
采用CRF模型的哈萨克语信息技术术语自动抽取技术研究
2016-12-01 09:25木合亚提尼亚孜别克古力沙吾利塔里甫达吾勒阿布都哈依尔
西北师范大学学报(自然科学版) 2016年1期
木合亚提·尼亚孜别克,古力沙吾利·塔里甫,达吾勒·阿布都哈依尔
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐 830046;2.新疆大学新疆多语种信息技术实验室,新疆乌鲁木齐 830046;3.新疆医科大学中医学院,新疆乌鲁木齐 830011)
采用CRF模型的哈萨克语信息技术术语自动抽取技术研究
木合亚提·尼亚孜别克1,2,古力沙吾利·塔里甫3,达吾勒·阿布都哈依尔1,2
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐 830046;2.新疆大学新疆多语种信息技术实验室,新疆乌鲁木齐 830046;3.新疆医科大学中医学院,新疆乌鲁木齐 830011)
研究哈萨克语信息技术术语自动识别方法.采用基于条件随机场(CRF)的方法,针对哈萨克语信息技术术语的组成形式、定界规则等术语自动识别标注问题,结合哈萨克语本身词性、词边界、术语类别标注的特征,分析不同特征组合对术语识别的影响,并探讨最有效的组合.结果表明,CRF模型正确识别率为83.08%,召回率为80.13%,F值为80.57%.
哈萨克语;信息技术;术语抽取;条件随机场

随着哈萨克语信息技术的日益普及,新闻、出版和语言研究领域里哈萨克语信息技术术语越来越受到重视,同时,术语识别在在线翻译、搜索引擎等信息技术研究热点领域也起着重要作用.
目前常见的术语抽取方法有3大类:① 基于规则的方法;② 基于统计的方法;③ 规则方法与统计方法相结合的混合策略技术.国外开展术语研究比较早,20世纪80年代有Choueka等[2]的研究;Maynard等[3]研究了医学领域的术语抽取,计算了术语上下文不同部分的相对重要程度和术语与上下文的相似性;Nakagaw等[4]提出了一种新的参数GM/FGM及其计算公式.在国内,张锋等通过计算字串的互信息得到候选术语[5];刘豹等应用基于统计和规则相结合的方法研究科技术语自动抽取[6];贾美英等使用条件随机场的方法分别在军事情报领域和汽车领域进行术语抽取实验,结果令人满意[7-8].文中在以上研究基础上,选择适合哈萨克语言特点的方法,对哈萨克语信息技术术语进行识别.
1 哈萨克语信息技术术语
1.1 信息技术术语概述
文中分析哈萨克语信息技术术语的特点,借助已有的研究成果,制定哈萨克语信息技术术语标准,认为只要符合标注标准的都是哈萨克语信息技术术语[9-10].标注标准如下:


1.2 语料库的选择
目前没有标注好的哈萨克语信息技术标准语料,要求人工标注.文中从《汉哈英俄信息与计算技术名词术语词典》[11]中抽取和筛选2 646个哈萨克语信息技术术语进行学习和分析,统计结果显示,简单术语占18.37%,由2个词组成的术语占68.03%,由3个词组成的术语占10.88%,由4,5,6个词组成的术语分别占1.36%,0.52%,0.34%,由7个及以上词组成的复杂术语占0.5%.
以来自“天山网”、“广播网站”、“哈萨克软件网”等网站的哈萨克文新闻,中小学信息技术教材的文本信息作为文中系统的训练和测试语料.
2 训练语料库的建立
哈萨克语信息技术术语抽取系统利用有监督的统计机器学习方法.文中设计出基于规则的哈萨克语信息技术术语抽取系统,并以此系统的术语抽取结果作为训练语料.
2.1 哈萨克语信息技术术语抽取规则

2.2 基于规则的哈萨克语信息技术术语抽取系统框架
图1中的原始语料是为本系统准备的从各种哈萨克文网站和中小学信息技术教材中获取的语料.原始语料是通过目前实验室使用的哈萨克语词法分析系统获得的已经单词提取、词缀提取和词性标注的熟语料.基于规则的系统中熟语料作为输入,通
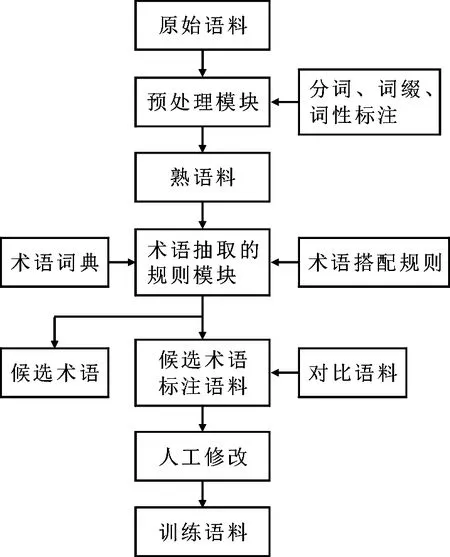
图1 系统框架Fig 1System framework
过哈萨克语信息技术术语词典和哈萨克语信息技术术语搭配规则库进行过滤,候选术语标注语料再通过人工方法修改生成训练语料.文中根据词在术语中位置的不同,为术语规定了不同的角色,B表示术语的开始,I表示术语的中间,对不能构成术语的词,一律为0.
图2和图3分别表示本系统中所使用的熟语料和训练语料.

图2 系统熟语料Fig 2Systems familiar with corpus
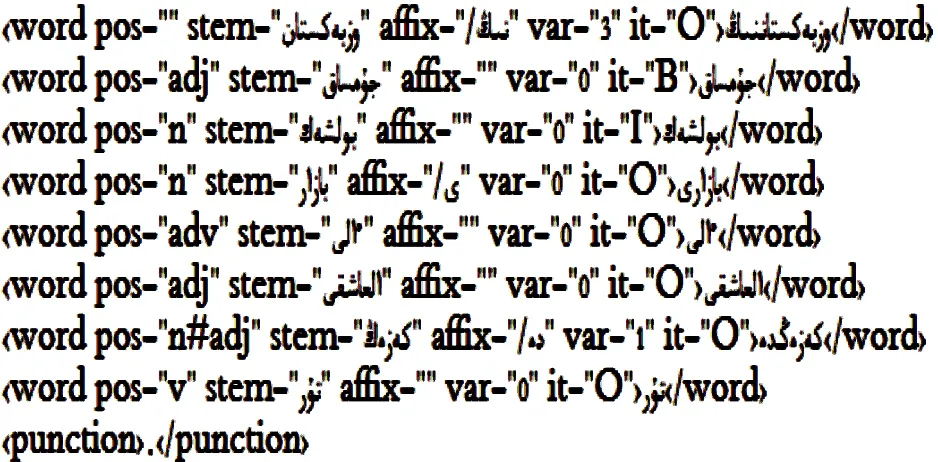
图3 系统训练语料Fig 3System training corpus
3 基于条件随机场的哈萨克语信息技术术语抽取方法
从图4可知,训练模块利用训练语料库和事前定义好的特征模板从文本中抽取特征,再利用CRF模型进行训练,便可获得每个特征的相关参数.标注哈萨克语信息技术术语时,通过特征模板和训练语料特征模板抽取特征,根据哈萨克语信息技术术语系统训练得到的参数,进行哈萨克语信息技术术语标注.
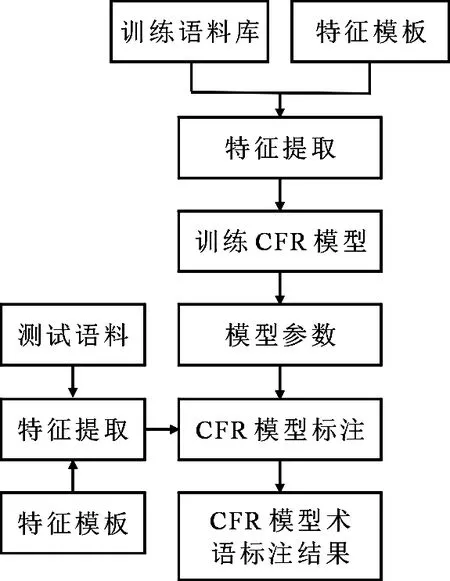
图4 抽取系统框架Fig 4Extaction system framework
3.1 特征模板选取
由于哈萨克语信息技术术语的构成具有很大的随意性,提取信息技术术语所具有的上下文语言信息,对于提高术语标注率是必要的.
在CRF模型中选择适当的特征模板非常重要[6],文中把哈萨克语信息技术术语特征模板分为原子特征模板和复合特征模板,分别为:
1)原子模板只考虑一种因素,文中所用的原子特征模版主要是词干、词缀、词性和左右词的术语标注信息,例如,CWord(当前词)、RWord(右边第一个词)、LPos(左边第一个词的词性)、CAffix(前词的后缀)、RIT(右边第1个词的it标注).
2)复合模板考虑的因素是2个或更多,简单的说,就是各个原子模板的相互组合.根据具体情况,取6个模板进行实验.具体模板参数如下:
模板1 [RRPos,RRIT,RWord,RAffix,RPos,RIT,CPos,CIT,CWord,CAffix,LLPos,LLIT,LWord,LAffix,LPos,LIT],观察特征空间的所有单词对实验结果的影响.
模板2 [CPos,CIT,CWord,CAffix,LLPos,LLIT,LWord,LAffix,LPos,LIT],观察候选词左边2个词对实验结果的影响.
模板3 [RRPos,RRIT,RWord,RAffix,RPos,RIT,CPos,CIT,CWord,CAffix],观察候选词右边2个词对实验结果的影响.
模板4 [RWord,RAffix,RPos,RIT,CPos,CIT,CWord,CAffix, LWord,LAffix,LPos,LIT],观察候选词左边和右边各1个词对实验结果的影响.
模板5 [RWord,RAffix,RPos,RIT,CPos,CIT,CWord,CAffix,LLPos,LLIT,LWord,LAffix,LPos,LIT],观察候选词左边2个词和右边1个词对实验结果的影响.
模板6 [RRPos,RRIT,RWord,RAffix,RPos,RIT,CPos,CIT,CWord,CAffix,LWord,LAffix,LPos,LIT],观察候选词左边1个词和右边2个词对实验结果的影响.
3.2 特征的选择
在条件随机场模型中常见的特征选择方法有两种.一种方法是在训练样本中选择出现次数高于一个常数N的特征,叫做频度的选择法[8]267:
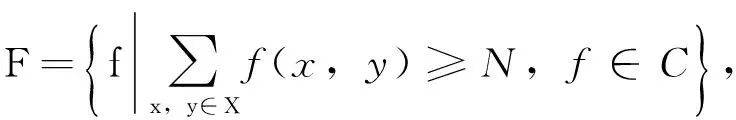
(1)
其中,C是特征空间;X是训练样本;N是一个常数.频度选择法效率高,而且实现简单,但是存在一定的冗余特征.另一种方法是增量选择法,具体思想就是如果某特征加入后能提高系统的效果,就保留,否则删除该特征.文中特征选择使用了基于频度的方法.虽然该方法不能保证得到最小特征集,但它能获得尽可能多的特征,实验表明它具有良好的性能.
4 实验结果与分析
文中采用以下几个指标:术语抽取的准确率P、召回率R、F值,计算方法为[10]495
(2)
(3)
(4)
本系统从各类哈萨克文网站和中小学信息技术教材中整理出大小为10.3 MB的语料作为训练语料进行试验,测试结果如表1所示.

表1 实验结果(%)Tab 2Demonstration
可见,基于规则方法的语料选择,语料的规模没有具体标准,对语料处理方法不同得到的词库就不同,缺乏统一的标准和处理方法.基于条件随机场方法的准确率比基于规则方法的准确率更高.
[1] 徐键.术语相似度计算方法研究[M].广州:中山大学出版社,2012.
[2] CHOUEKA Y,KLEIN T,NEUWITZ E.Automatic retrieval of frequent idiomatic and collocational expressions in a large corpus[J].JournaloftheAssociationofLiteraryandLinguisticComputing,1983,4(1):34.
[3] MAYNARD D,ANANIADOU S.Identifying contextual information for multi-word term extraction[J].Sandrini,1999:212.
[4] NAKAGAW H,MORI T,A simple but powerful automatic term extraction method[C]//ProceedingsoftheSecondInternationalWorkshoponComputationalTerminology.Taipei:Association for Computatienal Linguistics,2002:29.
[5] 张锋,许云,侯艳,等.基于互信息的中文术语抽取系统[J].计算机应用研究,2005,22(5):72.
[6] 刘豹,张桂平,蔡东风.基于统计和规则相结合的科技术语自动抽取研究[J].计算机工程与应用,2008,44(23):147.
[7] 贾美英,杨炳儒,郑德权,等.采用CRF技术的军事情报术语自动抽取研究[J].计算机工程与应用,2009,45(32):126.
[8] 李丽双,党延忠,张婧,等.基于条件随机场的汽车领域术语抽取[J].大连理工大学学报,2013,53(2):267.
[9] 赵伟.条件随机场在蒙古语词切分中的应用[D].呼和浩特:内蒙古大学,2009.
[10] 向晓雯.基于条件随机场的中文命名实体识别[D].厦门:厦门大学,2006.
[11] 哈那提·叶列杰夫,赛力克·孙哈泰.汉哈英俄信息与计算技术名词术语词典[Z].乌鲁木齐:新疆科学技术出版社,2010.
(责任编辑 惠松骐)
Research on automatic Kazakh information technology term extraction using CRF mode1
MUHEYAT Niyazbek1,2,KUNSAULE Talp3,DAWEL Abilhayer1,2
(1.College of Information Science and Engineering,Xinjiang University,Urumqi 830046,Xinjiang,China;2.Key Laboratory of Multilingual Information Technology,Xinjiang University,Urumqi 830046,Xinjiang,China;3.College of Chinese Medicine,Xinjiang Medical University,Urumqi 830011,Xinjiang,China)
This paper purpose of research on automatic Kazakh information technology term extraction,a conditional random fields based method for term extraction is introduced,which intends to be used in Kazakh information technology process.This method takes the field term extraction as an issue of sequence marking,the term distribution quantitative information technology as training feature leverages,the CRF toolkit to generate a field term character template and uses the template for field term extraction.Experimental results show that:statistics-based approach to solve Kazakh information technology term extraction is valid,test accuracy of 83.08%.
Kazakh language;information technology;term extraction;conditional random field
10.16783/j.cnki.nwnuz.2016.01.012
2014-11-03;修改稿收到日期:2015-03-29
国家自然科学基金资助项目(61462084);新疆多语种信息技术实验室开放课题资助项目(XJDX0905-2013-03 )
木合亚提·尼亚孜别克(1967—),男,新疆塔城人,副教授.主要研究方向为自然语言与信息处理.
E-mail:muheyatn@xju.edu.cn
TP 391.1
A
1001-988Ⅹ(2016)01-0053-04
猜你喜欢
通信技术(2021年12期)2022-01-25
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年3期)2015-07-18
语言与翻译(2015年1期)2015-07-18
语言与翻译(2015年1期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
