
邮件分类
2016-10-26 03:10陈锐峰王硕杨
科学中国人 2016年26期
陈锐峰,王硕杨
山东大学
邮件分类
陈锐峰,王硕杨
山东大学
当今社会,邮件是人们交流信息的一个重要途径。然而随着广告业的迅猛发展,垃圾邮件逐渐成为了困扰广大邮件用户的最大的问题。本文的核心就是利用机器学习的方法,区分出垃圾邮件与普通邮件,意在对网络净化做出微薄贡献。
垃圾邮件;分类;机器学习
1.问题阐述
在现如今的社会,人们每天都用电子邮件与彼此进行交流,无论是业务往来还是个人行为,电子邮件的作用不言而喻。据报道,现如今已存在超过四十亿的电子邮件账户,这个数字可占现今存在词汇数量的几乎一半。但与之相伴而来一种现象,那就是越来越多的垃圾邮件出现在我们的电脑屏幕前。据估计,仅在2009年,超过97%的电子邮件被认为是垃圾邮件,这的确是个大问题。我们这篇文章的主要目的是将我们需要的邮件与垃圾邮件进行邮件分类,以挑选出我们所感兴趣的邮件。
理论介绍:支持向量机:在机器学习的领域中,支持向量机是一种与学习算法有关的可以为分类与回归问题分析数据的有监督学习模型。它的一种很重要的应用就是对有标签的数据进行分类。其目的是通过已知类别的两种数据点来预测新的数据点所属类别。其动机是将已知k维空间上的数据降维,并在k-1维的超平面上对其进行分类。
主成分分析:主成分分析是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量。它是用来简化数据的重要方法。其目的是用某几个主成分代替整个数据及以解释整个因变量,从而达到降维简化数据的目的。
2.方法描述
2.1数据集
我们的数据来自于https://archive.ics.uci.edu/ml/datasets/Spambase.
此数据集包含4691个样本,58个变量。最后一个变量(数据的最后一列)代表的是每一封邮件是否被判定为垃圾邮件,它是一个0-1变量。绝大多数的变量代表了某个单词或字母在电子邮件里出现的频数。第55到57三个变量测量了连续的大写字母序列的长度。
2.2核支持向量机
我们随机选择了全数据集的2/3作为训练数据集来找到合适的核函数,并且我们将剩余的1/3数据集作为检验数据集来进行预测并计算错误率。而后我们分别用交叉验证法以及循环来挑选高斯核,多项式核以及线性核的最优参数(交叉验证法是准确的,但同时又是耗时的)。

我们选择的最好的核是K(x,y)=0.9xTy(线性核)。
2.3线性主成分分析
为了减少数据集的维数并简化问题,我们在应用支持向量机之前先应用了主成分分析方法降维。我们试图使错误率最小化,将0.1作为分界水平,并同时降低数据集的维数。因此,在权衡了这其中的交换取舍后,我们最终将数据集的维数减少到13,这是一个可以接受的维数,并且可以简化本来维数很高的原问题。最终我们计算得到的错误率是0.099.
2.4核主成分分析
在完成线性主成分分析后,本文考虑在超平面上对数据进行分类来得到一个更好的结果,因为数据本身并不在线性平面上,因此本文尝试用核主成分分析对数据进行转化。本文首先运用多项式核函数来完成核主成分分析。和线性主成分分析的方法一样,在这里本文确定维数为15。选择新的数据后,本文重复高斯、多项式和线性三种核函数来完成核支持向量机。
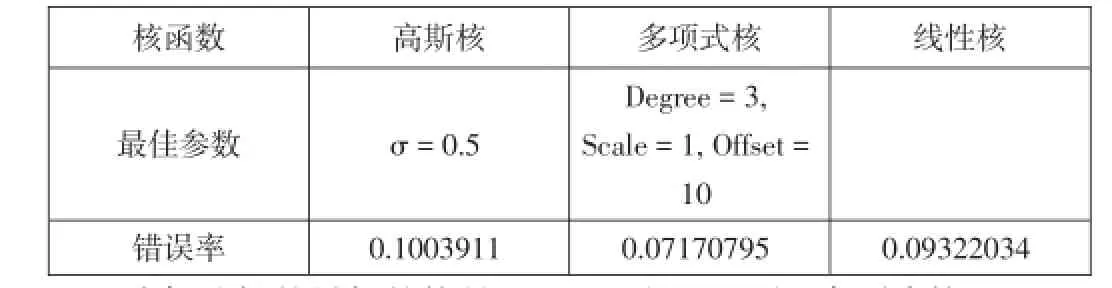
我们选择的最好的核是K(x,y)=(xTy+10)3(多项式核)。
2.5其他方法
2.5.1logistic回归QDA LDA。本文尝试用logistic回归、QDA、LDA的方法对数据进行分类,作为与核方法的比较,从而检验先前所用的核方法是否具有显著的优势。我们已经了解到在支持向量机的运用上,线性核函数是最佳选择,所以我们可以推测在logistic回归部分可以得到相似的结果。在QDA LDA部分,因为我们假设数据是呈正态分布的,我们可以推测最终得到的结果应该是不如核支持向量机得到的结果精确的。

2.5.2kmeans聚类。最后,本文尝试采用kmeans聚类的方法对数据进行分类。kmeans聚类在处理线性空间上的数据时表现非常好,然而在非线性空间上表现一般。通过应用kmeans聚类的方法,本文也佐证了我们的数据处于非线性空间上面。在kmeans聚类这部分,我们选择k=2(垃圾邮件和非垃圾邮件),最终本文得到的错误率是0.341。
3 结论
从R的输出结果我们可以发现,通过运用线性支持向量机,我们可以得到最小的预测错误率0.06323338.同时当我们运用由多项式主成分分析处理过的数据(降低维度至15)做支持向量机时,我们得到预测错误率为0.07170795。这些结果表明当我们想要得到最精确的结果时,我们最好运用线性支持向量机而不是在高维空间上直接运用复杂的数据。再有我们还可以先采用多项式主成分分析对数据进行降维处理,将维数降至15,这样一来我们可以降低问题的复杂性,让数据在一个较低的维度上呈现,这样我们也可以得到一个比较好的结果和可接受的预测错误率。
在我们的应用中,邮件分类的主要依据是高频出现在垃圾邮件中的词汇和字符,这些词汇和字符的出现率是有别于普通邮件的。鉴于此,我们还可以考虑更多诸如此类的因素作为邮件分类的依据。举个例子说明,很多垃圾邮件会在凌晨发送给用户(即发送时间因素)。
[1]Ron Kohavi;Foster Provost(1998)."Glossary of terms".Machine Learning 30:271-274.
[2]Mannila,Heikki(1996).Data mining:machine learning,statistics,and databases.Int'l Conf.Scientific and Statistical Database Management.IEEE Computer Society.
陈锐峰(1994-),男,汉族,重庆市人,学生,统计学士,单位:山东大学,研究方向:数理统计。
王硕杨(1994-),男,汉族,山东省青岛市人,数学学士,单位:山东大学,研究方向:数理统计。
猜你喜欢
广西大学学报(自然科学版)(2022年2期)2022-07-06
火力与指挥控制(2021年10期)2021-12-29
英语文摘(2021年10期)2021-11-22
广东蚕业(2021年2期)2021-04-22
计算机与网络(2020年4期)2020-04-20
新课程·上旬(2019年1期)2019-03-18
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
教学研究与管理(2014年4期)2014-05-16
计算机世界(2009年35期)2009-11-17
