
文学模式识别:文本细读与机器学习之间的现代主义①
2016-12-20 02:41霍伊特懿译
山东社会科学 2016年11期
[美]霍伊特·朗 [美]苏 真 撰 林 懿译
(芝加哥大学 东亚语言与文化系,美国 芝加哥 60637;芝加哥大学 英文系,美国 芝加哥 60637)
文学模式识别:文本细读与机器学习之间的现代主义①
[美]霍伊特·朗 [美]苏 真 撰 林 懿译
(芝加哥大学 东亚语言与文化系,美国 芝加哥 60637;芝加哥大学 英文系,美国 芝加哥 60637)
本文的标题即宣告了它的核心目标:提出一种可以整合常见的人文主义手法和电脑计算手法的文学文本阅读形式。近年来,运用计算机来阐释文学引发了激烈的争论。一方面,弗朗科·莫瑞狄(Franco Moretti)、马修·乔克斯(Matthew Jockers)、马修·威尔肯斯(Matthew Wilkens)和安德鲁·派博(Andrew Piper)等学者支持运用主题建模、网络分析等精密机器技术来揭示从海量数字化文学资料库中挑选出的语言与形式的宏观模式。*Franco Moretti, Distant Reading, London, 2013; Matthew L. Jockers, Macroanalysis: Digital Methods and Literary History, Urbana, Ill., 2013; Matthew Wilkens, “The Geographic Imagination of Civil War-Era American Fiction,” in American Literary History 25 (Winter 2013), pp. 803-40; and Andrew Piper and Mark Algee-Hewitt, “The Werther Effect I: Goethe, Objecthoods, and the Handling of Knowledge,” in Matt Erlin and Lynn Tatlock (eds), Distant Readings: Topologies of German Culture in the Long Nineteenth Century, Rochester, N.Y., 2014, pp. 155-84.另一方面,亚历山大·加洛韦(Alexander Galloway)、大卫·科伦比亚(David Golumbia)、塔拉·麦克弗森(Tara McPherson) 和艾伦·刘(Alan Liu)等新媒体研究领域的学者则批评机器技术,认为此类技术将文学文本的复杂性化约成纯粹的“数据”,或它们与批评理论的目标无法匹配。*有关加洛韦、科伦比亚与麦克弗森的近期批评,参见期刊Differences关于“在数字人文的阴影下”主题的特别话题。他们的论文包括:Alexander Galloway, “The Cybernetic Hypothesis,” in Differences 25, No.1(2014), pp.107-31; David Golumbia, “Death of a Discipline,” in Differences 25, No. 1 (2014), pp.156-76; 与 Tara McPherson, “Designing for Difference,” in Differences 25, No. 1, 2014, pp.177-88.同时参见Alan Liu, “Where is Cultural Criticism in the Digital Humanities?” in Debates in the Digital Humanities, Matthew K. Gold (ed), Minneapolis, 2012, pp. 490-509.这里我们要通过创建一个不将一种阅读模型与另一种模型对立,而是把人文主义方法和电脑计算方法整合进一种我们称为文学模式识别的文学分析方式,来超越这一僵局。
这一整合的动机是双重的。首先,当下多数人文主义学者已经参与了某些形式的电脑计算批评。正如泰德·安德伍德(Ted Underwood)指出的,任何计算机辅助的信息搜索,不管是通过谷歌还是更正式的诸如JSTOR这样的学术数据库,都是一种由机器学习算法所支持的“数据挖掘”。*Ted Underwood, “Theorizing Research Practices We Forgot to Theorize Twenty Years Ago,” in Representations 127 (Summer 2014), p.65.每次我们在谷歌图书或其他数字化资料库中输入一个搜索词条,我们都在与这些算法互动。安德伍德补充道,人文主义研究者们倾向于忽略这种互动而不进行理论研究,他们认为搜索引擎仅仅是帮助我们通达真正阐释工作的工具,同时还往往坚称这些工具背后的科学是非人性的、僵硬的、机械的。甚至在我们批评这些工具与我们作为人性读者所参与的细致分析和批判性思考相比的“黑箱”性质时,我们还是在自己的研究中把这些工具黑箱化。*“黑箱”是理工类程序中的常见概念,指某程序的机制无法被人完全掌控或观测,只能知道输入和输出的结果。——译者注运用更复杂数据挖掘工具的文学研究学者更是加倍地受到指责,理由是他们通过冰冷而不知变通的机器逻辑来扭曲了文学文本。然而,随着我们与文本(以及信息)的互动越来越多地受到数字格式和大数据库的影响,这一立场变得愈发站不住脚。我们无法在继续忽视机器算法如何“阅读”文学信息的同时,又盲目地依赖它们来强化我们自身的阅读与阐释实践。
与此同时,主张批评家们必须学习这些计算程序如何操作并不表示这些程序是毫无问题的人力阅读模式的替代品——也不意味着对机器技术正当性的评判可以由更复杂的计算模型和更大容量的数据库来满足,尽管斯坦福文学实验室(Literary Lab)的莫瑞狄、马克·阿尔及-休伊特(Mark Algee-Hewitt)与莱恩·霍伊泽尔(Ryan Heuser)已在这些方面作了杰出的工作。*参见这一团队在斯坦福文学实验室印发的一系列出色的手册,Pamphlets,
以上正是我们这里通过一个对文学现代主义、特别是英语俳句的案例分析所试图达到的目标。从什么定义了现代英语俳句这一基本问题开始,我们同时运用常见批评模型(文本细读与历史主义批评)和计算机手段(机器学习)来给出三种相异的答案。也就是说,我们将通过三种文本分析模型来考察一个实质为文体辨认的问题。这种做法意在表明每一种模型都暗含了其自身的文本本体观,且每种模型都揭示了与它的本体观相连的对文学模式和文体学影响的理解。不过,我们并非要偏重某一模型而贬低另一模型,而是要主张通过这类人力阅读与机器阅读的交互作用,凸现出一种关于俳句这种文学事物的新的批评视角。通过将这些文学分析模型理解为按其自身视域具有理据、而在更广阔的模式识别阐释学中可相互对照,一种关于俳句——以及广义地关于现代主义文本——的新的本体观出现在人们视野中。
本论文由四部分组成。第一部分通过文本细读来详述俳句的特点;第二部分将俳句作为社会历史事物来阅读;第三部分则通过机器学习的框架来阐释俳句。在以上各部分中,我们将分析每一种批评手法提供的特有而自发的关于俳句的观念,并且揭示这些观念如何架构起相应手法辨别俳句——作为一种特殊且可重复的文体或文学模式——的能力。在最后一部分中,我们使各批评手法直接对话,以表明尽管它们遵循的对俳句的本体论认识各不相同,不同的识别文学模式(pattern)的方式却可以补充各自的不足。综合起来考察,这些批评手法提供了作为社会与文化氛围的英语俳句的更全面的图景——它是更广阔的流行于20世纪初的东方主义风格的一部分。*结语部分将阐明我们运用这一术语的准确意义。由此,本论文最终通过展示我们如何能够把美国现代主义时期的东方主义历史重新理解为不同本体论范畴所表达的一套相互重叠的文本模式,为现代主义时期的东方主义研究作出贡献。
作为现代主义文本的英语俳句
首先,什么决定了一首诗是否是英语俳句?一种判定诗歌属于某种创作体裁的方法是将它当作一个单独的文本来研究,并仔细分析它的内容与形式特点。这种方法就是我们认为的典型的文本细读。假设我们面对埃兹拉·庞德的《四月》这首诗,我们将怎样决定它是否是英语俳句?
三个幽灵向我走来
撕裂我
引我走向橄榄树枝
赤裸躺卧之地;
光亮雾霭下的苍白尸体。*Ezra Pound, “April,” in Personae: Collected Shorter Poems of Ezra Pound, London, 1952, p. 101.
由于这首诗不具备日本俳句“五七五”的传统音节模式,我们可以首先总结出,就最严格的形式定义而言,这首诗不是俳句。然而一些纵然天真却是直觉性的观察却能够支持该诗借用了日本俳句的其他文体特点这一看法。首先,这是首短诗,特别短。其次,这首诗不关注叙事而突出了一系列生动的意象——诗里没有故事,也没有“人物”——并且这些意象取自自然。在这些方面,《四月》与浅表观点中的俳句特点相吻合。更深刻更投入的读法则可以把该文本视为某种哲学声明来考察。在开头两行中,我们发现说话的自我或诗中的“我”实际上被文本撕裂且迅速被一个具体意象所取代:橄榄树枝。主体性——该文本暗示道——是栖居于外部事物而非人的身体或心灵中。是“树枝”赤裸躺卧在地,它替换了之前被撕裂的身体或意识。最后一行则通过与其他意象的重叠而强调了这一意象,树枝被转移为“光亮雾霭”下的“苍白尸体”。主体性回归了(与“树枝”的纯粹物性不同,“苍白尸体”这一意象暗示了情绪与感情),但此时是经由一个以并置方式运作的生动意象的中介。一半是取自自然的物质(“雾霭”),另一半则蕴含情绪(“苍白尸体”),诗句成功地将主体与客体融合起来。
基于这样的阅读,我们可以认为《四月》代表了一例英语俳句,因为它满足了我们赋予其他这一类型的诗歌的某些标准。我们又是怎样获得这些标准的呢?部分靠直觉。作为文学作品的读者,我们继承了关于用英文写成的俳句是何模样的普遍直感:它应该是短的,包含自然意象,并在表达上是含蓄的。更严密地说,我们用以判断一首诗是否是英语俳句的标准源自其他文学研究者的论著。例如,厄尔·迈纳(Earl Miner)提出英语俳句通常具有以下特征:对精简与准确的倚重、对常常将具体却不相称的意象并置的视觉语言的运用,以及由这些意象的运用产生的具有暗示性而非刻意或外显的意义。*参见Earl Miner, The Japanese Tradition in British and American Literature, Princeton, N. J., 1958, p.125; 下文简称JT.我们可以将这些特征视为英语俳句普遍遵循的一套规则。
运用这些标准,我们还可以开始通过判断诗歌甲或诗歌乙是否具备与《四月》相似的美学特征来辨别出这一时期的其他英语俳句。试思考威廉·卡洛斯·威廉斯的《婚姻》:
如此不同,这男人
和这女人:
田里流动的
一条小溪。*William Carlos William, “Marriage,” in The Collected Poems of William Carlos William, A. Walton Litz and Christopher MacGowan (eds), 2 vols. (New York, 1986-1988), 1:56.
直觉再一次暗示了这是一首受到俳句启发的诗。这首诗简短、基于意象,并以取自自然的事物结尾。更为重要的是,它也满足了迈纳提出的基本标准。在内容与排印两个方面看,它都聚焦于呈现而非再现,并且将男人、女人与自然景物相重叠,明显地使用了并置法。然而,将它与《四月》对比时又出现一些区别。诗中确实有并置(或叠加)发生,但这一技巧却没有那般牢固地基于意象。诗歌虽然也有从主体性的到客体性的转换和二者最终的相互融合,却不似前诗那般专注于将这一现象凝结为视觉观感。学术界也肯定了以上粗略的比较。查尔斯·阿尔提艾瑞(Charles Altieri)写道,“总体而言,威廉斯拒绝庞德那种关于形式的抽象话语,并强调对地点与寻常话语的敏感性就已足够使事实更加生动。”*Charles Aliteri, The Art of Twentieth-Century American Poetry: Modernism and After, Malden Mass., 2006, p.41.如此一来,要把两首诗都辨识为俳句,我们必须进行妥协,承认二者虽都体现了俳句的风格影响,但个体诗人的性情和身处环境各自不同。事实上,这正是当我们试图分析某一文体跨作家和跨语境的丰产性和流变过程时,文本细读常常使我们处于的分析立场:探查不同艺术家如何不同程度地加入了这一文体。正如此处所演示的,这些分析步骤的实施预设了英语俳句具有某种理想模式,将某首诗与它进行比对即可根据其近似或偏离的程度来评估该诗的“俳句性”。
这些分析步骤在现代主义诗歌研究中无疑是很常见的。阿尔提艾瑞、玛乔瑞·帕洛夫(Marjorie Perloff) 与海伦·文德勒(Helen Vendler)等重要学者在描述某文体与某一特定诗人或诗人圈的关联时,常常运用与形式有关的语言。例如,阿尔提艾瑞认为意象主义诗人追求一种关于“感知”的“与众不同的形式”*Charles Aliteri, The Art of Twentieth-Century American Poetry: Modernism and After, Malden Mass., 2006, p.23.,而文德勒则肯定了一种华莱士·史蒂文斯形式的存在,它运作起来就像“一种代数式的陈述,每个读者都能用自己的价值来取代其中的x或y”*Helen Vendler, Wallace Stevens: Words chosen out of Desire, Knoxville, Tenn., 1984, p. 8.。这类批评思路试图辨明现代主义诗人是如何将语言的整个范畴改造成某种文体或写作形式——帕洛夫称之为诗歌的“模式”(pattern),在她的理解中它与语义和印刷版式均有关。*参见Marjorie Perloff, The Dance of the Interllect: Studies in the Poetry of the Pound Tradition, Evanston, Ill., 1996.
然而,在其他案例中,现代主义学者们运用对比性的文本细读来达成相反的目标。他们倾向于关注各文本“活生生的独一性”而非它们共享的对某一“形式”或“模式”的继承。*Peter Nicholls, “The Poetics of Modernism,” in The Cambridge Companion to Modernist Poetry, Alex Davis and Lee M. Jenkins (eds.), New York, 2007, p. 61.在这些例子中,学者们会关注一首诗通过它被写就以及它通过语言获得形式的过程所获得的意义的深浅。意义产生于物质性的语言和文本自身的显现。不但诗歌表达的力量来自于它自身的语言,而且诗歌阅读也关乎将诗歌本身视为一起正在发展的事件。这些观点被处于庞德、威廉斯与史蒂文斯等作家的经典阐释领域中的权威学者们着重肯定。例如,彼得·尼科尔(Peter Nicoll)认为每个现代主义文本都揭示了“某一语言的纹理内的一个崭新和‘别样的现实’”,并“创建了它自己的世界”*Peter Nicholls, “The Poetics of Modernism,” in The Cambridge Companion to Modernist Poetry, Alex Davis and Lee M. Jenkins (eds.), New York, 2007,p.6,p.61.。在这些描述中,一首诗就是一个表达之独一性的例子;它只属于其被创造出来的那种语言。潜藏在此处的是这样一种信仰,即每一个文本,它作为在读者眼前展开的一个语言世界,只能是且只将其自身呈现为某一独特类别的诗歌。
如果放在一起考察,这两种文本细读的阐释倾向留给我们一种多少有些油滑的现代主义文本本体观。一方面,文本被视为不同程度地隶属于更普遍的文学风格形式,如“史蒂文斯形式”。另一方面,文本又作为一个“活生生的独一性”而存在,或是作为一个自我建构的现实,其美学价值取决于它对一切成规的背离。在现代主义诗歌研究中,第二种观点往往获得胜利。对个体文本进行精深细读并说明它们的独特性质在这些研究中成为主流,而将诗歌根据普遍化的风格形式或模式来分类则受到较少关注。这自然与相关领域盛行的某些批评倾向有关,不过,我们也可以将之部分归因于文本细读这一方法自身的限制。根据一个共享的风格模式来不断筛选诗歌的计划在数十篇诗歌的层面似乎还可行,但到数百篇的层面该怎么办呢?如果人们偏向于认为每个阅读行动本质都是主观的,且文本的风格也取决于仅对那一特定例子适用的一干因素,那么将文本细读当作一种模式辨认的方式就变得十分难以操作了。详述某文本的独特方面或描述它如何偏离了预设的规范模型会比试图界定该模型更有回报。如果某一形式在每次阅读新文本时都需要进行更改或调整,要设想它有任何可确证的一致性就变得更困难了,因此放弃形式或仅仅将之假定为一个模糊的概念会更容易些。
我们本来或可接受这种不稳定的文学模式概念,然而英语俳句却给我们呈现了一个特殊的例子。作为文本细读的对象,英语俳句往往在学术批评中同时横跨两个方面。也就是说,它被一些人理解为遵循一个明显可辨的模式,又被另一些人解读为一个极度开放且模糊的美学形式。例如,杰弗瑞·约翰逊(Jeffrey Johnson)坚持认为存在一个明确的“俳句形式”,并同迈纳一样勾勒出一套规则来描述这一形式的特征。这些规则包括“以名词为主宰的诗句”和“无评论的意象”等例,而一首英语俳句中总会呈现这些规则的某些组合。*Jeffrey Johnson, Haiku Poetics in Twentieth Century Avant-Garde Poetry, Lanham, Md., 2011, p. 69,p.68.但另一些学者却认为这些规则达成的是一个宽松得多的对形式与风格的限定,甚至只是一个模糊的美学倾向。例如,当文德勒提出“史蒂文斯形式”时,她所想的是这些诗歌共有的一种普遍特质或感觉,而不是一个形式准则清单。*Vendler, Wallace Stevens, p. 57.英语俳句既像“五七五”格律一般易于辨认,又变幻不定得只是一种共有的感觉。
这种双面特征在劳拉·赖丁(Laura Riding)和罗伯特·格雷夫斯(Robert Graves)的经典专著《现代主义诗歌考察》(ASurveyofModernistPoetry, 1927)中被很好地体现出来。在两位作者为创造性活动的自足性辩护时,用俳句作为反面例子来表达这种自足性。在他们看来,俳句在现代主义诗歌中到处泛滥寄生,已成为一种模仿性的、更像社会建制而非个体行动的诗歌范例。身为杰出的文本细读读者,两位作者用几例代表性诗歌就诊断出问题所在(见图1),并进而“绘制一幅文学图示”来追索英语俳句的起源和出问题之处:*Laura Riding and Robert Graves, A Survey of Modernist Poetry (London, 1927), p. 216,p. 217,p.218.
是谁发明了前两首诗的文体,奥尔丁顿先生(Mr.Aldington)还是威廉斯先生?抑或H. D.或弗林特(F. S. Flint)?……在后两首诗中谁为其形式负责?是谁首先想到模仿日本俳句的形式?或者应该说是谁首先想到模仿法国人对俳句形式的模仿?是奥尔丁顿先生向史蒂文斯先生或庞德先生建议了短一些的诗歌,或是庞德先生向奥尔丁顿先生建议了长些的诗歌等等,或者是庞德先生、史蒂文斯先生和奥尔丁顿先生、威廉斯先生两队伙伴决定作为一个学派团队共同工作;又或者是威廉斯先生、史蒂文斯先生和奥尔丁顿先生、庞德先生两相结合,鉴于从国别上这样配对更合适?*Laura Riding and Robert Graves, A Survey of Modernist Poetry (London, 1927), p. 217.

图1 以上赖丁和格雷夫斯引用的四首诗表现了俳句的寄生特性。这几首诗也是引文中所指的诗
然而,在尝试将俳句形式的兴起和传播独立出来的问题上,赖丁和格雷夫斯就走到这儿。剩下的只能留待猜测。他们面对的僵局正是一个偏向于将诗歌视为自我实现的活生生的独一体的研究手法所面临的僵局。他们将俳句视为典型性的文学模式,认为俳句激起了一种共有的感觉,它又形成了一种更广泛的、被过度复制的风格。但是谁首先开始的?谁是传播它的罪魁祸首?这些诗歌是如何相像的?坚决忠于一种阅读模型和一种对诗文的看法,赖丁和格雷夫斯只能戏拟出一串文学批评问题,既不相信也不愿意找到令人信服的答案。对他们来说,英语俳句既是一种传统文学模式的典型,同时又是一种他们乐于仅仅通过指认就分辨出来的东西。
作为社会历史事件的英语俳句
一种在更大数量的诗歌之中发现文体模式的办法是选择一种不同的英语俳句文本本体观。这里我们可以求助于新现代主义研究(New Modernist Studies)。它以新历史主义为指导,为现代主义学者拓展了研究手法与材料。丽贝卡·沃克维奇(Rebecca Walkowitz)与道格拉斯·毛(Douglas Mao)提出,现代主义研究的对象一度只狭隘地聚焦于一小众经典的、精英的、大半为英语的文本,但现在正朝着新的“时间、空间和深度方向”发展。*Douglas Mao and Rebecca L. Walkowitz, “The New Modernist Studies,” PMLA 123 (May 2008), p.737.这意味着现代主义的时间范畴在向前向后都有扩展;其空间范畴含括了表面上与英美地理中心相距遥远的地方;其文化范畴也伸向了小圈子精英创作之外的各种文本和体制环境。伴随这些扩展而来的是对现代主义文本的看法变化:它是体制与媒体环境的产物,并同样根植于历史话语体系。*如参见Lawrence Rainey, Institutions of Modernism: Literary Elites and Public Culture, New Haven, Conn., 1999, 以及Andrew Goldstone, Fictions of Autonomy: Modernism from Wilde to de Man, New York, 2013.关于体制环境,还可参见Mark Wollaeger, Modernism, Media, and Propaganda: British Narrative from 1900 to 1945, Princeton, N.J., 2008和Mark Goble, Beautiful Circuits: Modernism and the Mediated Life, New York, 2010中关于现代主义与现代媒体形式的关系。这些看法改变了我们阅读文本的方式,并将文本视为更广阔的美学与社会学模式的一部分。
根据这种看法,英语俳句开始看起来不那么像一个自足独立的诗歌艺术品,而更像美国作家们借鉴外国诗歌体裁的集体尝试。这里,俳句成了流行体裁和历史事件——一个陷在特定社会物质流通模式中的美学关注对象。很大一部分在现代主义和东方主义名义下的研究(如克里斯托弗·布什、罗伯特·科恩、埃里克·海奥、史蒂文·姚*上述学者英文名分别为Christopher Bush, Robert Kern, Eric Hayot, Steven Yao.——译者注和钱兆明等学者的研究)已经提供了一个以浓厚历史主义为支持的框架,意在将亚洲美学文本在英语中的出现理解为20世纪早中期西方艺术家对东亚文化广泛痴迷的一部分。*参见Christopher Bush, “Modernism, Orientalism, and East Asia,” in A Handbook of Modernism Studies, ed. Jean-Michel Rabaté, Malden, Mass., 2013, pp.193-208; Robert Kern, Orientalism, Modernism, and the American Poem, New York, 1996; Eric Hayot, Chinese Dreams: Pound, Brecht, Tel Quel, Ann Arbor, Mich., 2004; Steven G. Yao, Translation and the Languages of Modernism: Gender, Politics, Language, New York, 2002; and Zhaoming Qian, Orientalism and Modernism: The Legacy of China in Pound and Williams, Durham, N.C.,1995.这种痴迷已经超出了纯粹的美学兴趣;受更大政治力量影响的异域情调和帝国主义等话题激起了西方世界对中国和日本艺术的兴趣。科恩就这一课题提出了精辟的总结:“我们面临的问题可被称为‘囚禁于西方的中国诗歌’,以及翻译实践自身被某些具有优先权的事物征用与引导的程度,这些事物试图扰乱并改变中国诗歌接触西方读者的本来过程。”*Kern, Orientalism, Modernism, and the American Poem, p.175.
在新的现代主义框架内,关注焦点由之转向决定俳句如何接触到英语读者的历史要素,以及这些要素对俳句接受的影响。整个过程可分为三个阶段来描述。第一阶段称为发现阶段,开始于20世纪初并主要由收集行动或样本采集行动所决定。这时的目标是为了在东方文学的陈列柜里再添珍品。当时,随着日本在地理政治舞台的出场增多,东方文学的陈列品也在扩大。威廉·乔治·阿斯顿(William George Aston)和巴兹尔·霍尔·张伯伦(Basil Hall Chamberlain)两位日本研究学者在20世纪初搜集了部分最早的俳句学术翻译。*当时更常用“hokku”和“haikai”两词来指称这一文体。两个词虽然与“haiku”同义,但严格说来它们仍有区别。“Hokku”指具有五七五音节的开放序列,在历史上它是长得多的系列相连诗歌。“Haikai”则专指这种相连诗歌的特定传统,它可以追溯到17世纪早期。“Haiku”则是诗人正冈子规在19世纪90年代新造的词,用以将这些诗歌分离出来作为各自独立的诗歌单元。他们还提出了一些关于俳句音节结构和文学谱系的最早的形式描述。然而,在努力把俳句介绍给英语读者时,两位学者倾向于以典型东方主义话语的方式来对待俳句——把它作为异域的新奇事物和国家民族特点的标志。如此一来,这许多“极小的情感迸发”*W. G. Aston, A History of Japanese Literature, New York, 1899, p. 294.和“微观创作”*Basil Hall Chamberlain, “Bash and the Japanese Poetical Epigram,” in Transactions of the Asiatic Society of Japan 30, no. 2 (1902), p.243.——他们这样称呼俳句——就被归统于类型学的描述,以便理解这一文类何以如此奇怪和特别。例如,阿斯顿就认为他们珍藏的是“微小却珍贵的真实情感与美丽幻想之珠”,它“最突出的品质就是暗示性”*Aston, A History of Japanese Literature, p. 294.。与此相似,张伯伦也把俳句形容为“最微小的文本”,它在最好的情况下是“一个为自然中的小事和日常生活的偶然事件而开启的孔洞”*Chamberlain, “Bash and the Japanese Poetical Epigram,” p. 245、p. 305.。拉芙卡迪奥·赫恩(Lafcadio Hearn)则以更流行的方法对待该形式,声称“短诗的创作者努力通过运用一些精选的词汇……来激发某个意象或某种情绪,”其造诣深浅“完全取决于暗示的能力”*Lafcadio Hearn, In Ghostly Japan, Boston, 1899, p.154.。
这批珍奇搜寻者虽急于搜集归档这一异国文学品种,最终却对培养本土特点没什么兴趣。不过他们对俳句翻译的选择——以及这些译作日后的流行——可以说为一套美学考虑要素和“精选词汇”提供了示例,这些都在下一阶段的俳句接受中继续表达出来。*例如,有些人运用俳句译作的语言(尤其是像庙钟、小花、盘旋的昆虫等短语)来描述俳句带给读者的理想效果;参见同上,以及Chamberlain, “Bash and the Japanese Poetical Epigram,” p. 309. 与之类似,保罗-路易·库苏1906年在一篇有影响的文章中写道,一首俳句的意义“像屏风背后的竖琴之声或穿过雾霭而来的梨花香气那样”向我们飘来。(Paul-Louis Couchoud, “The Lyric Epigrams of Japan,” in Japanese Impressions: With a Note on Confucius, Frances Rumsey (trans), London,1921, p.38.我们称这下一阶段为试验阶段,此时诗人们变得更愿意激活运用起上一代人积累下来的范例。这是现代主义学者们最为关注的阶段,他们往往将其发源追溯到1913年前后一个文学家们组成的小圈子。不过谁和谁说话、在什么时候这样的细节则较为模糊不清。实际上,把这一阶段界定为一个高度活跃于早期接受者和“本土”信息提供者中的“议论”阶段或许最为合适。参与其中的主要是英美两国的与意象主义运动有关的诗人,他们在俳句中发现了各种美学创新的可能性。正如其中一位诗人弗林特于1915年提到的,意象主义运动的起源可追溯到一批伦敦艺术家,他们对英语诗歌不满,并“在不同时刻提倡用纯粹的自由体诗(vers libre)来替换它,用日本的短歌(tanka)和俳谐(haikai);我们都写了数十首日本俳谐以资娱乐”*F. S. Flint, “The History of Imagism,” in The Egoist 2 (May 1915), p. 71. 诗人把短歌和俳谐与自由体诗联系在一起,体现出他并不知晓这些形式的音节结构在创作实践中有多么严苛。这也暗示了模糊二者区别的广泛倾向,我们会在下个部分中考察这一论点。。某些人视为娱乐的东西对另一些人则是严肃的事,俳句在先锋杂志与意象主义文选中激起了一阵改编为英语语言的热潮。这些现象自然产生了一套关于什么使俳句如此与众不同的新依据。
庞德与伦敦团体意趣相投,他于1912年开始尝试这一文体,并在1914年的论文《旋涡主义》中达到顶峰。他在该文中强调了日本诗歌的简洁、意象和叠加(“一个想法在另一想法之上”),认为这些特征是造出他的名诗《在地铁站》(1913)那样的“形似俳句的句子”的根本。同年庞德协助结集了第一部意象主义文选,其中奥尔丁顿(Richard Aldington)、洛威尔(Amy Lowell)和之后的弗莱彻(Fletcher)都尝试了受発句(hokku)启发的诗歌。*一位批评家甚至声称“日本発句诗歌无疑就是组成首部意象主义文选的参照模本,尤其是其中庞德先生的贡献”。(George Lane, “Some Imagist Poets,” in The Little Review 2, May, 1915, p. 27)值得注意的是,洛威尔和弗莱彻欣赏俳句的原因与第一阶段批评家指出的某些俳句特征相吻合,即它的简洁性、暗示性,以及情感与自然世界的明确连接。*洛威尔力图在她的改编诗歌中“保持発句的简洁与暗示,并将它维持在自然的空间中”(引自JT, p. 165)。弗莱彻欣赏俳句对“源自自然事物的普世情感”的运用,以及它“用最少的词语”来表达这种情感”(引自JT, p. 177)。事实上,暗示性已成为批评话语中的支柱,以至于到了1913年,日本诗人野口米次郎(Yone Noguchi)(他也是所有这些议论的关键贡献者)宣称:“没有哪一个词像暗示性那样被西方批评者们这样泛滥地使用,它造成的损害大于启迪。”*Yone Noguchi, “What is a Hokku Poem?” in Rhythm 2, Jan.1913, p. 355.然而野口在把“内在广阔而外在模糊”的俳句语言比作“沾满夏日露水的蛛丝,像空气中的隐形幽灵一般在树枝间摇摆,保持着完美平衡”*Noguchi, The Spirit of Japanese Poetry, London, 1914, pp. 42-43、p. 51. 关于野口对庞德等早期接受者的影响,参见Edward Marx, “A Slightly Open Door: Yone Noguchi and the Invention of English Haiku,” in Genre 39 (Fall 2006), pp. 107-26.时,同样渲染了这一批评话语中的东方主义意味。
虽然表面上对俳句的新颖之处已有共识,但学者们也展示了庞德、威廉斯、野口以及其他诗人在俳句的运用上如何各具不同。不过正如上文指出的,这些学者同样坚持认为俳句有一套吸引诗人们的共同特征:“[俳句的]短小与简练:它的直接性,它的呈现模式,它的暗示,以及它对并置的具体细节的运用。”*Johnson, Haiku Poetics in Twentieth Century Avant-Garde Poetry, p. 45.正是这些前后衔接的观点推动俳句进入了第三个接受的阶段:模仿的狂潮绕之兴起,超出了原先意象主义诗人及其友人的小圈子。这一最为平民化的阶段可由改编诗作的数量上升、俳句在诗歌领域的更广泛分布和当时的批评评论所印证。实际上,这后一点暗示了俳句到1920年已达到了一个饱和点。此时俳句无处不在。在某些人看来,这一现象值得庆祝,因为它显示了东西方艺术“出人意料的紧密修好”,以及日本诗歌和美国诗歌前所未有的根本性融合。*Royall Snow, “Marriage with the East,” in The New Republic, 29 (June 1921), p.138. 另参阅Torao Taketomo, “American Imitations of Japanese Poetry,” in The Nation, 17 Jan. 1920, p. 70.但在其他人看来,现在有理由对这场狂热叫停了。一位研究洛威尔和其他“用英语写発句(hokku)”的诗人的评论家把俳句贬斥为一个“远远被高估的形式,它只适合于传达情感的最微小面相”*Marjorie Allen Seiffert, “The Floating World,” review of Pictures of the Floating World by Amy Lowell, in Poetry 15 (Mar. 1920), p. 334.。哈佛的一位学者虽承认発句的“灵敏和精确”是“诗歌珍贵价值的重要部分”,但也将它视为诗歌形式由长到短的普遍消极转向的症候。“人们对某些人称为‘水洼中的星星的迷你素描’会很快感到厌倦。”*John Livingston Lowes, Convention and Revolt in Poetry, Boston, 1919, p. 166、p. 309.中西部讽刺杂志《塞壬》则更不友善地戏仿起発句与高眉艺术的关联,并以如下“五七五”形式的嘲讽副歌结尾:“你觉得発句这玩意儿里有什么名堂吗?/我也觉不出来。”*“Hoch der Hokku!” in Siren (Sept.1921), p. 10.英语俳句终于真正到来了。
随着英语俳句的到来而出现的大批改编诗作,对我们来说比意象主义者的诗歌要更陌生。据迈纳的说法,这些诗作给读者呈现了一个“由混杂的形式、无意义的技巧模仿和异域风情组成的杂乱丛林”(JT, p. 184)。不过,不论在个体诗歌层面扩散得多广,在将俳句当作批评话语的研究对象方面则一直保持着令人吃惊的连贯性。日本批评家武友寅夫(Taketomo Torao)声称“発句的诗学优点……完全取决于暗示性的力量”,并认为美国的俳句诗人“倾向于使用最少的词,偏好运用意象与象征而非解释来展示事物的本来面目”*Taketomo, “American Imitations of Japanese Poetry,” p. 71.。罗亚尔·斯诺(Royall Snow)在为《新共和》撰文时则更进一步声称俳句让“西方人的心灵”如此着迷的原因,在于“它能够在有限空间内创造出来的效果”。他指出“亚洲诗歌”两个最主要且有影响力的特征是“集中,还有和它的客观性神秘相连的暗示性特征”;斯诺只需援引意象主义者们自己的宣告,即可认定这些特征与俳句具有如此根本的他异性和如此明确的东方感的原因是何等紧密相关。*Snow, “Marriage with the East,” p.138. 斯诺援引了庞德914年的一篇文章,其中写道,“我们在接下来的世纪里躲不开……东方思想的强烈敏锐感和凝练的东方文学形式给我们的既定标准造成的越来越大的改变。”艾米·洛威尔也被提及,特别是她这句“暗示是我们从东方学到的重要的东西之一”(p. 138)。正是这类关于俳句美学影响的概括性说法决定了俳句接受第三阶段的批评话语。*杰伊·哈贝尔和约翰·比蒂将俳句视为“亚洲诗歌对当代诗歌产生的巨大且还在日益增大的影响”的一部分,“[这一影响]带来了更大的简洁性和润色度”(Jay Hubbell and John O. Beaty, An Introduction to Poetry, New York,1922, p. 360).然而,伴随这些说法而来的是一个客体化模式,它像前期阶段一样,忽略俳句的具体细节而去关注一套与明显东方主义话语相结合的模糊的美学理想。这一模式在一篇关于野口诗歌的评论文章中被最为简明地体现出来,该文评论道:“这首诗以発句形式写成,三行诗里包含十七个音节。但形式并不构成発句。一些最优秀的発句并不以该形式写成。那种决定発句本质的、精细而梦幻般的情感足以启示宇宙的无限,它藏在哪儿呢?”*Jun Fujita, “A Japanese Cosmopolite,” review of Seen and Unseen: Or Monologues of a Hmeless Snail and Selected Poems of Yone Noguchi by Noguchi, Poetry 20, June 1922, p. 164.
在把俳句文本视为社会历史事物来研究时,我们发现一般体认的俳句本质特点——简短、暗示性和自然意象——不断被众多评论者积极肯定。现在,我们可以把这些特点视为观察判断的历史积累的一部分。不过我们也可以将其视为一套更广阔的、如今被简单称为东方主义的政治文化形态的一部分。如果说有关俳句的话语和创作尝试在其第三阶段在美国社会中逐渐形成了一个广为流行的模式,那么应该说这一模式是源自美国在众多领域对东亚进行异域化处理这一更大的模式中。最后,此处的简史还揭示出一些对俳句的流行与繁盛十分关键的重要的社会偶然性。弗林特需与庞德交流,庞德又需与野口交流才使得他对俳句产生兴趣,接着庞德又使其他人也产生了兴趣。与货币类似,俳句在诗人、编辑和读者组成的社会物质网络中流通,而其中的许多人对俳句价值何在的问题抱着同一套优先考虑因素和同样的认识。这些力量——既有美国东方主义又有艺术网络——结合起来,将俳句文本的现实标记为一个社会历史事件,它反映并也激活了艺术家群体中更广阔的文化话语与社会行为模式。
不过,我们在试图辨明这些模式时又留下了一些新的问题。尤其是:这些模式与它们表面上帮助生成的“混杂形式的丛林”有什么样的关系?如果将俳句文本视为更广阔的社会活动的一部分,那么在文本自身的层面又发生了什么?这些俳句文本经过从外国译作到先锋试验作品到亲民流行形式的转变,它们是否体现出相似性?这里历史文化的研究方法就没有多少用处了,因为它只能说明我们之所以能提出这些问题的背景。而文本细读,就其独重个体文本的“活生生的独一性”而言,也无法满足需求。我们希望找到一种比文化历史批评更精细、但又开阔到能考虑一个比文本细读所提供的文本模式定义更宽松的阅读模型——一个不把文本当作个体美学效应的纽带或者社会话语的产物,而是将其视为上百个例子共同分享的一套种属特征。我们需要一个新的关于英语俳句的本体观,以帮助我们将俳句视为大于某种意象类型和含蓄语言的编排、又小于松散连系在东方主义概念中的杂乱模仿性形式的东西。简洁与暗示性或许是比严格的形式模仿更微妙、同时又比印象主义的美学直觉更具体的文本模式带来的效果。
作为统计模式的英语俳句
自上世纪90年代初,机器学习以及它在文本自动分类中的应用成为发现大量文本中的模式的一个流行方法。机器学习是指一套完整的统计算法,它们把每个文本视为一个特定的可量化特征的混合体,并认为这些特征跨文本分布的方式有助于识别文本之间的差异。这些统计算法试图“学习”这些特征,以便就某文本可能所属的类别或组群进行分类或预测。举例说明,这样的算法可以根据它们学到的与每个类型的信息相关联的特征,来帮助决定一封电子邮件是否有可能是垃圾邮件。*这种筛选是机器学习自上世纪90年代初崛起后最常见的用途之一。它比旧的文本分类方法更为有效和高效,因为旧的分类方法要依靠人类专家以人力来设定与他们分析的任何文本都密切联系的分类规则。随着机器学习的发展,专家们可以放手让机器来推导出规则,他们则把关注点集中在识别类别本身。法布瑞尔·塞巴斯蒂阿尼(Fabrizio Sebastiani)在《文本自动分类中的机器学习》一文里全面介绍了信息系统领域内机器学习的历史。见“Machine Learning in Automated Text Categorization,”in ACM Computing Surveys 34 (Mar. 2002), pp.1-47.在文学研究中,使用机器学习来完成类似的对文学或其他美学文本的信息筛选已有十年的历史。学者们试图用这种方法在戏剧叙事结构、政治隐喻、剧场对话以及小说体裁中识别诸如词汇的、语义的或其他文本差异上的模式。*参见Stephen Ramsay, “In Praise of Pattern,”in TEXT Technology 14, No. 2 (2005), pp. 177-90; Bradley Pasanek and D. Sculley, “Meaning and Mining:The Impact of Implicit Assumptions in Data Mining for the Humanities,” in Literary and Linguistic Computing 23 (Dec.2008),pp.409-24;Shlomo Argamon et al., “Gender, Race, and Nationality in Black Drama, 1950-2006: Mining Differences in Language Use in Authors and Their Characters,” in Digital Humanities Quarterly 3,No. 2 (2009); Matthew Jockers, Macroanalysis:Digital Methods and Literary History, Urbana, Ill., 2013, chap.6.近来,机器学习已经在高度复杂的分类任务,如小说体裁检测和人物类型识别中发挥了不可或缺的作用。*Ted Underwood, et al., “Mapping Mutable Genres in Structurally Complex Volumes,”该文是2013年“IEEE大数据国际会议”发言论文(未发表)Santa Clara, Calif., 6-9 Oct. 2013; David Bamman, Underwood &Noah Smith, “A Bayesian Mixed Effects Model of Literary Character,”该文是第52届计算机语言学年会提交论文,Baltimore, 22-27 June 2014,
机器学习作为一种方法由四项关键任务构成,每项任务都促使俳句以迥异于其他阅读方式的文本对象而存在。这些任务是分类(categorization)、表示(representation)、学习(learning)和归类(classification)。“分类”指按照文本所归属的系列类别或纲目来给它们分配标签。“表示”指分离出文本的各具体特征,并采取机器学习算法可以解释的方式来量化这些特征。紧随其后的是“学习”,此处机器需要把关联着每个文本的各种特征提取出来,并评估它们使该文本属于它被分配的类别的区分程度。最后一步是“归类”的任务,即运用学习阶段获得的信息,仅依靠某一文本的特征(也就是说,标签是未知的)来预测它的类别。接下来,我们将循序经历这些任务,并突出每一个阶段中的阐释决策以及这些决策是如何最终塑造了过程中出现的俳句文本本体观。
“分类”是根据不同的类别来为文本设定标签的看似简单的行为。这些类别在最常见的情况下都是二元制的(如垃圾邮件和非垃圾邮件),但也可以是多元的。*对多类型文本分类的解释与示范,参见Jockers, Macroanalysis, chap. 6.更重要的是,类别“不能被确凿无疑地决定”, 它们取决于“专家的主观判断”,是专家在阅读一批文献后根据他/她所感兴趣的特质而进行的分类。*Sebastiani, “Machine Learning in Automated Text Categorization,” p. 3.这就叫机器学习的“监督学习方法”*与之相对,“无监督方法”允许机器首先根据某些特定的特点决定文件可以如何聚集;这些聚类是否能与有意义的类型相对应则留待使用者决定。对此较有帮助的解释见Jockers, Macroanalysis, pp.70-71.。这一步虽然听起来简单,但它从根本上决定了分析的结果,并且要求一套内在不同的文本需要在表面上被归档到有限数量的类别中去。对我们来说,这意味着要找到一大批符合20世纪初对英语俳句的期待的诗歌,以及一大批不符合期待的诗歌。在分别标记它们为“俳句”和“非俳句”后,我们就可以将两类文本进行对照划分。不过,这并不是要强化我们最初所做的区分,而是要检验它的界限,并确定什么样的文本模式才是每一组文本所特有的。也就是说,我们想要知道机器能否识别出俳句和非俳句文本,如果可以识别,它又是用什么样的统计证据来得出结论的。
为了确定我们的两个语料库,我们首先使用原始档案和次级资源来寻找符合以下基本条件的俳句诗歌:它们必须是来自发现阶段的重要学术文献中的译作;或者在标题中指认自身为俳句;又或者是由诗人或评论家明确认定受到日本短诗形式的影响。这样就产生了一个包含400个文本的语料库;我们又将其分为两个类别,即翻译作品和改编作品。翻译作品代表了最初被英美读者所接受的、更紧密地遵循“五七五”格律这样严格形式限制的经典俳句。改编作品则代表了一组更为多样化的诗歌,它们虽偏离了这一形式惯例,但至少诗人和批评家们认为它们在内容或审美意向的层面仍遵从俳句。这其中包括了对日本短歌(tanka)的明确改编作品——短歌是一个由31个音节组成的形式,批评家经常把它与俳句放在一起,作为日本短诗这一更普遍的类型的一部分(见图2)。*在日本,俳句和短歌天然与截然不同的审美取向、艺术谱系以及风格和社会标记相连。传统上俳句专门描述自然世界或给出哲学与社会方面的评论;短歌则与情绪和感情表达相关。不过这些精细的区别通常被美国的诗人和评论家忽视,结果二者往往被混在一起,都作为一个单一的日本诗歌传统的一部分。图示中上世纪头十年末期和20年代早期出现的高峰段包括了洛威尔、弗莱彻、野口等人受俳句启发而创作的大批诗歌,以及一批与意象派无关的大小诗人的翻译和改编作品。
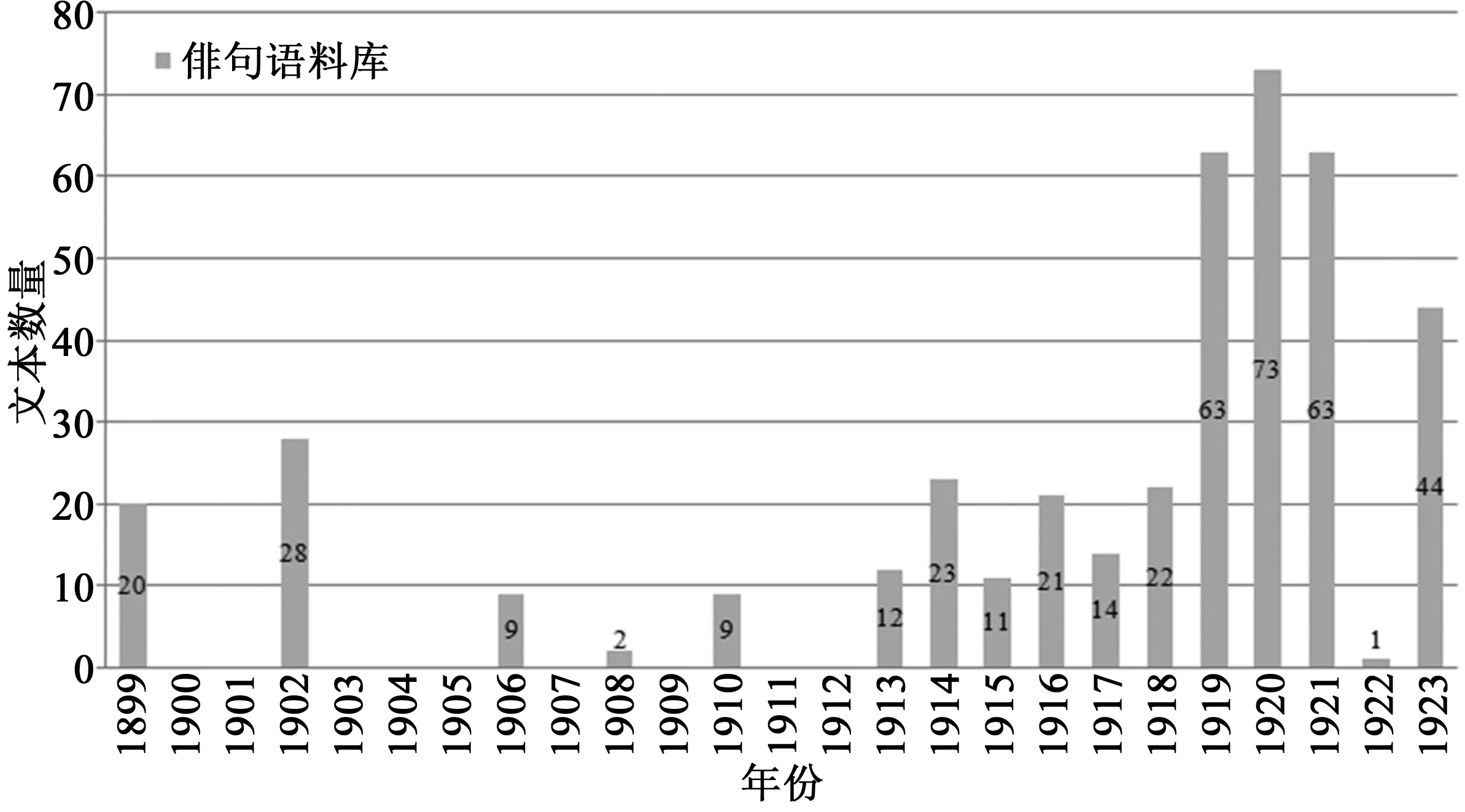
图2 所选俳句文本随时间的分布图
为了搜集一个非俳句语料库,我们需要找到一大批不属于英语俳句运动、却又有可能从中发现该运动痕迹的诗歌。因此,我们在俳句接受第二阶段和第三阶段的诗集和其他重要杂志中收集了1900多首短诗;这些杂志包括诸如《诗歌杂志》、《小评论》和《他者们》之类的小杂志,诸如《哈泼斯杂志》、《Scribner出版社杂志》和《国家》这样的综合刊物,包括《危机报》和《机遇报》在内的哈莱姆文艺复兴的关键期刊,以及像俄亥俄州的《中部地区》和加利福尼亚的《抒情西部》这样的地区杂志(见图3)。*这些诗歌是从哈蒂信托基金数字图书馆(Hathi Trust Digital Library)和现代期刊项目中收集来的。由于这些资料集仅限于公共领域的作品,我们只能收集在时间限制上早于1923发表的诗歌。对于哈莱姆文艺复兴的期刊,我们是根据原版的内容手动输入诗歌。这里的“短”是指长度低于300个单词的任何文字,略高于我们语料库中俳句的平均长度。我们要尝试对照着这些属于其他文本类别的诗歌来分析两组俳句之间的界限。

图3 从当代杂志汇编的短诗语料库列表。这些短诗来自大约11,000首在给定的日期中从表中出处发表的诗
接下来,我们必须确定这些文本的“表示”(representation),以便它们可以被归类算法读取和解释。在这一步骤中,文本的本体观真正变为机器自身所有。由于归类依赖于文本的统一索引,所以这些文本必须被看作某(几)种较小单元(单词、短语、话语片段)的集合体。文本一旦被选中,便被分解成这些单元的简单列表,以显示单元的存在与否或相对频率(即某一单元在文本中是否出现或出现的次数)。每个单元都被看作是其所在文本的一个“特征”(feature)——一种辨识特点——而该文本则成为这些特点的向量(vector)。但是机器“表示”往往不考虑这些个体单元的结合规律,这也佐证了贾斯丁·格里默尔(Justin Grimmer)和布兰登·斯图尔特(Brandon steward)的观察:“自动化的内容分析方法使用有见地的,但却是错误的……文本模型,来帮助研究者从他们的数据中做推论”*Justin Grimmer and Brandon Stewart, “Text as Data: The Promise and Pitfalls of Automated Content Analysis Methods for Political Texts,” in Political Analysis 21 (Summer 2013), p. 270.。“错误”是因为它们没有抓住文本如何通过语言而产生的复杂过程,但“有见地”是因为这些“不正确”的模型可以在大量丰富的数据库之间探测出文本单元的模式。
机器学习中一个最常见、也最简单的表示法就是“词包”(bag-of-words)模型,它将文本视为包含于其内的单词的集合。我们就以这一模型入手。上图显示了单独一首俳句被转化成词包表示时的样子(见图4)。当然,这一“表示”还可以进一步细化,这取决于我们决定由什么来构成一个有意义的区分特征。结果表明并不是每一个词对检测我们所感兴趣的语义模式都是有用的。由此,我们删除了譬如语法功能词(或停顿词),因为这些词不适用于区分内容层面上的模式。我们也没有记录诗歌中单词的出现频率,因为这对于小词汇量的语料库来说效果不大。*在一个二元制词包方法中,单词由它的存在或缺席来表示;关于它的优点,参见Pasanek and Sculley, “Meaning and Mining,” p. 413; 以及Bei Yu, “An Evaluation of Text Classification Methods for Literary Study,” in Literary and Linguistic Computing 23 (Sept. 2008), pp. 329-30. 二人都探讨了何时应该包括功能词的问题。功能词可能有助于识别作者风格。另见Jockers, Macroanalysis, p. 64. 我们也没有考虑字母大写,并且去除了所有标点符号,仅保留俳句文本中经常出现的感叹号和长破折号。此外,我们把所有的名词按屈折变化进行合并,像“群山”和“山”这样的词被看作是同一个单元,又排除了在受分析文本中只出现一次的单词。*后一种任务通常被称为特征选择(feature selection),它有助于减少由大量的低频特征产生的统计噪音。我们还可以略去在两种文本类别中都多次出现的词,这样也可以减少其他方向上的特征。最后,除词汇层面的特征外,我们还可以把更复杂的形式特征囊括进表示中,简单记录这些特征在文本中存在还是不存在。考虑到在俳句早期接受中音节数对认知俳句的重要性,我们把音节数这个特征也包括了进去。*诗歌的音节数取自用户输入并参照卡耐基梅隆大学(CMU)美式英语发音词典。随后,我们查看了翻译和改编两种俳句语料库音节数的分布,并使用该结果来创建截点。这样在翻译作品中我们使用18个音节作为阈值,每个文本被表示为或多于或少于这个数量。得出的结果是出现在图4底部的文字:一个被标记的特征向量,现在它就是所有文本的模板。现在,我们作出的关于如何“表示”这两类诗的选择使我们能够去测试这样一个假设,即俳句可以通过共有的措词和音节数模式来区别于非俳句。

图4 单一俳句文本的机器解读的“表示”。注意在最后的“表示”中,每个特征被分配到“True”这一参数值(value),表示它在原文本中的存在。“haiku”(俳句)则是分配给该特征向量的标签
要做到这一点,接下来我们就要选定一个归类算法(也叫学习方法),它会根据向量的各特征对辨别向量标签(俳句或非俳句)的影响大小来对它们进行衡量。有许多种这样算法可以执行该任务,但是每个算法对于“影响”的理解各不相同,也往往不可通约。一些算法将特征看作高维直角坐标空间的坐标,并尝试画出一条线来将某一类别的独特特征最好地与另一类别的特征划分开来。另一些算法则采取符号化的、非数字化的方法,将某一特征的出现或缺席看作是一套逻辑关联结果(即这个特征的出现是由先于它出现的其他特征所造成的)。还有其他算法认为有一个概率的过程来驱动这些特征的出现,并试图确定某特征与某一特定类别相关联的可能性。*该观点见Pasanek and Sculley, “Meaning and Mining,” p. 412. 第一组方法包括支持向量机(SVM)和逻辑回归等基于线性的模型;第二组方法包括朴素贝叶斯算法和隐马尔科夫模型;最后一组方法包括决策树分类器。对上述所有方法的详细描述,参见Sebastiani, “Machine Learning in Automated Text Categorization.”
朴素贝叶斯分类器(the Naïve Bayes classifier)是最后一组算法广泛使用的基准方法,也是我们要使用的方法。在给定一个俳句和非俳句向量的随机样本后,分类器就对其中的一个部分(训练集)进行训练,并学习两个类別间特征的分布情况。随后,它会给每个特征分配一个概率评分,以显示该特征分别属于两种类别的概率大小(见图5)。一旦训练完成,分类器就利用计算出的概率评分对样本中的其余向量(测试集)进行分析,试图根据它所看到的特征对每一个向量所属的类别进行预测。亦即,它得出每个特征属于俳句或非俳句的概率大小后,将这些概率分别按这两个类别相加,并根据哪一参数值更高来预测向量的类别。*对该分类器更全面的介绍,参见Grimmer and Stewart, “Text as Data,” p. 11. 它的“朴素”特征与其核心统计学假设有关,即在一个特定类别的文本中,各单词都是相互独立地生成的。这显然是错误的,因为在一组类似的文本中,单词的使用通常高度相关。但是,在某些种类的文本归类中,这种简单的方法仍然被证明是非常有效的。根据朴素贝叶斯算法,一个“文本”是否是俳句只需看它分析出的特征有多大可能是属于某一类文本而不是另一类。这些特征对于每个类别越是特有的,就越容易作出判断。虽然有文学学者指出贝叶斯分类器不适用于在美学文本间作出某些区分,但它却擅长识别那些独特的、频率较低的特征(和单词),这些特征(和单词)又标记了类别间的差异。*参见Yu, “An Evaluation of Text Classification Methods for Literary Study,” p. 336. 在利用机器学习分析文学文本时,朴素贝叶斯算法经常被拿来与支持向量机(SVM)相对比。参见Argamon et al., “Gender, Race, and Nationality in Black Drama, 1950-2006”; Pasanek and Sculley, “Meaning and Mining”; Yu, “An Evaluation of Text Classification Methods for Literary Study.” 支持向量机往往分离出较高频次的单词隔离,将其作为有影响力的特征。这些长处使贝叶斯分类器在我们探索某些初始问题的时候特别有用,如翻译和改编的俳句作品与这个期间的其他短诗有何不同、能否在其他这些诗歌中也检测到体现在措词和音节数上的“俳句性”模式等。

图5 从单个归类测试中产生的概率列表样本。在这个例子中,单词“天空”(sky)与非俳句(not-ha)相连的概率与是与俳句(haiku)相连的5.7倍。相反,单词“雪”(snow)与俳句相连的概率是与非俳句相连的3.7倍
带着这些问题,我们把俳句的翻译和改编作品分别与来自每一种(或一套)期刊的短诗进行对比归类。同时我们还包括进一个控制案例,以便验证朴素贝叶斯算法能识别出我们已知的文本差异。该控制组由长度为300单词的片段组成。这些片段取自卡尔·桑德堡(Carl Sandburg)的诗,他早期的自由体诗歌描绘了芝加哥和周边城镇粗粝的街景以及居住在那里的人,包括工人阶级的劳动者、腐败的政治家、贫穷的移民和妓女。与来自诗歌刊物里的短诗不同,我们事先已经知道桑德堡的这些诗歌表现出的措词和音节数模式完全不同于俳句。*所有诗歌片段都均取自Carl Sandburg, Chicago Poems, New York, 1916. 我们只选取那些明确表现城市主题或描写城市居民的诗歌。我们从两类文本中抽出相同大小的样品并分为训练集和测试集,并为每个归类测试(俳句译作与《诗歌杂志》作品对比、俳句译作与桑德堡作品对比等等)进行了100次测试。这一过程被称为交叉验证,是为确保得出的结果不偏向某一小个文本子集的特征。*具体说来,我们执行了四重交叉验证,使用四分之三的组合样本作为训练数据,其余四分之一作为测试数据。最后,我们从这些测试中计算出平均准确度得分, 该分数显示了机器按文本标签将文本正确归类的次数比例(见图6)。

图6 一百次归类测试后得出的平均准确度分数。图表上半部分是对俳句改编作品与各短诗语料库对比的归类得分。下半部分是对俳句翻译作品的归类得分
这些准确度分数表明,朴素贝叶斯算法能够特别精确地从各种短诗语料库中区分出俳句来。平均而言,它猜对俳句翻译作品的概率是91%,猜对俳句改编作品的概率是86%。与预期相同,桑德堡的诗歌在这两种情况下都是最容易区分的。*所有这些准确度得分基于对每组归类做的随机测试,具有高度统计学意义。得分范围在54%到64%之间,而这种测试的理想分数是50%,这意味着该机器正确猜测的能力与抛硬币决定相差无几。翻译作品的得分稍高,这证明了它们作为一个依赖于更受限的词汇量的类别,具有自身的特殊性。相比之下,改编作品的准确度得分稍低则暗示了其特征所具有的多样性。由于这些分数可以反映出不同的潜在结果,所以有必要看看发生分类错误的地方。对于一些期刊,尤其是《诗歌》和哈莱姆文艺复兴的杂志,分类器不能准确识别非俳句文本,出现了更多把它们误判为俳句的情况。也就是说,它在更多的这些短诗中发现了与俳句相关联的特征。对于其他的期刊,尤其是图中那些频谱低下的,分类器识别俳句的能力不敏感,把更多的俳句误判为非俳句。这可能意味着俳句的特征具有更小的内部统一性,或某些常见于两个类别的特征,如“春天”(spring)、“寒冷”(cold)这些通用词,使分类器偏向了某一类别。*在机器学习中,“查准率”(precision)衡量的是分类器的准确度,并显示分类器正确分辨给定文本所属类别的频度。高查准率意味着在某个文本类别中发现了高度独特的特征。“查全率”(recall)衡量的是分类器的全面性或敏感性,并显示分类器猜对某一特定类型的文本的数量。低查全率意味着该类别的文本更经常地省略能辨识其所属类型的特征。因此,举例说明,如果“春天”出现在非俳句文本中的次数要多得多(这增加了它与这个类别的可能联系),当被发现在俳句中的时候,它对分类器决策的影响就可能要高过其他的词。
这类归类错误揭示出朴素贝叶斯预测文本类别时所做的假设。特别是:文本的类别是由在每个类中按特定比例使用的特征所组成的,这个比例决定了某一特征与该文本的类别相关联的可能性大小。在分析两种具有非常独特特征的类别、且这些特征在每个类別中的分布差异鲜明时,这个假设是有用的。但是,如果类别之间重叠得越多,或类别表现出的内部差异越大,该假设就可能导致问题。就是说,如果要断言两个类别间的绝对类别差异,可能会有问题。但如果是要像我们这样寻找重叠点与融合点,那么这些问题实际上是长处。事实上,我们希望看到更多类似的问题。若把音节数和仅仅出现最频繁的单词算入考虑范围,这样得出的文本差异模型就太过死板,遮蔽了有些诗人不考虑音节数、或某些低频词与“春天”和“冷”这些词结合起来表现俳句美学(或更广泛的东方主义美学)的情况。要揭示这些潜在的重叠的情况,我们需要一个更为灵活的方式来表示文本。
因此,我们在不使用音节数作为特征的前提下重做了一遍测试,这一次还包括了除功能词外的所有单词(见图7)。我们发现机器的准确度得分大幅下降,翻译作品的准确度平均为73%,改编作品为65%。控制案例的得分虽然相比之下仍是高的,不过就连它也有明显下跌,降至82%。一些期刊比其他期刊的独特性稍高,例如《诗歌》《他者们》以及《小评论》,但总体来说对文本可兼性更高的表示显示出极多的重叠。但是,与早先的测试一样,如果不分析错误发生在什么地方,准确度得分会带来误导。分析结果发现,对许多期刊来说,分数下降的很大一部分原因是分类器把更多的短诗误归类为俳句了。*某些期刊出现了相反的情况,即准确率下降是由于更多的俳句被误判为非俳句了。虽然对这些错误的分析不在本文范畴内,但是我们需要注意到,这些结果告诉我们一些关于这些期刊短诗的创作的重要信息。完全基于这些诗的发表出处,我们暂且把它们视为不同于俳句的一个统一类别,尽管事实上这些诗以各自独特的方式具有内在多样性。通过扩展朴素贝叶斯用以辨识文本模式的特征集,我们得到了更多的归类错误,也因此得到了更多有关俳句和非俳句语料库重叠之处的证据。如果说以更为宽松的方式表示语料库间的区别会让机器产生混乱,它也为观察机器概率逻辑下的文本模式创造了更多的机会。

图7 使用定义更宽松的特征组进行100次归类测试得出的平均准确率
东方主义氛围
听起来或许有些矛盾:通过迷惑机器,我们可以更好地评估它是如何作出决定的。这其中的含义在我们分析迷惑机器所导致的某些结果时,会变得更加清晰。首先,简要回顾一下机器学习告诉我们的关于英语俳句的知识会有所帮助。对朴素贝叶斯分类器而言,俳句文本只是一些特征的组合,这些特征通常在某类文本中比在其他文本中出现得更多。如果一首诗包含了更多与分派为俳句的诗歌相关联的特征,如包含“雪”(snow)或“寒冷”(cold)等词,它就更可能被辨认为俳句,反之亦然。在我们的初步测试中,朴素贝叶斯很擅长以强化我们自己标记俳句或非俳句的方式来进行辨认。测试确认了俳句在措词和韵律上与同时期的其他短诗不同。机器学习告诉我们的本质上就是,在把英语俳句中出现的特征视为一个整体时,这些特征就组成了一个统计模式,它与流行于其他短诗中的统计模式区别开来,这一区别具有重要的意义。
不过,能否作出这样清晰的区别,最终取决于我们指示朴素贝叶斯考察什么样的具体特征。朴素贝叶斯之所以表现出色,是因为我们只选择最有可能把俳句从其他文本中区分出来的特征放入我们对文本的表示中。根据机器学习的传统目标,这是一个完全合理的手段。在人们试图从私人电邮帐户中过滤垃圾邮件这样的例子中,更高的准确率是受期待的。如果一个机器学习算法老是把朋友的信息误判为垃圾邮件,数据科学家就会把这种情况看作是个错误,并且寻找方法来改进他/她的模型,以提高该算法的准确率。但是对于我们来说,错误却引发了一个阐释性的问题:是什么让朋友的邮件这么像垃圾邮件?如果我们不是去纠正错误,而是思考该错误如何挑战了植入程序中的初始类型区别呢?或者更好的选择是,如果我们尝试去制造类似的错误来模糊这种区别呢?这就是我们扩大朴素贝叶斯用以从非俳句中辨识出俳句的特征集的目的。正是通过放松对英语俳句这一统计模式的限定,我们扩大了该算法发现具有俳句风格的诗歌的能力。
如此一来,被文学机器学习视为归类错误的地方,我们却将其视为阐释的契机。在这最后一部分中,我们就以两种办法进行阐释。首先,每首被错误归类的俳句(标签为非俳句、却被分辨为可能是俳句的文本)对我们来说都是一个了解机器如何阅读文本模式的窗口。它促使我们思考机器在该诗中发现了什么更能表示俳句而不是非俳句的特征,该特征是否又在多例错误中出现。通过重视俳句作为统计模式的观念,这些被误判的文本证明了俳句在现代主义内的影响分布得多么广泛,也证明了俳句在构成更广泛的美国东方主义氛围中的重要角色。不过,它们能作为证据的原因并不仅仅基于机器的本体观,而是因为这些误判的俳句为考察机器识别出的模式如何跟文本细读和文化历史识别出的模式相协调提供了二次机会。这些误判不仅使我们得以解释机器如何理解模式,还提示我们分析如何把机器的理解与人类阅读模式中所固有的理解进行对比。其结果就是一种新的文学模式识别方法,它因为包含阐释的多种本体视野间的汇聚点而格外充实。
在我们进行的几百个归类测试中,有585首短诗(来自总计大约1900首诗)被误判为俳句,其中一些测试的归类错误比别的测试要多得多。*相比之下,当我们采用更精确的俳句模型时,仅出现45首分类错误的诗歌。在这个组群中,一首诗被误判的平均次数为6次。如果仅考虑达到或超过这一阈值的诗歌,我们就会有202首额外的俳句添加到我们的语料库中(见图8)。这是一批相当可观的新材料,可以用于重新想象英语俳句的历史;但遗留的问题是这些新材料如何(或是否)应包含进俳句的历史中。我们可以简单地接受机器的判断,但一个更能产生批评成果的方法,则是去调查机器识别的模式与人类识别的模式在何处相交或不相交。

图8 归类错误的俳句分布与初始俳句语料库分布的对照图大部分诗歌发表于1916至1918年间,1922之后的诗来自哈莱姆文艺复兴期刊
这些误判的文本分为三组。第一组我们称为候补俳句。其中不但包括庞德和理查德·奥尔丁顿(Richard Aldington)等著名俳句承袭者的诗歌,还包括了通常不与意象派相联系的人物,如路易丝·布莱恩特(Louise Bryant)、伊丽莎白·科茨沃斯(Elizabeth Coatsworth)和哈莱姆文艺复兴诗人刘易斯·亚力山大(Lewis Alexander)等人的作品。这些诗之所以是候补俳句,是因为从文本细读和文化史的角度来看,它们和被纳入俳句语料库的诗歌之间具有相似性。这些诗虽是被机器发现的,但若用更传统的方式,它们也会很容易地被认定为英语俳句。一个代表性的例子是奥尔丁顿的《隽语》,该诗发表于1916年的《小评论》:
雨铃在池塘上摔破
芦苇有白色的雨滴下
她颤抖着喃呢曲身;
风摇荡着紫藤掉落。
水鸟有红色的喙
在百合的叶子下畏缩;
一只灰色蜜蜂,震惊于狂风暴雨,
紧紧附着我的衣袖。*Richard Aldington, “Epigram,” in The Little Review 3 (Mar. 1916), p. 29.
这首诗既充满恰当的自然意象,又得益于一个动静并置的重叠技巧,客观的凝视与淡淡的诗意内省相结合。它的作者和发表出处也符合对俳句影响最为普遍之处的预期。机器在“滴水”“叶子”和“依附”等词汇的索引下发现的模式,与文本细读的读者或文化历史学家辨认的俳句风格相一致。可以肯定,机器是用不同的方式来辨认风格,但它暗示了仅靠措词和简短性就可以同样好地指示出人类读者所阐明的、更加严格但也更加模糊的风格定义。有时候,似乎一种难以言喻的对俳句性质的感觉着实可以化约为词语选择的统计模式。在一些情况下,暗示性这个被众多评论家吟诵的隐晦概念,只不过是选对正确词汇的事。
第二组误判的俳句文本则不那么符合文本细读读者或文化史家的批评直觉。我们把这些文本称为机器俳句。其中的一个极端例子是乔治·布里格斯(George Briggs)的《伊芙林》(“Evelyn”)(1917):
当她把头转向一边;
她下巴和喉咙的连线
延伸到颈肩之下
雅致如孔雀脖子起伏;
又如玫瑰花瓣的柔嫩。
而她的嗓音
听来如汉子,
把锅炉的铁锈清除。*George Briggs, “Evelyn,” in The Smart Set 52 (Aug. 1917), p. 28.
这首诗发表在《聪明人》(TheSmartSet)上 ,与当时人们对仿俳句诗的预期背道而驰。它不仅出现在不符合期待的地方——一个以小说和讽刺笑话闻名的纽约文学杂志,其材料本身也有所欠缺;没有自然意象,也没有任何指向更大的存在洞见的暗示性语言。结尾幽默的并置手法把诗人和读者从他们空灵的幻梦中摇醒,这在日本俳句传统里绝不陌生,而人们也能够在英语中找到戏仿的讽刺作品。机器只根据措词就发现了戏仿作品,这肯定是巧合,不过它也促使我们去进一步研究措词是如何可能与更复杂的文体特征相关联的。来自这份期刊的另一首误判诗歌,题为《自然诗》(“Poem of Native”),1916年发表,就肯定了这种冲动:“一只松鼠顺墙而跑。仅此而已。”*Sarsfield Young, “Poem of Nature,” in The Smart Set 50 (Dec.1916), p. 104.我们承认,朴素贝叶斯算法在俳句风格的识别上比文本细读或文化历史所允许的要慷慨得多。在《伊芙林》中,“玫瑰”这类频繁出现在俳句语料库中的词引导它把该诗也归类为俳句,而“锅炉”这类远为少见的词却被忽略了。*这是被施罗姆·阿加门和马克·奥尔森称为“最小公分母”的问题。分类算法往往会倚重所有特征里的一小部分,这样既没有足够突出、也没有在思辨上公正地对待文学作品的复杂性。(见Shlomo Argamon and Mark Olsen, “Words, Patterns and Documents: Experiments in Machine Learning and Text Analysis,” in Digital Humanities Quarterly 3, no. 2, 2009
最后一组误判文本给文本细读和文化历史方法施加了更大的压力,同时也指出了一个更普遍的东方主义氛围。这些诗介于候补俳句和机器俳句之间。这里我们发现朴素贝叶斯也是一个风格上的敏锐“读者”,能揭示出不同语言模式相交叉的含糊地带。我们来考察《山间刺柏》(“A Sierra Juniper”, 1921),这首诗由安娜·波特(Anna Porter)所作,刊于洛杉矶的《抒情西部》期刊:
我从花岗岩里夺取生命;
抗击风暴,我强炼肢体与根茎,
蹲伏,我抓握住危崖的边缘,
一如我英勇搏斗几千年。*Anna Porter, “A Sierra Juniper,” in Lyric West 1, No. 4 (1921), p. 18.
作为潜在的俳句,这首颂扬一株嶙峋山木的诗兼具两方面特征。它给出了一个高度集中的自然事物意象,但又让人觉得受了韵律编排和重复动词(夺取、抗击、蹲伏)的拖累;它融合了诗性主体和客体,但拟人的感觉又太过外显。把它称为一首严格受俳句影响的诗是走得太远了,但我们又完全可以说它加入了更大范围的对东亚文化的热衷,而英语俳句则是其中不可分割的一部分。正是在这儿,机器学习宽松的本体观被证明极富价值,尽管它关于诗歌文本的概念相对贫乏。机器学习不仅将我们寻找文本模式的能力拓展到较低知名度以及边缘诗人的作品,还涵盖了原本在我们视野之外的文化历史语境。《抒情西部》,一份立足于加利福尼亚、远离小杂志文化和意象主义的传统中心(纽约和芝加哥)的期刊,过去从未成为那个故事的一部分。但机器学习却表明它可以。这份期刊中的其他诗歌,如乔治·罗尔斯(George Rowles)受俳句启发的短文或斯诺·兰利(Snow Langley)对庄周梦蝶的影射——这些同样作为误判俳句而被发现的诗歌——看来也参与了那个时代更普遍的东方主义争鸣。*罗尔斯有好几首诗被错误归类,其中包括《致武士》《日落》和《艺伎与古筝》,均发表于1922年。对庄子的指涉出自兰利的《四月幻觉》,同样发表于1922年。在调查了所有误判诗歌后,我们发现大约20%属于候补俳句,40%属于机器俳句,剩下的40%属于居中的俳句。
《山间刺柏》这首诗是一个令人信服的例子,它说明,一个多元化的文学模式识别模型有助于重绘文学影响的边界。仅从文本细读的角度,这首诗并未严格满足迈纳等学者给出的某些标准,也没有证据支持它受到俳句风格的影响。作为文化历史学家,我们很难将这首诗定位在现代主义学者所划定的已知传播范围之中,特别是由于波特并不知名。文本细读和历史研究限定了一套文学以及社会模式,其中文本却被轻易排除出来。另一方面,机器学习则表明在统计模式的层面存在着与俳句的某些关联——一个微妙却始终存在的关于单词和单词配置的模式。这里“影响”是作为一种统计上的可能性,其中词汇和其他文体特征被认为是各自独特地分布在不同文本类型之间。这些潜在的、非显明的影响痕迹正是机器最擅长检测的,而个体读者却无法在一个大的规模中对其进行识别。
在一些情况下,这些痕迹汇成一首符合对俳句文体的既定期望(基于自然意象、暗示性、简洁)的诗。在另一些情况下得出来的诗与俳句文体的关系却似乎是完全任意的,或顶多是通过定义得更宽松的东方主义话语和俳句才勉强相关。但需要记住的是,即使机器关于影响上的看法与文本细读或文化历史告诉我们的有时不一致,在这些情况中,后两种的方法也是从一开始就给机器的判断提供了信息。毕竟,它们是我们一开始用来选定俳句语料库的依据。机器揭示了存在于这些俳句和误判文本之间明确的现实关系,虽然这一关系与我们作为文学批评者往往侧重的那类关系在本体论上完全不同。在个别诗歌的层面这一关系看似偶然,但在散落于数十家期刊的上百首诗歌的层面,却出现了一个共享着俳句文体特定要素的文本集合。俳句译作和改编作中的文本模式似乎渗透进一系列更广泛的诗作之中,汇成了一个既与俳句文体相关、同时又属于某些更广泛的事物的东方主义氛围。我们可以把这一氛围想象为一种流传中的文本模式,由于与其他模式不同,它可能与某些类型而非另一些类型的美学要更加亲近。这样一来,机器就有助于把俳句的接受历史延长到其最直接和明显的影响节点之外,使我们得以在一个更广泛的诗学话语中考察它的影响和地位。
最后这部分仅指出我们可以如何开始追索这一东方主义氛围的形成和发展,但我们要强调的是,这需要一个在人力解释与机器解释之间交替或连接二者的阅读方法,其中的每一方在批评家从文本中提取意义的努力中都向另一方提供反馈。这样一来,文学模式识别就把文本细读、文化历史和机器学习汇集在一起,使它们相互补充。我们对这些方法的记录体现了每种方法不可避免的局限性,但也表明每种方法都具有一种模式发现的方式。模式(pattern)这一概念是在各种方法间进行调节的控制条件,更重要的是,它还使各种关于文本(以及文本关系)的本体观相对化。我们坚持认为,这种结合导致的碰撞可以产生关于英语俳句以及广泛意义上的现代主义的新历史。
必须承认,我们的方法得益于这样一个事实,即俳句以及现代主义诗歌本身的某些看法总是已经有一些模式似的和计算式的东西。这正是19世纪后期日本文学评论家正冈子规(Masaoka Shiki)试图给出的结论。他写道:“从排列的理论来看,俳句明显具有数值上的阈限……它被局限于仅20到30个音节。”*转引自Janine Beichman, Masaoka Shiki: His Life and Works, Boston, 2002, p. 35. 正冈子规这里借自“‘一名精通数学的当代学者’”来支持俳句即将走到尽头的论点(p. 35)。达达主义者特里斯唐·查拉(Tristan Tzara)也间接提出了这一观点,他说诗人从新闻文章中精心地裁剪出单词,“把它们都放在一个袋子里”,轻轻摇晃,然后将剪下的文字一张张地抽出来,这样就写成了诗。*Tristan Tzara, “To Make a Dadaist Poem” (1920); Seven Dada Manifestos, in “Seven Dada Manifestos” and “Lampisteries,” Barbara Wright (trans.), London, 1977, p. 39.还有马里内蒂(Marinetti),他认为,“语言作为一个系统,根本上是机械的,并能够被分割成可再组合的元素。”*Johanna Drucker, The Visible Word: Experimental Typography and Modern Art:1909-1923, Chicago, 1994, p. 114.由此看来,提出人力与机器阅读的融合是一次挑战,但不是对文学文本及我们作为文学评论家所做工作的异化或是倒退。这里是要使文学对象返回到曾经属于它自身、且目前也越发属于它自身的本体观——我们如今通过数据和计算语言塑造这一本体观,而前几代人则通过频率、公式和模仿的语言来塑造。我们一直知道有一些关系模式在文学体裁的创造和传播之中运作,但直到现在我们仍受限于自己的识别能力。机器学习能够帮助我们发现这些模式。
附录:美国芝加哥大学霍伊特·朗副教授访谈*本文系栏目主持人戴安德、姜文涛对霍伊特·朗所作本刊独家访谈,由清华大学人文社科学院中文系博士研究生赵薇翻译。
提问:可以稍微谈谈您的学术背景吗?您是怎么进入数字人文领域的呢?
回答:我原本的学术训练是在日本近现代文学领域,主要集中在20世纪早期这个历史时段。尽管本科时我也拿到了一个计算机专业的副学位,但计算和量化的研究方法并非我研究生时期专业训练中的一部分,我博士论文中也没有采取计算与量化的方法,后来我的博士论文成为我的第一部学术出版物,是关于诗人、作家宫泽贤治(Miyazawa Kenji,1896—1933)的。我第一次接触到数字人文方法时还是一名助理教授,当时参加了一个由国家人文基金会(NEH)组织的为期两周的工作坊,内容是关于网络分析及其在人文领域中的应用的。由于我的早期工作,我对探索艺术家工作网络的形成与发展发生了兴趣,特别是诗人与诗歌流传的网络。在这个工作坊期间,我学会了如何将这些网络可视化和进行分析,此后,我使用这些方法开始了一项关于二战前日本现代主义诗歌期刊的研究。
最初吸引我转向这项工作的是掌握大量信息的技能,这些信息是关于诗歌的出版时间和出版地的,以及在此基础上去发现诗人间合作和社会区分的模式。涉及的规模之大,是我之前没有想到的。一个拥有几千名诗人和近十万首诗歌的数据库,可以让我以全新的方式去探索这些档案,开始以单个文本和作者的方式来提问。转换了分析的单元和规模之后,潜藏在历史材料中的模式浮现出来,这促进了新的研究问题的产生,以及对艺术生产中社会过程的新理解。自从参加了2010年的工作坊后,我在学习计算机方法方面投入了越来越多的研究时间,尤其是那些用于发现和分析大体积文学文本模式的技能方面。我现在正写的一本书就用到了这些方法,从量化的视角来考虑日本近现代文学史。
提问:您接受的训练是成为日本研究专家,曾对日文和中文文本做过数字人文方面的研究工作。和您相似的做亚洲研究的学者们在使用数字人文工具时会面临哪些挑战?或者说,您能谈谈关于数字人文在北美、日本研究中的现状吗?或者它在日本本国的日本研究中的情形,以及这和它在北美及欧洲学界的情况有什么不同?
回答:在这方面,学者们面临的最大挑战是技术上的,这很大程度上和分析非字母脚本(non-alphabetic scripts)时遇到的困难相关,在这些脚本中,词与词之间没有界限。很多计算工具是以单词为单元进行分析处理的,你想分析的任何文本必须事先是切分(或标记)好的。尽管现在有大量程序可以做这个切分的工作了,却没有一个程序可以达到百分百准确,而且大部分工具都偏向于处理当代语言。这意味着,能够处理20世纪晚期日文文本的程序,在处理20世纪早期文本时可能就没有那么准确,而且肯定无法应付任何日本书面白话文(written vernacular)定型之前的文本。鉴于这一情况,对中日语言由古典向现代白话转变关键历史时期的研究,如果以这种大型、量化的方法来进行,就不可能了;或者这种情况至少使得采取大型量化的分析不那么容易了。而这种语言转变的历史时期正是界定日本和中国近现代文学的时间点。除了文本分割之外,一个更重要的挑战来自于如何运用光学字符识别软件(optical character recognition ,即OCR)来将文本数字化。尽管这个领域的技术已经取得了许多进步,可是在识别亚洲文字中产生的困难情形,尤其是年代越久远的亚洲文字越难识别,这使得大型数字语料库的建设速度减慢。这一情况正在有所改观,大量的工作已经做了起来,尤其是在处理前近代时期文本方面,但毫无疑问,与那些面对字母书写文字(alphabetic scripts)的研究相比,我们慢了几十年。需要更多的学者来做数字化的工作,更多的学者愿意去创建和分享数字语料库,这样才能赶上去。
就日本研究来说,这些技术障碍已经减慢了北美和日本学者们采用数字方法的步伐。开始进入数字研究的门槛看起来似乎太高了,特别是对于老一代的研究日本的学者来说。几位北美日本研究学者,包括我自己在内,已经开始组织工作坊,创造探索分析工具,藉此改变现状,但这毕竟是少数。对于我们从事近现代文学的人来说,一个有利条件是“青空文库(Aozora bunko)”,它收集了超过12000个无版权约束的20世纪初文本,这些都是以众包的形式手动输入的。这便给予我们一个非常重要的起点,来做大规模的现近代文学分析工作。然而,这个数据库里存在着关键性的漏洞和一些不符合规范的地方,这使得它并不那么能代表近现代文学生产。而且这个数据库覆盖的范围也非常小。相比之下,制作精良的数据库,在英语文学研究者们手里,已经用了一段时间了,它们涵盖了18世纪晚期到今天的文学作品。日本文学研究者想要用上这样长时段的数据库,恐怕还要很多年。
有趣的是,正是前近代领域的学者们在引领人们开拓这方面的研究方法,这种情况在日本尤其如此。比如,早期的一些数字工作是由一些宗教学者们完成的,他们投入了大量的经历和时间来制作升级版的数字化佛经。古典时期的学者也发现,他们更易于采用数字方法,一部分原因是由于他们的语料库更小也更易于数字化。早期近代视觉文化的数字化工作也取得了很大进步。同时,也是由于大部分的工作已经做了几十年了,人们也不会经常同北美和欧洲最前沿的理论和计算技术对话交流。我认为,这一沟壑阻碍了数字人文在日本近现代学者中的流行,因为他们看不到这项技术进步可以带来的知识上的帮助。我知道只有非常少数的学者在将计算方法运用于近现代文本的研究,而且他们中的大多数还是语言学领域的。我希望,随着越来越多的人可以使用相关工具,可以使用语料库,会有更多的日本学者能看到这个领域可以带来的效能。最近,弗朗科·莫瑞蒂《远读》(DistantReading)一书被翻译为日文,这很可能产生重要影响,也许会有助于复苏日本文学批评中的量化思路,这一思路可以追溯到夏目漱石(1867—1916)。
提问:假设一名中国的文学研究者想要使用计算机去探索分析100个中文文本,为此,他愿意接受某种培训(例如,某种程序语言),如果可以拿出半年或两三年的时间,那么他该做些什么呢?
回答:如果一个人只有六个月的时间,我会建议他首先阅读一些该领域内领先学者们的文章和书籍,这有助于他弄清哪些类别的分析可以(或不可以)采用计算机方法来进行。这可能包括马修·约克斯(Matthew Jockers)比较基础性的著作《大分析》(Macroanalysis),杰弗里·洛克维尔(Geoffrey Rockwell)和斯蒂芬·辛克莱(Stephan Sinclair)的《诠释学》(Hermeneutica),以及安德鲁·派博(Andrew Piper)、泰德·安德伍德(Ted Underwood)、马修·威尔肯斯(Matthew Wilkens)还有其他很多学者等的学术作品。看过这些后,他有可能想要阅读一些关于统计学和自然语言处理方面的介绍性材料。就编程来说,这真的取决于他之前的经验。但是如果之前完全没有背景,我会建议从一种叫作“旅行者”(Voyant)的线上工具开始,它可以对单个文本做多种分析,也可以用于小批量文本的处理。*参见其网址:https://voyant-tools.org/如果有更大的雄心的话,我推荐去读一下马修·约克斯的《文学学者如何使用R语言进行文本分析》(TextAnalysiswithRforStudentsofLiterature),这是一本非常简单易懂的书。人们在重新为中文文本编码时很可能会遇上一些难题,但我怀疑这些问题都可以参考R语言的编程书来解决,或者参考一些为中文使用者所写的在线指导。我也建议去参加数字人文年会,例如数字人文组织联盟(ADHO)的年会,或者其他会议中的相关专题研讨及工作坊。这将便于你熟悉该领域业已存在的学术环境,也会让你接触到一些当下的讨论和问题。
如果可以投入两至三年的时间,我建议参加一些编程的课程学习(甚至可以是在线课程),学习一些Python和(或者)R语言的基础知识,也可以通过一些指导性的教科书来自学。这样的话,我推荐一些专门的教科书,诸如《使用Python的自然语言编程》(NaturalLanguageProcessingwithPython)。Python和R语言都是用途极为广泛的编程语言,它们可以用于数字人文中的其他方面,包括社会网络和空间分析。我也建议与老师和(或者)学生展开跨学科合作(例如语言学的、社会科学的),他们已经对这些方法相当熟悉了,可以更有效地为你提供资源。他们自己在使用工具时可能会有不同的目的,但是可以提供许多帮助,使你学到基础知识。对于那些想要做网络和空间分析的人来说,也有大量的指导资源。这取决于他们拥有什么样的方法和工具,以及你在开始前对现存的文献资料有多熟悉。
提问:我们对量化的文本分析如何能够挑战文学史的现有结论很感兴趣。您能谈谈数字人文如何确认或定义新的文学类型吗,或者数字人文如何扩张现有文学体裁的边界?
回答:这是一个相当宽泛的问题,我宁肯你去读一些我发表的文章,里面描述了我认为比较新的量化分析,以及它将会为文学史研究带来什么。简单地说,我认为与其说这种分析在界定新的文学类型方面作出了贡献,还不如说它更能够促使我们去批评和重审现有的文学体裁定义。也就是说,这迫使我们去思考,我们如今的定义是如何被某种规模的分析,以及关于文学文本如何起作用的那些不太明显的假设和模型所规定的。数字方法的关键并非是为了要使这些模型以及从中派生出来的解释无效,而是要将这些模型放置在与不同模型和规模分析的比较中,这样我们才有可能丰富我们的总体视野。数字人文最有前景的方面不在于它可以让我们脱离文学基本问题,而在于让我们能够从新的有利角度回到这些问题,从而使这些概念的讨论可以再度热起来。它迫使我们重新认识诸如文体、叙事、情节、人物以及话语等全部概念。但也刺激着我们去重审“细读”和其他解释实践,这些解释实践处于具体的历史和意识形态中,充满了偏见和未经审视的假设。
提问:关于数字人文是如何转变大学教育和研究使命的,我们想听听您的思考。简言之,有人指责数字人文的兴起正是高校新自由主义化的表征,您对此作何感想?
回答:我当然理解这一看法。向量化的靠拢、采取似乎科学的方法,给人一种感觉,似乎我们将很大地盘割让给了侵蚀人文研究领域的经济和社会权力。这在日本是尤其现实的,那里的政府努力重建大学体系(以及取消人文科学的项目),为的是使这个体系更直接地与当下的劳动力市场匹配。所以人们对这种威胁的体会非常真实,而且看上去数字人文不过是顺其道行之的。但是,我认为这种观点是非常短视的,它忽视了数字人文领域的学者们实际上真正从事的工作。如果认为只有人文学领域受到了大学新自由主义化的不利影响,进而对此作出的反应不过是对无论任何形式的数字人文研究都拒绝,且毫无旁顾地继续做我们学术界一直做的那种类型的研究,那都是非常错误的。对于我来说,这种心态既反智也误入歧途,因为它为我们现存体系之外设置了一个批评空间。但这从来未曾发生过。人文学者从来就是在大学的行政体系和经济结构之内工作的,而且在并不久远的过去,他们还十分愿意从事跨学科的工作呢。实际上,人文和文化研究与科学研究相悖的思想是相当晚近的发明。在我们为现存的人文学科形式丧失而哀悼之前,我们应该始终记住更长时段的人文学科史。
的确,人文科学和自然科学当然蕴含了不同的认识论以及解释学假设,我们不能指望文化现象可以像生物或物理过程那样被量化和抽象化。但是,认为所有形式的量化研究都不适用于人文学科就不够坦诚了,这忽略了艺术与科学之间长久的交流史。如果新自由主义化正在逼迫人文学者去与科学领域之中发生的研究进行谈话、与其他看待世界的模式之间再次沟通对话,那这便未必是一桩坏事 。如果对话是单边的,那将带来问题,但这也正是为什么人文学者应该多去参与其他科学领域发展的原因。越是自绝于其他领域,我们将越是无法展开真正的对话,也无法为人文研究的独特性做辩护。保存我们的相关性并不是要拒绝曾经指引过我们研究的问题和对象,而是要在数字技术全面渗透的今天,重新思考这些问题和对象的处境。我们需要全面参与到这些技术中去,不仅为了帮我们把研究的问题和对象转换到这新的数字时代,同时也让我们以一种明智的、知情的方式去质询这转变带来的得失。我们,作为人文学者,应积极为这种讨论贡献力量,但如果我们只是继续自言自语下去,那终将无济于事。
(责任编辑:陆晓芳)
2016-09-25
霍伊特·朗(Hoyt Long),美国芝加哥大学东亚语言与文化系副教授,主要研究方向为现代日本文学、媒体历史、文学社会学与数字人文,著有OnUnevenGround:MiyazawaKenjiandtheMakingofPlaceinModernJapan(2012),与苏真一起合作负责芝加哥文本实验室(Text Lab)。 苏 真(Richard Jean So),美国芝加哥大学英文系副教授,主要研究方向为数字人文等,著有TranspacificCommunity:America,ChinaandtheRiseandFallofaGlobalCulturalNetwork(2016)。
I0-05
A
1003-4145[2016]11-0034-20
译者简介:林 懿,女,南京大学英语系博士研究生,美国杜克大学访问学者,主要研究方向为当代英美文学与文学理论。
①Hoyt Long, and Richard Jean So, “Literary Pattern Recognition: Modernism between Close Reading and Machine Learning,” inCriticalInquiry, 42:2 (2016), pp.235-267. The University of Chicago Press. Translated and reprinted with permission of The University of Chicago Press.
猜你喜欢
读写月报(高中版)(2022年10期)2022-11-19
中学生天地(A版)(2022年9期)2022-10-31
云南教育·小学教师(2022年4期)2022-05-17
制造技术与机床(2019年10期)2019-10-26
中华诗词(2019年1期)2019-08-23
电子制作(2018年18期)2018-11-14
大众文艺(2018年16期)2018-07-12
椰城(2018年2期)2018-01-26
名作欣赏(2017年19期)2017-07-15
小学教学参考(2015年20期)2016-01-15
