
基于加权贝叶斯网络的隐私数据发布方法
2016-11-14 02:13王伟平
计算机研究与发展 2016年10期
王 良 王伟平 孟 丹
1(中国科学院信息工程研究所 北京 100093)2(中国科学院大学 北京 100049) (wangliang@iie.ac.cn)
基于加权贝叶斯网络的隐私数据发布方法
王 良1,2王伟平1孟 丹1
1(中国科学院信息工程研究所 北京 100093)2(中国科学院大学 北京 100049) (wangliang@iie.ac.cn)
数据发布中的隐私保护问题是目前信息安全领域的一个研究热点.如何有效地防止敏感隐私信息泄露已成为信息安全领域的重要课题.差分隐私保护技术是最新发展起来的隐私保护技术,它的最大优点是不对攻击者的背景知识做任何特定假设,该技术不但能为隐私数据发布提供强有力的安全防护,而且在实践中也得到了广泛应用.现有的差分隐私保护技术并不能全面有效地处理高维隐私数据的发布问题,虽然基于贝叶斯网络的隐私数据发布方法(PrivBayes)有效地处理了高维数据集转化为低维数据集的发布问题,但这种方法也存在一定的缺陷和不足.基于对贝叶斯网络的隐私数据发布方法的分析研究和改进优化,建立了加权贝叶斯网络隐私数据发布方法(加权PrivBayes),通过理论分析和实验评估,该方法不仅能保证原始隐私发布数据集的隐私安全性,同时又能大幅提升原始隐私发布数据集的数据精确性.
数据隐私;贝叶斯网络;隐私保护;数据发布;差分隐私
当前,许多特定的数据组织机构需要将组织机构内的原始数据(例如医院医疗数据、民意调查数据等)发布出去,以供其他组织科研机构进行研究分析或进行其他目的的应用.发布出去的原始数据集中可能包含着敏感的个人隐私信息(例如疾病、收入、存款等).数据组织机构需要将隐私数据经过特殊保护技术处理后发布出去.这些隐私保护处理技术大致分为3类:1)基于数据失真的发布技术.它能够使隐私数据失真但又保持原有数据的某些特性,例如:随机化操作、随机扰动[1-3]、凝聚[4-5]、关联规则挖掘[6]、向数据注入噪声[7-8]、交换技术[9]等.2)基于数据加密的发布技术.数据加密技术已经有了成熟的发展,例如DES加密、RSA加密等.3)基于限制条件的发布技术.根据原始数据的特性,有选择性地发布局部特性数据,例如:k-匿名隐私保护方法[10-13]、l-多样性模型[14]、t-近似模型[15].
差分隐私保护技术是基于数据失真的发布技术,该数据发布技术已经得到了深入的研究和广泛的发展,但这些技术并不能有效地处理高维数据集的发布,特别是当发布的数据集中包含大量的属性字段时,已有的发布技术[16-21]需要向数据集中注入大量的噪声信息,可能导致发布的数据集失去应用价值.Zhang等人[22]提出了PrivBayes数据发布方法,该方法基于贝叶斯网络选取高维发布数据集的属性字段,实现高维数据集向低维数据集的转化,即降低原始发布数据集中属性字段个数,以达到减小发布数据集体积的目的,同时在低维发布数据集中采用差分隐私保护处理技术,最终实现高维数据集的安全发布.虽然PrivBayes方法能够保证高维数据集的安全发布,但也存在缺陷和不足,见2.1节所述,针对这些缺陷和不足,我们改进后提出了一种新的基于贝叶斯网络的隐私数据发布方法,并命名为基于加权贝叶斯网络的隐私数据发布方法,也称为加权PrivBayes方法.加权PrivBayes方法继承了PrivBayes方法的优点,又弥补了其在选择隐私发布数据集属性字段方面的缺陷和不足,通过实验结果证明,加权PrivBayes方法既显著提升了隐私数据集发布的数据精确性又有效提高了隐私数据集发布的安全性,该方法也很好地兼顾了隐私数据泄露的安全防护和发布数据应用的价值这2个方面的问题.
本文主要探讨加权PrivBayes方法是如何提高高维数据集的发布数据的精确性和保障隐私数据的安全性,同时给出了具体的改进算法和实验证明.
1 相关工作
随着数据发布领域中对个人隐私信息安全防护级别要求的不断提升,差分隐私保护方法自从创立后,便得到了广泛的应用和快速的发展.差分隐私保护方法业已成为数据发布领域中最重要的隐私保护方法之一.
1.1 差分隐私保护方法
为了防范统计数据库中个人隐私信息泄露的安全风险,Dwork等人[23-25]提出了一种新的隐私保护方法,并命名为差分隐私保护方法,该方法能为发布数据集中的个人隐私信息提供强有力的安全保护.
定义1. 差分隐私(differential privacy)[23].对于任意2个邻近的数据集D1和D2,二者仅相差一个数据元组,Range(G)表示一个随机函数G的取值范围,Pr[Es]表示事件Es的信息安全披露风险,若随机函数G满足:
Pr[G[D1]∈S]≤eε×Pr[G[D2]∈S],
(1)
并且S⊆Range(G),那么随机函数G提供ε-差分隐私保护,其中参数ε为隐私保护预算.
差分隐私保护方法通过向发布数据集中注入适量的干扰噪声来实现发布数据集中数据元组隐私信息的安全防护,其统计学模型如图1所示:
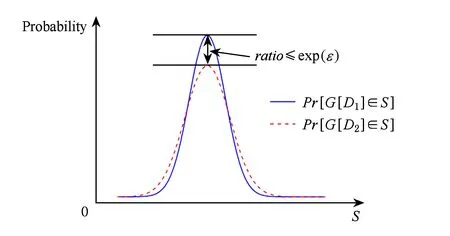
Fig. 1 The statistical model of differential privacy.图1 差分隐私的统计学模型
差分隐私保护方法的主要优点是:1)不对攻击者的能力(数据分析、推理、背景知识等)做任何特定假设;2)具有严谨的统计学模型.缺点是:1)差分隐私只考虑了在个体元组中加入适量的干扰噪声;2)参数ε没有恒定的度量标准.
差分隐私保护方法[16,26-27]的实现方法有很多种,其中最著名的且被广泛使用的2种方法是:1)拉普拉斯机制(Laplace mechanism)[24],只适用于操作发布数据集中属性值为数字类型的元组;2)指数机制(exponential mechanism)[28],仅适用于数据查询的返回值为实数值的场合.
定义2. 敏感度(sensitivity)[23].给定F是将一个数据集映射到一个固定大小实数向量的函数,那么函数F的敏感度定义为

(2)
其中,D1和D2为任意2个邻近数据集,二者仅相差一个数据元组.
函数的敏感度是由函数本身决定的,不同的函数有不同的敏感度.敏感度过低会使发布数据集安全性得不到保障,敏感度过高会使发布数据集的发布结果实用性降低.参数ε的确定标准仍然是一个未决的问题[24],在实际应用中,参数ε的取值一直缺乏一个广泛认可的标准.
1.2 贝叶斯网络
设A是原始数据集D的属性字段集合.
定义3. 贝叶斯网络N是一个有向无环图.贝叶斯网络N中的每一个结点都代表着原始数据集D中的某一个属性字段,即属性字段集合A中的某一个元素.如果N中某2个属性字段结点之间存在着直接依赖关系,则2个属性字段结点之间用一条弧(或有向边)进行直接连接.例如图2是一个具有5个属性字段结点的贝叶斯网络.
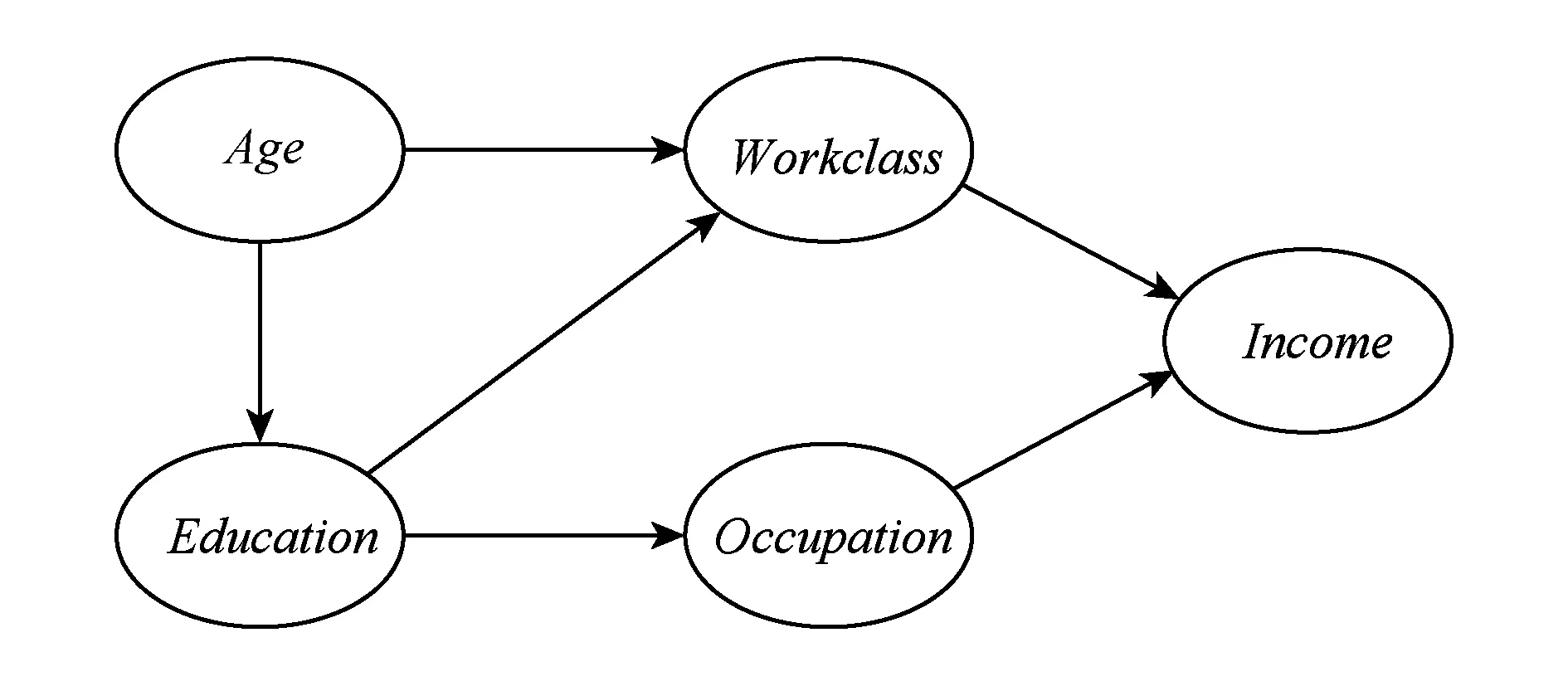
Fig. 2 A Bayesian network N over five attributes.图2 5个属性字段结点的贝叶斯网络N
定义4. 结点的入度.在贝叶斯网络N中,以某一个结点为弧头,终止于该结点弧的数目称为该结点的入度.
定义5. 结点的出度.在贝叶斯网络N中,以某一个结点为弧尾,起始于该结点弧的数目称为该结点的出度.
在贝叶斯网络N中,若存在一条从x属性字段结点到y属性字段结点的有向边,x属性字段结点为弧尾,y属性字段结点为弧头,我们称x属性字段结点为y属性字段结点的父结点.
在图2的贝叶斯网络N中,5个属性字段结点分别是Age,Workclass,Education,Occupation,Income.对于图2中任意2个属性字段结点x,y∈A,x与y之间的关系存在3种可能性:
1) 直接依赖关系.即x属性字段结点与y属性字段结点之间存在一条有向边.例如从Age属性字段结点到Workclass属性字段结点之间有一条有向边,Age属性字段结点称为弧尾,Workclass属性字段结点称为弧头,也就是说Workclass属性字段的属性值直接依赖于Age属性字段的属性值.
2) 间接依赖关系.即x属性字段结点与y属性字段结点之间不存在一条有向边,但x属性字段结点与y属性字段结点可以通过其他结点,用一条有向边路径连接起来.例如从Education属性字段结点到Income属性字段结点之间不存在一条直接有向边,但是Education属性字段结点与Income属性字段结点,可以通过Workclass属性字段结点或Occupation属性字段结点用一条有向边路径连接起来,即Education属性字段结点与Income属性字段结点之间存在2条有向边路径.换句话说,Income属性字段的属性值间接依赖于Education属性字段的属性值.Income属性字段结点的父结点集合为{Workclass,Occupation}.
3) 无依赖关系.即x属性字段结点与y属性字段结点之间不存在一条有向边或有向边路径.例如Workclass属性字段结点与Occupation属性字段结点之间就不存在任何依赖关系.
定义6. 一个具有d个属性字段结点的贝叶斯网络N可以用一个(属性字段结点,父结点集合)对集合来表示,即{(A1,Π1),(A2,Π2),…,(Ad,Πd)}.
从该定义中,我们可以得到:
1)Ai(i∈d)为属性字段集合A中的某一个元素,即某一个属性字段.
2)Πi(i∈d)为属性字段Ai父结点的集合.
3) 贝叶斯网络N中任意2个结点Ai,Aj(1≤i≤j≤d),如果Aj∉Πi,那么从Aj结点到Ai结点不存在一条有向边或有向边路径.
我们将数据集D中的元组分布记作Dt[A],我们定义一种方法利用贝叶斯网络N中d个属性字段的Dt(A1,Π1),Dt(A2,Π2),…,Dt(Ad,Πd)无限接近Dt[A].尤其是在假设条件下,对于任意Ai,Aj且Aj∉Πi无依赖关系,则可以得到:
Dt[A]=Dt[A1,A2,…,Ad-1,Ad]=Dt[A1]×
Dt[A2|A1]×…×Dt[Ad|A1,A2,…,Ad-1]=


算法1. GreedyBayes.
输入:数据集D、参数k;
输出:贝叶斯网络N.
步骤1. 初始化N=∅,V=∅;
步骤2. 从属性字段集合A中随机选取一个属性字段X1,加(X1,∅)入N,加X1入V.
步骤3. ① fori=2 toddo
② 初始化Ω=∅;

④ 加(X,Π)入集合Ω;
⑤ end for
⑥ 从集合Ω中选择最大交互信息对(Xi,Πi);
⑦ 将(Xi,Πi)加入贝叶斯网络N,将属性字段结点Xi加入V;
⑧ end for
步骤4. 返回贝叶斯网络N.
2 贝叶斯网络算法的局限性
2.1 贝叶斯网络算法描述
Zhang等人[22]在PrivBayes模型中利用算法1来构建贝叶斯网络.算法1描述了如何将高维数据集D中的属性字段集合构建成为一个贝叶斯网络.
在算法1中,步骤2随机选择一个属性字段加入贝叶斯网络N,步骤3利用贪婪算法从属性字段集合中选择d-1个属性字段结点(该属性字段结点具有最大交互信息,即入度最大的结点)加入贝叶斯网络N,步骤4输出贝叶斯网络N.

通过对算法1的分析研究,我们得出贝叶斯网络算法在对高维数据集进行发布时,存在4个缺陷和不足:
1) PrivBayes模型只考虑了属性字段之间的关系
PrivBayes模型在选取属性字段时只考虑数据集D中属性字段之间的关系,并没有考虑属性字段值的属性,这种忽略了属性字段值的设计方案,严重影响发布数据集的质量和安全.如果某-个属性字段的属性值多样性稀少,即属性值存在大量重复值的情况,发布出去的数据集将存在隐私数据泄露的安全隐患,严重威胁到发布信息的安全,或者发布出去的数据集的数据信息重复单一,失去实际应用价值.
2) PrivBayes模型选取首个属性字段的方法随机
发布的贝叶斯网络N中,属性字段的结点是有限的,这就要求N中的任何一个结点都能够真实、全面、尽可能地反映原始数据集.因此第1个属性字段不能随机选择,如果这样操作,将严重影响到发布数据集的数据质量.
3) PrivBayes模型缺乏敏感属性字段的首选机制
如果原始数据集D中存在敏感属性,那么敏感属性字段一定要出现在发布数据集中.在大多数情况下,缺少敏感属性字段的发布数据集是无任何应用价值.
4) PrivBayes模型不能解决属性字段结点在入度相同的条件下,如何选择出最优的属性字段结点的问题.
在算法1中,k值是被PrivBayes模型自动生成并且是一个非常小的值.在多个属性字段结点的入度q(1≤q≤k)值相同时,PrivBayes模型不能选择出最优的属性字段结点.
例1. 在图2的贝叶斯网络N中,一共有5个属性字段结点,它的(属性字段结点,父结点集合)对如表1所示.如果使用算法1的贪婪算法在表1中发布3个属性字段的结点时,算法1会自动生成{Income,Workclass,Education}或{Income,Workclass,Occupation}三个属性字段结点的贝叶斯网络进行数据发布,我们经过分析发现,这种选择算法仅侧重考虑了属性字段结点间交互信息的最大化,并没有充分考虑到发布数据集中数据的多样性和实际应用意义.本实例中,Age属性字段在现实生活中具有重要的实际应用价值,它能够真实反应出Income属性字段属性值分布的情况和数据的实际应用价值,因此Age属性字段结点在发布数据时是必须要进行选择的.我们依据图2中的贝叶斯网络N,人工进行选择属性字段结点发布时,会选择生成含有{Income,Occupation,Age}三个属性字段结点的贝叶斯网络进行数据发布,因为这样选择,既能增加发布数据集的数据多样性,同时还能增加发布数据集的实际应用价值.人工生成时,为什么没有选择Workclass属性字段,而选择Occupation属性字段呢?是因为Occupation属性字段值更能体现Income属性字段的属性值.另外,Age属性字段也能对Education,Occupation属性字段进行替换,也就是说Age属性字段值也能从侧面反映出这个个体的Education,Occupation情况.这种人工选择方案明显优于贪婪算法的选择方案.我们通过为贝叶斯网络N中的属性字段结点增加权重值的方法能够模拟人工选择方案,得到人工选择的结果,从而弥补算法1中选择属性字段结点方法的缺陷和不足.

Table1 The Attribute-Parent Pairs from N
5) PrivBayes模型没有考虑贝叶斯网络N中存在多个连通分量的情况.
在算法1中,如果属性字段结点的关系是紧密的,并且存在唯一的连通分量,那么输出的贝叶斯网络N会满足完整性约束条件.但是当存在多个连通分量时,输出的贝叶斯网络N应用价值会存在降低的情况.
例2. 图3是一个具有9个属性字段结点的贝叶斯网络,它的(属性字段结点,父结点集合)对如表2所示.如果使用算法1从表2中生成5个属性字段结点的贝叶斯网络时,算法1会自动选择{B,E,F,H,I}这5个属性字段结点,我们经过分析研究后发现,图3中包含着2个连通分量,自动选择{B,E,F,H,I}五个属性字段结点,全部来自第1个连通分量,而第2连通分量{C,D}中没有一个属性字段结点被选择出来.从发布数据集数据的整体性、全面性和代表性方面考虑,第2连通分量{C,D}中,至少应该有一个属性字段结点被选择发布出去.在实际的隐私数据发布处理过程中,构建的贝叶斯网络可能包含着多个连通分量,当其中某一个连通分量中各属性字段结点关系紧密时,可能会造成发布的数据集中属性字段结点相对集中.我们通过优化,计算贝叶斯网络中每个连通分量中元素的个数与所有连通分量中元素的个数总数占比来确定此连通分量中应被选择元素的个数,以达到数据均衡发布的目的.
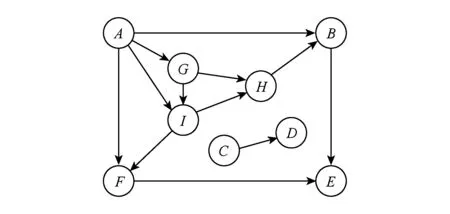
Fig. 3 A Bayesian network M over nine attributes.图3 9个属性结点的贝叶斯网络M

iAiΠi1A∅2B{A,H}3C∅4D{C}5E{B,F}6F{A,I}7G{A}8H{G,I}9I{A,G}
算法2. NoisyConditionals.
输入:数据集D、贝叶斯网络N、参数k;
输出:低维数据集P*.
步骤1. 初始化P*=∅.
步骤2. ① fori=k+1 toddo
② 构建属性结点Xi的联合分布
Dt[Xi,Πi];
④ 设Dt*[Xi,Πi]中的负值归0并正常化;
⑤ 从Dt*[Xi,Πi]提取Dt*[Xi|Πi]并加入P*;
⑥ end for
步骤3. ① fori=1 tokdo
② 从Dt*[Xk+1,Πk+1]中提取Dt*[Xi|Πi]并加入P*;
③ end for
步骤4. 返回k度的低维数据集P*.
2.2 贝叶斯网络加入噪声处理的算法
算法2展现了PrivBayes模型加入噪声的逻辑处理框架,它通过构建d-k个噪声条件分布Dt*[Xi|Πi],i∈[k+1,d]并且满足(ε2)-差分隐私,实现高维数据集的隐私安全发布.
算法2也存在缺陷和不足:
1) PrivBayes模型并没有考虑加入噪声处理时,属性字段结点的加入顺序.
2) 当PrivBayes模型在低维数据集中加入噪声时,并没有考虑属性字段属性值的多样性.如果某一个属性字段属性值过于单一,加入过多的噪声并不能提高该属性字段的安全性.相反,如果某一个属性字段的属性值过于丰富,加入过少的噪声并不能提高该属性字段的安全性.这类操作会影响到发布数据集的整体安全性.
总之,PrivBayes模型在原始数据集D中根据最大交互信息选择d个属性字段,并不能最大化相似(或接近)原始数据集,因为属性字段的属性值多样性也影响着发布数据集的数据精确性.
3 加权贝叶斯网络算法
在贝叶斯网络N中,如何在属性字段结点交互信息相同的情况下选择一个最优的属性字段结点,可以通过为属性字段结点加入权重值的方法进行解决.在理想的情况下,原始数据的所有者能够正常区分每一个属性字段的重要性,并分析所有数据元组给每一个属性字段加入一个权重值进行区分.但是,在现实情况下,我们所面对的是海量数据,要分析所有元组数据是一个不可能的任务.属性字段属性值的多样性,即属性字段属性值的不同有效值是可以通过分析有限的元组数据来获得一个非常接近最终结果值的近似值.用这种方法替代属性字段的重要程度是一个不错的选择,在实践中也是可行的.
3.1 权重值
定义7. 权重值.在一个具有d个属性字段结点的贝叶斯网络N中,为了表示每一个属性字段结点在发布数据集中的重要程度,为每一个属性字段结点增加一个数值,称为该属性字段结点的权重值或静态权重值.
图4是图2中属性字段结点加入权重值的贝叶斯网络N.
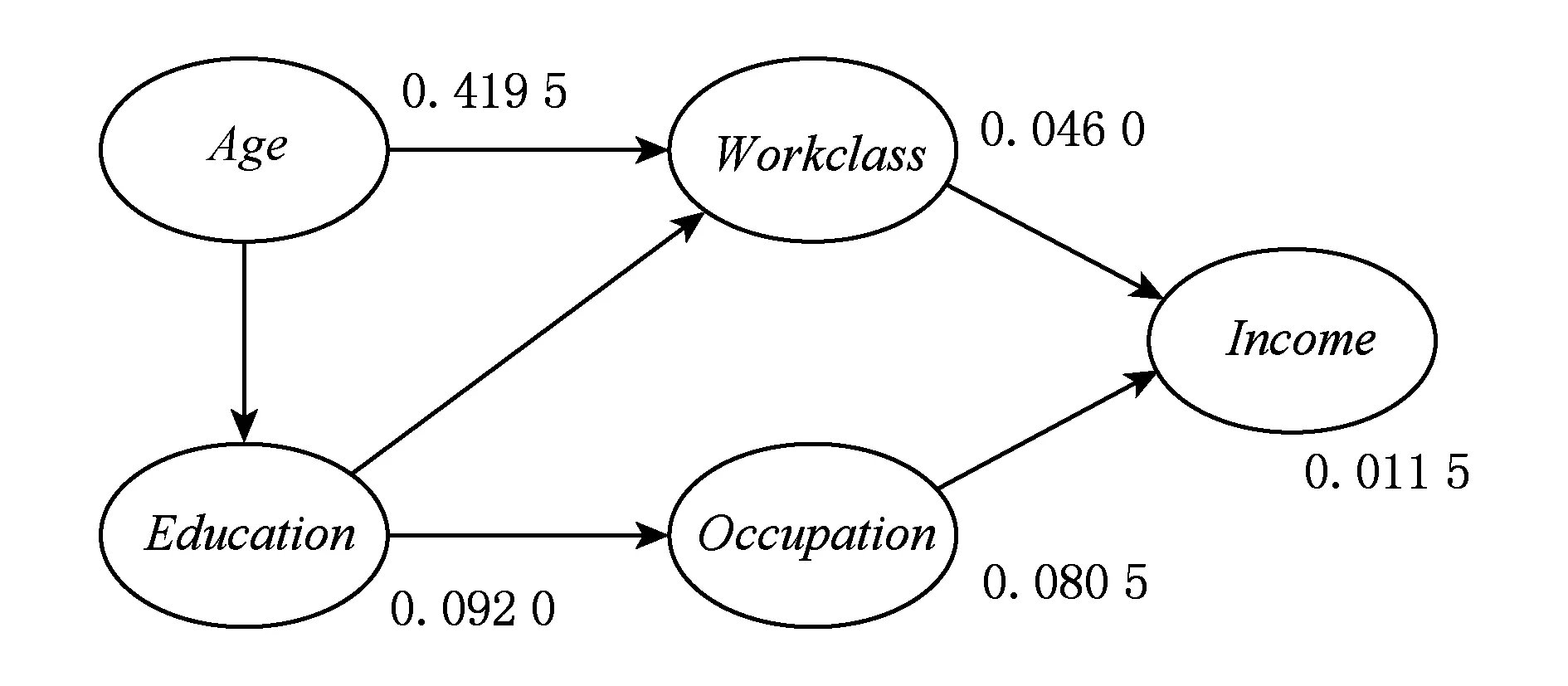
Fig. 4 A Bayesian network N over five weighted attributes.图4 5个加权属性字段结点的贝叶斯网络N
定义8. 权重值计算方法.在一个具有n个属性字段的数据集D中,由其构建的d个属性字段的贝叶斯网络N中,属性字段Ai的权重值=属性字段Ai属性值的多样性÷(属性字段A1的属性值的多样性+…+属性字段An属性值的多样性,1≤i≤d.
当原始数据集D中的元组较少时,贝叶斯网络N中的权重值可以通过定义8计算得出.如果原始数据D的元组不可计数时,属性字段属性值的多样性可以通过计算有限的元组获得接近的近似值.
例3. 在图4的贝叶斯网络N中,Age属性字段结点的权重值计算方法是:Age属性字段结点的权重值=Age属性字段属性值的多样性÷(属性字段A1属性值多样性+…+属性字段An属性值多样性)=73÷(73+8+16 +7+14+6+5+2+41+2)≈0.4195.其中,A1,A2,…,An为Adult数据集中所有属性字段.其他属性字段结点的权重值计算方法相同,Adult数据集中所有属性字段的权重值如表3所示.在表3中,列1为序号字段,列2为属性字段,列3为该属性字段属性值多样性的总数,列4为计算后的属性字段结点权重值.

Table 3 The Weights Table of Adult Data Set
定义9. 结点的动态权重值.在贝叶斯网络N中,某一个属性字段结点的权重值与该属性字段结点所有入度结点权重值平均值之差,与该属性字段结点所有出度结点权重值平均值之和,称为该属性字段结点的动态权重值.
动态权重值是我们评估贝叶斯网络N中属性字段结点的重要性的一个工具.当前属性结点的所有入度之和代表当前属性字段结点对其他结点的依赖性,该属性字段结点的出度之和代表这个属性字段结点对其他结点的贡献.
例4. 在图4的贝叶斯网络N中,属性字段结点Age的入度为0,出度为2,Age属性字段结点的动态权重值=0.4195-0+(0.0460+0.0920)2=0.4885,Workclass属性字段结点的动态权重值=0.0460-(0.4195+ 0.0920)2+0.0115=-0.19825,其他属性字段结点的动态权重值如表4所示:
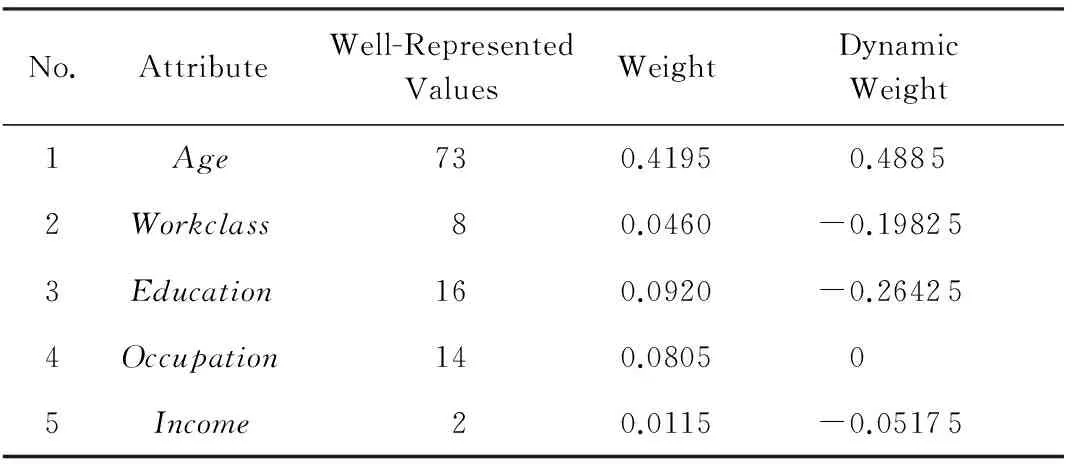
Table 4 The Dynamic Weights Table of N
在进行隐私数据集发布时,我们要尽可能地增加发布数据数值的多样性,增强发布数据的实际应用性,也就是说我们发布的低维数据集不仅要尽可能地接近原始高维数据集,而且要具有更大的应用价值.因此,我们在发布数据集时,尽可能选择具有实际代表性的数据属性字段,尽可能选择属性值丰富的属性字段,即动态权重值更大的属性字段,确保发布后的数据集无限接近原始数据集.
算法3. IAGreedyBayes.
输入:数据集D、参数k;
输出:贝叶斯网络N.
步骤1. 初始化N=∅,Z=∅;
步骤2. 计算原始数据集D中所有属性字段A1,A2,…,An的动态权重值,并标记敏感属性字段;
步骤3.m←计算属性字段集合中所有的连通分量;
步骤4. ① fori=1 tomdo
②Ci,Vi←根据d值确定每个连通分量中应该选择的属性字段结点总数,每个连通分量中属性字段结点的集合;
③ end for
步骤5. ① fori=1 tomdo
②U=∅;
③ forj=1 toCido

⑤ 将(Xi,Πi)加入N,Xi加入Z;
⑥ end for
⑦ end for
步骤6. 返回贝叶斯网络N.
3.2 加权贝叶斯网络算法描述
由于贝叶斯网络算法存在2.1节中所描述的缺陷和不足,我们基于贝叶斯网络算法提出了一个新的算法,并命名为加权贝叶斯网络算法,它不仅同时考虑了属性字段结点之间的交互信息也兼顾了属性字段属性值的多样性,并在贝叶斯网络结点中加入权重值,该算法的详细描述如算法3所示.
步骤2通过属性字段结点的权重值计算动态权重值并标记所有敏感属性;步骤3计算属性字段集合中所有的连通分量;步骤4根据输出贝叶斯网络网络中属性字段结点数d值,计算每个连通分量中应该输出的属性字段结点数目,并记录每个连通分量中的属性字段结点集合;步骤5从每个连通分量中选择出最优的属性字段结点.最后,输出贝叶斯网络.

使用算法3,对图4中的贝叶斯网络N发布3个属性字段结点时,贝叶斯网络N中所有结点的动态权重值如表4所示.贝叶斯网络N中只有一个连通分量,首先选择权重值最大的属性字段结点Age,发布{Age};其次选择动态权重值最大的属性字段结点,由于N中有敏感属性字段结点Income,因此要优先选择发布{Income},然后发布{Age,Income};再选择动态权重值最大的属性字段结点Occupation,发布{Age,Income,Occupation},所以最终发布的贝叶斯网络属性字段结点集合为{Age,Income,Occupation},与我们人工选择方案相一致,是一种最优的选择发布方案.
改进后的算法3,将原始高维数据集D转化为低维数据集D′,低维数据集D′能够最大化地贴近原始高维数据集D,使发布数据集D′的数据更具多样性,更能保留原始数据集的实际应用价值.
算法4. IANoisyConditionals.
输入:数据集D、贝叶斯网络N、参数k;
输出:低维数据集P*.
步骤1. 初始化P*=∅;
步骤2. ① fori=k+1 toddo
② 构建属性结点Xi的联合分布Pr[Xi,Πi];

④ 设Pr*[Xi,Πi]中的负值归0并正常化;
⑤ 从Pr*[Xi,Πi]提取Pr*[Xi|Πi]并加入P*;
⑥ end for
步骤3. ① fori=1 tokdo
② 从Pr*[Xk+1,Πk+1]中提取Pr*[Xi|Πi]并加入P*;
③ end for
步骤4. 返回k度的低维数据集P*.
3.3 差分隐私处理过程优化
原始高维数据集D通过构建的贝叶斯网络转化成低维数据集D′,低维数据集D′加入差分隐私算法处理后,生成最终的发布数据集.新的发布数据集与原始数据集无限接近,并且经过差分隐私保护技术处理后增强了发布数据集的安全性.Zhang等人[22]提出的算法2通过加入噪声来保障低维发布数据集的安全性.虽然此种方法能够保证发布数据集的安全性,但也存在缺陷和不足,例如在性别的属性字段中加入过量的噪声,对原有性别属性字段属性值的影响不大,可以忽略不计,在实际应用过程起到的安全防护作用并不明显,不会影响攻击者对该属性字段值的推测.如果在年龄的属性字段中加过少的噪声,会显著地影响年龄属性字段属性值的安全性,容易使攻击者在更大概率地推测出年龄属性字段属性值,在实际应用过程中造成该属性字段属性值信息泄露的安全风险.因此,需要对这个处理过程进行优化,在我们的具体实验中,对原算法2中的步骤2中第②步进行了优化处理,其他实现步骤与原算法保持一致.实验中我们使用了拉普拉斯算法,将贝叶斯网络中所有属性字段结点按动态权重值服从拉普拉斯分布进行重新序列排列,并依次加入噪声.通过这种改进,明显改善了发布数据集的安全性.
算法4使用了一个k度的贝叶斯网络N,将原始高维数据集D利用(ε2)-差分隐私保护方法,生成了低维发布数据集D′,低维发布数据集D′的安全性有充分保障.
4 实 验
我们根据实验测试结果,评估了加权贝叶斯网络隐私保护方法(加权PrivBayes)的算法运行时间;分析了经该算法处理后的发布数据集隐私信息泄露的可能性;并对该算法发布数据集的精确性进行了深入分析.同时我们也将该模型与贝叶斯网络隐私保护方法(PrivBayes)在算法运行时间、敏感隐私信息泄露的可能性、发布数据集的精确性3方面进行了对比分析.
本实验中,我们采用美国UCI(University of California,Irvine)所提供的机器学习库中的成人数据集,该数据集由美国人口普查数据组成,共计32 561个元组.在该数据集中一共选取了10个属性字段:Age,Workclass,Education,Marital-status,Race,Occupation,Relationship,Sex,Native-Country,Income.实验中所使用的软硬件参数如下: 1)操作系统:Windows7 x64 Professional Edition; 2)硬件参数:Intel CoreTMi3-370M 2.4 GHz CPU,6 GB DDR内存; 3)编译环境:Microsoft Visual Studio 2012 C++.此外,Laplace实现代码参考了Zhang等人[22]通过构建贝叶斯网络实现发布高维数据集论文实验相关代码.
4.1 安全性分析
在实验中,我们采用了差别度量方法,将加权PrivBayes隐私保护方法与PrivBayes隐私保护方法进行了数据泄露可能性对比分析,其中d=6,ε=(0.05, 0.2).d取固定值6是因为在实验中所使用的成人数据集中一共有15个属性字段,去掉5个无发布意义(多个属性字段含义相同而表示方法不同)的属性字段,剩余10个属性字段,我们认为取大于属性字段总数一半的最小值进行对比分析比较合理.原始数据集元组大小为1×105,按元组增量每104为一个度量点进行敏感属性信息泄露可能性比较,对比分析结果如图5所示.根据实验测试的数据结果,我们对比分析了这2种模型方法在数据泄露可能性方面的差异,可以得出加权PrivBayes隐私保护方法,在ε预算开销恒定的情况下,其数据泄露的可能性明显低于PrivBayes隐私保护方法,其中差分隐私保护方法(Laplace)向发布数据集注入噪声的优化和贝叶斯网络中属性结点的权重值计算选择起到了决定性的作用.从实验结果我们可以分析得出,加权PrivBayes隐私保护方法能够对高维数据集的发布提供更安全的防护.
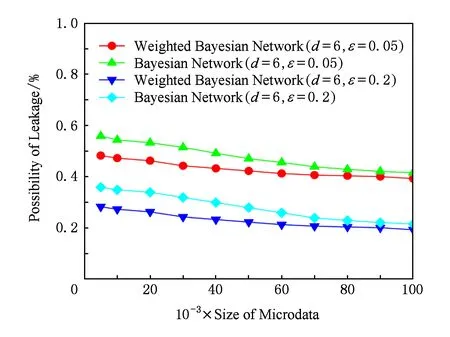
Fig. 5 The possibility of data leakage.图5 数据泄露可能性分析
4.2 时间性能分析
在实验中,我们将加权PrivBayes隐私保护方法(ε=0.05)与PrivBayes隐私保护方法(ε=0.05)按发布数据集属性字段总数由小到大进行了运行时间的对比分析,对比分析结果如图6所示.通过对运行时间的对比分析,我们发现加权PrivBayes隐私保护方法运行时间相对PrivBayes隐私保护方法运行时间较长,究其原因是由于该模型算法是构建在贝叶斯网络基础上,增加了对贝叶斯网络所有连通分量的遍历,增加了对贝叶斯网络中属性字段结点权重值的计算以及对选择最优发布属性字段的选取的判断,增加了对差分隐私保护(Laplace)向发布数据集注入噪声属性字段的优化.加权PrivBayes隐私保护方法在总体运行时间上并不优于PrivBayes隐私保护方法,它的总体运行时间相对较长.参数ε预算开销值的变化,对其整体运行时间影响非常小,可以忽略.加权PrivBayes隐私保护方法增加了系统运行时间,但却提高了发布数据集的实际应用价值和安全性,其所增加的时间是在系统使用用户可接受的范围内.
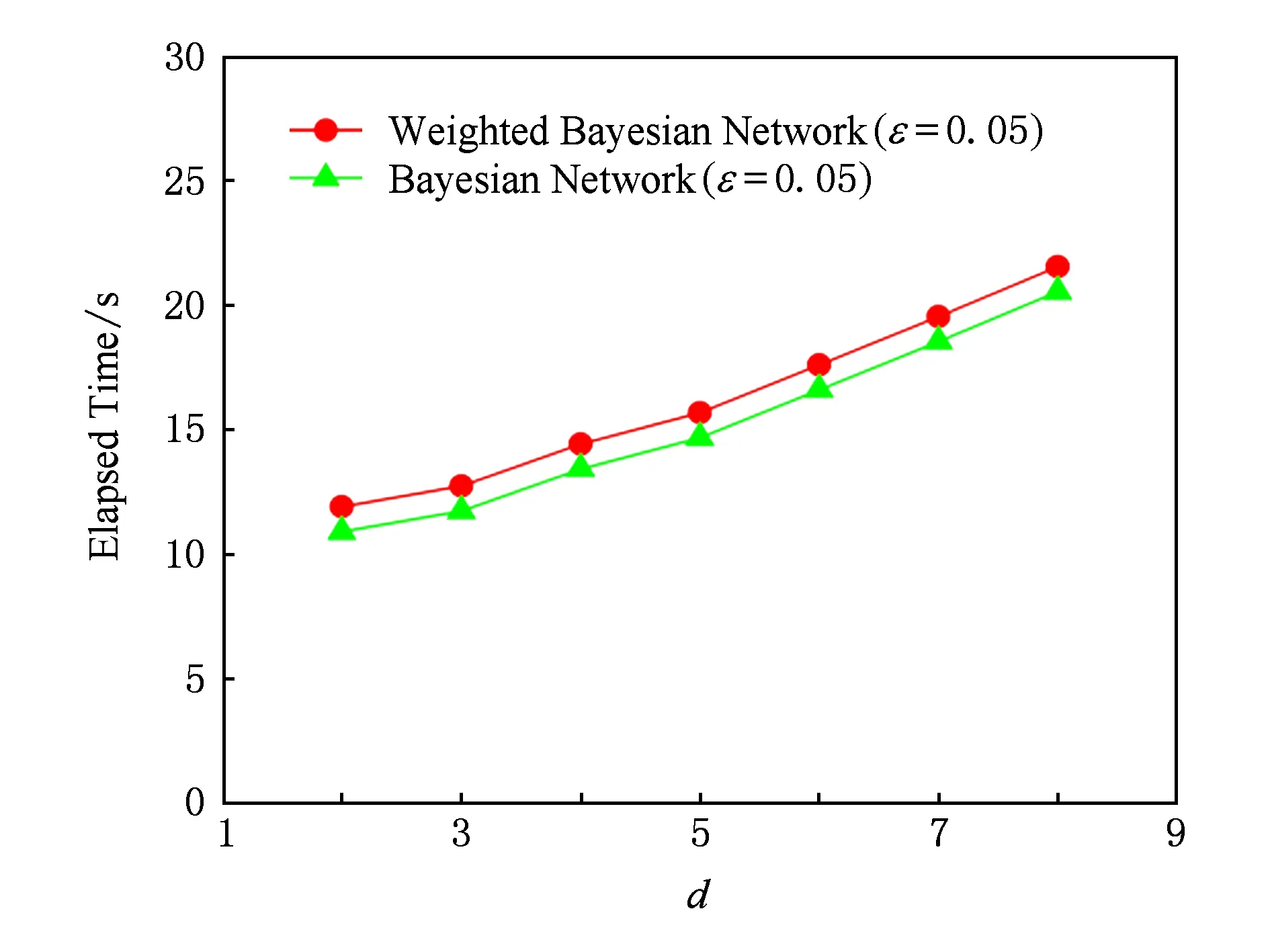
Fig. 6 The performance of the algorithms.图6 算法性能
4.3 数据质量分析
发布数据集的精确度也是衡量隐私保护方法优劣的一个极其重要指标.在本实验中,我们对原始数据集进行了降维和差分隐私保护方法(Laplace)加噪声处理,采用直接比较的方法[29-30],对处理后的数据集信息丢失率进行精确度测算.为了对比分析处理前后数据的真实对应关系,我们对原始数据进行了改造,添加了唯一标识信息,使得匿名化处理后的数据能够通过唯一标识信息找到原始数据,然后进行信息丢失率计算.对差分隐私模型处理后数据的精确度的计算,我们采用四舍五入取相邻最近数据值的方法,虽然数据的计算结果有一定误差,但根据实验后的统计分析,数据计算损失率比较低,对分析对比结果没有实质的影响,可以忽略不计,不影响实验对比结果图.实验中将d取值为2,3,4,5,6,7,8进行多批数据信息丢失率对比,结果如图7所示.从图7中可以得出随着d值的逐渐增大,发布的低维数据集数据信息精确度也逐渐增大.从图7中我们能观察到一种有趣的现象,PrivBayes的精确度是一条向下凹的弧线,随着d值的逐渐增大逐渐向上延伸,原因是PrivBayes选择的属性字段是随机的,也有交互信息最大的,这些属性字段信息反映原始数据集的数据精确度低.而加权PrivBayes的精确度是一条向上凸的弧线,随着d值的逐渐增大逐渐向上缓慢延伸,这是因为加权PrivBayes选择的属性字段从一开始就考虑了属性字段属性值的多样性,这些属性字段属性值能最大化贴近原始数据集,因此这些属性字段信息反映原始数据集的数据精确度高.通过实验对比分析结果,加权PrivBayes隐私保护方法在发布数据集的精确性上明显优于PrivBayes隐私保护方法.
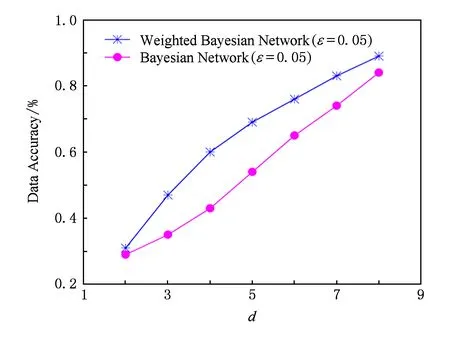
Fig. 7 The accuracy of published dataset.图7 发布数据集精确性对比
5 结束语
本文阐述了PrivBayes模型的实现方法,并分析了PrivBayes模型存在的缺陷和不足.针对PrivBayes模型不能保证发布高质量的数据集、不能有效地防止敏感属性信息泄露的问题,我们对PrivBayes模型进行了优化处理,提出了加权PrivBayes隐私保护方法,该方法考虑了属性字段属性值的多样性,对贝叶斯网络中的结点增加权重值,优化选择的属性字段结点加入噪声时的顺序服从拉普拉斯分布.我们通过样例分析和真实的实验数据结果证明,加权PrivBayes模型较之PrivBayes模型在发布数据集的数据精确性和安全性方面都有显著的提升.
我们将在下一步的实验工作中在研究内容和研究方向进行扩展,首先,我们将与更多的隐私保护模型进行实验对比分析,本文仅限于与PrivBayes模型的对比;其次,我们将对更多的实验测试数据集进行实验对比分析;最后,我们将利用海量原始数据集的所有元组统计分析结果替代属性字段属性值的多样性,研究这种替代方法是否具有更高的发布数据集数据精确性、安全性和可行性.
[1]Muralidhar K, Sarathy R. Security of random data perturbation methods[J]. ACM Trans on Database Systems, 1999, 24(4): 487-493
[2]Kargupta H, Datta S, Wang Q, et al. On the privacy preserving properties of random data perturbation techniques[C] //Proc of the 3rd Int Conf on Data Mining. Piscataway, NJ: IEEE, 2003: 99-106
[3]Chen K, Liu L. Privacy preserving data classification with rotation perturbation[C] //Proc of the 5th Int Conf on Data Mining. Piscataway, NJ: IEEE, 2005: 4
[4]Aggarwal C C, Philip S Y. A condensation approach to privacy preserving data mining[C] //Proc of Int Conf on Extending Database Technology. Berlin: Springer, 2004: 183-199
[5]Aggarwal C C, Yu P S. On static and dynamic methods for condensation-based privacy-preserving data mining[J]. ACM Trans on Database Systems, 2008, 33(1): 41-79
[6]Evfimievski A, Srikant R, Agrawal R, et al. Privacy preserving mining of association rules[J]. Information Systems, 2004, 29(4): 343-364
[7]Zhang X, Wu Y, Wang X. Differential privacy data release through adding noise on average value[G] //Network and System Security. Berlin: Springer, 2012: 417-429
[8]Dwork C, McSherry F, Nissim K, et al. Calibrating noise to sensitivity in private data analysis[G] //Theory of Cryptography. Berlin: Springer, 2006: 265-284
[9]Li M, Sampigethaya K, Huang L, et al. Swing & swap: User-centric approaches towards maximizing location privacy[C] //Proc of the 5th ACM Workshop on Privacy in Electronic Society. New York: ACM, 2006: 19-28
[10]Sweeney L.k-anonymity: A model for protecting privacy[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 557-570[11]Sweeney L. Achievingk-anonymity privacy protection using generalization and suppression[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2002, 10(5): 571-588
[12]Wong R C W, Li J, Fu A W C, et al. (α,k)-anonymity: An enhancedk-anonymity model for privacy preserving data publishing[C] //Proc of the 12th Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2006: 754-759
[13]Xiao X, Tao Y. Personalized privacy preservation[C] //Proc of the 2006 Int Conf on Management of Data. New York: ACM, 2006: 229-240
[14]Machanavajjhala A, Kifer D, Gehrke J, et al.l-diversity: Privacy beyondk-anonymity[J]. ACM Trans on Knowledge Discovery from Data, 2007, 1(1): 3
[15]Li N, Li T, Venkatasubramanian S.t-closeness: Privacy beyondk-anonymity andl-diversity[C] //Proc of the 23rd Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2007: 106-115
[16]Xiao X, Wang G, Gehrke J. Differential privacy via wavelet transforms[J]. IEEE Trans on Knowledge and Data Engineering, 2011, 23(8): 1200-1214
[17]Barak B, Chaudhuri K, Dwork C, et al. Privacy, accuracy, and consistency too: A holistic solution to contingency table release[C] //Proc of the 26th Symp on Principles of Database Systems. New York: ACM, 2007: 273-282
[18]LeFevre K, DeWitt D J, Ramakrishnan R. Incognito: Efficient full-domaink-anonymity[C] //Proc of the 2005 Int Conf on Management of Data. New York: ACM, 2005: 49-60
[19]Xiao X, Wang G, Gehrke J. Interactive anonymization of sensitive data[C] //Proc of the 2009 Int Conf on Management of Data. New York: ACM, 2009: 1051-1054
[20]McSherry F, Talwar K. Mechanism design via differential privacy[C] //Proc of the 48th Annual IEEE Symp on Foundations of Computer Science. Piscataway, NJ: IEEE, 2007: 94-103
[21]Nissim K, Smorodinsky R, Tennenholtz M. Approximately optimal mechanism design via differential privacy[C] //Proc of the 3rd Innovations in Theoretical Computer Science Conf. New York: ACM, 2012: 203-213
[22]Zhang J, Cormode G, Procopiuc C M, et al. PrivBayes: Private data release via Bayesian networks[C] //Proc of the 2014 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2014: 1423-1434
[23]Dwork C. Differential privacy: A survey of results[G] //Proc of Int Conf on Theory and Applications of Models of Computation. Berlin: Springer, 2008: 1-19
[24]Dwork C. Differential Privacy[M]. Berlin: Springer, 2011: 338-340
[25]Dwork C, McSherry F, Nissim K, et al. Calibrating noise to sensitivity in private data analysis[G] //Theory of cryptography. Berlin: Springer, 2006: 265-284
[26]Ding B, Winslett M, Han J, et al. Differentially private data cubes: Optimizing noise sources and consistency[C] //Proc of the 2011 Int Conf on Management of Data. New York: ACM, 2011: 217-228
[27]Hay M, Rastogi V, Miklau G, et al. Boosting the accuracy of differentially private histograms through consistency[J].Proceedings of the VLDB Endowment, 2010, 3(1-2): 1021-1032
[28]Cormode G, Procopiuc C, Srivastava D, et al. Differentially private spatial decompositions[C] //Porc of the 28th Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2012: 20-31
[29]Navarro-Arribas G, Torra V, Erola A, et al. Userk-anonymity for privacy preserving data mining of query logs[J]. Information Processing & Management, 2012, 48(3): 476-487
[30]Lixia W, Jianmin H. Utility evaluation ofk-anonymous data by microaggregation[C] //Proc of the 2009 Int Conf on Communication System, Networks and Applications. Piscataway, NJ: IEEE, 2009: 381-384

Wang Liang, born in 1975. PhD candidate of the Institute of Information Engineering, Chinese Academy of Sciences. Member of China Computer Federation. His main research interests include information security, and process of big data.

Wang Weiping, born in 1975. PhD. Professor of the Institute of Information Engineering, Chinese Academy of Sciences. Member of China Computer Federation. His main research interests include database technologies, storage and process of big data, and cloud computing(wangweiping@iie.acn.cn).

Meng Dan, born in 1965. PhD. Professor of the Institute of Information Engineering, Chinese Academy of Sciences. Fellow member of China Computer Federation. His main research interests include cloud computing and system security(mengdan@iie.ac.cn).
Privacy Preserving Data Publishing via Weighted Bayesian Networks
Wang Liang1,2, Wang Weiping1, and Meng Dan1
1(InstituteofInformationEngineering,ChineseAcademyofSciences,Beijing100093)2(UniversityofChineseAcademyofSciences,Beijing100049)
Privacy preserving in data publishing is a hot topic in the field of information security currently. How to effectively prevent the disclosure of sensitive information has become a major issue in enabling public access to the published dataset that contain personal information. As a newly developed notion of privacy preserving, differential privacy can provide strong security protection due to its greatest advantage of not making any specific assumptions on the attacker's background, and has been extensively studied. The existing approaches of differential privacy cannot fully and effectively solve the problem of releasing high-dimensional data. Although the PrivBayes can transform high-dimensional data to low-dimensional one, but cannot prevent attributes disclosure on certain conditions, and also has some limitations and shortcomings. In this paper, to solve these problems, we propose a new and powerful improved algorithm for data publishing called weighted PrivBayes. In this new algorithm, thorough both theoretical analysis and experiment evaluation, not only guarantee the security of the published dataset but also significantly improve the data accuracy and practical value than PrivBayes.
data privacy; Bayesian network; privacy preserving; data publishing; differential privacy
2016-06-20;
2016-08-15
国家“八六三”高技术研究发展计划基金项目(2013AA013204);中国科学院战略性先导科技专项课题(XDA06030200)
TP309.2
This work was supported by the National High Technology Research and Development Program of China (863 Program) (2013AA013204) and the State Priority Research Program of the Chinese Academy of Sciences (XDA06030200).
猜你喜欢
China Report Asean(2022年8期)2022-09-02
江苏科技信息(2022年16期)2022-07-17
电子制作(2021年14期)2021-08-21
物联网技术(2020年12期)2021-01-27
数学物理学报(2018年1期)2018-03-26
汽车零部件(2017年4期)2017-07-12
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
电子设计工程(2014年12期)2014-02-27
图书馆建设(2014年3期)2014-02-12
