
基于变长马尔科夫模型的用户购物行为分析
2016-09-20 08:14郑天宇吴爱华
现代计算机 2016年21期
郑天宇,吴爱华
(上海海事大学信息工程学院,上海 201306)
基于变长马尔科夫模型的用户购物行为分析
郑天宇,吴爱华
(上海海事大学信息工程学院,上海 201306)
用户的行为序列具有的连续性特征能够很好地反映用户的购买习惯或者用户的购物偏好,而这种特性在利用显式反馈算法进行商品推荐时往往会被忽略。因此,根据用户的购物行为等隐式反馈信息,提出一种基于变长马尔科夫模型的“自适应两阶段过滤”推荐算法。该算法主要是利用概率后缀树构建变长马尔科夫模型,然后利用该模型对用户行为序列数据集进行多次分类过滤,以判断出用户对商品的购买倾向,生成用户的商品推荐列表。实验表明所提出的推荐策略具有不错的推荐效果。
用户购物行为;概率后缀树;变长马尔科夫;个性化推荐
0 引言
在电子商务领域,以用户的浏览、收藏、加入购物车和购买为主要特征的用户购物行为是其主要的隐式用户反馈[1]信息。隐式反馈信息因为不需要用户主动地进行反馈操作,所以相对于显式反馈数据[2],隐式反馈数据有着收集成本低,数据规模大等特点。然而在当前的个性化推荐系统的研究中大量的分析挖掘是基于显式反馈信息,这不仅浪费了海量的隐式数据资源,也限制了个性化推荐系统的研究与发展。因此利用用户的购物行为等隐式反馈数据进行个性化推荐研究具有很高的现实意义。
在电商领域的用户购物行为除具有一般的序列数据的特点之外,其还有以下特征:
(1)用户的行为序列是随时间变化的动态变量,并且这种动态变量的发展总是承前启后的,当前变量的改变不一定马上在下一步的转移状态中体现出来。未来的状态也不单单与现在的状态有关,其还受到过去的一个或者多个状态的影响。即用户行为序列数据中元素的状态转移不具有一阶无后效性。
(2)用户行为特征所代表的用户购买意愿具有时效性。即以往的行为特征记录对用户当下的购买决定的影响随时间的推移逐渐减弱。
(3)用户行为记录中各行为特征之间的时间间隔对整个序列来说也是一种重要影响因素。例如序列A<浏览,浏览,Ø,浏览,浏览,加入购物车>(其中Ø代表序列存在的时间间隔)和序列B<浏览,浏览,浏览,加入购物车,购买>,如果将A中的时间间隔去掉,从表面上看A中的浏览次数大于B,即可以认为A中数据具有的购买可能性高于B。然而实际上A中的用户行为对购买行为的出现真正起到直接作用的可能仅仅是间隔之后的一系列行为。
基于以上对用户购物行为的分析,本文提出了将基于用户购物行为数据的个性化推荐研究问题转化为基于用户购物行为序列集的序列分类问题的思路,即根据用户购物行为所代表的用户购物兴趣倾向程度来判断用户是否会产生购买行为,并据此将用户行为序列分为购买类和非购买类两类序列数据集。考虑到用户购物行为序列无一阶无后效性和时效性特点,本文提出了基于变长马尔科夫模型的序列分类算法,并在此基础上提出了用户购买兴趣倾向度的概念和计算方式。本文的主要贡献有:
(1)利用变长马尔可夫模型能够模拟多个以往序列元素对未来元素的跳转概率的影响来解决用户购物行为序列中元素跳转的无一阶无后效性的问题。
(2)改进了变长马尔可夫模型的相似度计算方式,提出了自适应的相似度计算方法以解决用户的行为序列元素的时效性要求。
(3)提出两阶段过滤法,使得每一次的预测结果都可以成为下一次预测模型的训练样本集,能够达到动态地跟踪用户行为习惯的效果,解决了用户行为特征数据因时间久远而与用户当前行为习惯相差太大的问题。同时,也提高了模型构建的效率和预测的准确性。
1 相关工作
目前对用户购物行为研究方法根据其利用隐式反馈数据的方法的不同可以将其分为两类:直接利用隐式反馈数据法和将隐式反馈数据转化为显式评分 (间接利用)方法。间接的利用隐式反馈数据方法,先对各种隐式反馈特征赋予一定的权重,将其转化为显式的评分数据,然后再利用已有的显式反馈算法加以处理。如文献[3]中将隐式数据转化为显式数据之后再将其转化为分类问题处理,文献[4]中利用加权的序列模式挖掘方法。这类方法在对用户的行为特征进行评分时确定其评分的权重太过随意,而且这种直接的转换方式会忽略掉用户行为特征所具有的实效性的特点。如<a,d,a,a,b,a,a,d>,<a,b,a,a,c,a,a,b>(其中 a代表浏览,b代表收藏,c代表加入购物车,d代表购买),其中序列元素a,b,d在转化为显式数据时其所代表的行为权重是一样的,然而因为序列具有的时效性特点,使得不同的位置的相同元素所代表的用户对商品“感兴趣”程度是不一样的。相比间接利用方式,直接利用用户的隐式反馈数据克服了“打分”的缺陷,如BPR(Bayesian Personalized Ranking)[5],贝叶斯分类[6-7],这两种算法都为能考虑到用户购物行为序列的时效性问题,当用户行为序列数据变化很小的时效果明显,但是当用户行为序列数据变化很大时,其并不能及时地反映用户兴趣的变化。而本文提出的基于变长马尔可夫模型克服了以上这些方法存在的不足。
2 模型及相关概念的介绍
本节主要讨论用户购物行为序列数据的相关定义并介绍分析若干的相关工作。首先说明全文中使用到的相关概念及记号。
定义1用户的购买行为特征是指用户在购物网页上的操作标识,如浏览、收藏、加入购物车、购买等。设αi为用户的一个行为特征,集合A={α1,α2,…,αi}为用户的所有可能的行为特征集.为了解决用户行为序列中时间间隔被忽略的问题,特别定义两个特殊符号作为行为序列的间隔符,Ø代表一条行为序列中的短期间隔(以小时为单位),$代表一条行为序列的长期间隔(以天为单位)。则最终的行为集合A={α1,α2,…,αi,$}。
定义 2 给定一个用户集U={u1,u2,u3,…,up},一个商品目录集I={e1,e2,e3,…,eq},用户ui对商品ej的一条浏览行为序列为 s'uiej={s1,s2,…,sl}。
其中sl∈A,sl称为序列 s'uiej的一个元素;l称为序列 s'uiej'的长度,表示|s'uiej|;1~l之间的数字称为序列的位置。由所有的用户的行为序列组成的集合表示为S={sm'|sm'=s'uiej,ui∈U,ej∈I},m是序列集的个数。
变长马尔可夫模型[8]是一个平稳随机过程{Xn,n= 0,1,2,…,Xi∈Σ},其中Σ为有限状态集{xi},模型中的转态转移概率为:
其中,k是模型的阶,有限序列(xn-k,…,xn-1)称为子序列。倘若将用户行为序列集对应于状态集Σ,则用户行为序列也可看成一个平稳的随机过程,相应的用变长马尔可夫模型表示如下:
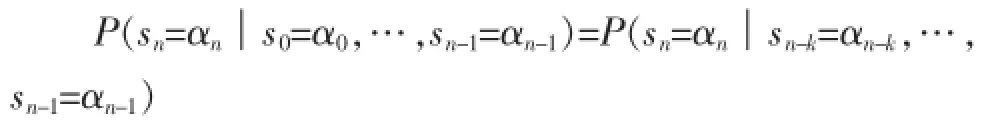
将用户行为序列依据其是否产生购买将其分为购买类和非购买类,利用训练算法为每一个类别训练一个变长马尔可夫模型。然后对每一个新的未知序列s'= {s1,s2,…,sm},计算s'与每一个模型的相似度。序列与模型的相似度计算公式如下:
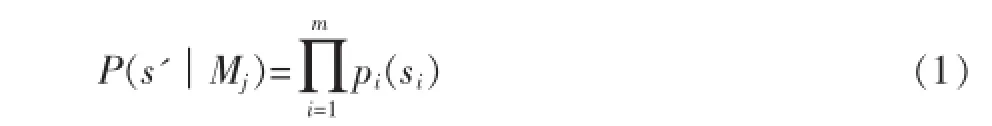
其中,pi(si)=p(si|si-k,…,si-1)(k<i<l,l是序列的长度,k是马尔科夫模型的阶数).当i≤k时,有:
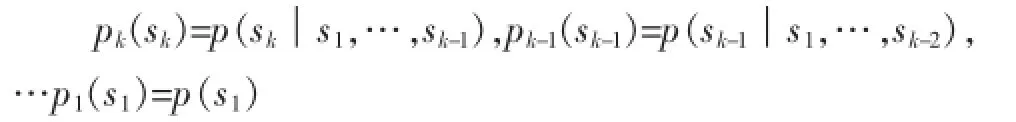
上式中的pi(si)又称为由以往的一段序列状态si-k,…,si-1跳转到下一个序列状态si的跳转概率,它的计算公式如下:
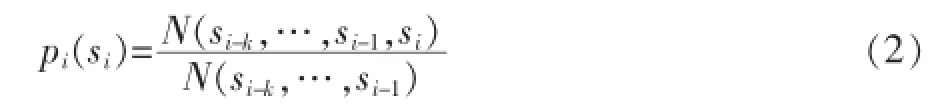
其中,N(si-k),…,si-1,si)表示在分类训练模型Mj中序列si-k,…,si-1,si出现的次数。序列模型Mj由马尔科夫模型训练得来,在3.2节中会详细讲解模型的构建过程。
定义3用户ui对商品ej做出购买决定的倾向程度θij,是用户的行为序列s'={s1,s2,…,sm}与训练集中购买行为序列特征类M1的相似度和非购买行为序列特征类M2的相似度的比值。其计算公式如下:
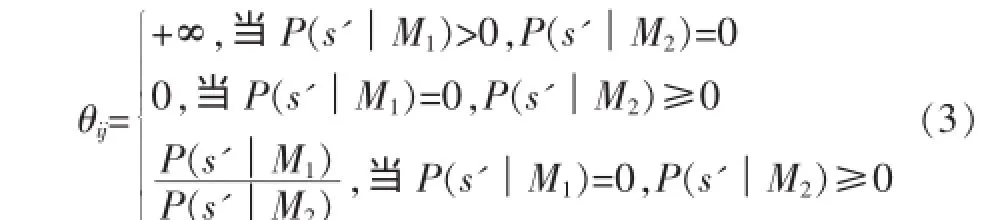
通常当P(s'|M1)>P(s'|M2)时,判定序列s'属于购买类M1。因此,设阈值δ(δ≥1),当用户ui对商品ej做出购买决定的倾向度θij>δ时,则由用户ui对商品ej组成的二元<ui,ej>作为推荐数据集输出。需要注意的是,当θij等于无穷大时,将其设为一个足够大的值,一般设为θij>1值的均值。
定义4样本集有若干个类别,每个类别都有模型Mi与之对应,对于任意序列s',若序列s'与模型Mi的相似度P(s'|Mi)大于序列s'同其余模型的相似度,则称序列s'相似于模型Mi,亦可称序列s'属于类别Mi。若有模型PMi中的每一条序列都相似于Mi,则称PMi是Mi的子类。
性质1设序列a,模型M1和PM1,PM1是M1的子类,若序列a相似于PM1,则a一定相似于M1。即若序列a属于类PM1,则其也属于类M1。
性质2若PM1是M1的子类,子类PM1的序列特征要高于M1。
3 变长马尔科夫模型的构建与算法设计
在下面各个小节中,将一一介绍基于概率后缀树的变长马尔可夫模型的构建方法,相似度的自适应计算方法以及两阶段模型的实现过程。
3.1 概率后缀树(PST)的构建
在实现变长马尔科夫模型的算法中概率后缀树[9]算法要比一般的CA算法计算复杂度低,并且其可在线性时间与空间复杂度内构建[10]。因此本文采用概率后缀树算法来构建变长马尔科夫模型。本节主要是简要介绍一下概率后缀树的结构,并给出变长马尔可夫模型的概率后缀树构造过程。
概率后缀树(PST)模型是基于后缀树建立起来的,该模型树是一棵非空树。树中每一个PST节点都代表一个行为序列元素,并且每个节点都包含一个|A|维概率分布向量(|A|是指用户行为特征集的个数)。并且树中的每个节点的出度在0到|A|之间,每条边代表A中的一个符号标记,每个节点的边无重复标记出现,每个节点序列是由根节点到该节点所经过的边的标记构成。根节点的概率向量是A集合中每个行为事件的无条件概率。其他节点的概率分布向量是该序列节点的下一个行为事件出现的条件概率组成。例如,有序列s,它的下一个事件α出现的概率为p(α|s)。p(α|s)等于序列{s,α}出现的次数/序列s出现的次数。
如图1所示一个序列s=accactact
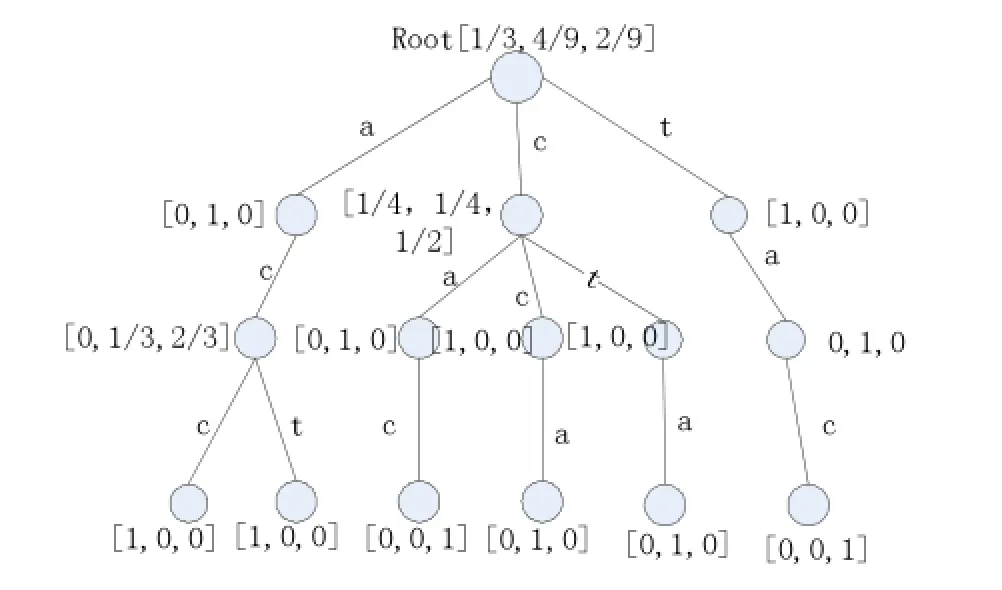
图1
图2 树中的每条边代表一个字符如a,c,t,每个节点存储着有这个节点跳转到下一个节点的条件概率向量,如[1/3,4/9,2/9],[0,1/3,2/3]。如由行为特征序列a跳转到状态c的概率为P(c|a)=1,由行为特征序列ac跳转到状态c的概率为P(c|ac)=1/3。
本文的PST的构造算法是基于Ukkonen法[11]构建的,则本文的PST树的构建伪代码介绍如下:
算法:Build-PST(S):
输入:训练数据集S,事件集合A
输出:PST树
Begin
初始化PST,根节点的概率向量值为每个符号在所有的符号序列中出现的相对频率。
当S≠Ø,取s∈S并从S中删除s:利用Ukkonen方法将序列s中元素加入树中
If∃σ∈A:
计算p(σ|s)→proArray End
3.2 自适应分类部分
在变长马尔科夫模型中,高阶马尔科夫增强马尔科夫模型的分类预测能力,然而同时其也面临究竟多少阶的马尔科夫模型合适的问题。文献[12]认为高阶模型可以减少预测的不确定性,但阶数的高低有一个改善的极限,而这个极限可以通过历史数据的最大相关性获得。在预测用户属于哪个类别(购买类/非购买类)时如果为预测模型确定一个相对高的阶数,而用户的序列数据不能支持这种阶数,也即序列的深度过大出现跳转概率为0的情况,这时有可能导致多个模型的预测数据都为0的情况,此时就无法对其进行相关性分类判定。针对这种情况,本文提出一个自适应的k阶马尔科夫模型,使得模型可以根据用户的历史序列数据的相关性在1阶到k阶马尔科夫模型中进行适配,最终使用户的序列数据与模型的相似性数据能够达到最大值。即:
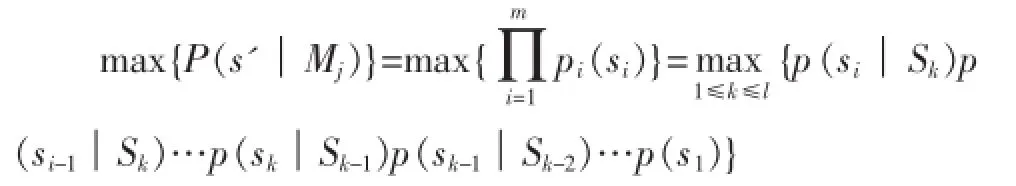
其中,Sk={si-1,si-2,…,si-k}表示序列元素si的前k个元素。
自适应分类算法AdaptiveVLMM(S,M)如下:
输入:序列s,模型M=Build-PST(TrainingData)
输出:相似度Value Begin
For k in(1,length(s))
Value[k]=P(s'|M)//用户序列与购买模型M的相似度
Return Max(Value)End
3.3 两阶段过滤策略
用户的浏览网页的行为习惯会随时间的变化而不断的变化,所以用户的购物行为序列数据的时效性是个不能忽视的问题。例如,在换季的时候,用户的购物行为可能就有别于以往。本文在自适应的基础上又采用了两阶段过滤的动态跟踪用户行为变化的策略。将每次的推荐结果集按预测正确和预测不正确分类,作为构建下次预测模型的数据源。
根据性质1,2可知,利用第二阶段得到的准确与不准确数据集进行下一次预测模型的建模,使得最后筛选出来的新行为序列所代表用户的购买倾向度要远远高于第一阶段得到的用户购买倾向度。
利用两阶段过滤法,在保持足够明显的分类特征的同时使得模型的构建时间和后期的序列与模型的相似度计算时间大大减小,提高了算法运行效率。下面给出两阶段算法的详细介绍及相关流程图例。
第一阶段先将初始序列数据集分为购买类和非购买类两类,并分别对两类数据集进行PST建模,形成购买模型M1和非购买模型M2。之后利用公式(1)计算预测数据集中每一条序列记录同模型M1,M2相似度,并根据公式(3)计算得到θij,选取θij值大于指定阈值δ的数据集作为新的候选推荐数据集S'。第二阶段将推荐数据集S'与验证数据集进行比对验证得到准确数据集S1'和非准确数据集S2'。然后分别对S1'、S2'进行PST建模得到PM1和PM2。之后将新的待预测数据集同模型PM1和PM2进行相似度计算并得到θij,最后选取θij>δ的数据集作为最终的推荐数据集。数据训练、验证各阶段的筛选比对过程如图2所示。
第一阶段过滤算法如下:
输入:训练数据集TrainingData,分类标记数据集C,测试数据集S,验证数据集W,阈值δ
输出:分类行为序列特征集S1',S2'

浏览行为序列
Compare(Candidate set,W)→S1',S2'
Return S1',S2'
End
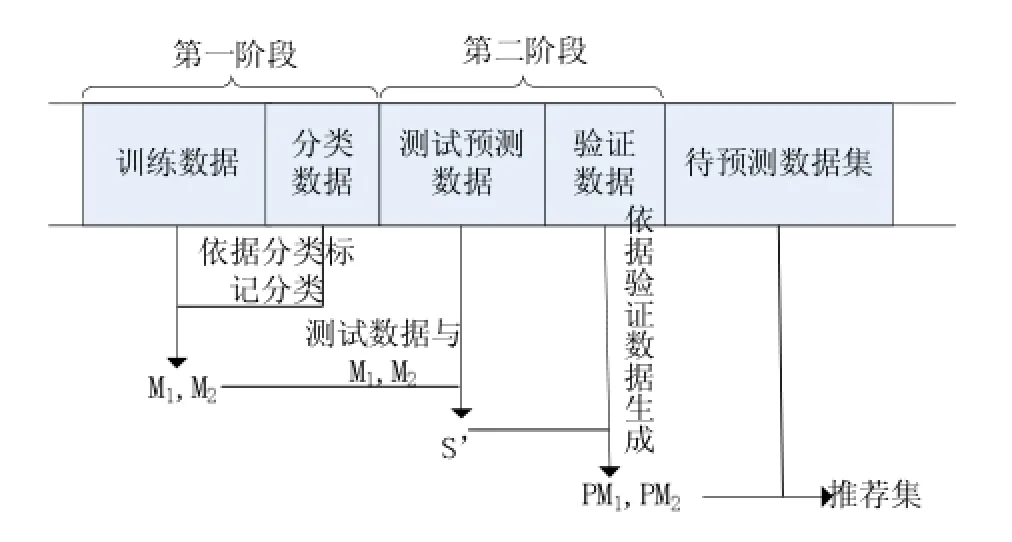
图2
图2 其中训练数据,分类数据,测试预测数据,验证数据是按时间先后顺序排序
第二阶段过滤算法如下:
输入:第一阶段得到的分类行为序列数据集S1',S2',待预测数据集S,阈值δ
输出:推荐数据集Set Begin
Build-PST(S1')→PM1Build-PST(S2')→PM2For siin S
AdaptiveVLMM(si,PM1)→Value_1
AdaptiveVLMM(si,PM2)→Value_2
θij=Value_1/Value_2
If θij≥δ:
<ui,ej>→Candidate set
Return Candidate set
End
本实验的主要目标利用“自适应两阶段过滤法”处理12月18日之前的数据,根据得到用户购买倾向程度值预测12月19日这天用户购买决定,然后进行相应商品的推荐。
根据以上分析可知,在预测天的前两天的行为数据转化率最大。所以本文选用12月19日前两天(17日~18日)的数据作为待预测数据,选用距离待预测数据前六天 (12月11日~12日数据作为训练数据集,13日作为分类标记数据集,14~15日数据作为测试数据集,16日作为验证数据集)的数据来构建模型。
4 实验结果
本节首先介绍实验所用数据集以及相关数据的处理,之后在进一步的说要实验的设置、评价标准以及不同阈值直接的对比结果,最后给出同其他算法的对比实验结果并对实验结果进行了相依的分析。
4.1 数据集
本文实验所采用的数据来自于2015年阿里巴巴的天池大数据平台的移动推荐算法竞赛[13],该数据主要包含了一定量的用户在2014年中的一个月时间(11.18~12.18)之内的移动端行为数据。这些行为数据主要的是指用户对某一商品的“浏览,收藏,加入购物车,购买”等操作。总的数据量包含了144321条记录。本文先将原数据集中的数据格式处理成以<userid,itemid>为主键的用户浏览行为序列数据集。本文将不连续的数据(即在用户行为在时间上有间隔的数据)进行插值,用0代表当天的数据浏览具有间隔,用5代表间隔了一天没有浏览行为记录。其数据格式如表1所示:

表1 生成的用户浏览序列数据集
其中user_id表示用户标识,item_id指商品标识,behavior_type指用户对商品的行为类型(其中1代表浏览,2代表收藏,3代表加入购物车,4代表购买)
同时,基于对样本数据的分析发现,用户的行为类型数据所代表的用户对商品的感兴趣程度具有实效性,即用户的各种行为类型数据转化为购买行为的转化率随时间的推移逐渐递减。如图3所示。
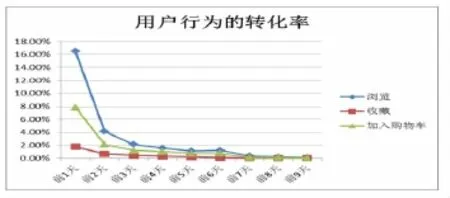
图3 在某一特定天之前的用户行为转化为购买的比率
4.2 实验环境及分析
本节通过实验来验证本文提出的基于马尔可夫模型的自适应两阶段算法的有效性。本文算法的实验环境为酷睿i3 3.0GHz双核CPU,4G内存,500G硬盘。操作系统为Windows 10 64位操作系统,代码全部使用Python编写并利用了Numpy等相关工具包做数据清洗的相关工作。本文对实验的评判主要是使用综合评价指标F1值。
为了有效的评估模型的优劣,本文选取文献[3]中的逻辑回归模型和BPR[14]加以比较。其中逻辑回归是将隐式数据转换为显式数据的形式加以分类处理,BPR直接运用隐式数据的概率进行处理。本文算法与这两种算法的F1值的平均值比较如表2所示,可知本文算法的F1值在总体上优于其他两类算法:
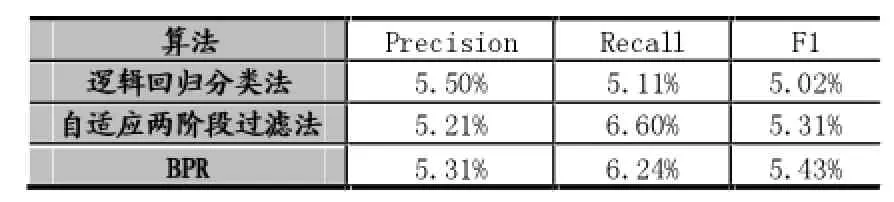
表2 三种算法的准确率、召回率和F1值的平均值比较
5 结语
本文的提出的“自适应两阶段过滤法”是完全用户的隐式反馈数据建立的,该方法是利用变长马尔可夫模型对用户的购买行为序列进行购买兴趣倾向度计算,并依此为依据将那些购买兴趣倾向度大于某一设定阈值的<用户,商品>二元作为推荐商品输出。这种方法避免了人为地对用户行为进行打分,将隐式数据转换为显式数据后进行商品推荐的缺陷,更加准确地反映了用户行为所代表的用户的购买意愿。但是,该方法的不足之处,构建变长马尔可夫模型的空间和时间开销都非常大。鉴于此,后续的研究考虑利用分布式计算来解决这些问题。
[1]Bobadilla J,Ortega F,Hernando A,et al.Recommender Systems Survey[J].Knowledge-Based Systems,2013,46(1):109-132.
[2]Oard D W,Kim J.Implicit Feedback for Recommender System[C].Massachusetts Institute of Technology,Department of Electrical Engineering and Computer.2010:81--83.
[3]王聪.基于用户行为的个性化推荐算法研究[D].哈尔滨工业大学.2015:17-31
[4]Duen-Ren Liu,Chin-Hui Lai,Wang-Jung Lee.A Hybrid of Sequential Rules and Collaborative Filtering for Product Recommendation[J].Information Sciences,2009,179(20):3505-3519.
[5]Lerche L,Jannach D.Using graded Implicit Feedback for Bayesian Personalized Ranking[C].ACM Conference on Recommender Systems.ACM,2014:353-356.
[6]Liu D R,Lai C H,Lee W J.A Hybrid of Sequential Rules and Collaborative Filtering for Product Recommendation[J].Information Sciences,2009,179(20):3505-3519.
[7]许昕.基于用户隐式反馈的个性化资讯推荐系统研究与实现[D].北京工业大学.2012:22-50
[8]Leonardi F G.A generalization of the PST Algorithm:Modeling the Sparse Nature of Protein Sequences[J].Bioinformatics,2006,22 (11):1302-1307.
[9]Ron D,Singer Y,Tishby N.The Power of Amnesia:Learning Probabilistic Automata with Variable Memory Length[J].Machine Learning,1996,25(2-3):117-149.
[10]Schulz M H,Weese D,Rausch T,et al.Fast and Adaptive Variable Order Markov Chain Construction[M].Algorithms in Bioinformatics.Springer Berlin Heidelberg,2008:306-317.
[11]Ukkonen E.Online construction of suffix trees[J].Algorithmica,1995,14(3):249-260.
[12]Bhattacharya A,Das S K.LeZi-update:an Information-Theoretic Approach to Track Mobile Users in PCS Networks[C].Proceedings of the 5th Annual ACM/IEEE International Conference on Mobile Computing and Networking.ACM,1999:1-12.
[13]阿里巴巴天池大数据平台,https://tianchi.aliyun.com/competition/information.htm?spm=5176.100067.5678.2.DG4xjr&raceId=1
[14]Rendle,Steffen,Freudenthaler,Christoph,Gantner,Zeno,et al.BPR:Bayesian Personalized Ranking from Implicit Feedback[C]. Conference on Uncertainty in Artificial Intelligence.AUAI Press,2012:452-461.
Analysis of User's Shopping Behavior Based on Variable Length Markov Model
ZHENG Tian-yu,WU Ai-hua
(College of Information Engineering,Shanghai Maritime Univeristy,Shanghai 201306)
User behavior sequence with the continuity features can be a very good response to user's buying habits or the user's shopping p
,and this characteristic in the explicit feedback algorithm is recommended products tend to be ignored.Therefore,according to the user's shopping behavior and implicit feedback information,proposes a model based on variable length Markov“two stage adaptive filtering”recommendation algorithm.The algorithm is mainly using probabilistic suffix tree construction of variable length Markov model,and then uses the model of user behavior sequence data set several times of classification and filtering,to determine the user of the commodity purchase intention,user generated commodity recommendation list.Experiments show that the proposed recommended strategy has good recommendation effect.
User Shopping Behavior;Probabilistic Suffix Tree;Variable Length Markov;Personalized Recommendation
1007-1423(2016)21-0008-07
10.3969/j.issn.1007-1423.2016.21.002
郑天宇(1989-),男,河南信阳人,硕士研究生,研究方向为数据挖掘、个性化推荐系统
2016-05-04
2016-07-20
吴爱华(1976-),女,上海人,博士,副教授,研究方向数据挖掘、不一致数据库对比
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
有色金属(矿山部分)(2021年4期)2021-08-30
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
计算技术与自动化(2019年3期)2019-11-05
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
科技创新导报(2019年31期)2019-04-07
