
基于视觉特征的书法风格识别
2016-09-20 08:14汪潇章夏芬韩德志
现代计算机 2016年21期
汪潇,章夏芬,韩德志
(上海海事大学信息工程学院,上海,201306)
基于视觉特征的书法风格识别
汪潇,章夏芬,韩德志
(上海海事大学信息工程学院,上海,201306)
纸质图书和书法书籍的数字化及网络传播,方便书法学术的研究和书法爱好者的使用。为了对书法风格进行识别,提出基于特征书法风格分类方法:首先,对单字图像进行特征提取。接着,用爬虫技术,将单字转化为笔画,提取笔画特征。然后,将提取的24类特征作为特征向量,构造风格模型。最后,提取用户提交样本图的风格特征,与五类风格进行相似性比较,将样本字归属为概率最大的风格类型。
书法风格;风格识别;视觉特征;风格量化
0 引言
随着书籍的数字化及网络技术的推进,大量书法书籍扫描图像在网络上传播,使原本脆弱的、易被大火焚烧的历史书法书籍得以保存、传承和传播,如亚历山大图书馆由于战火而遭到永久毁灭。扫描得到的大量书法页面图像扫描至中美百万册数字图书馆中[1],是全球数字图书馆的重要组成部分[2],采集来的图像主要由碑帖和书帖组成,碑帖的背景主要为黑色,前景色书法字为白色,如图1(b)和(e)所示,书帖的背景色主要为灰色或黄色,字体为黑色,如图1(a)、(c)和(d)所示。扫描来的书法图像,是由不同朝代的人书写,与有着同一字体模型的打印体不同,富有情感色彩,风格多变。传统的将书法作品分为五大类,分别是篆书、隶书、楷书、行书、草书。篆书属于古文字,其特点是字单纯简单、以直弧笔画为主、粗细一致、横平竖直、多圆转而无方折[3]。隶书的横画最有特点,也是最能够表征隶书区别于其他书体的特征,文字描述就是“蚕头雁尾、一波三折、雁不双飞”[4]。楷书的特点为字体方正、中心平稳、笔画分明,因此,对于楷书的主要衡量方式使用书法字的结体特征能够比较好地进行表征。行书是楷书的连写与快写,草书是对行书的笔画简化以及进一步的连写、快写。如图1所示即为五种风格书法的页面扫描图像。

图1 页面图像
书法风格的分类,在以往的艺术领域,是由人工操作通过视觉的感触对书法作品进行分类。在计算机领域对书法识别分类进行初步研究,是基于底层的书法特征对书法进行分类识别。书法风格的分类基于笔记学[5],所以对于书法风格的识别需要从单个笔画的特征入手。
本文为了使计算机能识别书法风格,将视觉风格特征转化为可供计算机读取的书法字图像底层语义,提取风格特征,判别书法风格。
1 相关工作
书法是手写体的一种,用毛笔书写而成,书法风格的分类与手写体笔迹鉴定具有相似的问题。对手写体数字识别进行了相关研究[6-7],基于手写体的研究,大量的研究人员对书法风格展开了研究[8-10]。将手写字分为汉字领域和非汉字领域,在非汉字领域里,Srihari已对手写字研究数十年,提出手写体鉴定方法[11],基于统计模型判断两种手写体是否由同一人书写。Azmi等人提出了基于不等边三角形提取特征的阿拉伯书法分类[12],但是三角形特征不适用与中国的书法结构。国外的手体结构是一维的,而汉字的构成是二维的,所以研究字的特征并不相同,可以将方法应用到书法的研究上。Bar-Yosef等人对历史希伯来书法作品进行二值化和书写识别,通过选取的信件和比较知名的手写样本中提取特征向量,他们的目的是识别不同手写风格的位置、日期和作者,他们的方法虽然使用于汉字笔画,但是他们的实验数据量较小,对于复杂度大的笔画还不适用[13]。
在汉字书法领域的研究上,基于CADAL扫描中心的书法图像,鲁伟明等人为了使用者可以便利地欣赏同一种风格的书法作品,提出了一种基于元数据的方法[14],提取书法风格特征,对书法风格进行研究,但是他们所用的测试图片有限,构成的数据库不够明确,有待改进。庄越挺等人挖掘书法潜在风格模型[15],提出基于多项式概率分布的风格代表来估计可能影响风格模型的因素,用于满足人们能欣赏到同一种风格的书法作品。这种计算不同风格相似性的想法是可行的,但是他们没有详细说明风格特征和风格要素。
上述作者都对手写体的风格做了一定的研究,不同文字风格识别方法上存在一定相似性,但是特征不同,所以风格模型也不相同。因此,对于书法风格的研究需要新的方法去识别,基于书法的视觉特征对书法风格进行量化识别是现在要完成的工作,其中的首要任务,是根据统计学的原理进行风格特征的提取,将特征进行数字量化。
2 系统架构
2.1 系统框架
本文的书法风格识别系统框架如图2所示,对扫描得到的页面图像提取特征,将24类风格特集组成特征向量,对其进行聚类分析,构成风格模型存入书法数据库。然后对样本字图像经过特征提取,用PCA进行风格分类,最后对分类结果进行展示。
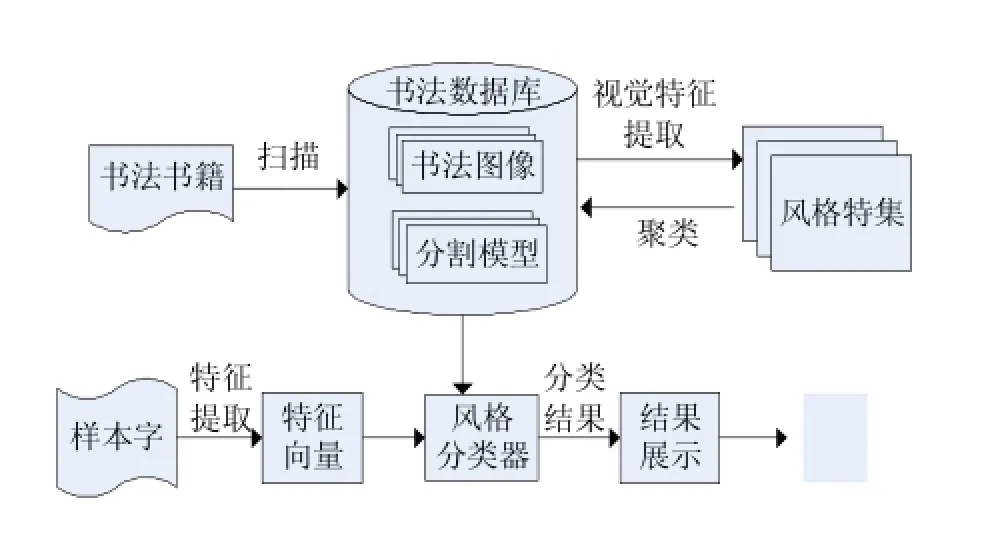
图2 书法风格识别系统
2.2 数据来源
实验数据是由《中国历代楷书真迹》、《中国历代帝王御藏名帖》、《柳公权玄秘塔碑》等54卷书法书籍扫描的得到的页面图像,将得到的页面图像进行切分,扫描精度的600DPI(Dots Per Inch),图像格式为*.TIFF,共259页的页面图像被分割成8279个单字图像。
书法分类前需要对8279个字的训练样本进行标注,以页为单位,将书法风格分为五类(#1,#2,#3,#4,#5)。图3展示了书法数据库结构,包括书的信息(book)、页面信息(page)、作者信息(author)。
3 特征提取
本文书法风格特征有两个层次:基于单字的字级书法特征和基于笔画的笔画级书法图像特征。
3.1 页面切分
切分书法字的原理是利用字间空白的地方框出书法字,先分离出背景色和字的颜色。然后纵向切分出列,接着横向把列切分成单个书法字。按照如上方法,将图1所示的页面图像切分至单字图像,切分的部分单字图像如图4所示,每个单字图像由最小包围(topX,topY,buttonx,buttonY)和确定字的位置;判断风格识别是否正确(#1,#2,#3,#4,#5):
3.2 去噪
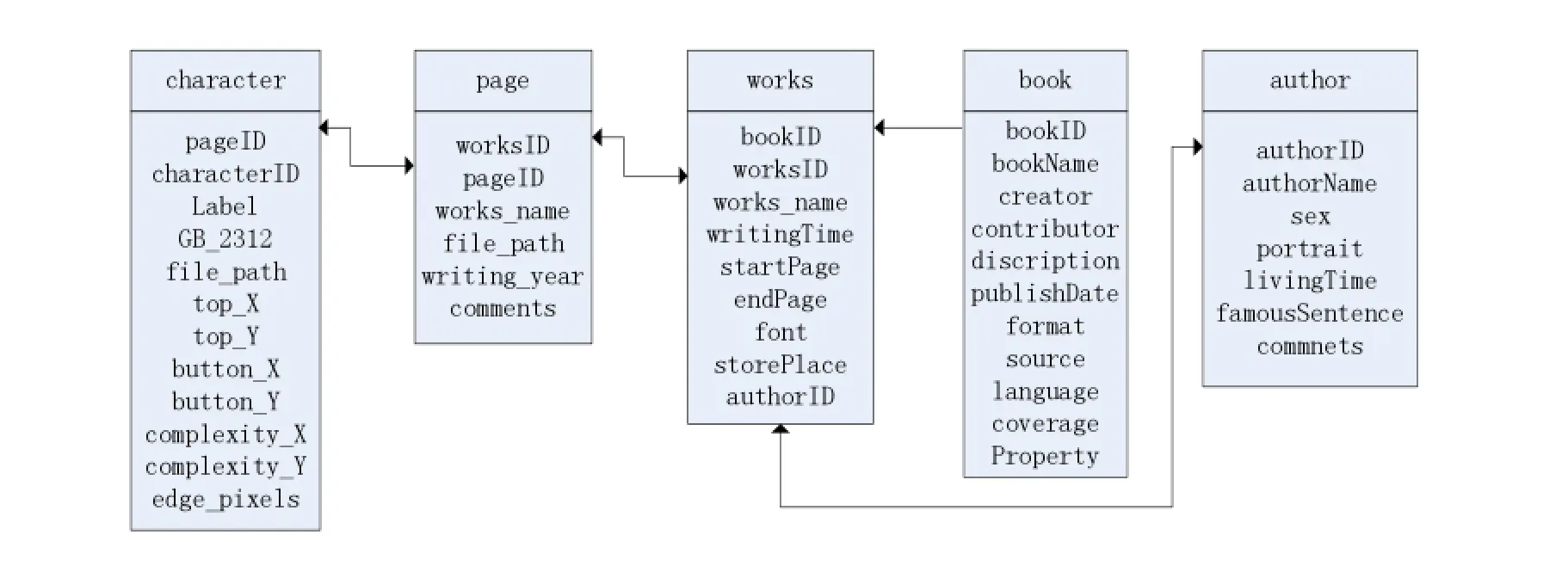
图3 五张数据表之间的主外键关系

图4 单字图像
大部分历史书籍会有不同程度的噪声存在,噪声可以分为两类:(1)噪声为印章、毛刺、自然腐蚀,如图5 (a)所示红色圈标注的印章噪声;(2)噪声是由于书法家对行书和草书的书写过快,导致了有些笔画粘连在一起,如图5(b)所示,这些噪声的存在都会对视觉特征的提取和书法风格的识别造成影响,不能正确提取书法的骨架,所以我们需要对单字的噪声进行处理。
如下图5(b)所示骨架之间出现粘连:
对第二类噪声的处理,先找到牵丝处,然后断开牵丝点:
(1)提取每个骨架点:用参考文献[16]的细化方法,使骨架点为一个像素点;
(2)计算骨架点宽度:如图6所示,以骨架点为中心的圆,初始半径为一个像素点,依次增加半径,以95%为阈值,当圆内有95%是背景色时停止半径增大,此时的半径即为该点骨架宽度,即图中的d;

图5 带噪声的书法字图像

图6 骨架某点笔宽
(3)判断有无牵丝:牵丝即为两个粗笔中间细小的粘连,譬如图7(a)中圈出来的地方;计算整个字内骨架点宽的均值u和方差σ,根据实验测试如果某点大于1.8σ的范围,则此点为牵丝点;
(4)断开牵丝:以该骨架点为中心,将此点和周围两个像素点置为背景色,即牵丝断开;如图7(b)所示;
(5)提取新的骨架;上述处理结果再次细化后的结果如图7(d)所示,未细化前的处理结果如图7(c)所示。
3.3 字级特征提取
字级特征是以字为单位,对字的粗细、高宽比等特征进行研究而提取的特征。提取这些图像上的视觉特征,组成特征向量。因为书法字笔画的粗细不均匀、变化幅度大,所以平均笔宽、笔宽变化率、最大笔宽值、最细笔宽值可以作为字级风格的特征。同时,研究书法字图像的其他方面,那些不依赖与骨架和笔画提取的特征有黑白二值比、高宽比、重心位置、左右墨点比、倾斜率、字在X轴压力变化、字在Y轴压力变化、字在X轴倾斜平衡、字在Y轴倾斜平衡。令骨架图上共有n个像素点,二值化图像为M×N像素点,(x,y)为坐标,P(x,y)表示二值图像像素点:

黑白二值比为:

对于每个字,以每个骨架点i为中心,圆内像素点95%以上的点为二值前景色的最大半径di:
平均笔宽:

笔宽在不同书法风格中是不一样的,笔宽计算基于上文骨架点,统计该字内所有骨架点平均笔宽即为平均字的平均笔宽。由于隶书和楷书书写速度比较慢,有着均匀的笔宽和变化率,而草书和行书书写随意,经常有粘连出现,笔宽变化较大,可以由最大笔宽值和最细笔宽值来量化表示,最大笔宽值即为所有点宽度的前1/5的平均宽度:

最小笔宽值,就是所有点宽度的后1/5的平均宽度

如图3(a)笔画宽度比较细,图3(b)的笔画宽度比较粗,各种风格的笔画宽度都不相同,可作为风格特征向量。
笔宽变化率:
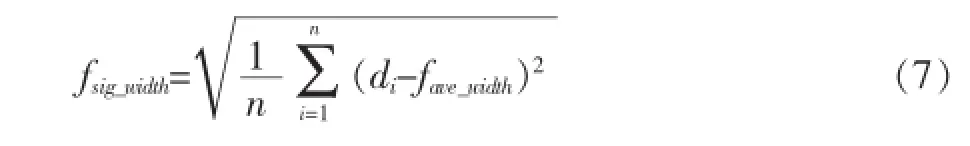
如图3(a)笔画宽度粗细比较一致,变化率小,图3 (b)的笔画宽度有粗有细,变化率大。
不同书法风格字体的中心位置有上下左右之分,重心位置可作为风格特征之一,重心位置计算公式如下:
字在横向(X轴)的重心:

由于书写书法的毛笔较软,手写的力度不同会导致墨点的深浅不一,所以墨点比可作为风格特征向量之一,左右墨点比:
字在Y轴压力变化特征fstress_y如公式(11)。
字在X轴倾斜平衡fslant_x如公式(12)。
字在Y轴倾斜平衡fslant_y如公式(13)。

图7 断牵丝处理图
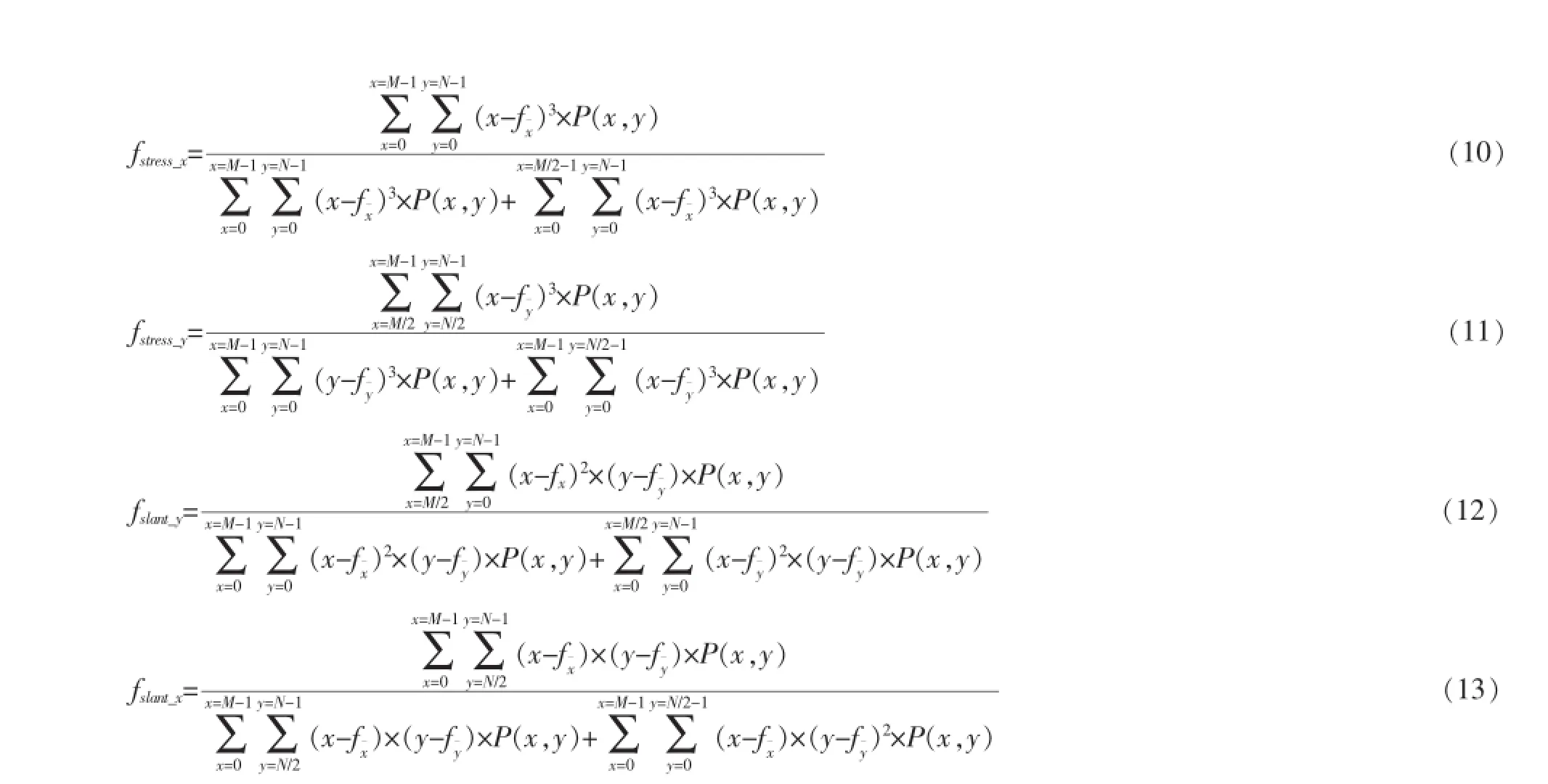
3.4 笔画级的特征
对于行书和草书来说,书写速度快,不容易检测出横竖笔划,而隶书、楷书横竖笔划比较容易分辨。根据单个字的笔画对比,发现可以将笔画风格分成两类,即横笔特征和竖笔特征,包括笔画个数、平均斜率、横向码比值等。
3.5 风格特征向量
将上文的12类字级特征与12类笔画级特征元素组成具有24个元素的特征向量,如表1所示。
4 书法风格模型
基于上文的特征向量及训练样本,风格模型基于高斯概率分布模型构造。接下来需要分析训练样本的特征数据统计分布,用于构建书法风格模型。将量化的特征存于特征向量里,计算训练样本的概率分布情况,最后计算待识别字的特征概率分布,从而判断类型。
实验组穿刺成功率高于对照组,差异具有统计学意义(P<0.05);实验组穿刺时间短于对照组,差异具有统计学意义(P<0.05);实验组并发症发生率低于对照组,差异具有统计学意义(P<0.05)(表2)。两组并发症均为误入颈内动脉,均未发生血胸、气胸及神经损伤。
4.1 符号说明
本文的符号如下所示:
wk:书法风格分类,其中下标k=1,2,…,5是5种风格的标号;
Mk:每种风格各自具有的样本数;
Sj,k:数据库存储的一个书法字样本, 其中j= 1,2,...,Mk;
σ2j,k:书法字样本每类风格的方差;
fl,j,k:书法字Sj,k的24个特征变量,其中l=1,2,…,24;
Fj,k=[f1,j,k,f2,j,k,…,f24,j,k]:每一个书法字样本的24个特征值fl,j,k组成特征值向量。
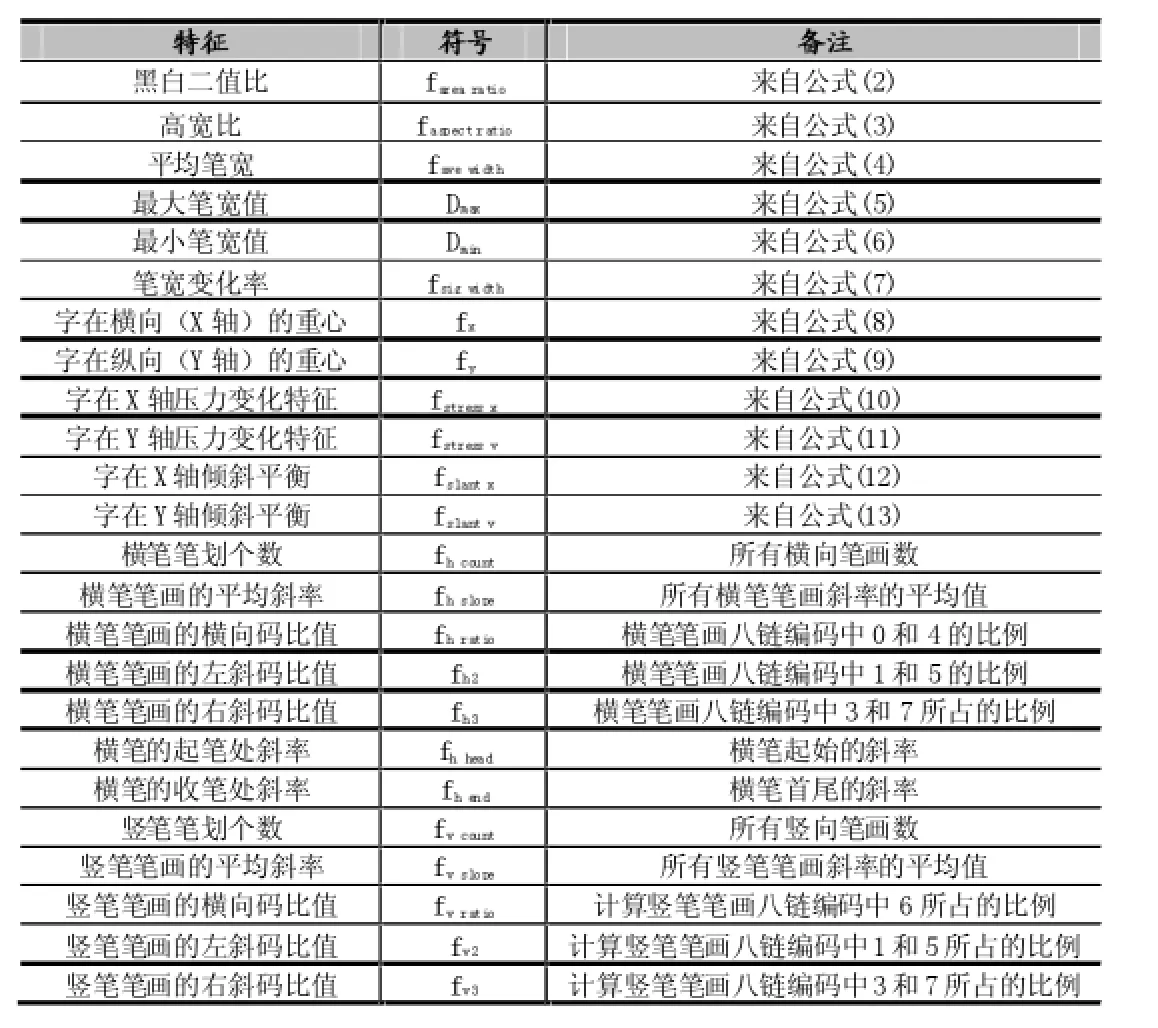
表1 风格特征向量表
4.2 聚类中心
基于已标注的五类风格,计算每一类风格的类中心,求得平均值uk,离聚类中心最近的字,即为这种类的风格类型。平均值的计算公式如下:

4.3 类间变化
计算同一类风格训练样本的聚类偏差,如下:

4.4 协方差
计算每种风格的训练样本的风格特征值向量的协方差矩阵公式如下:
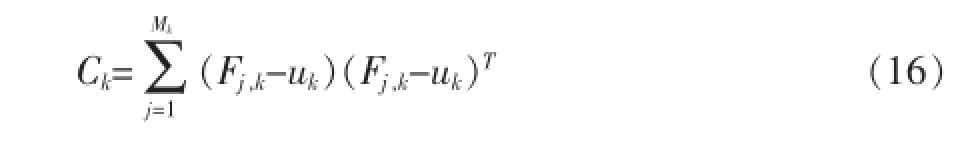
5 风格识别
本文选取PCA的分类方法,对于待识别的字,先提取特征,将提取的特征量化作为特征向量,计算待识别字的类分布概率,判断跟哪一类风格最为相似,从而确定字的风格属于哪一类。

图8 五种书法风格的例子
本文所使用的线性分类器是基于高斯特征分布的,计算待识别书法字属于每一种风格的条件概率Pk,一共有5个条件概率值,根据条件概率的值判断书法字的风格,条件概率值最高的那个风格即是这个待识别书法字的主要风格,风格概率的计算公式为:

Ck-1是每种风格的训练样本的风格特征值向量的协方差矩阵的逆矩阵,uk是每种风格的训练样本的风格特征值向量的平均值向量,Q是待识别书法字,F是待识别书法字的风格特征值,wk是书法风格分类标签。
对样本属于哪一类风格的概率值,进行归一化处理,处理公式:

6 实验
6.1 数据选取
本文所用实验数据从CADAL数字图书馆中获取,共从256页书法图像上分割出600像素的单字图像8279个。从中选取4500个作为训练样本,进行风格标
6.2 实验结果
基于上文的聚类,挑选出离聚类中心最近的前8个字图像,如图8所示:每个字下面的阿拉伯数字为character ID的值;第一行为篆书图像、第二行为隶书图像、第三行为楷书图像、第四行为行书图像、第五行为草书图像。
对于单个字的分类结果如图9所示,属于五类风格的概率图如下所示:
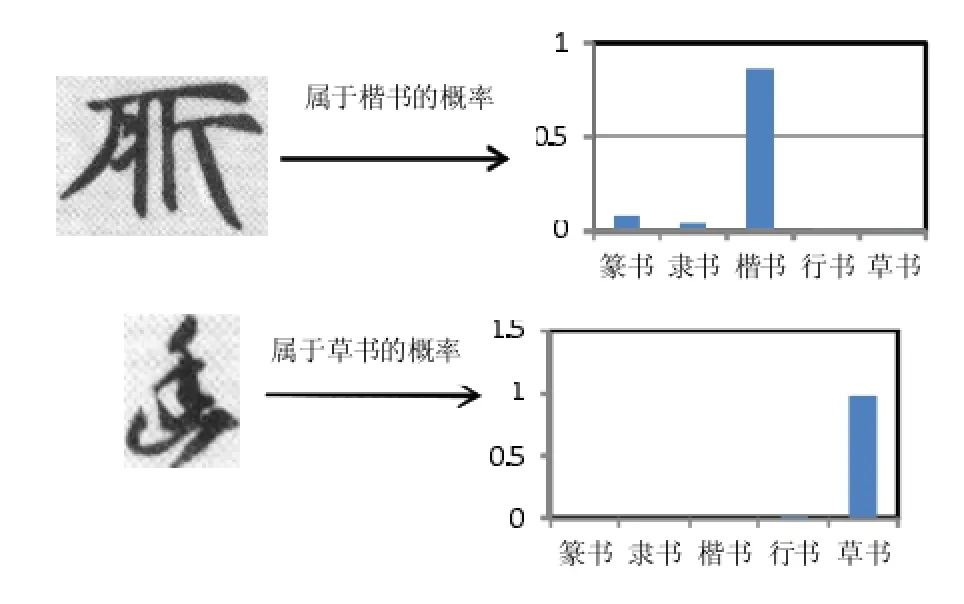
图9 样本字属于五类风格的概率
从训练样本中挑选出 2640个字(529个风格#1,918个风格#2,493个风格#3,211个风格#4,489个风格#5)进行风格识别的正确率统计,结果如下表2所示。
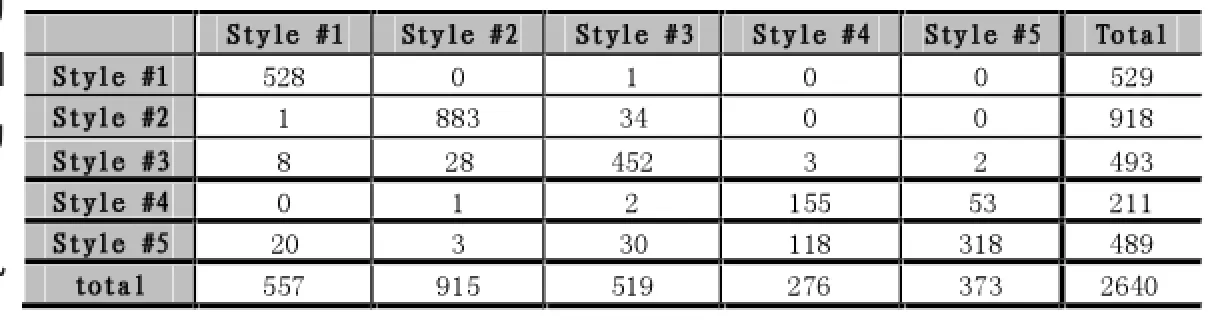
表2 风格分配表
通过上表计算可得,风格#2的识别错误率为:1-883/918=0.04;风格#4的识别错误率为:1-155/211= 0.27;风格#5的识别错误率为:1-118/489=0.76。由此可见,识别率越来越低。
7 结语
本文通过提取底层书法字级以及笔画级的图像特征,构建书法风格模型,将样本与所构建风格模型进行相似度比较,能初步实现对书法风格的识别功能。对篆书和隶书的平均识别的正确率达到70%。但是,对于草书和行书,这类笔画粘连过多的书法字,识别率较低,是以后仍要研究的方向,继续提高书法识别的正确率。
[1]CADAL书法.http://www.cadal.zju.edu.cn、.访问日期:2015年9月28日
[2]全球数字图书馆.http://www.ulib.org.访问日期:2015年9月28日
[3]巨保铭.汉字书法风格浅析[J].沧桑,2008,,(5):237-238.
[4]曹云鹏.历代书法风格转换与书法创新分析[J].艺术百家,2012.
[5]H.Clifford.Graphology:How to Read Character from Handwriting,with full Explanation of the Science,and Many Examples Fully Analyzed,Penn Pub.Co.,Philadelphia,1905.
[6]K.Hanusiak R,S.Oliveira L,Justino E,et al.Writer Verification Using Texture-Based Features[J].Document Analysis&Recognition,2012,15(3):213-226.
[7]Mori S,Suen C.Y.,Yamamoto K.Historical Review of OCR Research and Development[J].Proc.IEEE.,1992,80(7):1029-1058.
[8]X.Zhang,G.Nagy.Style Comparisons in Calligraphy,Procs.SPIE/IST/DRR,San Francisco,Jan,2012.
[9]Han C C,Chou C H,Wu C S.An Interactive Grading and Learning System for Chinese Calligraphy[J].Machine Vision and Applications,2008,19(1):43-55.
[10]L.Yang and L.Peng.Local Projection-Based Character Segmentation Method for Historical Chinese Documents.Proc.SPIE8658,86580O,2014.
[11]S.N.Srihari.Computational Methods for Handwritten Questioned Document Examination.Final Report,Award Number:2004-IJCX-K050,U.S.Department of Justice.
[12]M.S.Azmi et al..Arabic Calligraphy Identification for Digital Jawi Paleography Using Triangle Blocks[J].in International Conf.on Electrical Engineering and Informatics,Malaysia,2011:1-5.
[13]I.Bar-Yosef et al..Binarization,Character Extraction,and Writer Identification of Historical Hebrew Calligraphy Documents[J].Int. J.Doc.Anal.Recognit,2007,9(2-4):89-99.
[14]Wei-ming Lu,Yue-ting Zhuang,Jiang-qin Wu.Discovering Calligraphy Style Relationships by Supervised Learning Weighted Random Walk Model[J].Multimedia Systems,2009,15:221-242.
[15]W.Lu,Y.Zhuang,and J.Wu.Latent Style Model:Discovering Writing Styles for Calligraphy Works.[J].Vis.Commun.Image Represent,2009,20(2):84-96.
[16]刘峡壁,贾云得.一种字符图像线段提取及细化算法[J].中国图象图形学报,2005,10(1):48-53.
Calligraphy Style Identification Based on Visual Features
WANG Xiao,ZHANG Xia-fen,HAN De-zhi
(College of Information Engineering,Shanghai Maritime University,Shanghai 21306)
The digitalization of calligraphy paper books enables convenient use for academic researchers and calligraphy learners.Identifies the calligraphy style by extracting and modeling calligraphy image features in character level and stroke level:Firstly extracts characters features.Second,extracts features of stroke by the crawler and stroke features are extracted.Totally,24 style features are used as the feature vector,when a user submits an unknown character,its 24 style features are extracted and compared with those features of 5 styles in the database five styles eventually,the style which has the biggest similarity probability assigned to the unknown.
Calligraphy Style;Style Identification;Visual Features;Style Quantification
1007-1423(2016)21-0039-08
10.3969/j.issn.1007-1423.2016.21.009
2016-04-25
2016-07-15
汪潇,女,硕士研究生,研究方向为图像处理与模式识别章夏芬,女,讲师,研究方向为图像处理与模式识别
韩德志,男,教授,研究方向为大数据、信息管理
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
科技创新与应用(2020年6期)2020-02-29
北方文学(2019年5期)2019-03-15
数学学习与研究(2018年15期)2018-11-12
法制博览(2018年7期)2018-11-05
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
中华诗词(2016年11期)2016-07-21
西南学林(2013年1期)2013-11-22
