
LSTM-in-LSTM for generating long descriptions of images
2016-12-14 08:06:14JunSongSiliangTangJunXiaoFeiWuandZhongfeiMarkZhang
Computational Visual Media 2016年4期
Jun Song,Siliang Tang,Jun Xiao,Fei Wu(),and Zhongfei(Mark)Zhang
Research Article
LSTM-in-LSTM for generating long descriptions of images
Jun Song1,Siliang Tang1,Jun Xiao1,Fei Wu1(),and Zhongfei(Mark)Zhang2
In this paper,we propose an approach for generating rich fine-grained textual descriptions of images.In particular,we use an LSTM-in-LSTM(long short-term memory)architecture,which consists of an inner LSTM and an outer LSTM.The inner LSTM effectively encodes the long-range implicit contextual interaction between visual cues(i.e.,the spatiallyconcurrent visual objects),while the outer LSTM generally captures the explicit multi-modal relationship between sentences and images(i.e.,the correspondence of sentences and images).This architecture is capable of producing a long description by predicting one word at every time step conditioned on the previously generated word,a hidden vector(via the outer LSTM), and a context vector of fine-grained visual cues(via the inner LSTM).Our model outperforms state-of-theart methods on several benchmark datasets(Flickr8k, Flickr30k,MSCOCO)when used to generate long rich fine-grained descriptions of given images in terms of four different metrics(BLEU,CIDEr,ROUGE-L,and METEOR).
long short-term memory(LSTM);image description generation;computer vision;neural network
1 Introduction
Automatically describing the content of an imageby means of text(description generation)is a fundamental task in artificial intelligence,with many applications.For example,generating descriptions of images may help visually impaired people better understand the content of images and retrieve images using descriptive texts.The challenge of description generation lies in appropriately developing a model that can effectively represent the visual cues in images and describe them in the domain of natural language at the same time.
1 College of Computer Science and Technology,Zhejiang University, Hangzhou 310027, China.E-mail:J. Song,songjun54cm@zju.edu.cn;S.Tang,siliang@cs. zju.edu.cn;J.Xiao,junx@cs.zju.edu.cn;F.Wu,wufei@ cs.zju.edu.cn().
2 Department of Computer Science,Watson School of Engineering and Applied Sciences,Binghamton University,Binghamton,NY,USA.E-mail:zhongfei@ cs.binghamton.edu.
Manuscript received:2016-07-25;accepted:2016-08-19
There have been significant advances in description generation recently. Some efforts rely on manually-predefined visual concepts and sentence templates[1–3].However,an effective image description model should be free of hard coded templates and categories.Other efforts treat the image description task as a multi-modal retrieval problem (e.g.,image–query–text)[4–7]. Such methods obtain a descriptive sentence of each image by retrieving similarly described images from a large database and then modifying these retrieved descriptions based on the query image.Such methods lack the ability to generate descriptions of unseen images.
Motivated by recent successes in computer vision and natural language processing,current image description generation approaches generate more reasonable descriptive sentences of given images[8–10]based on an approach of word-by-word generation via recurrent neural networks(RNN)(e.g.,using long short-term memory (LSTM))since these approaches store context information in a recurrent layer.Most description generation research only utilizes the image being described to the RNN at the beginning[10].By looking at the image only once during word-by-word generation,the precision and recall of the predicted noun words(i.e.,visual objects in images)decrease rapidly with their position of
occurrence in a sentence(as shown in Fig.5),since these approaches merely preserve global semantics at the beginning and disregard the fine-grained interactions between visual cues which could be useful if we wish to generate richer,more descriptive captions.
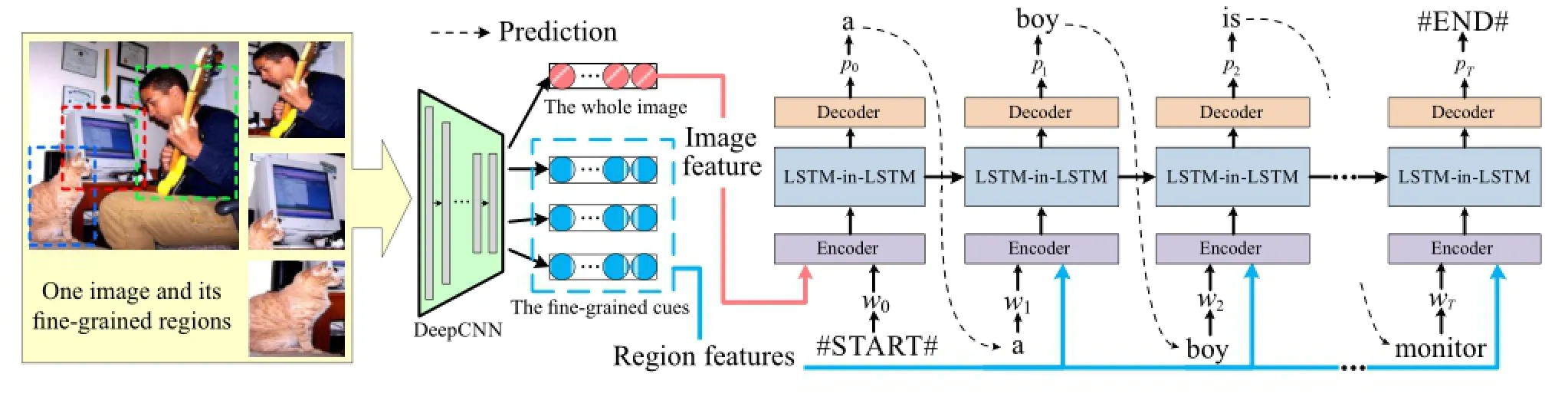
Fig.1 Overview of our approach.The DeepCNN model projects the pixels of an image and its fine-grained regions into a 4096-dimensional feature.The encoder layer encodes the textual words,the whole image,and the visual objects as vectors.The prediction layer outputs one hidden vector at each step which is then used to predict the next word in the decoder layer.While training,the tthword in the sentence is fed into the model to predict the next word(solid lines).While testing,the word predicted at the previous step(t−1)is fed into the model at step t.
From the point of view of the mutual utilization of visual and textual contexts during each step of wordby-word generation,image description generation methods may in general be categorized into two classes.The first class repeatedly takes advantage of the whole image at each time step of the output word sequence[9].Such methods may identify the most interesting salient objects the words refer to;however,they may still ignore the fine-detail objects.
The second class explicitly learns the correspondences between visual objects(detected as object-like or regions of attention)and the matching words at each step of generation, and then generates the next word according to both the correspondences and the LSTM hidden vector[11,12].Such methods may neglect longrange interactions between visual cues(e.g.,the spatially-concurrent visual objects).
In this paper,we develop a new neural network structure called LSTM-in-LSTM(long short-term memory)which can generate semantically rich and descriptive sentences for given images.The LSTM-in-LSTM consists of an inner LSTM(encoding the implicit long-range interactions between visual cues)and an outer LSTM(capturing the explicit multi-modal correspondences between images and sentences).This architecture is capable of producing a description by predicting one word at each time step conditioned on the previously generated word, a hidden vector(via the outer LSTM),and the context vector of fine-grained visual cues(via the inner LSTM).
Compared with existing methods,the proposed LSTM-in-LSTM architecture,as illustrated in Fig. 1,is particularly appropriate for generating rich finegrained long descriptions with appealing diversity, owing to its modeling of long-range interactions between visual cues.
2 Related work
2.1 Natural language models
Over the last few years,natural language models based on neural networks have been widely used in the natural language processing domain.Artificial neural networks have been employed to learn a distributed representation for words which better captures the semantics of words[13]. Recursive neural networks have been used to encode a natural language sentence as a vector[7].Palangi et al.[14] use a recurrent neural network(RNN)with long short-term memory(LSTM)to sequentially take each word in a sentence,and encode it as a semantic vector.A recurrent neural network encoder–decoder architecture has been proposed to encode a source language sentence,and then decode it into a target language[15].
2.2 Deep model for computer vision
Methods based on deep neural networks have been adopted by a large number of computer vision applications.Deep convolutional neural networks (DeepCNN)have achieved excellent performance in image classification tasks(e.g.,AlexNet[16],
VggNet[17]).Object detection systems based on a well trained DeepCNN outperform previous works (RCNN[18],SPPNet[19]).Girshick[20]proposed Fast-RCNN which is much faster than RCNN and SPPNet for object detection during both training and testing.
2.3 Image descriptions
There are two main categories of methods for automatically describing an image:retrieval based methods and generation based methods. Many works try to describe an image by retrieving a relevant sentence from a database. They learn the co-embedding of images and sentences in a common vector space and then descriptions are retrieved which lie close to the image in the embedding space[4,5,7]. Karpathy et al. [21] argue that by using a correspondence model that is based on a combination of image regions and phrases of sentences,the performance of retrieval based image description methods can be boosted. Generation based methods often use fixed templates or generative grammars[22]. Other generation methods more closely related to our method learn the probability distribution of the next word in a sentence based on all previously generated words[8–10].
3 Method
Our model comprises three layers:the encoder layer, the prediction layer,and the decoder layer.In the encoder layer,the words in sentences are encoded into different word vectors(one vector per word).For whole images and visual objects(detected as objectlike regions),a deep convolutional neural network is used to encode them into 4096-dimensional visual vectors.The prediction layer outputs a single hidden vector which is then used to predict the next word in the decoder layer.The overview of our approach is illustrated in Fig.1.
3.1 Encoder layer
First,we encode the words in sentences,the whole image,and the visual objects in the image as vectors.Given training data denoted as(S,I), which is a pair of a sentence S and its length(in words)T,and image I.The words in the sentence S are w1,w2,···,wT.We first denote each word as a one-hot representation w1,w2,···,wT.This representation is a binary representation which has the same dimension as the vocabulary size and only one non-zero element.After that,the one-hot representation is transformed into an h-dimensional vector as follows:
ωt=Wswt(1)
Wsis a matrix of size h×V,where V is the size of the vocabulary.Wsis randomly initialized and learned during the model training.
For images,we use Fast-RCNN[20]to detect the visual objects in the image.Fast-RCNN is a fast framework for object detection based on a deep convolutional neural network. This framework is trained using a multi-task loss function in a single training stage,which not only simplifies learning but also improves the detection accuracy.
A threshold τ is set to select the valid visual objects from all objects detected by Fast-RCNN. Visual objects with a detection score higher than τ are considered as valid visual objects;the rest are discarded.The number of the valid objects may be different in each image.
For each image I and each visual object r,we first obtain their 4096-dimensional VGGNet16[17] fc7 features.Then these features are encoded as hdimensional vectors as follows:
vI=WeC N NVGGNet16(I)+be(2)
r=WrC N NVGGNet16(r)+br(3)
vIis the vector of image I and r is the vector of visual object r. The C N NVGGNet16(·) function projects the pixels into a 4096-dimensional VGGNet16[17]fc7 feature.Weand Wrare matrices with dimension h× 4096;beand brare bias vectors with dimension h.We,Wr,be,and brare parameters learned during training.
3.2 Prediction layer
The prediction layer consists of two LSTMs,namely the outer LSTM and the inner LSTM.We call this architecture LSTM-in-LSTM.
3.2.1 Basic LSTM unit
In order to predict each word in a sentence,the recurrent net needs to store information over an extended time interval.Here we briefly introduce the basic LSTM approach[23]which has had great success in machine translation[24]and sequence generation[25].
As shown in Fig.2,a single memory cell c is surrounded by three gates controlling whether to input new data(input gate i),whether to forget history(forget gate f),and whether to produce the current value(output gate o)at each time t.The memory cell in LSTM encodes information at every time step concerning what inputs have been observed prior to this step.The value of each gate is calculated according to the word vector ωtat step t and the predicted hidden vector mt-1at step t-1.The definitions of the memory cell and each gate are as follows:
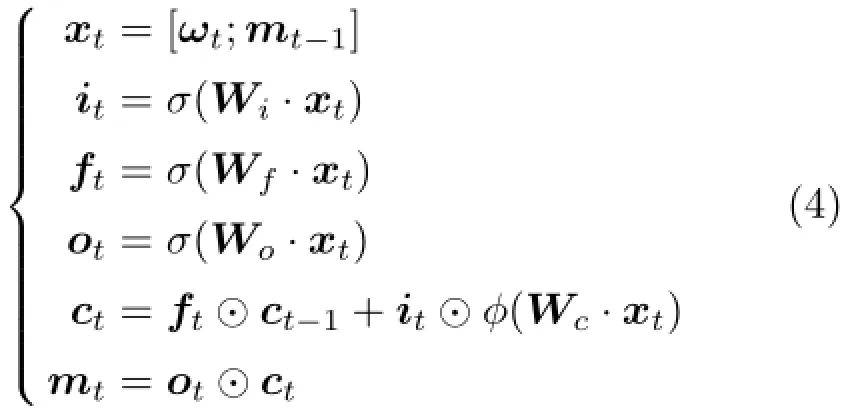
where⊙ represents the element-wise product.σ and φ are nonlinearlity mapping functions.In our experiments,we set σ as a sigmoid function and φ as hyperbolic tangent.mtis the output of the LSTM at step t.Wi,Wf,Wo,and Wcare parameter matrices learned during training.
3.2.2 LSTM-in-LSTM unit
As previously discussed,we attempt to employ both the explicit multi-modal correspondence of sentences and images,and the implicit long-range interactions of fine-grained visual cues,during the prediction of each word.The proposed LSTM-in-LSTM has two layers of LSTM networks,namely the outer LSTM and the inner LSTM.
See Fig.3.The outer LSTM is a basic LSTM unit. At each step t,the outer LSTM takes a word vector ωt(the tthword vector of the sentence in training,or the word vector of the previously predicted word in prediction),the last predicted hidden vector mt-1, and the context output vector of the inner LSTMas the input.In the outer LSTM,the vector xtis defined as follows:
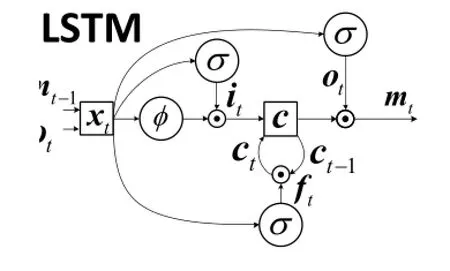
Fig.2 The basic LSTM method.
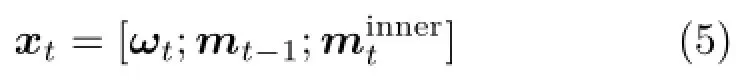
xtis employed to obtain the t step output of the LSTM-in-LSTM mt.
The inner LSTM is composed of stacked LSTM units.In essence,the gates of the inner LSTM learn to adaptively look up significant visual object-like regions,and encode the implicit interactions between visual cues at each step.For the kthbasic LSTM in the inner LSTM,the input is the kthobject vector rkand the output vector of the previous basic LSTM (mt-1for the first LSTM unit),as follows:
Note that the parameters of the outer LSTM(e.g., Wi,Wf,Wo,and Wc)differ from those of the inner LSTMhowever all basic LSTM units in the inner LSTM share the same parameters.
For the inner LSTM,each basic LSTM unit takes one visual object vector as an input,so the number of basic LSTM units in the inner LSTM equals the number of valid visual objects.
3.3 Training the model
We use a probabilistic mechanism to generate the description of each image.The training objective is to minimize the log-likelihood of the perplexity of each sentence in the training set using an L2regularization term,as shown in Eq.(7):
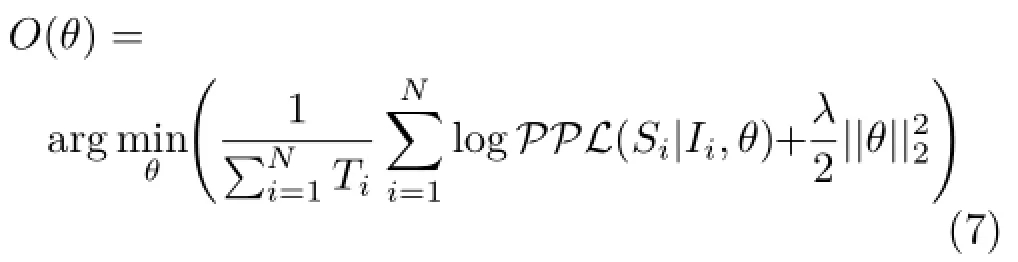
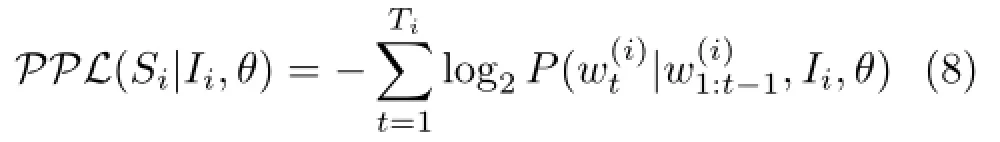
θ denotes all training parameters in our model,N is the size of the training set,i indicates the index of each training sample,and Iiand Sidenote the image and the sentence for the ithtraining sample.Tidenotes the length(in words)of sentence Si;λ is the weighting parameter for standard L2regularization of θ.
The perplexity of a sentence is calculated as the negative log-likelihood of its words according to its associated image,as follows:
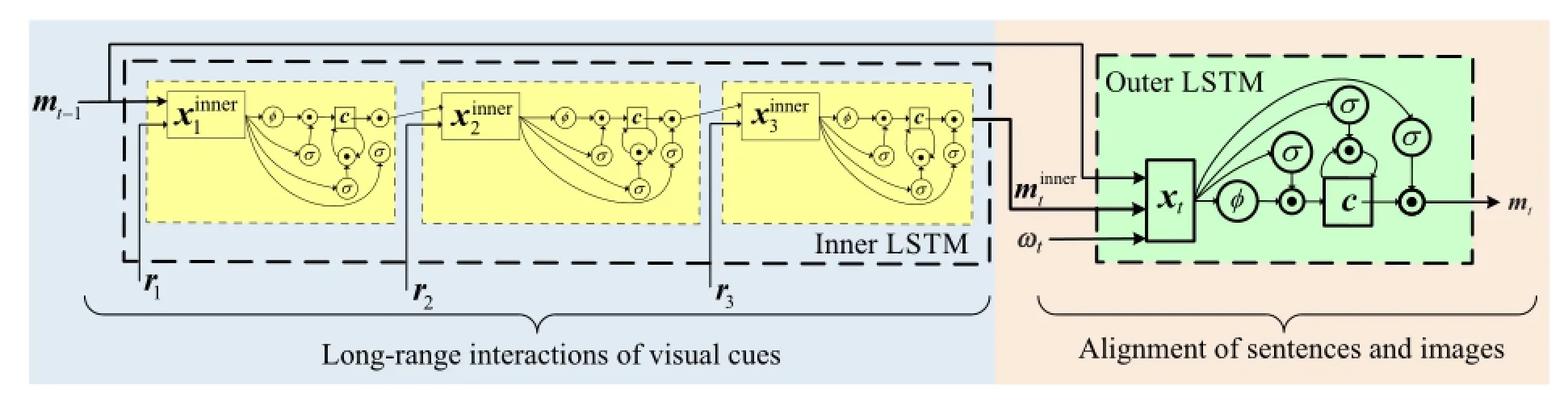
Fig.3 LSTM-in-LSTM structure.For simplicity,we show three visual object vectors r1,r2,and r3,so there are 3 LSTM units in the inner LSTM.The 3 visual objects are sequentially fed into the inner LSTM in a descending order according to their Fast-RNN detection scores.The parameters of the outer LSTM and the inner LSTM differ,but each LSTM unit in the inner LSTM shares the same parameters.
Here the probability of each word is computed based on the words in its context and the corresponding image.denotes the tthword in the ithsentence anddenotes the words before the tthword in the ithsentence.Therefore,minimizing the perplexity is equivalent to maximizing the loglikelihood.Stochastic gradient descent is used to learn the parameters of our model.

Algorithm 1:Algorithm for training our model Input:A batch B of training data,as image and sentence pairs. for all pair(Si,Ii)∈B do /*Encoder layer*/ Encode each word in sentence Iiinto word vectors ωt(t=0,···,Ti). Detect visual objects and learn the vector of objects rk(k=1,···,K)and the image vIi. /*Prediction layer*/ m0=outerLSTM(ω0,0,vIi) for all t←1 to Tido minnert =innerLSTM(r1,r2,···,rK) mt=outerLSTM(ωt,mt-1,minnert ) end for /*Decoder layer*/ for all t←0 to Tido pt=Softmax(Wdmt+bd) end for Calculate and accumulate the gradients. end for Calculate the update values∇θ /*Update the parameters*/ θ=θ−∇θ Output:The parameters θ of the model.
Algorithm 1 summarises the training procedure for our model.outerLSTM(·)denotes the forward pass of the outer LSTM and innerLSTM(·)denotes the forward pass of the inner LSTM.We insert a start token#START#at the beginning of each sentence and an end token#END#at its end.Thus the subscript t expands from 0(#START#)to T+1 (#END#).In the first step(t=0),the word vector of the start token#START#ω0and the vector of the ithimage(vIi)are fed into the outer LSTM to obtain the first predicted hidden vector m0.
3.4 Sentence generation
Given an image,its descriptive sentence is generated in a word-by-word manner according to the predicted probability distribution at each step,until the end token#END#or some maximum length L is reached. We insert a start token#START#at the beginning of each sentence and an end token #END#at its end.Thus the subscript t goes from 0(#START#)to T+1(#END#).In the first step(t=0),the word vector of the start token #START# ω0and the vector of ithimage(e.g., vIi)are fed into the outer LSTM to get the first predicted hidden vector m0.We use BeamSearch to iteratively select the set of κ best sentences up to step t as candidates to generate sentences at step t+1,and keep only the resulting best κ of them. Algorithm 2 summarises the process used to generate one sentence.
4 Experiments
4.1 Comparison methods
Since we are interested in word-by-word imagecaption generation which utilizes mutual visual and textual information during each prediction step,we compare our work to three types of algorithms as follows:
·NIC model[10]and Neural-Talk[8]:NIC and Neural-Talk models only utilize whole-image
information at the beginning during description prediction.

Algorithm 2:Generating one sentence in our model Input:The input image I. Detect visual objects and learn the vectors rk(k = 1,···,K)and vI. ω0is the word vector of#START#. m0=outerLSTM(ω0,0,vI) t=1,wtis the word with the highest probability. while wtis not#END#and t≤L do minnert =innerLSTM(r1,···,rK) mt=outerLSTM(ωt,mt-1,minnert ) pt=Softmax(Wdmt+bd) t=t+1 wtis the word with the highest probability. end while Output:The sentence with words in sequence:w1,···, wT.
·m-RNN[9]:the m-RNN model employs wholeimage information at each prediction step.
·attention model[11]: this attention model uses fine-grained visual cues(regions of attention) during each prediction step.
4.2 Datasets
Three different benchmark datasets were used in the experiments;Table 1 shows the size of each dataset.
·Flickr8k:the Flickr8k[5]dataset comprises 8000 images from Flickr showing persons and animals. Each image has 5 descriptive sentences.
·Flickr30k:the Flickr30k[26]comprises 30,000 images from Flickr showing daily activities, events,and scenes.Each image has 5 descriptive sentences.
·MSCOCO:the Microsoft COCO[27]dataset comprises more than 120,000 images.Each image has 5 descriptive sentences.
4.3 Experimental setup
In order to perform a fair comparison,we used the same VGGNet16 fc7 feature as the visual feature for all models.For the Flickr8k and Flickr30k datasets,the dimension of the hidden vectors was h=512. For MSCOCO,h=600.In our experiments,we used the threshold τ=0.5 to select valid visual objects in each image.
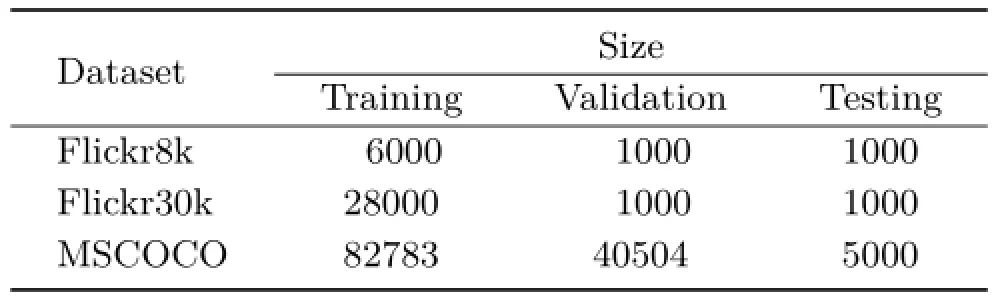
Table 1 Sizes of the three benchmark datasets,and the numbers of images used for training,validation,and testing
4.4 Results
Our experiments compared the methods in three ways:(i)a qualitative analysis of long description generation performance in terms of four metrics,(ii) the predictive ability for rich fine-grained semantics in long descriptive sentences,and(iii)the ability to predict SVO(subject–verb–object)triplets.
4.4.1 Generation of long descriptions
Many metrics have been used in the image description literature.The most commonly used metrics are BLEU[28]and ROUGE[29].BLEU is a precision-based measure and ROUGE is a recallrelated measure.BLEU and ROUGE scores can be computed automatically from a number of ground truth sentences,and have been used to evaluate a number of sentence generation systems[2,5,30].In this paper we use BLEU-N,ROUGE-L,CIDEr[31], and METEOR[32]to evaluate the effectiveness of our model.We used the open-source project cococaption software1coco-caption:https://github.com/tylin/coco-caption.to calculate those metrics.
When generating descriptions,accurate generation of the sentences which consist of many words(i.e., long sentences)is difficult,as it is likely that long sentences deliver rich fine-grained semantics.We argue that the LSTM-in-LSTM architecture is capable of predicting long sentence descriptions since it implicitly learns the contextual interactions between visual cues.Thus,we divide the test data into two parts:images with long sentence descriptions and images with short sentence descriptions.Descriptions of images in the test dataset are considered to be long if they have more than 8 words(which is the average length of the sentences in the MSCOCO test dataset);the remaining images have short descriptions.
Table 2 reports the image-captioning performance of the images with long and short descriptions.BN gives the BLEU-N metric.The performance of our model is comparable to that of the state-of-theart methods on short descriptions.However,the performance of our approach is remarkably better than that for other models for long descriptions.Compared with the second best methods,our long descriptions of the MSCOCO data show 5.2%, 7.3%,8.5%,11.6%,14.1%,6.0%,and 8.0%average performance improvements for B-1,B-2,B-3,B-4,CIDEr,ROUGE-L,and METEOR metrics, respectively.Other methods which utilize the visual cues at each step also achieve a better performance than methods only using the visual cues at the beginning step;this observation demonstrates that appropriate utilization of visual information helps boost the performance of image-captioning with rich diverse semantics.We show some examples generated by our model for the MSCOCO dataset in Fig.4.
4.4.2 Fine-grained semantic interaction
During image captioning,the caption is predicted word-by-word in grammatical interaction order.It is interesting to show the prediction performance of the nouns(i.e.,the corresponding grounded visual objects)in order(deminstrating how the next noun word is generated).Figure 5 illustrates the average prediction performance of the first 5 noun words in sentences in terms of recall and precision for the Flick8k dataset.
As can be seen in Fig.5(a),our model(red line with diamond)shows better performance than the other models due to taking into account long-range interactions between visual objects at each prediction step in our model.
Figure 5(b)shows that our model does not perform better than m-RNN.In m-RNN,the whole image is used at each step and therefore mRNN has a tendency to predict noun words for a large region several times.For the test images in the Flick8k dataset,the occurrence rate of one noun word appearing more than once in a sentence is 0.076. The rates of the predicted noun words occurring more than once in a sentence are 0.245(m-RNN), 0.015(Neural-Talk),and 0.039(our model).This demonstrates that our model is capable of generating more diverse rich fine-grained descriptions.
4.4.3 SVO triplet prediction
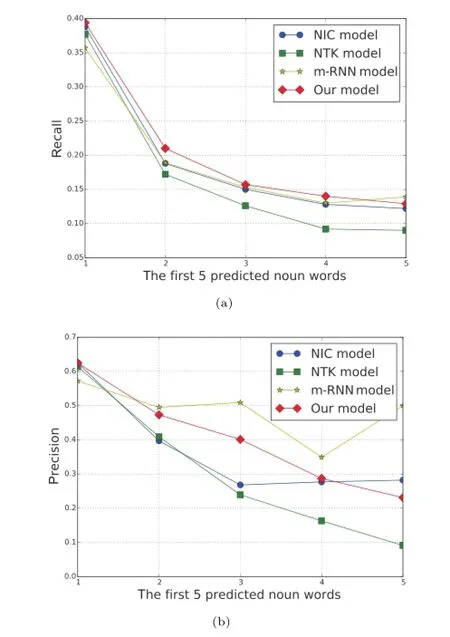
Fig.5 Recall–precision curves in terms of the first 5 predicted noun words from NIC model,Neural-Talk(NTK)model,m-RNN model, and our model.
We next evaluate the performance of our model in terms of predicting SVO(subject–verb–object) triplets. First,we found all SVO triplets in the descriptive sentences in the Flickr8k and Flickr30k test data respectively,using the Stanford Parser[33]. For example,given the sentence“a small girl in the grass plays with fingerpaints in front of a white canvas with a rainbow on it”,we get the following SVO triplets:(girl,in,grass),(rainbow,on,grass), (girl,play,fingerpaint),(girl,play,rainbow).Then we remove the object of each triplet,and feed the visual content(the whole image and the visual objects),the subject and the verb into each method, and evaluate how well it can predict the removed object.
Table 3 compares the ability of different models to predict the removed object. R@K(Recall at K)measures whether the correct result is ranked ahead of others.We use R@K(K=1,5,10,15,20) to compute the fraction of times where the correct result is found among the top K ranked items.A higher R@K means a better performance.
5 Limitations and further work
The major limitation of our model lies in the time taken to train our model.Compared to other modelswhich ignoring contextual interaction between visual cues,our model spends more time for object detection and encoding the long-range implicit contextual interactions.Our model can generate rich fine-grained textual descriptions of each image;it could be further extended to generate much more detailed descriptions of visual objects in each image and much more accurate descriptions of the interactions between visual objects.
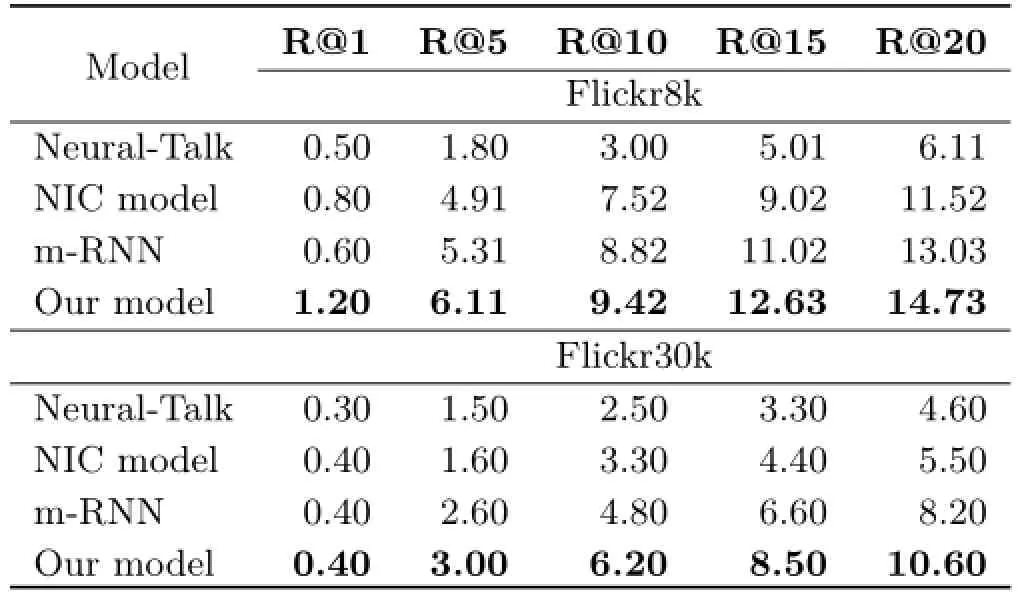
Table 3 Triplet prediction performance.The best results are shown in boldface
6 Conclusions
This paper proposed an LSTM-in-LSTM architecture for image captioning. The proposed model not only encodes long-range implicit contextual interactions between visual cues (spatially occurrences of visual objects), but also captures the explicit hidden relations between sentences and images(correspondence of sentences and images).The proposed method shows significant improvements over state-of-the-art methods, especially for long sentence descriptions.
Acknowledgements
This work was supported in part by the National Basic Research Program of China (No.2012CB316400),National Natural Science Foundation of China(Nos.61472353 and 61572431), China Knowledge Centre for Engineering Sciences and Technology,the Fundamental Research Funds for the Central Universities and 2015 Qianjiang Talents Program of Zhejiang Province.Z.Zhang was supported in part by the US NSF(No.CCF-1017828)and Zhejiang Provincial Engineering Center on Media Data Cloud Processing and Analysis.
[1]Farhadi,A.;Hejrati,M.;Sadeghi,M.A.;Young, P.;Rashtchian,C.;Hockenmaier,J.;Forsyth,D. Every picture tells a story:Generating sentences from images.In:Computer Vision—ECCV 2010.Daniilidis, K.;Maragos,P.;Paragios,N.Eds.Springer Berlin Heidelberg,15–29,2010.
[2]Kulkarni,G.;Premraj,V.;Ordonez,V.;Dhar, S.;Li,S.;Choi,Y.;Berg,A.C.;Berg,T.L. BabyTalk: Understanding and generating simple image descriptions.IEEE Transactions on Pattern Analysis and Machine Intelligence Vol.35,No.12, 2891–2903,2013.
[3]Li,S.;Kulkarni,G.;Berg,T.L.;Berg,A.C.;Choi,Y. Composing simple image descriptions using web-scale n-grams.In:Proceedings of the 15th Conference on Computational Natural Language Learning,220–228, 2011.
[4]Gong,Y.;Wang,L.;Hodosh,M.;Hockenmaier,J.;Lazebnik,S.Improving image-sentence embeddings using large weakly annotated photo collections.In: Computer Vision—ECCV 2014.Fleet,D.;Pajdla,T.;Schiele,B.;Tuytelaars,T.Eds.Springer International Publishing,529–545,2014.
[5]Hodosh,M.;Young,P.;Hockenmaier,J.Framing image description as a ranking task:Data,models and evaluation metrics.Journal of Artificial Intelligence Research Vol.47,853–899,2013.
[6]Ordonez,V.;Kulkarni,G.;Berg,T.L.Im2text: Describing images using 1 million captioned photographs.In: Proceedings of Advances in Neural Information Processing Systems,1143–1151, 2011.
[7]Socher,R.;Karpathy,A.;Le,Q.V.;Manning,C. D.;Ng,A.Y.Grounded compositional semantics for finding and describing images with sentences. Transactions of the Association for Computational Linguistics Vol.2,207–218,2014.
[8]Karpathy,A.; Fei-Fei,L.Deep visual-semantic alignments for generating image descriptions.In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,3128–3137,2015.
[9]Mao,J.;Xu,W.;Yang,Y.;Wang,J.;Huang, Z.;Yuille,A.Deep captioning with multimodal recurrent neural networks(m-RNN).arXiv preprint arXiv:1412.6632,2014.
[10]Vinyals,O.;Toshev,A.;Bengio,S.;Erhan,D. Show and tell:A neural image caption generator. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,3156–3164,2015.
[11]Jin,J.;Fu,K.;Cui,R.;Sha,F.;Zhang,C.Aligning where to see and what to tell:Image caption with region-based attention and scene factorization.arXiv preprint arXiv:1506.06272,2015.
[12]Xu,K.;Ba,J.;Kiros,R.;Cho,K.;Courville,A.;Salakhutdinov,R.;Zemel,R.S.;Bengio,Y.Show, attend and tell: Neural image caption generation with visual attention.In:Proceedings of the 32nd International Conference on Machine Learning,2048–2057,2015.
[13]Bengio,Y.;Schwenk,H.;Senécal,J.-S.;Morin,F.;Gauvain,J.-L.Neural probabilistic language models. In:Innovations in Machine Learning.Holmes,D.E.;Jain,L.C.Eds.Springer Berlin Heidelberg,137–186, 2006.
[14]Palangi,H.;Deng,L.;Shen,Y.;Gao,J.;He, X.;Chen,J.;Song,X.;Ward,R.Deep sentence embedding using the long short term memory network: Analysis and application to information retrieval. IEEE/ACM Transactions on Audio,Speech,and Language Processing Vol.24,No.4,694–707,2016.
[15]Bahdanau,D.;Cho,K.;Bengio,Y.Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473,2014.
[16]Krizhevsky,A.;Sutskever,I.;Hinton,G.E.Imagenet classification with deep convolutional neural networks. In:Proceedings of Advances in Neural Information Processing Systems,1097–1105,2012.
[17]Simonyan,K.;Zisserman,A.Very deep convolutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556,2014.
[18]Girshick,R.;Donahue,J.;Darrell,T.;Malik,J. Rich feature hierarchies for accurate object detection and semantic segmentation.In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,580–587,2014.
[19]He,K.;Zhang,X.;Ren,S.;Sun,J.Spatial pyramid pooling in deep convolutional networks for visual recognition.In:Computer Vision—ECCV 2014.Fleet, D.;Pajdla,T.;Schiele,B.;Tuytelaars,T.Eds. Springer International Publishing,346–361,2014.
[20]Girshick,R.Fast r-cnn.In:Proceedings of the IEEE International Conference on Computer Vision,1440–1448,2015.
[21]Karpathy,A.;Joulin,A.;Li,F.F.F.Deep fragment embeddings for bidirectional image sentence mapping. In:Proceedings of Advances in Neural Information Processing Systems,1889–1897,2014.
[22]Elliott,D.; Keller,F.Image description using visual dependency representations.In:Proceedings of the Conference on Empirical Methods in Natural Language Processing,1292–1302,2013.
[23]Sutton,R.S.;Barto,A.G.Reinforcement Learning: An Introduction.The MIT Press,1998.
[24]Sutskever,I.;Vinyals,O.;Le,Q.V.Sequence to sequence learning with neural networks.In: Proceedings of Advances in Neural Information Processing Systems,3104–3112,2014.
[25]Graves,A.Generating sequences with recurrent neural networks.arXiv preprint arXiv:1308.0850,2013.
[26]Young,P.;Lai,A.;Hodosh,M.;Hockenmaier, J.From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.Transactions of the Association for Computational Linguistics Vol.2,67–78,2014.
[27]Lin,T.-Y.;Maire,M.;Belongie,S.;Hays,J.;Perona, P.;Ramanan,D.;Dollár,P.;Zitnick,C.L.Microsoft COCO:Common objects in context.In:Computer Vision—ECCV 2014.Fleet,D.;Pajdla,T.;Schiele,B.;Tuytelaars,T.Eds.Springer International Publishing, 740–755,2014.
[28]Papineni,K.;Roukos,S.;Ward,T.;Zhu,W.-J. BLEU:A method for automatic evaluation of machine translation.In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 311–318,2002.
[29]Lin,C.-Y.ROUGE:A package for automatic evaluation of summaries.In: Text Summarization Branches Out:Proceedings of the ACL-04 Workshop, Vol.8,2004.
[30]Kuznetsova,P.;Ordonez,V.;Berg,A.C.;Berg, T.L.;Choi,Y.Collective generation of natural image descriptions.In: Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics:Long Papers,Vol.1,359–368,2012.
[31]Vedantam,R.;Zitnick,C.L.;Parikh,D.CIDEr: Consensus-based image description evaluation.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,4566–4575,2015.
[32]Denkowski,M.;Lavie,A.Meteor universal:Language specific translation evaluation for any target language. In:Proceedings of the 9th Workshop on Statistical Machine Translation,2014.
[33]De Marneffe,M.-C.;Manning,C.D.The Stanford typed dependencies representation.In:Proceedings of the Workshop on Cross-Framework and Cross-Domain Parser Evaluation,1–8,2008.

Jun Song received his B.Sc.degree from Tianjin University,China,in 2013.He is currently a Ph.D.candidate in computer science in the Digital Media Computing and Design Lab of Zhejiang University. His research interests include machine learning, cross-media information retrieval and understanding.

Siliang Tang received his B.Sc. degree from Zhejiang University, Hangzhou,China,and Ph.D.degree from the National University of Ireland, Maynooth,Co.Kildare,Ireland.He is currently a lecturer in the College of Computer Science,Zhejiang University. His current research interests include multimedia analysis,text mining,and statistical learning.


Jun Xiao received his B.Sc.and Ph.D.degrees in computer science from Zhejiang University in 2002 and 2007,respectively.Currently he is an associate professor in the College of Computer Science,Zhejiang University. His research interests include character animation and digital entertainment technology. Fei Wu received his B.Sc.degree from Lanzhou University,China,in 1996,M.Sc.degree from the University of Macau, China, in 1999, and Ph.D.degree from Zhejiang University, Hangzhou, China, in 2002, all in computer science.He is currently a full professor in the College of Computer Science and Technology,Zhejiang University.His current research interests include multimedia retrieval,sparse representation,and machine learning.

Zhongfei(Mark)Zhang received his B.Sc.(Cum Laude)degree in electronics engineering,M.Sc.degree in information science,both from Zhejiang University, and Ph.D.degree in computer science from the University of Massachusetts at Amhers,USA.He is currently a full professor of computer science in the State University of New York(SUNY)at Binghamton,USA, where he directs the Multimedia Research Laboratory.
Open Access The articles published in this journal are distributed under the terms of the Creative Commons Attribution 4.0 International License(http:// creativecommons.org/licenses/by/4.0/), which permits unrestricted use,distribution,and reproduction in any medium,provided you give appropriate credit to the original author(s)and the source,provide a link to the Creative Commons license,and indicate if changes were made.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095. To submit a manuscript,please go to https://www. editorialmanager.com/cvmj.
© The Author(s)2016.This article is published with open access at Springerlink.com
 Computational Visual Media2016年4期
Computational Visual Media2016年4期
- Computational Visual Media的其它文章
- Texture image classification with discriminative neural networks
- Weighted average integration of sparse representation and collaborative representation for robust face recognition
- Modified filtered importance sampling for virtual spherical Gaussian lights
- A computational model of topological and geometric recovery for visual curve completion
- Computational design of iris folding patterns
- User controllable anisotropic shape distribution on 3D meshes