
基于K-均值和K-中心点算法的大数据集分析
2016-12-29 05:59郭晨晨朱红康
太原师范学院学报(自然科学版) 2016年2期
郭晨晨,朱红康
(山西师范大学 数学与计算机科学学院,山西 临汾 041000)
基于K-均值和K-中心点算法的大数据集分析
郭晨晨,朱红康
(山西师范大学 数学与计算机科学学院,山西 临汾 041000)
大数据已然成为当今世界最热门的话题之一,对于海量数据处理方法的研究一直是重要的科研领域,将原有的数据统计分析方法加入到大数据分析中也是必然的研究方向.文章选取了 K-Means 及其K-Mediods算法对KEEL的transaction10k数据集进行评估.该数据包含较大的数据容量,因此对于模拟大数据环境有很好的作用.可以想象到,现实世界庞大的数据真实客观地反映到图像中必然会为分析数据带来极大的便利.输入到这些算法中是随机分布的数据点,并根据其相似度产生的聚类已经生成.比较结果表明,K-Medoids在种子对象的选取和聚类间重叠的合理控制方面要比K-均值更有优势.
大数据;聚类;数据处理;K-Means;K-Medoids
0 引言
海量数据指数型的增长提前宣告了大数据时代的到来,而作为大数据核心的数据挖掘成为信息时代研究的核心领域.数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程,这些信息是清晰的、易理解的、有用的、合理的.而数据挖掘的主要工作任务是将现有数据或者经简单分析的“粗加工”数据“加工”成包含知识的有用信息的过程[1].
数据挖掘服务端接收来自客户端的原始数据、元数据和可能的特定领域知识.海量数据通过数据挖掘的筛选、提取、改造后通常不再巨大,这也为详细研究数据提供可能性.经过“粗加工”的数据通常还需要用相应的聚类算法进一步“细加工”,聚类是数据挖掘中常见的最常见的技术,它是一种对抽象或现实事物的认知、分类和归纳过程.在数据处理方面,其探索能力、构建预测模型以及克服数据中的“噪声”方面具有巨大的潜力.数据集通过聚类形成不同的簇进而形成图像,这样有利于对数据集直观性的分析和规律、知识的表露.常见聚类方法主要是基于距离的、层次的、网格的或者密度的,每种方法都有其优势和局限性.而本文主要介绍基于距离的K-Means及其改进算法K-Medoids.
1 算法
1.1 K-Means
K-Means是是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则.K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量的最优分类,使得评价指标最小.算法采用误差平方和准则函数作为聚类准则函数.
K-Means首先需要事先选取若干个中心点,这一过程主要依靠用户对数据的预先估计.最初中心点的选取直接影响聚类的效果和最终的聚类数量.当然,为了降低这部分的人为误差,可以使用很多方法来实现,诸如:
1)层次聚类法:利用层次聚类的迭代算法寻找初始中心数目[2].
2)稳定性法:通过对一个数据集的多次采样,利用聚类算法分别进行聚类,比较它们间的相似性最终确定中心数目[3].
3)系统演化法:系统演化方法能提供关于所有聚类之间的相对边界距离或可分程度,它适用于明显分离的聚类结构和轻微重叠的聚类结构[4].
4)canopy法:参考文献[5].
5)贝叶斯信息准则法:参考文献[6].
K-Means算法如下:
输入:结果簇的个数K,包含n个对象的数据集D;
输出:K个簇的集合.
第一步:输入数据集和K的值;
第二步:若K=1,则退出;
第三步:从D中选择k个对象作为最初的簇中心;
第四步:将其余对象分配到最近的种子对象所代表的簇中;
第五步:计算每个簇中所有对象的平均值获得每个类的类中心,替代最初的簇中心;
第六步:重复上面两步,直到每个簇的聚类中心不再改变.
算法成功的标准在于衡量迭代次数或者说是聚类中心变化的次数.
1.2 K-Medoids
K-Mediods是基于K-means的改进算法.在K-means算法中,由于中心点的选取是基于当前簇中所有对象的平均值,因而容易受到异常值或者离群值的影响.为了克服这样的问题,从而提出了新的中心点选取方法,即从当前簇中选取这样的一个点——它到当前簇中所有点的距离是最小的,作为新的中心点.
K-Mediods算法如下:
输入:结果簇的个数K,包含n个对象的数据集D.
输出:K个簇的集合.
第一步:从数据集D中随机选择k个对象作为初始的种子对象;
第二步:将其余对象分配到最近的种子对象所代表的k个簇中;
第三步:随机选择一个非种子对象;
第四步:计算用非种子对象代替种子对象的总代价C;
第五步:如果C<0,则用非种子对象替换种子对象,从而产生新的对象集合;
第六步:除非种子对象不再发生变化,否则重复四步过程.
2 实验
本文分别将K-Means和K-Mediods算法应用于transaction10k数据集[7]上,程序是基于MATLAB编译实现的.由于该算法相对简单,因此时间消耗并不多,只是毫秒级别.当然在不同性能的计算机中运行的时间有一些差别.随机交易10 000次,商品及数据生成见表1.

表1 transaction10k数据集基本信息
K-Means的聚类效果如图1所示,几个聚类间存在着明显的重叠,这是由于K-Means本身的缺陷导致的.
K-Mediods的聚类效果如图2所示,聚类间的重叠部分相比K-Means明显减少,这表明基于中心点或者中心对象划分方法具有一定的优势.
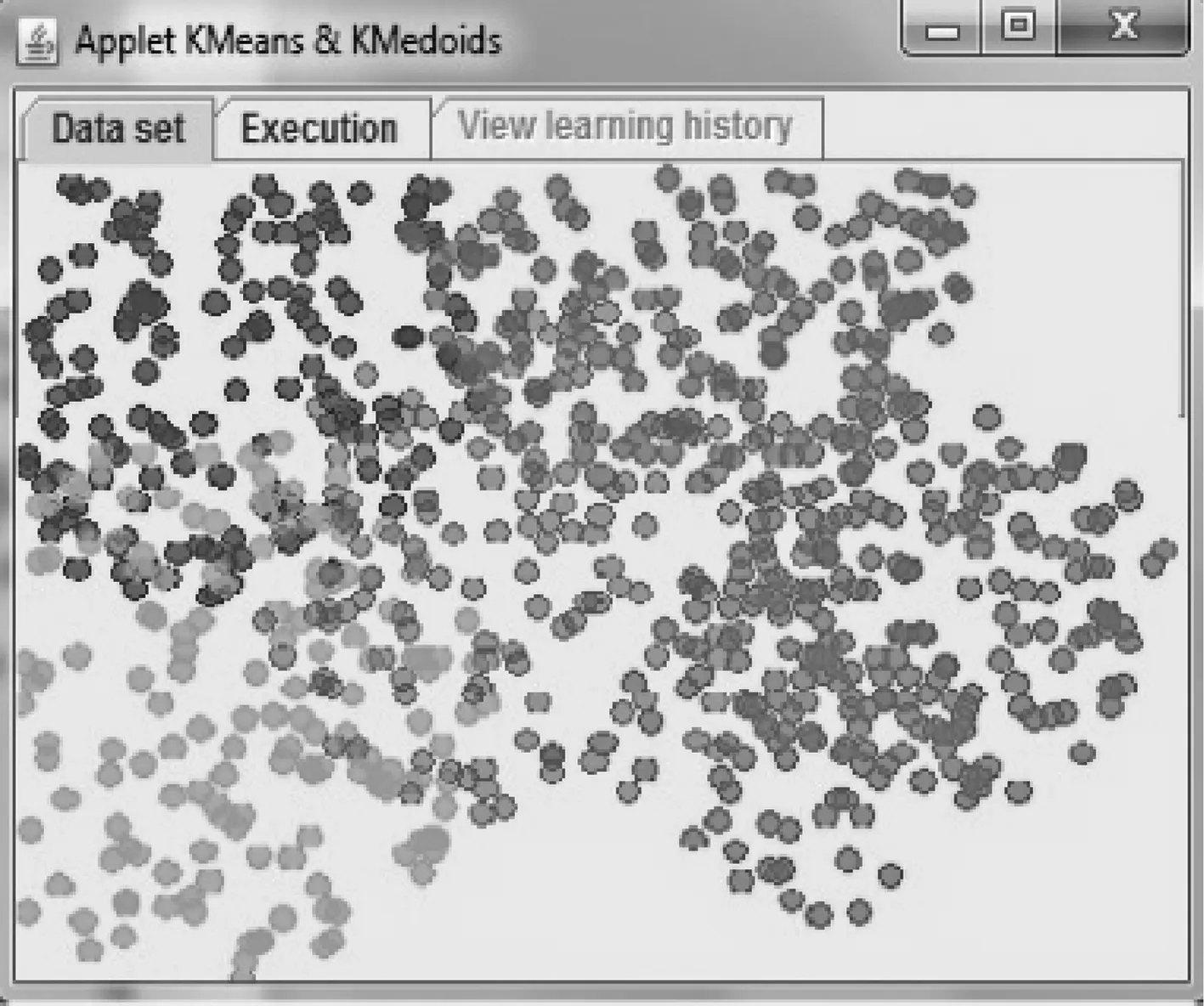
图1 K-Means聚类示意图
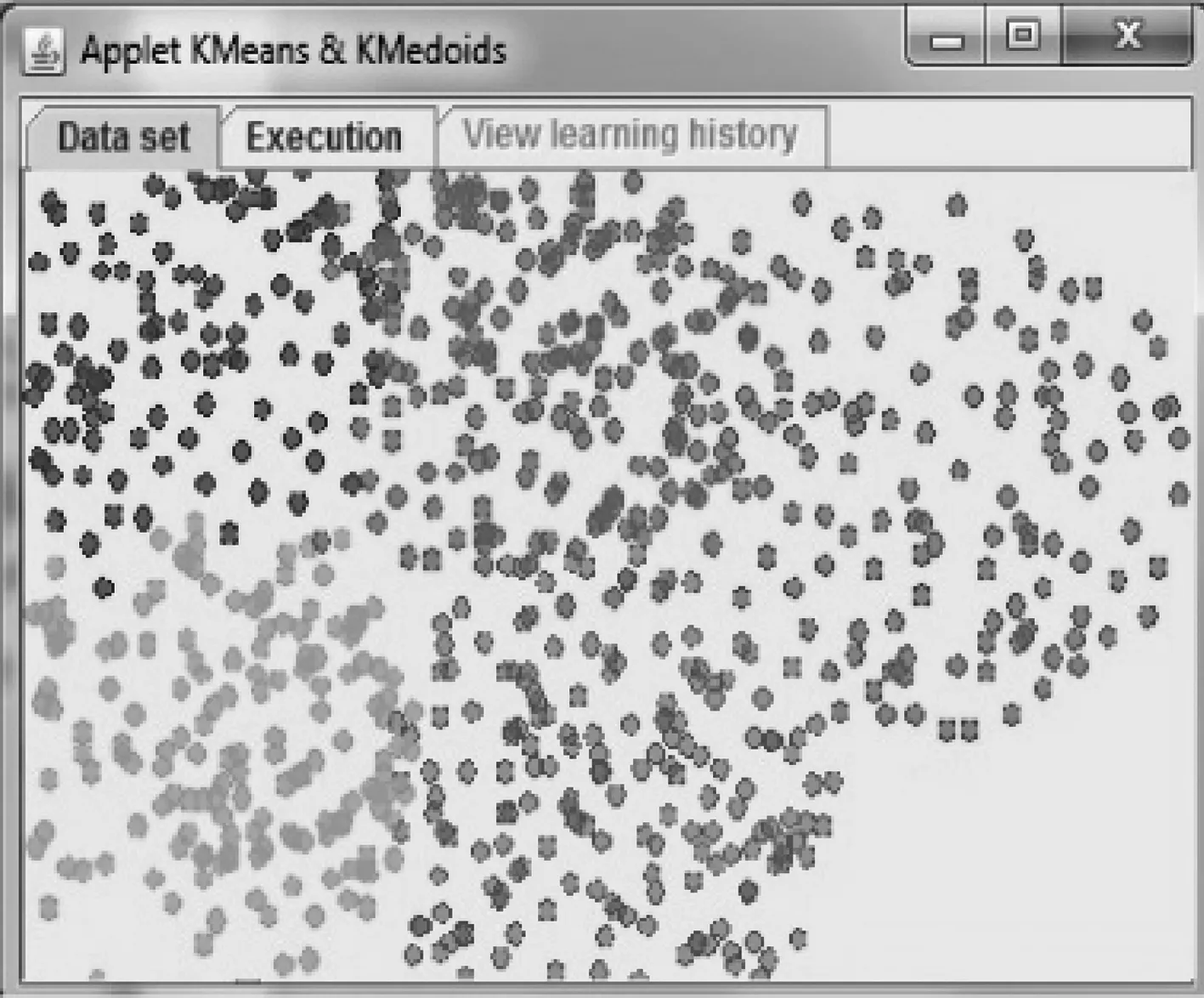
图2 K-Mediods聚类示意图
图3和图4分别表示了K-Means和K-Mediods各个聚类中心的位置.可以发现,在不同的种子对象迭代算法影响下,聚类中心的位置也存在很大的不同.
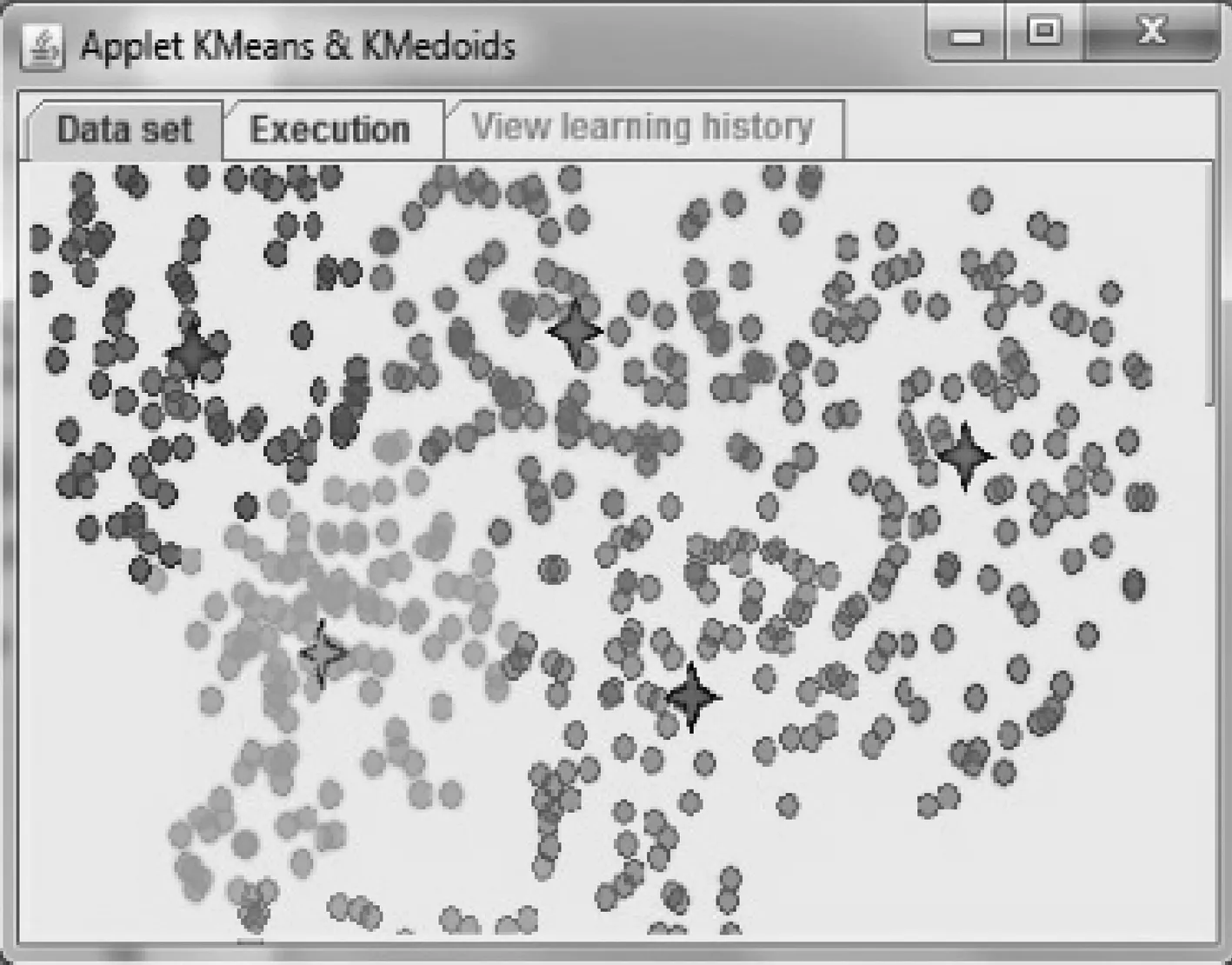
图3 K-Means聚类中心分布图
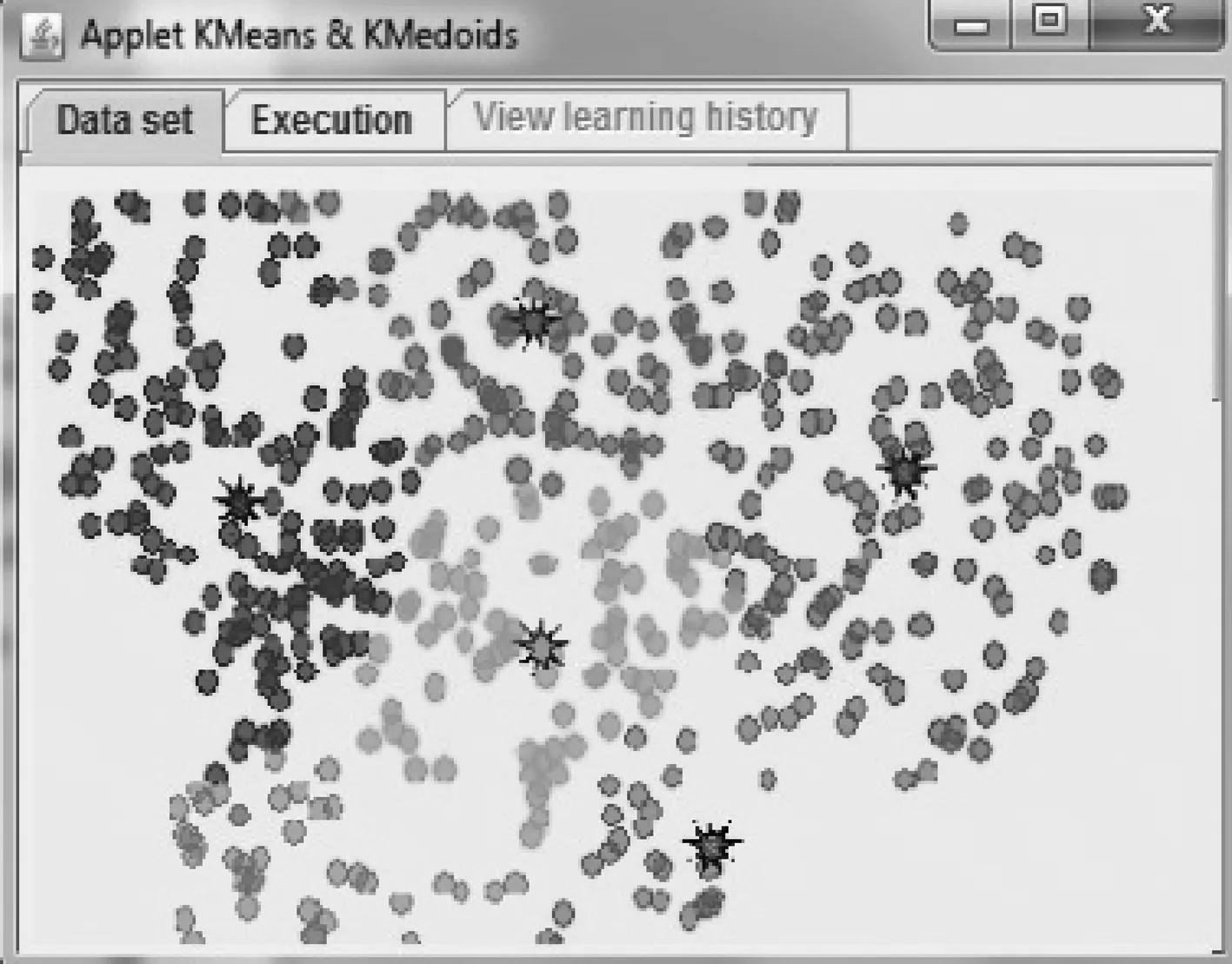
图4 K-Mediods聚类中心分布图
图5、图6展示了K-Means和K-Mediods对于异常值得处理,容易发现,K-Mediods在这一方面显示了强大的能力,这也是K-Mediods抗噪声能力最明显的体现.

图5 K-Means异常点处理图

图6 K-Mediods异常点处理图
3 结论
本文介绍了我们常见的两种聚类算法,通过KEEL(Knowledge Extraction based on Evolutionary Learning)提供的模拟软件,对数据量相对较大的数据集进行了聚类分析.显示出在数据集较大的情况下,K-Means和K-Mediods聚类效果间的差异.由于后者更加合理地处理异常值,因此聚类结果收到的噪声数据的干扰明显小于K-Means.对于大数据处理中很多庞大数据问题,K-Mediods显然更具有开发和应用潜力.
[1] VELMURUGAN T,SANTHANAM T.A survey of partition based clustering algorithms in data mining:an experimental approach.Information Technology Journal,2011,10 (3):478-484
[2] PANG Ningtan.MICHELINE Steinbach,VIPIN kumar.数据挖掘导论.北京:人民邮电出版,2011:320-327
[3] HAN Jiawei.MICHELINE kamber, PEI Jian.数据挖掘概念与技术.北京:机械工业出版社,2012:295-304
[4] 王开军,李 健,张军英,等.聚类分析中类数估计方法的实验比较[J].计算机工程,2008,34(9):198-199
[5] 毛典辉.基于MapRecude的Canopy-kmeans改进算法[J].计算机工程与应用,2012,48(27):22-26
[6] 储岳中.一类基于贝叶斯信息准则的k均值聚类算法[J].安徽工业大学学报(自然科学版),2010(4):409-412
Analysis of Large Data Sets Based on K-Means and K-Mediods Algorithm
GUO Chenchen,ZHU Hongkang
(School of mathematics and computer science,Shanxi Normal University,Linfen Shanxi 041000, China)
Big data has already become one of the hottest topics in today’s world, Research on massive data processing methods is always an important research area.The original data statistics analysis method to join the big data analysis is also an inevitable research direction.In this paper the two most popular clustering algorithms K-Means and K-Medoids are evaluated on dataset transaction10k of KEEL.You can imagine, The reality of the huge data in the world objectively reflected in the image is bound to bring great convenience for the analysis of data.The input to these algorithms are randomly distributed data points and based on their similarity clusters has been generated.The comparison results show that time taken in cluster head selection and space complexity of overlapping of cluster is much better in K-Medoids than K-Means.
Big data; Clustering; Data processing; K-Medoids; K-Means
2016-04-20
郭晨晨(1992-),男,山西长治人,山西师范大学数学与计算机科学学院在读硕士研究生,主要从事计算机应用研究.
1672-2027(2016)02-0056-04
TP18
A
猜你喜欢
大众投资指南(2021年35期)2021-02-16
计算机技术与发展(2020年8期)2020-08-12
中国交通信息化(2020年1期)2020-07-27
电脑报(2020年12期)2020-06-30
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年4期)2019-09-10
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
大众摄影(2015年9期)2015-09-06
