
基于聚类分析的C4ISR系统服务关键要素自动提取方法
2016-11-02 00:38罗爱民
系统工程与电子技术 2016年5期
罗爱民,施 鼎
(国防科技大学信息系统与管理学院信息系统工程重点实验室,湖南 长沙 410073)
基于聚类分析的C4ISR系统服务关键要素自动提取方法
罗爱民,施鼎
(国防科技大学信息系统与管理学院信息系统工程重点实验室,湖南长沙 410073)
从业务模型中发现和识别业务层服务是面向服务架构系统设计的关键活动。为面向服务架构设计,提出了一种基于聚类分析的自动化服务提取方法。该方法将服务提取问题转换为多目标优化求解的问题,以C/U矩阵业务模型为基础,综合考虑服务设计中耦合度、内聚度、重用性、可维护性等原则,构建优化设计的目标函数,并提出模拟退火的求解方法。最后通过案例进行验证。
服务;聚类;耦合度;内聚度
网址:www.sys-ele.com
0 引 言
信息系统体系结构设计在系统建设中发挥着越来越重要的作用。由于基于面向服务架构(service oriented architecture,SOA)技术架构正在成为系统开发主流技术体制、流行的体系结构框架,如美军国防部体系结构框架(DoD architecture framework,DoD AF)2.0、英国国防部体系结构框架(MoD architecture framework,MoDAF)1.2、TOGAF9.1等都增加了服务相关的设计内容。如DoD AF2.0的服务视图中,包括服务组成、服务资源流描述、服务之间关系、服务与系统关系等模型。这些都是体系结构设计中服务视图的核心内容,其中服务组成更是最基础的内容,它是其他服务设计内容或模型的基础。但是目前的体系结构框架中没有提供服务获得的具体方法。
目前关于服务设计研究多集中在服务计算、服务标准和服务实现等方面,这些研究偏服务实现技术层面,常常忽视对业务层服务的设计与分析。应用层服务与业务模型密切相关,从业务模型中发现和提取业务层服务是SOA系统设计的关键活动,服务提取方法对体系结构中服务设计有重要的应用价值。
在服务设计中,传统的服务识别和提取方法主要是设计人员凭经验分析。这种人工分析方法难以满足复杂系统的设计要求。针对服务识别和提取的问题,近几年国内外学者也开展了相关的研究。文献[1]分析了服务设计的公理化原则;文献[2]提出了一种面向服务建模体系架构(service oriented modeling and architecture,SOMA)的方法;文献[3-5]提出了从业务模型自动识别服务的框架,认为服务提取应该是一个多目标优化问题,但是文中没有具体的实现方法;文献[6-9]提出了基于图、矩阵元素等半自动化服务提取方法。此外,有不少学者将聚类方法用于信息系统识别的研究[10 13],这些研究主要是非自动化的方式,或只考虑了单一的影响因素。本文针对信息系统体系结构设计中应用层服务提取的问题,综合考虑服务设计的多种约束规则,将服务提取为多目标优化设计的数学问题,提出一种基于聚类分析的自动化服务提取方法。该方法能够实现从业务模型中提取有效的服务体系,为信息系统体系结构服务视图的产品设计提供基础,也为SOA中服务设计提供有力的支持。
1 基于C/U矩阵的业务模型构建方法
一般来说,体系结构层面的服务设计主要是应用服务的设计。应用服务与业务活动和流程是密切相关的。因此,应用服务体系的设计必须以业务模型为基础。为便于后续分析,业务模型采用常用的C/U矩阵建模。
定义1一个业务模型可以定义为M={(BPi,BEj,PEij),i=1,…,#row,j=1,…,#column}。其中,BP表示业务活动集,BPi是第i个业务活动;BE表示业务实体集,BEj是第j个BE;#row和#column分别表示集合BP和BE元素的数量;PEij表示BPi与BEj之间的操作关系,操作关系按照数据模型的基本操作创建(C)和使用(U)来表示。
根据定义1,常用的C/U矩阵是描述业务模型的有效方式。其中,矩阵的行表示业务活动,矩阵的列表示业务实体,矩阵中每个单元表示业务活动与业务实体之间的操作关系。该模型称为业务模型的C/U矩阵。
目前信息系统体系结构设计多采用多视图设计方法。在多视图体系结构设计中,业务模型主要体现在业务视图中。因此,可根据业务视图的内容来构建相应的业务模型。其中业务活动集来自业务活动模型(OV-5),业务实体模型与逻辑数据模型对应,逻辑数据模型来自数据信息视图的逻辑数据模型(DIV-2)。尽管业务视图中没有模型详细描述逻辑数据模型与业务活动之间的具体操作,但是业务活动模型和业务信息交换矩阵都分析了业务活动模型之间的信息交换关系。因此,在建立业务模型时,可以根据信息交换关系、业务规则模型以及需求分析中业务活动更细节的内容,定义C/U矩阵中各单元的操作类型。
构建业务模型C/U矩阵的简单流程如下:
步骤1利用业务视图模型,列出所有的业务活动作为C/U矩阵的行;
步骤2利用数据信息视图模型,列出所有的逻辑数据作为C/U矩阵列;
步骤3分析业务活动与逻辑数据模型的操作关系,定义C/U矩阵中各单元的操作类型。
表1表示一个业务模型的C/U矩阵。

表1 业务模型的C/U矩阵示例
2 基于C/U矩阵的聚类分析
服务体系提取的核心就是按照某种原则对业务活动或功能进行合理的分组划分,使其满足服务设计的要求。
在业务模型的C/U矩阵中,业务模型明确了业务活动与逻辑数据之间的关系,因此可以分析C/U矩阵中定义的操作以及操作之间的关系,按照服务设计原则对类似或相关性强的活动、数据进行聚类,根据聚类结果提取服务集。每一个聚类对应一个候选服务。
定义2C/U矩阵的第k个聚类模块Clusterk={(BPi,BEj),i。其中,lk1是该聚类模块在C/U矩阵中的起始行,hk1是该聚类模块在C/U矩阵中的结束行,lk2是该聚类模块在C/U矩阵中的起始列,hk2是该聚类模块在C/U 矩阵中的结束列,1≤l1K<hK1≤ #row并且
设存在聚类模块

设M表示业务模型对应的C/U矩阵。一个好的聚类方案至少具有以下特点:
(1)非交互性
对于∀K,N,Clusterk∩ClusterN=Ø。这要求每个聚类模块在业务活动和数据模型上没有交互关系。
(2)合并性

(3)完整性
如果一个聚类方案将C/U矩阵划分并形成N个聚类模块,那么这N个聚类模块的并集覆盖了C/U矩阵中BP集与BE集。
(4)唯一性
定义3服务Sk={Name,I,Msg,Rs}。其中,Name是服务的名称;I是与Sk完成的活动集;Msg是与Sk相关的数据集;Rs是服务Sk与其他服务之间的关系集。
基于C/U矩阵按照聚类方法提取服务,C/U矩阵中每个聚类模块只能唯一地被定义为一个服务,即∀Clusterk,ClusterK⇒SK。
按照服务的定义,服务模型中I对应该聚类模块中BP的相关集,Msg对应该聚类模块中BE的相关集。
3 自动化的聚类优化求解方法
按照面向服务设计的基本原理,服务设计必须有助于最大限度地发挥服务的优势。通常在服务设计中,主要考虑的约束因素为:粒度适中,低耦合度,高内聚度,可重用性,便于维护。
由于影响服务优化设计的因素多且相互关联,因此对于复杂的业务模型,依靠人工、定性的方法对C/U矩阵进行聚类分析难以满足设计要求。
根据基于业务模型通过聚类方法提取服务的特点,将多制约因素的聚类问题转化为一个多目标最优求解的数学问题,通过对C/U矩阵的定量化处理,综合考虑服务设计的多个约束因素,构建优化的目标函数,通过目标函数自动化求最优解,最终形成最优的聚类方案,即服务提取方案。
为便于定量化计算,将C/U矩阵各单元的操作变为量化的数值。量化规则是:若矩阵单元元素为C或U,则单元的值设为1,否则设为0。在实际应用中,建立C/U矩阵也可划分为创建(Create)、读取(Read)、更新(Update)和删除(Delete)等4类,并针对4类操作定量化4个数值。
在前面提出的服务设计约束原则中,服务的重用性与粒度设计是相关的,粒度小的服务重用性高。可维护性与耦合度密切相关,耦合度低的服务可维护性好。为简化求解问题,本文重点考虑耦合度、内聚度和粒度3个测度因素。
(1)内聚度
内聚度指服务内部功能以及数据关系紧密程度。服务内聚度越高,服务设计质量越高,它与聚类模块中各单元的相关性有关。
设聚类模块
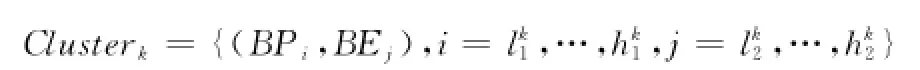
定义聚类Clusterk的内聚度coh(k)为

式中,mij表示C/U矩阵各单元操作量化后的数值。
假设针对业务模型的C/U矩阵形成的聚类方案C中包含N个聚类模块,即共提取N个服务,则该聚类方案的内聚度为

根据式(1)和式(2),0<coh(k)≤1,0<Coh(C)≤1。
(2)耦合度
耦合度主要指服务之间的关联关系,即聚类模块之间的相互关系。服务之间关联性越小,则耦合度越低,服务设计质量越高。对于表2所示的服务聚类结果来说,假设S1和S2是两个聚类,表中的两个阴影部分体现S1和S2之间的关系,S1和S2的耦合程度由这两个阴影部分单元的操作决定。如果阴影部分单元值全为0,则S1和S2之间没有数据交互关系,则它们的耦合度为0。同理,如果阴影部分区域内非0的单元数越多,说明S1和S2之间的关联性越大,即耦合度越大。
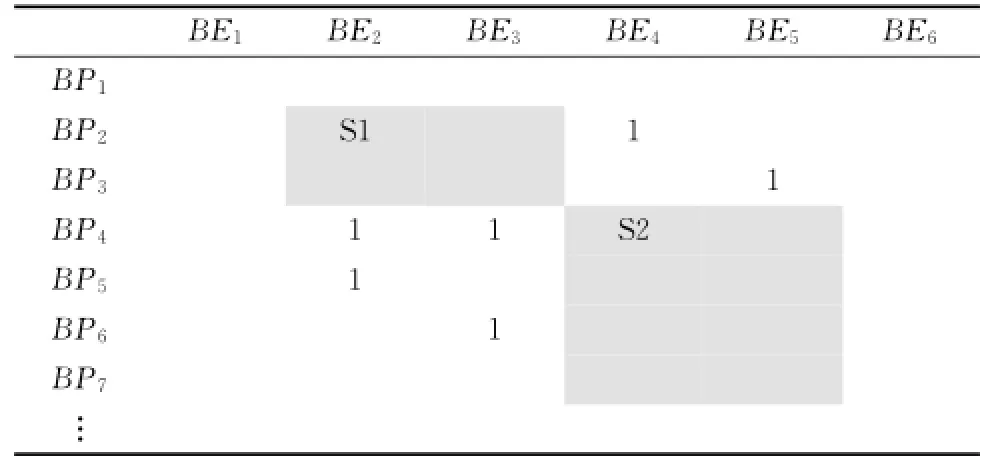
表2 服务聚类结果示例


根据式(3)和式(4),0<Cou(m,n)≤1,0<Cou(C)≤1。
(3)粒度
粒度主要反映聚类中包含的业务活动和逻辑数据的多少。粒度直接影响服务的重用性。
服务包含的业务活动和逻辑数据数量越多,说明服务的粒度越大,Gk越小。如果聚类Clusterk只包含1个业务活动和1个逻辑数据实体时,聚类对应的服务粒度越小,则Gk=1,达到最大值。
假设聚类方案中共包括N个服务,则这种聚类方案的粒度为

根据式(5)和式(6),0<Gk≤1,0<G≤1。
上面讨论的3个因素相互制约和影响。基于构建的C/U矩阵通过聚类来提取服务体系,就是要综合考虑上述影响因素,在这些影响因素中找到一个最佳的折中点。为此,将聚类提取服务问题转换为一个多目标求最优解的问题。耦合度最小最优,内聚度最大最优,粒度最小最优。
构建优化目标函数

式中,C表示聚类方案;Z(C)为目标函数。考虑到耦合度、内聚度和粒度目标值的特点,定义函数f为
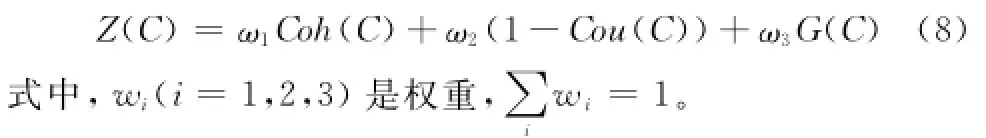
针对目标函数的特点,采用模拟退火算法进行优化求解[9]。模拟退火算法求解步骤如下所示。
输入C/U矩阵,指标权重ωi(i=1,2,3)。
总之,文山州农村地区因受社会经济、文化教育、传播工具和交通条件等诸多因素影响,农村居民较少有机会接受无偿献血知识方面的宣传,所以对无偿献血认识不足。只有加大农村无偿献血的宣传力度,采取形式多样的宣传方式对农村进行宣传,重点普及血液生理知识和无偿献血优惠政策,以提高无偿献血知晓率,破除旧思想、转变新观念、消除献血染病等顾虑,才能提高农民无偿献血的积极性,壮大农民无偿献血队伍,全面协调地推动文山州无偿献血工作的发展。
输出聚类方案,满足特定需求的聚类集合。
步骤1设置输入参数和迭代次数。
步骤2随机生成一个解决方案,作为Current方案
在1~#row之间生成一个随机数作为服务的个数并赋值给变量CurrentSerυice;
等概率为每一行分配一个服务编号;
等概率为每一列分配一个服务编号;
扫描每一列分配的服务编号,若该服务编号不属于行服务编号集,则重新分配该列服务号直至满足条件;
将最终的服务个数更新给CurrentSerυice。
步骤3随机生成一个相对于当前方案的候选方案
在0~CurrentSerυice之间随机生成一个数,加1后赋值给变量NextSerυice;
随机选择一行和一列做为候选行和候选列;
将选择的候选行和候选列的服务号更新为NextSerυice;
扫描每一列分配的服务编号,若该服务编号不属于行服务编号集,则重新分配该列服务编号直至满足条件;
扫描每一行分配的服务编号,若该服务编号不属于列服务编号集,则重新分配该行服务编号直至满足条件。
步骤4分析目标函数的变化,ΔE=Z(next)-Z(cuurent)。
步骤5若ΔE≥0,则用候选方案取代当前方案;若ΔE<0,则候选方案以概率eΔE/T取代当前方案。
步骤6T=1/迭代次数。
步骤7对于给定的迭代次数重复步骤3~步骤6。
4 案 例
为验证上述方法的可行性,选用文献[1]中表1定义的CRUD矩阵进行案例分析。该CRUD矩阵是以美军后勤业务为背景建立的,其中定义了Create、Read,Update,Delete等4种操作。该CRUD矩阵具体值可参看文献[1]。
在案例研究中,不区分文献[1]表1中单元的Read,Update,Delete 3种操作,将这3种操作统一定义为Use操作,这样将原来的CRUD矩阵简化为C/U矩阵。针对修改后的C/U矩阵,利用前面提供的算法进行最优化求解。优化求解采用Matlab平台实现,聚类结果如图1所示。其中图1中第一行和第一列的数字N表示对应文献[1]表1中第N行(或列)的过程或数据,设ω1=0.4,ω2=0.3,ω3=0.4。
通过聚类计算后得到服务数量为5个(对应图中5个阴影区域),如图1所示。图2是最优化求解算法的收敛速度。
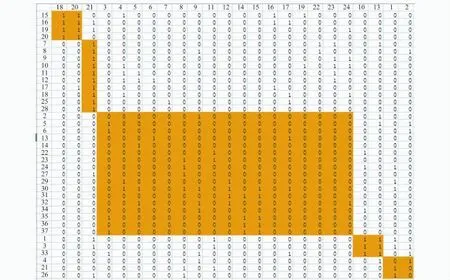
图1 聚类后的C/U矩阵

图2 最优化求解算法的收敛速度
5 结 论
本文提出一种通过聚类分析提取服务的方法,将聚类分析提取服务转化为多目标优化求解的问题,建立了目标函数,给出求解方法。这种方法能够为服务提取提供自动化的、定量化分析方法,提高服务体系设计的科学性和效率。
服务提取是面向服务设计中的核心问题。本文提出的聚类分析方法是以业务活动与逻辑数据模型之间的关系为基础,主要是从数据关系测角度来进行聚类分析。业务活动执行的过程对服务设计有较强的影响,在内聚度、耦合度、粒度等方面都应该考虑。因此充分结合数据和流程两方面建立目标函数能够更高效地设计服务体系。同时,在现有方法的基础上,可以探索服务接口关系的自动化生成方法。
[1]Nyamekye K.Methodology of designing and evaluating reliability of the DoD net_centric ecosystem[J].International Test and Eυaluation Association Journal,2010,31(3):399-409.
[2]Arsanjani A,Ghosh S,AllamA,et al.SOMA:a method for developing service-oriented solutions[J].IBMSystems Journal,2008,47(3):377-396.
[3]Jamshidi P,Teimourzadegan R,Nikravesh A,et al.An automated method for service specification[C]//Proc.of the ACM/ IEEE International Conference on Software Engineering and Warm up Workshop,2009:25-28.
[4]Jamshidi P,Khoshnevis S,Teimourzadegan R,et al.Toward automatic transformation of enterprise business model to service model[C]//Proc.of the International Conference on Software Engineering Workshop on Principles of Engineering Serυice Oriented System,2009:70-74.
[5]Khoshnevis S,Jamshidi P,Nikravesh A,et al.ASMEM:a method for automating model evolution of service-oriented systems[R].CMU/SEI-2010SR004.
[6]Zhang L J,Zhou N,Chee YM,et al.SOMA-ME:a platform for the model-driven design of SOA solutions[J].IBM Systems Journal,2008,47(3):397-413.
[7]Jain H,Zhao H,Chinta N R.A spanning tree based approach to identifying web services[J].Web Serυice Research,2004,1(1):1-20.
[8]Wang X Z,Wang Z J,Xu X F.Semi-empirical service composition:a clustering based approach[C]//Proc.of the IEEE International Conference on Web Serυices,2011:219-226.
[9]Jamshidi P,Mansour S,Sedighiani S,et al.An automated service identification method[R].TR-ASER-2012-01.
[10]Jain H,Chalimeda N,Lvaturi N,et al.Business component identification:a formal approach[C]//Proc.of the 5th IEEE International Conference on Enterprise Distributed Object Computing,2001:183-187.
[11]Fayad M E.Accomplishing software stability[J].Communications of the ACM,2002,45(1):111-115.
[12]Lee J K,Jung S J,Kim S D.Component identification method with coupling and cohesion[C]//Proc.of the 8th Asia-Pacific Software Engineering,2001:79-86.
[13]MenascéD A,Casalicchio E,Dubey V.On optimal service selection in service oriented architectures[J].Performance Eυaluation,2010,67(8):659-675.
Research on automatic identification method for key elements of service in C4ISR based on clustering
LUO Ai-min,SHI Ding
(Department of Information System and Management,Science and Technology on Information Systems Engineering Laboratory,National Uniυersity of Defense Technology,Changsha 410073,China)
A key process in the design of the service oriented architecture(SOA)system is to identify application level service from business models.An automated service identification method is provided based on clustering.Based on the business model of the C/U matrix,service identification is formulated as a multi-objective optimization problem.An optimization objective function is presented that derives service design principles,such as coupling,cohesion,reusability and maintainability,and the solving method of the simulated annealing optimization is provided.A case is given to illustrate the method.
service;clustering;coupling;cohesion
TP 303
A
10.3969/j.issn.1001-506X.2016.05.17
1001-506X(2016)05-1081-05
2015-02-02;
2015-08-16;网络优先出版日期:2015-12-23。
网络优先出版地址:http://www.cnki.net/kcms/detail/11.2422.TN.20151223.1111.024.html
国家自然科学基金(71171197)资助课题
罗爱民(1970-),女,教授,博士,主要研究方向为信息系统工程。
E-mail:amluo@nudt.edu.cn
施鼎(1991-),男,硕士研究生,主要研究方向为信息系统工程。
E-mail:1148307406@qq.com
猜你喜欢
防爆电机(2022年1期)2022-02-16
粉末冶金技术(2021年3期)2021-07-28
生产力研究(2020年5期)2020-06-10
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
系统工程与电子技术(2016年12期)2016-12-24
浙江大学学报(工学版)(2016年11期)2016-06-05
商场现代化(2016年1期)2016-03-18
