
非阻塞事务型实时数据注入技术研究与实现
2016-11-29 09:34余楷李志方周敏奇周傲英
华东师范大学学报(自然科学版) 2016年5期
余楷,李志方,周敏奇,周傲英
(华东师范大学数据科学与工程研究院,上海200062)
非阻塞事务型实时数据注入技术研究与实现
余楷,李志方,周敏奇,周傲英
(华东师范大学数据科学与工程研究院,上海200062)
伴随着大数据时代来临,传统数据库系统已逐渐无法应对海量数据处理带来的挑战,而分布式数据库系统得到了越来越多的部署和应用.分布式数据库系统部署数据于多台机器上,利用大规模并行计算技术实现了对海量数据的存储、管理和分析.但针对金融领域严苛的事务型实时数据注入需求,现有分布式数据库系统对其支持有限,其主要原因在于利用锁和两阶段提交等方式实现分布式事务处理,无法做到非阻塞式数据注入,极大地影响了数据注入的性能.华东师范大学数据科学与工程研究院自主研发的分布式内存数据库系统—-CLAIMS,已能提供面向关系型数据集的实时数据分析服务,但尚不能支持实时数据注入.针对上述实时数据注入的问题,本文重点分析了现有数据注入技术和基于分布式事务处理的实现方式,设计了面向元数据的集中式事务处理策略,利用无锁编程技术,实现了支持分布式事务的高性能实时数据注入框架,并通过热备机制实现系统的高可用性.上述框架在CLAIMS系统中的实现,经充分实验表明:该框架能够实现高通量的事务型实时数据注入,同时支持低延时的实时数据查询.
分布式数据库;实时数据注入;事务;CLAIMS
0 引言
随着信息技术的快速成熟和互联网的高速发展,传统行业加速信息化.大型企业的数据规模普遍已经达到TB级,甚至PB级,同时每天仍以TB的量级不断增加.应对海量数据对数据存储和数据分析带来的巨大挑战,目前业界使用的解决方案是基于MapReduce框架[1]的HADOOP和SPARK[2].两者构建在分布式文件系统HDFS上,由其负责将巨大的数据集分派到集群中的多个节点进行存储,同时提供良好的容错性[3],实现数据的多备份策略. HADOOP使用MapReduce模式实现并行计算,具有天然的容错能力;后者主要在内存中处理和分析所有数据,不写回中间结果到磁盘,极大地提高性能.同样地,内存数据库将数据全部存放于内存,使数据的查询分析性能提升一个数量级.SAP HANA[4-5]和Exalytics[6]作为内存数据库的代表,提供数据的实时查询分析,达到秒级的响应速度.
数据从事件发生到支持决策经历多次延迟:数据注入延迟、分析延迟、决策延迟,实时数据的价值依次递减.为了减少企业因数据延迟带来的经济损失,数据需要在实际产生后立刻实时注入数据库系统中,同时立即提供实时的查询和数据分析,以同时降低注入延迟和分析延迟.而数据的实时存储和分析都基于实时数据注入的基础上,因此数据注入延迟更显重要.大数据环境下的数据注入不仅注入数据量非常巨大,同时数据注入的速度要求极高.实际需求中,实时注入和实时分析同时执行,并按需实现两者隔离(如实现read committed等隔离级别).在更加严格的金融领域,数据注入必须支持事务,保证数据的持久性和一致性.以上现实需求对数据注入提出以下要求:
1.实现较高性能的数据注入,压缩注入延迟在毫秒量级,实现数据注入的实时性;
2.通过事务处理的方式保证实时数据注入过程中数据的完整性和一致性;
3.对数据注入和数据分析进行必要的隔离,以保证数据实时注入不影响实时数据查询、分析执行及其正确性.
面对大数据时代对海量数据存储管理和实时分析的需求,华东师范大学数据科学与工程研究院自主研发了支持高性能数据查询的集群感知分布式内存数据库--CLAIMS(Cluster Aware In-Memory SQL engine).CLAIMS系统基于Master-Slave的Shared-Nothing架构,利用大规模并行计算提供基于关系型数据集的高性能实时数据分析[7],并极大降低分析延迟.然而,针对注入延迟问题,CLAIMS暂时不能提供高效的解决方案.
针对CLAIMS的数据注入框架无法实现实时数据注入并实现系统容错等问题,本文摒弃传统基于分布式事务处理的实现方式,广泛使用无锁结构与算法,以等价的面向元数据的集中式事务处理方式替代传统的分布式事务型实时数据注入方式.主要贡献如下:
1.扩展传统的单机数据注入为面向分布式系统的数据注入,充分利用集群多台机器的资源,避免由于单机资源耗尽导致的性能瓶颈.
2.结合HDFS系统中文件只能截断,无法被修改的特性,设计实现面向服务的分布式并发控制机制.该系统基于无锁思想,利用事务快照实现“读写分离”,预分配分布式节点内存来实现“写写分离”,大幅度提升数据注入和查询的性能,实现非阻塞实时数据注入.
3.在实时数据注入的同时,对外提供强一致性的实时数据查询分析,并实现数据的快照隔离级别.
4.实验证明本文所提出的分布式实时数据注入框架具有较高的数据注入性能、较低的数据注入延迟与较高的事务型数据注入吞吐量,满足大多数实时注入的需求,并提供数据的完整性保证.
本文第1节介绍数据实时注入实现技术和分布式事务处理的方式,以及本文实验基于的CLAIMS系统的架构;第2节阐述分布式数据注入的设计、分布式事务管理的设计实现等;第3节对实现的框架进行测试和对比实验;最后一节是本文的总结.
1 相关工作
实时数据注入是指数据从消息队列系统注入到数据库系统的延时较低(通常在毫秒级别),并实现对数据库系统中的数据实时更新,是大幅提升数据的处理价值的必要前提.对实时数据的实时分析,包括数据注入的实时性和数据分析的实时性,并通过隔离数据注入和数据分析实现数据分析的一致性.本文工作主要面向CLAIMS系统的分布式系统环境,实现事务型实时数据注入.下面从分布式实时注入、分布式系统的事务处理、CLAIMS系统三个方面来介绍本文的相关工作.
1.1 分布式数据实时注入
目前流行的大数据分析工具对数据实时注入支持较不完善,例如Facebook开源的分布式SQL查询引擎Presto和SPARKSQL都针对于分布式查询问题,在海量数据上提供分布式的SQL查询能力,但无法保证实时的数据加载[8-9].Druid是一个列存储的分布式数据存储[10],专门为了快速导入海量数据并立即对外提供查询而设计,但是它查询上不支持SQL,使其在电信、金融服务等依赖SQL的行业无法广泛使用.不同于Druid,Pinot同时支持实时数据注入和SQL语句查询.Pinot[12]划分数据为两类,离线数据(存于HADOOP等)和在线的准实时数据(存于Kafka).然而Pinot不支持SQL中极为重要的JOIN语义,因此无法满足现实的需求.同时其受限于Kafka支持的“At Least Once”消息消费模型[13],可能出现重复冗余的消息,应用场景有限.因此实时数据注入需要支持事务的四个特性:ACID[11](原子性、一致性、隔离性、持久性).Vertica[14]、HAWQ[15]作为支持批量数据事务型注入功能的系统代表,不能将最新插入的数据反映在查询中,无法满足实时查询的需求.目前支持事务型分布式数据实时注入和数据实时查询的系统只有VoltDB,因此该系统是本文的实验对照对象.
1.2 分布式系统的事务处理
分布式系统中数据处于不同的机器节点,需要事务支持来保证数据的ACID特性.
1.2.1 两阶段提交
分布式事务一般通过锁和两阶段提交协议(Two-phase Commit,2PC)来实现[23],分为一个协调者和多个资源管理者角色.该协议将分布式事务划分为两个阶段:预提交阶段和提交阶段.协议的执行通过阻塞操作完成,大幅影响计算资源的使用率和事务性能,两阶段提交涉及多次节点间的网络通信,通信时间大大延长.由于锁的阻塞,资源的等待时间大量增加.其核心问题是如果协调者宕机,整个系统将处于不可用状态.针对2PC的缺点,三阶段提交协议被提出[25],但其网络延迟再次增大,无法作为有效的解决方案.
1.2.2 多版本事务处理
除了基于锁的事务并发控制,多版本事务并发控制得到广泛的使用.每个数据项对应于多个副本,更一般的情况是,不同事务可以对相同数据项的不同版本进行读和写[20].基于多版本的并发控制方法可以实现写写分离和读写分离以避免事务执行过程中的阻塞.SQL Server 2014中的Hekaton内存计算框架就是基于多版本并发控制实现[21].表中的每个元组均保存有多个不同版本的副本(基于时间戳),删除和修改元组时创建新的版本.读取数据的时候根据时间戳只读取定版本的数据.由于Hekaton系统是集中式数据库,对使用的单台机器性能有较高要求,因此在可拓展性和成本方面有较多要求,严重地限制其应用场景.
1.2.3 基于单线程的事务处理
多线程并发的事务处理有许多限制和要求,甚至反而降低性能,因此单线程的事务并发处理框架被提出.该框架将数据进行切分,在每个数据分区上仅有单个线程进行读写,避免事务执行的冲突,从而完全避免锁的开销和其他多线程并发控制的开销.Micheal Stonebraker主导的H-Store/VoltDB分布式内存数据库就基于单线程的事务处理,简化并发控制的机制[16].通过在集群中简单增加节点的方式VoltDB可实现性能的线性增加,因此目前的分布式事务处理系统中VoltDB拥有几乎最高的性能.
1.3 CLAIMS系统
CLAIMS系统作为分布式内存计算系统,提供高性能的实时交互式数据分析与处理.不同于NOSQL[26],CLAIMS支持SQL92,兼容金融等领域的历史上层应用.
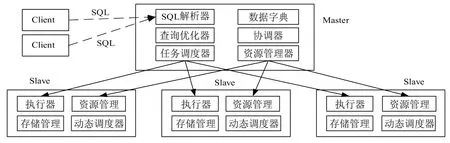
图1 CLAIMS系统架构图Fig.1System architecture of CLAIMS
CLAIMS系统采用经典的主从架构(Master-Slave),集群包括一个主节点和若干个从节点,如图1所示.主节点接收SQL语句并解析,生成查询计划分发给从节点,最后汇总结果集,管理和调度每台机器上的计算资源和查询执行过程.主节点包括SQL解析器、查询优化器、数据字典管理器、集群资源管理器、全局调度器、协调器六个组件.从节点主要负责在内存实际存取数据和接收并执行查询计划,由执行器、资源管理器、单机调度器、存储管理器四个组件组成.
2 实时数据注入框架的设计实现
为了实现面向CLAIMS的事务型实时数据注入框架,在深刻理解CLAIMS系统架构的基础上,参考各类分布式事务处理系统的设计经验,本文提出新型的事务处理控制方式,设计并实现以下的一系列功能:
1.针对实时数据注入对应的追加型事务,采用面向元数据的集中式事务处理的策略,实现事务性数据注入,以避免直接对分布式数据注入操作实现事务性管理.
2.非阻塞式分布式数据注入框架,将传统的集中式单机数据注入转变为分布式数据注入,充分利用多台机器的性能,避免性能受限于单机的处理瓶颈.
3.提供强一致性的数据查询模型,实时注入的数据在后续的实时查询中即时可见,支持在实时注入更新的数据集上实时查询.
4.使用log-shipping技术实现数据热备,面对服务机器宕机支持快速切换,对外提供高可用性的服务,满足金融领域的可用性要求.
在当前的CLAIMS的系统架构基础下,本文设计如图2的系统架构,并实现并行的实时数据注入框架和原有的实时数据分析框架,两者之间互不阻塞.

图2 CLAIMS数据注入框架Fig.2Framework of data ingestion in CLAIMS
2.1 框架总体设计
如图2所示,实时数据注入框架主要分为数据实时注入器以及事务管理器(TM)、HDFS持久存储层.数据注入器主要分为主注入器(下称Coordinator)和从注入器(下称Worker).完整的数据注入框架包括一个事务管理器、多个Coordinator、多个Worker和持久存储层HDFS.其中Coordinator和Worker可共存于同一机器节点.
数据注入引擎中各组件功能如下所示:
·TM:管理所有事务相关的数据并维护事务状态,向其他节点提供事务管理服务.
·Coordinator:多个Coordinator独立提供服务.每个Coordinator从MQ拉取数据注入请求,对数据进行合法性等检查,向TM申请事务的支持,获得该事务预分配的注入地址后,将注入任务切分为多个Worker上的子任务并分发给对应的Worker.在Worker完成(commit或者abort)事务后收集反馈,提交给TM.接收反馈超时则采取重试一次的策略,再失败则认定事务失败,并提交给TM.
·Worker:每个Worker负责该节点上绑定的所有数据分区的读写操作.其接收从Coordinator发送的注入任务,并在对应数据分区上实际执行.所注入的数据被保存Worker节点的内存中,提供快速查询与访问.
·持久存储层:CLAIMS系统采用HDFS作为Worker内存中已提交的历史数据持久化的介质.一旦写入HDFS中,则由HDFS保证数据不会丢失.
Coordinator同Worker共用机器以充分利用每个节点的性能.一般情况可选用单Coordinator多Worker的架构,实现难度较低,对性能要求较高时可采用多Coordinator多Worker架构来提高系统的吞吐率,防止单一的Coordinator成为系统的瓶颈.理论上可通过增大Coordinator和Worker节点的数量达到近线性横向拓展CLAIMS的数据注入处理能力. 2.2事务并发控制
2.2.1 事务对象模型
传统数据采用页模型和对象模型[20],其任何对数据的高层操作最终都要映射为一组对磁盘页的Read/Write动作.内存数据库将表存放在内存中,直接进行随机读写操作,相比传统数据库减少很多限制.本文采用内存条带的概念描述事务执行的对象,并以如下的三元组的形式描述内存条带s的概念:

s表示在分区part上,以该分区的起始地址记为0地址,在[pos,pos+length)之间的连续内存空间.对于任意二个内存条带si和sj,如果满足下面的条件,则称si和sj是重叠的,表示为si∩sj=Ø;否则为不重叠,表示为si∩sjØ.

类似页模型,在内存条带s上,本文定义Read和Write二种基本操作,它们表示的含义如下所示:
Read(t,s):扫描分区s.part中[pos,pos+length)范围内的数据;
Write(t,s,d):将分区s.part中[pos,pos+length)范围内的数据写为d,其中t表示某一个事务.
在分布式事务t的执行中,需要对多个内存条带同时进行读写操作,所以本文称一组内存条带的集合为内存向量,如下所示:

在内存向量上本文拓展了Map,Merge以及Filter三种辅助操作,如下所示:
·Map:该函数将单个内存向量划分成多个内存向量的集合.

其中λ为划分函数,Map操作将所有λ函数值相同的内存条带划分到同一个内存向量.在本框架具体实现中,λ函数按part值进行划分,每个part对应一个内存向量.
·Merge:该函数将内存向量内相邻的内存条带进行合并,如下所示:

通过合并相邻内存条带,多次的读写简化为单次读写,有效地降低读写IO次数,提高系统性能.
·Filter:该函数对内存向量进行过滤,去除所包含的不满足条件的内存条带.

其中f为过滤函数,Filter函数将f函数值为false的内存条带过滤掉,仅保留结果为true的内存条带集.
通过引入内存条带上的Read/Write操作,以及内存向量上的Map,Merge和Filter辅助操作,本文将复杂的分布式事务的执行过程抽象成上述简单操作的组合.
2.2.2 事务处理模型
在CLAIMS的数据注入框架中包括消息队列MQ,1个用于集群资源管理的节点M,1个用于分布式事务管理的节点TM,n个用于执行查询和注入任务的工作节点,组成的集合为S.系统中每个节点i的机器都有m个可利用的处理器核心,组成的集合为Corei.CLAIMS集群中所有被创建的表的集合为T,并且每个表Ti对应的分区的集合为PTi.为了简化问题,本文统一地将所有表中的所有分区的集合定义为P.
数据注入过程中,交易系统将不断产生的交易流水实时地不间断地分批发送到作为中间件的消息队列MQ中,并随后被注入到CLAIMS中.对于某批次b中这些元组所对应的分区的集合为Pb.对于某个分布式注入事务t,本文定义分区pi上的注入数据d的动作为Write(t,si,d),其中si是TM在pi上分配的内存条带,满足si.part=pi∧pi∈Pb.当P′中所有分区上的操作都成功时,使用操作Commit(t)使注入的t所注入的数据对其他事务可见;否则调用Abort(t)撤销t进行的所有修改.
在数据被实时地注入CLAIMS系统的同时,企业的分析用户通过M节点向CLAIMS集群发送所要执行的SQL查询语句q.本文假设q执行过程中所要扫描的分区的集合为Pq, Pq中每个分区上已提交的内存条带组成的集合记为sq.q在执行过程中依次对sq中的每个内存条带都执行Read操作,即可获取查询q所需数据.
在数据库的研究领域中,冲突可串行化提供了事务执行所必需的隔离性,在商用系统中具有重要的应用价值,通常被商用数据库强制满足并执行.CLAIMS的实时注入引擎和查询引擎所产生的调度利用写写分离策略保证写事务之间的无冲突,利用多版本快照策略来保证读写分离,从而保证读写事务并发控制调度冲突可串行.
2.2.3 事务管理器
在分布式实时数据注入框架中,事务管理器(TM)主要对外提供三种服务:第一是原子性分配注入事务所需的资源并维护事务在整个生命周期内的状态信息;第二是基于事务的状态信息生成查询事务所需要的事务快照,实现读写分离;第三是周期性地合并连续内存上的连续事务,依据合并的事务信息,帮助各个Worker节点发起数据持久化.
为了提供上述服务功能,TM节点在内存中维护事务状态表和内存分配表.事务状态表记录并维护已创建事务的编号、事务提交状态和分配内存向量等信息.内存分配表记录每个数据分区的末尾地址,记录下次分配内存的起始地址.
考虑现代机器基本是多核多CPU,为了充分利用机器各CPU的性能,TM设计成多线程并发控制结构.对于TM所需要维护的两个结构:事务状态表和内存分配记录表,本文摒弃基于锁的阻塞式策略,采用不同的多线程并发结构实现非阻塞式的并发操作.
现代多级存储器体系中,处理器和内存之间通常有三级缓存(cache),缓存的访问速度远大于内存.由于缓存大小有限,一般使用LRU算法[26]保存最近频繁访问的内存,因此满足“局部性”的程序可充分利用cache显著提高程序运行速率.同时每个核有独立的L1缓存,由硬件保障其一致性.某个缓存数据的修改会导致其他核的缓存无效,导致重新载入.
基于上述两个cache特性,事务状态表抛弃传统的由多线程全局共享的方式,切分为多个线程局部的事务状态子表,如图3所示.每个事务子表由其独占的线程负责读、写、回收等操作.基于线程局部的事务表切分方式避免多线程并发操作的冲突,并在一定程度上维持事务的多线程的性能加速,同时此方式将事务子表长久地保存于L1缓存中,免于缓存不命中,同时每个CPU只保存一部分的子表,相互间没有交叠,避免出现缓存失效,减少因为子表频繁换入换出缓存带来的额外性能开销.
当创建注入事务,本文通过特定的策略确定其所在的事务状态子表,并转发任务给对应工作线程.当读事务获取快照时,基于流水线执行方式,对所有事务状态表的工作线程发送创建快照的任务,最后合并所有的子快照,得到最终的快照.具体步骤见章节2.3与2.4.

图3 事务状态表结构Fig.3Transaction state table structure
内存分配状态表只有各自数据分区的尾部地址信息,所有对该表操作的冲突均来自对尾部地址的并发读和写,本文利用无锁编程技术,采用原子性操作来操作各自分区的尾部地址,实现非阻塞事务创建和事务资源无冲突的分配.每个注入事务在创建事务之前获得其所需要的内存空间大小,原子性地修改尾部地址,达到预分配内存的目的,每个事务之间申请的资源没有重叠,从而天然地支持无冲突事务并发.
2.3 数据注入
CLAIMS系统底层以HDFS为文件存储系统,由于HDFS只支持数据追加到文件末尾而不支持原地修改,CLAIMS采用日志式存储,注入的数据均以追加的模式添加到对应分区的末尾.针对传统数据库支持的UPDATE操作,本文将其分解为两个INSERT操作,分别在原表和隐藏的deleted表中各插入一条数据,注入新值到原表之中,插入旧值到deleted表.查询同时查询两张表,增加JOIN操作过滤旧值保留新值,等价于UPDATE操作.
TM节点对每个分布式注入事务分配互不重叠的内存条带,如图4所示.因此CLAIMS系统在处理数据注入的过程中,对每个事务访问的资源进行隔离,事务实现写写分离.得益于此,不同的注入事务可实现完全的并行执行,同时事务不会因为相互冲突而中止,大幅减少事务的失败率.只有事务涉及的每个内存条带上的注入都成功执行,提交事务,之后注入的数据即时可见.

图4 事务内存分配图Fig.4Memory allocation for transaction
注入事务的完整执行过程分为如下步骤,如图5所示.
1.数据到达:Coordinator节点从MQ中读取最新的数据包,开始执行数据注入过程.
2.创建事务:Coordinator节点解析获得注入的若干条元组,并按照每个元组对应的分区进行划分.计算该事务在每个分区上的内存需求量后,Coordinator向TM发起创建注入事务t的请求.TM节点分配t执行所需资源,例如事务ID,所注入的内存条带等,并返回申请者.这些操作同步地追加到磁盘中的日志文件,用于故障后恢复TM.发起事务后给消息队列MQ发送确认信息.
3.数据注入:Coordinator创建事务成功后,按照分区的划分将元组进行打包,生成数据日志,并发送到对应分区所在的Worker节点上.数据日志中包含对应的内存条带以及所要注入的数据.Worker节点收到数据日志,按照日志的内容将数据注入对应的内存条带中,并反馈结果给Coordinator.
4.日志迁移:Worker节点完成注入操作后,转发数据日志到其他Worker节点上进行备份,最后给Coordinator发送确认信息.
5.提交事务:Coordinator完成分布式数据注入后根据各Worker节点的反馈向TM节点请求提交事务或者撤销事务.TM将事务的提交或撤销记录在磁盘的日志文件中.
6.数据持久化:Worker节点周期性将各个分区在内存中已提交的数据整理并写入HDFS中,将注入CLAIMS的数据持久化.一旦写入HDFS成功,即认为数据不会丢失.

图5 数据注入流程图Fig.5Data ingestion flow chart
2.4 数据查询分析
为了保证实时查询结果的一致性,本文支持事务执行的隔离性,并提供已提交读,可重复读,冲突可串行化等隔离级别[11].CLAIMS系统中使用多版本并发控制,对每个读事务都创建事务快照,实现快照隔离级别,保证事务之间的隔离性.本框架对TM节点管理的元数据进行多版本控制而不是数据本身的多版本控制.
本文引入“快照”的概念来描述数据库某个一致性版本的子集.本文定义分区集合P上已提交的内存条带的集合为快照SP,如下所示:

其中t.v为事务t所申请的内存向量,t.commit为事务t的提交状态.当获取到SP后,本文通过遍历SP所包含的内存条带,并依次调用Read来读取P分区集合上的数据.为了减少Read操作执行的次数,以降低开销,本文利用定义的Map和Merge函数对快照SP进行化简.首先将SP利用Map函数按照分区进行划分,得到每个分区的快照的集合ΠP,如下所示:

对ΠP中每个快照使用Merge函数合并相邻的内存条带,得到简化后的Π′P:


Coordinator接受用户的SQL查询,通过数据字典管理器获取要查询的表,进而确定需要进行扫描的分区集合P,向TM节点申请获取在P上的最简化的内存快照.编译后的查询计划中的Scan算子通过对所有内存中的数据进行过滤,只读取在中的数据.通过每个Core获取快照方式是基于流水线方式,如图6所示.从第一个Core向其加入本地的已提交事务立即转发给下一个Core,同时处理下一个读事务的请求.基于Pipeline的处理方式最大程度地提高每个核的利用率,增加事务的吞吐量,在事务足够多的理想情况下,虽然每个Core都是单线程,实现的性能接近多线程并行的性能.本框架的事务管理器避免因多线程处理之间并发操作带来的锁或其他控制结构的额外开销,且基本达到多线程处理的性能,实现非阻塞式事务处理,具有较高的工程创新意义.
上述可得,本文设计的事务管理器支持事务的强一致性.一旦事务提交,后续的读事务都能立刻访问这个提交事务的元数据快照,已提交事务的结果能即时访问.
2.5 高可用方案
在金融领域,用户需要实时地访问、分析、修改金融交易数据,而且服务方不能中断或停机,一旦无法提供服务,会给企业造成无法估算的损失.尤其是数据库系统需要保证提供不间断的数据服务,尽量减少系统处于不可用状态的时间,做到数据库的高可用性.

图6 实时数据查询流程图Fig.6Real-time data query flow chart
本文设计的数据注入框架考虑到满足系统的高可用性,采用双机热备等方案.CLAIMS是基于内存的数据库,相对于传统的磁盘数据库,出错率相对较低,在两台机器上备份数据在绝大部分情况下可满足需求.如图5所示,Worker在接收到Coordinator节点发送过来的子事务请求后,一方面将该日志格式的数据转发给绑定的另一台热备机器上,另一方面将数据切实地写入到本机的内存中,两者并行,可压缩Worker工作的时间.两个操作均完成后,给Coordinator发送反馈.热备机器收到日志后,在本机回放日志,再发送确认消息给Worker,保证Worker与热备机器维护有相同的数据,一旦原Worker出错或者宕机,系统快速将请求转发给热备机器,理论上系统的不可用时间仅相当于请求切换时间,保证极高的可用性.
同样地,事务管理器全局唯一,有宕机后导致整个系统不可用的风险.事务管理器同样支持热备,实时地将事务日志发送给备机,同时备机在本机上重做所有事务日志.
3 实验
前文已经提及,在分布式工具中,只有VoltDB支持事务型的数据实时注入和数据实时查询,因此将其作为本文的实验对比对象.对于CLAIMS,由TM独占一台机器,设置12个线程运行,另一台机器负责发起注入事务;对于VoltDB,一台机器作为其master,设置注入器sites为12,另一台机器负责发起注入事务.测试服务器基于CentOS release 6.5(Final)系统,CPU型号为Intel(R)Xeon(R)CPU E5-2620 0@2.00 GHz,双路,共12核,可超线程到24核,机器拥有165 G内存和100 G以上大小的硬盘以及千兆网卡.本文采用TPC-H基准测试集的LINEITEM表作为数据注入的实验数据集.本文假设每个批次的注入事务包括150个元组,每个元组大小为200字节,数据由TPC-H数据生成器生成.
实验1测试4台机器,在每个机器分布一个partition的环境下,不同注入线程数下CLAIMS与VoltDB的吞吐量及其单个注入时延,结果如图7所示.实验结果显示:在不同线程数下,CLAIMS系统的注入引擎的事务吞吐量均远大于VoltDB.随着注入线程数不断增大,在不超过机器物理核数量时,CLAIMS的吞吐量大幅增加,时延基本稳定在10 ms之内,直到线程数约等于机器物理核数量时,其吞吐量达到上限,稳定在1300TPS左右.线程数继续增大到16线程,由于各注入线程竞争CPU,导致其吞吐量开始大幅下降,同时事务时延急剧增加.VoltDB在线程数为3时达到其吞吐量的峰值,其后略降,稳定在60TPS,其事务时延随着注入线程数量增长呈线性递增趋势.实验说明CLAIMS在不超过物理核数的线程数下能提供极高的事务吞吐量和极低的时延,完全满足大量实时注入任务的需求,同时充分利用机器的性能,对比VoltDB具有较大的性能优势.

图7 实验1测试结果Fig.7Result of experiment 1
实验2测试4台机器,在采用12个注入线程的环境下,不同partition(均匀分布在4台机器上)下两个系统的吞吐量和时延,实验结果如图8所示.实验表明,在不同partition数量下,CLAIMS仍提供较高的注入事务吞吐量,远大于VoltDB的性能.两者的吞吐量都随着partition数量的增大而下降,主要因为单个事务被分解为更多的子事务处理(每个partition作为一个子事务).在单次注入平均时延方面,CLAIMS在partition较少时延迟远低于VoltDB,在partitions per machine=3左右,急剧增长,因为当前版本的CLAIMS在Worker上仅实现了单线程处理,因此在达到单线程处理极限后延迟大幅增加,在partition数量较大时,增速放缓.Worker上的优化将作为后续工作进行.VoltDB的单次事务延时随partition数量增加呈现线性增长趋势,在partition数量较大时相比CLAIMS具有一定优势.
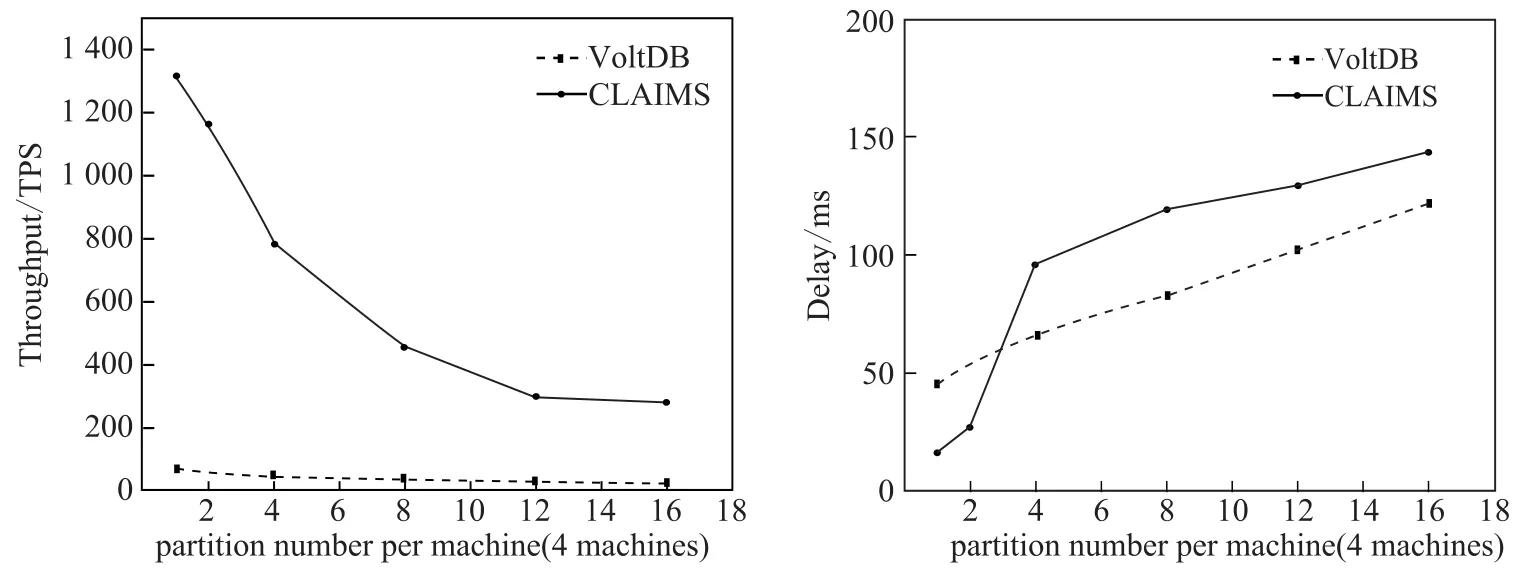
图8 实验2测试结果Fig.8Result of experiment 2
实验3测试基于TPC-H数据集在4台机器各分布1个partition的环境下,实时注入时实时SQL查询的延时情况,并进行对比,结果如表1所示.实验结果显示,实时注入对大部分实时查询的性能影响较小,基本延时增长在10%以内,查询达到秒级响应,但对于长查询,影响稍大,达到12%,仍处于可接受范围之内.总体来看,实时注入框架能保证数据的实时查询不受较大影响.

表1 实验3测试结果Tab.1Result of experiment 3
4 总结
分布式环境下,事务型实时数据注入在电信、金融和电子商务等领域有着巨大的需求和广泛的应用前景.本文介绍了目前分布式数据实时注入的研究现状,阐述事务并发控制的几种方式,面向自主研发的分布式内存数据库CLAIMS,设计了一套高可用、高性能、高通量的分布式数据实时注入框架,保证了数据的实时注入,同时结合CLAIMS的执行引擎提供实时的数据分析查询,详细说明了数据注入和数据查询的整个流程.经试验证明,本文所提出的实时数据注入框架具有良好的性能,并能提供实时的数据注入服务和实时数据分析服务,能够较好满足金融等领域的实际需求.
[1]DEAN J,GHEMAWAT S.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[2]ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:Cluster computing with working sets [C]//Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing.Berkeley:USENIX Association,2010:10.
[3]SHVACHKO K,KUANG H,RADIA S,et al.The hadoop distributed file system[C]//Proceedings of IEEE Conference on MSST.2010:1-10.
[4]胡健,和轶东.SAP内存计算--HANA[M].北京:清华大学出版社,2013.
[5]FÄRBER F,CHA S K,PRIMSCH J,et al.SAP HANA database:Data management for modern business applications[J].ACM Sigmod Record,2012,40(4):45-51.
[6]GLIGOR G,TEODORU S.Oracle exalytics:Engineered for speed-of-thought analytics[J].Database Systems Journal,2011,2(4):3-8.
[7]WANG L,ZHOU M Q,ZHANG Z J,et al.Elastic pipelining in in-memory DataBase cluster[R].2016.
[8]TRAVERSO M.Presto:Interacting with petabytes of data at Facebook[EB/OL].(2013-11-07)[2016-06-10]. http://www.facebook.com/notes/facebook-engineering/presto-interacting-with-petabytes-of-data-at-facebook/ 10151786197628920.
[9]ARMBRUST M,XIN R S,LIAN C,et al.Spark SQL:Relational data processing in spark[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data.ACM,2015:1383-1394.
[10]YANG F,TSCHETTER E,LÉAUTÉ X,et al.Druid:A real-time analytical data store[C]//Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data.2014.
[11]GARCIA-MOLINA H,ULLMAN J D,WIDOM J.Database System Implementation[M].Upper Saddle River, NJ:Prentice Hall,2000.
[12]NAGA P N.Real-time Analytics at Massive Scale with Pinot[EB/OL].[2016-06-10].https://engineering. linkedin.com/analytics/real-time-analytics-massive-scale-pinot.
[13]KREPS J,NARKHEDE N,RAO J,et al.Kafka:A distributed messaging system for log processing [C]//Proceedings of the NetDB.2011:1-7.[14]LAMB A,FULLER M,VARADARAJAN R,et al.The vertica analytic database:C-store 7 years later [C]//Proceedings of the VLDB Endowment.2012:1790-1801.
[15]CHANG L,WANG Z,MA T,et al.Hawq:A massively parallel processing sql engine in hadoop[C]//Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data.2014.
[16]STONEBRAKER M,WEISBERG A.The VoltDB main memory DBMS[J].IEEE Data Eng Bull,2013:21-27.
[17]BRYANT R E,O′HALLARON D R.深入理解计算机系统[M].北京:机械工业出版社,2013.
[18]ESWARAN K P,GRAY J N,LORIE R A,et al.The notions of consistency and predicate locks in a database system[J].Communications of the ACM,1976,19(11):624-633.
[19]STONEBRAKER M.One Size Fits None-(Everything You Learned in Your DBMS Class is Wrong)[R/OL]. (2013-05-30)[2016-07-01].http://slideshot.epfl.ch/talks/166.
[20]WEIKUM G,VOSSEN G.Transactional Information Systems:Theory,Algorithms,and the Practice of Concurrency Control and Recovery[M].San Francisco:Morgan Kaufmann Publishers,2002.
[21]DIACONU C,FREEDMAN C,ISMERT E,et al.Hekaton:SQL server’s memory-optimized OLTP engine [C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data.2013.
[22]MICHAEL M M.High performance dynamic lock-free hash tables and list-based sets[C]//Proceedings of the 14th Annual ACM Symposium on Parallel Algorithms and Architectures.2002:73-82.
[23]LAMPSON B W,STURGIS H E.Crash Recovery in a Distributed Data Storage System[R].Palo Alto,California: Xerox Palo Alto Research Center,1979.
[24]SKEEN D.Nonblocking commit protocols[C]//Proceedings of the 1981 ACM SIGMOD International Conference on Management of Data.1981.
[25]HAN J,HAIHONG E,LE G,et al.Survey on NoSQL database[C]//Proceedings of the 2011 6th International Conference on Pervasive Computing and Applications.2011:363-366.
[26]O’NEIL E J,O’NEIL P E,WEIKUM G.The LRU-K page replacement algorithm for database disk buffering [C]//Proceedings of the ACM SIGMOD International Conference on Management of Data.1993:297-306.
(责任编辑:林磊)
Research and implementation of transactional real-time data ingestion technology without blocking
YU Kai,LI Zhi-fang,ZHOU Min-qi,ZHOU Ao-ying
(Institue for Data Science and Engineering,East China Normal University, Shanghai200062,China)
With the advent of big data era,traditional database systems are facing difficulties in satisfying the new challenges brought by massive data processing,while distributed database systems have been deployed widely in real applications.Distributed database systems partitioned and the dispatched the data across machines under a designed scheme and analyzed all the massive data in massive parallel manner.In facing of the requirements of the transactional real-time data ingestion from financial field, distributed database systems are ineffective and inefficient due to their implementation ofthe distributed transaction processing based on the lock and two-phase commit,which lead to the impossibility of non-blocking data ingestion.CLAIMS is a distributed in-memory database system designed and implemented by Institute for Data Science and Engineering of ECNU.It supports real-time data analysis towards relational data set but is incapable of real-time data ingestion.To address these problems,we analyzed data ingestion technology and distributed transaction processing algorithms first,and proposed to mimic the transactional data ingestion in the distributed environment with the centralized transaction processing based on meta data,and eventually achieved the real-time data ingestion with high availability and without blocking.The experiment results with the implementation of the proposed algorithms in CLAIMS proved that the proposed framework could achieve high throughput transactional real-time data ingestion as well as low latency real-time query processing.
distributed database system;real-time data ingestion;transaction processing;CLAIMS
TP392
A
10.3969/j.issn.1000-5641.2016.05.015
1000-5641(2016)05-0131-13
2016-05
国家自然科学基金重点项目(61332006),上海市基金(13ZR1413200)
余楷,男,硕士研究生.研究方向为内存数据库系统.E-mail:yukai@gmail.com.
周敏奇,男,副教授.研究方向为对等计算、云计算、分布式数据管理、内存数据管理系统. E-mail:mqzhou@sei.ecnu.edu.cn.
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
天津科技(2022年5期)2022-05-31
山西电子技术(2021年3期)2021-06-28
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
网络安全和信息化(2018年5期)2018-03-03
三联生活周刊(2017年44期)2017-11-01
现代计算机(2017年7期)2017-04-22
计算机应用文摘·触控(2009年15期)2009-09-27
计算机应用文摘·触控(2009年15期)2009-09-27
