
基于微调优化的深度学习在语音识别中的应用
2017-01-04 05:26彭玉青高晴晴张媛媛
郑州大学学报(理学版) 2016年4期
彭玉青, 刘 帆, 高晴晴, 张媛媛, 闫 倩
(河北工业大学 计算机科学与软件学院 天津 300401)
基于微调优化的深度学习在语音识别中的应用
彭玉青, 刘 帆, 高晴晴, 张媛媛, 闫 倩
(河北工业大学 计算机科学与软件学院 天津 300401)
针对深度学习模型在对小样本进行训练时会出现过拟合现象,提出随机退出优化方法和随机下降连接优化方法.这两种方法针对深度学习模型的微调阶段进行改进,最大限度减少由于训练数据量较少使得深层网络模型训练出现过拟合现象,并且使权值的更新过程更具有独立性,而不是依赖于有固定关系的隐层节点间的作用,同时可以降低识别错误率.对自建孤立语音词汇库进行了训练和识别,结果表明,在深度信念网络的基础上引入随机退出优化方法和随机下降连接优化方法可以提升识别率,缓解过拟合现象.
深度学习; 语音识别; 神经网络; 深度信念网络
0 引言
深度学习模型的发展基础是传统神经网络模型,深度学习可以完成需要高度抽象特征的人工智能任务,如语音识别、图像识别与检索和自然语言理解等[1].深层模型是包含多个隐层的神经网络,与传统神经网络只具备有限隐层结构模型相比,深层模型可以对特征进行更好的表达,也具备更强大的建模能力[2-3].深度学习模型较传统的神经网络模型而言具有很大的优势,可以克服浅层模型计算能力有限以及泛化能力受到一定制约等缺点[4-5].然而深层模型也遇到一些问题,在训练时需要大量的数据进行训练,否则训练过程中可能学习到训练数据的噪声,出现过拟合现象[6].目前,构建大数据集用来进行训练与学习是比较复杂的,小数据集在实践领域中的应用更加普遍.因此,解决小数据集在深层模型中的应用会遇到的过拟合问题,具有现实研究意义.
本文提出随机退出优化方法和随机下降连接优化方法,对深度学习预训练后的微调过程进行改进,减少因为训练数据较少而对深层模型所造成的过拟合,使得权值的更新过程更具有独立性,而不是依赖于有固定关系的隐层节点间的作用,提高了学习效率.
1 基于随机退出优化方法的深度学习
深度学习在训练少量样本时,随着迭代次数的增加,节点间的依赖性也会增加,导致某些节点必须在其他节点的联合作用下才工作.提出随机退出思想的目的是减少节点间的依赖性,此外,也为了减少深度学习对小样本训练时过拟合现象的出现.
1.1 随机退出的思想
过拟合是指一个拟合数据在训练数据上能够获得比其他数据更好的拟合,但是在训练数据外的数据集上却不能很好地拟合数据,这种现象称为过拟合现象.在深度学习训练中,如果训练的样本比较少,那么很容易出现过拟合现象.为了有效防止过拟合现象的产生,提出随机退出的方法.例如,给定一个假设空间M,设m属于M,若存在其他数据m′,使得在训练样本中m比m′的错误率小,但在整体实例分布上m′比m的错误率小,那么就说m过度拟合训练数据.训练数据中存在噪音或者训练数据过少是导致过拟合的主要原因.随机退出是指在进行模型训练时,随机选定一些网络中隐层的某些节点,令这些节点的权重不工作.被选中的隐层中不工作的节点权重可以看作非该网络结构的节点,但是仍将其权重进行保留,停止这些节点的工作目的是使其暂时停止更新权重,而在下一次样本输入时,这些节点将重新开始工作[7].
通常情况下,网络中的每个节点都是相对独立的,并且具有保留节点本身的固定概率p,概率p可以根据验证集来确定,或者直接将其设为0.5.对输入节点来说,通常最佳的固定概率更接近1.
图1为没有引入随机退出的网络,将随机退出引入网络模型后,将会形成一个稀疏网络,如图2所示.图2中的虚线圆圈表示已经退出的网络节点,该稀疏网络包含所有被保留下来的节点.假设该网络为一个n层网络,那么该网络有2n种可能形成的稀疏网络.这些所有可能形成的稀疏网络共享权值,总参数仍然为O(n2).每次进行训练时,将对形成的新的稀疏网络进行训练.因此,对引入随机退出的网络进行训练的过程可以看作是对2n个共享权值的稀疏网络进行训练的过程.

图1 未引入随机退出的网络Fig.1 Network without dropout

图2 引入随机退出的网络Fig.2 Network with dropout
1.2 随机退出模型描述
假设一神经网络模型有L层隐层,l∈{1,…,L}为网络隐层的索引,向量z(l)为l层的输入向量,向量y(l)(y(0)=x为输入)为l层的输出向量,W(l)和b(l)分别为l层的权值和偏置.
标准神经网络的前馈操作如图3所示,其中l∈{0,…,L-1},隐层单元为i.zi和yi分别满足:

(1)
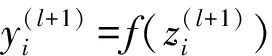
(2)
式中:f为任意激活函数.
当引入随机退出之后,神经网络的前馈操作过程如图4所示.此时zi和yi满足:

(3)
(4)
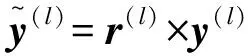
(5)

1.3 随机退出在深度学习中的应用
深度信念网络(DBNs)是由多个受限玻尔兹曼机(RBMs)组成的深层网络,它既可以被看作一个生成模型,也可以被看作一个判别模型[9].它的训练过程是使用非监督方法进行预训练获得权值,这一步与神经网络随机初始化初值的过程相似,不同的是深度学习的第一步是通过学习输入数据结构得到的,与神经网络通过随机初始化相比,深度学习获得的这个初值更接近全局最优.训练完成之后还需要对网络参数进行调优,使得认知和生成表示一致.

图3 标准神经网络的前馈操作Fig.3 Feed forward of standard network model
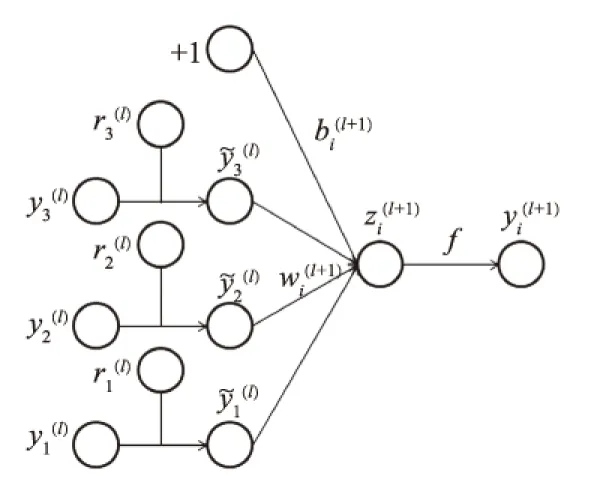
图4 引入随机退出后神经网络的前馈操作Fig.4 Feed forward of network model with dropout
方法测试样本正确率/%训练样本错误率的均方误差未引入随机退出85.50.042引入随机退出880.066
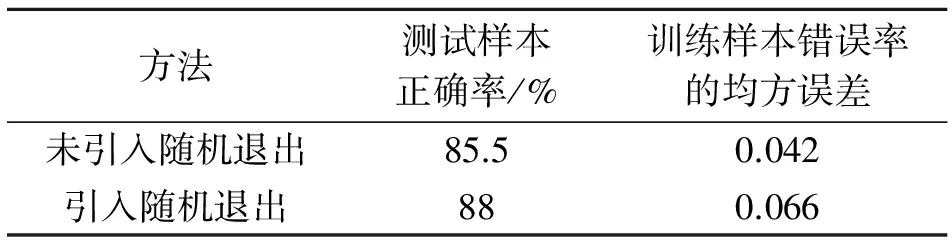
深度学习的调优是根据第一步各层参数进一步优化整个多层模型的参数,这是一个有监督学习的过程.将随机退出方法应用于深度学习的调优过程,使得每一个单独节点学习有用的特征,降低神经元之间的依赖性,调优之后获得更稳定的权重,提高深度学习的学习效率.表1 为将随机退出应用于MNIST数据库识别的前后对比结果,可以看出,过拟合现象减少,识别率提高.
通过实验可以看出,引入随机退出方法之后,训练数据错误率的均方误差较引入前有所增长,但测试样本识别正确率得到提高,说明随机退出具有较好的泛化能力,可以防止过拟合.
2 基于随机下降连接优化方法的深度学习
提出的随机退出思想是随机选择隐层网络中的一些节点不工作,那么被选中不工作的节点就相当于暂时不在这个网络中,与之相连的所有权重也不进行工作[10].如果仅仅使与节点相连的一些权值停止工作,则会形成另外一种网络,就是所提出的基于随机下降连接思想的网络.

图5 引入随机下降连接后的网络Fig.5 Network with dropconnect
2.1 随机下降连接的思想
随机退出的思想是在反向传播时只利用剩余的“活跃”节点,也就是只利用那些被随机选中的节点.这种做法可以显著减少过拟合现象,并且提高测试性能.随机退出方法是在训练过程中以一定概率1-p将隐层节点的输出值清零,不再更新与该节点相连的权值.与随机退出方法不同的是,随机下降连接不是随机将隐层节点的输出清零,而是将节点中的每个与其相连的输入权值以1-p的概率清零.随机下降连接的推理部分与随机退出不同,在对随机退出网络进行推理时,是把所有的权重W都规整到一个系数p.而在对随机下降连接进行推理时,采用的是对每个输入的权重进行高斯分布的采样,该高斯分布的均值和方差与p有关.图5是引入随机下降连接后的网络.
2.2 随机下降连接模型描述
假设有一个具有全连接层的神经网络,输入层为v=[v1,v2,…,vn]T,权值参数为W(d×n),输出层为r=[r1,r2,…,rd]T,该输出是由输入向量和权值矩阵利用非线性激活函数进行矩阵相乘得出的.设该激活函数为a(u),则
r=a(u)=a(Wv).
(6)
随机下降连接与随机退出类似,这两种方法都引入了动态稀疏模型,但是两者不同的是,随机下降连接是权值的“稀疏”,随机退出是输出层中输出向量的“稀疏”.换句话说,将随机下降连接应用于全连接层时,在训练阶段的“稀疏”连接是随机进行选择的.将随机下降连接应用于全连接层时,输出为
r=a((M*W)v),
(7)
式中:M表示连接信息的二元矩阵,Mij服从伯努利分布(Mij~Bernoulli(p)).矩阵M中的每个部分在每一次训练过程中都是独立的,这就使得每一次初始化网络连接时都会形成不同的网络连接.
随机下降连接模型主要分为3个部分:输入层、随机下降连接层和Softmax分类层.
输入层:x为整个模型的输入数据,v为输出,Wg为提取的参数,则有
v=g(x;Wg),
(8)
式中:g()为具有全连接层的神经网络;Wg为滤波器,即网络中的参数.
随机下降连接层:v作为第一步的输出,W为全连接权值矩阵,a为非线性激活函数,M为二元矩阵,则有
r=a(u)=a((M*W)v).
(9)
Softmax分类层:将r作为输入,使用参数Ws计算输出k的维数(k为数字分类的数目),则有
o=s(r;Ws).
(10)
2.3 随机下降连接在深度学习中的应用
随机下降连接方法在深度学习中的应用与随机退出方法相似.深度学习的调优是根据第一步各层参数进一步优化整个多层模型的参数,若训练样本数量较小,则很可能在预训练时产生过拟合.调优阶段,将反向传播网络引入随机下降连接,把第一步预训练获得的输出数据作为引入随机下降连接的反向传播网络的输入进行训练,调整第一步学习到的权重.由于网络层之间是神经网络连接,此时引入随机下降连接方法可以在调优阶段调整第一步通过预训练得到的比较不理想的权重.
引入随机下降连接,输入时随机让一些节点不工作,这些不工作的节点也不会得到误差贡献,其泛化能力较随机退出方法更强一些.
3 实验与结果分析
语音样本为数字1~10的英文读音,语音样本库中包括9个说话者(6男和3女),并且发音较清晰.实验首先对语音样本进行语音特征提取,采用对语音样本的梅尔倒谱系数MFCC参数进行提取.由于每一个英文数字读音的特征参数矩阵的维数都比较大,如果不对提取的语音特征进行处理,那么在进行参数训练时,会使得所需存储空间以及计算量变得非常庞大.因此,本文使用主成分分析法(PCA)对数据进行降维,得到语音样本库,用于语音识别.
3.1 深度信念网络进行语音识别
在语音样本库中取2 000个样本用于训练,1 000个样本用于识别,并构建具有2个隐层的深度信念网络.训练阶段,大致过程是每层训练一个RBMs,RBMs网络如图6所示.根据RBMs训练的权值,利用可视层的偏置来产生上一层的输入,再继续进行下一个RBMs的训练[10].与进行传统神经网络训练一样,每次以100个数据单位进行训练.
对RBMs的训练,根据v1(可视层的第一个节点)生成h1,根据h1构造v2,根据v2重构h2,之后更新权值与可视层的偏置和隐层的偏置.深度信念网络的训练完成之后还需要把参数传递给神经网络,调优阶段仍需要使用普通的神经网络BP算法.图7为DBNs训练流程图.DBNs预训练后还有一个调优阶段,即在最顶层的RBMs网络上增加一层BP网络进行反向传播,对权值进行微调.经过训练后,孤立数字识别的正确率为89%.
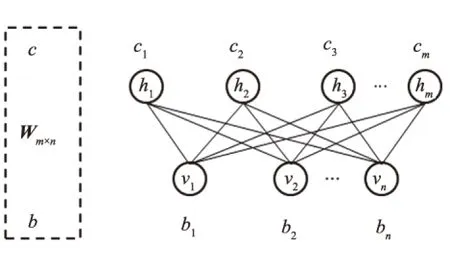
图6 RBMs网络Fig.6 RBMs network
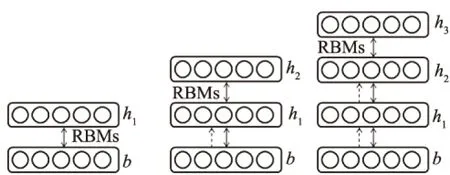
图7 DBNs训练流程Fig.7 DBNs training processing
3.2 基于随机退出优化的深度学习语音识别
基于随机退出优化的深度学习在预训练阶段仍然使用深度信念网络完成,之后在调优阶段引入随机退出优化的神经网络.实验中深度信念网络的网络结构及参数设置为:输入层500,h1隐层400,h2隐层400,输出层10,学习率0.01.由于网络参数是经过深度学习预训练过的,因此,在调优阶段的随机退出比例较小,设随机退出的比例为20%,也就是将p设为0.8,与普通神经网络微调相比,加入随机退出优化之后,识别率提高了1.5%.
3.3 基于随机下降连接优化的深度学习语音识别
基于随机下降连接优化的深度学习在预训练阶段仍然使用深度信念网络完成,之后在调优阶段引入随机下降连接优化的神经网络.基于随机下降连接优化的深度学习与基于随机退出优化的深度学习类似,也是在深度学习调优阶段引入优化方法,设置随机下降连接的比例为20%,与普通神经网络微调阶段相比,加入随机下降连接优化之后,深度学习的识别率提高了0.64%.而在运算时间上,加入随机退出的DBNs网络以及加入随机下降连接的DBNs网络的运行时间,要比相同网络结构的普通DBNs网络的运行时间短.BP网络与3种DBNs网络的实验对比结果为:普通BP网络的正确率为87.2%,普通DBNs网络的正确率为89%,加入随机退出的DBNs网络的正确率为90.5%,加入随机下降连接的DBNs网络的正确率为91.14%.
4 结束语
深度学习在对小样本数据集进行训练时,容易出现训练不充分,学习效率不理想以及过拟合现象.针对深度学习在训练少量数据时易产生的问题,提出了对于深度学习微调阶段的改进方法,即随机退出和随机下降连接方法,这两种方法都是针对深度学习在预训练后的调优阶段的优化.随机退出优化是指随机选定一些网络中隐层的一些节点,令选中的节点的权重不工作,随机下降连接是在输入时就随机选定一些网络中的节点的权重不工作,两者都类似于平均模型.将这两种方法应用于深度学习,使得权值更新的过程更具有独立性,不依赖有固定关系的隐层节点间的作用,降低神经元之间的依赖性,通过调优获得更稳定的权重,提高了深度学习的效率.
[1] 蒋文,齐林.一种基于深度玻尔兹曼机的半监督典型相关分析算法[J]. 河南科技大学学报(自然科学版), 2016, 37(2):47-51.
[2] 余凯,贾磊,陈雨强,等.深度学习的昨天、今天和明天[J].计算机研究与发展,2013, 50(9):1799-1804.
[3] 孙志军,薛磊,许阳明,等.深度学习研究综述[J].计算机应用研究,2012,29(8):2806-2810.
[4] 尹宝才,王文通,王立春.深度学习研究综述[J].北京工业大学学报,2015,41(1):48-59.
[5] 李海峰,李纯果.深度学习结构和算法比较分析[J].河北大学学报(自然科学版),2012,32(5):538-544.
[6] 王洪,刘伟铭. 深度信任支持向量回归的耕地面积预测方法[J].郑州大学学报(理学版),2016,48(1):121-126.
[7] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of machine learning research, 2014, 15(1):1929-1958.
[8] HINTON G, SRIVASTAVA N, KRIZHEVSKY A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. Computer science, 2012, 3(4): 212-223.
[9] 胡侯立,魏维,胡蒙娜.深度学习算法的原理及应用[J].信息技术,2015(2):175-177.
[10]WAN L, ZEILER M, ZHANG S, et al. Regularization of neural networks using dropconnect[C]//Proceedings of the 30th International Conference on Machine Learning. Atlanta, 2013:1058-1066.
(责任编辑:孔 薇)
Application of Deep Learning Model in Speech Recognition Based on Fine-tuning Optimization Method
PENG Yuqing, LIU Fan, GAO Qingqing, ZHANG Yuanyuan, YAN Qian
(SchoolofComputerScienceandSoftware,HebeiUniversityofTechnology,Tianjin300401,China)
Deep learning models in the training with small samples appeared over-fitting phenomenon. Two optimization methods called dropout and dropconnect based on deep learning were proposed. The two methods intended to improve the fine-tune stage of deep learning models, which could reduce the amount of training data, and made the update process more independent, rather than depended on the hidden layer nodes. Moreover,the error rate could be reduced. Then the experimental methods and the models were used to train and identify the MNIST handwritten digit data set and the isolated speech vocabulary database. The results showed that the two methods could improve the recognition rates, and ease the phenomenon of over-fitting.
deep learning; speech recognition; neural network; deep belief network
2016-06-23
国家自然科学基金资助项目(51175145);河北省高等学校科学技术研究重点项目(ZD2014030).
彭玉青(1969—),女,湖南永顺人,教授,主要从事基于认知机制的多模式感知信息融合、数据挖掘、图像处理与应用研究,E-mail: pengyuqing@scse.hebut.edu.cn.
彭玉青,刘帆,高晴晴,等.基于微调优化的深度学习在语音识别中的应用[J].郑州大学学报(理学版),2016,48(4):30-35.
TP391
A
1671-6841(2016)04-0030-06
10.13705/j.issn.1671-6841.2016649
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
成都信息工程大学学报(2022年3期)2022-07-21
复旦学报(自然科学版)(2022年1期)2022-06-16
计算机应用与软件(2020年9期)2020-09-09
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
人民珠江(2019年4期)2019-04-20
小说界(2018年5期)2018-11-26
计算机与数字工程(2018年5期)2018-05-29
