
时空上下文编码的视频拷贝检测*
2016-11-04 09:11王荣波孙小雪张江丰
传感器与微系统 2016年11期
王荣波,陈 浩,孙小雪,张江丰
(1.杭州电子科技大学 认知与智能计算研究所,浙江 杭州 310018;2.国网浙江省电力公司电力科学研究院,浙江 杭州 310014)
时空上下文编码的视频拷贝检测*
王荣波1,陈 浩1,孙小雪1,张江丰2
(1.杭州电子科技大学 认知与智能计算研究所,浙江 杭州 310018;2.国网浙江省电力公司电力科学研究院,浙江 杭州 310014)
基于内容的视频拷贝检测,目前最流行的方法是基于词袋模型的关键帧内容匹配方法。由于在空间上丢失了视觉词汇的上下文信息,而在时域中,同样丢失了关键帧时域上下文信息,此类方法的精度受到限制。针对这一问题,通过使用一个上下文模型用于计算视频关键帧的空间上下文信息和时域上下文信息,同时将时空上下文信息量化成二进制编码,并通过海明距离实现快速的时空上下文验证。在TREVID—2009视频集上的实验验证了该算法具有较高的效率与准确性。
视频拷贝检测; 词袋模型; 上下文编码
0 引 言
如今随着网络视频共享的急速发展以及数字视频的编辑、发送和拷贝变得越来越容易,数字版权保护遇到了新的挑战。基于内容的视频拷贝检测利用了“视频本身就是水印”的事实,越来越受到研究者的关注,基于内容的视频拷贝检测正在成为替代传统的水印方法来应付数字视频盗版和非法传播等问题的重要技术。
基于内容的视频拷贝检测算法主要由两个关键技术组成,即特征表示和视频匹配。
在现有的工作中使用的特征可以分为两类,即全局特征和局部特征。全局特征一般是根据整个帧或整个剪辑片段的统计信息,因此,它们具有紧凑性和低计算复杂度的优点,如Kim C等人[1]提出的签名特征是基于帧图像的全局统计特征的。然而全局特征不能有效处理更复杂的变换,如视频后期处理时通常丢弃或替换原始帧或原始片段中的某个区域。相反,局部特征本质上对这些保留部分原始内容的变换具有抵抗性。在视频拷贝检测中使用的局部特征大多数是基于兴趣点的检测和局部描述子的计算,如SIFT,SURF,PCA—SIFT等。除了空间特征,时间特征也是视频拷贝检测时的重要特征,Shivakumar N等人[2]提出了利用视频拍摄时间作为时间特征参与检测,而Cheung S S等人[3]则使用关键帧的位置信息作为相似度计算的一个重要因素。同样,时间差特征[1]和时间序特征[4]被用于视频拷贝检测。
视频匹配方法主要分为两类,即顺序匹配[4]和帧融合匹配[5,6]。顺序匹配的基本思路是两个视频片段直接帧到帧匹配。由于一个查询序列通常比参考序列短得多,因此使用滑动窗口算法遍历式进行序列匹配。顺序匹配的主要缺点是与查询序列匹配的所有可能的参考子序列众多而导致较高计算复杂度。此外,序列匹配不能有效检测和定位涉及丢帧的拷贝变换。而帧融合匹配算法的主要思想是通过每一个查询帧在参考序列库中搜索相似的参考帧列表,最后将参考帧列表融合并确定查询序列是否为融合后的参考序列的拷贝。基于帧融合的匹配并没有适当时间融合机制,因此拷贝片段很难被精确检测和定位。
1 基于时空上下文编码的视频拷贝检测
针对已有工作的不足,本文提出了一种编码时空上下文信息的方法,利用这个编码弥补词袋模型在量化时丢失的上下文空间信息,同时加强关键帧在时间域中的描述信息。在空间上,主要通过以关键帧的中心为起点均匀的将空间划分为k块区域,根据这些区域包含的局部特征构建关键帧空间上下文描述信息,而在时域上,主要通过关键帧所在的时域范围内的普通帧构建关键帧的时间上下文信息。
为了加速匹配,将时空上下文信息量化为二进制码,并使用海明距离作为相似度评测方法,本文算法相比传统的拷贝检测算法具有较高拷的精度和速度,在TREVID—2009视频库上的实验已证明该方法具有很好的效果。基于时空上下文编码的视频拷贝检测框架如图1所示。本文主要对时空上下文编码的生成过程和序列匹配方法进行详细讲解。
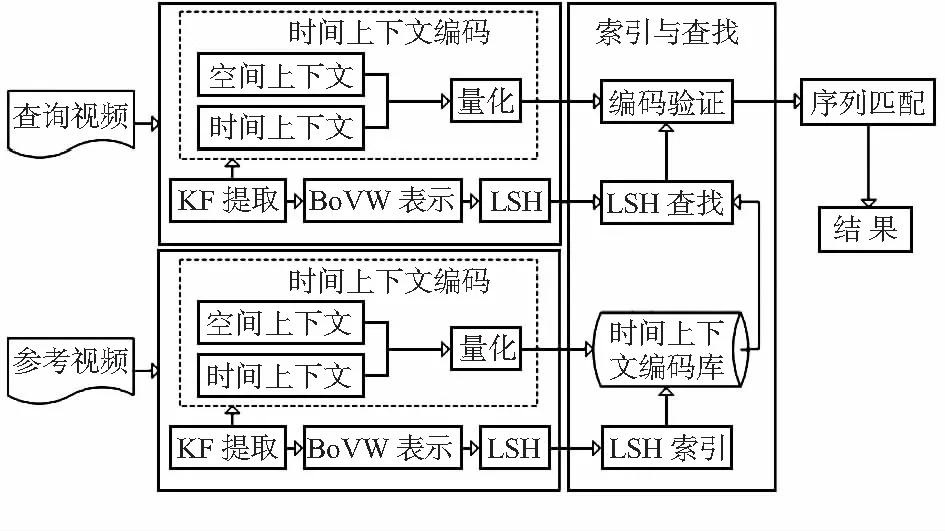
图1 基于时空上下文编码的拷贝检测框架Fig 1 Framework of video copy detection based on spatial-temporal contextual code
2 时空上下文信息
关键帧的上下文是关键帧在视频中所处的周围环境,它在视频处理中的价值主要体现为在视频处理应用问题的解决过程中,上下文扮演者解决问题所需的信息和资源提供者的重要角色。当前视频拷贝检测中,采用关键帧的内容的集合表示一个视频的方式,本来就丢失了关键帧的周围环境信息,所以有必要把单个关键帧和它作用域中的普通帧同时加以考虑。
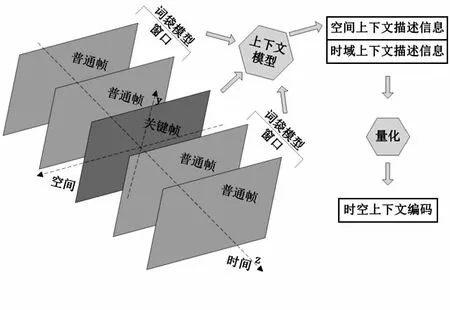
图2 时空上下文编码原理Fig 2 Principle of spatial-temporal contextual coding
通常上下文的选取是基于核心关键帧左右一定范围进行的,这个固定的范围被称为"窗口"。时空上下文编码的生成过程如图2所示。在空间上,通过关键帧内容包含的局部特征生成一个体现关键帧内容的上下文,在时域中,通过关键帧前后"窗口"内的普通帧生成一个用于描述关键帧环境信息的时域上下文,接下来进行详细讲解。
2.1 量化策略
接下来介绍如何将高维向量量化成二进制码,对于给定的高维向量R,首先通过公式(1)将其投影到低维空间Rp为
RP=P·R
(1)
式中 P为一个随机生成且元素为1或-1的投影矩阵。然后,高维向量R的二进制码向量可以通过公式(2)得到
B=sgn(RP)
(2)
式中 sgn(·)为一个应用于每一个维度的符号函数,即当值为正时返回1,当值为负时返回0。最后通过二进制码向量即可获得高维向量R的二进制码。
2.2 上下文模型
对于给定的中心,通过其周围的元素分布构建用于描述该中心的上下文环境信息。其数学模型如下,定义周围元素的集合为S、周围元素特征向量集合为D={di|ei∈S},则用于描述中心上下文环境的上下文向量可以定义为
(3)
式中 di和wi分别为周围元素ei的特征向量和权重。
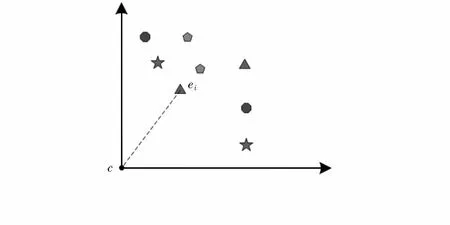
图3 中心周围元素分布Fig 3 Distribution of elements surrounding center
为了抵抗在各种变换下周围元素的丢失,为每一元素赋予不同的权重。如图3所示,根据周围元素距离中心元素的距离为其分配重要性,权重wi定义如下
wi=e-t‖Ic-Ii‖2
(4)
式中 |‖lc-li‖为周围元素ei与中心C之间的距离,直观的说,分配较小的权重给距离中心较远的元素,分配较大的权重给距离中心较近的元素。参数t用于控制参与描述上下文信息的周围元素的数量,即在时域上,控制核心关键帧左右范围“窗口”的大小,在空间上控制包含内容的多少。
2.3 空间上下文
在关键帧的SIFT特征提取完毕之后可以获得每一关键帧中所有局部特征的基本信息(如位置、尺度、主方向、描述子等),通过局部特征的位置信息计算出关键帧的中心并将图像空间均匀的划分为k块区域,如图4所示,最后为每块区域计算上下文向量从而构建关键帧空间上下文向量。
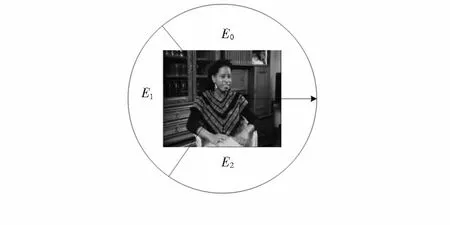
图4 空间上下文Fig 4 Spatial context
1)计算局部特征中心:考虑到部分变换会改变原始帧的图像中心,因此,计算局部特征所在的中心作为划分k块区域的中心。假设在特征提取完毕之后得到局部特征的位置坐标为f1(x1,y1),f2(x2,y2),…,fn(xn,yn),则局部特征中心坐标fc(xc,yc)通过式(5)、式(6)计算获得
(5)
(6)
2)计算空间上下文向量:在k块区域划分后,定义Sk和Dk={di|ei∈Sk}表示第k块区域中的局部特征和SIFT描述子的集合。将每块区域中的局部特征看成以中心分布的元素,SIFT描述子为元素的特征向量,通过式(3)可以计算出每一块区域的上下文向量,最后将所有的Ek连接起来得到关键帧空间上下文向量ES=[E1E2…Ek…]。
2.4 时间上下文
时间上下文信息用于描述关键帧所在视频中的上下文环境信息,如包含关键帧之前后的环境信息,这类信息对于关键帧的匹配有着重要作用。如何图5所示,每个关键帧在时间域中都围绕着众多的普通帧,通过使用这些普通帧来构建关键帧的时间上下文信息。下面详细介绍时间上下文的具体步骤。
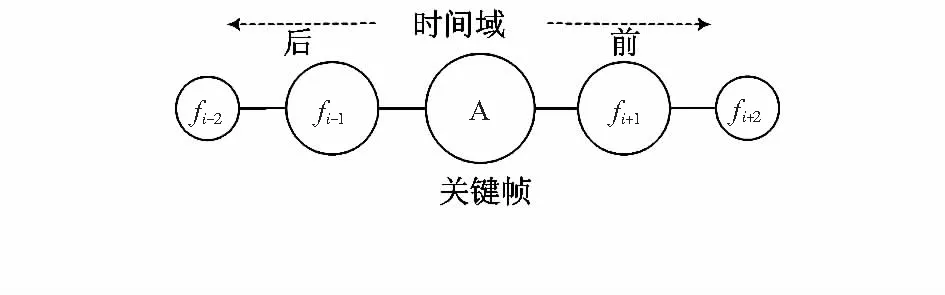
图5 时域上下文Fig 5 Temporal context
定义关键帧A的前后普通帧的集合分别为Sb和Sf。特征向量的集合分别是Db={bi|fi∈Sb}和Df={bi|fi∈Sf},其中bi为普通帧fi使用词袋模型统计的词频向量。通过公式(3)可以计算出关键帧A的前后上下文向量Eb和Ef。最后关键帧的时域上下文向量为ET=[EbEf]。在实验中,为了降低计算复杂度,每5帧选取一帧加入集合为Sb和Sf。
2.5 时空上下文编码
在经过2.3节和2.4节的计算之后获得了关键帧的空间上下文向量ES和时间上下文向量ET。为了使时空上下文信息容易存储和易于相似度计算,需要将上述高维向量量化成二进制码。本文使用2.1节中的量化方法对关键帧的空间上下文向量ES和时间上下文向量ET进行量化分别得到空间上下文编码BS和时间上下文编码BT,最后将它们组合起来得到关键帧的时空上下文编码BST=[BSBT]。在试验中,选取的时空上下文编码的长度为256位。
3 关键帧索引
为了得到更精确的初始匹配和改善检索性能,需要为海量的视频关键帧建立索引。在使用词袋模型之后,每一个关键帧都可以用一个给定的视觉词典统计的词频向量表示。因此,以该词频向量为依据,使用局部敏感哈希算法[7]将关键帧投影到不同的桶中,以此为视频库关键帧建立索引。由于只有相似的关键帧才能被投影到同一个桶中,因此在相似性关键帧查询时可以明显提高效率,如图6所示,索引结构中的每一项包含关键帧编号和时空上下文编码。
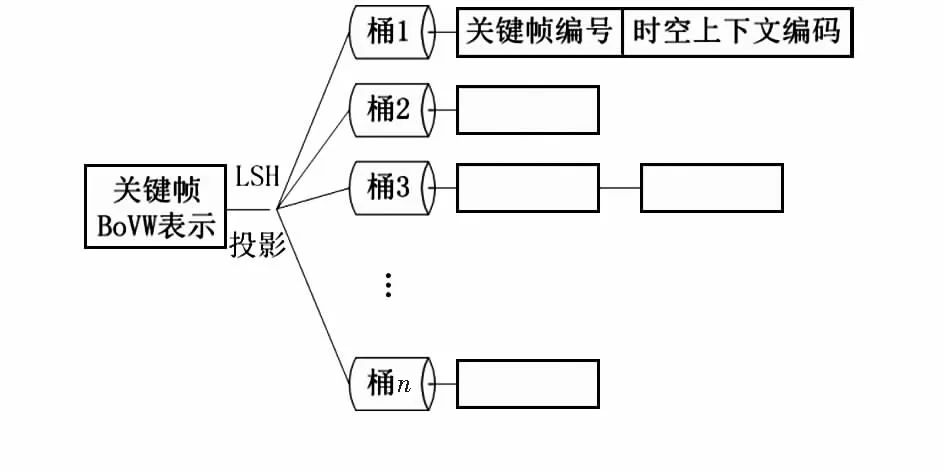
图6 局部敏感哈希投影Fig 6 Projection by local sensitive Hash
4 序列匹配
序列匹配的目的在于通过给定的查询视频在参考视频中定位其拷贝片段。本文提出一种基于最长公共子序列的合算法对拷贝的片段进行定位。图7说明了一个简单的例子。该过程主要由两个步骤分别是构建序列匹配矩阵和子序列融合,接下来详细讲解两个步骤。
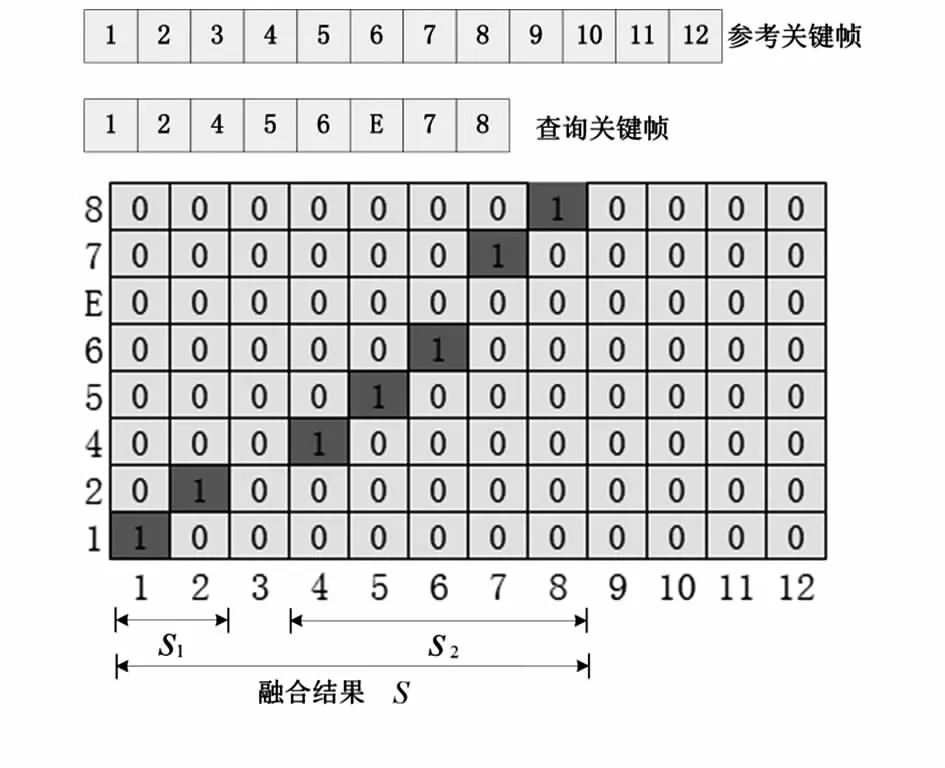
图7 序列匹配例子Fig 7 Example of sequence matching
1)构建序列匹配矩阵
序列匹配矩阵用于描述参考视频关键帧与查询视频关键帧的相似性匹配状态。通过式(7)构建一个二维的序列匹配矩阵
(7)
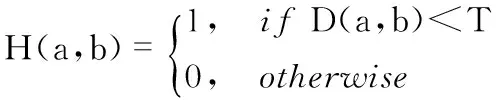
(8)
2)最长公共子序列融合算法
在序列匹配矩阵构建完毕后,使用最长公共子序列算法查找出一个最长的匹配序列S=(s1,s2,s3,…,sn),其中,sn是一个连续的子序列。最后通过式(9)计算S中两个连续的子序列之间的间隔大小来决定是否需要融合,从而获得一个最长的连续序列。
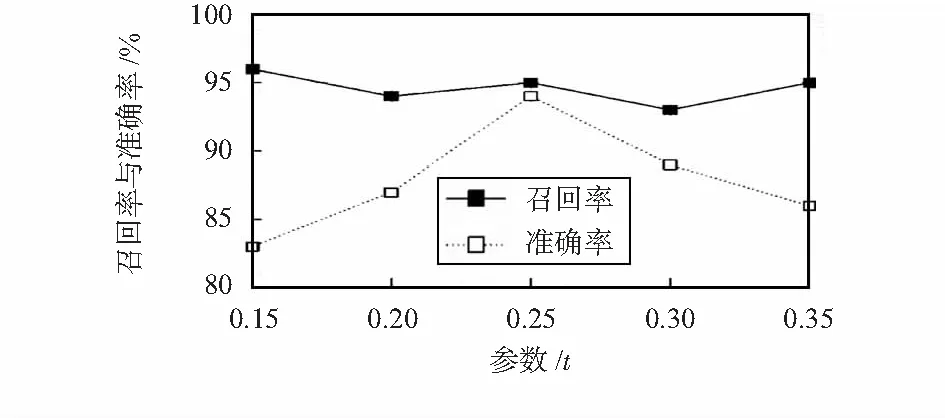
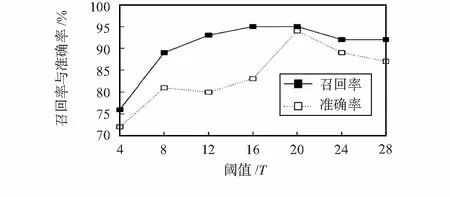
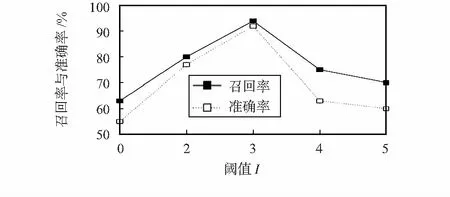
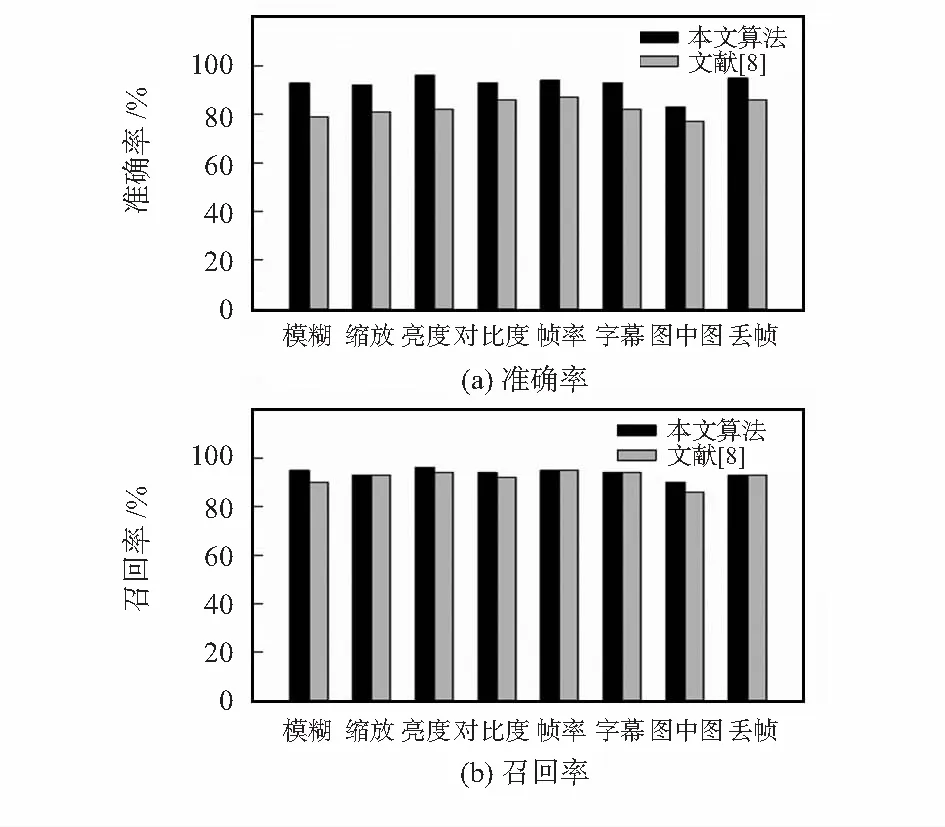
dist(sn-1,sn) (9) 式中 dist(sn-1,sn)为子序列sn-1和sn之间的间隔大小,I为一个给定的阈值,算法思想如表1所示。 为了验证本文提出的基于上下文编码的视频拷贝检测方法的有效性,本文对400段参考视频及其对应的拷贝视频进行测试实验。本文使用的测试视频均来自TRECVID—2009视频库。查询视频是随机从400段参考视频中截取的200个60 s的视频片段,分别进行模糊、缩放、亮度改变、高斯噪声、图中图、平移,改变帧率以及嵌入字幕8种方式进行攻击,共产生1 200段拷贝视频用于拷贝检测。 5.1 参数选择 本节将通过实验结果分析,参数t、阈值T和阈值I在 表1 最长公共子序列融合算法 不同取值下的实验性能。为了简化实验,选取划分的区块数k=3,同时选取召回率与准确率作为评估标准。 式(4)中参数t对性能的影响如图8所示,当t取值很小时,较少的空间上下文信息被记录,然而当t取值很大时,较多嘈杂的空间上下文信息被包括。正如图8所示,在t=0.25时可以获得最佳的性能。 图8 参数t对性能的影响Fig 8 Impact of parameter t on characteristics 图9显示时空上下文编码受不同阈值T取值的影响情况,可以观察出当T=20时具有较好的查询效果,召回率与准确率均在90 %以上,表明本文算法能够满足使用要求。 图9 阈值T对性能的影响Fig 9 Impact of threshold T on characteristics 图10显示了基于最长公共子序列的融合方法受到不同阈值I的影响情况,当I较小时,很多正确的子序列无法被合并,当I叫大时,很多干扰子序列被合并,可以观察出当I=3时具有较好的性能。 图10 阈值I对性能的影响Fig 10 Impact of threshold I on characteristics 5.2 性能评估 为了验证本算法具有较好的效果,将本文算法和其他算法的效果。文献[8]中的算法是一种常见的视频拷贝检测算法。当t=0.25,T=20,I=3时,使用一些较难处理的拷贝变换下的查询视频,分别使用本算法和文献[8]中的算法进行检测,得到的评测效果对比直方图如图11所示。图11表明,实验结果中召回率与准确率明显优于文献[8]中的算法,说明本算法能够对一些复杂的局部变换具有更好的鲁棒性,这些局部变换改变了帧图像的部分内容。 图11 与文献[8]的效果对比Fig 11 Effect comparison with references[8] 在本文中,提出了一种使用上下文编码来表征关键帧时空上下文信息的算法,通过将其与词袋模型配合使用,使其在查询时具有更快的速度且存储时需要更小的存储空间,在标准数据集上的实验验证了该算法的有效性。在今后的工作中,将寻找一种更精确的关键帧提取方法以减少关键帧数量,同时检索性能得以保留。 [1] Kim C,Vasudev B.Spatiotemporal sequence matching for efficient video copy detection[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,15(1):127-132. [2] Shivakumar N.Detecting digital copyright violations on the internet[D].Stanford:Stanford University,1999. [3] Cheung S S,Zakhor A.Efficient video similarity measurement with video signature[J].IEEE Transactions on Circuits and Systems for Video Technology,2003,13(1):59-74. [4] Chen L,Stentiford F W M.Video sequence matching based on temporal ordinal measurement[J].Pattern Recognition Letters,2008,29(13):1824-1831. [5] Kim H,Lee J,Liu H,et al.Video linkage:Group-based copied video detection[C]∥Proceedings of 2008 International Confe-rence on Content-based Image and Video Retrieval,ACM,2008:397-406. [6] Wei S,Zhao Y,Zhu C,et al.Frame fusion for video copy detec-tion[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(1):15-28. [7] Datar M,Immorlica N,Indyk P,et al.Locality-sensitive hashing scheme based on p-stable distributions[C]∥Proceedings of the Twentieth Annual Symposium on Computational Geometry,ACM,2004:253-262. [8] Zhao W L,Wu X,Ngo C W.On the annotation of web videos by efficient near-duplicate search[J].IEEE Transactions on Multimedia,2010,12(5):448-461. 陈 浩,通讯作者,E—mail:norvinq@163.com。 Video copy detection based on spatial-temporal contextual code* WANG Rong-bo1,CHEN Hao1,SUN Xiao-xue1,ZHANG Jiang-feng2 (1.Institute of Cognitive and Intelligent Computing,Hangzhou Dianzi University,Hangzhou 310018,China;2.State Grid Research Institute of Electric Power,Hangzhou 310014,China) The most popular approach for content-based video copy detection is based on bag-of-visual-words model with invariant local features.Due to the neglect of the spatial context information and the temporal context information,these methods are limited.An algorithm of representing the spatial and temporal context information of key frames quantified into binary codes,and spatial-temporal verification is quickly achieved by Hamming distance.Experiments on TREVID—2009 video set demonstrate the proposed algorithm has high efficiency and accuracy. video copy detection;bag-of-visual-words;contextual code; 10.13873/J.1000—9787(2016)11—0143—05 2016—02—22 国家自然科学基金青年基金资助项目(61202280,61202281) TP 391 A 1000—9787(2016)11—0143—05 王荣波(1978-),男,浙江义乌人,博士,副教授,CCF会员,从事自然语言处理、篇章分析研究工作。5 实验结果分析

6 结 论
猜你喜欢
四川党的建设(2022年8期)2022-04-28
微型电脑应用(2020年12期)2020-12-25
小学生学习指导(低年级)(2020年11期)2020-12-14
作文大王·低年级(2018年10期)2018-12-06
中国生殖健康(2018年1期)2018-11-06
今日中国·中文版(2017年8期)2017-09-03
大连理工大学学报(2017年4期)2017-08-07
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
小猕猴智力画刊(2016年5期)2016-05-14
西北工业大学学报(2015年3期)2015-12-14
