
基于Clementine平台的MOOCs学习者流失分析与预测
2016-11-19 08:41高婕梅韩骏刘菁
中国教育技术装备 2016年4期
高婕梅 韩骏 刘菁

摘 要 首先提出MOOCs平台高注册率和高流失率成明显反差这一严重现象,进而提出改进MOOCs平台的一些建议,使得可以收集更多的有关学习者信息的数据,紧接着通过这些数据运用Clementine平台中的神经网络数据分析技术来研究MOOCs学习者的流失状况,建立起MOOCs学习者流失的基本模型。最后通过输入需要预测的学习者的基本数据进行神经网络流失预测,如果发现该学习者有流失的可能性,即可采取必要的措施来挽留学习者。
关键词 Clementine平台;神经网络;MOOCs平台;学习者流失
中图分类号:G434 文献标识码:A
文章编号:1671-489X(2016)04-0001-06
Loss Analysis and Prediction of MOOCs based on Clementine Neural Network//GAO Jiemei, HAN Jun, LIU Jing
Abstract In this paper, we first propose the serious phenomenon of the high registration rate and high loss rate of MOOCs platform, and then put forward some suggestions to improve the MOOCs platform, so that we can collect more information about the learner, and then use Clementine neural network data analysis technology to study the loss of learners on MOOCs platform, and establish the basic neural network model of MOOCs. Finally, input the basic data of the learners through the neural network to predict whether the learners will loss. If it is found that the learner has the possibility of loss, then it is necessary to take the necessary measures to retain the learners.
Key words Clementine; neural network; MOOCs platform; lost learners
近两年来MOOCs无论在国内还是在国外得到飞速发展,各大学都在争先恐后建立自己的MOOCs课程,但同时大规模的注册学习者却与大规模的流失率和小规模的通过率形成明显的反差。据统计,Coursera平台上的课程完成率只有7%~9%,可见大部分注册学习者在中途流失了。其中效果比较好的课程是斯坦福大学于2011年夏季开设的“人工智能”,注册学习者多达16万名,然而只有2.3万名学习者完成学业,通过率只有14%[1];杜克大学开设的“生物电学:定量方法”课程注册学生多于1万名,最后只有261名学生获得成绩证书,通过率不到3%;Edx平台上的“电路与电子”课程注册学生人数超过15万,但是最终只有7157名取得证书,完成率为4.62%[2]。那么这种高注册率和低通过率的反差能给后续课程的开设者提供什么反思呢?能否让MOOCs不再重蹈精品课程建设的覆辙呢?为了降低MOOCs的流失率,同时提高其通过率,本研究引入Clementine平台中的神经网络模型对MOOCs学习者的流失进行分析与预测,并对MOOCs平台的建设和课程开发者提供一些有效的建议。
1 Clementine
Clementine是一款数据挖掘平台,通过此平台可以快速建立预测性模型,并将其应用于后续活动之中,从而起到改进决策的作用。Clementine中提供了许多优秀的人工智能、统计分析模型,比如决策列表、数值预测器、时间序列、回归、二元分类器、逻辑回归、神经网络等[3]。此外,Clementine平台是基于图形化界面的,把这些高深的挖掘算法和技术封装起来,整个数据挖掘的全流程都可以从界面上处理和观察,使得人们更加易于操作。
本研究选择Clementine平台中的神经网络模型对MOOCs学习者的流失进行分析和预测。神经网络是模仿人类的大脑结构和功能。此模型中的处理单元是通过模拟大量类似人脑中的神经元的抽象形式,其处理方式是模仿人脑的信息加工处理方式把处理单元相互连接而作用,通过各组成部分非同步化的转变,进而实现信息的整体处理任务,同时也使其具有高速的信息处理能力[4]。
Clementine平台中的神经网络属于BP(Back Propa-gation)神经网络,一般包括输入层、中间层、输出层。输入层各神经元负责接收来自外界的输入信息,并传递给中间层;中间层是内部信息处理层,负责信息变换,可以设计为单隐层或者多隐层结构;最后一个隐层把信息传递到输出层进一步处理。BP神经网络可以实现从输入到输出的任意复杂的非线性映射关系,并具有良好的泛化能力,能够完成复杂模式识别的任务[5]。
2 MOOCs平台的改进
目前,包括“三座大山”(Edx、Udacity、Cours-era)在内的许多MOOCs平台,学习者注册时不需要填写太多的信息,主要包括用户名和电子邮箱。虽然这样简化了注册步骤,使得学习者操作简单,但同时也失去了解学习者具体情况的机会。(虽然有一些研究者做过对MOOCs学习的问卷调查,但是他们都是通过线下广泛发放问卷而并没有针对某门课的学习者进行特殊研究。)MOOCs之所以有如此多的学习者流失,就是因为其最重要的一个特点——“为学习者提供个性化学习”并没有得到真正的体现。为了能够提供个性化的学习,就需要对学习者特征进行分析,那么MOOCs平台当前收集到的学习者的信息是远远不够的。
为了能够降低某一门MOOCs的流失率,本研究建议学习者开始学习该门课程之前,必须做一个问卷表,后台可以收集问卷数据,根据收集到的样本数据,将已流失学习者和未流失学习者的属性特征作为研究对象,将数据组成训练数据集,利用Clementine平台中的神经网络进行训练,建立MOOCs学习者流失分析模型。Clementine同时提供分析模型结果值,这个值便可以说明MOOCs学习者是否有流失的可能。为了验证模型建立的准确性,可以建立与上述训练数据集结构相似的数据集合组成检验数据集,进行验证和模型评估。待验证后,即可以用建立的分析模型对现有的MOOCs学习者进行流失预测,并给出结果[6]。根据预测的结果,教师可以了解到学生流失的可能性,并做出相应的预防性措施。
表1是为了了解每位学习者的一些具体情况而设计的问卷表,学习者在MOOCs平台上开始学习一门课程之前必须进行填写,以便于该门课程的教师可以收集到数据,进而对学生流失群体进行研究。
3 基于Clementine神经网络的MOOCs学习者流失模型的构建与预测
数据指标体系的构建 根据表1的问卷可以提取出MOOCs学习者流失预测的指标体系,又因为Clementine神经网络预测模型的建立必须知道该学生最终是否流失,所以在问卷信息的基础上必须再加上是否流失这一指标。最终形成表2所示MOOCs学习者流失预测的指标体系。其中第一栏是指标,第二栏备注中把每一项指标可能的值量化为数字,便于下文研究中预测模型的构建。
建立数据库 根据MOOCs学习者流失预测的指标体系,在MySQL数据库中构建表3,并设置各个字段的属性。由于本研究是对现有的MOOCs平台提出的改进建议,并未进行真正的实施,没有得到真实的数据,因此在基于Clementine神经网络的MOOCs学习者流失模型的构建过程中,使用的数据都是通过在问卷网中发放问卷收集而来,问卷虽然没有能够针对具体某一门课程,但是仍然可以在一定程度上反映出MOOCs学习过程中学习者的流失状况,并且与真实的数据具有一致性,所以可为后续的研究提供一定的借鉴。
建立神经网络训练模型 首先在Clementine中建立神经网络训练流程,如图1所示。建立好流程后便可以开始进行具体的操作。
第一步:使用Clementine中的sql节点,连接MySQL数据库,选择表moocsinfo导入训练集数据,如图2所示。
第二步:使用过滤节点,过滤掉对训练没有用的输入输出字段。本研究中过滤掉姓名user_nm字段,如图3所示。
第三步:使用抽样节点,抽取样本数据如图4所示。由于每门MOOCs的注册学习者人数非常多,在Clementine中建立神经网络的训练数据过程中可以进行取样,采样方法有多种,可以根据具体情况选择合适的抽样方法,本研究中采用随机抽样。
第四步:使用类型节点,设置训练集的输入,输出字段如图5所示。该训练集中用户是否流失字段is_flowaway是训练集的输出字段。其他过滤后的字段作为训练集的输入字段。
第五步:使用神经网络节点训练数据,如图6所示。
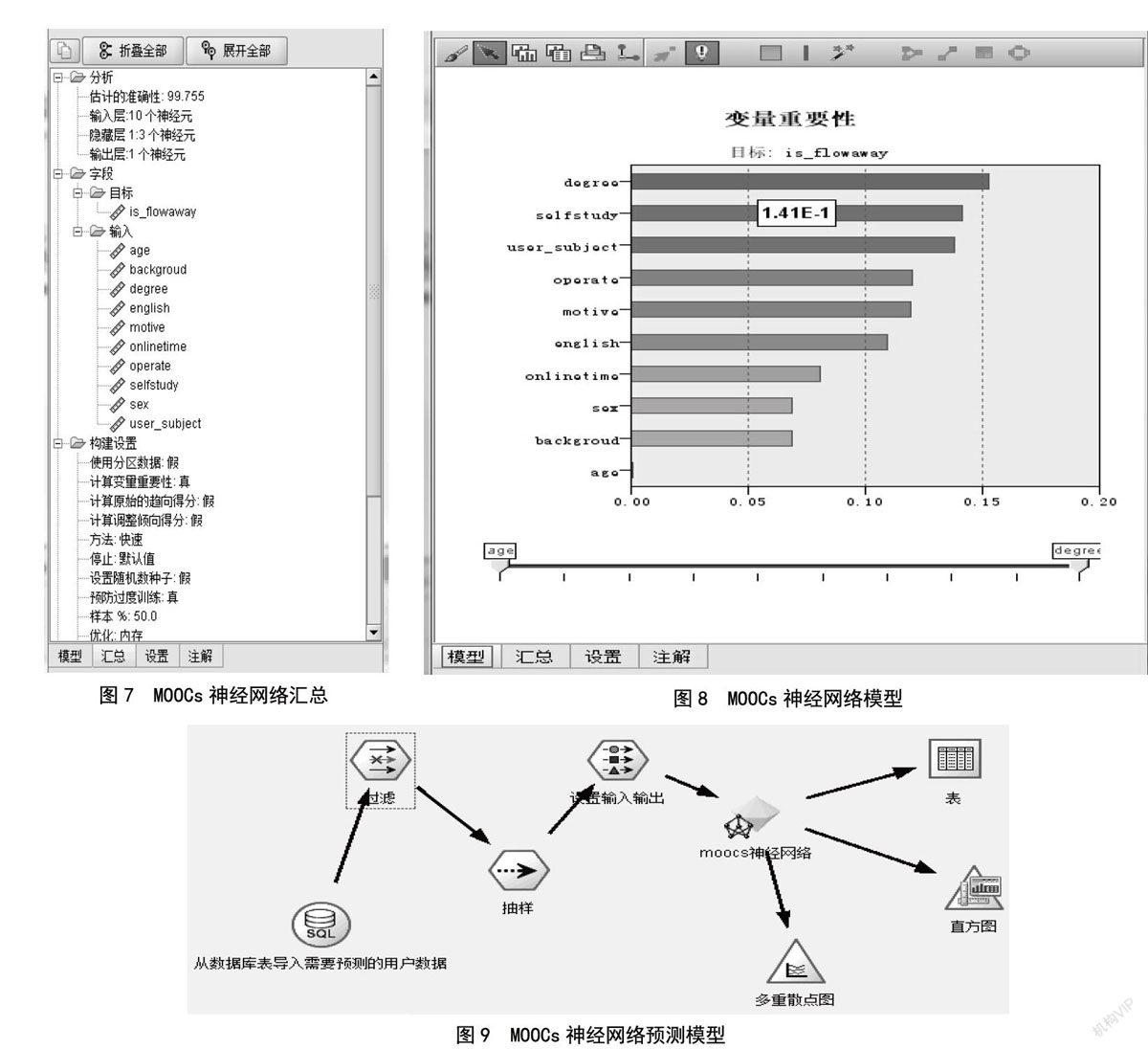
设置完成之后,基于该训练集训练出的MOOCs神经网络如图7、图8所示。图7中估计的准确性为99.755%。输入层是10个神经元,隐藏层1:3个神经元,输出层1个神经元。在真实的情况下训练的数据越多,训练出的模型会更加接近真实情况,这样预测的数据才更准确。图8中是训练出来的MOOCs神经网络中数据指标变量重要性的排列,根据变量的重要性便可得出影响MOOCs学习者流失率的重要因素。
影响MOOCs学习者流失率的重要因素分析:在图8所示的MOOCs神经网络训练模型中,变量重要性排行中最高学位(degree)居第一,原因是在收集到的问卷中,真正完成过一门MOOCs的学生,其最高学历大部分是硕士或者本科,也就是说这种学习群体更容易坚持学习完成完整的一门MOOCs;第二是自主学习能力(selfstudy),因为MOOCs是一种在线学习且没有教师的监督,需要学习者有较强的自主学习能力才能完成;第三是学科背景(user_subject),因为针对具体某一门MOOCs需要学习者有此门课程的一些学科背景知识,只有已经具备一定学科背景的人,才能够更好地完成该课程。通过对变量重要性的分析发现,该研究中得出的MOOCs神经网络模型与实际的预期基本一致,也就是说具有一定程度的准确性,当然由于指标的选取不是很准确,可能会存在一定的误差。
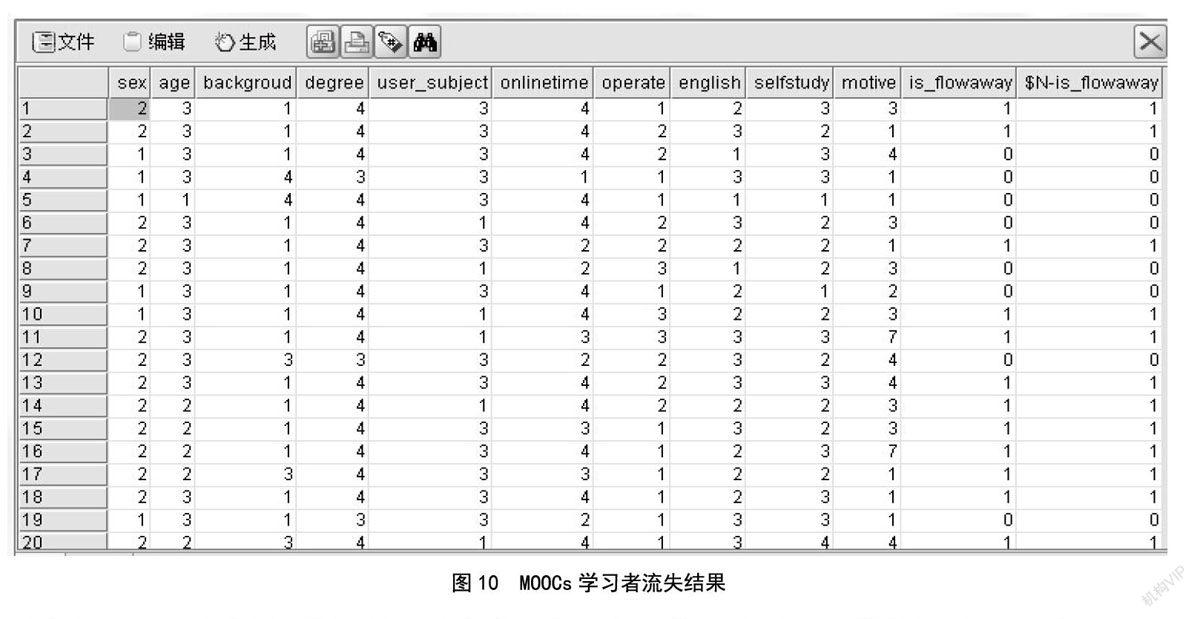
MOOCs学习者流失预测 使用上面建立的MOOCs神经网络模型对新的MOOCs学习者进行预测,在上述过程中只需要改变图中sql节点的输入数据为所需要预测的学习者的真实数据即可。在使用MOOCs神经网络节点之后,还可以使用表节点、多重散点图节点、直方图节点,进行必要的数据查看与分析,如图9所示。
双击图9中的表节点得到图10,根据图10的最后一个字段¥N-is_flowaway可以看到通过模型预测后该MOOCs学习者是否流失。其中前一列is_flowaway是预测数据真实的流失状况,二者对比可以验证出预测值与真实值基本一致。
4 挽留MOOCs即将流失学习者的对策
通过Clementine神经网络对MOOCs平台上某门课程的学习者进行流失模型的构建,该门课程的教师一方面可以从其中得出影响学习者流失的重要变量,如果是信息技术能力,那么开课教师需要为其提供一些信息技术的知识;如果是学习者的学习动机,那么教师在授课过程中或者练习测验中应该更注重激发学习者的学习动机。另一方面可以通过对新注册的学生进行流失率的计算,如果得出其流失的可能性比较大,则可以通过电话、视频、邮件等与其进行沟通,提醒上课时间并为其定时提供特殊的学习资料和辅导,真正做到个性化的服务。
5 总结
本研究在MOOCs平台大数据的背景下,提出使用Cle-mentine神经网络节点对MOOCs每门课的注册学习者进行流失率的分析与预测,来避免流失率严重这一现象。但是由于并没有真实的MOOCs平台能用来进行改进和收集实验数据,因此,该研究只是在模拟的数据上进行操作,同时如果在技术允许的条件下可以收集更多的数据指标,比如学习者的定期点击率、学习者每次上网学习的实际时间等,这些就能为准确预测流失率提供强大的依据。希望本文能够为后续的研究者和MOOCs平台的开发者提供一些新的改进方法。
参考文献
[1]姜蔺,韩锡斌,称建钢.MOOCs学习者特征及学习效果分析研究[J].中国电化教育,2013(11):54-55.
[2]刘杨,黄振中,张羽,等.中国MOOCs学习者参与情况调查报告[J].清华大学教育研究,2013(4):27-34.
[3]基于clementine神经网络的电信客户流失预测[EB/OL].
[2015-08-29].http://wenku.baidu.com/link?url=Ej0xifLjasTvvVMGS01Ym7WohOHCcvgkhGvIcHumS_4YrZhWKskX7oaWkaAUAt097FdhniDv8TadgfP3ZDTCrJf7oU9DZmfpZFLeneUg86W.
[4]林盾,张伟平.人工神经网络在教育资源管理中的应用[J].现代教育技术,2009(7):120-121.
[5]迟春佳.BP神经网络在高校图书馆网站评价中的应用[J].科技情报开发与经济,2008(15):79-80.
[6]王忠.数据挖掘技术Clementine在电信客户流失问题上的应用[J].技术应用,2010(9):89-93.
猜你喜欢
食品科学(2020年21期)2020-11-27
学生天地(2020年15期)2020-08-25
意林·少年版(2020年2期)2020-02-18
电子制作(2019年19期)2019-11-23
商情(2017年10期)2017-04-30
综艺报(2017年4期)2017-03-29
海外华文教育(2016年4期)2017-01-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
