
GraphHP:一个图迭代处理的混合平台
2016-11-29 09:34:29苏静索博陈群潘魏李战怀
华东师范大学学报(自然科学版) 2016年5期
苏静,索博,陈群,潘魏,李战怀
(西北工业大学计算机学院,西安710072)
GraphHP:一个图迭代处理的混合平台
苏静,索博,陈群,潘魏,李战怀
(西北工业大学计算机学院,西安710072)
BSP(Bulk Synchronous Parallel,BSP)计算模型是建立大规模迭代式图处理分布式系统的重要基础.现有平台(如Pregel、Giraph、Hama)虽然已经实现了较高的可扩展性,但主机之间高频同步和通信负荷严重影响了并行计算的效率.为了解决这个关键性问题,本文提出了一种基于混合式模型的执行平台GraphHP(Graph Hybrid Processing).它不仅继承了以顶点为中心的BSP编程接口,而且能够显著减少同步和通信负荷.通过在图分区内部和分区之间建立混合执行模型,GraphHP实现了伪超步迭代计算,把分区内部计算从分布式同步和通信中分离出来.这种混合执行模型不需要繁重的调度算法或者以图为中心的串行算法,就能有效减少同步和通信负荷.最后,本文评估了经典的BSP应用在GraphHP平台的实现方式.实验表明它比现有的BSP实现平台效率更高.本文提出的GraphHP平台虽然是基于Hama实现的,但它很容易迁移到其他的BSP平台.
图迭代;分布式计算;BSP;GraphHP
0 引言
目前越来越多的大数据应用都聚焦于具有复杂数据依赖关系的图模型,如各种社交网络、Web图、生物基因网络等都需要利用图模型进行计算处理.图模型的计算离不开迭代,迭代的本质就是对目前系统的一系列状态进行改变,特别是在大规模数据集中运行这类算法时,就需要一种快速执行并行迭代的技术.设计和实现大规模分布式并行处理系统面临诸多挑战,它需要编程人员处理死锁、数据竞争、分布状态和通信协议等问题.现有的抽象并行编程模型如MapReduce和Dryad并不适合依赖分析,因此人们开发了以顶点为中心的并行编程平台,如Pregel、Giraph和Hama等.这些平台都基于BSP模型,其系统通过调用BSP程序中用户自定义的超步进行图计算.BSP模型相对其他模型更适合于图迭代计算,而且很容易推理图语义.但目前这些平台在进行图计算时收敛并不快,而且通信开销也较大.
为了解决上述问题,人们开始对BSP同步平台进行改进和优化,现有研究成果主要分成两类:一类的典型代表是分布式GraphLab和Giraph++.GraphLab采用异步GAS计算模型,允许用户直接读取和修改邻接点的数据.它通过锁机制保证数据一致性,调度代价比较高.Giraph++采用以图为中心的编程接口,要求用户为图分区编写复杂的调度算法.它的执行效率严重受制于用户编写的程序.第二类主要是一些零碎的BSP系统优化方案[1-4],尽管目前这些技术能够减少同步和通信负荷,但它们或者是专门用于特定图算法,具有有限的可用性,或者仅仅基于边缘的优化,并没有改变BSP执行模型低率的现状.
随着BSP平台的广泛使用,急需一种Q能解决BSP模型同步代价高和通信量大,又能保持以顶点为中心模型简洁性的通用平台.为此本文提出了一种新的分布式图计算平台GraphHP,它不仅能大幅减少同步和通信负荷,而且保留了BSP编程模型的简单性.该平台在分区内部执行伪超步迭代计算,全局同步时执行边界点的迭代计算.这种混合执行模型能有效减少同步和通信负荷,同时不需要繁重的调度开销.本文具体描述了此混合执行模型,并说明了它是如何在BSP模型上实现的.主要贡献点是
·分析了现有BSP计算平台的性能,总结了它们在实现图迭代算法时的不足;
·建立了一个混合执行模型.对比标准BSP执行模型,该混合模型不仅具有较高的并行效率,而且具有较少的全局迭代次数;
·设计和实现了混合迭代图处理平台GraphHP.GraphHP继承了以顶点为中心的BSP编程接口,但具有不同的混合执行模型.虽然它是基于Hama的实现,但可以很容易地移植到其他的BSP平台;
·比较研究了经典BSP上的算法在GraphHP的应用,证明了GraphHP比目前BSP平台在性能上有显著提升.
本文组织结构如下:第1节介绍相关工作;第2节描述BSP平台及编程接口;第3节提出混合GraphHP执行模型;第4节介绍GraphHP平台的基本架构;第5节探讨经典BSP程序在GraphHP上的应用和实验分析;第6节对本文进行总结,并概述未来研究的方向.
1 相关工作
尽管Google的Pregel有几个通用的BSP实现库,如Green BSP库[5]和BSPlib[6],但都没有提供图计算相关的应用程序编程接口(Application Programming Interface,API),而且不涉及顶点为中心的编程接口.并行平台BGL[7]和CGM[8]提供了多点接口(Multi Point Interface,MPI)上使用的图计算API,但没有提供顶点为中心的编程接口,同时也没有处理关键性的容错问题.除GraphLab之外,还有其他异步抽象平台;但这些平台并不确保可串行性,或者提供足够的从数据竞争中恢复数据的机制.GRACE[9]是建立在单台机器上的异步图处理平台,采用类似以顶点为中心的编程接口,但使用用户定义的顶点调度和消息选择机制支持异步计算.尽管这些异步平台能够加速收敛计算,但仍需要大量的调度负荷.
还有其他混合平台如Trinity[10]和Kineograph[11].Trinity在分布式内存上存储图数据,支持联机图处理,它使用类似于BSP平台的执行模型进行脱机处理.Kineograph用于存储连续变化图的分布式系统,也是以顶点为中心的计算模型,但在它上面的图挖掘算法仍然在动态图的静态快照上执行.
2 BSP平台和编程接口
由于BSP模型的可扩展性、灵活性和以顶点为中心编程的易用性,出现了很多BSP平台(如Pregel、Hama、Giraph),这些平台都适合具有依赖的图迭代计算.BSP同步模型不需要编程者指定迭代执行顺序,确保了系统中程序没有死锁和数据争用.如果给定足够的并行松弛,BSP程序的性能与异步程序相比是具有竞争性的.Hama是开源BSP的实现,编程接口主要由顶点类(Vertex class)、聚合类(Aggregator class)和组合类(Combiner class)组成.Vertex class是最重要的类,负责构建顶点的行为,并维护它们的状态.compute()(计算函数)方法使用消息迭代器检查接受到的消息,定义每个超步中活跃顶点的行为,同时sendMessage()(发送消息函数).Aggregator class是一种全局通信和检测的机制,每个顶点在超步(S)提交一个值给聚合器(aggregator),aggregator合并接收到的值,并把合并后的新值在进行超步(S+1)计算前发送给各个顶点.Aggregator class提供的典型操作如min、max和sum.Combiner class用于减少通信负荷,聚合发送给同一个顶点的多个消息为一个.这个优化要求用户在combiner()(组合函数)中指定合并规则.集群上BSP程序由一个主机(master)和多个从机(worker)组成.master不参与具体的计算,主要负责worker之间的协调.每个worker负责一个或多个分区的计算,给每一个分区启动一个BSPPeer计算进程.使用BSP平台实现某些标准的图算法(如强关联图分量、最小生成森林和图着色),尤其是许多机器学习和数据挖掘算法(如信念传播和随机优化)可能导致较低的收敛率.
3 混合执行模型
在详细描述混合模型之前,先给出一些符号表示来简化表示.
定义1(本地顶点和边界点)一个图分区内部,如果顶点v与它入边的所有顶点在同一个分区,则该顶点被称为本地顶点.否则,v至少有一个入边的顶点位于远程分区中,则被称为边界点.
定义2(本地计算和边界计算)一个本地顶点的compute()操作被称为本地计算.边界点操作被称为边界计算.
本文所提出的混合计算模型建立在传统BSP基础上,通过实现异步消息通信机制优化性能.该混合计算模型由一系列的全局迭代组成,每个全局迭代由“计算-通信-同步”三阶段组成,其中把计算分成全局计算和本地计算两部分.本地计算由一系列连续的内部迭代组成,并且在内部迭代过程中支持异步操作.本地计算完成后,要把全局计算和本地计算阶段中发送给临界顶点的消息通过网络传输给其他计算节点,接着该混合执行引擎进行全局通信和同步过程,然后开始下一次全局迭代的计算,直到算法终止.可以看出,本地计算并不需要直接与其他分区通信,边界计算需要不同分区上的远程通信.
如图1(b)所示,该混合执行模型是抽象的.如标准的BSP模型一样,混合模型需要同样的初始化迭代.在第一次初始化迭代(迭代0)时,所有的顶点都是积极活跃的(active),由用户分配初始化值,并发送消息给邻接点.从迭代1开始,重复性的调用全局阶段和本地阶段.在全局阶段,每个active的边界顶点使用之前超步中发送给它的消息作为输入,执行compute(),确保每个边界点使用邻接点最新的消息参与计算.

图1 标准和混合计算模型对比图Fig.1Standard calculation model and hybrid contrast figure
4 基本架构
尽管是混合执行模型,但本地和边界顶点的行为都在Vertex class中被同一个compute()定义.顶点之间的通信通过Vertex class中的sendMessage()传递获取.在标准的BSP平台上,写GraphHP程序涉及预先定义的Vertex class的子类,此外用户可以指定边界点是否参与本地阶段计算.在迭代时,一个边界点可能收到另外一个顶点的多个消息,这时用户通过指定combine()合并这些消息.GraphHP提供了一个额外的函数sourcecombine()(源端组合函数),合并同一个发送者发给一个顶点的所有消息,同时用户可以自定义任何需要合并的规则.GraphHP的实现并没有重新设计Hama的分布式架构、通信和同步机制,仅仅涉及轻微的系统调整,所以它的实现可以很容易推广到其他BSP平台.
GraphHP执行初始化迭代跟Hama初始化方式一样.第一次迭代后,master命令每一个worker重复地执行全局阶段和本地阶段.worker在迭代中给每一个分区分配一个线程执行全局和本地阶段.全局阶段循环,通过调用active的边界点执行compute().本地阶段迭代调用伪超步.在每一个伪超步中,线程循环通过active本地顶点和执行compute().GraphHP利用基于Hama的超步机制实现全局迭代阶段.worker首先定义是否接收者和发送者位于同一个分区:如果是,消息直接放到目的顶点的入边消息队列;否则,消息将会暂时被缓存,之后会通过Hama上的RPC(Remote Procedure Call Protocol,远程过程调用协议)传输.由于不同分区之间传输的消息会在下一个阶段处理,所以仅仅要求在每个迭代开始前传输.当一个分区完成全局阶段,它立刻进入一个本地阶段,不需要通知master去转化.
GraphHP继承了Hama的容错机制,通过设置检查点来进行容错处理.在全局或本地阶段的开始前,master通知所有worker保存每个分区的状态信息到HDFS(Hadoop Distributed File System,Hadoop的文件系统)上,包含顶点的值、边值、顶点的状态和接收到的消息队列.由于一个分区中总是频繁地执行本地计算,因此GraphHP选择在本地阶段制定多个检查点.master周期性地发送“ping”消息给worker来检测worker的健康状态,如果master没有在指定的时间收到回应,将会标记worker为不成功的、失败的(failed).当一个worker是failed时,master把图分区重新分配到健康的worker上,新的worker将从最近的检查点重新加载分区.
5 实验研究
这一部分分别评估3个算法,即最短路径、PageRank和二分图在GraphHP上的性能.使用传统BSP平台Hama和它的优化版本AM-Hama.AM-Hama是像Hama一样的执行平台,即使用异步的方式处理消息.如果消息发送给远程分区上的顶点,它通过Hama上的RPC分布式机制传输,这时消息会被下一个超步处理;否则,在内存处理,直接放到目的顶点的入边消息队列.在GraphHP中,如果应用需要的话,边界点参与本地计算,异步消息机制被激活.
5.1 实验设置
表1中给出了测试数据的细节,前5个数据集都是典型的长尾分布图,被用于评估算法性能,最后的Delaunay n24是一个Delaumay图广泛用于图分区评估和聚类算法.最大匹配是图分区和聚类的基本操作,本文使用Delaunay n24数据集评估BM算法.使用的集群是1个master和12个worker.每个机器运行环境为Ubuntu Linux(10.04版本),16 G内存,160G磁盘存储和16核AMD Opteron(TM)处理器,具有2600 MHZ的频率,通过1 Gbit以太网互联.
我们基于Hama平台实现GraphHP.默认Hama通过hash函数(hash(id)mod k)分配一个顶点给一个分区,其中id是顶点标识符,k是分区数量.很明显,hash分区结果会导致大量跨分区的边.好的分区应该最小化跨分区的边数量,减少分布式计算的通信负荷.使用图分区启发式Metis[14]可产生更好的分区.当输入图很大不能被单个机器处理时,可以采用并行版本ParMetis[15]并行多层k-way图分区,它是一种基于图粗化[16]的分区方法.本文中我们只是使用ParMetis分割测试图,分配顶点产生分区,从而评估不同分布式平台的性能.关于不同分区方法的优略问题的研究不在本文讨论的范畴之内.
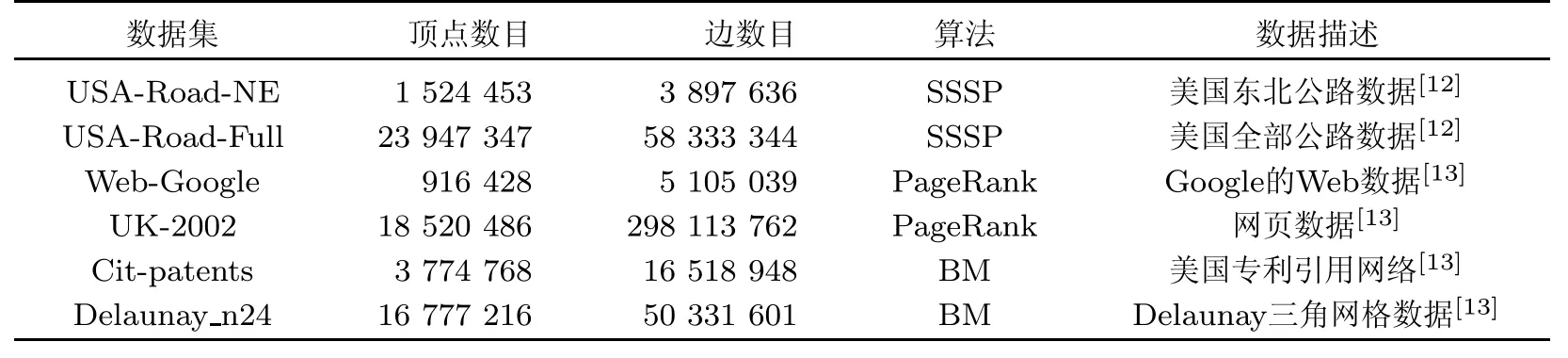
表1 数据集信息Tab.1Dataset information
5.2 最短路径
单源最短路径(Single Source Shortest Path,SSSP)[17]算法用于搜索图中源顶点到其他所有顶点的最短距离.在该算法中,初始源顶点的值是0,其他顶点的值设置为∞.初始源顶点广播自己的值给直接邻居,邻居反过来更新自己值并发送消息给它的邻居.在Hama上,一个超步仅仅传播一个顶点距离的值.由于每个顶点仅仅关心最短距离,只有收到一个较小的距离时才进行更新.
Hama、AM-Hama和GraphHP的性能采用3个度量标准:全局迭代次数;网络通信数量;执行时间.在USA-Road-Full上结果数据集很小,108个分区的详细结果在表2中给出,其中,I代表迭代次数,M代表网络消息量,T代表执行时间.与Hama相比,AM-Hama节省了较大的网络消息量,但仅仅减少了很少的迭代次数.GraphHP执行效果远远超出另外两个.
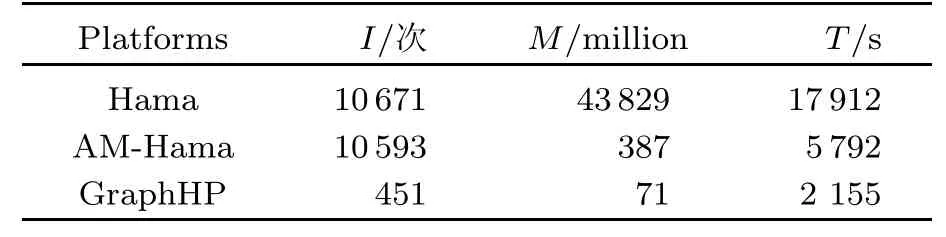
表2 SSSP在USA-Road上的评估结果Tab.2SSSP evaluation results on USA-Road-Full
5.3 PageRank
PageRank[17]属于典型的随机游走算法.利用网页相互链接关系对网页进行组织排名,确定出每个网页的重要级别,用PageRank值表示.

算法1:The Compute()Function for Incremental PageRank //Δ is the user-defined convergence tolerance; if getSuperstepCount()==0 then setValue(0); updateValue=0.15; else updateValue=sum(Msg); if updateValue>Δ then setValue(getValue()+updateValue); for u∈N(v)do sendMessage(u,updateValue/|N(v)|); voteToHalt();
算法1中给出了增量式PageRank的伪代码.在该增量式PageRank算法中,把每次接收到的消息累加到顶点当前的值,而且只是把中间更新值Δv按照计算公式计算后的值发送给邻接顶点,这样重复迭代,直到每个顶点的值收敛到一个预定义的容忍度.对于增量式算法,边界点可以参与本地阶段的计算.具体而言,GraphHP上增量式PageRank算法的初始化迭代跟经典式PageRank相同,接着进入第二次迭代的全局超步,每个分区更新边界点的PageRank值.然后执行本地阶段,参与顶点包括本地和边界顶点,通过伪超步迭代更新PageRank值,直到所有值收敛.迭代重复调用直到所有顶点不活跃,且没有消息传输,标志着顶点的PageRank值已经收敛.在迭代时,如果一个顶点发送多个消息给同一个顶点,使用用户定义的Combine()对在传输之前的所有更新值进行合并.GraphHP有效地压缩收敛计算到本地阶段中一个分区内部,减少了全局同步和通信的频率.
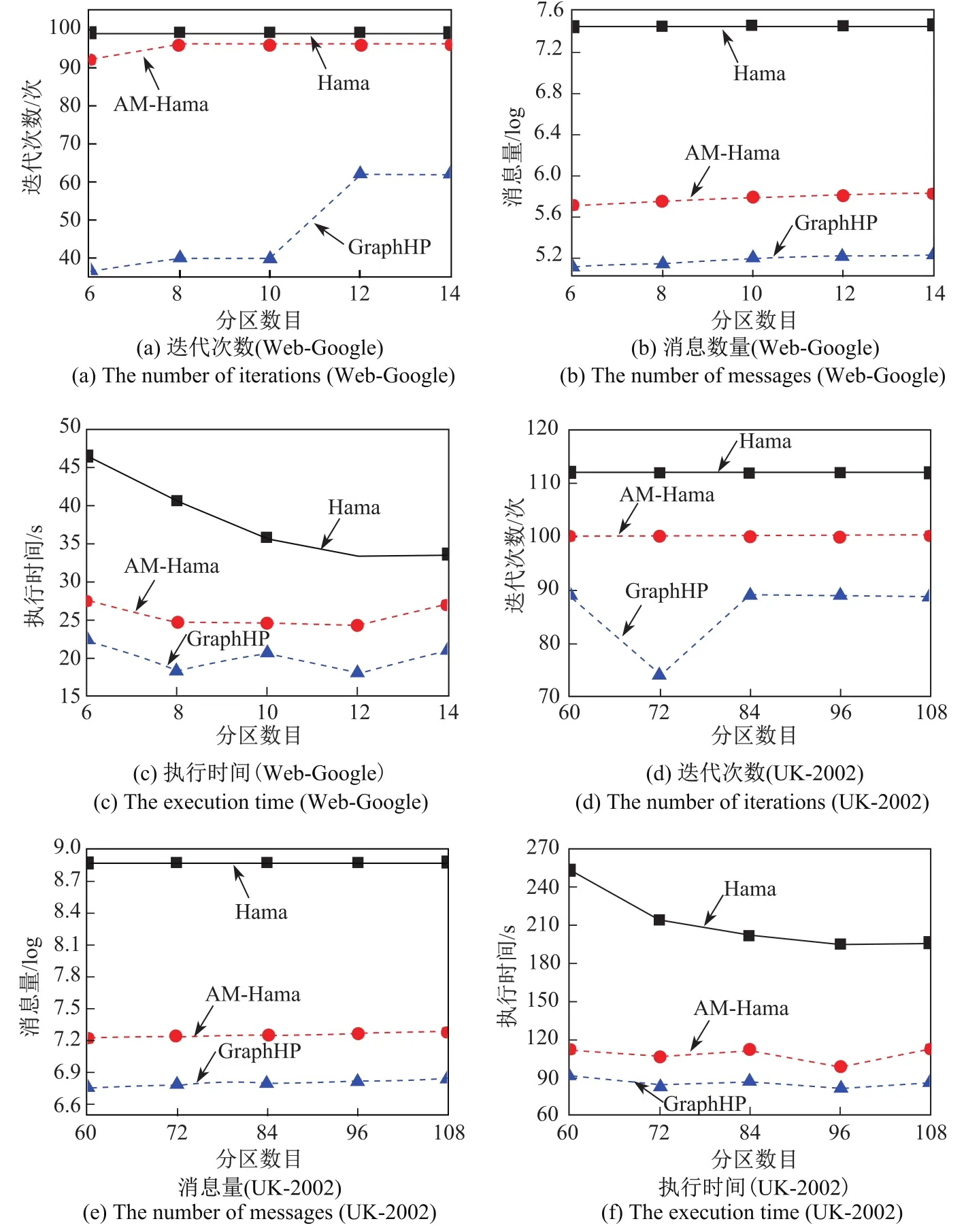
图2 PageRank的可扩展性评估Fig.2Scalability evaluation of PageRank
图2中分析了在Web-Google和UK-2002两个数据集上,随着同一数据分区数目的增加,系统的性能变化规律,收敛误差值Δ设置为1 E-5.两个数据集的最大分区数目分别设置为14和108.因为进一步增加分区数目并不能提高并行性能,同时由于3个系统的通信消息量相差较大,所以图中的消息量均取以10为底的对数(log)来表示.实验结果表明,GraphHP系统在迭代次数、通信消息量和执行时间这3个方面都要明显优于Hama和AM-Hama.虽然异步消息传递机制在两个数据集上均能有效减少全局迭代次数和通信消息量,使得AM-Hama的性能相比Hama具有一定的优势,但是根据实验结果,GraphHP系统的性能比AM-Hama还要好,说明GraphHP系统采用的混合计算模型能进一步减少全局迭代次数和通信消息量,能有效减少全局分布式的通信和同步代价.分析上图的实验结果,可以发现随着分区数目的增加,GraphHP系统的迭代次数和通信消息量只是稍有增长.因此,GraphHP系统具有良好的可扩展性.
5.4 二分图匹配
二分图[18]由两类不同的顶点集合组成,它们之间仅仅有连接不同集合的边存在.二分图匹配由没有共同端点的边子集组成.二分图匹配问题(Bipartite Matching,BM)是找到最大匹配,添加任何边都可能导致至少两条边共享一个端点.算法要求顶点在不同阶段处理不同类型的消息.由于GraphHP是异步执行模型,要求为握手机制建立左右端顶点的匹配.在算法实现中左端顶点有两种状态:不相配的(unmatched)和相配的(matched).右边顶点有3种状态:不准许(ungranted);准许(granted);matched.ungranted状态指右端顶点没有准许(grant)该匹配的请求.granted状态指右端顶点已经grant一个匹配的请求,发送grant消息,但是没有收到接受(accept)消息.granted状态中的右边顶点不能grant任何新的匹配请求,但是发送拒绝(deny)消息给每个需求者(requester).表3是二分图匹配在2个数据集上的评估结果,即Cit-patent和Delaunay n24,分别分为18个和48个分区.在Cit-patent上,Hama只要求20+次迭代,GraphHP减少了3倍的迭代次数,只需要7次.同时执行时间从原本需要42 s减少到13 s.与Hama相比,AM-Hama能够减少通信负荷,但仅仅减少了少量的迭代次数.从结果可以看到,GraphHP在每个指标上超出AM-Hama较大的量.
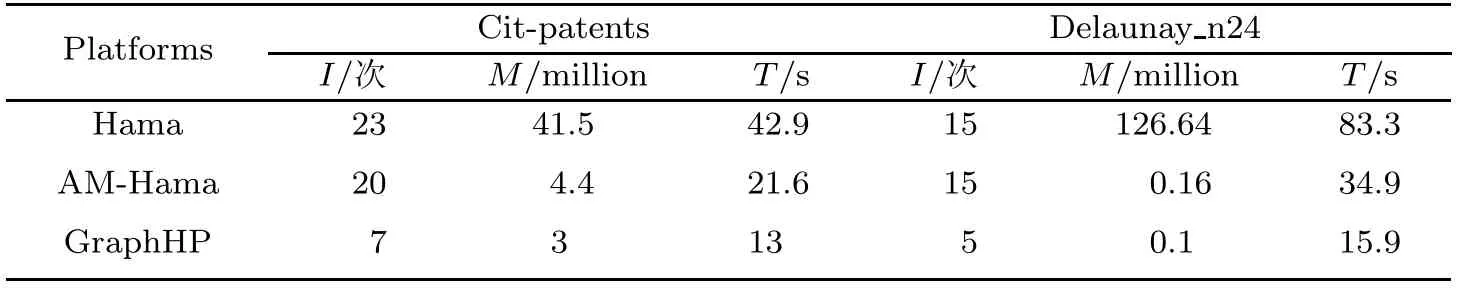
表3 BM评估结果Tab.3BM evaluation results
6 总结和未来工作
目前在BSP平台上实现大规模复杂图迭代算法仍具有较大挑战,因为同步迭代本身具有等待和通信成本.本文中提出了一种新的图计算混合执行模型,通过在每个全局迭代中加入一系列基于本地迭代的伪超步,优化同步等待和通信成本,并进一步基于Hama建立了GraphHP混合平台,证明了该模型在BSP中具有可实现性.
未来的工作将集中在多个方面,图中顶点由于在伪超步迭代过程中没有和其他分区的顶点通信,在后面的全局迭代中会同时收到多个阶段的消息,导致顶点在全局阶段消耗过多计算时间.因此如何在加速伪超步迭代的同时不牺牲以顶点为中心编程的统一性成为一项有趣的研究.另一方面,负载均衡技术对BSP的高效处理也非常重要.现有的BSP负载均衡技术[4,19]都是标准的执行引擎,因此另一个研究方向就是为GraphHP设计一个有效的负载均衡方法.
[1]SALIHOGLU S,WIDOM J.Optimizing graph algorithms on pregel-like systems[J].Proceedings of the VLDB Endowment,2014,7(7):577-588.
[2]SALIHOGLUS,WIDOMJ.GPS:Agraphprocessing system[C]//Proceedings ofthe25thInternational Conference on Scientific and Statistical Database Management.ACM,2013,Article No 22,doi: 10.1145/2484838.2484843.
[3]BAO N T,SUZUMURA T.Towards highly scalable pregel-based graph processing platform with x10 [C]//Proceedings of the 22nd International Conference on World Wide Web.ACM,2013:501-508.
[4]CHEN R S,YANG M,WENG X T,et al.Improving large graph processing on partitioned graphs in the cloud[C]//Proceedings of the 3rd ACM Symposium on Cloud Computing.ACM,2012,Article No 3,doi: 10.1145/2391229.2391232.
[5]GOUDREAU M W,LANG K,RAO S B,et al.Portable and efficient parallel computing using the bsp model [J].Computers IEEE Transactions on,1999,48(7):670-689.
[6]HILL J M D,MCCOL B,STEFANESCU D C,et al.BSPlib:The BSP programming library[J].Parallel Computing,1998,24(14):1947-1980.
[7]GREGOR D,LUMSDAINE A.The Parallel BGL:A generic library for distributed graph computations [C]//Proceedings of the Parallel Object-Oriented Scientific Computing(POOSC).2005:1-18.
[8]CHAN A,DEHNE F.CGMGRAPH/CGMLIB:Implementing and testing CGM graph algorithms on PC clusters and shared memory machines[J].Lecture Notes in Computer Science,2003,2840:117-125.
[9]WANGG Z,XIE W L,DEMERS A,et al.Asynchronous large-scale graph processing made easy [C]//Proceedings of the 6th Biennial Conference on Innovative Data Systems Research(CIDR).2013:58-70.
[10]SHAO B,WANG H,LI Y.Trinity:A distributed graph engine on a memory cloud[C]//Proceedings of the ACM-SIGMOD International Conference on Management of Data.ACM,2013:505-516.
[11]CHENG R,HONG J,KYROLA A,et al.Kineograph:Taking the pulse of a fast-changing and connected world [C]//Proceedings of the 7th ACM European Conference on Computer Systems.ACM,2012:85-98.
[12]DEMETRESCU C.USA road network[EB/OL].(2005-10-12)[2016-04-01].http://www.dis.uniroma1.it/ challenge9/download.shtml.
[13]DAVIST.TheUniversityofFloridasparsematrixcollection[EB/OL].(2011-10-13)[2016-04-01]. http://www.cise.ufl.edu/research/sparse/matrices/.
[14]KARYPIS G,KUMAR V.A fast and high quality multilevel scheme for partitioning irregular graphs[J].SIAM J Sci Comput,1998,20(1):359-392.
[15]KARYPIS G,KUMAR V.A coarse-grain parallel formulation of multilevel k-way graph partitioning algorithm [C]//Proceedings of the 8th SIAM Conference on Parallel Processing for Scientific Computing.1997:1-12.
[16]TIAN Y Y,BALMIN A,CORSTEN S A,et al.From“think like a vertex”to“think like a graph”[J].Proceedings of the VLDB Endowment,2013,7(3):193-204.
[17]CHERKASSKY B V,GOLDBERG A V,RADZIK T.Shortest paths algorithms:Theory and experimental evaluation[J].Mathematical Programming,1996,73(2):129-174.
[18]ANDERSON T,OWICKI S,SAXE J,et al.High-speed switch scheduling for local-area networks[J].ACM Sigplan Notices,1993,11(4):319-352.
[19]KHAYYAT Z,AWARA K,ALONAZI A,et al.Mizan:A system for dynamic load balancing in large-scale graph processing[C]//Proceedings of the 8th ACM European Conference on Computer Systems.ACM,2013:169-182.
(责任编辑:李艺)
GraphHP:A hybrid platform for iterative graph processing
SU Jing,SUO Bo,CHEN Qun,PAN Wei,LI Zhan-huai
(School of Computer,Northwestern Polytechnical University,Xi’an,710072,China)
BSP(Bulk Synchronous Parallel)computing model is an important foundation for the establishment of a large-scale iterative graph processing distributed system. Existing platforms(e.g.,Pregel,Giraph,and Hama)have achieved a high scalability, but the high frequency synchronization and communication load between the hosts have seriously affected the efficiency of parallel computing.In order to solve this key problem, this paper proposes a hybrid model based on GraphHP(Graph Hybrid Processing).It not only inherits the BSP programming interface with the vertex as the center,but also can significantly reduce the synchronization and communication load.By establishing the hybrid execution model between the interior and the interval partition of the graph, the GraphHP realizes the pseudo super step iteration calculation,and separates the internal computation from the distributed synchronization and communication.This hybrid execution model does not need heavy scheduling algorithm or the serial algorithmcan effectively reduce the synchronization and communication load.Finally,this paper evaluates the implementation of the classic BSP application in the GraphHP platform,and the experiment shows that it is more efficient than the existing BSP platform.Although the GraphHP platform proposed in this paper is based on Hama,it is easy to migrate to other BSP platforms.
graph iterative;distributed computation;BSP;GraphHP
TP311
A
10.3969/j.issn.1000-5641.2016.05.013
1000-5641(2016)05-0112-09
2016-05
国家973计划项目(2012CB316203);国家863计划项目(2015AA015307);国家自然科学基金(61332006,61472321,61502390).
苏静,女,博士研究生,研究方向为大数据处理技术.E-mail:jinjin-su@163.com.
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
测绘学报(2021年11期)2021-12-09 03:13:12
中等数学(2021年9期)2021-11-22 08:06:58
激光技术(2021年5期)2021-08-17 03:36:02
山东科学(2018年6期)2018-12-20 11:08:58
金桥(2018年4期)2018-09-26 02:24:54
中国卫生(2014年5期)2014-11-10 02:11:26
电脑与电信(2014年6期)2014-03-22 13:21:06
时代农机(2010年11期)2010-01-15 13:53:52
