
基于代码自动生成技术的变电站自动化系统软件开发与实现
2016-12-07 06:00汪溢余晓明马凯张静单超
电气自动化 2016年4期
汪溢, 余晓明, 马凯, 张静, 单超
(1.广东电网有限责任公司电力科学研究院,广东 广州 510080; 2国电南瑞科技股份有限公司,江苏 南京 211106)
基于代码自动生成技术的变电站自动化系统软件开发与实现
汪溢1, 余晓明2, 马凯1, 张静2, 单超2
(1.广东电网有限责任公司电力科学研究院,广东 广州 510080; 2国电南瑞科技股份有限公司,江苏 南京 211106)
随着变电站自动化及其建设水平的日益提高,软件中包含的模块越来越多,各对象间信息传递更加频繁,大大增加了电力系统非计算机专业人员的开发工作难度,导致软件开发周期长、开发成本居高不下且整个过程包含大量的重复劳动。立足于使电力系统非软件专业人员能够摆脱繁琐的底层编程,集中精力到电力自动化专业核心技术学习研究,基于代码自动生成技术、编译原理中的词法分析语法分析,深入研究了模型解释器和代码生成引擎,给出了基于模型驱动框架的变电站自动化系统软件的开发和实现方案,可根据需要灵活配置模型和程序模板,将系统中有规律可循、大量重复的代码自动生成,减少代码出错率,提高软件开发的效率。
变电站;代码自动生成;实时数据库;模型解释器;代码生成引擎
0 引 言
变电站自动化系统软件对变电站运行自动进行监视、控制和管理[1],它对下与站内通信网相连,将全站的信息顺利写入数据库,并根据需要将数据上送调度和控制。同时,通过友好的人机界面和强大的数据处理能力实现就地监视、控制功能[2]。软件中包含对象种类多,各对象间信息传递频繁,通讯和界面显示实时性要求高,而且其业务逻辑需要资深的电力系统专业人士才能胜任。这些专业人士一般都有十年以上电力行业工作经验,具有高学历的专门人才,难以由软件领域的专业开发人员代替。因此,要将变电站自动化系统软件开发为功能完备、易于使用的现代化软件必须克服许多困难,除了大型软件开发中常见的一些困难之外, 还必须解决电力系统非计算机专业人士编程水平不高、对现代软件开发所需了解的面向对象、开发模式等概念不熟悉的问题,以及由于业务逻辑发生变化所产生的大量的维护和开发工作。
随着电力系统的日益复杂,变电站自动化系统软件普遍采用了模块化设计思想进行系统设计,其中数据处理模块、网络通讯模块、用户界面模块以及用于模块间交互的接口是变电站自动化系统软件的核心组成部分。传统的变电站自动化软件的开发往往耗费大量的时间编写上述这些基础代码,导致软件开发周期长、开发成本居高不下且可移植性差,因此,如果能将这些基础代码采用自动生成技术[3]实现,将大大降低非软件专业人员开发工作难度,使其摆脱繁琐的底层编程,集中精力到电力自动化专业核心技术、技能的学习与研究。
1 代码自动生成技术与变电站自动化系统
1.1 概述
变电站自动化系统包含大量的配置界面、数据交互和数据转换,没有统一风格的用户界面,参数配置复杂,但是其实现又有一定的相似性,整个过程包含大量的重复劳动。
将代码自动生成技术应用到变电站自动化系统基础代码开发中,可以产生规格统一的代码,弱化业务流程的变化对软件开发的影响,减少系统的复杂程度,提高软件开发的效率[4]。
1.2 系统需求
变电站自动化系统中,大量的配置信息都存储在关系型数据库,关系型数据库在存储和管理永久性、非短暂数据方面有着广泛的应用[5],但是,由于关系型数据库系统主要存储在慢速的外部存储设备,对时限有严格要求的变电站自动化系统必须将数据库上的配置信息加载、映射到实时数据库。同时,组态工具对这些配置信息进行维护,也需要将配置信息加载到配置库,修改商用数据库后通过发送消息修改实时数据库。实时数据库和配置库中包含很多张表,这些表与数据库中的表一一对应,相当于C++的类,表中的记录对应于类的实例 , 相同类型的记录放在同一个表中,主要有厂站类、间隔类、一次设备类、二次设备类、遥测类、遥信类、 电度类、计算规则类、控制操作类、操作规则类、系统参数类、节点信息类、端口参数类等。实时数据库和配置库采用面向对象方法[6]定义这些类的属性和操作方法,而且在初始化和保存数据时需要对每张表、每个字段进行数据类型检查和数据转换。数据流如图1所示。

图1 数据流
这些表的类定义、数据的组织方式都有一定的规律可循,而且一些操作无论何种业务逻辑都会用到如新增、删除、修改、查询等。

图2 消息/服务总线
为方便应用系统间的数据交换, 变电站自动化系统设计了服务/消息总线,总线提供协议转换、消息路由、消息过滤和数据适配等功能,如图2所示。
消息/服务总线的承载体为报文,由两部分组成:报文头和报文体。报文头主要包括每类报文的公共信息,从报文头的信息分析出该报文完成的功能。报文头包含报文体的长度、消息类型、事件标识、源节点、源进程、目标节点、目标进程等信息。报文头是每个消息发送必须带的公共信息,报文体视各个应用而定。报文体是发送的具体数据信息。报文体针对不同应用的功能定义各自的数据体,应用系统在发送报文前需要对数据体进行序列化,接收报文后再通过反序列化获得请求的结果,这样每种应用都需要提供报文体的序列化和反序列化接口,这些接口应用的场景虽不一样,但是功能上都是对输入参数进行序列化或反序列化,将结果作为输出参数传出。
针对上述特征,文中提出了一个基于C++的代码自动生成的实现方案,该方案分析了变电站自动化系统软件体系结构,抽象出模型和程序模板两部分,软件开发人员通过编辑模型,可选择任一模型和与之匹配的模板,在配置了项目信息后,可为指定项目生产代码。该代码生成器具有良好的可扩展性和灵活性,可根据模块需要新增模型和模板,将系统中有规律可循、大量重复的代码利用工具来自动生成。
2 总体设计
文中所描述的代码自动生成方案采用OMG组织提出的模型驱动框架(Model Driven Architecture)[7]进行设计,将模型作为代码生成器的输入,按照指定的程序模板和映射规则,将具体的业务模型映射成应用程序源代码,如图3所示。
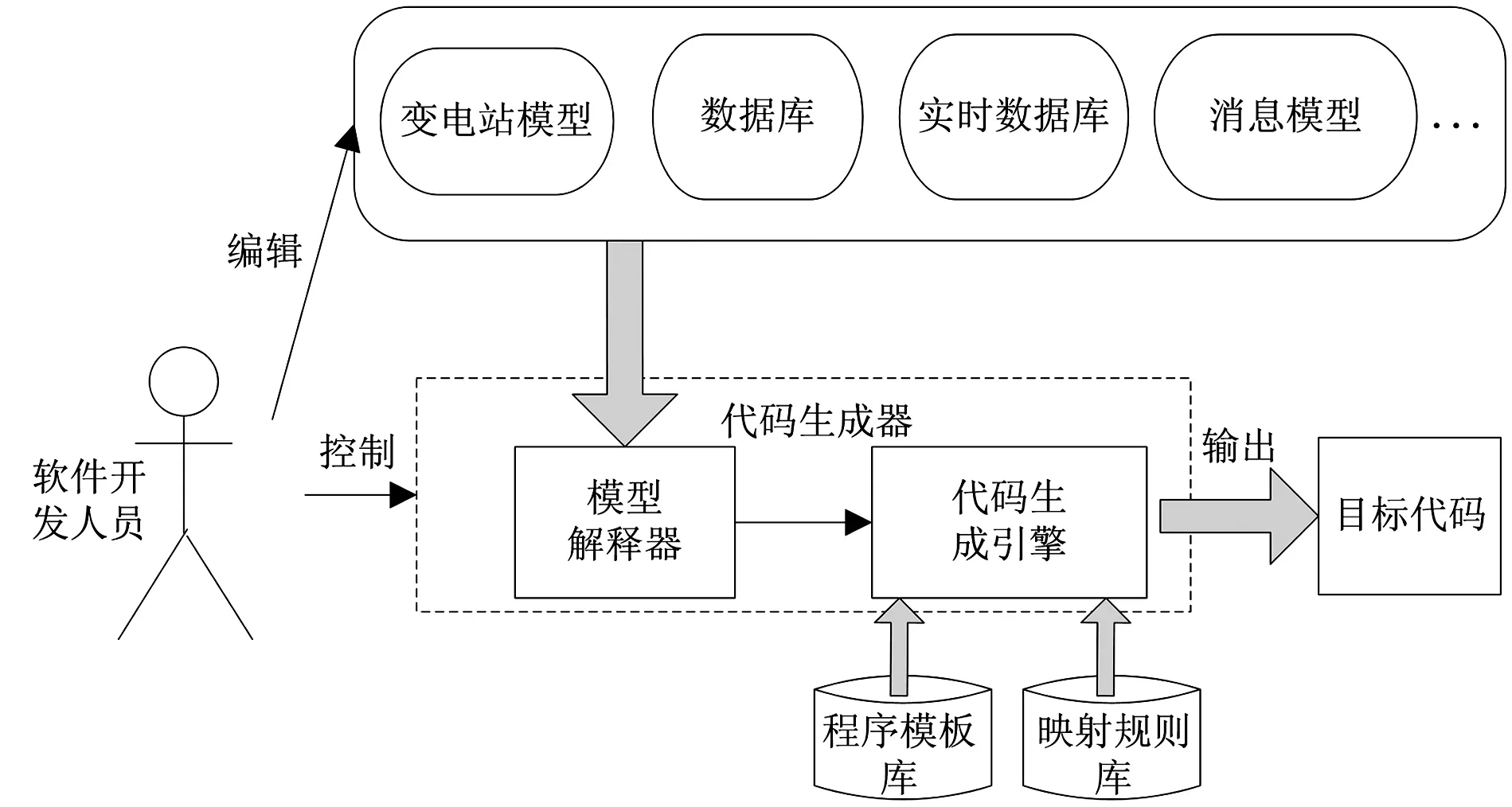
图3 代码自动生成结构
3 代码自动生成的实现方案
本文基于代码自动生成技术,并将编译原理的相关概念引入到系统中,提出一种结合词法分析、语法分析等技术的代码自动生成的实现方案,其中语法分析、词法分析的作用是从输入中分析出其结构并将其转换为在后续处理过程中更易于访问的数据结构,并检测可能存在的语法错误[8]。
该方案包括两个核心部分,即模型解释器和代码生成引擎,分别完成数据准备和代码生成工作。
3.1 模型解释器
要实现将一个模型通过代码生成器映射为所需要的代码,首先需要将某个具体业务模型转换为代码生成器可以读取的文件,然后代码生成器从这些输入文件中提取模型中的信息并生成系统应用代码[9]。模型解释器的作用就是将模型转换为代码生成器可读取的文件,并从文件中提取元数据加载到内存中以待访问。
为了便于代码生成引擎读取元数据,本文设计一组类,包括模型信息类和对象类(包含属性和方法)来共同描述业务模型中的元数据。当第一次读取模型文件时,元数据被加载到这组类中,这组类的关联关系如图4所示。
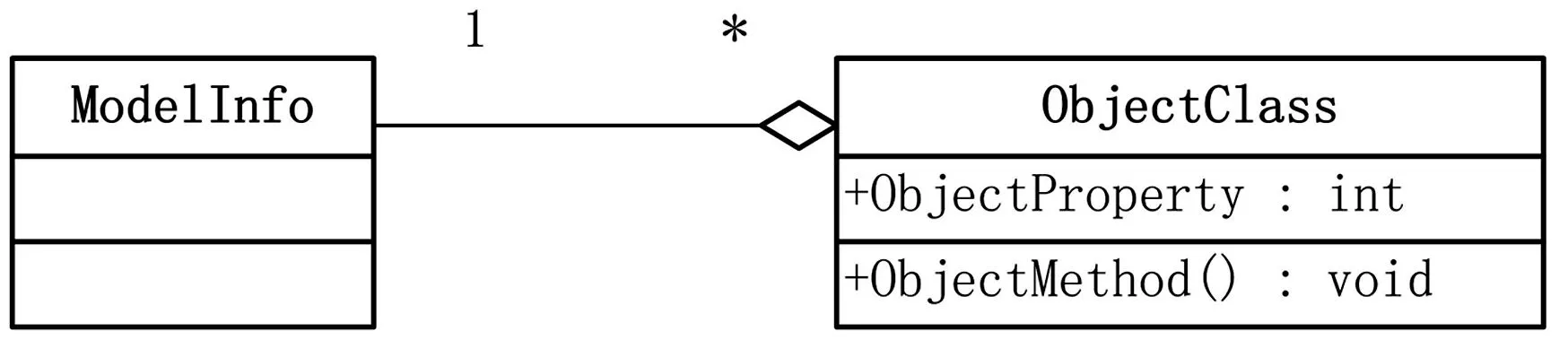
图4 模型中元数据的类描述图
以变电站自动化系统中实时数据库和配置库数据结构和接口的代码自动生成为例说明元数据的提取过程和表示方式。实时数据库、配置库所用到的元数据应包含所有的数据信息及数据的组织方式,本文采用从关系数据库提取元数据,表是关系数据库的基本组成部分,表由字段组成,关系数据库中每张表抽象为图4的ObjectClass,表的字段为ObjectProperty,表中每条记录为ObjectClass的对象。ModelInfo中包含了关系数据中所有需要读入配置库和实时数据库的表和字段信息,ModelInfo中数据信息及组织方式如图4所示,每条CField记录了数据库每张表的字段信息和数据类型、与之对应的配置库和实时库每个类的属性和数据类型。

图5 ModelInfo数据信息及组织方式
以图5的厂站信息表为例,生成给实时数据库用的元数据类为CRtSite,生成给配置库用的元数据为CCfgSite。
3.2 代码生成引擎
代码生成引擎是一个独立的应用程序,以模型解释器提取的元数据为基础,根据不同的代码模板和映射规则生成代码。代码生成引擎生成业务模型目标代码的过程主要包含以下步骤:
Step1. 初始化。初始化过程定义一个数组缓存从模型提取的所有对象类信息,并指定业务逻辑需要生成的头文件和源程序文件的名称。数组的对象属性根据不同的业务逻辑填写,以自动生成实时数据库和配置库数据结构及转换接口为例,填写的数组属性包括数据表名称、配置结构类名称、实时结构类名称、Field数组名称、Field数组指针和Field数量。报文的序列化和反序列化的数组属性则只需要填写对象类名称及属性。
Step2. 检查数据类型、参数设置是否合法。
Step3. 生成中间代码。
Step4. 生成基本变量、函数。
Step5.生成代码,保存到指定的头文件和源程序文件。
4 应用实例
本文设计的代码生成方案已经应用于变电站自动化系统软件开发,实现了实时数据库和配置库数据结构、数据转换接口代码的自动生成,实现了报文序列化、反序列化接口代码的自动生成,省去了大量重复代码的编写,大大提高了软件开发的效率,减少了因业务需要增加字段产生的大批量修改相关类定义和接口。表1列出了自动生成的文件及文件中的主要数据结构或接口。
5 结束语
本文提出的基于模型驱动框架的代码自动生成方案已经得到全面实现,生成的代码可以直接在Windows、Unix、Linux平台下进行编译和执行。代码的自动生成,替代了程序员大量重复性工作,提高了代码的生成效率,减少了代码出错率,提高了变电站自动化系统的健壮性和可维护性。

表1 自动生成的文件及数据结构、接口
[1] 赖明江,耿英兰,张国纲,等. 变电站自动化系统中实时数据库的研究[J].继电器,2006,34(2):66-69.
[2] 傅蕾,胡敏强. 变电站监控软件系统中内存数据库的研究[J].电力自动化设备, 2002,22(10): 21-23.
[3] 杨芙清,朱冰,梅宏. 软件复用[J]. 软件学报, 1995,6(9): 525-533.[4] 丁亮,许舒人. 基于SSH框架的java代码自动生成[J].计算机系统应用, 2014,23(9): 72-77.
[5] 崔江峰,王冬青,刘沛,等. 实时数据库在变电站自动化系统中的应用[J]. 继电器, 2004,32(12): 47-50.
[6] 仝庆贻,颜钢锋. 面向对象的实时数据库管理系统的研究与开发[J]. 电力系统及其自动化学报, 2001, 13(5):61-64.
[7] 张静,孔芳,杨季文. 一种基于java代码生成工具的设计与实现[J].微电子学与计算机, 2007,24(6): 222-224.
[8] London K C著.编译原理及实践[M].冯博琴,冯岚等译.北京:机械工业出版社,2000.
[9] 赵艳平,张书杰.基于MDA的央行会计核算系统前台代码自动生成[J].计算机与信息技术,2007,15(Z1):76-79.
Software Development and Implementation of the Substation Automation System Based on Automatic Code Generation Technology
Wang Yi1, Yu Xiaoming2, Ma Kai1, Zhang Jing2, Shan Chao2
(1.Electric Power Research Institute, Guangdong Power Grid Co., Ltd.,Guangzhou Guangdong 510080, China;2. NARI Technology Co., Ltd., Nanjing Jiangsu 211106, China)
Along with increasingly improved automation and construction level of substations, software contains more and more modules and information transfer among different objects becomes more and more frequent, thus greatly increasing the difficulty of development by non-software professionals working in the electric power system and resulting in long software development cycle, high development cost and a lot of duplication of labor in the whole process. In order that these professionals may get rid of tedious basic programming and concentrate on studying core technologies in the specialty of electric power automation, based on automatic code generation technology as well as lexical analysis and syntax analysis of the compilation principle, this paper discusses in depth the model interpreter and code generation engine, and presents a software development and implementation scheme for the substation automation system based on the model-driven architecture. This scheme allows flexible configuration of models and program templates according to the need, and a large amount of regular repeated codes are generated automatically with lower code error rate and improved software development efficiency.
substation; automatic code generation; real-time database; model interpreter; code generation engine
南方电网科技项目“K-GD2014-0473变电站自动化统一化配置研究及应用”
10.3969/j.issn.1000-3886.2016.04.026
TP272/278
A
1000-3886(2016)04-0083-03
汪溢(1987-),男,湖北黄冈人,硕士,工程师,主要从事智能变电站通信及测试技术研究,以及变电站自动化新技术研究。 余晓明(1982-),通讯作者,女,福建泉州人,硕士,工程师,主要从事变电站自动化系统技术研究、电力信息分析与处理及监控系统软件开发。 马凯(1985-),男,山东济宁人,硕士,工程师,主要从事智能变电站新技术研究及测试工作。张静(1981-),男,湖北潜江人,工程师,从事变电站自动化系统、信息安全研究及应用工作。 单超(1986-),男,河南信阳人,工程师,从事变电站自动化系统研究及软件开发工作。
定稿日期: 2015-12-29
猜你喜欢
汽车电器(2022年9期)2022-11-07
铁道运输与经济(2022年3期)2022-03-17
铁道通信信号(2020年4期)2020-09-21
甘肃教育(2020年14期)2020-09-11
中国外汇(2019年11期)2019-08-27
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
网络空间安全(2016年3期)2016-06-15
