
基于模糊改进聚类分析的数据挖掘模型
2016-12-29 05:59:12庞天杰
太原师范学院学报(自然科学版) 2016年2期
庞天杰
(太原师范学院 计算机系,山西 晋中 030619)
基于模糊改进聚类分析的数据挖掘模型
庞天杰
(太原师范学院 计算机系,山西 晋中 030619)
针对对海量数据库中的大数据进行优化挖掘,可以提高数据特征的提取和检测能力.传统方法采用模糊C均值聚类的数据挖掘算法,当数据在层次聚类过程中空间特征的相似度差异性较小时,数据挖掘的准确度不高.提出一种基于粒子群混沌差分训练对模糊C均值聚类算法进行改进,建立数据挖掘优化模型.首先提出了数据聚类据挖掘模型的总体构架,采用非线性时间序列分析方法进行数据信息流拟合,对数据信息流进行高阶累积量特征提取,采用粒子群混沌差分训练实现模糊C均值聚类算法改进.以改进的模糊聚类算法对提取的高阶累积量特征进行聚类分析,以分析结果为依据对数据挖掘模型进行优化.仿真结果表明,该数据挖掘模型能有效实现海量数据的优化聚类和特征提取,数据挖掘的精度较高,性能较好,避免挖掘过程陷入局部收敛.
模糊C均值聚类;数据挖掘;混沌;粒子群
0 引言
随着网络大数据信息处理技术的不断发展以及云计算的深入应用,海量的大数据通过云存储分布在网络空间中,如何能从海量的大数据中提取有用的信息特征,实现信息检索和分离,成为相关领域专家研究的重点.数据挖掘又称为数据探勘、数据采矿,是建立在对海量数据的信息特征提取和时间序列分析模型构建的基础上,进行数据聚类分析和特征检测的关键技术,数据挖掘可以实现对海量数据信息特征的可靠性检测和感兴趣数据的统计和在线分析处理,通过构建专家信息库,实现专家系统构建和机器学习等,是解决上述问题的有效途径之一,同时,优化的数据挖掘模型将在模式识别、故障诊断和情报检索等领域具有较高的应用价值.
对海量数据进行挖掘是建立在数据信息流的时间序列分析的基础上,通过对数据信息流的特征信息提取,实现数据的聚类挖掘,传统方法进行数据挖掘主要采用基于时频分析的数据挖掘方法、基于粒子群聚类的数据挖掘算法、基于语义特征提取的数据挖掘算法、基于波束形成的数据挖掘算法和基于支持向量机的数据挖掘算法等[1-4],根据以上算法原理,相关学者进行了数据挖掘算法的研究与改进,其中,文献[5]提出一种基于自相关特征匹配的数据挖掘算法,对海量级联数据库中的数据进行自相关波束形成,通过波束形成提高数据的聚焦性能,结合功率谱密度特征提取实现数据优化聚类和挖掘,但是该算法的缺点是计算开销过大,海量数据挖掘的实时性不好;文献[6]提出一种基于文本检测法的网络数据库中关联特征数据挖掘算法,在云计算环境下,采用层次聚类法以及文本检测进行数据的非线性特征空间重构,在此基础上进行语义关联特征检索和特征滤波匹配,提高了数据挖掘和数据库优化访问的性能,但该算法在干扰较大的情况下降低了数据检测和挖掘的准确性;文献[7]采用模糊C均值聚类方法实现数据挖掘,当数据在层次聚类过程中空间特征的相似度差异性较小时,数据挖掘的准确度不高.
针对上述问题,提出一种基于粒子群混沌差分训练对模糊C均值聚类算法进行改进,建立数据挖掘优化模型.首先提出了数据聚类据挖掘模型的总体构架,进行数据结构分析,采用非线性时间序列分析方法进行数据信息流拟合,以数据信息流为研究对象提取数据的高阶累积量特征,描述了模糊C均值聚类(Fuzzy C means clustering,FCM)算法原理,采用粒子群混沌差分训练方法进行模糊C均值聚类算法改进,针对海量的高阶累积量数据特征,采用改进的模糊C均值聚类算法实现数据挖掘模型优化,最后通过仿真实验进行了性能测试,展示了本文设计的聚类算法的优越性能.
1 数据结构分析与数据信息流模型构建
1.1 数据挖掘的总体模型构架

(1)
在(1)式中,i=1,2,…,S,Nc,Nre和Ned分别表示数据挖掘的迭代次数、单位步长下数据个体前进趋化次数和后缀项表个数.

Xi(j+1,k,l)=Xi(j,k,l)+θi×step×φ(i)
(2)
(3)
在上式中,step表示迭代步长,φ(i)表示属性值的集合阶数,Xrand(j,k,l)为当前数据分布节点在Xi(j,k,l)处的先验概率,数据分布结构进行调整后的空间状态矢量特征聚类中心的距离满足:
DS=‖Xi(j,k,l)-Xrand(j,k,l)‖
(4)

图1 数据库中海量数据挖掘的总体流程
假设频繁模式下数据粗糙集ai的属性值为{c1,c2,…,ck}.利用上述获取的特征聚类中心对数据粗糙集ai的属性值进行不断筛选,直到寻找符合频繁模式的候选数据集合,通过数据的信息特征表达模式,实现数据挖掘,根据上述分析,得到对数据库中海量数据挖掘的总体流程如图1所示.
1.2 数据信息流优化模型构建
在上述数据挖掘总体设计的基础上,为了实现数据挖掘模型的优化,需要建立数据信息流模型,首先假设X和Y为的数据流微簇分类属性集合,采用非线性时间序列分析方法建立数据流微簇模型,将其作为研究对象,采用滑动时间窗口采样方法提取大数据信息流的高阶累积量特征[8-10],以此为基础,获取阶累积量特征向量量化所需的时间序列为{x(t0+iΔt)},i=0,1,…,N-1,在向量量化分布空间中海量数据的标记符中心CF记为CF=〈F,Q,n,RT1,RT2,RW〉,数据流时间采样的滑动窗口总数为n,数据特征的平均测度为ε,当ε满足2-λt<ε,λ>0的条件时,利用公式(5)建立数据信息流模型:
X=[x(t0),x(t0+Δt),…,x(t0+(K-1)Δt)]=
(5)
在(5)式中,x(t)表示不同时间和频率下的数据采样时间序列,J是局部均值,m是时移不变性特征函数.假设在数据存储空间内,由于数据分布的非连续层次性,导致在数据挖掘中产生位置和聚类属性偏移,数据时频分布的标量时间序列为x(t),t=0,1,…,n-1,对数据的语义状态特征进行量化编码,利用公式(6)对数据信息流模型进行优化:
u=[u1,u2,…,uN]∈RmN
(6)
其中,m,n分别是在数据的模糊聚类矢量空间中的嵌入为维数和深度,根据上述描述,构建数据信息流模型,以此为基础进行数据挖掘改进设计.
2 基于模糊改进聚类分析的数据挖掘模型建立
2.1 模糊C均值数据聚类及改进
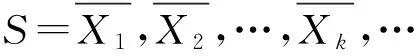
(7)
当满足梯度特征差异度显著、聚类中心初始值一定的情况下,以不同的关联指向性特征为依据,提取非连续层次数据的模糊聚类中心,对数据聚类过程进行自适应训练,训练过程分别表示为:
(8)
(9)
(10)

X={x1,x2,…,xn}⊂Rs
(11)
利用上述的粒子群混沌差分训练方法,对语义本体模型集进行禁忌搜索,完成种群样本xi,i=1,2,…,n的优化,并利用公式(12)获取种群样本的最大趋化算子:
xi=(xi1,xi2,…,xis)T
(12)
在利用粒子群混沌差分训练执行算子后,把有限数据集合X分为c类,利用公式(13)获取挖掘模糊聚类中心矩阵:
V={vij|i=1,2,…,c,j=1,2,…,s}
(13)
在(13)式中,Vi为数据特征分解的第i个矢量.
对优化后的种群粒子进行判断,确定是否达到最大趋化,将达到最大趋化海量数据进行交叉编译,利用公式(14)输出的编译结果:
引入={μik=1,2,…,c,k=1,2,…,n}
(14)
引入混沌扰动量对编译结果进行不断更新,结合公式(13),利用公式(15)获取数据挖掘的聚类目标函数:
(15)
在(15)式中,m为粒子种群大小,(dik)2为采样的海量数据样本xk与Vi的测度距离,利用公式(16)进行计算:
(dik)2=‖xk-Vi‖2
(16)
满足
(17)
假设Nc,Nre和Ned分别表示粒子的趋向性运动次数、粒子复制次数和粒子迁徙次数,根据混沌差分进化算法的全局搜索性寻找聚类目标函数进行求解,利用公式(18)求得粒子群混沌差分训练后的优化数据聚类目标函数的最优解,提高数据聚类算法的寻优能力,完成模糊C均值数据聚类的改进:
(18)
2.2 特征提取及数据挖掘算法实现
利用上述改进的模糊C均值聚类算法,进行数据挖掘模型优化设计,详细实现过程描述如下:假设数据信息流中时域窗TLX,TLY,利用公式(19)获取二维平面(m,n)上数据信息流的空间轨迹:
(19)
假设在两个离散采样网格参数内的高阶累积量密度谱为amn,采用Gabor基函数对数据信息流的空间轨迹进行自适应误差修正,修正值为:
(20)
以自适应误差修正后的数据信息流空间轨迹为依据,利用选择特定的窗函数,通过积分变换核得到输出的数据信息流的高阶累积量为:
(21)
(22)

数据编码后,为了反映出数据类群的多样性特征,按照差分进化(DE,differential evolution)算法流程进行数据挖掘,在聚类中心的辐射半径内,得到NP个数据的混沌序列:
xn+1=4xn(1-xn)n=1,2,…,NP
(23)
获取混沌序列中非连续层次数据的扰动变量,通过高阶累积量特征提取,把特征数据加入到扰动变量中,结合混沌分量的伴随跟踪性,获取数据挖掘的迭代方程为:
Δxi=a+(b-a)xnn=1,2,…,NP
(24)
数据挖掘迭代方程可以使数据之间的交叉项之间产生衰减,避免了在数据挖掘过程中陷入局部最优,利用公式(25)建立数据挖掘的优化模型:
(25)
3 仿真实验与结果分析
为了测试本文算法在实现数据模糊改进聚类和优化挖掘中的性能,进行仿真实验.实验采用Matlab仿真软件进行数据挖掘算法的编程设计,参数设计中,粒子个体10 000,最大种群数S=59 023,迭代次数K1=456,K2=240.设置r1=r2=1,p1=2,m=12,L2=12,粒子位置的阈值设为μ=10,数据的采样的间隔为0.26 ms,大数据信息采样的归一化初始频率f1=0.8,大数据聚类中粒子群混沌差分扰动的交叉概率取值为[0,1],离散采样率为fs=10*f0Hz=10 KHz,带宽B=1 000 Hz.根据上述仿真环境和参数设定,以大型网络Web数据库Deepweb2015中的数据为采样对象,进行数据优化聚类和挖掘仿真,首先进行数据信息流的原始时域波形采样,得到采样结果如图2所示.
以上述采样数据为研究对象,进行数据聚类分析,取其中的两段样本为测试对象,提取高阶累积量特征,高阶累积量特征在时间-频率面上的分布结果如图3所示.

图2 数据信息流时域采样波形

图3 海量数据的高阶累积量特征提取结果
针对海量的高阶累积量数据特征,采用改进的模糊C均值聚类算法实现数据挖掘,得到聚类结果如图4所示.

图4 数据聚类输出
分析图4可知,采用本文改进的FCM聚类算法进行大数据优化聚类,能有效分别数据的种类属性,实现数据优化挖掘,为了定量分析算法性能,采用本文方法和传统方法,以数据挖掘的精度为测试指标,得到对比结果如图5所示.分析图5可知,采用本文算法进行数据挖掘的准确挖掘概率高于传统方法,展示了本文方法的优越性能.

图5 数据准确挖掘概率对比分析
4 结束语
本文提出一种基于粒子群混沌差分训练的模糊C均值改进聚类算法实现数据挖掘模型优化,首先构建了数据聚类据挖掘模型的总体结构,进行数据结构分析,采用非线性时间序列分析方法进行数据信息流拟合,采用粒子群混沌差分训练方法进行模糊C均值聚类算法改进,针对海量的高阶累积量数据特征,采用改进的模糊C均值聚类算法实现数据挖掘模型优化.研究结果表明,采用本文算法进行数据聚类和挖掘,性能较好,精度较高,功能指标优于传统方法,展示了较高的应用价值.
[1] 刘经南,方 媛,郭 迟,等.位置大数据的分析处理研究进展[J].武汉大学学报·信息科学版,2014,39(4):379-385
[2] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015(5):2015099
[3] 李 鹏,刘思峰.基于灰色关联分析和D-S证据理论的区间直觉模糊决策方法[J].自动化学报,2011,37(8):993-999
[4] 刘 俊,刘 瑜,何 友,等.杂波环境下基于全邻模糊聚类的联合概率数据互联算法[J].电子与信息学报,2016,38(6):1438-1445
[5] BAE S H,YOON K J.Robust online multiobject tracking with data association and track management[J].IEEE Transactions on Image Processing,2014,23(7):2820-2833
[6] JIANG X,HARISHAN K,THAMARASA R,et al.Integrated track initialization and maintenance in heavy clutter using probabilistic data association[J].Signal Processing,2014,94:241-250
[7] 陆兴华,陈平华.基于定量递归联合熵特征重构的缓冲区流量预测算法[J].计算机科学,2015,42(4):68-71
[8] 王跃飞,于 炯,鲁 亮.面向内存云的数据块索引方法[J].计算机应用,2016,36(5):1222-1227
[9] 吴鸿华,穆 勇,屈忠锋,等.基于面板数据的接近性和相似性关联度模型[J].控制与决策,2016,31(3):555-558
[10] 阎 芳,李元章,张全新,等.基于对象的OpenXML复合文件去重方法研究[J].计算机研究与发展,2015,52(7):1546-1557
Data Mining Model Based on Fuzzy Improved Clustering Analysis
PANG Tianjie
(Department of Computer Science,Taiyuan Normal University,Jinzhong 030619, China)
To optimize the massive big data in the database mining, can improve the data feature extraction and detection ability. Traditional method using fuzzy c-means clustering data mining algorithm, when the data in the process of hierarchical clustering space characteristics of similarity difference is small, the accuracy of data mining is not high. In this paper, a chaos particle swarm optimization difference training to improve the fuzzy c-means clustering algorithm, establish the optimization model for data mining. First puts forward the data clustering according to the overall architecture of the mining model, data structure analysis, nonlinear time series analysis method is adopted to improve the flow of information data fitting, higher-order cumulant features of data streams are extracted, using particle swarm chaos difference fuzzy c-means clustering algorithm to improve the training implementation. With the improved fuzzy clustering algorithm to extract the higher-order cumulant features for clustering analysis, based on the results of the analysis of the data mining model optimization. The simulation results show that the data mining model can effectively realize the optimization of huge amounts of data clustering and feature extraction, data mining of high precision, good performance, avoid digging into local convergence.
fuzzy C means clustering; data mining; chaos; particle swarm optimization
2016-03-13
庞天杰(1980-),男,山西太谷人,硕士,太原师范学院计算机系讲师,主要从事数据挖掘与机器学习研究.
1672-2027(2016)02-0040-06
TP391
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:18
大众投资指南(2021年35期)2021-02-16 01:06:26
军事运筹与系统工程(2020年1期)2020-09-11 06:41:08
当代陕西(2019年14期)2019-08-26 09:42:00
铁道通信信号(2018年12期)2019-01-31 05:36:40
军事运筹与系统工程(2018年1期)2018-11-10 05:33:12
电力与能源(2017年6期)2017-05-14 06:19:37
中学数学杂志(初中版)(2016年5期)2016-11-01 09:00:33
信息通信技术(2015年6期)2015-12-26 01:16:46
军事运筹与系统工程(2015年3期)2015-09-08 13:12:35
