
基于Map/Reduce的分布“数据排序算法分析
2016-11-29 09:34:29余晟隽宫学庆祝君钱卫宁
华东师范大学学报(自然科学版) 2016年5期
余晟隽,宫学庆,祝君,钱卫宁
(华东师范大学数据科学与工程研究院,上海200062)
基于Map/Reduce的分布“数据排序算法分析
余晟隽,宫学庆,祝君,钱卫宁
(华东师范大学数据科学与工程研究院,上海200062)
为了解决大规模数据的存储与计算,近年来分布式系统得到了大量的应用.如何在分布式系统中对大规模数据集进行排序是影响许多应用性能的基础问题,其中不仅涉及每个节点上排序算法的选择,更重要的是设计协调各节点的分布式算法.本文总结了分布式系统中常用的分布式排序算法,对每种算法的执行流程、代价模型和适用场景进行了分析,并通过实验对分析结果进行了验证.本文的工作可以帮助开发人员选择和优化分布式环境下大规模数据排序的算法.
分布式系统;排序算法;代价模型
0 引言
排序是计算机科学中的基础问题,传统的排序算法研究多关注于集中式环境下算法的性能、资源消耗和稳定性[1].近年来,在很多领域中数据的规模快速增长,已经很难在集中式环境中进行存储和处理,Hadoop等分布式系统[2]逐渐成为大规模数据处理的主流平台.在分布式环境中对大规模数据进行排序处理时,不仅需要考虑单节点上排序算法的选择,还需要考虑分布式系统的架构、数据分布策略和分布式计算模型等因素的影响.在分布式系统中如何提高大规模数据排序处理的性能是一个值得研究的问题.
本文关注于分布式系统中大规模数据排序算法的性能分析问题,提出了单节点排序(Single Node Sort,SNS)、多节点归并排序(Multiple Node Merge Sort,MNMS)和多节点分区排序(Multiple Partition Sort,MPS)3种排序算法.针对每种算法策略,将算法的执行过程细分为磁盘I/O(Input/Output,I/O)、网络I/O和排序计算等多个阶段,给出了算法的代价模型,并讨论了数据分布和数据分片大小等因素对算法的影响.在实验分析中,我们采用Map/Reduce计算模型[3]分别实现了3种排序算法,并在Sorting Benchmark[4]的数据集上验证了分析的正确性.本文的工作能够帮助开发人员在分布式环境下选择和优化排序算法.
本文后续内容组织如下:第1节对排序相关的研究工作进行综述;第2节对分布式场景中影响排序算法性能的因素进行分析;第3节对3种排序算法进行详细的介绍和分析;第4节是对3种排序算法的实验分析;第5节给出不同算法适用场景的结论.
1 相关工作
分布式系统快速发展,近年来基于分布式系统的应用相继出现.Facebook[5]基于Hadoop平台构建了一个实时系统来完成其新消息推送,为开发者提供数据分析工具、统计内部软硬件状态等需求.Twitter[6]使用Hadoop平台,帮助公司能够更快地分析和处理数据.对数据进行排序在这样的系统中是常见的操作.
分布式环境,数据集通常是按特定的策略被划分为多个分片,分布存储于不同的节点中,每个节点上只保存整个数据集的一部分.为了对整个数据集进行排序,人们需要编写分布式算法来协调多个节点共同完成排序任务.Jim Grey发起的Sort Benchmark推动了分布式环境中大规模数据排序问题的研究,处理能力已经有了非常大的进步.2009年,Yahoo公司[7]使用Map/Reduce计算模型对大规模数据集进行排序,在3 452个节点的集群上达到了0.578 TB/min的处理能力;到了2015年,阿里巴巴集团实现的Fuxi Sort系统[8],采用Map/Sort模型在3 377个节点的集群上达到了15.9 TB/min的数据排序能力.对于分布式排序算法的分析能够帮助开发人员在分布式环境下选择和优化排序算法.
以上的工作,或是作为排序操作的调用者,或是基于特定的场景提供快速有效的排序算法.本文提出了3种排序算法,针对每种算法策略,分析其执行代价,讨论了在不同场景下排序算法的优劣情况.
2 算法性能影响因素
在分布式系统中,排序算法效率不仅仅取决于内存排序算法的实现,系统中其他因素对排序算法的效率也起着至关重要的作用.
2.1 并行程度
这里的并行程度主要指两个方面:一方面是计算节点是否需要从存储节点获取到所有的数据分片才可以开始进行排序操作;另一方面是是否可以有多个计算节点协同进行排序操作.当节点需要获取到所有的数据分片才可以进行计算时,往往会伴随大量的网络等待时间,这样显然会降低排序的性能.而多个节点的协同计算往往需要有一个主控节点来负责整体的调度,可能会出现负载不均等问题.
2.2 待排序数据集的分布
当需要多个节点共同完成本次排序操作时,往往需要对数据按照一定的规则来重新划分.如果事先无法知晓待排序数据分布,一般需要通过采样来获取数据的分布,并以此作为划分任务的依据.划分策略是否能均匀划分数据对排序效率的影响主要体现在两个方面:首先,合理的划分可以使得各个节点之间的运算负载大致相同,不会出现大量数据被分配至同一节点,使得少数节点负载过高的情况;其次,可以通过改变数据划分的策略来减少数据在节点间的传输量,从而起到提升效率的作用.如果在排序之前就已经知晓待排序的数据范围,以及待排序数据的分布,那么就可以对数据进行更加合理的划分以提升排序的效率.
2.3 副本使用
如前所述,分布式系统常常通过冗余存储数据分片的方式来保证系统的可靠性.在多个节点参与运算的情况下,计算的过程中可以读取数据分片副本的形式来减少网络的传输,以此来优化排序的性能.
考虑如下场景,数据分片di的主副本存储在节点N1中,di的第二副本存储在节点N2中.当节点N2计算需要使用到数据分片di时,如果不能使用副本,则需要到N1节点中获取数据分片di;但是如果可以使用副本,则仅需要在本地读取数据分片di的副本即可.通过这样的方式来减少网络间的传输,以此来提升效率.
2.4 数据分片大小
在分布式场景下,如果设置较大的数据分片大小,那么在读取数据时,以最小化磁盘寻道时间的代价,来提升系统的性能.同时数据在网络中传输时,能够最小化网络建立连接的代价,帮助进一步提升系统性能.但是如果数据分片的大小设置得过大,又会导致单个子任务需要处理的任务过多,进而降低系统的性能.
2.5 硬件配置
硬件配置主要分为节点间的网络配置和节点内的硬件配置.节点间的网络配置方面,如今,机房普遍能够配置千兆交换机,且PC(Personal Computer,个人计算机)也能够配置千兆网卡.在千兆网的环境下,极限带宽为125 M/s.当网络传输速度成为瓶颈时,可以使用更高性能的硬件来提升性能,如万兆网、InfiniBand等.节点内的硬件配置主要指的是节点计算机的体系结构,例如CPU(Central Processing Unit,中央处理器)架构中使用CMP(Chip Multiprocessors,单片多核架构)、SMP(Symmetrical Multi-Processing,对称多处理架构)等,通过线程的并行,使得同一时间内,节点能够进行更多的运算.此外还有SSD(Solid State Drives,固态硬盘)等的应用,由于没有了传统磁盘寻道时间的消耗,可以大大提升系统随机读写的性能.
3 分布式排序算法
考虑分布式系统中的一个典型场景:有待排序数据集被按照一定的划分策略分成了A、B、C、D 4个数据分片,设置副本个数为3,冗余地存储在具有m个存储节点的分布式存储系统中,其中A′、B′、C′、D′分别表示各分片的数据副本.为了尽可能详尽、全面地描述排序算法在分布式环境中的代价,我们定义以下符号来表示排序算法的各个子操作的代价(表1).

表1 符号定义Tab.1Symbol definition
3.1 单节点排序(SNS)
假设数据存储在多个节点中,但是负责计算的节点之间没有并行计算的能力,只有当前被连接的节点能够提供计算并对对客户端提供服务.在这样的场景下对进行数据排序,流程的主要步骤如图1所示,各节点将数据读入内存,并通过网络传输至排序的节点,在该节点上进行排序.
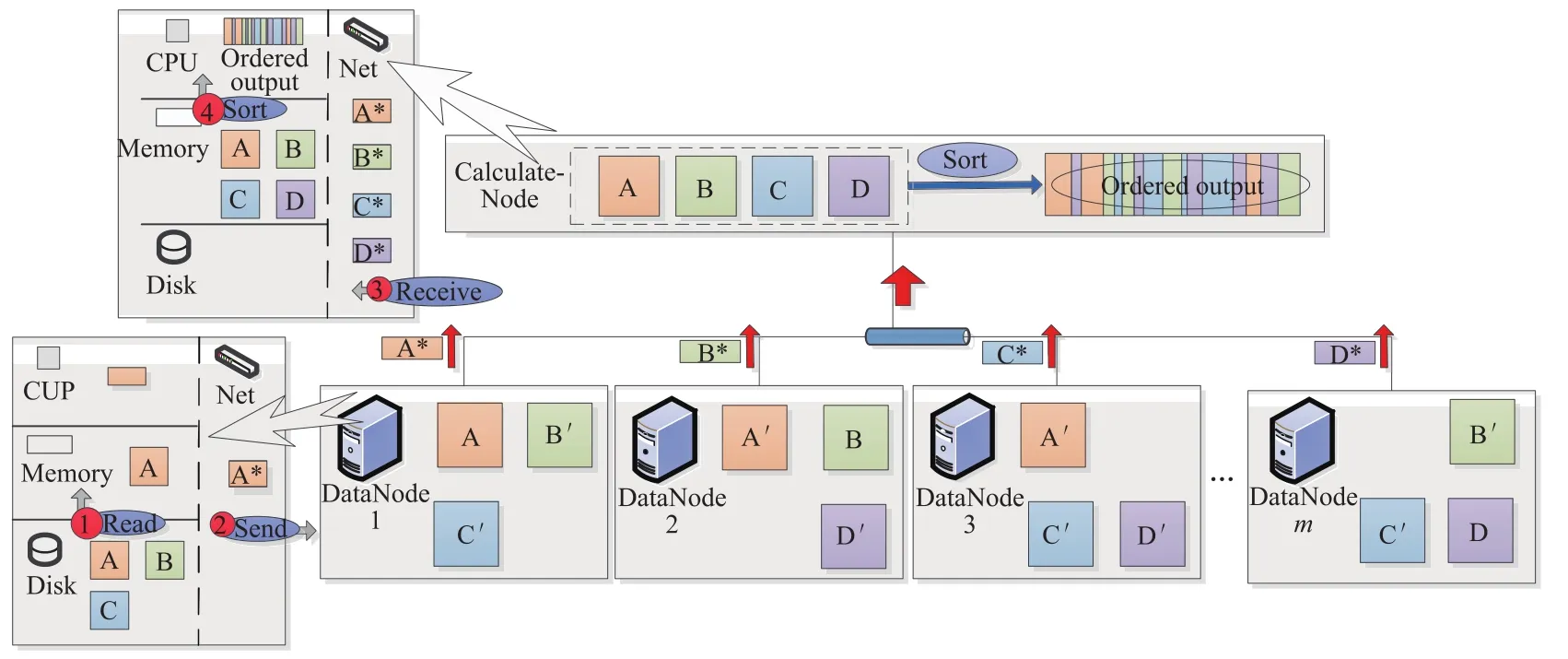
图1 集中式内存排序Fig.1Single node sorting
在这样的场景下,根据表1的符号定义,可以认为存储数据节点的代价为
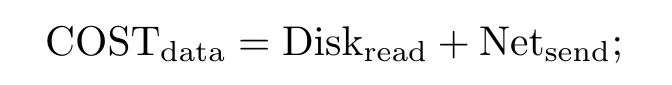
计算节点的代价为
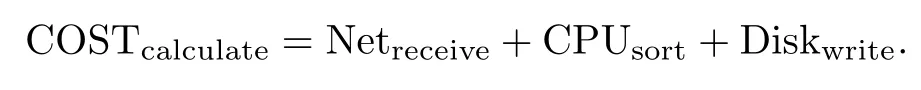
由于计算节点需要在得到所有数据节点传输过来的数据分片后才可以进行排序操作,因此,我们可以得到
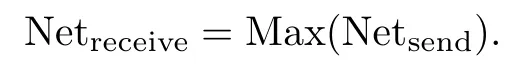
这样我们可以认为排序的总代价为
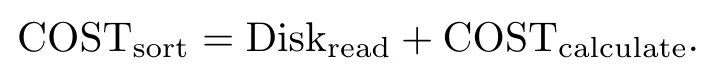
3.2 ı节点归并排序(MNMS)
当存储数据的节点同时也拥有计算能力的时候,可以采用如图2所示的算法.各节点先对存储在本地的数据进行排序,待所有的存储节点都对本地的数据排好序之后,再传送至某一个处理节点进行归并排序.
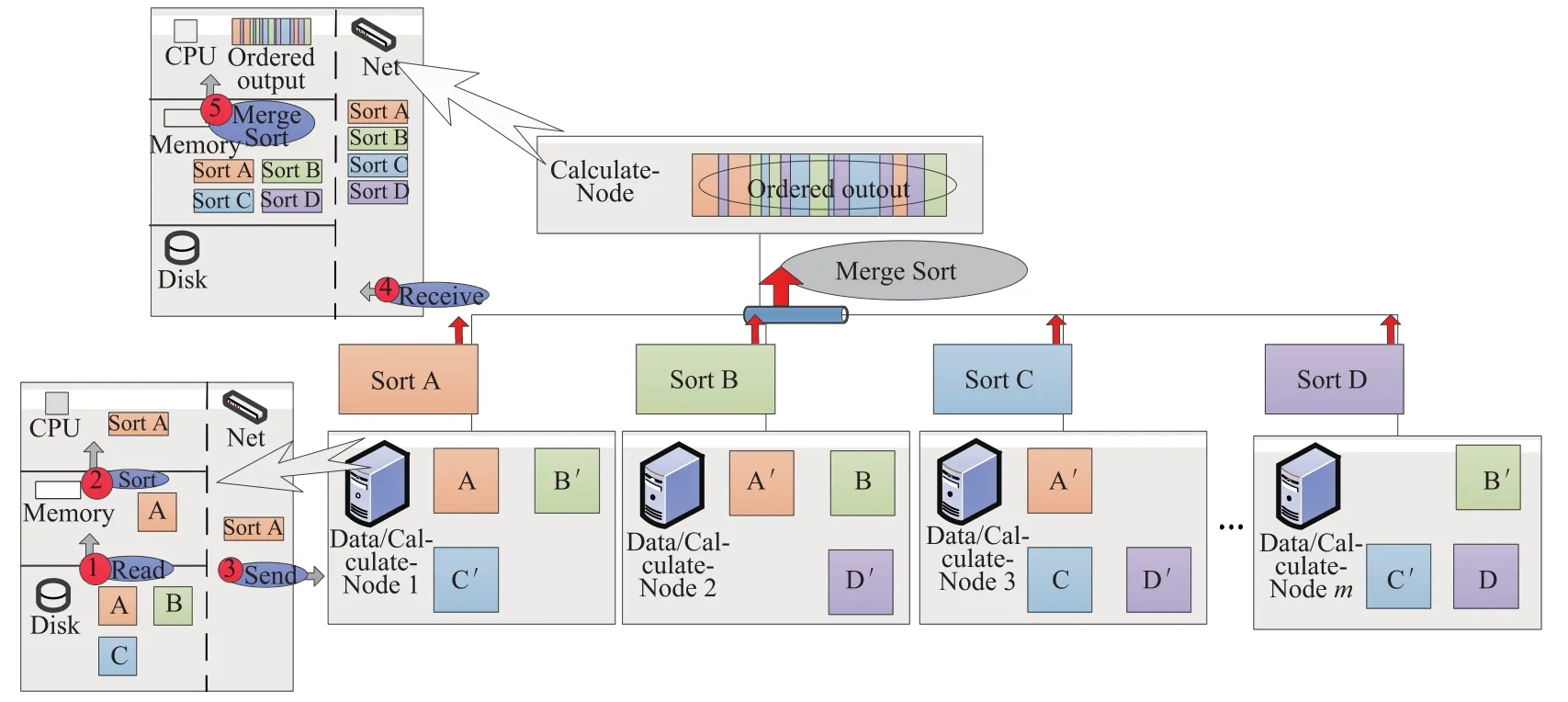
图2 分布式归并排序算法Fig.2Multiple node sorting
在这样的排序场景下,根据表1所述的符号定义,可以将具有存储数据的计算节点排序的代价归结为
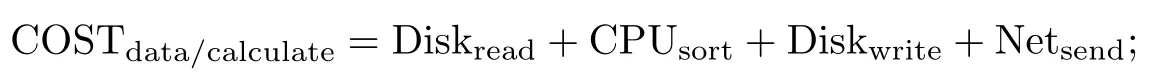
对客户端进行响应的计算节点代价为
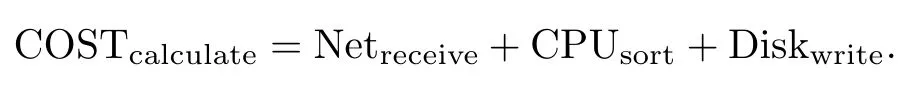
由于需要等到所有存储节点完成数据处理之后,响应客户端的计算节点才会开始排序计算,因此排序的总代价可以归结为
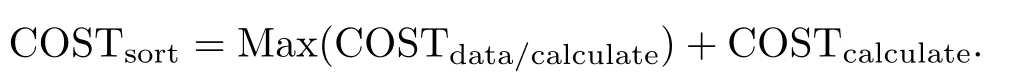
3.3 ı节点分区排序(MPS)
当节点具有并行计算能力,可采用如图3所示的算法.将数据按照一定的范围进行划分,每个节点处理一定范围内的数据,当节点获取到属于该范围的所有数据后,对数据进行排序操作.
在这样的排序场景下,根据表1所述的符号定义,可以将Map任务的执行代价归结为
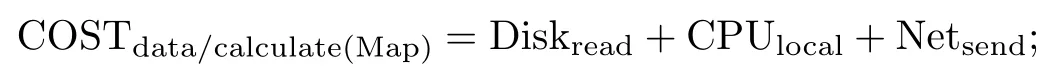
Reduce任务的执行代价归结为
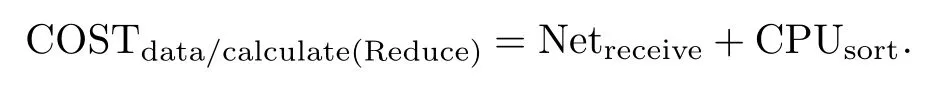
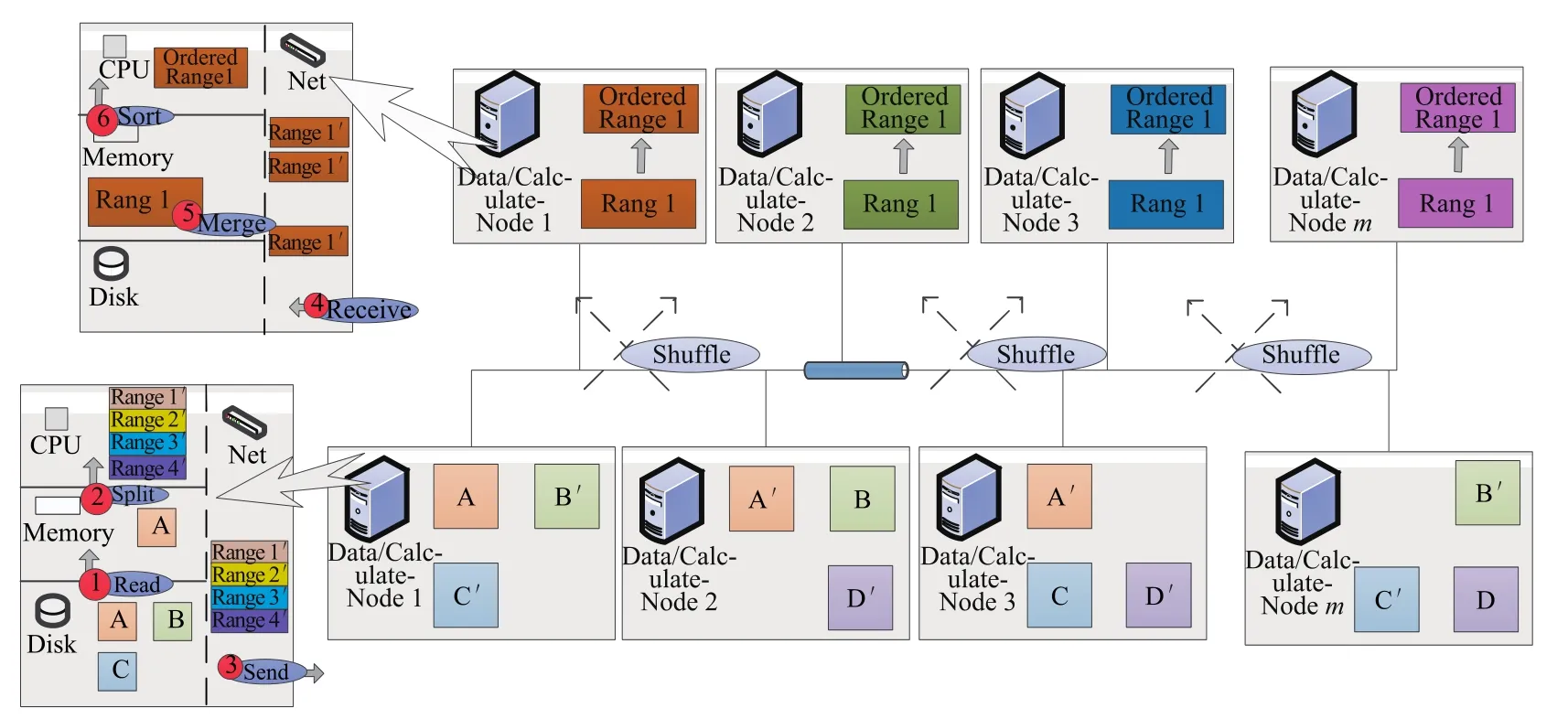
图3 分布式分区排序算法Fig.3Multiple partition sorting
由于不同的系统对Map任务、Reduce任务的并行不一样,如在Hadoop中只需要在有一个Map任务完成之后就可以开启Reduce任务;而在Spark中,需要当所有的Map任务完成之后才可以开启Reduce任务.这里排序的总代价可以归结为
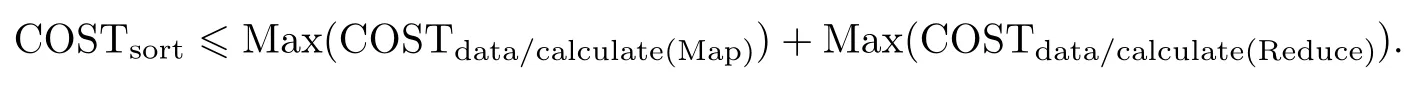
3.4 算法效率分析
对于集中式的排序方法,由于系统中提供的计算模块的节点没有协同的计算能力,仅有对客户端提供服务的节点能够对存储的数据进行处理,因此只能够用集中式的内存排序来满足排序的功能.如果计算节点的内存排序算法采用类似于插入排序的算法,那么计算节点将不再需要等待所有的数据分片到达计算节点后才进行排序操作.但是由于插入排序相比于快速排序等方式会增加CPU的使用,因此在节点中具体采用哪种内存排序算法需要根据具体的硬件水平来进行衡量:当网络传输速率过慢,而CPU等资源充裕的场景下,可以选择插入排序算法对数据进行排序;然而当数据量过大,甚至超出单个计算节点的内存大小时,需要使用外部排序才能完成排序操作,其间带来的大量磁盘I/O势必会成为性能的一大瓶颈.
对于分布式归并排序方法,适用于系统中存储数据的节点有简单计算的模块,但不具备各节点协同计算能力的情况.相比于集中式内存排序算法,归并排序可以流水线式地输出结果,在数据库系统中进行排序归并连接时,能获得良好的应用;且当数据量过大,超出单个计算节点的内存大小时,由于每个数据分片都已经是有序的,在最终的计算节点上进行外部排序的效果会好于集中式内存排序算法.但是,与集中式内存排序相同,由于计算压力都被分配在一个节点上,在待排序数据量过大的场景下,均不能获得良好的性能.
对于分布式并行排序算法,适用于计算节点有并行计算能力的系统.采用分布式并行排序算法,由于事先不知道待排序数据的分布,需要通过采样获取待排序数据的分布后对数据的范围进行划分.常用的采样算法有:随机采样,根据采样率随机地选取待排序的数据;头部采样,根据需要采样的数值x,选取待排序数据的前x条数据;等间隔采样,根据需要采样的数值x与数据总量X,等距地选取x条记录.
由于集中式排序和分布式归并排序的数据分片,最终都只是传输到处理节点上进行总体的排序,所以是否使用数据副本对最终的排序效率影响不大.而对于分布式并行排序,由于之前的分析,可以通过使用副本减少网络传输,进而提升一定的排序性能.
对于待排序数据在进行排序操作之前就已经是有序的场景下,集中式内存排序算法和分布式归并排序算法需要的仅是传输并扫描一遍数据,代价较小.分布式并行排序则根据采样算法的不同可能呈现出不同的效果:随机采样由于其随机性,能够得到大致均匀的数据划分;头部采样由于被采样数据本身就已经是有序的,反而造成了划分的不均;等间隔采样在这样的场景下能发挥出最好的性能,做出最准确的划分.
4 实验分析
为了验证分析结论的正确性,我们搭建了7个节点的Hadoop集群,节点间通过千兆以太网连接.每个节点的配置为2颗Intel(R)Xeon E5-2650 CPU、128 G内存和SSD存储,软件环境包括Red Hat Enterprise Linux Server release 6.2、Hadoop 2.7.2和JDK 1.7.0 79.实验中使用的数据集由Sort Benchmark的数据生成器gensort产生,数据集规模分为20 GB、40 GB和80 GB 3种.
实验分为3组:第一组用于对比3种排序算法对不同规模数据集的排序性能;第二组测试数据分片大小对排序性能的影响;最后一组实验用于分析影响分布式分区算法性能的因素.在实验中我们使用监控工具nmon for Linux[9]来获取排序算法执行过程中各节点的资源使用情况. 4.13种排序算法性能比较
如图4所示,显示了3种排序算法在不同数据量场景下的运行时间.其中,SNS为单节点排序算法,MNMS为多节点归并排序算法,MPS为多节点分区算法.在各数据量上,分布式分区算法的运行时间均要小于SNS与MNMS.由于SNS和MPS最终的排序只由一个节点处理,处理节点伴随着大量的网络I/O,同时计算节点还需要对大量数据进行处理,所以排序的运行时间要长于分布式分区算法.
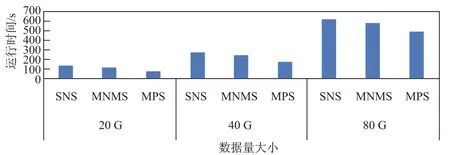
图4 算法性能比较Fig.4Performance comparison of algorithms
图5所示,是在待排序数据量为40 G的场景下,3种排序算法在运行过程中,某一数据节点以及某一计算的节点的资源监控图.由于在SNS以及MNMS的模拟实现中,计算节点上也存储着待排序的数据,因此其资源监控图中计算节点也含有数据节点的代价.由图5可以看出,无论是SNS还是MNMS,它们最终都是在某一个节点上完成所有的排序操作,因此这个节点在总的排序操作开始时,有大量的网络传输来获得待排序数据,以及大量的磁盘I/O来完成排序后的数据写入操作.而对于MPS来说,前期由于需要进行采样操作;所以伴随着少量的磁盘I/O,之后无论是磁盘还是网络的压力,MPS均小于其他两种算法.
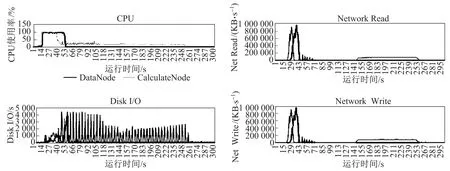
图5(a) SNS代价Fig.5(a)Cost of single node sort
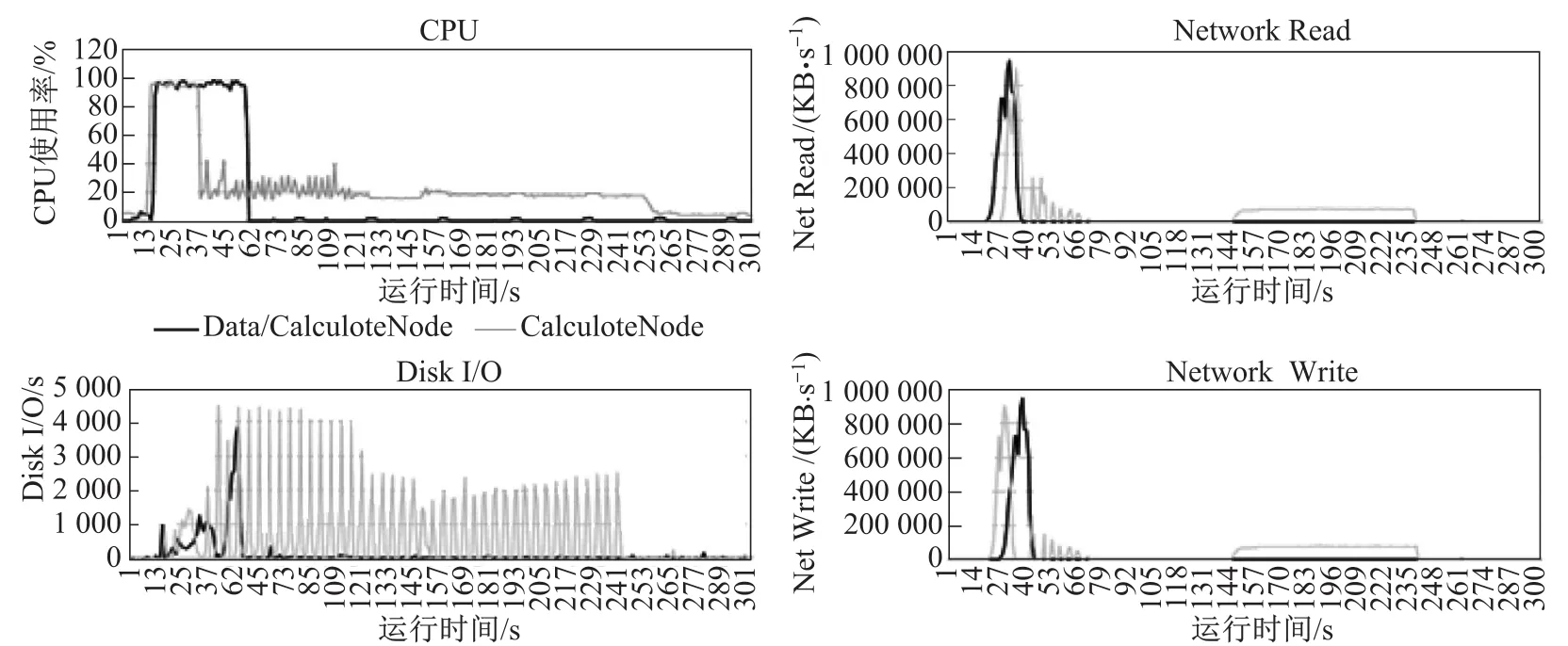
图5(b) MNMS代价Fig.5(b)Cost of mutiple node merge sort
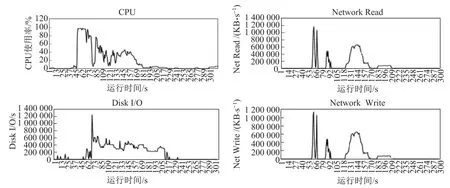
图5(c) MPS代价Fig.5(c)Cost of mutiple partition sort
4.2 数据分片大小的影响
如图6所示,显示了待排序数据量为40 G场景下,数据分片大小分别为64 M、128 M、256 M时,执行不同排序算法需要的时间,其中SNS为单节点排序算法,MNMS为多节点归并排序算法,MPS为多节点分区算法.
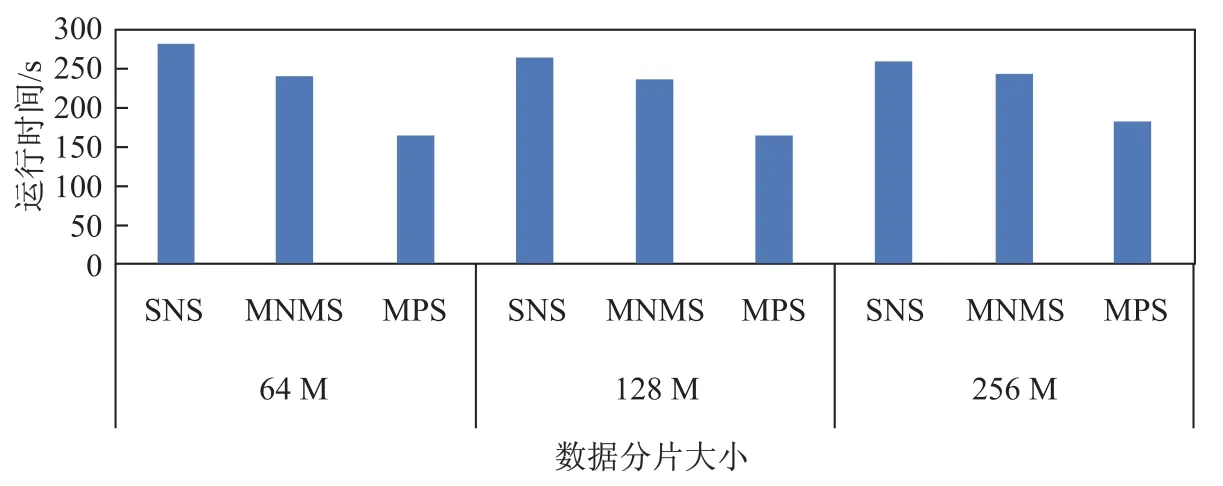
图6 不同数据分片大小的性能比较Fig.6Performance comparison of different block sizes
由于实验中集群采用SSD硬盘配置,没有硬盘的寻道时间,所以3种排序算法在不同数据分片大小的场景下变化不大.SNS由于主要代价在最终节点的排序上,增大了数据分片的大小,使得网络上有了些许提升,因此在算法运行时间上有所减少.分布式归并排序虽然在网络上也得到了优化,但是每个数据分片本地排序的时间也有稍许提升,因此总体没有太大变化.分布式分区排序由于本地需要处理的数据量增多,所以运行时间上有一定的增加.
4.3 分布式分区排序算法分析
实验使用了随机数据、正态分布数据,以及执行排序操作前就已经是有序的有序数据这3种不同的数据分布,测试采样策略为随机采样、头部采样以及等间隔采样3种不同的采样策略.实验结果如图7所示.
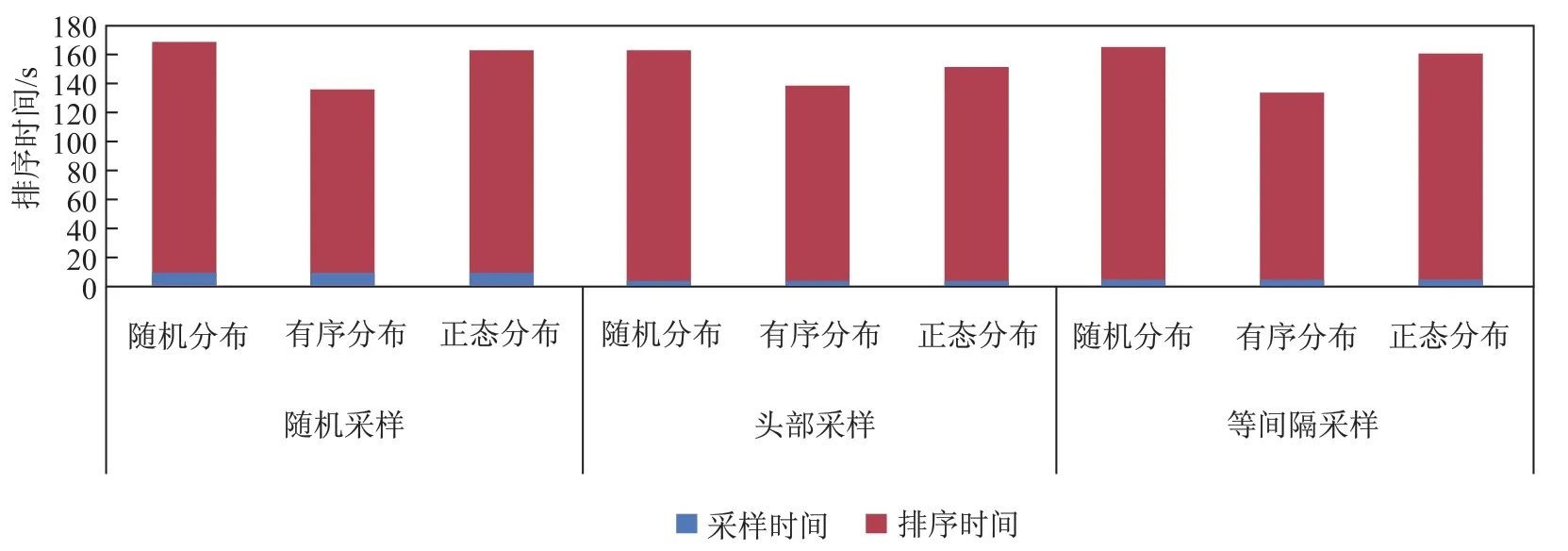
图7 不同采样策略的性能比较Fig.7Performance comparison of different sampling strategies
由图7可以看出,采样效率上由于随机采样需要扫描更多的数据,所以效率最低,头部采样的效率最高.如果待排序数据原本已经是有序的,由于排序计算时间的减少,排序算法的运行时间要少于其他情况.同时在数据有序的场景下,等间隔采样能在较少的时间内对数据进行均匀的划分.
5 总结
本文描述了在分布式场景下3种不同的排序算法,描述了它们与传统的单节点内存排序算法的不同之处,分析了排序算法不同阶段的代价,并结合分布式场景的特点讨论了数据分片大小、数据副本、数据分布等问题对不同算法的影响.通过实验对比验证了分析的正确性.在分布式场景下,为了能够更快地对数据进行处理需要充分考虑系统架构特点、系统参数设置、各节点的硬件水平等诸多因素,综合评选,选择最适合的排序算法.
[1]KNUTH D E.The Art of Computer Programming:Sorting and Searching[M].2nd ed.Indianapolis:Addison-Wesley Professional,1998.
[2]BORTHAKUR D.The hadoop distributed file system:Architecture and design[J].Hadoop Project Website, 2007,11:1-10.
[3]DEAN J,GHEMAWAT S.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[4]CHRISNYBERG,MEHULSHAH.SortBenchmarkHomePage[EB/OL].(2015)[2016-04-20]. http://sortbenchmark.org/.
[5]BORTHAKUR D,GRAY J,SARMA J S,et al.Apache Hadoop goes realtime at Facebook[C]//Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data.ACM,2011:1071-1080.
[6]MANE S B,SAWANT Y,KAZI S,et al.Real time sentiment analysis of twitter data using hadoop[J].International Journal of Computer Science and Information Technolo,2014,5(3):3098-3100.
[7]O’MALLEY O,MURTHY A C.Winning a 60 second dash with a yellow elephant[J].Proceedings of Sort Benchmark,2009,1810(9):1-9.
[8]WANG J,WU Y,CAI H,et al.Fuxi Sort[EB/OL].(2015)[2016-04-20].http://sortbenchmark.org/FuxiSort2015.pdf.
[9]GRIFFITHS N.Nmon performance:A free tool to analyze AIX and Linux performance[EB/OL].(2003-11-04) [2016-04-20].http://www.ibm.com/developerworks/aix/library/au-analyze aix/.
(责任编辑:李艺)
Sorting algorithm analysis of distributed data based on Map/Reduce
YU Sheng-jun,GONG Xue-qing,ZHU jun,QIAN Wei-ning
(Institute for Data Science and Engineering,East China Normal University, Shanghai200062,China)
Distributed system has been widely applied in recent years to tackle the storage and calculation of big data.Sorting of large-scale dataset in the distributed system has become the fundamental problem to affect a varieties of application performances which is not only concerning about the selection of sorting algorithm at each node,but also about the development of distributed algorithms to coordinate at each node.This paper summarizes the common distributed sorting algorithms which are applied in the distributed system.Analysis has been conducted to the implementation process,cost model and applicable field of each algorithm.And the analysis results have been verified by experiments.This work can help developers choose and optimize the big data sorting algorithm in distributed environments.
distributed system;sorting algorithm;cost model
TP311
A
10.3969/j.issn.1000-5641.2016.05.014
1000-5641(2016)05-0121-10
2016-05
国家自然科学基金(61332006);国家863计划项目(2015AA015307)
余最隽,男,硕士研究生,研究方向为分布式数据库.E-mail:sjyu@obase.com.cn.
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
计算机系统应用(2019年2期)2019-04-10 05:08:46
火控雷达技术(2018年4期)2019-01-15 05:07:22
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
计算机与生活(2016年11期)2016-11-22 02:07:32
计算机工程与科学(2015年3期)2015-03-27 07:46:15
中学生(2015年12期)2015-03-01 03:43:53
