Duffing frequency cepstral coefficients(DFCC)characteristic parameters of audio signals are extracted based on the human hearing characteristics and chaos characteristics of speech signal.Then,the amplitude of characteristic parameters is enhanced and support vector machine(SVM)is used to classify the characteristic parameters and characteristics in corpus.In case of successful classification,the audio signal will be judged whether it is tampered as per the size of the amplitude enhanced.Meanwhile,the speaker gender will be judged according to the size of the amplitude enhanced and the gender of the audio.Through a large number of experiments,it shows that the method has stable performance and high accuracy both in the audio signal tampering detection and audio speaker real gender judgement.
tamper detection;feature extraction;DFCC;SVM
A
:1674-5124(2017)02-0098-06
10.11857/j.issn.1674-5124.2017.02.020
2016-06-16;
:2016-08-03
贵州省科学技术基金项目(黔科合J字[2012]2132);贵阳市科技计划项目(筑科合同[2011101]1-2);长江大学工程技术学院科学研究发展基金(15j0401)
何朝霞(1984-),女,湖北黄冈市人,讲师,硕士,研究方向为语音信号处理。
猜你喜欢
家庭影院技术(2021年10期)2021-11-20
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
家庭影院技术(2019年8期)2019-08-27
中国交通信息化(2019年12期)2019-08-13
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
电子制作(2018年1期)2018-04-04
家庭影院技术(2017年9期)2017-09-26
中国交通信息化(2017年8期)2017-06-06
