
农产品价格主题搜索引擎的研究与实现
2016-10-26 06:28孟繁疆姬祥袁琦刘东侯哲鹏
东北农业大学学报 2016年9期
孟繁疆,姬祥,袁琦,刘东,侯哲鹏
(东北农业大学电气与信息学院,哈尔滨 150030)
农产品价格主题搜索引擎的研究与实现
孟繁疆,姬祥,袁琦,刘东,侯哲鹏
(东北农业大学电气与信息学院,哈尔滨150030)
当前农业垂直搜索引擎无法预测农产品价格趋势,难以满足农业生产者行情分析需要。文章设计农产品价格主题搜索引擎。首先网络爬虫从农业综合网站搜集网页,对网页进行转码、去重、提取内容等处理;使用主题相关度算法计算网页的主题相关度,用分类器对网页分类,将与主题相关的网页解析、存储;最后提取农产品价格及其影响因素信息。结果表明,系统可搜集农产品价格信息及影响农产品价格因素信息,为后续农产品价格预测提供数据支持。
网络爬虫;信息抓取;农产品价格;农业搜索引擎
孟繁疆,姬祥,袁琦,等.农产品价格主题搜索引擎的研究与实现[J].东北农业大学学报,2016,47(9):64-71.
Meng Fanjiang,Ji Xiang,Yuan Qi,et al.Research and implementation of agricultural prices subject search engine[J].Journal of Northeast Agricultural University,2016,47(9):64-71.(in Chinese with English abstract)
随着农业信息化迅速发展,国外农业搜索引擎起步较早,美国农业网络信息中心、WEB AgriSeareh、Agriscape Search等应用广泛[1-3]。我国农业搜索引擎起步较晚,但发展较快,自2007年首个农业搜索引擎上线以来,已建成“中国搜农”“农搜”等多个较为成熟农业垂直搜索引擎。
现有农业垂直搜索引擎对农产品价格主题搜索时,返回信息总量大、数据不直观,存在大量重复和无用信息,用户无法快速准确定位所需信息,不便于分析行情,无法为农业生产提供参考。
本文从新农网、富农网等知名农业综合网站搜集农产品价格信息设计垂直搜索引擎,为用户提供农产品价格趋势图,方便农业生产者准确、及时了解不同农产品价格趋势,为农产品价格预测提供参考。
1 系统架构
农产品价格搜索引擎系统结构如图1所示,工作流程主要包括:在互联网上搜集网页;对网页过滤、解析,建立索引数据库;给用户提供查询接口。农产品价格搜索引擎由三部分组成:
①信息搜集模块:在互联网上搜集信息;
②数据管理模块:网页数据解析、存储;
③用户服务模块:处理用户查询、记录日志。
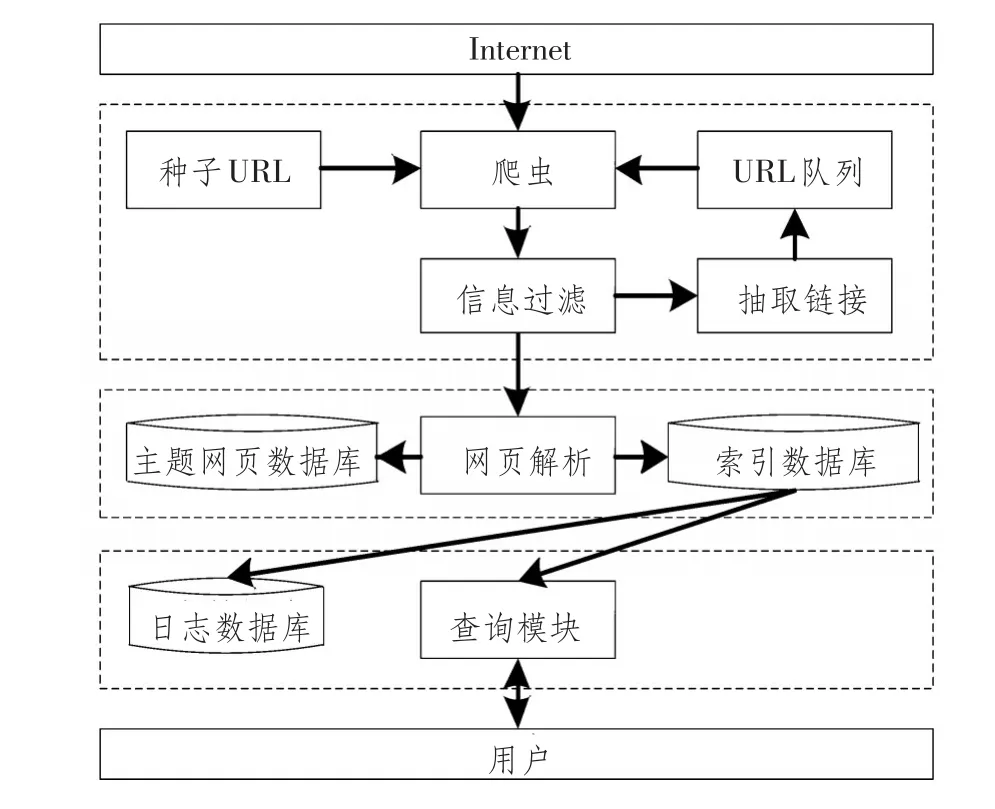
图1 农产品价格主题搜索引擎系统结构Fig.1System structure of agricultural prices subject search engine
网络爬虫是信息搜集模块核心[4],爬虫从一组种子URL出发,不断从互联网上抓取网页,并把网页交由分类器过滤,剔除与主题无关网页,解析与主题相关网页,加入主题网页数据库中,抽取其中链接,把抽取链接加入待抓取URL队列中。
数据管理模块负责保存抓取网页、解析网页并存储解析后网页信息,对网页和数据建立索引。数据管理模块须定时更新,保证数据库信息与互联网同步,更新频率决定搜索结果及时性,直接影响搜索引擎性能。
当用户查询农产品价格时,用户服务模块根据查询条件在索引数据库中检出农产品价格数据和价格影响因素信息并反馈给用户。
2 算法设计
2.1网页预处理
2.1.1编码转换
目前,常用中文编码有UTF-8、Unicode、GB2312、GBK等[5-6],系统在分词时要作位操作,如果系统中文编码与网页中文编码不一致,会出现数据乱码问题,因此在系统分词前应先编码转换。网页默认编码是GBK,也可通过meta标签charset属性对编码设置,如百度首页编码为utf-8,<meta http-equiv=Content-Type content="text/html;char⁃set=utf-8">。
本文转码流程为:
①打开并读取一个网页源文件;
②提取网页中meta标签,其属性charset值表示当前网页中文编码方式,若编码方式是UTF-8,则无需转码;
③若网页源码中无charset设置,则网页中文编码方式是GBK默认编码;
④将数据转换为UTF-8编码;
⑤关闭文件。
2.1.2中文分词
中文分词是信息检索、信息过滤等中文信息处理关键技术及难点,是指将组成句子汉字序列用分隔符加以区分,切分成单独词[7]。目前常用中文分词器有Ansj、Jcseg、ICTCLAS、MMSEG4J等,分词准确度分别是96%、98%、98.45%、98.42%[8]。其中ICTCLAS单机分词速度快,API不超过占用空间小,且支持用户词库,本文选用ICTCLAS3.0,为后续工作提供保障。ICTCLAS3.0分词流程如图2所示。

图2 ICTCLAS分词流程Fig.2Word segmentation flowchart of ICTCLAS
2.1.3去除重复网页
对于搜索引擎,相同或相似内容由不同URL给出,无故消耗系统内存和硬盘空间,因此预处理阶段主要任务是消除相似或转载网页,搜索引擎对网页检索实际上是对关键词匹配,本文提出一种去除重复网页方法。令Pi表示第i个网页,提取网页中词频最高前10个关键词,按拼音字母升序规则排序,得到网页特征项集合Ui={ti1,ti2,…,ti3},如果两个网页特征项集合相同,判定二者互为转载网页。
2.2主题相关度计算
主题相关度[9]判定模块主要计算未被解析网页为主题相关度,按照主题相关度将网页URL插入URL优先级队列中,优先解析主题相关度高网页,舍弃相关度低URL,尽可能减少索引和检索资源浪费[10]。
本文主题相关度算法主要探讨父网页与主题相关度、网页描述中主题词汇出现频率、网页描述中主题词对网页贡献度得分。
①网页从父网页集继承主题相关度grade_ parent
父网页u与主题相关度较大时,所指向网页有很大可能与主题相关。子网页v能从父网页u中继承一定相关度得分,但在主题相关度传递过程中,从父网页继承分数应有所减小,否则后代网页相关度分数应越来越高。因此,网页主题相关度可以均分给其前向链接。子网页v从其父网页集继承主题相关度得分,对所有父网页相关度加和求平均值。因此网页从父网页继承得到相关度得分公式如式(1)所示:

式中:S(u)表示指向网页u网页集合,F(U)表示网页u指向网页集合,weight(u)表示网页u主题相关度,count(S(u))表示指向网页u网页个数。
②网页v从兄弟链接即父网页u中其他链接得到相关度得分grade_brother
假设网页u中含有指向网页v和网页b链接URL,如果网页b与主题有关,那么网页v与主题相关可能也较大。所以,在计算网页v主题相关度时,也需要酌情考虑其兄弟链接主题相关度。由此可以得到网页v从兄弟链接得到相关度得分公式如式(2)所示。
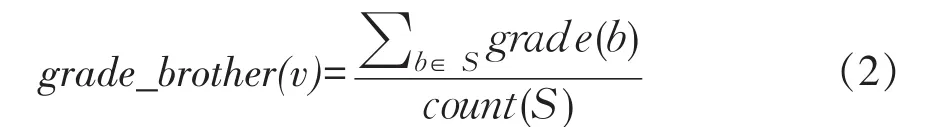
表示网页v父网页中所包含URL集合,count(S)表示网页v父网页中包含URL集合数量。
③网页描述中出现主题词汇加权得分grade_ word
主题词库是存储农产品价格相关词汇专业词库,是主题相关度判定重要依据。本文将主题词库分为5个等级,等级越高权值越大,主题相关度越大,“地名+农产品名+价格”权值为5,如:“大庆玉米价格”,“农产品名+价格”权值为4,如“玉米价格”,“地名+农产品”权值为3,如:“大庆玉米”,“农产品名”权值为2,如:“玉米”,其他相关词权值为1,如:“价格”。对主题词汇权值与出现次数积求和平均,即可得到grade_word。因此,网页中出现主题词汇加权得分公式如式(3)所示。
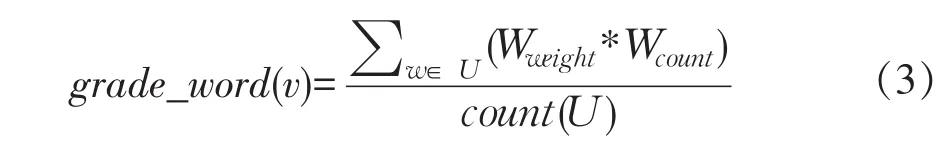
式中:U表示网页中出现主题词汇集合,Wweight表示主题词权值,Wcount表示主题词在网页出现次数,count(U)表示网页中出现主题词个数。
网页中出现主题词汇加权得分只考虑文档中关键词出现频数,并未考虑关键词对文档内容贡献度,即关键词对网页作用。而主题词汇对网页贡献度得分反映关键词对网页贡献度,与具体文档无关。
网页中出现主题词汇加权得分计算公式如公式如式(4)所示:
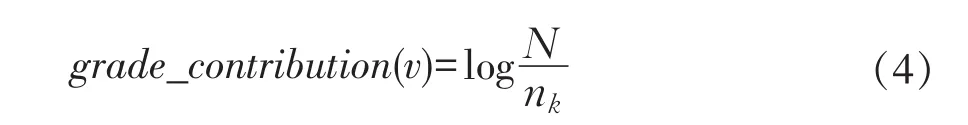
式中:nk为含关键词k文档频率,N代表文档集合规模。由公式(7)可知,文档频率nk与grade_ contribution是为反比例关系,即nk越大与之对应grade_contribution越小。grade_contribution值反映是关键词k对文档辨识力,其值越大说明信息含量越多,越有价值,对文档辨识度越高。
⑤综合考虑父网页、兄弟网页和主题词汇三个因素,对grade_parent、grade_brother、grade_ word、grade_contribution加权求和,得到网页v主题相关度计算公式如式(5)所示。
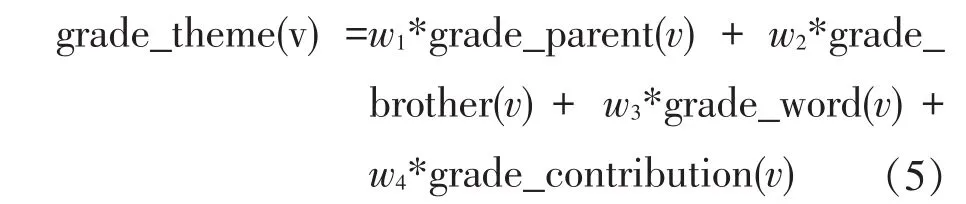
式中:w1、w2、w3、w4表示相关度得分权重值,w1+w2+w3+w4=1。
3 系统设计
3.1网络爬虫
现有许多成熟且开源网络爬虫框架[11-12],如Nutch、Crawler4j等,适合用于通用搜索引擎,对于本系统来说许多模块冗余。因此本文在已有搜索引擎技术理念[13-16]基础上,利用HttpClient和ht⁃mlparser为本系统设计一个功能全面、结构清晰主题网络爬虫。爬虫工作流程如下:
①选取国内知名农业门户网站作为种子URL地址,将种子地址输入LinkDB中,作为爬虫抓取初始地址。爬虫从种子URL开始解析页面URL及其链接;
②爬虫在抓取网页时要解析域名,为爬虫建立一个缓存区存放解析域名和对应IP地址,提高爬虫抓取效率;
③抓取并解析网页信息,判定主题相关度并抽取其中链接,将与主题相关链接加入LinkDB中;
④更新LinkDB库,将抓取链接放入已抓取队列中,计算新加入链接主题相关度;
⑤重复2~4步,直到终止程序。
本文网络爬虫共分为3层:抓取层、判定层、处理层;其中,抓取层负责从互联网上抓取网页,对网页预处理,并管理URL队列;判定层对抓取网页作主题相关度判定,抽取网页中链接,消除非法URL,并设定URL抓取状态和初始主题相关度得分,将URL及其状态和分值保存到LinkDB中;处理层主要负责解析网页、信息提取和数据存储工作。本文爬虫存储数据库主要有3个:网页数据库、源网页数据库、核心数据库,各存储数据库功能分别为:网页数据库存放链接关联关系,同时记录最后更新抓取时间及URL权值等参数信息;源网页数据库用于存放系统抓取网页源文件并为其建立索引,是非结构化数据,主要用于备份网页源文件;核心数据库存放网页提取数据。爬虫体系结构如图3所示。
3.2主题词库搭建
主题词库是存储农产品价格相关词汇专业词库,是主题相关度计算基础,直接影响农产品价格主题相关度判定,对所采集信息准确性有直接影响。本文目标是搜集农产品价格信息及价格影响因素相关信息,为后续农产品价格预测提供数据基础,因此关键词库包含价格相关和影响因素两个部分,其中影响因素分为供给因素、需求因素和国际因素[17-19]。
从供给层面看,农业生产成本、自然条件、播种面积等因素通过影响农产品产量,间接影响农产品价格。其中,农业生产成本是农产品价格基础,变化决定农产品价格变动基本趋势,主要包括农业生产资料成本、劳动力成本、土地成本。
从需求层面看,人口数量、国民收入、工业用粮等因素变化直接影响农产品需求量,间接影响农产品价格。农产品供给关乎国计民生,即使价格波动,消费者需求量不会大量减少。城乡居民收入增加,消费结构随之升级,对农产品价格波动有一定程度影响。而工业化发展明显提高农产品需求量,导致耕地面积和农村劳动力减少,影响者农产品价格。
从国际方面来看,国际农产品价格、国际石油价格、农产品进出口等均影响农产品价格。国际市场因素对中国农产品价格影响方法通过成本推动,即上游商品价格变化经由成本环节推动下游商品价格变化。石油价格上涨直接影响农业生产成本和生物燃料需求,提高农产品生产成本和需求量。进出口贸易可以调节国内生产要素利用率,改善国际供求关系,调整经济结构,影响农产品价格。
农业领域不断出现相关农产品价格词汇,需及时添加到系统主题词库中,保证系统准确统计农产品价格信息。系统提供两种方式更新词库,一是系统定期分析用户查询日志,记录近期频繁出现检索词汇,由管理员确认后加入主题词库,二是系统管理员手动将新词汇加入词库。关键词库结构如图4所示。
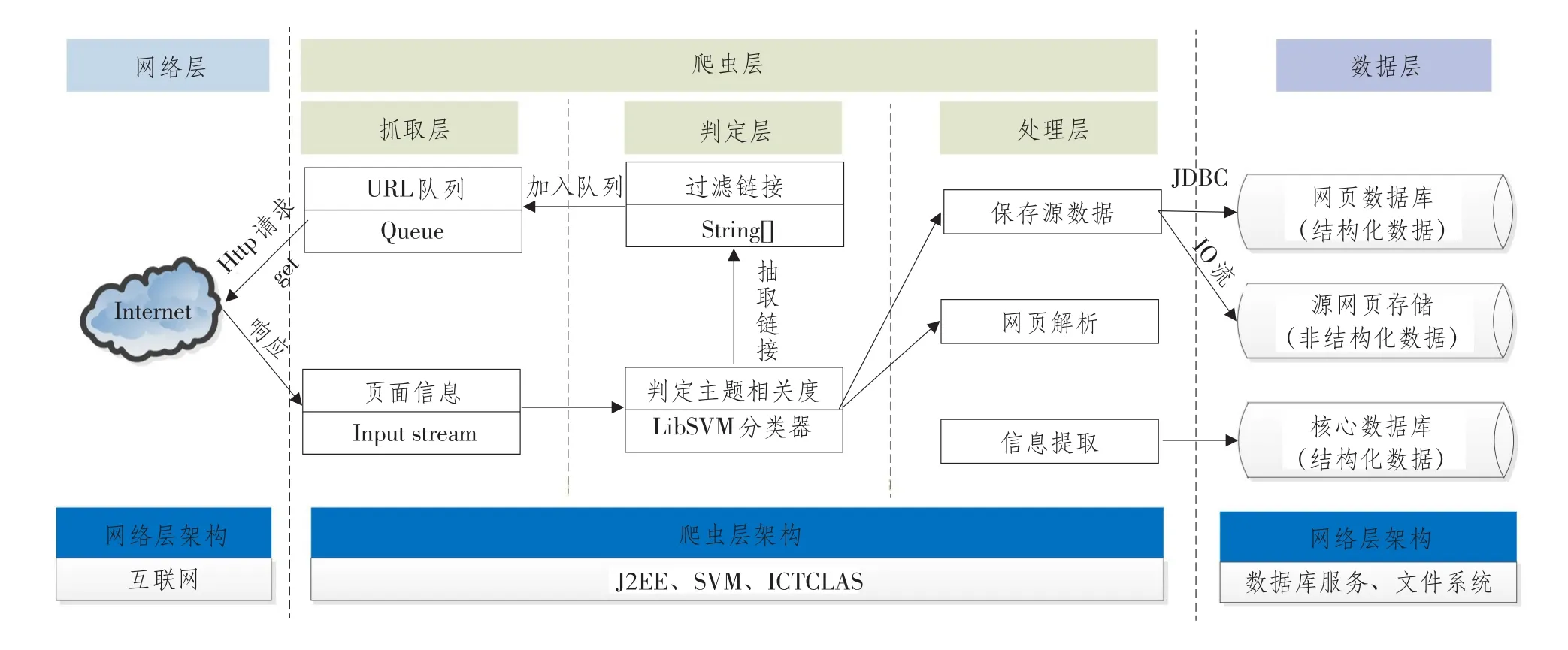
图3 爬虫体系结构Fig.3System architecture of crawlers
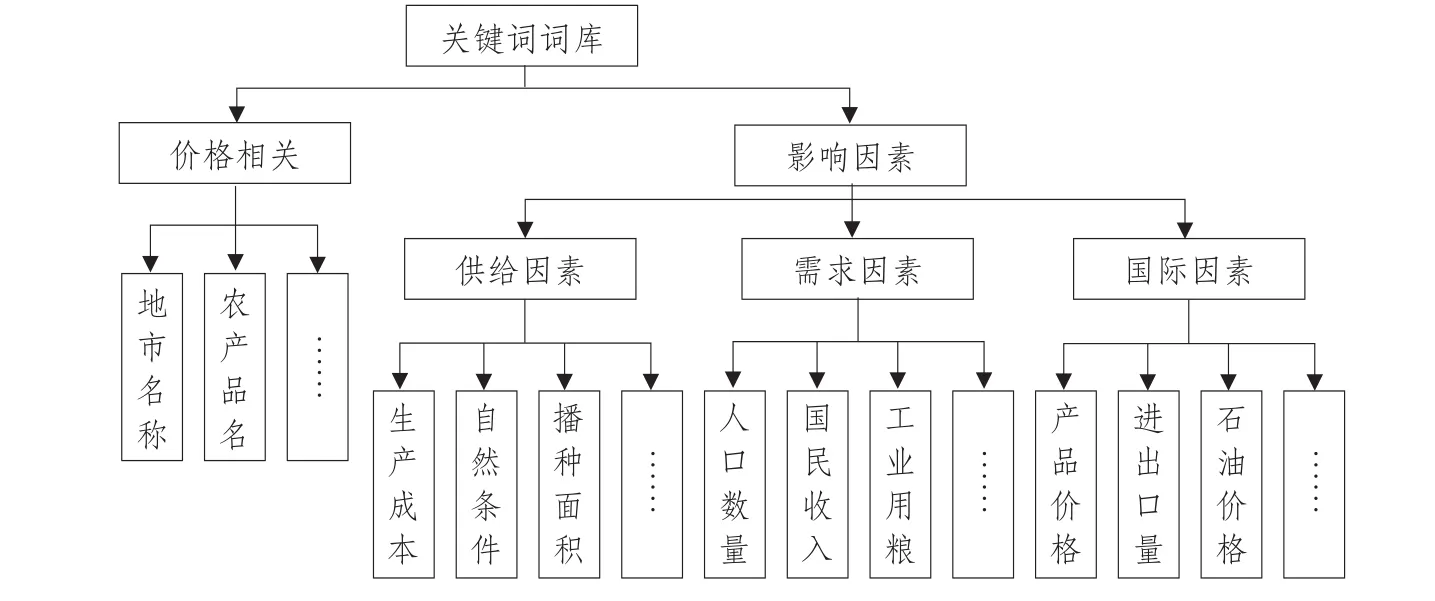
图4 关键词库Fig.4Keywords database
3.3分类器设计
支持向量机法(SVM)是Vapnik基于结构风险最小化原则提出的机器学习分类法,主要思想是针对线性可分情况进行分析,对于线性不可分情况,通过使用非线性映射算法将不可分低维输入空间转化为高维特征空间,高维特征空间使用线性算法对样本非线性特征进行线性分析[20-24]。
最优分类函数如式(6)所示:

式中:ai表示支持向量,yi表示样本向量类别值,xi表示训练样本向量,K表示核函数,b为待求常数。
K最近邻(KNN)分类算法主要思想是根据传统空间向量模型,对文本预处理、分词、权重计算操作,将文本内容转换成特征空间中向量V=V (w1,w2,……,wn)。对每个样本数据,计算其和训练样本集中每个训练样本相似度,并按相似度样本排序,获得K个相似度最高样本,通过加权计算K个样本确定待分类样本所属类别[25-27]。
本文农产品价格分类模型中,主要利用SVM分类器支持向量思想改进KNN分类器,首先通过试验确定农产品价格数据集区分阈值,再通过训练农产品价格样本得到SVM分类器,利用SVM分类器支持向量SV作为KNN分类器训练样本,构建基于支持向量KNN分类器。在分类过程中,计算待分类农产品价格样本与SVM分类器中最优分类面H之间距离d,若存在d>0,则直接使用SVM分类器分类,否则使用基于支持向量KNN分类器,计算待分类样本和类别支持向量间距离,计算支持向量权重之后,输出得到高权重样本级别。分类器分类流程如图5所示,其中,U1到Un分别表示父网页u1到un主题相关度,W1到Wm分别表示主题词汇w1到wm词频。分类具体步骤如下:
①对爬虫抓取待分类网页,通过预处理可计主题词汇在网页文本中出现次数,即词频,并从数据库中提取网页父网页信息;
②将父网页信息、兄弟网页信息、词频等文本向量化;
③通过输入特征向量集合,选择合适核函数,农产品价格样本训练,得到SVM模型;
④将上一步得到SVM模型各类别支持向量作为KNN分类器训练样本集,得到KNN分类模型;
⑤计算样本和类别支持向量之间距离,决定使用SVM分类模型还是基于支持向量KNN分类模型。

图5 相关度计算过程实例Fig.5Example of correlation degree calculation process
4 结果与分析
查全率和查准率作为评价搜索引擎系统性能主要指标[28],前者衡量系统检索结果与用户需求内容相关能力,计算公式如式(7),后者衡量系统拒绝不相关内容能力,计算公式如式(8)。

式中R表示检出信息数量,C表示检索出相关信息数量,T表示整个文档集合。由于互联网信息海量,无法得知网络上共有多少相关信息,因此将查准率作为评价搜索引擎重要指标。通过试验,以“哈尔滨玉米价格”为关键词,使用本系统检索,检索出网页数为100,200,300,400,500,600,700,800,900,1 000。检索出相关网页数分别为85,167,248,338,411,486,571,650,726,806。
通过式(8)得到查准率见图6。
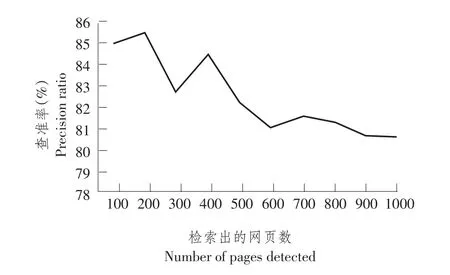
图6 系统查准率Fig.6Pprecision ratio of the system
由图6可知,系统查准率在检出网页较少时波动较明显,随着检出网页增多,系统查准率逐渐稳定在80%左右,由此可见系统能够拒绝与主题无关网页。
另外,系统可统计“哈尔滨玉米价格”信息,根据“哈尔滨”“玉米”两个关键词将近期哈尔滨玉米价格抽取,并统计哈尔滨玉米价格影响因素信息,为后续农产品价格预测提供数据。
2015年1月到2016年8月哈尔滨玉米价格波动如图7所示,系统统计的影响哈尔滨玉米价格因素信息见表2。
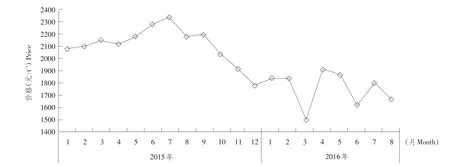
图7 2015年1月~2016年8月哈尔滨玉米价格Fig.7January 2015-August 2016 maize prices Harbin
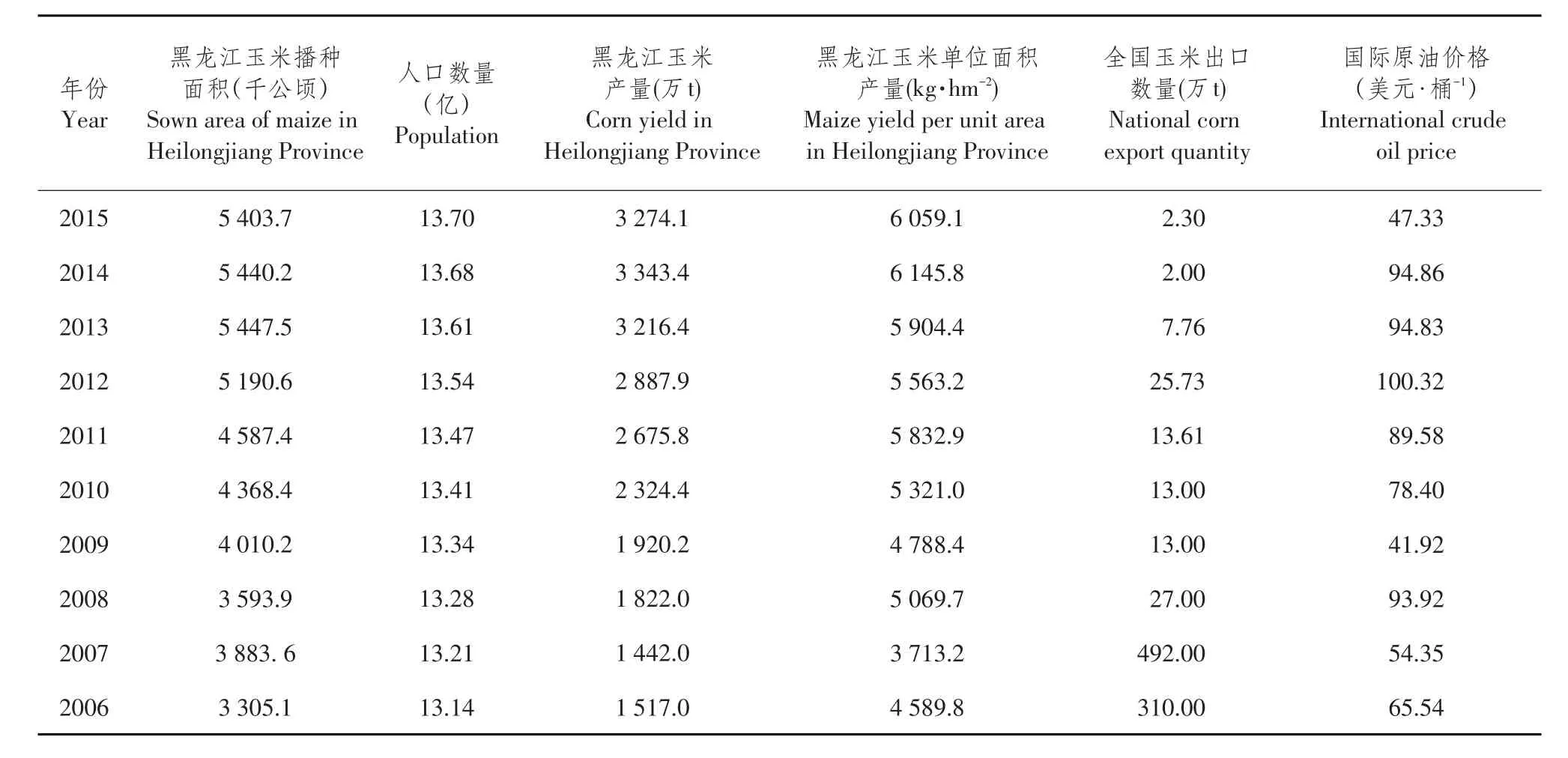
表2 玉米价格影响因素信息Table 2Influence factor of corn price
5 结论
针对现有农业搜索引擎反馈农产品价格信息不够直观等问题,本文使用HttpClient和htmlparser架构网络爬虫,提出基于父网页、兄弟网页和关键词主题相关度算法计算网页主题相关度,在不同情况下分别利用SVM分类器和支持向量KNN分类器确保抓取网页准确性,有效搜集互联网农产品价格信息,为用户提供更直观数据。系统收集农产品价格影响因素信息,为农产品价格预测提供数据基础。
[1]陈威,郭书普.中国农业信息化技术发展现状及存在问题[J].农业工程学报,2013(22):196-205.
[2]许世卫.农业信息科技进展与前沿[M].北京:中国农业出版社,2007.
[3]Law M R,Mintzes B,Morgan S G.The sources and popularity of online drug information:an analysis of top search engine results and web page views[J].Annals of Pharmacotherapy,2011,45(3):350-356.
[4]孔涛,曹丙章,邱荷花.基于MapReduce视频爬虫系统研究[J].华中科技大学学报:自然科学版,2015(5):129-132.
[5]黄小花,李俊晶.浅析页面头部Meta标记[J].电脑知识与技术,2015(6):192-194.
[6]侯整风,张浩,张娜.基于字频分布中文网页编码识别算法[J].计算机工程,2014(12):199-204.
[7]韩冬煦,常宝宝.中文分词模型领域适应性方法[J].计算机学报,2015(2):272-281.
[8]许玉赢.常用开源中文分词工具[EB/OL].(2014-04-20)[2016-01-15]http://www.scholat.com/vpost.html?pid=4477.
[9]Mathew M,Shine N D,Lakshmi T R.A novel approach for nearduplicate detection of Web pages using TDW matrix[J].Interna⁃tional Journal of Computer Applications,2011,19(7):16-21.
[10]Agrawal A,Husain M,Tiwari R G.A novel technique for data⁃base selection and document selection[J].International Journal of Computer Applications,2011,17(8):22-26.
[11]张文龙,刘一伟,张杰.基于Nutch垂直搜索引擎研究[J].南开大学学报:自然科学版,2012(2):37-44.
[12]Cafarella M,Cutting D.Building nutch:Open source search[J]. ACM Queue,2004,2(2):21-24.
[13]成龙.Lucene搜索引擎开发进阶实战[M].北京:机械工业出版社,2015.
[14]罗刚,王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010.
[15]张俊林.这就是搜索引擎核心技术详解[M].北京:电子工业出版社,2012.
[16]王国平.IBM SPSS Modeler数据与文本挖掘实战[M].北京:清华大学出版社,2014.
[17]刘洪来,张小素.我国农产品价格波动影响因素分析[J].金融发展研究,2012(12):34-38.
[18]魏振香,徐菲.生产成本与农产品价格变化关系[J].价格理论与实践,2013(5):77-78.
[19]许世卫,李哲敏.农产品价格传导机制及其主要影响因素分析[J].中国科技论坛,2012(9):71-75.
[20]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000(1):32-43.
[21]HACIB T,Le Bihan Y.Microwave characterization using ridge polynomial neural networks and least-square support vector ma⁃chines[J].IEEE Transactions on Magnetics,2011,47(5):990-993.
[22]Deng N,Tian Y,Zhang C.Support vector machines:Optimization based theory,algorithms,and extensions[M].Boca raton:CRC Press,2012.
[23]Chang C C,Lin C J.LIBSVM:A library for support vector machines[J].ACM Transactions on Intelligent Systems and Tech⁃nology,2011,2(3):27-36.
[24]Habibi Y,Sheisi G H,Abdi H.Voltage instability detection in power system using support vector machine(SVM)[J].Technical Journal of Engineering and Applied Sciences,2015(2):22-26.
[25]张宁,贾自艳,史忠植.使用KNN算法文本分类[J].计算机工程,2005(8):171-172.
[26]闫永刚,王建.KNN分类算法MapReduce并行化实现[J].南京航空航天大学学报,2013(4):550-555.
[27]郝秀兰,陶晓鹏,徐和祥,等.KNN文本分类器类偏斜问题一种处理对策[J].计算机研究与发展,2009(1):52-61.
[28]刘丽,孙燕唐.智能型元搜索引擎设计与实现[J].计算机工程,2003(6):118-120.
Research and implementation of agricultural prices subject search engine
MENG Fanjiang,JI Xiang,YUAN Qi,LIU Dong,HOU Zhepeng
(School of Electrical and Information,NortheastAgricultural University,Harbin 150030,China)
Current agricultural vertical search engine can't assess the price trend of agricultural products,not suitable for agricultural producers to analysis the market quotations,in view of the present situation,paper researched and designed the agricultural prices subject search engine.First,web crawler collected web pages from the agricultural comprehensive web site,and the web page for transcoding,deduplication,extract content and so on;then,use the Topic similarity algorithm of this paper to judge the correlation degree of web pages,and used the classifier to classify the web pages,topic related web pages would be parsed,stored;finally,extracted the information of the price of agricultural products and the information of its influencing factors.Experimental results showed that the system could collect the information of agricultural products prices very well,and the system could also collect the information of the factors affecting the price of agricultural products,provided data support for the follow-up study of the price forecasting of agricultural products.
web crawler;information crawl;agricultural prices prediction;agriculture search engine
TP391.4
A
1005-9369(2016)09-0064-08
2016-04-26
国家星火计划项目(2010GA670006)
孟繁疆(1968-)男,副教授,硕士生导师,研究方向为计算机应用。E-mail:fjmeng68@126.com
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子制作(2018年2期)2018-04-18
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
