
基于极大频繁关联模式挖掘的复制算法研究
2016-10-15 07:01:47刘瑞雪秦丹阳杨松祥
黑龙江大学工程学报 2016年3期
刘瑞雪,秦丹阳,贾 爽,杨松祥
(1.哈尔滨工业大学 深圳研究生院,广东 深圳 518055;2.黑龙江大学 电子工程学院,哈尔滨 150080 )
基于极大频繁关联模式挖掘的复制算法研究
刘瑞雪1,2,秦丹阳2,*,贾爽2,杨松祥2
(1.哈尔滨工业大学 深圳研究生院,广东 深圳 518055;2.黑龙江大学 电子工程学院,哈尔滨 150080 )
针对现有基于数据挖掘的文件关联性复制算法无法有效提取文件关联性的问题,提出了基于极大频繁关联模式挖掘的分散群复制算法(Decentralized Replication strategy based on Maximal Frequent Correlated Patterns, DRMFCP)。DRMFCP算法通过二进制历史文件转换、极大频繁关联模式挖掘和复制,以实现极大减少复制模式数量、消除冗余以及优化复制的目的。数据分析与仿真结果表明,在不同存取模式下相较于无复制、DR2、PRA和PDDRA算法,DRMFCP算法提取文件关联性的效率更高,并能同时降低作业执行平均时间,为降低网格数据传输延迟提供新的解决方案。
数据挖掘;关联模式;数据复制;分散群
数据网格是一种管理科学实验和工程应用领域中产生的大量分布式数据的集成架构[1]。数据复制技术能够改善数据网格的响应时间,减少带宽消耗并维护系统可靠性。然而,目前多数复制算法在运行时只考虑了单一文件群,而忽略了各文件群间的关联性。分析表明,许多实际的数据密集型应用与文件群的关联性密切相关。因此,有效提取文件关联性成为相关研究领域的热点。数据挖掘技术可从大量数据集合中提取有价值信息,利用数据挖掘技术挖掘网格数据,能够有效发现文件间隐藏的关联性,从而实现优化网格副本管理模块的目的。
挖掘文件间关联性可以采用频繁序列挖掘和关联模式挖掘两种方法。典型的PRA[2]和PDDRA[3]算法主要是基于频繁序列挖掘的复制算法,每次运行时,为了预测请求的文件,将不断进行频繁序列挖掘,这不仅会增加复制的文件数量,也会对网格响应时间及存储占用百分比造成较大的影响。Apriori算法[4]是最典型的关联模式挖掘算法之一,它能够从大型数据集合中识别出频繁项集合,从而生成强关联模式。Apriori算法属于比较成熟的数据挖掘算法,其优化及衍生态挖掘方式可以应用于不同行业领域[5-7]。但是,常见的关联模式挖掘算法提取模式中大多存在冗余,无法反映出文件真实的关联情况[8,9]。为此,本文在已有研究的基础上,提出一种基于关联模式挖掘的分散群复制算法DRMFCP,通过优化周期参数并利用极大频繁关联模式挖掘模块,周期地在实际的网格环境中触发数据挖掘,用以实现降低网络延迟、快速访问远程有价值文件的目的。
1 极大频繁关联模式挖掘
1.1基本定义

定义1全置信度。全置信度是一种关联性度量,用于判断模式的关联性程度。项集X⊆I的全置信度的计算公式为:
(1)

1)反单调性。对于任意项集I⊆I,I1⊆I,如果I满足约束条件Q能推出I1也满足条件Q,则约束Q是反单调的。
3)零不变性。零不变关联性度量允许定量分析同一组中项的相互关联程度,而不考虑不属于提到的组的项[10]。对于模式I⊆I,称不包含I的事务为零事务,那么零事务数一定不能决定I的零不变关联性,从而避免了零事务对判断关联性的影响。

定义3极大频繁关联模式。若X是频繁关联模式,但是X的超集一定不是频繁关联模式,那么称X为极大频繁关联模式。定义极大频繁关联模式能极大减少待复制的分散群数量,降低网格的存储占用,优化复制过程。
1.2极大频繁关联模式挖掘模块
为了对网格的分散群进行挖掘,需要提取前文所述的极大频繁关联模式,本节设计了一种极大频繁关联模式挖掘模块(Maximal Frequent Correlated Patterns Miner, MFCPM),主要通过算法1实现,其中相关符号定义见表1。
对算法1的子程序GENERATE_NEXT_FCP说明如下:①以FCP为输入,运行Apriori算法,生成候选k+1项集Ck+1;②确保每个Ck+1中的模式Xk+1满足全置信度的交叉支持性,否则进行剪枝;③确保每个Xk+1满足频繁关联模式的反单调性,否则进行剪枝;④若Xk+1能够同时满足上述两种性质,计算Xk+1的支持度并与最小支持度阈值minsupp进行比较,判断模式Xk+1是否频繁;⑤若Xk+1是频繁的,继续计算其全置信度。若Xk+1的全置信度不小于最小全置信度阈值min-all-confidence,说明Xk+1是频繁关联模式,将其添加到频繁关联模式集中。算法最终输出频繁关联模式k+1项集FCPk+1。
MFCPM模块输出的极大频繁关联模式将作为后续描述的DRMFCP算法的输入,继续进行后续的复制过程。

表1 MFCPM模块中使用的符号

Algorithm1 算法1 极大频繁关联模式挖掘模块算法(MFCPM)Input:二进制历史文件,最小支持度阈值minsupp,最小全置信度阈值min-all-confidenceOutput:极大频繁关联模式1Begin2k:=1;3FCP1:={i∈I|Supp(i)≥minsupp};%确定频繁项4MFCP:=FCP1;5WhileFCPk≠ϕdo6FCPk+1:=GENERATE_NEXT_FCP(FCPk,min-supp,min-all-confidence);7Foreach(Xk+1∈FCPk+1)do8IF(∃Xk⊂Xk+1|(Xk∈MFCP))then9removeXkfromMFCP10MFCP:=MFCP∪FCPk+1;%确保不存在冗余的模式11k:=k+1;12ReturnMFCP13End

图1 DRMFCP算法的主要步骤Fig. 1 Main steps of the DRMFCP strategy
2 基于MFCP的分散群复制算法
2.1算法的步骤
本文基于前节提出的MFCPM算法,设计了一种面向P2P数据网格拓扑的分散群复制算法(Decentralized Replication strategy based on Maximal Frequent Correlated Patterns, DRMFCP),通过协同定位分散群来改善网格性能,该算法包括4个执行阶段,见图1。
1)提取文件存取历史。针对本地文件和远端文件的请求,当前站点作业需要在每个执行周期内记录文件存取历史,作业存取顺序由存取模式决定。
2)将文件存取历史转换为二进制历史文件。二进制历史文件实际上是由存取的目标文件和作业组成的包含逻辑值的列表。
3)生成极大频繁关联模式。利用MFCPM模块挖掘分散群之间隐藏的关联性,简化后续的复制过程。
4)复制和置换。以MFCPM模块的输出作为本阶段的输入,主要根据待复制和待删除文件的平均权重选择保留或置换。
2.2二进制历史文件转换

在进行数据挖掘前,将文件存取历史转换为包含逻辑值0或1的二进制历史文件。为了进行转换,需要考虑文件的普遍性。如果站点Si执行的作业频繁的存取某一文件Fj,那么认为Fj在站点Si范围内是普遍的。引入每个文件被请求的平均次数AvgAccess(Fj),以便于评估站点Si中文件Fj的普遍性。AvgAccess(Fj)的定义式为:
(2)
其中,nj是存取文件Fj的总作业数。

2.3DRMFCP算法的复制过程
以MFCPM模块输出的极大频繁关联模式MFCP作为复制过程的输入。设MFCP={α1,α2,…,αn},任意元素αi∈MFCP都是作业频繁同时存取文件的集合。
DRMFCP算法复制过程的具体步骤如下:
1)对于αi∈MFCP,按照αi包含模式数的递减顺序,对MFCP中的元素进行排序。
2)对于αi∈MFCP,如果站点的存储空间足够存储αi中的所有文件,那么将复制αi中的所有文件到站点Si。
3)否则,将通过式(3)计算站点Si的文件Fj的权重,选择要删除的候选文件。
(3)

4)根据式(4)和(5)分别计算待复制的和待删除的文件组的平均权重。
(4)
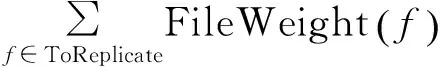
(5)

5)对两种平均权重值进行比较。若AvgGroupRepWeight>AvgCandidateDelWeight,那么待删除的候选文件将被待复制的文件所代替;否则放弃复制。

图2 OptorSim的体系结构Fig. 2 OptorSim architecture
3 性能分析与仿真评价
3.1仿真环境
本文使用OptorSim仿真器进行仿真。OptorSim是一种用Java语言编写的仿真包,被用于仿真数据网格结构并测试作业调度和复制算法[11-12]。OptorSim由用户、资源代理和许多站点组成。每个站点由计算元、副本管理器和存储元组成。OptorSim的体系结构见图2。本文的仿真环境为CMS实验台网格,网格拓扑见图3,由模拟欧洲和美国的20个站点组成。CERN和FNAL站点都拥有100 Gb的存储容量,其他站点均拥有一个计算元和50 Gb的存储容量。最初,网格中文件大小为1 Gb,文件总数为97,作业总数为1 000,存储在站点的SE中,采用顺序存取方式,使用当前作业成本与队列作业成本之和最小调度算法。

图3 CMS实验台网格拓扑Fig. 3 CMS testbed grid topology

图4 不同执行周期下DRMFCP算法的作业平均执行时间Fig. 4 Mean job execution time of the DRMFCP strategy for different periods
3.2执行周期对算法性能的影响
给定作业数为1 000,最小支持度和最小全置信度阈值固定,研究不同执行周期对DRMFCP算法作业执行平均时间的影响。这里定义所有作业独立运行时间的总和除以运行作业的总数即为作业执行平均时间。显然作业执行平均时间越短,算法性能越好。
仿真结果见图4,这表明1 000个作业执行时,每20个作业后(即2%)触发DRMFCP可以得到最小的平均执行时间。周期过短或过长时,都会频繁存取远端文件,导致作业执行平均时间增加,复制效率下降。
3.3阈值对算法性能的影响
给定作业数为1 000,周期为2%,分别研究最小全置信度阈值和最小支持度阈值等于0.2、0.4和0.6时,对应的最小支持度阈值和最小全置信度阈值的变化对DRMFCP算法的作业执行平均时间的影响,见图5。

图5 不同阈值下DRMFCP算法的作业平均执行时间Fig. 5 Mean job execution time of the DRMFCP strategy for different thresholds
由图5可见,阈值在0~0.5时,作业执行平均时间开始缓慢衰减,阈值超过0.5后,作业执行平均时间迅速增长,意味着算法性能恶化。仿真结果表明,阈值的增加可能会引起性能恶化,当最小支持度阈值和最小全置信度阈值均等于0.5时,算法的平均执行作业时间达到最低,意味着此时DRMFCP算法的性能达到最佳。
3.4存取模式对算法性能的影响
给定作业数为1 000,周期为2%,最小支持度阈值和最小全置信度阈值均为0.5,对比提出的DRMFCP算法与其他4种复制算法在不同存取模式下的性能表现,4种算法分别是无复制算法、DR2[13]、PRA和PDDRA算法。每次对比过程至少重复10次,并计算其均值。

图6 不同存取模式下的作业执行平均时间Fig. 6 Mean job execution time for different access patterns
1)不同存取模式下5种算法的作业执行平均时间见图6。仿真结果表明,对于不同的存取模式,相比无复制、DR2、PRA和PDDRA算法,DRMFCP算法的作业执行平均时间最多可分别降低80%,60%,20%和15%。
2)有效网络利用率(Effective Network Usage, ENU)是转移的文件与请求文件的比率,ENU的取值范围在0至1之间,计算公式如(6)所示,其数值越小说明采用的复制算法性能越好。不同存取模式下5种算法的ENU见图7。
(6)
其中,Nremotefileaccesses代表远端文件存取数;Nfilereplications代表文件副本数;而Nlocalfileaccesses代表本地文件存取数。
仿真结果表示,相比DR2、PRA和PDDRA算法,DRMFCP算法的ENU值最多可分别降低80%,70%和65%。算法研究的主要目标之一是最小化带宽消耗,减少网络业务量,相比之下,DRMFCP算法实现效果更好。
3)复制总数即为复制执行的总次数,复制总数大表明请求的文件大部分存储在远端。不同存取模式下5种算法的复制总数见图8。

图7 不同存取模式下的有效网络利用率Fig.7 Effectivenetworkusagefordifferentaccesspatterns图8 不同存取模式下的复制总数Fig.8 Totalnumberofreplicationsfordifferentaccesspatterns
仿真结果表明,对于所有的存取模式,相比DR2、PRA和PDDRA算法,DRMFCP算法的复制总数最多可分别减少40%,68%和70%,但仍然能确保数据网格中文件的可用性。复制总数越大意味着文件传输越多,其他的算法只是消耗了合理的网络带宽,而DRMFCP算法则成功地降低了复制总数且不会浪费更多的网络带宽。
4)命中率(Hit Ratio, HR)是存取本地文件总次数与存取所有文件总次数的比率,命中率的计算如式(7)所示。不同存取模式下各算法的命中率见图9。
(7)
仿真结果表明,对于所有的存取模式,相比DR2、PRA和PDDRA算法,DRMFCP算法的命中率最多可分别提高65%,20%和15%。
5)存储占用百分比是网格中各站点存储元利用率的平均值。存储元利用率是指文件使用的存储资源与存储元容量的比率。不同存取模式下5种算法的存储占用百分比见图10。

图9 不同存取模式下的命中率Fig. 9 Hit ratio for different access patterns

图10 不同存取模式下的存储占用百分比Fig. 10 Percentage of storage filled for different access patterns
由仿真结果不难看出,由于无复制算法不执行复制,因此存储占用百分比最小。除无复制算法外,对于所有的存取模式,相比同类DR2、PRA和PDDRA算法,DRMFCP算法的存储占用百分比最多可分别降低60%,65%和70%。
4 结 论
当今社会许多科学和工程领域产生的数据量与日俱增,因此各领域对计算和存储的要求也越来越高,数据网格作为一种合理的解决方案应运而生。本文以网格中各站点分布的分散群为对象,在传统的复制算法基础上增加了极大频繁关联模式挖掘模块,提出了基于极大频繁关联模式挖掘的分散群复制算法DRMFCP。与同类算法相比,DRMFCP算法的作业执行平均时间和ENU最多可降低80%,而命中率最多可提高65%。仿真结果说明,DRMFCP算法以分散群为挖掘对象,能够减少待复制的文件数量,从而改善网格性能,具有一定优势和良好的应用前景。未来的研究将对站点的文件存取历史进行优化,并采用多维动态的数据挖掘技术,以进一步改善复制过程,使算法更加适应实际网格环境的要求。
[1]王元卓, 贾岩涛, 刘大伟, 等. 基于开放网络知识的信息检索与数据挖掘[J]. 计算机研究与发展, 2015, 52(5): 456-474.
[2]Tian T, Luo J, Wu Z, et al. A pre-fetching-based replication algorithm in data grid[C]//Proceedings of the 3th International Conference on Pervasive Computing and Application. 2008: 526-531.
[3]Saadat N, Rahmani A M. PDDRA: a new pre-fetching based dynamic data replication algorithm in data grids[J]. Future Generation Computer System, 2012, 28(4): 666-681.
[4]Agrawal R, Imielinski T, Swami A. A mining association rules between sets of items in large databases[C]//Proceedings of the 1993 ACM SIGMOD Conference. 1993: 207-216.
[5]刘端阳, 冯建, 李晓. 一种基于逻辑的频繁序列模式挖掘算法[J]. 计算机科学, 2015, 42(5): 260-264.
[6]王秀枝, 冯建, 李晓. 基于支持度和置信度智能优化的关联分类算法[J]. 计算机应用与软件, 2013, 30(11): 184-186.
[7]赵佳璐, 杨俊, 韩晶, 等. 基于事务ID集合的带约束的关联规则挖掘算法[J]. 计算机工程与设计, 2013, 34(5): 1663-1667.
[8]Bouasker S,Hamrouni T, Yahia B S. Ecient mining of new concise representations of rare correlated patterns[J]. Intelligent Data Analysis, 2015, 19(2): 359-390.
[9]Kiran R U, Kitsuregawa M. Mining correlated patterns with multiple minimum all-confidence thresholds[C]//Proceedings of the 17th Pacific-Asia Conference on Knowledge Discovery and Data Mining. 2013: 295-306.
[10] Wu T, Chen Y, Han J. Re-examination of interestingness measures in pattern mining: a unified framework[J]. Data Mining and Knowledge Discovery, 2010, 21(3): 371-397.
[11] Grace R K, Manimegalai R. Dynamic replica placement and selection strategies in data grids-a comprehensive survey[J]. Journal of Parallel and Distributed Computing, 2014, 74(2): 2099-2108.
[12] Amjad T, Sher M, Dau M.A survey of dynamic replication strategies for improving data availability in data grids[J]. Future Generation Computer System, 2012, 28(2): 337-349.
[13] Suri P, Singh M. A two-stage dynamic replication strategy for data grid[J]. Recent Trends in Engineering and Technology, 2009, 2(4): 201-203.
Research on replication strategy based on maximalfrequent correlated patterns mining
LIU Rui-Xue1,2,QIN Dan-Yang2,*,JIA Shuang2,YANG Song-Xiang2
(1.ShenzhenGraduateSchool,HarbinInstituteofTechnology,Shenzhen518055,Guangdong,China;2.SchoolofElectronicEngineering,HeilongjiangUniversity,Harbin, 150080,China)
Aiming at the problem that most of the existing data mining based replication strategies cannot extract correlations between files effectively, an improved replication strategy based on maximal frequent correlated patterns mining, called DRMFCP, is proposed. By converting the file access history to a binary history file, applying maximal frequent correlated patterns mining and performing replication, DRMFCP can extremely reduce the number of patterns to replicate, eliminate redundancy and optimize the replication performance. Data analysis and simulation results show that comparing with other strategies, such as no replication, DR2, PRA and PDDRA, DRMFCP can extract correlations more effectively and gain lower mean job execution time with different access patterns, which will provide a new option to reduce transmission delay in data grid.
data mining; correlated patterns; data replication; distributed groups
10.13524/j.2095-008x.2016.03.045
2016-05-13
国家自然科学基金资助项目(61302074);教育部高等学校博士学科点专项科研基金资助项目(20122301120004);黑龙江省自然科学基金资助项目(QC2013C061)
刘瑞雪(1993-),女,内蒙古赤峰人,硕士研究生,研究方向:数据挖掘,E-mail:ruixue_liu@foxmail.com;*通讯作者:秦丹阳(1984-),女,江苏苏州人,副教授,硕士研究生导师,博士,研究方向:泛在通信与普适计算,E-mail:qindanyang@hlju.edu.cn。
TN915.5
A
2095-008X(2016)03-0074-08
网络出版地址:http:www.cnki.net/kcms/detail/23.1566.T.20160719.1132.008.html
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
计算机应用(2018年5期)2018-07-25 07:41:26
中成药(2017年3期)2017-05-17 06:09:05
中国自行车(2017年1期)2017-04-16 02:53:52
故事会(2016年21期)2016-11-10 21:15:15
中国环境监察(2016年12期)2016-10-24 05:29:18
中国卫生标准管理(2015年6期)2016-01-14 05:17:08
轴承(2015年2期)2015-07-25 03:51:04
